自然语言处理与BERT模型:从基础到实践入门
自然语言处理(NLP)的核心目标之一是让计算机理解人类语言的语义和上下文。本文将从基础的字词表示出发,逐步解析传统模型的局限性、Self-attention的突破性思想,以及BERT如何通过预训练成为强大的特征编码器。
一、字的表示:从离散符号到语义向量
传统NLP中,字或词的表示主要依赖离散符号(如One-Hot编码),但这种方式无法捕捉语义相似性(如“猫”和“狗”均为动物,但One-Hot向量正交)。深度学习中,通过Embedding技术将字映射为低维稠密向量(如300维),使得语义相近的字在向量空间中距离更近。例如:
- 词袋模型(Bag of Words)
- Word2Vec、GloVe等预训练词向量
这一过程让模型能够从数学上理解“字”的语义特征。
二、上下文建模:RNN与LSTM的探索
为了捕捉序列中字与字之间的上下文关系,早期模型引入了循环神经网络(RNN)。RNN通过隐状态(Hidden State)/ 记忆单元传递历史信息,但其存在两大问题:
- 长距离依赖丢失:随着序列变长,早期信息逐渐衰减(如段落开头的主题词影响结尾)。
- 梯度消失/爆炸:反向传播时梯度难以稳定更新参数。
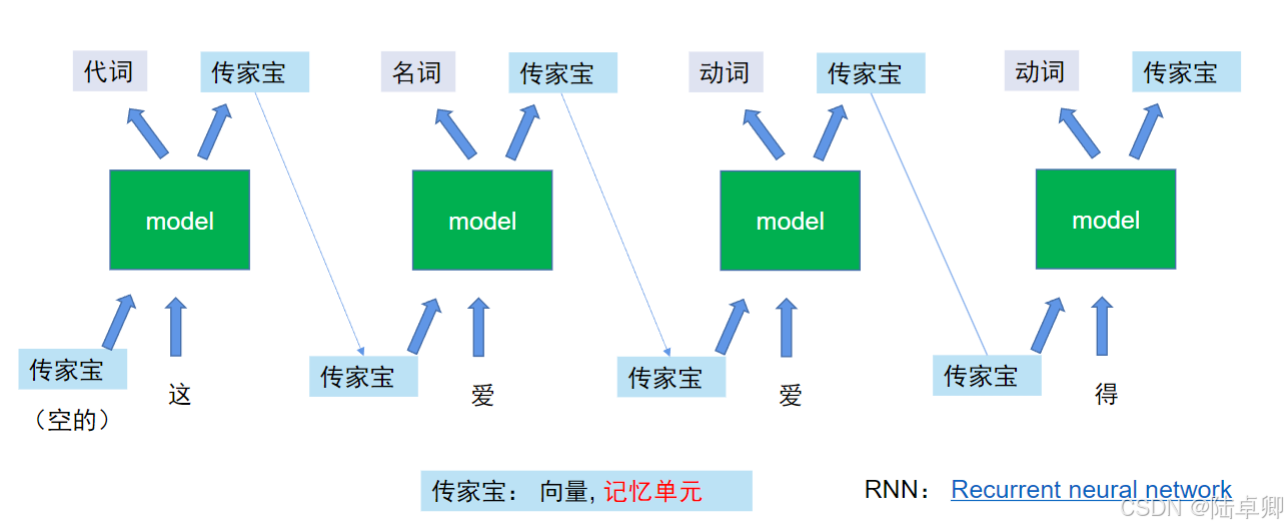
**LSTM(长短期记忆网络)**通过门控机制(输入门、遗忘门、输出门)缓解了这些问题,但仍存在局限性:
- 无法并行计算:必须按顺序处理序列,训练速度慢。
- 单向上下文:传统RNN/LSTM仅能捕捉从左到右的依赖,双向模型(Bi-LSTM)虽融合双向信息,但复杂度更高。
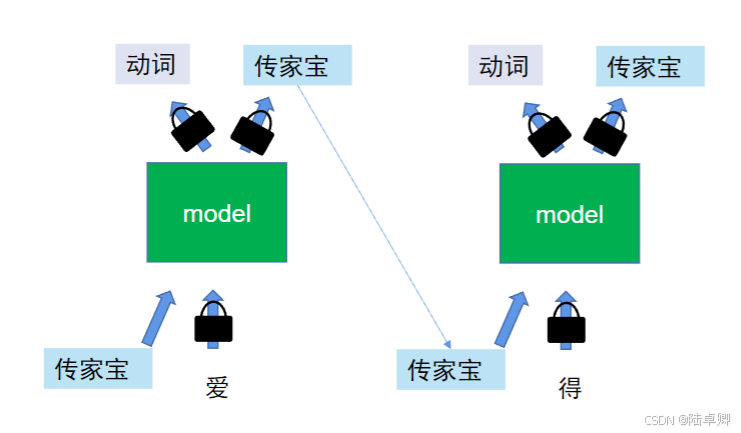
三、Self-attention的突破:并行化与全局上下文
为解决RNN系列模型的缺陷,Self-attention机制应运而生。其核心优势在于:
- 并行计算:所有字的同时处理,大幅提升训练速度。
- 全局感知:每个字直接与序列中所有字交互,捕捉长距离依赖。
- 双向建模:天然支持双向上下文(如同时考虑左右字的影响)。
这一机制成为Transformer架构的核心,彻底改变了NLP模型的设计范式。
