随着人工智能技术的快速发展,多模态模型成为了当前研究的热点。多模态模型的核心思想是能够同时处理和理解来自不同模态(如文本、图像、音频等)的数据,从而为模型提供更加全面的语境理解和更强的泛化能力。
杨新宇,卡内基梅隆大学博士生,InfiniAI实验室与Catalyst实验室成员,AI领域的创新研究者之一。在其最新研究中,杨新宇创新提出了Multiverse模型,这一新型AI架构旨在突破传统模型的局限,通过动态调整并行度,实现更高效的推理与生成,推动AI模型在多任务和多模态数据处理上的进展。

本课题将分为上下两篇文章。本文作为上篇,将介绍Multiverse模型的设计理念与应用,深入探讨其创新过程及核心亮点。
一、模型架构设计与应用的出发点
基于数据特性——以CNN与RNN为例
为什么模型架构的设计往往需要以数据本身的特性为基础?可以从两个早期的经典例子谈起:
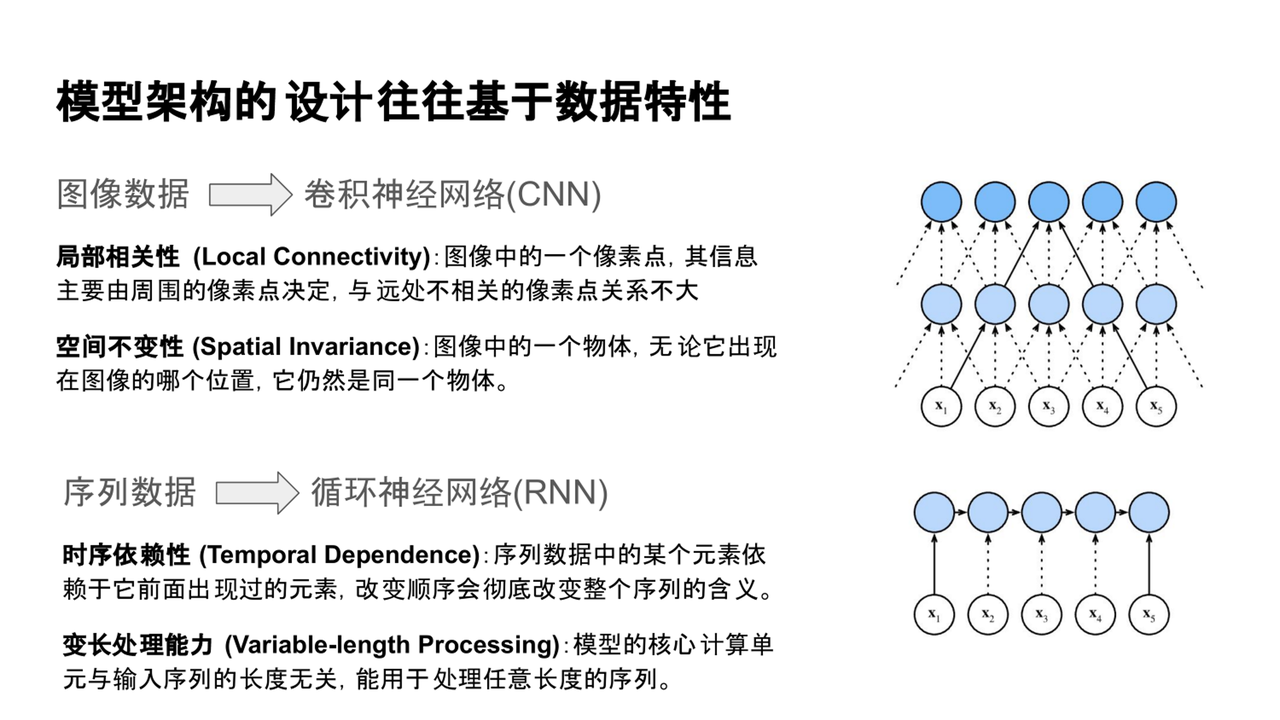
1、图像数据处理:CNN的设计
