好吧,我承认我是个标题党!(不这样你会点进来享受这篇 ' 通俗易懂 ' 的好文章吗?) ![]()
正经标题:文本预处理全流程:从基础到实践
(屏幕前的你,帅气低调有内涵,美丽大方很优雅…
所以,求个点赞、收藏、关注呗~)
前言
伊索寓言里,农夫没理顺葡萄藤就猛浇水,藤蔓缠成一团,果子又小又涩。
这像极了做自然语言处理 —— 有开发者直接把爬来的文本喂给模型,结果 “差点没赢” 被认成输,“好得不得了” 成了三个无关词。
原始文本就像乱麻般的葡萄藤:乱码是野草,重复语气词是多余卷须,近义词异写是缠绕枝蔓。不先梳理干净,再聪明的模型也结不出 “准果子”。
本文跟着寓言思路,拆解预处理全流程:
- 剪除 “野草”(清乱码)
- 剪掉 “卷须”(去冗余)
- 理顺 “枝蔓”(统一表述)
新手入门、老手优化,做好这步,NLP 的 “葡萄藤” 才能结甜果。跟着诗人啊_开始整理藤蔓吧
目录
前言
文本预处理
1 认识文本预处理
1.1 核心作用
1.2 关键环节
1.3 语言适配
2 文本处理的基本方法
2.1 分词
示例(定制化文本)
工具:jieba(Python 主流分词库)
2.2 命名实体识别(NER)
示例(定制化文本延伸)
作用
工具推荐
2.3 词性标注
示例(定制化文本)
作用
2.4 小结
3 文本张量表示方法
3.1 核心目标
3.2 One - Hot 编码
示例(定制化词汇表)
实现代码
优缺点
3.3 Word2Vec 模型
示例(用 fasttext 实现)
工具优势
3.4 Word Embedding(词嵌入)
实现(PyTorch 示例)
核心价值
3.5 小结
4 文本数据分析
4.1 核心作用
4.2 分析维度
(1)标签分布(以分类任务为例)
(2)句子长度分布
(3)词频统计与词云
4.3 小结
5 文本特征处理
5.1 核心目标
5.2 N - Gram 特征
示例(定制化文本)
实现代码
5.3 文本长度规范
实现(Keras 示例)
5.4 小结
6 文本数据增强
6.1 核心目标
6.2 回译增强法
实现(调用有道翻译 API 示例) # 这个被封了看个思路旧县..现在直接用GTP
6.3 同义词替换
实现(jieba + 同义词词林)
总结
文本预处理
在自然语言处理(NLP)任务中,文本预处理是模型训练的基石。高质量的预处理能让模型 “读懂” 文本,直接影响最终效果。本章系统拆解文本预处理核心环节,从基础概念到代码实操,帮你构建完整知识体系。
1 认识文本预处理
1.1 核心作用
将原始文本转化为模型可理解的格式(如张量、规范长度的序列),同时通过分析数据分布,指导后续流程(如超参数选择、数据增强策略),最终提升模型评估指标(准确率、F1 值等)。
1.2 关键环节
文本预处理是一套 “流水线”,包含以下递进步骤:
- 文本处理基础方法:分词、词性标注、命名实体识别(拆解文本语义单元)。
- 文本张量表示:将词转化为数值向量(如 One - Hot、Word2Vec),让模型可计算。
- 文本数据分析:统计标签分布、句子长度等,发现数据问题(如样本不平衡)。
- 文本特征处理:增强有效特征(如 N - Gram)、规范数据格式(长度补齐 / 截断)。
- 文本数据增强:扩充数据集,提升模型泛化能力。
1.3 语言适配
本章方法覆盖中文 + 英文(最常用语言),实操中可灵活扩展到其他语种。
2 文本处理的基本方法
2.1 分词
定义:将连续文本拆分为词(或字)序列的过程。
- 英文依赖空格分词,中文需算法(如统计、深度学习)识别词边界。
示例(定制化文本)
原始文本:
诗人啊程序员,是我学习路上的引路人,帮我解开代码与创作的双重谜题!
分词结果(jieba精确模式):
['诗人', '啊', '程序员', ',', '是', '我', '学习', '路上', '的', '引路人', ',', '帮', '我', '解开', '代码', '与', '创作', '的', '双重', '谜题', '!']