四、Self-attention的实现细节
1. 输入表示:Embedding与位置编码
每个字的输入由两部分相加构成:
- 字Embedding:表示字本身的语义(如“猫”对应的向量)。
- 位置Embedding:表示字在序列中的位置(如第1个字、第2个字),通过正弦函数或可学习参数生成。
二者相加后得到最终的Token表示,既包含语义又包含位置信息。
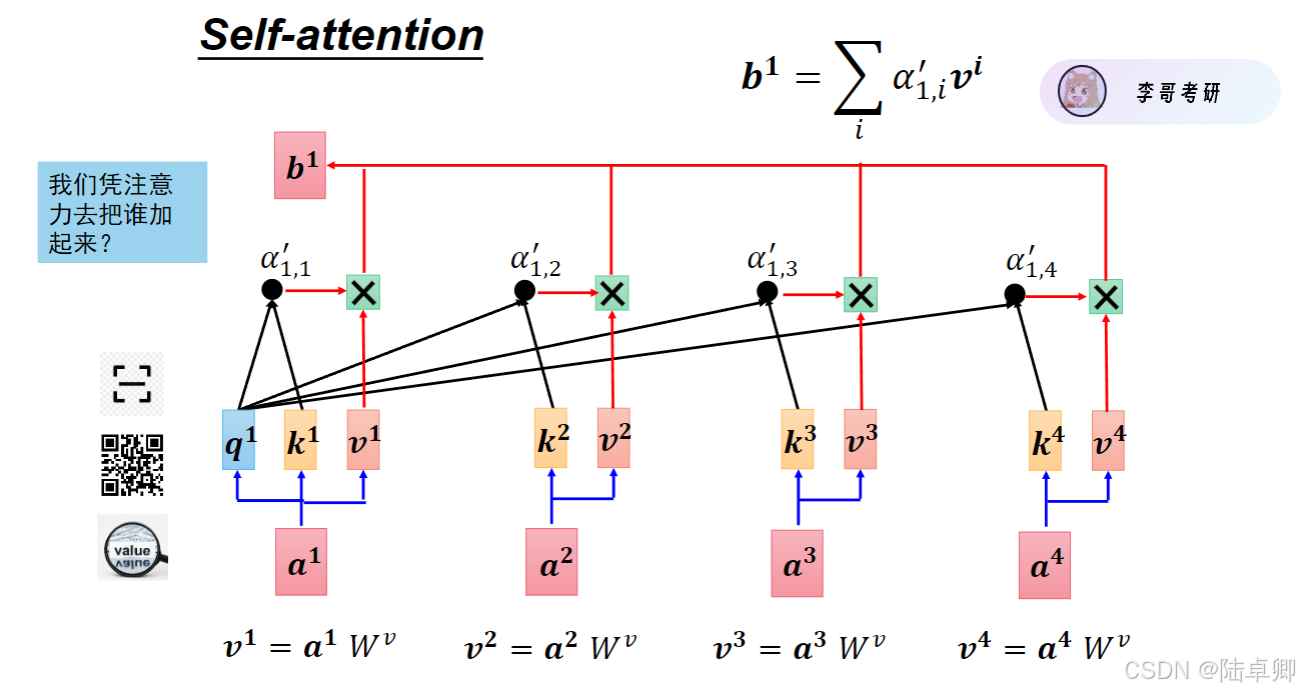
2. QKV交互与注意力计算
Self-attention通过三个矩阵(Query, Key, Value)实现字与字之间的交互:
- Query(Q):当前字需要查询的信息。
- Key(K):其他字提供的索引信息。
- Value(V):其他字的具体内容信息。
计算步骤如下:
- 通过Q和K的点积计算注意力分数,反映字与字的相关性。
- 对分数归一化(Softmax)得到注意力权重。
- 根据权重对V加权求和,得到当前字的上下文感知表示。
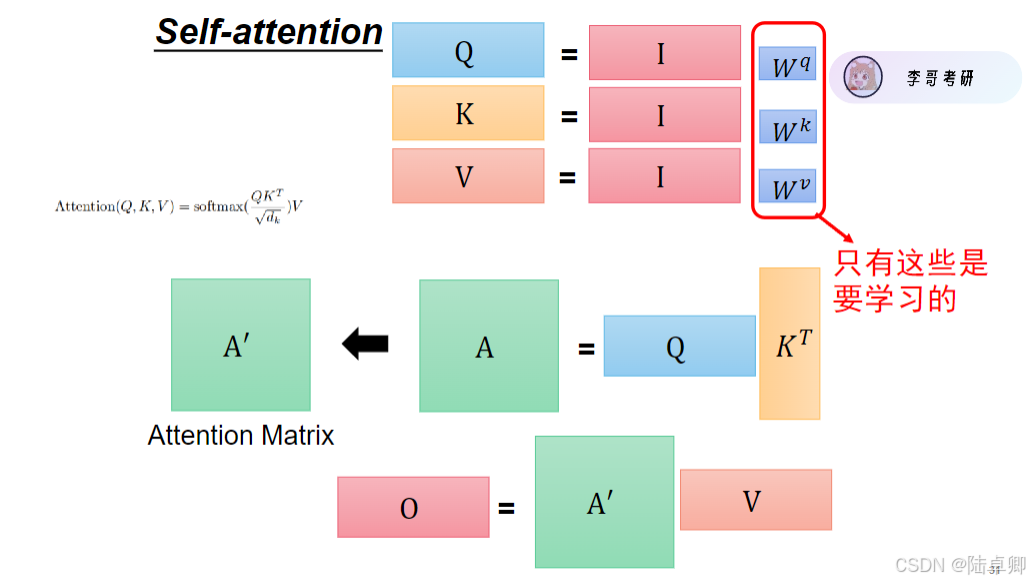
公式表达:
\ [
\ text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
]
五、BERT:基于Self-attention的特征编码器
BERT(Bidirectional Encoder Representations from Transformers)是一个多层Transformer编码器堆叠的模型,其核心目标是将输入文本编码为上下文相关的特征向量。
由Google AI在2018年提出的预训练语言模型,它是基于Transformer架构的一个具体应用实例。与原始Transformer不同的是,BERT仅使用了Transformer的编码器部分,并在此基础上进行了创新,采用了双向训练的方式——即同时考虑一个词左边和右边的所有上下文信息,这与传统单向语言模型形成了鲜明对比。
1. 自监督预训练
BERT通过以下任务预训练,无需人工标注数据:
- Masked Language Model (MLM):随机遮盖15%的字,模型预测被遮盖的字(如“猫坐在[MASK]上” → “垫子”)。