卷积神经网络(CNN)最早被广泛应用于图像任务。CNN的核心思想是通过滑动窗口提取图像的局部特征,重点关注局部区域的信息聚合。这种设计来源于对图像数据特性的理解:
(1)局部相关性:图像中一个像素点的信息主要由其周围像素点决定,远处像素的关系较弱。
(2)空间不变性:物体的语义与其在图像中的位置无关
通过这些例子,我们可以看到,模型架构设计通常是基于数据特性的需求来进行的。
2、序列数据处理:RNN的设计
循环神经网络(RNN)用于处理时序数据,尤其是语言等序列数据。其设计的原因在于:
(1)时序依赖性:一个元素通常依赖于其前面出现的元素,顺序不可改变。
(2)变长处理能力:RNN具有处理不同长度输入的能力。
通过这些例子,我们可以看到,模型架构设计通常是基于数据特性的需求来进行的。
基于硬件友好——架构应用的迭代
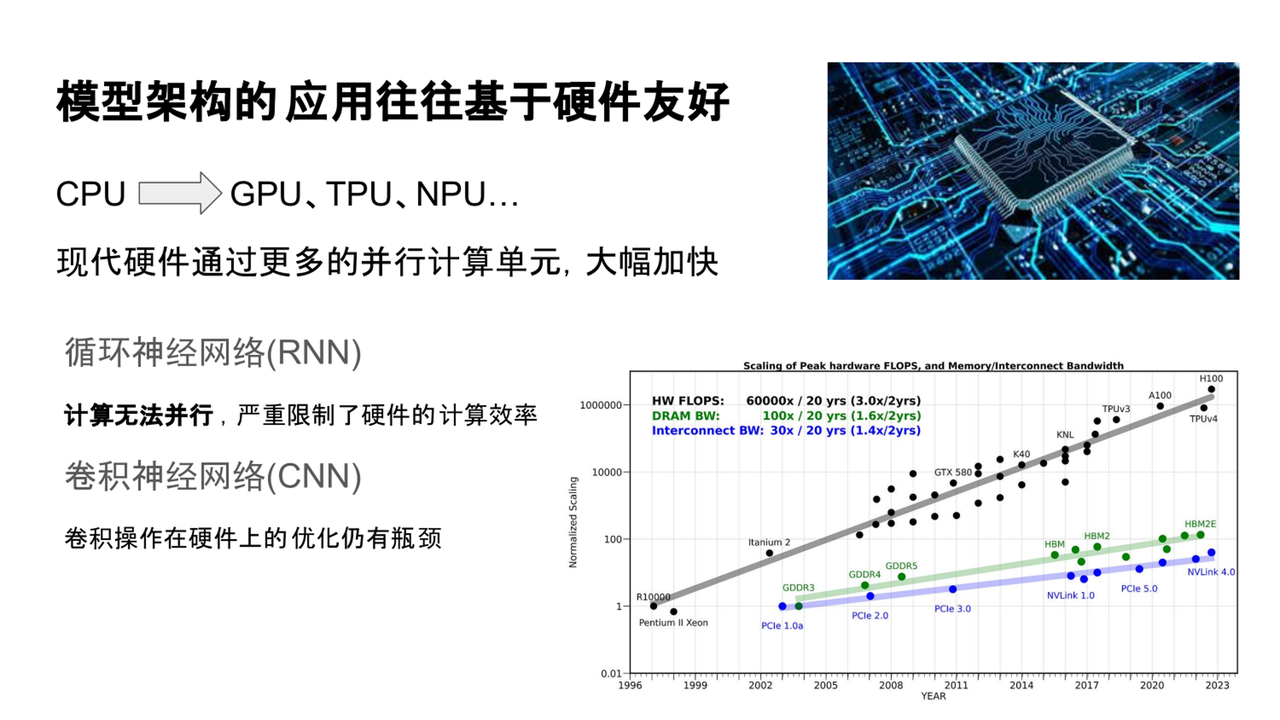
