文章目录
- 一、Dataset 与 DataLoader 功能介绍
- 抽象类Dataset的作用
- DataLoader 作用
- 两者关系
- 二、自定义Dataset类
- Dataset的三个重要方法
- `__len__()`方法
- `_getitem__()`方法
- `__init__` 方法
- 三、现成的torchvision.datasets模块
- MNIST举例
- COCODetection举例
- `torchvision.datasets.MNIST`使用举例
- `torchvision.datasets.CocoDetection`举例
一、Dataset 与 DataLoader 功能介绍
抽象类Dataset的作用
简单来说,就是将原始数据(可能是图片、文本、音频等各种格式)整理成模型可以处理的格式,为后续的数据加载和处理做准备。功能是定义数据集的基本属性和数据获取方式。
- 初始化数据路径:在
Dataset类的__init__方法中,通常会初始化数据存放的路径,以及一些数据预处理的操作,比如指定图片数据集图片所在文件夹路径,文本数据集文本文件路径等 。包含 加载数据/读取数据、预处理数据、图像增强 等一系列操作 - 获取单个样本及其标签:通过实现
__getitem__方法,根据给定的索引(dataloader返回的),返回相应的数据样本和对应的标签。例如在图片分类任务中,给定索引后,返回该索引对应的图片数据(经过预处理,如调整尺寸、归一化等)以及图片的类别标签。 - 统计样本数量:通过实现
__len__方法,返回数据集中样本的总数,方便在训练和评估过程中知道数据规模 。
DataLoader 作用
DataLoader是在Dataset的基础上,提供了一种更加高效、便捷地加载数据的方式,它可以将Dataset返回的单个样本,按照指定的方式进行打包(如组成batch)、打乱顺序等操作,从而满足模型训练和评估的需求。
-
创建数据批次,指定数据打包输出规则:通过
batch_size参数,将Dataset中的单个样本打包成一个个批次(batch)的数据。collate_fn指定如何从NNN张训练集选出一个batch的Nbatch_size\frac{N}{batch\_size}batch_sizeN张图片。- 例如
batch_size=32,那么DataLoader每次会从Dataset中取出32个样本组成一个batch。每次迭代,返回的是 一个batch 的数据
-
自定义数据采样,指定数据迭代读取规则:
- 一般使用自定义的采样器(
