抽象
在计算机视觉和更广泛的深度学习领域,Transformer 架构已被公认为许多应用程序的最先进技术。然而,对于多任务学习,与单任务模型相比,可能需要更多的查询,考虑到实际的硬件限制,它的多头注意力通常接近计算可行的极限。这是因为注意力矩阵的大小随任务数量呈二次方比例(假设所有任务的查询数量大致相等)。 作为一种解决方案,我们提出了用于多任务模型的新颖可变形任务间自注意力,该模型能够更有效地聚合来自不同任务的特征图的信息。 在我们对 NYUD-v2 和 PASCAL-Context 数据集的实验中,我们证明了 FLOP 计数和推理延迟都减少了一个数量级。同时,我们还在单个任务的预测质量指标上实现了高达 7.4% 的大幅改进。
关键字:
多任务学习 变形注意力 多任务注意力。1介绍
多任务学习的两个主要目标是减少每个任务所需的计算资源量,并通过使模型能够使用来自一项任务的信息来提高另一项任务的性能来实现更好的泛化[5].这是通过在任务之间共享模型的部分可学习权重来实现的。最近,随着 Transformer 模型的兴起[28],架构的这个共享部分通常是一个注意力模块,因为在给定足够的训练数据的情况下,它为各种应用程序提供了很好的适应性[2,33,31]. 然而,这种适应性确实存在一个重大缺点,即注意力计算所需的计算资源随查询数量呈二次方比例。 特别是对于需要跨任务引起注意力的多任务模型,这种缩放行为会成为问题。假设不同任务的查询数量大致相当,这种模型中注意力机制的计算成本现在随任务数量呈二次方缩放,这违背了多任务学习减少每个任务所需的计算资源量的目的。对于通常需要大量与输入像素计数成正比的查询的多任务视觉转换器模型,这个问题更为相关。 以前的工作通过减少查询数量来解决这个问题,例如[32]或者通过合并任务特征图,从而关注更少的值[31].在可变形混频器变压器 (DeMT) [33],徐等人。接受计算开销,以支持更好的预测指标[32]和[31]. 灵感来自朱的《变形注意力》作品等。[38],我们取代了 DeMT 模型中使用的全局注意力[33]使用我们的可变形任务间自注意力,该功能专为具有多个任务特征图的应用程序而设计。通过这样做,我们允许模型克服上述先前工作的弱点,通过更有效地计算跨任务的注意力和更好的扩展属性,此外还实现了改进的性能指标。 正如[38],预测质量的提高可能是由于每个查询键对之间的学习全局注意力收敛性差。这表明,为了使多任务模型能够最佳地利用来自其他任务的信息并提高一项任务的性能,有效地访问这些信息非常重要。 我们在多个特征提取主干和不同的多任务计算机视觉(CV)数据集上评估了我们的方法。
我们工作的主要贡献可以概括如下:
- 我们介绍了我们新颖、更高效的可变形任务间自注意力 (ITSA) 机制。
- 我们将这种注意力机制集成到最先进的 DeMT 模型架构中。