随着深度学习的发展,我们发现许多模型架构的保留或淘汰,往往依赖于其是否具备硬件友好性。现代大规模模型训练和推理需要依赖并行计算设备,如NVIDIA GPU、Google TPU、NPU等。这些设备的计算能力不断提升,使得高效运行大规模模型成为可能。
近年来,英伟达等厂商推出了如A100、H100等GPU架构,以满足大规模模型对算力的需求。硬件性能的提升使得能够高效运行参数量巨大的模型成为现实。
但追求硬件效率也导致了一些早期广泛使用的模型架构逐渐被淘汰,尤其是在硬件计算能力越来越强的背景下。
二、基础模型:在AI硬件上高效且有效地处理不同模态的数据
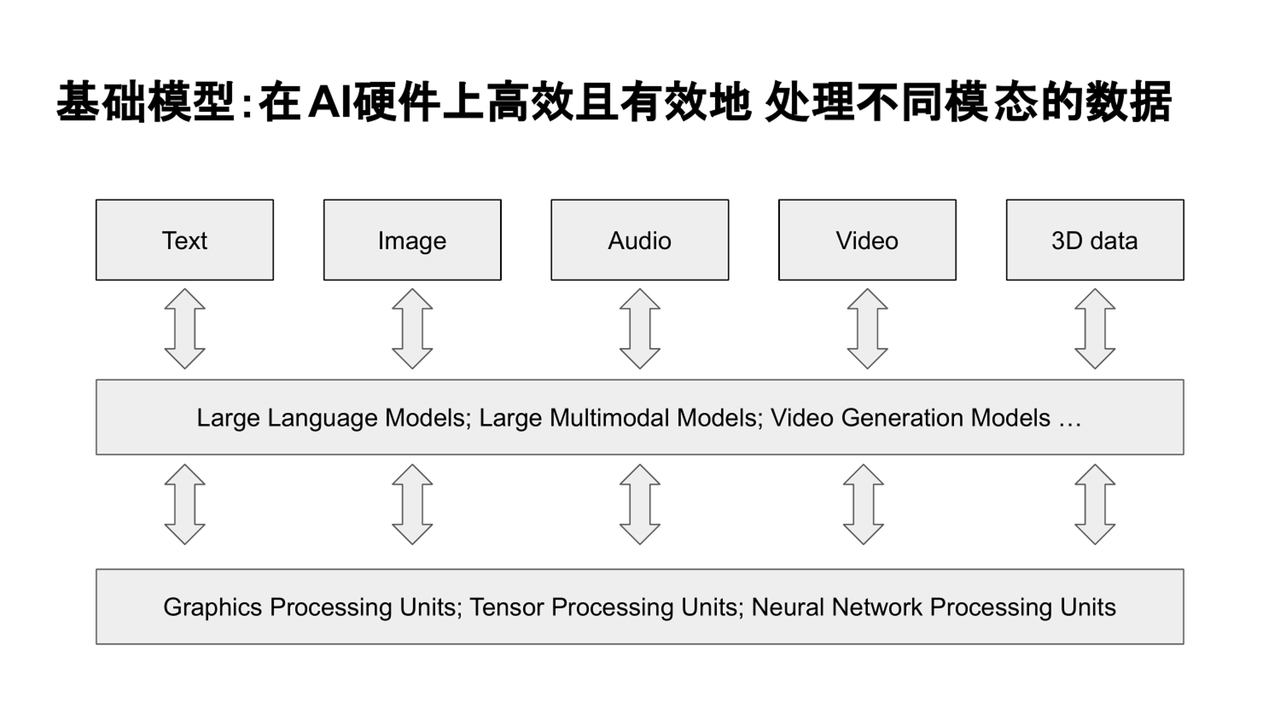
在当前的AI发展趋势下,“基础模型”(Foundation Models)成为了热门话题。这类模型的核心能力是灵活处理多种任务和多模态数据。例如,一个模型不仅要处理文本信息,还要理解图像、分析语音,甚至生成高质量的内容,同时还要能应用于推理、信息抽取、对话理解等多种任务。这种广泛的适应性使得泛化能力成为当前模型设计的关键目标。