Sampler),实现对数据的特殊采样方式,比如分层采样(在类别不均衡的数据集中,保证每个batch中各类别的样本比例与原始数据集相似)等。 - dataset对象是dataloader的一个参数,通过dataset让dataloader知道训练集一共多少图片,从而知道共跌代多少次。
- 一般使用自定义的采样器(
-
数据打乱:通过
shuffle参数设置是否在每个epoch开始时打乱数据顺序,这样可以避免模型在训练时对数据产生特定的依赖,有助于模型学习到更通用的特征,提高模型的泛化能力 。 -
多进程加载:通过
num_workers参数设置多进程加载数据,从而加快数据加载速度,尤其是在数据量较大、数据预处理较为复杂的情况下,多进程可以充分利用CPU资源,减少数据加载时间,避免数据加载成为训练过程中的瓶颈 。
两者关系
-
Dataset是数据的基础容器,定义了如何获取数据集中的单个样本; -
而
DataLoader则是Dataset的上层应用,负责按照特定规则(如批量处理、打乱顺序等)从Dataset中高效地加载数据,供模型进行训练、验证和测试等操作。 -
可以说,
Dataset是数据的来源和基本操作接口,DataLoader则是为了更好地适配模型训练需求,对Dataset的数据进行进一步处理和组织的工具。
二、自定义Dataset类
所谓的 自定义 dataset ,即自己去写一个 Dataset 类,要满足两个要求:
- 一般需要继承自
torch.utils.data.Dataset类- 继承
torch.utils.data.Dataset主要目的是为了与DataLoader保持兼容,确保数据集遵循DataLoader的接口标准,方便后续使用 PyTorch 提供的工具,比如 :批量加载、打乱数据、并行处理等功能
- 继承
- 并且满足和
DataLoader进行交互的规范 :- 因为
DataLoader会调用Dataset的len()和getitem()方法,所以自定义Dataset类必须实现这两个方法,如此才能保证DataLoader可以正确地加载和操作你的数据集
- 因为
- 兼容训练和推理阶段
Dataset的三个重要方法
创建自定义 Dataset类时,必须实现的3个方法 :__init__()、__len__()、 __getitem__()。
这些方法定义了数据集的基本结构和行为,也是 DataLoader 可以正确的从 Dataset 中读取数据的基础。
__len__()方法
DataLoader是通过Dataset的 __len__(),得知训练集一共多少数据样本的。