工具:jieba(Python 主流分词库)
- 安装:
pip install jieba - 核心模式:
- 精确模式(默认):适合文本分析,优先精准切分。
import jieba content = "诗人啊程序员,是我学习路上的引路人..." result = jieba.lcut(content, cut_all=False) print(result) - 全模式:速度快,但会切出冗余组合(适合初步探索)。
result = jieba.lcut(content, cut_all=True) # 输出含冗余词:['诗人', '啊', '程序', '程序员', ...] - 搜索引擎模式:对长词二次切分(适合搜索场景)。
result = jieba.lcut_for_search(content) # 输出更细粒度:['诗人', '啊', '程序', '程序员', '学习', '路上', ...] - 自定义词典:添加专业词汇(如 “诗人啊程序员”),提升切分准确率。
jieba.load_userdict("custom_dict.txt") # 词典格式:词语 词频 词性 result = jieba.lcut(content) # 输出可能包含:['诗人啊程序员', ...]
- 精确模式(默认):适合文本分析,优先精准切分。
2.2 命名实体识别(NER)
定义:识别文本中的专有名词(人名、地名、机构名、时间、数字等)。
示例(定制化文本延伸)
诗人啊程序员中的“诗性代码”理念,像李白的浪漫与图灵的严谨融合,在人工智能峰会引发热议。
识别结果(简化示意):
- 人名:
李白 - 机构名:
人工智能峰会 - 专有概念:
诗性代码
作用
为情感分析、信息抽取、知识图谱提供关键实体,让模型聚焦核心信息。
工具推荐
- 中文:
jieba(基础版)、BERT - NER(深度学习版,需训练 / 加载模型)。 - 英文:
spaCy、NLTK。
2.3 词性标注
定义:标记文本中每个词的语法属性(如名词、动词、形容词)。
示例(定制化文本)
我在学习路上与程序员交流人工智能创意
标注结果(jieba.posseg):
[pair('我', 'rr'), pair('在', 'p'), pair('学习', 'v'), pair('路上', 'n'), ...]
# rr:人称代词;p:介词;v:动词;n:名词
作用
辅助模型理解语法结构,为句法分析、文本生成(如诗歌创作)打基础。
2.4 小结
- 分词是文本理解的 “第一步”,
jieba是中文场景的高效工具。 - 命名实体识别和词性标注,进一步拆解文本语义与语法,为高阶任务(如情感分析、知识图谱)提供支撑。
3 文本张量表示方法
3.1 核心目标
将词 / 文本转化为数值张量(如向量、矩阵),让模型通过数学运算 “理解” 语义。
3.2 One - Hot 编码
原理:用长度等于 “词汇表大小” 的向量表示词,仅对应词的位置为1,其余为0。
示例(定制化词汇表)
词汇表:["诗人啊程序员", "学习路上", "引路人", "代码谜题"]
One - Hot 表示:
"诗人啊程序员" → [1, 0, 0, 0]
"学习路上" → [0, 1, 0, 0]
实现代码
from tensorflow.keras.preprocessing.text import Tokenizer # 1. 构建词汇表
vocabs = ["诗人啊程序员", "学习路上", "引路人", "代码谜题"]
tokenizer = Tokenizer()
tokenizer.fit_on_texts(vocabs) # 2. 生成 One - Hot 编码
for word in vocabs: seq = tokenizer.texts_to_sequences([word])[0] # 词转索引 one_hot = [0] * len(vocabs) one_hot[seq[0] - 1] = 1 # 索引从 1 开始,需减 1 print(f"{word}: {one_hot}") # todo: 输出结果
'''
诗人啊程序员: [1, 0, 0, 0]
学习路上: [0, 1, 0, 0]
引路人: [0, 0, 1, 0]
代码谜题: [0, 0, 0, 1]
'''
优缺点
- 简单直观,易实现。
- 词汇表大时向量极度稀疏,且无法表达词间语义关联(如 “诗人” 和 “程序员” 的关联性)。
3.3 Word2Vec 模型
原理:通过无监督训练,将词映射为稠密向量(语义相关的词,向量距离更近)。
- 模式:
CBOW(用上下文预测目标词)、Skip - Gram(用目标词预测上下文)。
示例(用 fasttext 实现)
import fasttext# 1. 训练词向量(可替换为自定义语料)
model = fasttext.train_unsupervised("corpus.txt", model="skipgram", dim=100, minCount=1)# 2. 查看词向量
vec = model.get_word_vector("诗人啊程序员")
print(f"词向量维度:{vec.shape}") # 输出 (100,)# 3. 找相似词
similar_words = model.get_nearest_neighbors("程序员")
print(f"相似词:{similar_words}")# 输出结果:
'''
词向量维度:(100,)
相似词:[(0.10706065595149994, '</s>'), (0.10659360885620117, '我在学习过程中,感受到程序员的代码智慧与诗人的创作灵感交融。'), (-0.00556528102606535, '诗人啊程序员,是我学习路上的好朋友,总能帮我解答疑惑。'), (-0.03436730429530144, '编程如同写诗,需要逻辑的严谨和创意的迸发,程序员和诗人有相似的思维火花。')]
'''工具优势
- 捕捉词间语义关联(如 “程序员” 和 “开发者” 向量相近)。
- 支持生僻词处理(通过子词分词)。
3.4 Word Embedding(词嵌入)
原理:神经网络中可训练的 “词向量层”,随模型训练动态优化,更贴合任务需求。
实现(PyTorch 示例)
import torch
import torch.nn as nn# 1. 构建词汇表(假设已分词)
vocab = ["诗人", "程序员", "学习", "路上", ...]