在这一背景下,Transformer架构成为了当前主流大模型的基础架构。其核心机制——注意力机制,允许每个token与其他位置的信息进行灵活的交互,从而实现全局信息的融合。这种无先验、完全自适应的设计方式使得Transformer适用于多任务、多模态数据处理,特别是对于需要高泛化能力的基础模型,Transformer的设计理念非常契合。
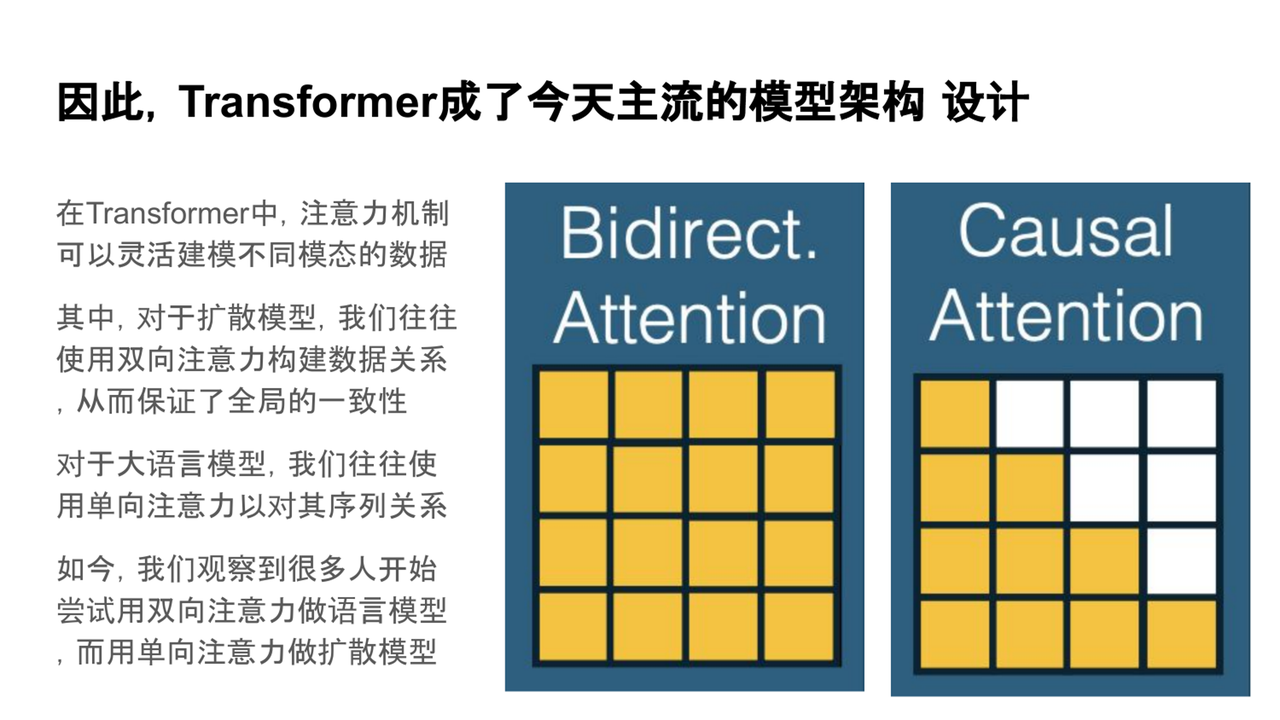
与传统的 RNN 和 CNN 不同,Transformer 并不依赖于固定的局部感受野或序列顺序等先验结构,而是提供了一种完全开放的信息建模方式,让模型根据数据本身去学习最合适的交互模式。这种“无先验、自适应 ”的设计理念,正好契合了基础模型对多任务、多模态、高泛化能力的需求。
目前最常见的两类模型中,一类是广泛应用于视频生成等任务的扩散模型(diffusion models) ,另一类则是我们熟知的大语言模型(LLM) 。这两类模型在注意力机制的设计上各有侧重。