def __len__(self):return len(self.file_list)
- 返回值:数据集中的样本的总数。
- 作用:
- 方便通过调用
len(dataset)来获取数据量,其中 dataset 为 Dataset 对象 - Dataloader 会用它和 batch_size 一起来计算一个 epoch 要迭代多少个 steps:
steps=len(dataset)batch_sizesteps = \frac{len(dataset)}{batch\_size}steps=batch_sizelen(dataset) - DataLoader调用len方法的代码封装在源码了,所以看不到显式调用。DataLoader得到一共NNN个数据样本后,生成000 ~ N−1N-1N−1的索引。再根据batch_size和是否打乱,生成一个batch的索引列表,再将每个索引
idx传入到Dataset的_getitem__()方法中返回得到图片和索引return image, label
- 方便通过调用
_getitem__()方法
作用: 根据给定的索引返回数据集中的一个样本。这是用于获取数据集中单个样本的方法。
def __getitem__(self, idx):# 通过索引idx,获取图片地址img_nameimg_name = os.path.join(self.data_folder, self.file_list[idx])# 根据图片地址img_name读取对应图像original_imageoriginal_image = Image.open(img_name)# 通过索引idx获取图片对应的标签(这里举的例子的标签含在图片名中)label = img_name.split('_')[-1].split('.')[0]# 图像预处理和数据增强(仅训练阶段)if self.train:image = self.transform(original_image)else:image = self.transform(original_image)# 返回处理好的一张图像和标签return image, label
- 接收参数: index(idx)是单个数据样本的索引,由DataLoader传来的
- 返回值: 返回数据集中索引指定的样本。通常是一个包含输入数据和对应标签的元组。这里可以根据自己的需求,进行自定义。
DataLoader返回的是一个batch的数据,具体是:
- DataLoader的采样器
sampler根据数据总量和batch_size=2,和采样方法(举例为顺序采样)得到第一次迭代结果为索引列表[0, 1] - DataLoader分别把索引0和1给Dataset,