- 我们在 NYUD-v2 和 PASCAL-Context 数据集上广泛评估了生成的模型,证明了其减少的计算资源需求和改进的预测质量。
2相关工作
视觉转换器。在引入图像分类后[12],近年来,Vision Transformer 已被确立为最先进的计算机视觉模型架构,特别是对于更复杂的任务。Vision Transformers 的一个共同特征是它们将查询分配给输入图像的小块。对于像图像分类这样的任务,这些补丁可能会稍大一些,但对于像分割这样的密集预测任务,如果选择的补丁大小太大,预测质量会受到显着影响。虽然 Dosovitskiy 等人。 在[12]能够使用 16 x 16 像素的补丁(在 Segmenter 模型中大于 8 x 8 的补丁)实现良好的分类性能[26]作者:Strudel 等人。导致结果相当差,而 Xie 等人。甚至在[30]。这证明了视觉转换器的缺点,即它们需要大量查询,从而导致昂贵的注意力计算。对于多个任务,这个问题会显着加剧。
可变形注意力。如第 1 节所述,减少与注意力计算相关的计算开销是一个高度相关的问题。通过利用低级优化,可以显着提高注意力计算的效率,例如[10,9]充分考虑了所用硬件的特定限制。工作方式[19,7]通过在注意力计算中引入门控来解决这个问题,这样实际上只需要执行完整的多头注意力计算的相关子集。然而,对于许多应用程序,特别是对于可以利用某些局部性偏差的输入,没有必要计算每对查询之间的完整注意力矩阵,并且可以通过可变形注意力很好地近似。这种注意力作的灵感来自可变形卷积[8]它通过允许从特征图中的任意位置采样来概括卷积运算。这些由使用卷积核计算的偏移量定义。将相同的想法应用于注意力计算,[38]引入可变形注意力:在这里,通过可学习的线性层,查询特征定义了采样偏移量和注意力权重:它们允许我们通过对该查询参考点周围的偏移量处的特征图进行采样,按各自的注意力权重对这些样本进行加权,最后对加权样本求和来计算该查询的注意力输出。通常,每个查询选择的偏移量数量很少(16 个是常见的选择),因此使得此作比传统的全注意力更有效,在传统的全注意力中,对于每个查询,都需要计算其彼此之间的交互。尽管如此,[38]表明可变形注意力实际上可以胜过全注意力,同时节省计算资源。 在[29], 夏等人。认为注意力计算中缺少键[38]限制了它的表示能力,因此不适合作为特征提取主干。相反,他们修改了可变形注意力计算,以从每个采样位置生成一个键和值,并将注意力计算为查询与每个采样位置的键之间的余弦相似度。然而,在我们的例子中,由于我们使用的是卷积主干,并在其提取的特征上应用了可变形注意力,因此这对我们来说不是问题,并且我们观察到遵循更简单的方法的强结果[38].