vocab_size = len(vocab)
embedding_dim = 8# 2. 定义 Embedding 层
embedding = nn.Embedding(vocab_size, embedding_dim)# 3. 查看词向量(需先将词转索引)
word_index = {"诗人": 0, "程序员": 1}
word_vec = embedding(torch.tensor(word_index["诗人"]))
print(f"诗人的词向量:{word_vec.detach().numpy()}")# todo: 输出结果'''
诗人的词向量:[ 1.8813473 0.35883304 -0.34900337 -0.96565574 -0.15248121 1.4000998-1.0328294 0.48301077]
'''核心价值
- 为特定任务定制词向量(如情感分析中,“惊喜” 和 “失望” 的向量会随训练优化)。
- 可通过
TensorBoard可视化词向量,辅助分析语义关联。
3.5 小结
- One - Hot 适合小词汇表,Word2Vec 适合无监督语义挖掘,Word Embedding 适合任务定制。
- 选择方法时,需权衡语料规模、任务需求、计算成本。
4 文本数据分析
4.1 核心作用
通过统计分析,发现数据规律与问题(如样本不平衡、句子长度异常),指导后续预处理策略(如数据增强、长度规范)。
4.2 分析维度
(1)标签分布(以分类任务为例)
目标:检查样本是否平衡(如情感分析中 “正面”“负面” 样本比例)。
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt # 导入matplotlib用于显示图表# 模拟数据
data = pd.DataFrame({"text": ["诗人啊程序员不行", "代码创作顶呱呱", "学习感悟几乎没有", "程序员是诗人", "代码创作不行"],"label": [0, 1, 0, 1, 0] # 0: 负面,1: 正面
})# 设置中文字体,避免中文乱码
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]# 绘制分布
sns.countplot(x="label", data=data)# 添加标题和标签
plt.title("情感标签分布")
plt.xlabel("标签类型")
plt.ylabel("样本数量")# 替换x轴刻度为有意义的文本
plt.xticks([0, 1], ["负面 (0)", "正面 (1)"])# 显示图表(这一步是关键,没有它图表不会会显示图表)
plt.show()
图表:
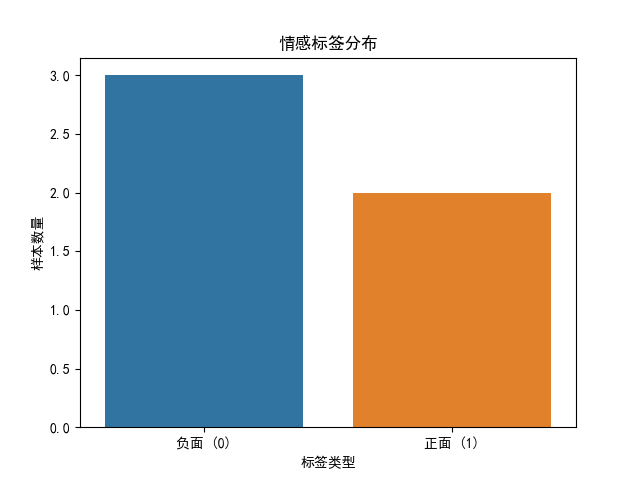
问题处理:若样本不平衡(如 1:9),可通过数据增强(回译、同义词替换)或采样(过采样少数类、欠采样多数类)调整。
(2)句子长度分布
目标:统计文本长度范围,为 “长度规范” 提供依据。
import pandas as pd # 导入 pandas 库,用于数据处理和分析
import jieba # 导入 jieba 库,用于中文分词# 导入数据
# 使用 pandas 的 read_csv 函数从 'data/train.csv' 文件中读取数据
# 'utf-8' 编码确保正确读取中文字符'''
train.csv 文件数据结构如下:label,text1,选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般1,15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错0,房间太小。其他的都一般。。。。。。。。。
'''
# 我们可以看到',' 作为列与列分隔符,所以sep = ',',将原本一列的label和text分成了两列
data = pd.read_csv('data/train.csv', encoding='utf-8', sep=',')# 打印数据的前 2 行,查看数据的基本情况
print("前2行数据:\n", data.head(2),data.head().shape)# 计算句子长度
# 使用 apply 函数和 lambda 表达式计算 'text' 列中每个句子的长度
# 将长度值存储在新的 'length' 列中
data['length'] = data['text'].apply(lambda x: len(x))
# 打印数据的前 2 行,查看句子长度计算的结果
print('新前2行数据:\n', data.head(2))# todo: 运行结果
前2行数据:label text
0 1 选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全...
