背景意义
研究背景与意义
随着全球食品产业的快速发展,食品安全和质量控制日益成为社会关注的焦点。食品分类与实例分割技术的应用,能够有效提升食品识别的准确性和效率,为食品监管、营养分析以及智能餐饮等领域提供重要支持。传统的食品识别方法多依赖于人工经验,存在主观性强、效率低下等问题,而基于深度学习的计算机视觉技术则为解决这些问题提供了新的思路。
YOLO(You Only Look Once)系列模型以其高效的实时检测能力和较高的准确率,广泛应用于目标检测和实例分割任务。YOLOv11作为该系列的最新版本,进一步优化了模型结构和算法性能,具备更强的特征提取能力和更快的推理速度。通过对YOLOv11的改进,结合FOOD103数据集的丰富类别信息,能够实现对多种食品的精准分类与实例分割,为食品行业的智能化转型提供技术支持。
FOOD103数据集包含7100张图像,涵盖103种不同类型的食品,数据的多样性和丰富性为模型的训练提供了良好的基础。该数据集不仅包含常见的水果、蔬菜、肉类等食品,还涵盖了多种加工食品和调料,能够有效提高模型的泛化能力和适应性。通过对该数据集的深入研究,可以推动食品图像识别技术的发展,为食品安全监测、智能厨房、个性化饮食推荐等应用场景提供强有力的技术支撑。
总之,基于改进YOLOv11的食品分类与实例分割系统的研究,不仅具有重要的学术价值,还有助于推动食品行业的智能化发展,提升食品安全管理水平,促进人们健康饮食的实现。通过这一研究,期望能够为未来的食品图像识别技术奠定坚实的基础,推动相关领域的进一步探索与应用。
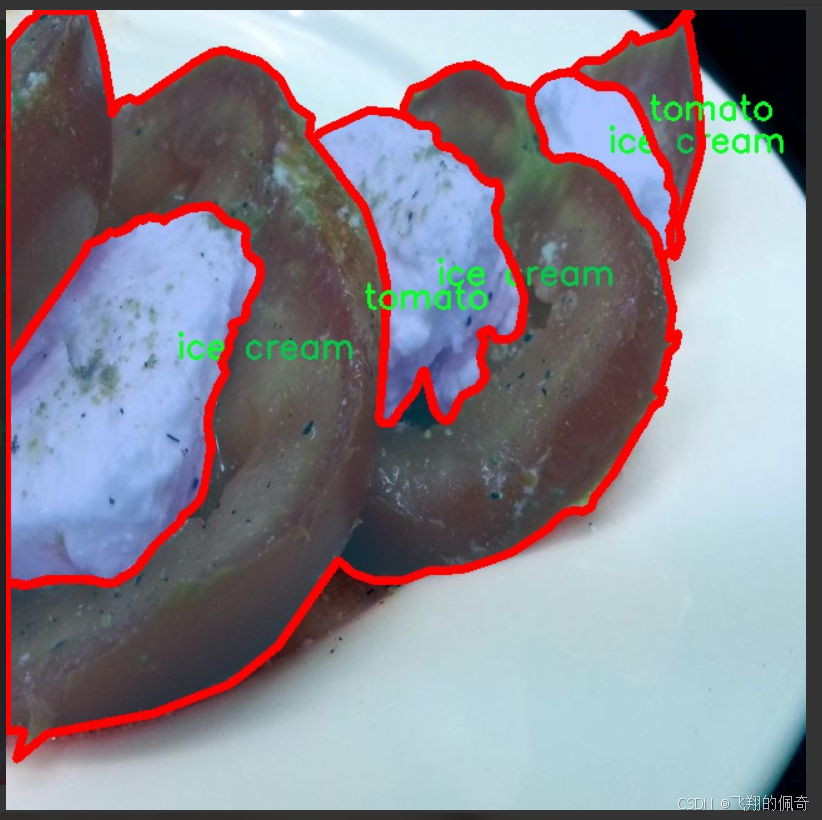
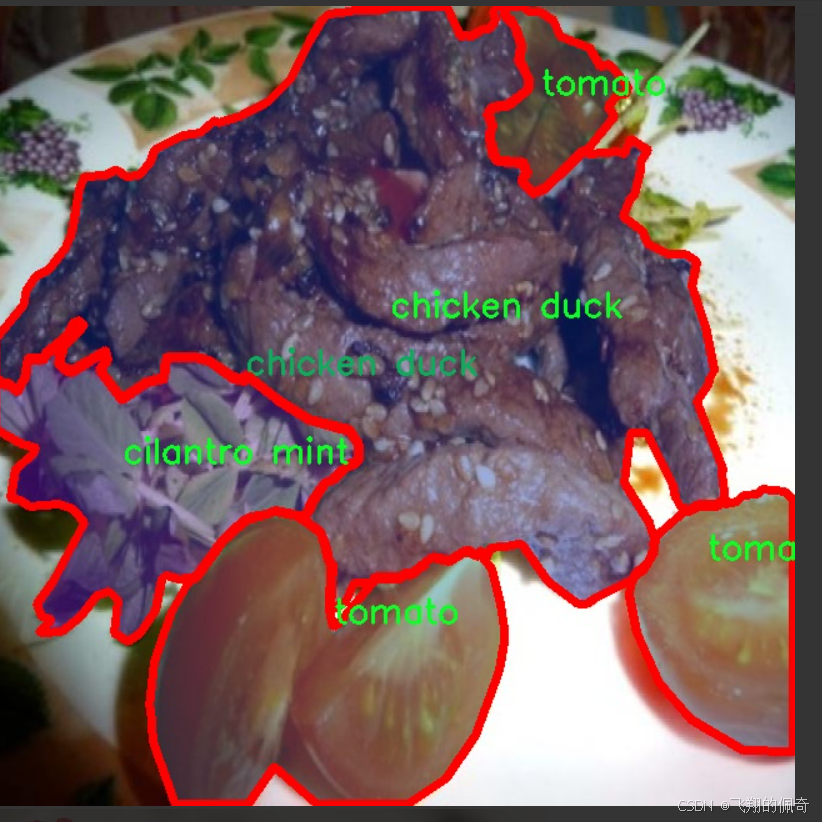
图片效果
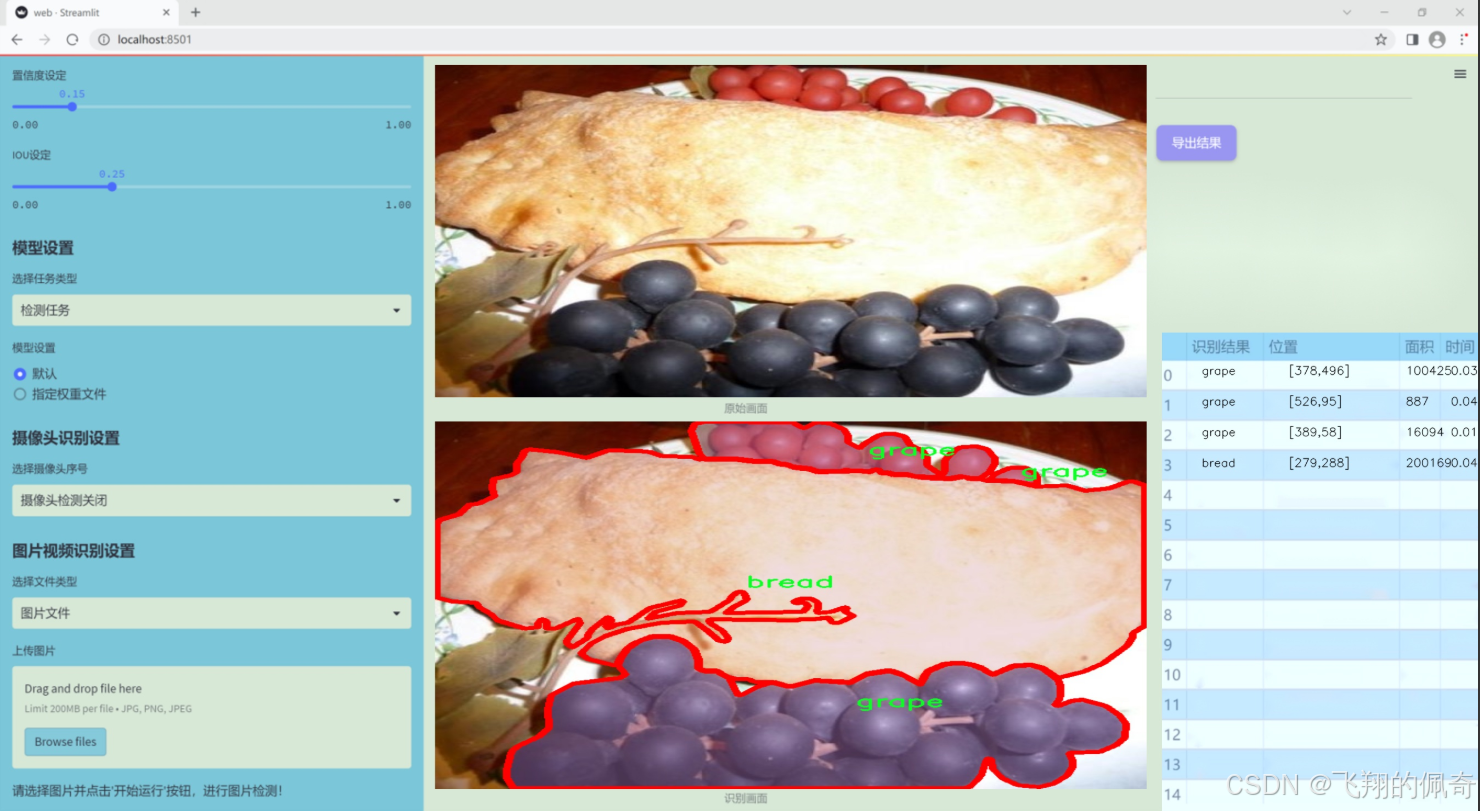
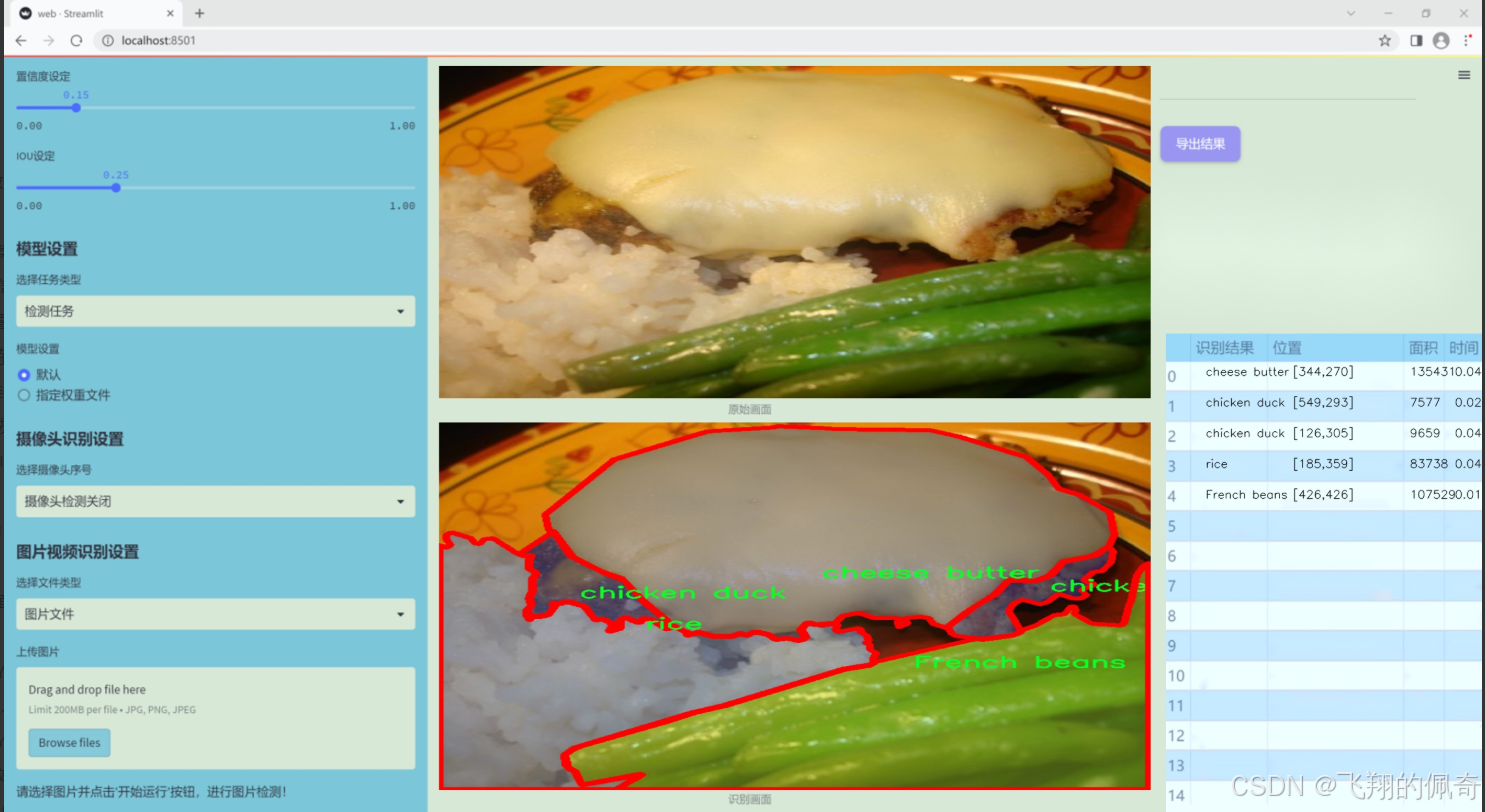
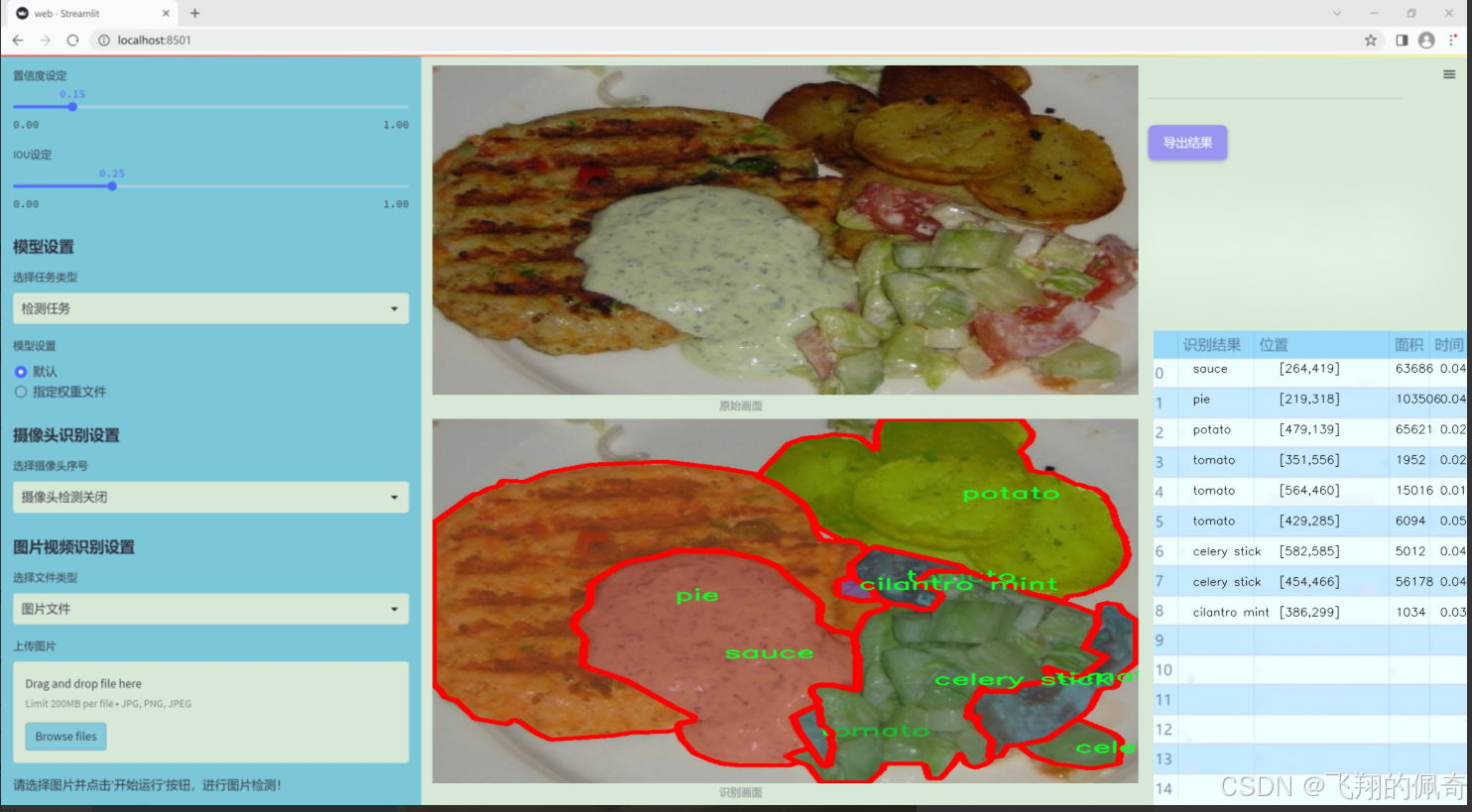
数据集信息
本项目数据集信息介绍
本项目采用的食品分类与实例分割数据集为“FOOD103”,该数据集专为改进YOLOv11模型而设计,旨在提升其在食品识别与分割任务中的性能。FOOD103数据集包含103个不同的食品类别,涵盖了丰富多样的食材与食品类型,从新鲜蔬菜到精致甜点,能够为模型提供全面的训练素材。这些类别包括但不限于法式豆、杏仁、苹果、杏、芦笋、鳄梨、竹笋、香蕉、豆芽、饼干、蓝莓、面包、花椰菜、卷心菜、蛋糕、糖果、胡萝卜、腰果、菜花、芹菜棒、奶酪黄油、樱桃、鸡鸭、巧克力、香菜薄荷、咖啡、玉米、螃蟹、黄瓜、枣、干蔓越莓、鸡蛋、蛋挞、茄子、金针菇、无花果、鱼、薯条、炸肉、大蒜、生姜、葡萄、青豆、汉堡、花卷、冰淇淋、果汁、海带、杏鲍菇、猕猴桃、羊肉、柠檬、生菜、芒果、甜瓜、牛奶、奶昔、面条、秋葵、橄榄、洋葱、橙子、其他配料、香菇、意大利面、桃子、花生、梨、辣椒、派、菠萝、比萨、爆米花、猪肉、土豆、布丁、南瓜、油菜、覆盆子、红豆、米饭、沙拉、酱料、香肠、海藻、贝类、香菇、虾、雪豆、汤、豆类、葱、牛排、草莓、茶、豆腐、西红柿、核桃、西瓜、白蘑菇、白萝卜、葡萄酒、馄饨等。