多任务学习。大多数多任务学习 (MTL) 工作都探索了新颖的模型架构[2,33,4,31,32],或专注于任务平衡和损失加权的优化方法[21,13,36,3]. 虽然 MTL 已应用于自然语言处理等各种学习领域[6,37]、雷达信号处理[15]和 LiDAR 点云分析[17],它的主要应用之一——也是这项工作的重点——是计算机视觉。多任务简历中的常见任务包括对象检测[16,14]、视觉问答[14]或 3D 简历任务[35,18,34].我们专注于处理密集预测任务的多任务转换器模型,例如语义分割、单眼深度估计、表面法线预测、显着性估计和物体边界检测。这些模型通常需要大量查询,但也有可能通过利用其特征的网格结构来大幅提高效率。在该领域具有重大建筑创新和强劲成果的有影响力的作品包括:在 MulT[2]由 Bhattacharjee 等人,每个任务解码器的共享注意力模块从模型编码器中相应的共享表示接收其查询和键。MQTransformer[32]展示了一种通过用更少的特定于任务的查询替换每像素查询来跨任务进行更有效的注意力计算的方法。MTMamba 是用于密集视觉任务的 MTL 的最新发展[20]作者:Lin 等人。它是一个状态空间模型而不是一个 Transformer,它根据查询数量提供更好的扩展行为,同时仍达到相当水平的预测质量。然而,与实现类似结果的基于 Transformer 的模型相比,它使用了更多的可学习参数和计算资源。
可变形混音器变压器。我们基于 Xu 等人引入的有影响力的 Multitask Vision Transformer 架构 DeMT 实现了我们的方法。在[33]以证明其对既定基线的影响。该模型取得了最先进的结果,在所有任务中都受到全球关注。它首先使用在 Imagenet 上预训练的主干网[11]从图像域中的输入数据中提取特征图。该主干网可以从多个选项中进行选择,包括 HRNetV2[27]和 Swin 变压器的变体[22].然后,作为 Transformer 编码器的一部分,提取的特征被传递到多个可变形混音器模块,每个任务一个,然后针对每个任务进行细化。此后,来自这些可变形混频器的输出特征图被输入到模型的解码器部分,即任务感知转换器解码器。该解码器由一个任务交互块组成,它允许将来自一个任务的信息传播到其他任务。最后,对于每个任务,其特征图在由多头自注意力(MHSA)模块和全连接多层感知器(MLP)组成的特定任务任务查询块中得到进一步细化。 我们在这项工作中重点关注的架构部分是任务交互块。在 DeMT 中,此块接受所有任务的编码器输出的串联作为其输入查询集,并对其执行 MHSA,然后执行 MLP。如前所述,对于多个任务,此任务交互块表现出较差的缩放行为和次优的预测质量。因此,我们将其替换为第 ̃ 3 节中描述的更有效的版本。
3方法论
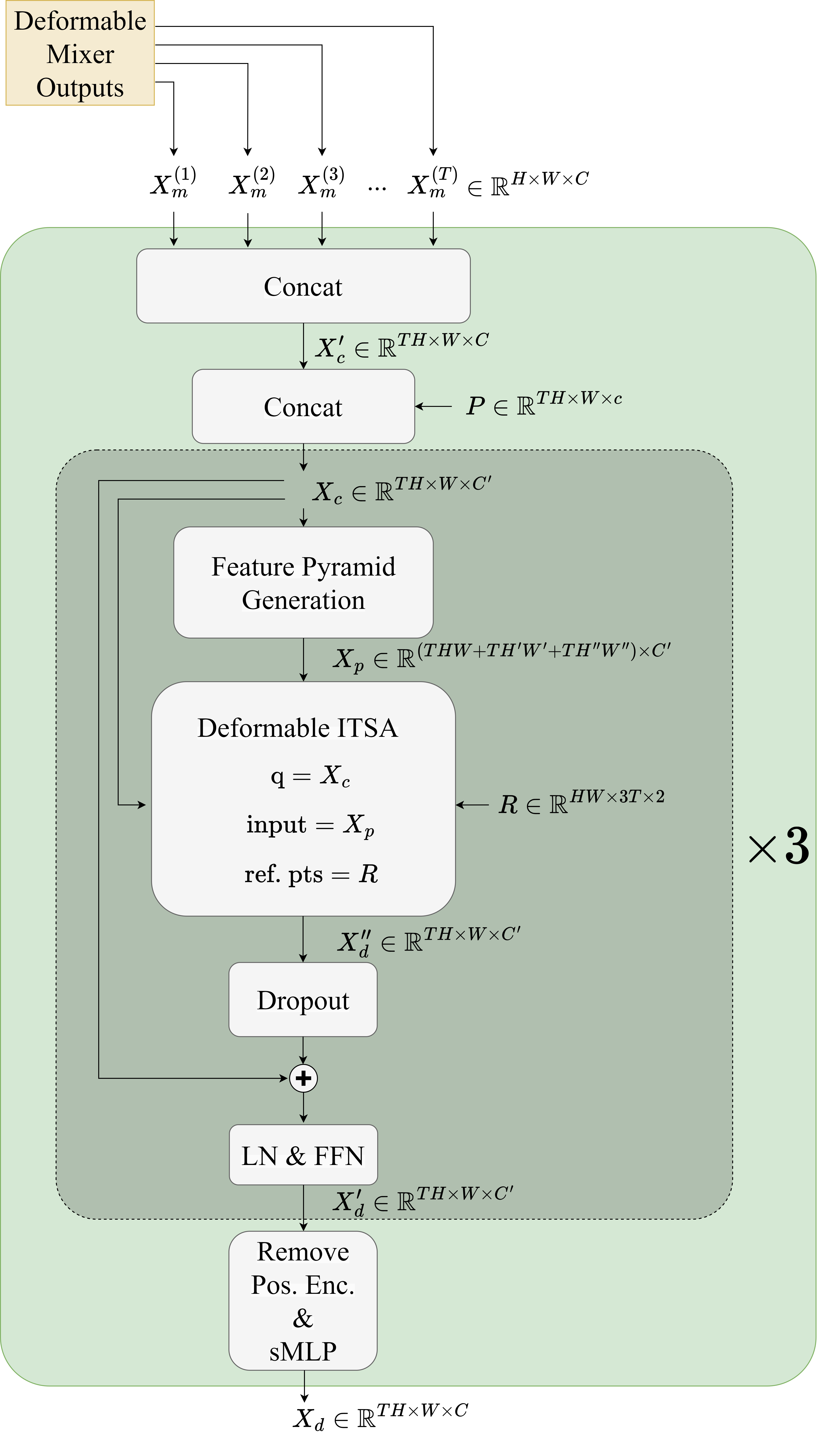
图 1:我们的任务交互块的示意图。LN 指的是层规范,FFN 是指前馈网络,sMLP 是线性层后跟层规范的小型 MLP。