目前常见的两类模型中,**扩散模型(Diffusion Model)和大语言模型(LLM)**都依赖于注意力机制,但它们在设计上有所侧重。
-
扩散模型:常用于处理图像、视频等数据,通常采用双向注意力,能够有效建模全局信息依赖。
-
语言模型(LLM):大多数基于单向注意力机制,适合处理具有明显序列特性的任务,如文本生成等。
为了解决生成效率问题,研究者们尝试将扩散模型的思路引入到语言建模中。扩散语言模型(Diffusion Language Models)尝试打破传统自回归建模的顺序限制,提升生成效率。该模型通过使用双向注意力和remask(重新掩码)机制,能够在保证生成质量的同时,利用并行计算优势提升效率。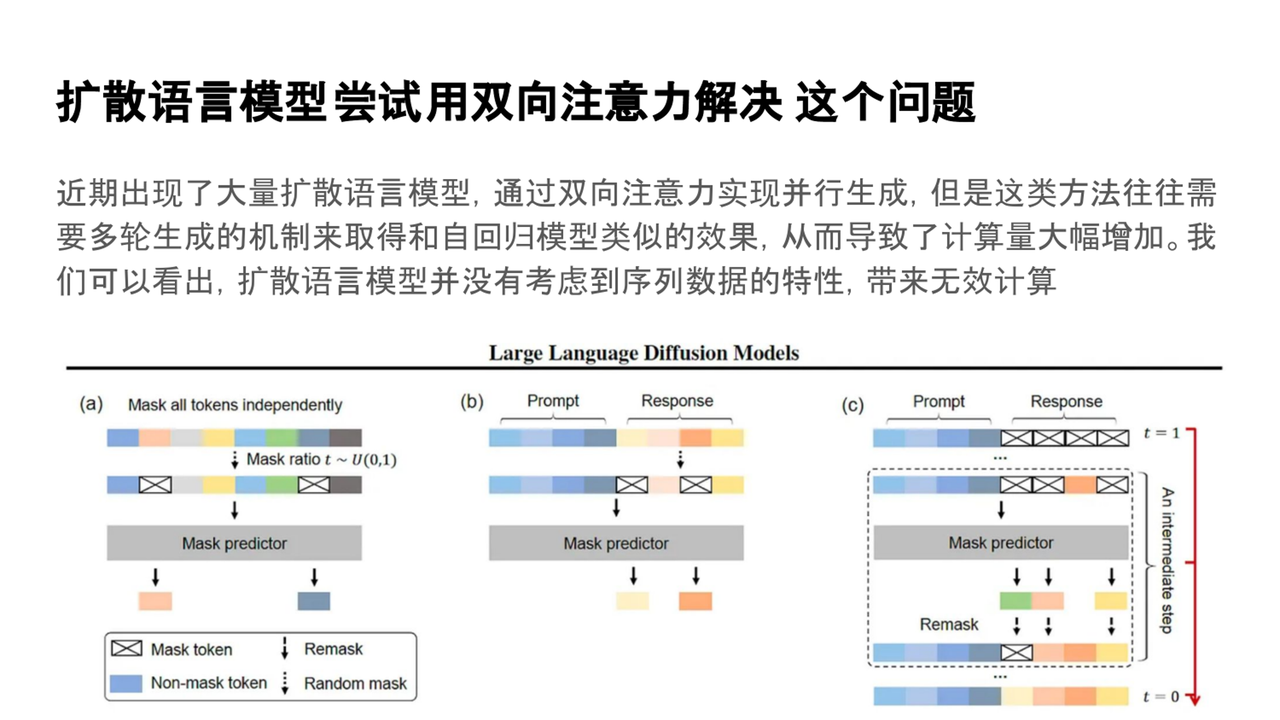
三、应对之策—— Multiverse(多元宇宙模型)
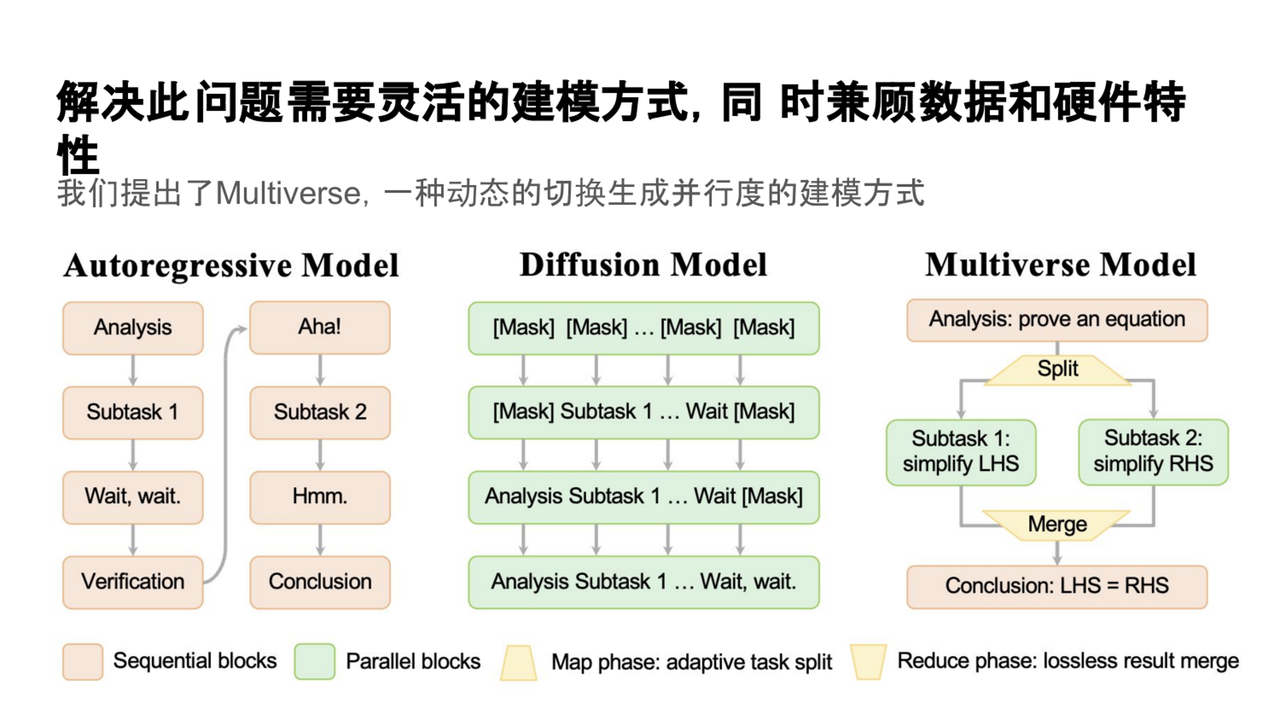