通过对这些类别的系统性标注,FOOD103数据集为深度学习模型提供了丰富的上下文信息,使其能够在复杂的食品场景中进行准确的分类与实例分割。
该数据集的多样性和丰富性不仅有助于提高模型的泛化能力,还能增强其在实际应用中的实用性,尤其是在餐饮、食品安全和营养分析等领域。通过使用FOOD103数据集,研究人员能够深入探索和优化YOLOv11模型的性能,推动食品识别技术的发展。
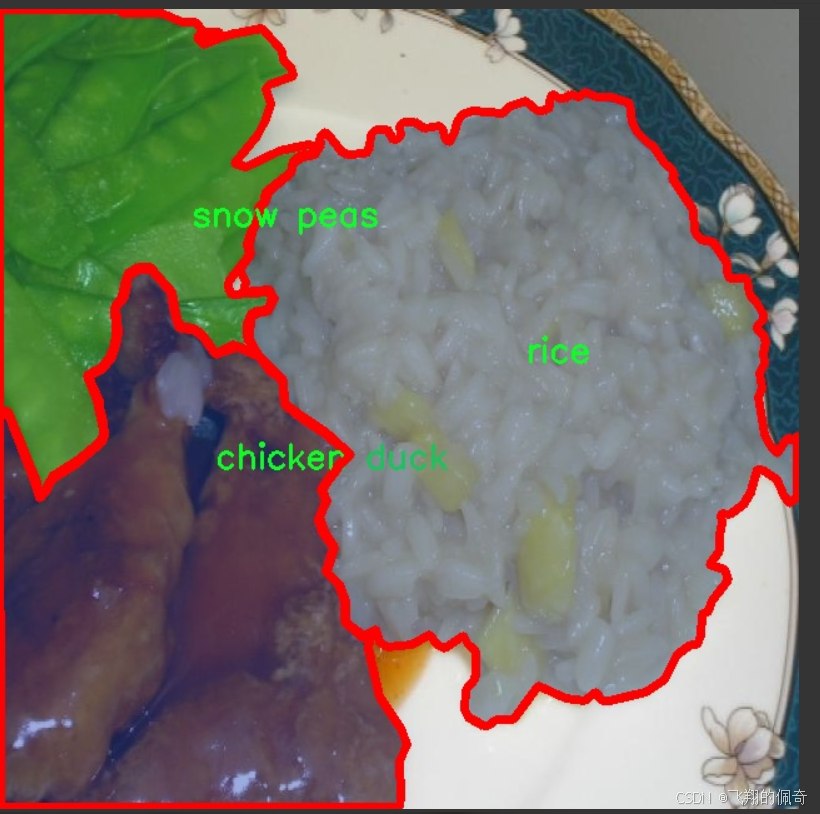


核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
from functools import lru_cache
import torch
import torch.nn as nn
from torch.nn.functional import conv3d, conv2d, conv1d
class KALNConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, conv_w_fun, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1, dropout: float = 0.0, ndim: int = 2):
super(KALNConvNDLayer, self).init()
# 初始化层的参数self.inputdim = input_dim # 输入维度self.outdim = output_dim # 输出维度self.degree = degree # 多项式的阶数self.kernel_size = kernel_size # 卷积核大小self.padding = padding # 填充self.stride = stride # 步幅self.dilation = dilation # 膨胀self.groups = groups # 分组卷积的组数self.base_activation = nn.SiLU() # 基础激活函数self.conv_w_fun = conv_w_fun # 卷积权重函数self.ndim = ndim # 数据的维度(1D, 2D, 3D)self.dropout = None # Dropout层初始化为None# 如果dropout大于0,则根据维度选择合适的Dropout层if dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)elif ndim == 2:self.dropout = nn.Dropout2d(p=dropout)elif ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 检查分组参数的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 创建基础卷积层和归一化层self.base_conv = nn.ModuleList([conv_class(input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])# 初始化多项式权重poly_shape = (groups, output_dim // groups, (input_dim // groups) * (degree + 1)) + tuple(kernel_size for _ in range(ndim))self.poly_weights = nn.Parameter(torch.randn(*poly_shape))# 使用Kaiming均匀分布初始化卷积层权重for conv_layer in self.base_conv:nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')nn.init.kaiming_uniform_(self.poly_weights, nonlinearity='linear')@lru_cache(maxsize=128) # 使用LRU缓存以避免重复计算Legendre多项式
def compute_legendre_polynomials(self, x, order):# 计算Legendre多项式P0 = x.new_ones(x.shape) # P0 = 1if order == 0:return P0.unsqueeze(-1)P1 = x # P1 = xlegendre_polys = [P0, P1]# 使用递推公式计算更高阶的多项式for n in range(1, order):Pn = ((2.0 * n + 1.0) * x * legendre_polys[-1] - n * legendre_polys[-2]) / (n + 1.0)legendre_polys.append(Pn)return torch.concatenate(legendre_polys, dim=1)def forward_kal(self, x, group_index):# 计算前向传播base_output = self.base_conv[group_index](x) # 基础卷积输出# 将输入x归一化到[-1, 1]范围x_normalized = 2 * (x - x.min()) / (x.max() - x.min()) - 1 if x.shape[0] > 0 else