下面,我们将详细描述我们的可变形任务间自注意力(ITSA)方法。它是一种自注意力,即它的查询集关注自己。我们方法背后的主要直觉是,对于特定任务的任何查询,它允许模型从所有任务特征图中相对较少的位置自由采样。因此,它可以有效地聚合来自所有任务的信息,以响应来自一个任务的查询。这种方法也适用于 CV 之外的各种 MTL 架构,前提是它们使用的查询涉及来自不同任务的网格结构特征。
我们的 DeMT 模型任务交互块的核心组件是可变形 ITSA。 如图 ̃ 1 所示,我们的任务交互块接收来自所有任务的先前可变形混合器模块的输出特征的串联,就像在 DeMT 中一样。在下文中,让H,W和C分别表示所有任务的全尺度特征图的高度、宽度和通道数,以及T模型中的任务数。对于属于任务的可变形混合器的输出特征t,Xm(t)∈ℝH×W×C,则交互块接受沿高度维度的串联:
图2:一个查询的可变形任务间自注意力的图示qh,w从任务t.任务的特征图t左侧包含位置查询(h,w),所有任务的特征金字塔(绿色和红色张量)是可变形注意力的输入,右侧的输出包含用于查询的细化特征qh,w的任务t在 ITSA 之后。\vectimes指示参考点Rh,w′查询qh,w.在此图中,我们仅显示两个特征金字塔级别和三个头,每个头部有三个偏移量,这些标部的实际值更高。
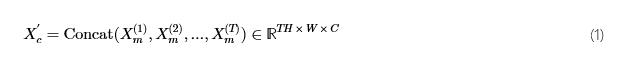
在下一步中,我们将连接一个二维正弦位置嵌入P∈ℝTH×W×c之c通道,产生该功能

Xc作为查询特征传递给可变形 ITSA,输入特征从中派生。 为了提高对输入数据中可变尺度图案的鲁棒性,可变形ITSA的输入特征是一个特征金字塔,如图 ̃ 2所示。 我们得到这些特征如下:对于任务的全尺寸特征图t,即Xc=:Xp0与任务相对应的t,Xp0t,我们计算了两个较小金字塔级别的下采样版本。为了在每个下采样步骤中将每个空间维度的大小大约减半,我们使用 3x3 卷积,步幅为 2。 下采样映射定义如下:

为t∈{1,…,T},
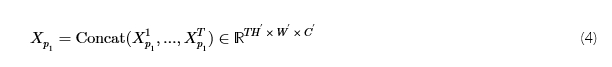
和

跟Xp2来自[Xp21,…,Xp2T]类似于Xp1.由此,我们得到Xp通过展平和串联:
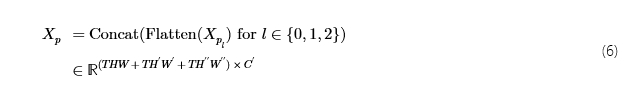
我们定义了所有查询的采样输入特征的参考点,如下所示:对于查询qh,w在索引处(h,w)对于任何任务,其分配的参考点为

即,其单元格在查询网格中的中心Xc. 对于下采样的要素,参考点与上述相同,因为参考点是相对于要素大小定义的,而不是绝对坐标。展平后 的高度和宽度尺寸R′合二为一,对所有任务和三个金字塔水平重复它,我们得到参考点的张量

表1:将我们的方法与 NYUD-v2 数据集上以前最先进的方法进行比较。Δ%表示相对于 DeMT 的改进百分比[33].