- Next Sentence Prediction (NSP):判断两句话是否连续(如“今天下雨” + “我带了一把伞” → 正样本)。
2. 特征提取与下游任务
预训练后的BERT可直接作为特征提取器: 
- 提取任意字的Embedding或整句的
[CLS]向量。 - 将特征输入简单分类层,即可适配文本分类、问答等任务。
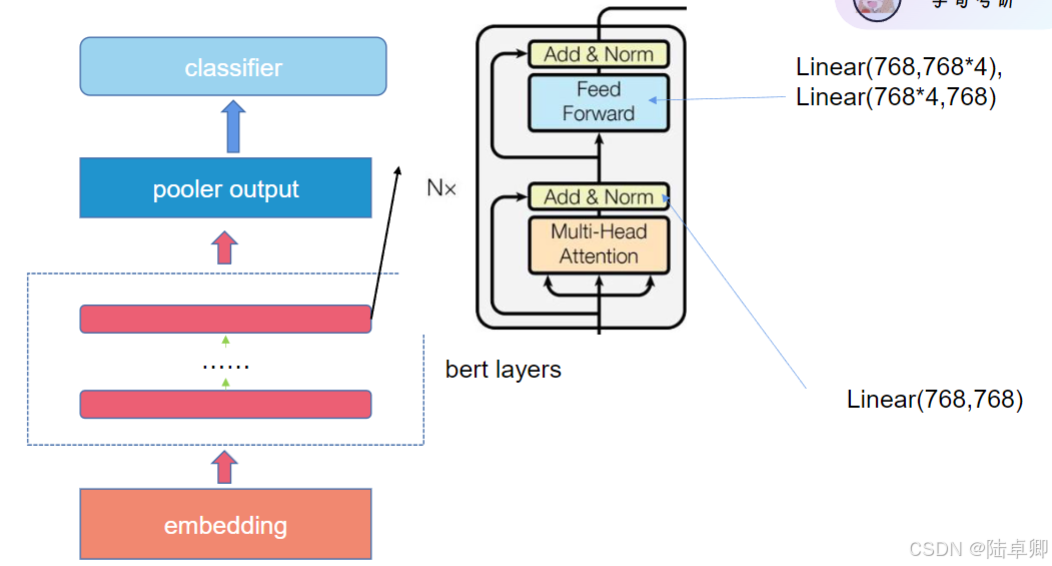
六、BERT的三大核心结构
1. Embedding Layer (嵌入层)
在BERT中,输入文本首先需要被转换为计算机能够理解的形式——向量。这个过程称为“嵌入”,即把词语映射到一个连续的向量空间中。BERT使用了三种类型的嵌入:
-
Token Embeddings: 这是将每个单词或子词(如WordPiece分词后的结果)转换成向量表示的过程。例如,“hello”可能会被转换成一个
768维的向量。 -
Segment Embeddings: BERT支持处理句子对的任务(比如问答),因此需要一种方法来区分这些句子。这通过给来自不同句子的tokens分配不同的段落标识(通常是0或1)来实现。
-
Position Embeddings: Transformer模型没有内置的方式来识别序列中元素的顺序。所以,位置嵌入用来告诉模型每个token在其序列中的相对位置。
2. BERT Layers (BERT层)
BERT由多层Transformer编码器组成。每层都包含以下两个主要组件:
-
Multi-Head Attention (多头注意力机制): 这个组件允许模型同时关注输入序列的不同部分,从而捕捉到词语之间的依赖关系。通过多个“头”并行运行,它可以专注于不同类型的信息。
-
Feed Forward Neural Network (前馈神经网络): 在注意力机制之后,有一个简单的两层全连接网络,用于进一步处理信息。每层之间都有残差连接和归一化步骤,有助于稳定训练过程。
3. Pooler Output (池化输出)