x# 如果存在Dropout,则应用Dropoutif self.dropout is not None:x_normalized = self.dropout(x_normalized)# 计算归一化后的x的Legendre多项式legendre_basis = self.compute_legendre_polynomials(x_normalized, self.degree)# 使用多项式权重进行卷积计算poly_output = self.conv_w_fun(legendre_basis, self.poly_weights[group_index],stride=self.stride, dilation=self.dilation,padding=self.padding, groups=1)# 合并基础输出和多项式输出x = base_output + poly_output# 进行层归一化if isinstance(self.layer_norm[group_index], nn.LayerNorm):orig_shape = x.shapex = self.layer_norm[group_index](x.view(orig_shape[0], -1)).view(orig_shape)else:x = self.layer_norm[group_index](x)# 应用激活函数x = self.base_activation(x)return xdef forward(self, x):# 前向传播,处理分组输入split_x = torch.split(x, self.inputdim // self.groups, dim=1)output = []for group_ind, _x in enumerate(split_x):y = self.forward_kal(_x.clone(), group_ind) # 对每个组进行前向传播output.append(y.clone())y = torch.cat(output, dim=1) # 合并所有组的输出return y
代码核心部分说明:
KALNConvNDLayer类:这是一个自定义的神经网络层,支持任意维度的卷积操作。它结合了基础卷积、归一化和多项式卷积的特性。
构造函数:初始化层的参数,创建基础卷积层和归一化层,并初始化多项式权重。
compute_legendre_polynomials方法:计算Legendre多项式,使用递推公式生成多项式序列,并利用LRU缓存提高效率。
forward_kal方法:实现了该层的前向传播逻辑,计算基础卷积输出、归一化输入、计算Legendre多项式并结合基础输出和多项式输出。
forward方法:处理输入数据的分组,并对每个组调用forward_kal进行计算,最后合并输出。