__getitem__()方法返回出对应单个索引的图片和标签。 - 把得到的一个batch的两组图片和标签给
collate_fn函数进行打包并以一种数据结构储存,由DataLoader返回
__init__ 方法
- 参数: 根据需要传递一些参数,例如文件路径、数据转换等。
- 作用: 构造方法,配好len和getitem方法做一些初始化工作,需要什么数据,就传入进来赋值到成员属性。
def __init__(self, data_folder, train, transform=None):self.data_folder = data_folderself.transform = transformself.file_list = os.listdir(data_folder)# 把文件名读取出来,存入到file_list,方便len方法获取数据量self.train = train
例如:设置文件路径selfl.data_folder、定义数据转换的transforms、当前是训练阶段还是验证阶段的布尔值train等。
三、现成的torchvision.datasets模块
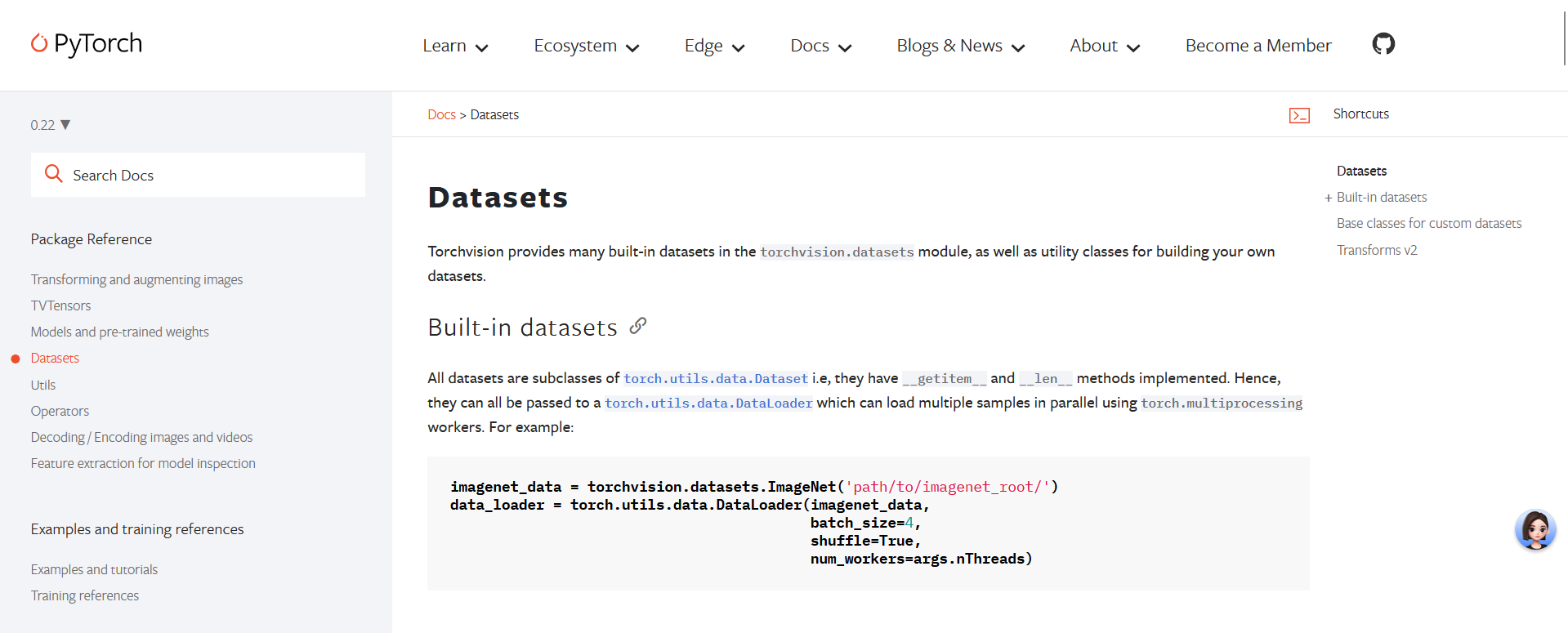
对于一些公开的数据集,可以直接用torchvision.datasets模块的现成的Dataset类。
Pytorch官方文档的torchvision的Dataset列出了可使用的数据集的Dataset,实现了getitem和len方法
MNIST举例
这里以Image classification任务的MNIST(mixed national institute of standards and technology database)数据集举例,点入详情页课查看:

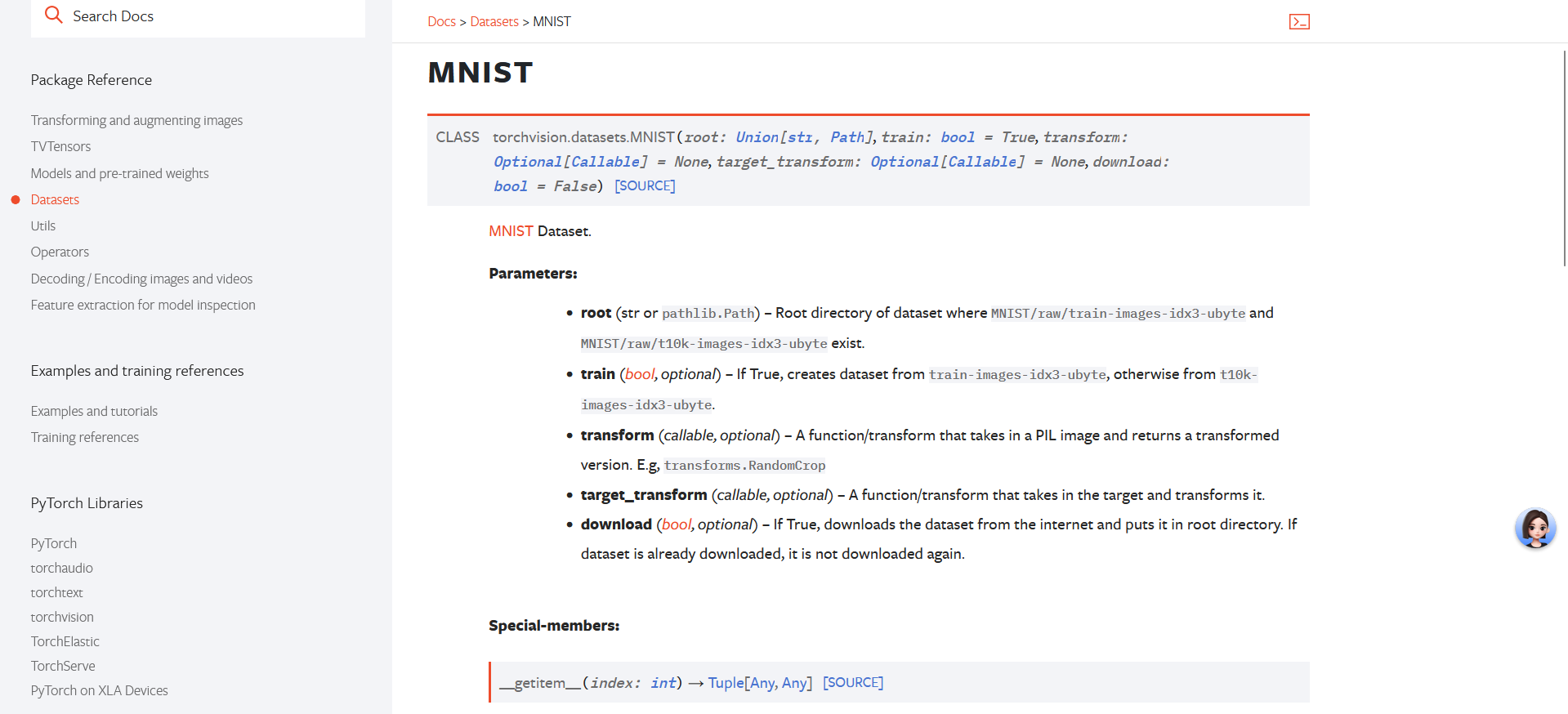
train_dataset = torchvision.datasets.MNIST(root, train=True, transform=None, target_transform= None download=True)
参数:
root:数据集存放的路径download:是否下载数据集,默认为False。配合root参数:- 若设置
download=Trueroot目录下没有该数据集,数据集将会被下载到root指定的位置。root目录下已经存在该数据集,则不会重新下载,而是会直接使用已存在的数据,以节省时间