针对现有模型的局限性,杨新宇提出了Multiverse(多元宇宙模型)。该模型的核心思想是根据任务和上下文的不同需求,动态调整生成过程中的并行度,从而提升推理效率和生成质量。
MapReduce 建模机制
Multiverse模型引入了一种新的建模机制——MapReduce机制。在这一机制中,模型会先进入规划阶段,输出不同子任务的短期计划。然后,为每个子任务初始化独立进程进行并行生成,最后再将所有子任务的结果合并,继续生成。这种流程使得模型能够在不同任务间灵活切换,并实现高效的并行生成。
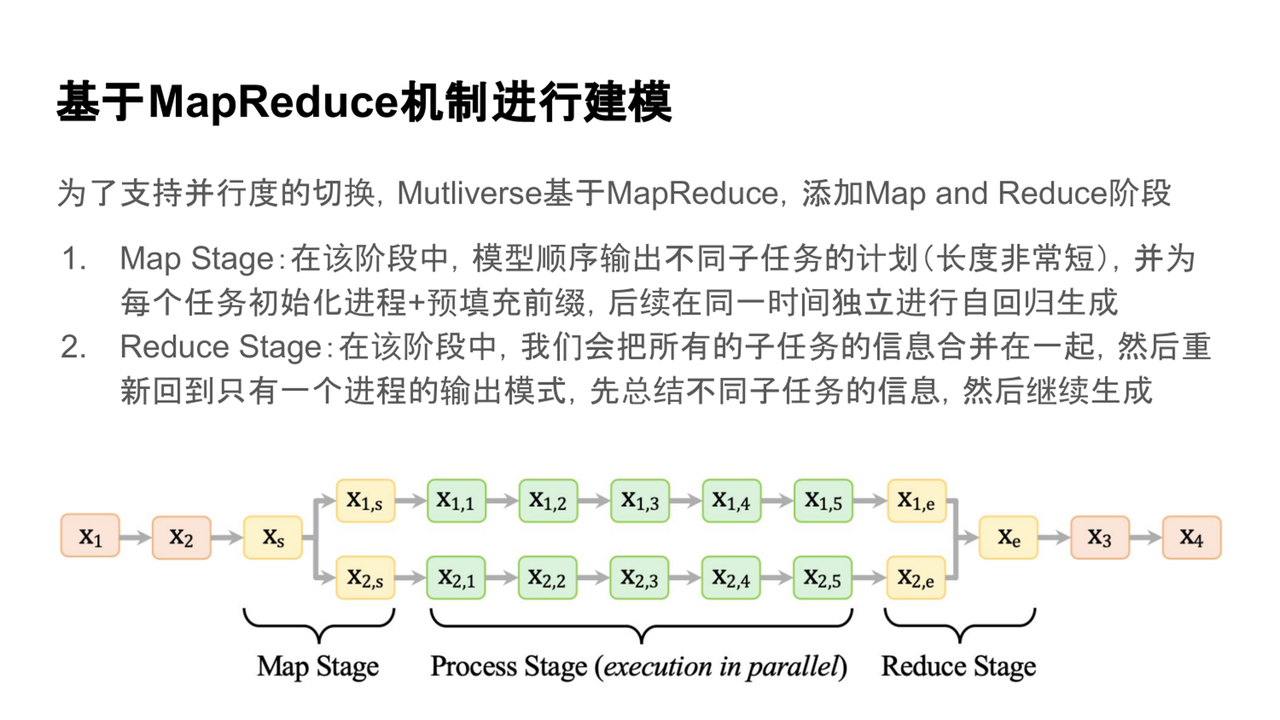
MapReduce机制的实现
MapReduce机制的实现借鉴了编译器设计中的思想,使用特殊控制字符来引导模型与推理引擎之间的交互。这种设计确保了不同子任务的输出能够无损地传递给后续的进程,提高了信息处理效率。

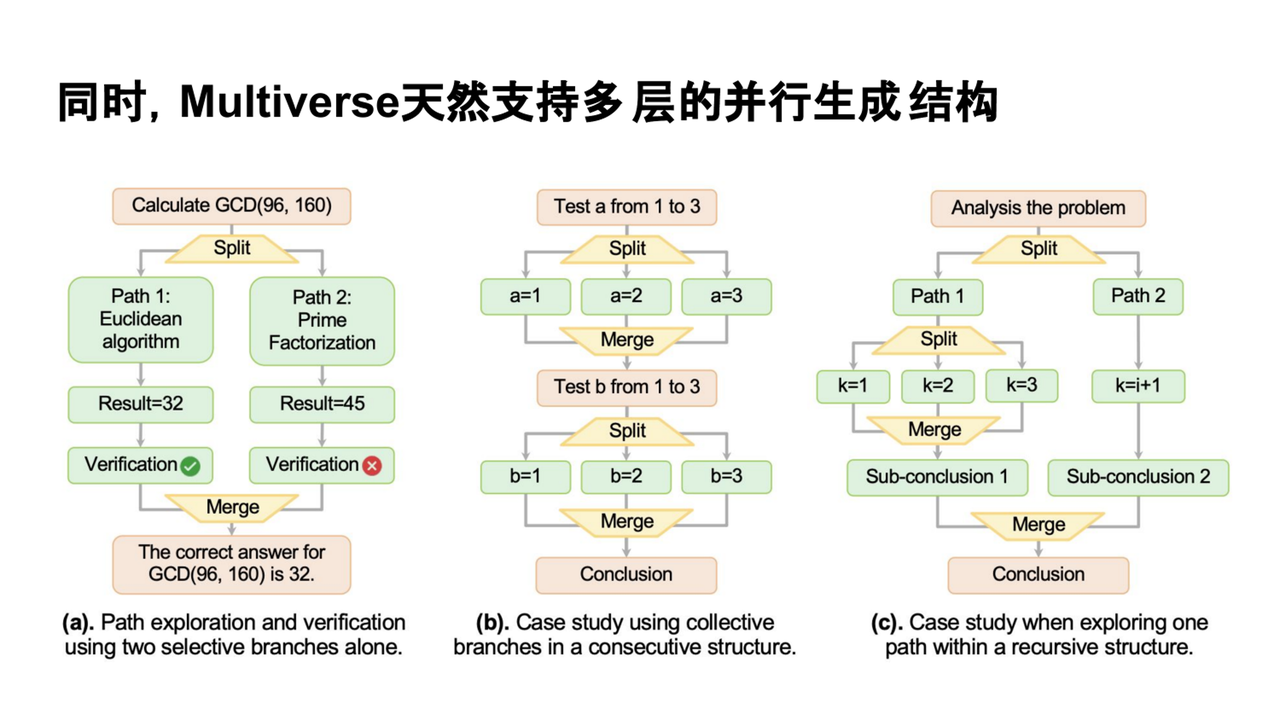