这个程序文件定义了一个名为 KALNConvNDLayer 的神经网络层及其子类,旨在实现一种新的卷积操作,结合了多项式基函数(Legendre多项式)和标准卷积操作。该层可以处理不同维度的输入(1D、2D、3D),并且具有可调的参数以适应不同的网络结构。
在 KALNConvNDLayer 类的构造函数中,首先初始化了一些卷积层的参数,包括输入和输出维度、卷积核大小、步幅、填充、扩张率等。该类还接受一个 conv_class 参数,允许用户指定使用的卷积类型(如 nn.Conv1d、nn.Conv2d 或 nn.Conv3d),以及一个归一化层的类(如 nn.InstanceNorm1d、nn.InstanceNorm2d 或 nn.InstanceNorm3d)。此外,构造函数中还定义了一个用于生成多项式权重的参数 poly_weights,并使用 Kaiming 均匀分布初始化这些权重,以提高训练的稳定性。
compute_legendre_polynomials 方法用于计算 Legendre 多项式,采用递归的方式生成指定阶数的多项式,并使用 lru_cache 装饰器来缓存计算结果,以避免重复计算。该方法返回的多项式将在前向传播中使用。
在 forward_kal 方法中,首先对输入进行基础卷积操作,然后将输入归一化到 [-1, 1] 的范围,以便于计算 Legendre 多项式。接着,调用 compute_legendre_polynomials 方法计算多项式基,并使用多项式权重进行线性变换。最后,将基础卷积输出和多项式输出相加,并通过归一化层和激活函数进行处理。
forward 方法负责处理整个输入,首先将输入按照组数进行分割,然后对每个组调用 forward_kal 方法进行处理,最后将所有组的输出拼接在一起,形成最终的输出。
此外,文件中还定义了三个子类 KALNConv3DLayer、KALNConv2DLayer 和 KALNConv1DLayer,分别用于处理三维、二维和一维数据。这些子类通过调用父类的构造函数来初始化特定的卷积和归一化层。
总体而言,这个程序文件实现了一种灵活且强大的卷积层,能够在不同维度上进行复杂的特征提取,并结合了多项式基函数的优势,以提高模型的表达能力。
10.4 convnextv2.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class LayerNorm(nn.Module):
“”" 自定义的层归一化(Layer Normalization)类,支持两种数据格式:channels_last(默认)和 channels_first。
channels_last 对应输入形状为 (batch_size, height, width, channels),
channels_first 对应输入形状为 (batch_size, channels, height, width)。
“”"