在BERT的最后一层编码器之后,通常会有一个池化层,它会取第一个token([CLS]标记)对应的隐藏状态作为整个句子的表示。这是因为,在预训练过程中,[CLS]标记的最终隐藏状态被用作句子分类任务的特征表示。
4. Classifier (分类器)
对于特定的下游任务,比如情感分析、命名实体识别等,会在BERT的顶部添加一个额外的分类层。这个分类层通常是一个简单的全连接层,可能后面跟着一个softmax函数,用于生成最终的预测结果。
5. Linear Layers (线性层)
在BERT的结构中,线性层主要用于调整向量的维度大小。例如,在前馈神经网络中,会有两次线性变换:第一次扩展向量维度,第二次则压缩回原始维度。这样做的目的是为了引入非线性,使模型能够学习更复杂的模式。
七.总结
从字的表示到BERT的完整架构,NLP模型的演进始终围绕“如何更好地理解上下文”展开。BERT的成功得益于Self-attention的并行化能力和自监督预训练策略。理解这些核心思想后,读者可进一步探索BERT的变体(如RoBERTa、ALBERT)及在多语言、多模态任务中的应用。
- BERT实战中的数据不平衡问题
- 在文本分类等任务中,数据不平衡是一个常见的挑战。例如,在情感分析任务中,“正面”评论往往比“负面”评论多得多。为了解决这个问题,可以使用Focal Loss函数来调整损失函数级别,无需修改数据集本身。这种方法特别关注那些难以正确分类的样本,从而有助于提高模型的整体性能。
代码示例(使用Hugging Face库):
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
inputs = tokenizer("自然语言处理很有趣!", return_tensors="pt")
outputs = model(**inputs)
# 获取整句特征([CLS]向量)
sentence_embedding = outputs.last_hidden_state[:, 0, :]
八.问题
以下是基于你提供的知识库内容和常见复试场景设计的BERT项目相关问题及参考答案,涵盖技术原理、实现细节、优化策略和应用实践:
1. 问题:BERT的输入处理步骤中,为什么要使用[CLS]和[SEP]标记?它们在模型中的作用是什么?