1 1 15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很... (5, 2)
新前2行数据:label text length
0 1 选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全... 106
1 1 15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很... 56
实操建议:
- 若 90% 文本长度 < 100,可将最大长度设为 100(截断 / 补齐)。
- 若存在极端长文本(如 1000 字),需人工核验是否为无效数据。
(3)词频统计与词云
目标:发现高频词、分析文本主题。
import jieba.posseg as pseg
import pandas as pd
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 词云生成
def word_cloud(data_good, data_bad):# 生成好评词云# 1. 实例化一个词云对象wordcloud_good = WordCloud(font_path='C:/Windows/Fonts/simhei.ttf', width=1000, height=800, background_color='white',max_words=12163, max_font_size=100, random_state=42, scale=2)# 2. 生成词云wordcloud_good.generate(' '.join(data_good))# 3. 画图plt.imshow(wordcloud_good, interpolation='bilinear')plt.axis('off') # 隐藏坐标轴plt.title("好评词云", fontsize=18, fontproperties='simhei') # 设置标题plt.show() # 显示图像# 生成差评词云# 1. 实例化一个词云对象wordcloud_bad = WordCloud(font_path='C:/Windows/Fonts/simhei.ttf', width=1000, height=800, background_color='white',max_words=12163, max_font_size=100, random_state=42, scale=2)# 2. 生成词云wordcloud_bad.generate(' '.join(data_bad))# 3. 画图plt.imshow(wordcloud_bad, interpolation='bilinear')plt.axis('off') # 隐藏坐标轴plt.title("差评词云", fontsize=18, fontproperties='simhei') # 设置标题plt.show() # 显示图像# 生成好评与差评混合词云# 1. 实例化一个词云对象wordcloud_mixed = WordCloud(font_path='C:/Windows/Fonts/simhei.ttf', width=1000, height=800, background_color='white',max_words=1000, max_font_size=100, random_state=42, scale=2)# 2. 生成词云wordcloud_mixed.generate(' '.join(data_good + data_bad))# 3. 画图plt.imshow(wordcloud_mixed, interpolation='bilinear')plt.axis('off') # 隐藏坐标轴plt.title("好评与差评混合词云", fontsize=18, fontproperties='simhei') # 设置标题plt.show() # 显示图像# 测试
if __name__ == '__main__':data = pd.read_csv('./data/train.csv', sep=',')# process_data(data)print(f'数据总量---> {len(data)}条')data_t = data[data['label'] == 1]['text']print(f'好评数据量---> {len(data_t)}条')data_f = data[data['label'] == 0]['text']print(f'差评数据量---> {len(data_f)}条')list_t = []for line in data_t:for word, flag in pseg.lcut(line):if flag == 'a':list_t.append(word)print(f'好评形容词---> {len(list_t)}个')list_f = []for line in data_f:for word, flag in pseg.lcut(line):if flag == 'a':list_f.append(word)print(f'差评形容词---> {len(list_f)}个')word_cloud(list_t, list_f)# todo: 输出结果
'''
好评数据量---> 4799条
差评数据量---> 4801条
好评形容词---> 16368个
差评形容词---> 12163个'''词云图像:



价值:若高频词与任务无关(如 “的”“了”),需考虑停用词过滤。
4.3 小结
- 数据分析是 “预处理的预处理”,能帮你避开数据分布不均、无效数据等坑。
- 核心工具:
pandas(统计)、seaborn(可视化)、wordcloud(词云)。
5 文本特征处理
5.1 核心目标