四、在真实任务中落地
对于实际应用中的团队,尤其是那些资源有限的团队,如何快速构建AI应用是一个关键问题。传统的自回归模型可以通过微调快速应用,但Multiverse模型的设计目标是使其具备良好的可迁移性和易用性,即使资源有限的团队也能轻松构建并部署高效模型。
部署挑战:数据、算法、引擎
Multiverse模型的实现涉及数据设计、算法设计和系统设计三个方面:
-
数据设计:我们提供了一整套prompting流程,借助现有的自回归模型推理能力和改写能力,将数据转化为Multiverse模型可用的训练样本。
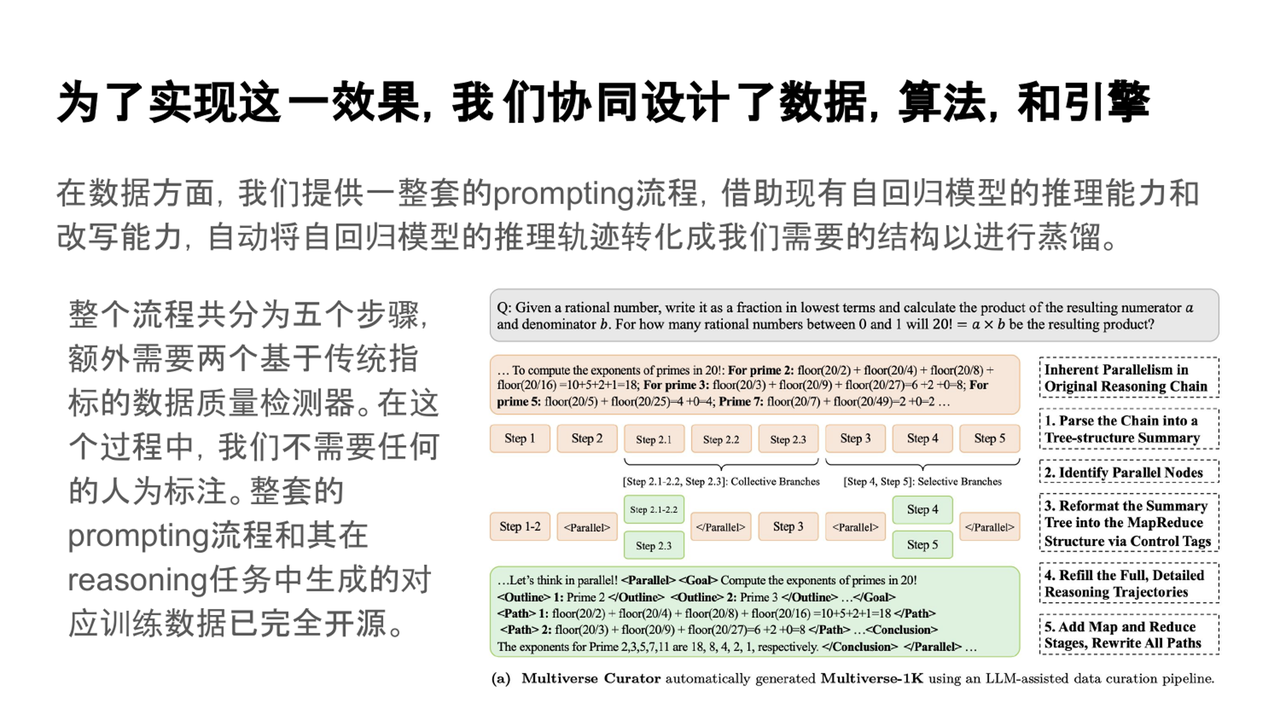
-
算法设计:引入了Multiverse Attention机制,通过精心设计的注意力掩码,实现任务之间的高效并行生成。

-
系统设计:基于SGLang平台,开发了Multiverse Engine,通过简单集成即可支持不同推理场景,实现高效的推理能力。