def init(self, normalized_shape, eps=1e-6, data_format=“channels_last”):
super().init()
# 权重和偏置参数
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps # 防止除零的微小值
self.data_format = data_format
if self.data_format not in [“channels_last”, “channels_first”]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):# 根据数据格式进行归一化处理if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":u = x.mean(1, keepdim=True) # 计算均值s = (x - u).pow(2).mean(1, keepdim=True) # 计算方差x = (x - u) / torch.sqrt(s + self.eps) # 标准化x = self.weight[:, None, None] * x + self.bias[:, None, None] # 应用权重和偏置return x
class Block(nn.Module):
“”" ConvNeXtV2中的基本模块(Block)。
Args:dim (int): 输入通道数。
"""
def __init__(self, dim):super().__init__()# 深度可分离卷积self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)self.norm = LayerNorm(dim, eps=1e-6) # 归一化层self.pwconv1 = nn.Linear(dim, 4 * dim) # 1x1卷积(用线性层实现)self.act = nn.GELU() # 激活函数self.pwconv2 = nn.Linear(4 * dim, dim) # 1x1卷积(用线性层实现)def forward(self, x):input = x # 保存输入以便后续残差连接x = self.dwconv(x) # 深度卷积x = x.permute(0, 2, 3, 1) # 转换维度顺序x = self.norm(x) # 归一化x = self.pwconv1(x) # 第一个1x1卷积x = self.act(x) # 激活x = self.pwconv2(x) # 第二个1x1卷积x = x.permute(0, 3, 1, 2) # 恢复维度顺序x = input + x # 残差连接return x
class ConvNeXtV2(nn.Module):
“”" ConvNeXt V2模型定义。