| 型 | 骨干 |
|
|
|
| Δ%↑ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 德蒙特[33] | 人力资源网18 | 0.3760 | 0.6286 | 20.80 | 0.7718 | 0.00 | ||||||||
| 我们 | 人力资源网18 | 0.4039 | 0.5819 | 20.34 | 0.7712 | 4.25 | ||||||||
| 单任务基线[33] | 斯温-T | 0.4292 | 0.6104 | 20.94 | 0.7622 | -3.42 | ||||||||
| 多任务基线[33] | 斯温-T | 0.3878 | 0.6312 | 21.05 | 0.7560 | -6.87 | ||||||||
| MQTransformer[32] | 斯温-T | 0.4361 | 0.5979 | 20.05 | 0.7620 | -1.44 | ||||||||
| 德蒙特[33] | 斯温-T | 0.4636 | 0.5871 | 20.65 | 0.7690 | 0.00 | ||||||||
| 我们 | 斯温-T | 0.4806 | 0.5567 | 20.14 | 0.7769 | 3.08 | ||||||||
| 单任务基线[33] | 斯温-S | 0.4892 | 0.5804 | 20.94 | 0.7720 | -4.20 | ||||||||
| 多任务基线[33] | 斯温-S | 0.4790 | 0.6053 | 21.17 | 0.7690 | -6.21 | ||||||||
| MQTransformer[32] | 斯温-S | 0.4918 | 0.5785 | 20.81 | 0.7700 | -3.89 | ||||||||
| 德蒙特[33] | 斯温-S | 0.5150 | 0.5474 | 20.02 | 0.7810 | 0.00 | ||||||||
| 我们 | 斯温-S | 0.5259 | 0.5356 | 19.87 | 0.7859 | 1.42 |
表2:将我们的方法与 PASCAL-Context 数据集上以前最先进的方法进行比较。Δ%表示相对于 DeMT 的改进百分比[33].
| 型 | 骨干 |
|
|
|
|
| Δ%↑ | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 德蒙特[33] | 人力资源网18 | 0.5582 | 0.5708 | 0.8417 | 14.21 | 0.7490 | 0.00 | ||||||||||
| 我们 | 人力资源网18 | 0.5821 | 0.5706 | 0.8453 | 14.02 | 0.7526 | 1.29 | ||||||||||
| 单任务基线[33] | 斯温-T | 0.6781 | 0.5632 | 0.8218 | 14.81 | 0.7090 | -1.38 | ||||||||||
| 多任务基线[33] | 斯温-T | 0.6474 | 0.5325 | 0.7688 | 15.86 | 0.6900 | -6.60 | ||||||||||
| MQTransformer[32] | 斯温-T | 0.6824 | 0.5705 | 0.8340 | 14.56 | 0.7110 | -0.31 | ||||||||||
| 德蒙特[33] | 斯温-T | 0.6971 | 0.5718 | 0.8263 | 14.56 | 0.7120 | 0.00 | ||||||||||
| 我们 | 斯温-T | 0.6987 | 0.5828 | 0.8485 | 14.03 | 0.7746 | 3.46 |
我们通过Xc作为查询特征,Xp作为输入特征和参考点R到中定义的“可变形注意力”功能[38]. 对于这些输入张量,我们将对它们执行可变形注意力称为可变形任务间自注意力。 作为输出,我们收到特征Xd′′,即在关注可变形ITSA中所有任务特征后,细化的任务特征图。图 ̃ 2 显示了如何为一个查询计算可变形 ITSAqh,w从任务t.对于每个参考点和任务特征图,固定数量的偏移量Δp通过线性层从查询特征计算。这些定义了相对于输入采样的参考点的位置。由于偏移量和参考点通常不是积分的,因此应用双线性插值来生成样本。与偏移量类似,根据查询,使用线性层后跟软max生成注意力权重。与多头注意力类似[28],输入特征映射Xp不是直接采样,而是对它们进行多个学习投影,每个头部一个。然后,注意力权重用于聚合不同头部、任务和特征金字塔级别的样本,以生成用于查询的可变形 ITSA 输出。 将此作应用于Xc,产生以下输出:
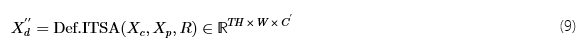
对于正则化,我们喂食Xd′′通过 Dropout 层[25]在 0.1 的下降概率下,为了更好地保留高频特征,我们将Xc通过残差连接到它。此后,我们应用层范数 (LN)[1]以及一个小型前馈网络 (FFN) 以生成
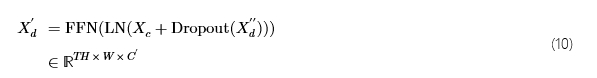
我们总共执行了三个 ITSA 细化步骤,即我们更新Xc:=Xd′再重复特征金字塔计算、可变形ITSA、Dropout、LN和FFN两次,得出最终的Xd′.从中,我们删除最后一个c包含位置信息的通道,以及以下[33],应用线性层的小 MLP,然后应用层范数来生成Xd∈ℝTH×W×C作为我们的任务交互块的最终输出。
表3:在具有 HRNet18 主干的 NYUD-v2 数据集上评估的任务交互块组件的消融。可变形的 ITSA 用我们的版本取代了任务交互块。3 x 3 转换下采样是指以 2 步幅的 3 x 3 卷积执行下采样,而不是 1 x 1 卷积,然后是 2 x 2 最大池化。3 个细化步骤是指执行 3 个可变形 ITSA 步骤而不是 1 个。
| 型 |
|
|
|
| Δ%↑ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeMT 基线[33] | 0.3760 | 0.6286 | 20.80 | 0.7718 | 0.00 | ||||||||
| 可变形 ITSA | 0.3907 | 0.5877 | 20.41 | 0.7721 | 3.08 | ||||||||
| + 3 x 3 转换下采样 | 0.3958 | 0.5954 | 20.34 | 0.7737 | 3.25 | ||||||||
| + 位置编码 | 0.4004 | 0.5943 | 20.30 | 0.7732 | 3.63 | ||||||||
| + 3 个细化步骤 | 0.4039 | 0.5819 | 20.34 | 0.7712 | 4.25 |
表4:梯度比例因子的消融λ在具有 HRNet18 主干的 NYUD-v2 数据集上进行评估。
| λ |
|
|
|
| Δ%↑ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1× | 0.3989 | 0.6010 | 20.35 | 0.7743 | 0.00 | ||||||||
| 10× | 0.4020 | 0.5939 | 20.28 | 0.7737 | 0.56 | ||||||||
| 30× | 0.4031 | 0.5920 | 20.31 | 0.7730 | 0.65 | ||||||||
| 50× | 0.4088 | 0.5915 | 20.32 | 0.7729 | 1.01 | ||||||||
| 100× | 0.4039 | 0.5819 | 20.34 | 0.7712 | 1.02 | ||||||||
| 200× | 0.0199 | 1.5089 | 45.34 | 0.4169 | -104 |
表5:在具有 HRNet18 主干的 NYUD-v2 数据集上评估的特征金字塔水平数量的消融。
| 金字塔级别 |
|
|
|
| Δ%↑ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.3979 | 0.5901 | 20.42 | 0.7734 | 0.00 | ||||||||
| 2 | 0.4028 | 0.5853 | 20.43 | 0.7707 | 0.41 | ||||||||
| 3 | 0.4039 | 0.5819 | 20.34 | 0.7712 | 0.75 |
| 输入图像 | Sem. Seg. | 深度 | 正常 | 边界 |