答案:
- [CLS] 标记:
- 位于输入序列的最开始,其对应的隐层输出(最后一层的[CLS]向量)被用作整个序列的分类表示。
- 在分类任务中(如情感分析),模型通过全连接层对[CLS]向量进行预测。
- [SEP] 标记:
- 用于分隔两个句子(如在NSP任务中),帮助模型区分句子边界。
- 在单句分类任务中,仅需一个[SEP]标记结束句子。
- 作用:
- 通过[CLS]向量聚合全局语义信息,避免依赖固定位置的平均或池化操作。
- [SEP]标记明确句子结构,防止两个句子的上下文混淆。
2. 问题:在BERT的预训练任务中,Masked Language Model (MLM) 如何解决自回归模型的单向性问题?
答案:
- MLM的核心思想:
- 随机遮蔽15%的词,模型需根据双向上下文(左、右两侧的词)预测被遮蔽的词。
- 例如,遮蔽“猫”时,模型需同时利用“黑”和“在睡觉”等信息,实现双向语义建模。
- 与自回归模型(如GPT)的对比:
- GPT仅利用左向上下文预测下一个词,无法捕捉右向信息;
- BERT通过MLM强制模型学习双向依赖,提升对复杂语义的理解能力。
- 数学实现:
- 遮蔽词的位置由均匀分布随机选择,80%遮蔽为[Mask],10%保留原词,10%替换为随机词(防止模型依赖[Mask]标记)。
3. 问题:BERT的位置编码(Position Embedding)与Transformer的原始实现有何不同?
答案:
- BERT的位置编码:
- 采用可训练的绝对位置嵌入(learned absolute positional embeddings),与Token Embedding和Segment Embedding相加。
- 通过反向传播学习位置信息,适应不同任务的上下文依赖。
- Transformer的原始实现:
- 使用固定的位置编码(sinusoidal函数生成的相对位置编码),不依赖训练数据。
- 差异与影响:
- BERT的绝对位置编码更适合需要明确序列顺序的任务(如文本分类);
- 固定编码在长序列(超过512)时可能失效,而BERT因位置嵌入长度固定(最大512),无法处理超长文本(需截断或分块)。
4. 问题:为什么BERT的NSP(Next Sentence Prediction)任务在某些下游任务中被认为效果有限?
答案:
- NSP任务的初衷:
- 预测两个句子是否连续,帮助模型学习句子间的
语义关系(如问答任务中的上下文理解)。
- 预测两个句子是否连续,帮助模型学习句子间的
- 局限性:
- 任务简单性:NSP的二分类任务容易被模型过拟合,且实际任务中句子对齐问题(如文档分类)与NSP关联性弱。
- 数据偏差:随机组合的负样本(非连续句子对)可能包含语义相关但非连续的句子,导致噪声。
- 改进方案:
- ALBERT:用**句子顺序预测(OSP)**替代NSP,判断两个句子的顺序是否合理;
- RoBERTa:完全移除NSP任务,仅保留MLM。
5. 问题:在BERT的微调阶段,如何避免过拟合?请结合代码说明。
答案:
- 常见策略:
- 学习率调度:
- 使用分阶段衰减(如
Cosine Annealing)或Warmup + Linear Decay(BERT论文推荐)。 - 代码示例(PyTorch):
from transformers import get_linear_schedule_with_warmup total_steps = len(train_dataloader) * num_epochs scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=total_steps)
- 使用分阶段衰减(如
- 正则化:
- 添加Dropout层(BERT默认在Transformer层后已配置);
- 使用AdamW优化器(解耦权重衰减,知识库[1]提到)。
- 早停法(Early Stopping):
- 监控验证集损失,当性能不再提升时终止训练。
- 学习率调度:
6. 问题:BERT的多头注意力(Multi-Head Attention)为什么需要对每个头进行降维?