Args:in_chans (int): 输入图像的通道数。默认值:3num_classes (int): 分类头的类别数。默认值:1000depths (tuple(int)): 每个阶段的块数。默认值:[3, 3, 9, 3]dims (int): 每个阶段的特征维度。默认值:[96, 192, 384, 768]
"""
def __init__(self, in_chans=3, num_classes=1000, depths=[3, 3, 9, 3], dims=[96, 192, 384, 768]):super().__init__()self.downsample_layers = nn.ModuleList() # 下采样层# Stem层stem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),LayerNorm(dims[0], eps=1e-6, data_format="channels_first"))self.downsample_layers.append(stem)# 添加下采样层for i in range(3):downsample_layer = nn.Sequential(LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),)self.downsample_layers.append(downsample_layer)self.stages = nn.ModuleList() # 特征分辨率阶段for i in range(4):stage = nn.Sequential(*[Block(dim=dims[i]) for _ in range(depths[i])])self.stages.append(stage)self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # 最后的归一化层self.head = nn.Linear(dims[-1], num_classes) # 分类头def forward(self, x):res = [] # 存储每个阶段的输出for i in range(4):x = self.downsample_layers[i](x) # 下采样x = self.stages[i](x) # 通过当前阶段res.append(x) # 保存输出return res # 返回所有阶段的输出
代码说明:
LayerNorm:实现了层归一化,支持不同的通道格式,确保在不同的输入格式下都能正常工作。
Block:ConvNeXtV2的基本构建块,包含深度卷积、归一化、激活和残差连接。
ConvNeXtV2:整体模型的定义,包含多个下采样层和多个阶段,每个阶段由多个Block组成,最终输出分类结果。