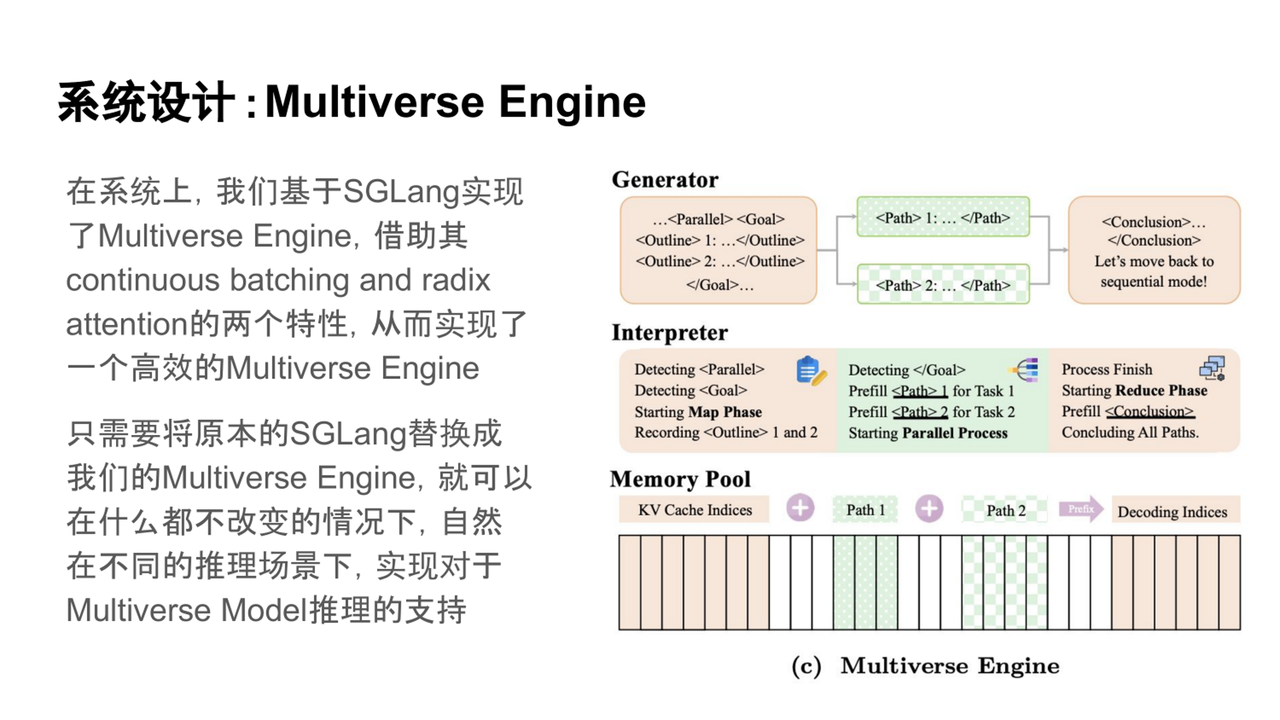
通过这一系统层面的优化设计,我们在实际测试中观察到了显著的推理效率提升。为了量化其性能优势,我们设计了一个基准测试:在相同时间内,测量模型能够生成的 token 数量,并将其与并行度进行对比分析。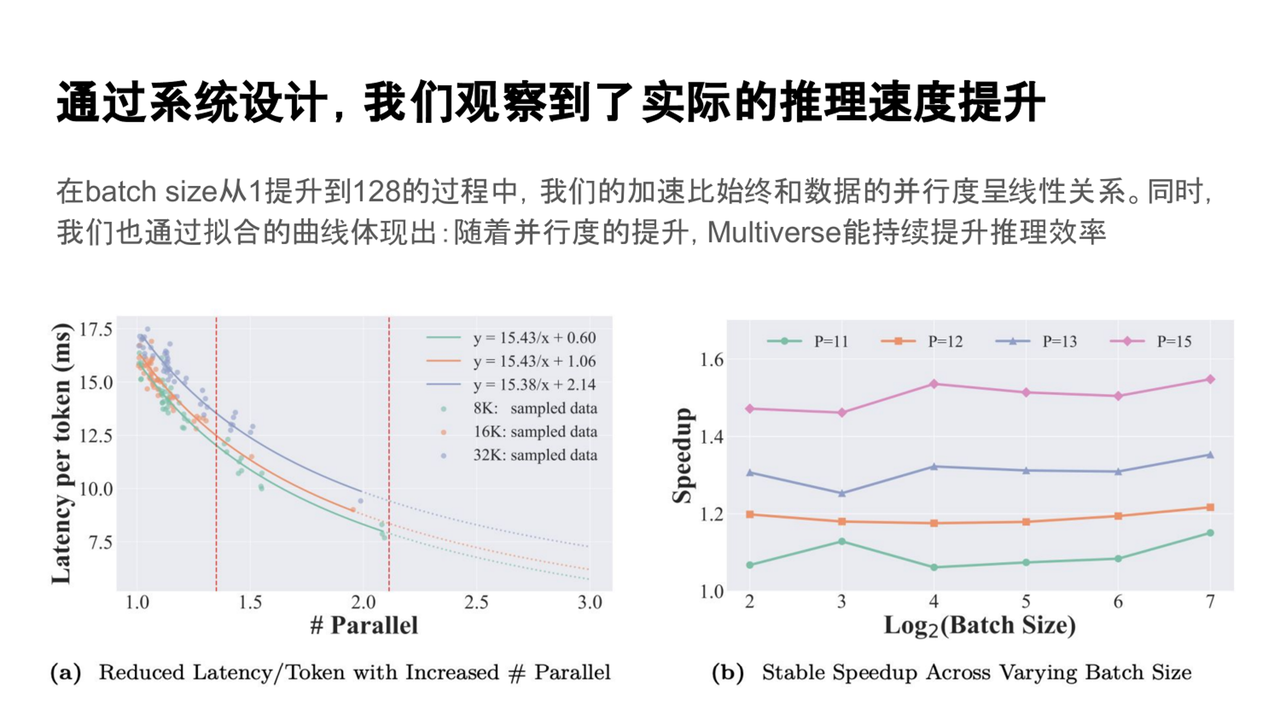
五、实验与结果
通过系统优化设计,实际测试显示Multiverse Engine在推理效率上显著提升。基准测试中,生成不同长度(8K、16K、32K)的任务时,Multiverse Engine的并行效率提高了约1.3到2倍,显著降低了延迟并增加了输出内容。实验结果还表明,提升并行度可进一步增强推理速度,且方法在不同批量大小下表现稳定,特别是在batch size从1到128增加时,系统有效提升了硬件资源利用率,展示了优越的扩展性和稳定性。




)



未完)






与节流(Throttle))

:策略模式)