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|















图 3:使用我们的模型生成的 NYUD-v2 验证集中的定性示例。
4实验
为了验证我们的方法并证明其在多个主干架构、模型大小和数据集中的一致有效性,我们在三个不同的主干和两个著名的多任务视觉数据集上进行了实验。
4.1实验设置
实现详细信息。我们评估集成到 DeMT 中的可变形 ITSA 方法[33]体系结构,如前所述。为了确保与 DeMT 的可比性,我们使用 SGD 优化器训练模型,其学习率值相同10−3和重量衰减5⋅10−4.我们的损失函数是单个任务损失的加权总和。为了与之前的工作进行比较,我们使用相同的任务损失函数和来自 DeMT 的损失权重,无需修改。作为训练硬件,我们为每个实验使用了一个 A100 80GB GPU。
模型超参数。我们的任务交互块的输入和输出都有一个通道号C=256,从而保持与 DeMT 架构的兼容性。对于可变形 ITSA 模块,位置编码c=24通道连接,导致总通道计数C′=280.在我们的网格搜索中,我们发现使用更多通道进行位置嵌入并没有产生额外的改进。在可变形 ITSA 模块中,我们使用 4 个头部,并在每个参考点周围取样 16 个偏移量。在最初的实验中,我们观察到学习到的偏移量非常接近它们的初始化。因此,作为一个新的超参数,我们引入了一个缩放因子λ用于可变形 ITSA 模块的梯度,允许模型学习有意义的采样偏移并显着提高其性能。我们发现 100 倍数在我们的实验中表现最好。在 LABEL:gradient_scale_ablation 中,对λ可见,说明不同选择对它的影响。
数据。我们在公共 NYUD-v2 上评估我们的方法[24]和 PASCAL-Context[23]数据。在多任务计算机视觉文献中,这些已被确立为基准数据集。 NYUD-v2 包含 795 张用于训练的图像和 654 张用于验证的图像。这些图像中的每一个的分辨率560×425像素并描绘室内场景。这些图像用语义分割、深度信息、表面法线和对象边界进行了密集的注释。 PASCAL-Context 数据集分为 4998 张训练图像和 5105 张验证图像。它的图像描绘了各种室内和室外场景。每个图像都有密集的像素标签,用于训练语义分割、人体部位分割、显着性估计、表面法线预测和物体边界估计。 对于 HRNet18 主干网,我们的结果无法与 DeMT 论文的结果直接比较,因为作者没有发布该设置所需的配置文件。因此,对于该主干网,我们必须创建自己的文件,并使用这些文件训练 DeMT 基线和我们自己的模型。
骨干。我们的方法在基于 CNN 的 HRNet-V2-W18-small (HRNet18) 主链(3.9 M 参数)上进行了评估[27],以及 Vision Transformer 主干网 Swin-T (27.5 M) 和 Swin-S (48.8 M)[22].
指标。在这两个数据集中,我们总共评估了六项任务。对于这些,它们各自的性能指标如下:对于语义分割和人体部分分割,我们报告平均交集多于并集 (mIoU) 分数,深度估计任务的性能通过均方根误差 (RMSE) 来衡量,表面正态估计质量通过平均误差 (mErr) 来判断,对于边界估计任务,我们报告最佳数据集尺度 F 度量 (odsF),显着性估计的质量通过最大 F 度量 (maxF) 进行量化。对于所有任务,这些是相关文献中常见报道的标准指标。我们还提供平均改善百分比 (Δ%)在与 DeMT 相关的所有任务中,这是我们的基线。
4.2结果
NYUD-v2 数据集。在 LABEL:NYUD_results 中,我们显示了 NYUD-v2 数据集的结果。对于所有骨架,与 DeMT 基线相比,我们的方法取得了显着增强的结果。评估平均改进,很明显,对于较小的骨干,质量的提高更为明显。这是可以预料的,因为对于来自更大主干的更强大功能,指标已经明显更好,因此使得大型改进更具挑战性。特别是对于较小的 HRNet-18 主干网,我们观察到了显着的改进:在那里,我们实现了7.4%语义分割和深度估计的得分都更好,同时仍然大大改进了其他两项任务。同样对于 Swin-T 主干网,我们看到性能提升5.2%对于深度估计任务,而所有其他任务也至少提高了1%.