这个程序文件实现了一个名为 ConvNeXt V2 的深度学习模型,主要用于图像分类任务。该模型的设计灵感来源于卷积神经网络(CNN),并结合了一些新的技术,如全局响应归一化(GRN)和层归一化(LayerNorm)。文件中包含多个类和函数,下面是对其主要内容的说明。
首先,文件导入了必要的库,包括 PyTorch 和一些用于模型构建的模块。接着,定义了一个名为 LayerNorm 的类,该类实现了层归一化,支持两种数据格式:通道优先(channels_first)和通道后置(channels_last)。在 forward 方法中,根据输入数据的格式应用相应的归一化操作。
接下来,定义了 GRN 类,它实现了全局响应归一化层。该层通过计算输入的 L2 范数并进行归一化,来调整特征的响应。它使用两个可学习的参数 gamma 和 beta 来控制输出。
然后,定义了 Block 类,表示 ConvNeXt V2 的基本构建块。每个块包含一个深度可分离卷积层、层归一化、点卷积层(通过线性层实现)、激活函数(GELU)、GRN 和另一个点卷积层。该块还支持随机深度(drop path)技术,以增强模型的泛化能力。
接着,定义了 ConvNeXtV2 类,这是整个模型的核心。构造函数中接受多个参数,包括输入通道数、分类类别数、每个阶段的块数、特征维度、随机深度率等。模型的构建包括一个初始卷积层和多个下采样层,随后是多个特征分辨率阶段,每个阶段由多个残差块组成。最后,模型包含一个层归一化层和一个线性分类头。
在模型的初始化过程中,使用 _init_weights 方法对卷积层和线性层的权重进行初始化,采用截断正态分布的方法。
forward 方法定义了模型的前向传播过程,输入经过下采样层和特征阶段的处理,最终返回每个阶段的输出。
此外,文件还定义了一个 update_weight 函数,用于更新模型的权重。该函数会检查权重字典中的每个键是否在模型字典中,并且形状是否匹配,符合条件的权重会被更新。
最后,文件提供了多个函数(如 convnextv2_atto、convnextv2_femto 等),用于创建不同规模的 ConvNeXt V2 模型。这些函数接受权重文件路径和其他参数,并在需要时加载预训练的权重。
总体而言,这个文件实现了一个灵活且强大的图像分类模型,结合了现代深度学习中的多种技术,适用于不同规模的任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式




![[Responsive theme color] 动态更新 | CSS变量+JS操控 | 移动端-汉堡菜单 | 实现平滑滚动](http://pic.xiahunao.cn/[Responsive theme color] 动态更新 | CSS变量+JS操控 | 移动端-汉堡菜单 | 实现平滑滚动)









——历史点、数学方式推导点)