答案:
- 数学原理:
- 多头注意力的计算复杂度为 (O(T^2D)),其中 (T) 是序列长度,(D) 是嵌入维度。
- 通过将每个头的维度从 (D) 降为 (D/h)((h) 为头数),总复杂度变为 (O(T^2D/h * h) = O(T^2D)),复杂度不变,但降低了单个头的计算量。
- 作用:
- 允许模型在多个低维子空间中并行学习不同特征(如语法、语义),提升表达能力;
- 例如,BERT-base使用12头,每个头维度为64(总维度768)。
7. 问题:如何处理输入文本超过BERT最大长度(512)的问题?
答案:
- 解决方案:
- 截断与分块:
- 截断过长文本(如保留前512个token),但可能丢失关键信息;
- 分块处理(如将长文本分成多个片段,合并结果)。
- 模型扩展:
- 使用长序列模型(如Longformer,通过稀疏注意力机制处理长文本)。
- 任务适配:
- 在文本分类中,仅保留关键段落(如摘要);在问答任务中,结合滑动窗口策略。
- 截断与分块:
8. 问题:BERT与GPT在训练目标和应用场景上的根本区别是什么?
答案:
| 维度 | BERT | GPT |
|---|---|---|
| 训练目标 | MLM(双向上下文) + NSP | 自回归语言模型(单向左到右) |
| 架构 | Transformer Encoder(无Mask) | Transformer Decoder(带Mask) |
| 优势场景 | 需要全局语义理解的任务(分类、问答) | 需要生成连续文本的任务(文本生成、对话) |
| 计算效率 | 并行计算速度快 | 逐词生成,推理速度慢 |
| 上下文利用 | 双向上下文(通过MLM) | 单向上下文(仅左向) |
9. 问题:在BERT的预训练中,为什么需要对注意力权重进行缩放(除以√d_k)?
答案:
- 数学原因:
- 注意力分数 (QK^T) 的值可能很大(维度 (d_k) 趋大时),导致softmax后的权重梯度消失(指数爆炸)。
- 缩放因子 (\sqrt{d_k}) 使分数的尺度更小,梯度更稳定。
- 实验效果:
- 未缩放时,注意力权重可能集中在少数位置,模型无法有效学习全局关联(知识库[3]提到的QK矩阵测试)。
10. 问题:如何将BERT与知识图谱结合提升模型效果?请举例说明。
答案:
- 结合方法:
- 静态知识注入:
- 在预训练阶段,将知识图谱中的实体关系编码到BERT的词嵌入中(如通过图神经网络)。
- 动态推理:
- 在微调阶段,引入知识图谱的先验知识作为约束(如约束问答任务的答案必须来自知识图谱的实体)。
- 联合训练:
- 将知识图谱的三元组(头、关系、尾)作为额外训练数据,扩展MLM任务(如预测被遮蔽的实体关系)。
- 静态知识注入:
- 应用场景:
- 在医疗问答中,BERT结合疾病知识图谱,确保答案符合医学知识体系。
11. 问题:BERT的LayerNorm为什么选择在Transformer层的内部使用,而不是BatchNorm?
答案:
- LayerNorm的优势:
- 数据依赖性低:LayerNorm按样本维度归一化,不受batch大小影响,适合小batch训练;
- 稳定性:Transformer的残差连接需要稳定的激活值分布,LayerNorm能有效缓解梯度消失。
- BatchNorm的局限性:
- 在NLP任务中,序列长度变化较大,BatchNorm的统计量(均值、方差)依赖batch数据,可能引入噪声。
12. 问题:在BERT的微调阶段,如何选择冻结哪些层?
答案:
- 策略:
- 渐进式解冻:
- 初始冻结所有层,仅训练分类头;逐步解冻顶层Transformer层,再解冻底层。
- 基于任务相似性:
- 若下游任务与预训练语料相似(如新闻分类),可仅冻结底层;若差异大(如医学文本),需解冻更多层。
- 实验验证:
- 通过验证集性能调整冻结策略,避免过拟合或欠拟合。
- 渐进式解冻:



)





:端口无权限)
线性方程组解的结构)

 这样的 Controller 方法)