- 若设置
download=False,程序将会在root指定的位置查找数据集,如果数据集不存在,则会抛出错误。
- 若设置
train:- 如果是
True,下载训练集trainin.pt; - 如果是
False,下载测试集test.pt。默认是True
- 如果是
transform:接收torchvision.transforms的对象,一系列作用在PIL图片上的转换操作,用于对数据集的图像预处理和数据增强。target_transform:对target处理,一般不用。因为出来target出来一般用自定义的Dataset,因为图像处理和target处理要放一个transform里写
COCODetection举例
Image detection任务的COCO数据集
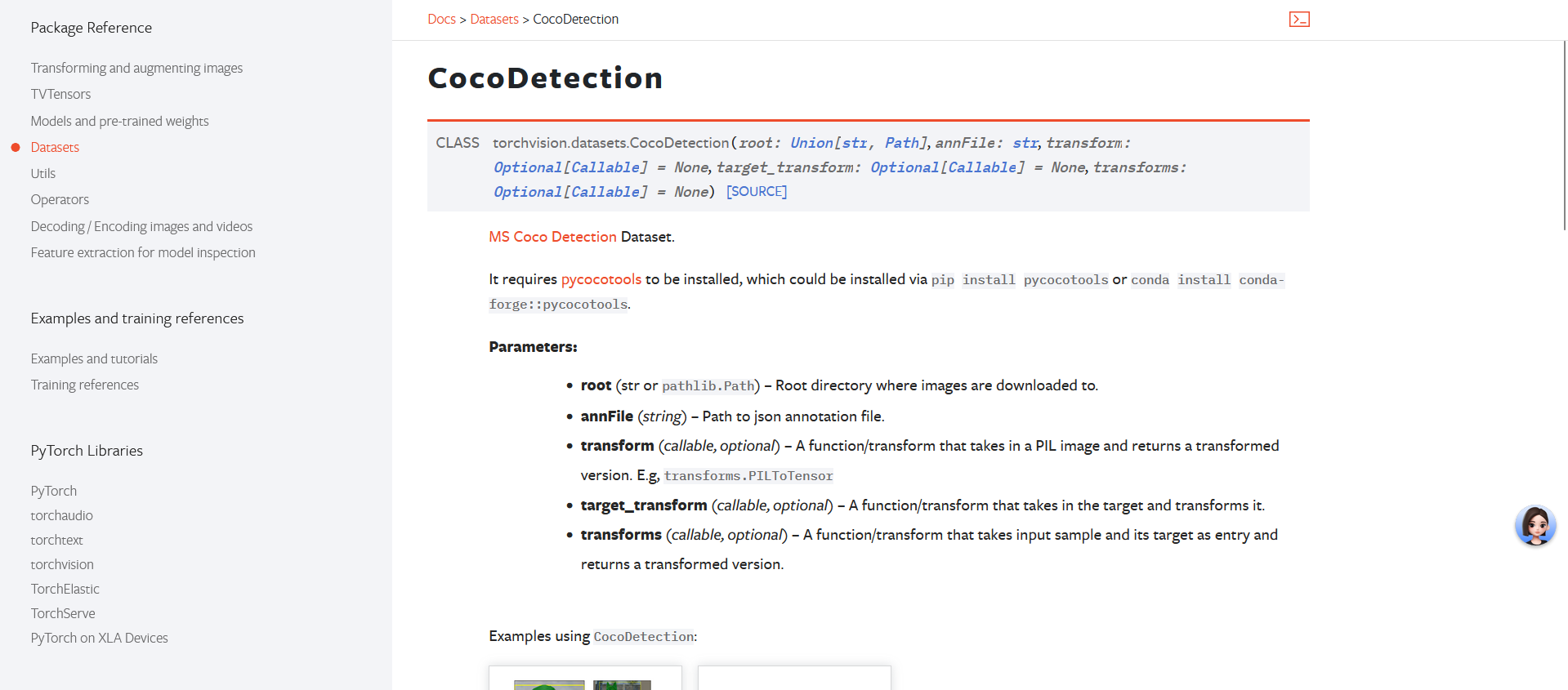
注意:对于一部分数据集比如torchvision.datasets.CocoDetection,Pytorch不提供下载功能 (具体情况取决于数据集的来源和许可协议),就没有download参数。
所以在使用 torchvision.datasets.CocoDetection 这个现成的Dataset类之前,需要确保已经下载并淮备好COCO数
据集的图像和标注文件。然后使用torchvision.datasets.CocoDetection 类来加载 COCO数据集。
torchvision.datasets.CocoDetection(root, annFile, transform=None, target_transform=None, transforms=None)
root:指定图片地址(本地已经下载下来的图像地址)annFile:指定标注文件地址(本地已经下载下来的标注文件地址)transform:图像处理 (用于PIL)target_transform:标注处理transforms:图像和标注的处理
torchvision.datasets.MNIST使用举例
训练集和验证集分别实例化一个Dataset类(torchvision.datasets.MNIST)的对象,传入的transforms参数都为实例化的transforms.Compose对象my_transform。数据集下载到当下文件所在目录下。
import torchvision
from torchvision.transforms import transforms
import torch.utils.data as data