- 增强有效特征:如 N - Gram(捕捉词的相邻关系)。
- 规范数据格式:统一文本长度(截断 / 补齐),适配模型输入。
5.2 N - Gram 特征
定义:提取文本中连续 n 个词的组合(如 2 - Gram:“诗人 啊”“啊 程序员”),补充语义信息。
示例(定制化文本)
分词列表:["诗人", "啊", "程序员", "是", "引路人"]
2 - Gram 特征:("诗人", "啊"), ("啊", "程序员"), ("程序员", "是"), ("是", "引路人")
实现代码
def create_ngram_set(input_list, n=2):return set(zip(*[input_list[i:] for i in range(n)]))# 调用
words = ["诗人", "啊", "程序员", "是", "引路人"]
ngrams = create_ngram_set(words)
print(f"2 - Gram 特征:{ngrams}")# todo: 输出结果
# 2 - Gram 特征:{('程序员', '是'), ('诗人', '啊'), ('啊', '程序员'), ('是', '引路人')}
价值:让模型捕捉 “词序关联”(如 “诗人” 常和 “创作” 搭配)。
5.3 文本长度规范
需求:模型输入需固定长度(如 RNN、Transformer 要求等长序列)。
实现(Keras 示例)
from tensorflow.keras.preprocessing.sequence import pad_sequences # 模拟数据(数值化后的文本序列)
sequences = [[1, 2, 3], [4, 5], [6, 7, 8, 9]] # 规范长度(最大长度 3,补齐用 0)
padded = pad_sequences(sequences, maxlen=3, padding="post", truncating="post")
print(padded)
# 输出:
# [[1 2 3]
# [4 5 0]
# [6 7 8]]
策略:
padding="post":在序列末尾补齐。truncating="post":超长时截断末尾。
5.4 小结
- N - Gram 补充词序信息,适合捕捉短语、搭配。
- 长度规范是模型输入的 “必修课”,需结合数据分析结果(如 90% 文本长度)设置
maxlen。
6 文本数据增强
6.1 核心目标
扩充数据集,缓解样本不平衡问题,提升模型泛化能力(让模型见更多 “变种文本”)。
6.2 回译增强法
原理:利用翻译工具,将文本译为其他语言(如中文→英文→中文),生成 “语义相似但表述不同” 的新样本。
实现(调用有道翻译 API 示例) # 这个被封了看个思路旧县..现在直接用GTP
import requests def back_translate(text): # 中文→英文 url = "http://fanyi.youdao.com/translate" data = { "from": "zh", "to": "en", "i": text, "doctype": "json" } res = requests.post(url, data).json() en_text = res["translateResult"][0][0]["tgt"] # 英文→中文 data["from"] = "en" data["to"] = "zh" data["i"] = en_text res = requests.post(url, data).json() return res["translateResult"][0][0]["tgt"] # 调用
text = "诗人啊程序员,是我学习路上的引路人"
new_text = back_translate(text)
print(f"原文本:{text}\n新文本:{new_text}")
# 输出示例:
# 原文本:诗人啊程序员,是我学习路上的引路人
# 新文本:诗人啊程序员,是我学习道路上的引路人
优化:
- 多语言接力翻译(如中→日→英→中),降低与原文本重复率。
- 控制翻译次数(≤3 次),避免语义失真。
6.3 同义词替换
原理:用同义词替换文本中的词(如 “好”→“优秀”),生成变体。
实现(jieba + 同义词词林)
import jieba
from synonyms import near synonyms # 需安装:pip install synonyms def replace_synonyms(text): words = jieba.lcut(text) new_words = [] for word in words: syns = near synonyms(word) if syns and len(syns[0]) > 1: # 存在同义词 new_words.append(syns[0][0]) # 选第一个同义词 else: new_words.append(word) return "".join(new_words) # 调用
text = "诗人啊程序员,帮我解开代码谜题"
new_text = replace_synonyms(text)
print(f"原文本:{text}\n新文本:{new_text}")
# 输出示例:
# 原文本:诗人啊程序员,
总结
文本预处理这几步看似琐碎,却是 NLP 的 “地基”。把数据 “洗” 干净,模型才能少踩坑、出效果~
觉得有用?点个关注~
系列文章持续更新中, 欲知后事如何,且听下回分解~
下一集链接---->
文本预处理:NLP 版 “给数据洗澡” 指南-CSDN博客

















![[系统架构设计师]系统架构基础知识(一)](http://pic.xiahunao.cn/[系统架构设计师]系统架构基础知识(一))