PASCAL-Context 数据集。 LABEL:PASCAL_results 显示 PASCAL-Context 数据集上的结果。除了使用 HRNet18 主干的人体部分分割任务外,与 DeMT 基线相比,我们观察到使用任务交互块在每个任务指标中都有更好的性能。对于评估的两个主干,我们观察到任务的平均改进1.29%和3.46%分别。
4.3运行时指标
为了说明我们的方法对所需计算资源的显着改进,我们计算了所需的 FLOP,并测量了推理过程中任务交互块中注意力模块的延迟。我们将这两个指标与 DeMT 实现的指标进行了比较[33].对于这两个版本,我们在同一硬件上测量了推理时间,即具有 3000GB GPU 内存的 RTX A6 GPU。对于这两个实验,我们在 NYUD-v2 数据集上使用 HRNet18 主干进行评估,批量大小为 1、3 个特征金字塔级别和单个细化层。
表6:比较 DeMT 基线和我们的方法之间注意力计算的计算资源需求。
| 型 | 失败↓ | 推理延迟↓ |
|---|---|---|
| 德蒙特[33] | 3.75吨 | 10.72秒 |
| 我们 | 0.24吨 | 1.34秒 |
正如 LABEL:runtime_metrics_table 所示,我们的方法将计算注意力所需的资源量减少了大约一个数量级。
4.4消融
任务交互块。为了展示我们实现的各个功能的影响,在 LABEL:component_ablation 中可以看到对任务交互块组件的消融。从与 DeMT 基线相比的改进百分比来看,很明显,用我们的可变形 ITSA(第二行)的精简版本替换全局 MHSA 已经导致所有任务指标的平均值有了很大的相对改善。此版本仅执行单个可变形 ITSA 步骤,没有附加位置编码Xc,并使用 1 x 1 卷积和 2 x 2 最大池化对特征金字塔生成执行下采样。应用步幅为 2 的 3 x 3 卷积进行下采样、附加位置编码以及使用 3 个细化步骤都具有较小的相对影响。然而,与基线相比,它们较小的个人贡献仍然使功能齐全的模型有了实质性的改进。
梯度缩放因子。 标签:gradient_scale_ablation显示了梯度比例因子的消融λ用于可变形ITSA,强调为该超参数选择适当值的重要性。将平均改进百分比与因子 1 的版本进行比较,该版本根本不缩放梯度,我们观察到 10 和 30 的因子已经导致指标的改善,但缩放 50 或 100 似乎接近最佳值。为了说明超出我们选择的 100 不会产生显着的进一步改进,我们还尝试了 200 的系数,此时模型的指标崩溃了。这是因为,对于如此大的缩放因子,很大一部分采样点将位于特征图之外,因此需要将它们裁剪到地图边缘周围的位置。这将模型置于一个深的局部最小值中,对于大多数查询和偏移量,只能对那些边缘位置进行采样,这解释了糟糕的结果。
特征金字塔级别。 标签:feature_pyramid_ablation表明,额外的金字塔级别对语义分割的改善最大,对深度估计任务的影响较小。由于其余两个任务的性能大致保持不变,因此总体平均提升不是特别大。然而,我们仍然认为,仅为了提高分割性能,在模型中保留多个特征金字塔水平是值得的。
5结论
在这项工作中,我们引入了可变形的任务间自注意力,这是一种显着降低与在具有许多查询的 Vision Transformer 模型中任务之间进行相关的计算成本的方法。我们证明,我们的方法使 FLOP 计数和推理延迟提高了大约 10 倍。同时,我们仍然能够在不同的主干和数据集中大幅度提高模型中任务的预测质量。
目前我们方法的一个局限性是它专注于密集的预测任务。在未来的工作中,我们打算将我们的方法推广到其他结构化程度较低的任务中。特别是,我们也想扩展我们的方法以支持对象检测任务。这将涉及必须学习从对象查询中计算参考点,因为我们不能再仅使用特征图中查询的位置作为其参考点。










)

HTML基础教程:文档类型声明与字符编码详解)
接口文档自定义排序(万能大法,支持任意swagger版本))