import matplotlib.pyplot as pltbatch_size = 5# transforms.Compose的对象,传入到transforms参数
my_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.5], # mean=[0.485, 0.456, 0.406]std=[0.5])]) # std=[0.229, 0.224, 0.225]train_dataset = torchvision.datasets.MNIST(root="./",train=True,transform=my_transform,download=True)val_dataset = torchvision.datasets.MNIST(root="./",train=False,transform=my_transform,download=True)
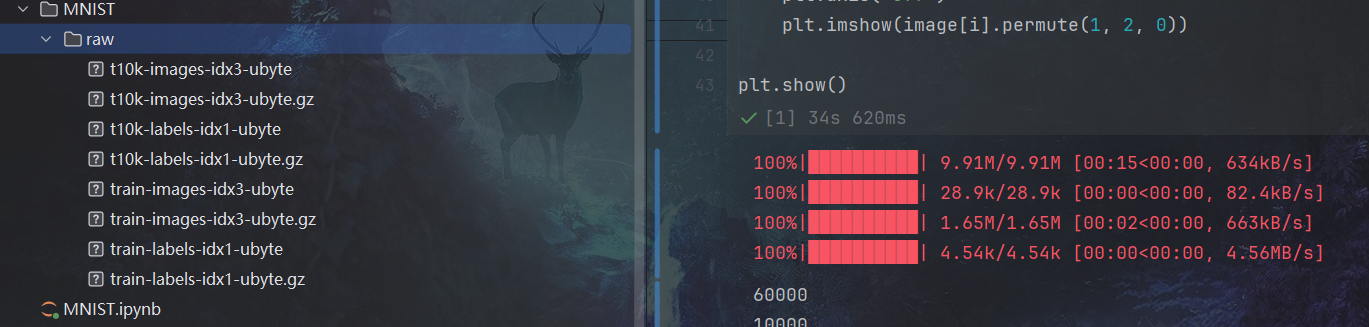
- 可以看的在当下目录下出现了一个MNIST文件夹,
.gz后缀的是下载的压缩文件,程序自动解压为同名的二进制文件- Dataset会自动处理好二进制文件,最终从DataLoader跌代出来的是正常的单通道灰度图。
将定义出的训练集和验证集的Dataset对象,分别作为参数传入到两个DataLoader,得到两个DataLoader对象
train_loader = data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True)val_loader = data.DataLoader(val_dataset,batch_size=batch_size,shuffle=True)
分别调用量Dataset的len方法,输出数据量。再将train_loader转换为迭代器iter(train_loader),通过next方法得到一个batch的image和label。
打印出一个batch的image的shape。[5, 1, 28, 28]分别指batch_size,图片通道数,图像长宽。
打印出标签label列表。
最后可视化一个batch的图和标签。
print(len(train_dataset))
print(len(val_dataset))image, label = next(iter(train_loader))
print(image.shape)
print(label)for i in range(batch_size):plt.subplot(1, batch_size, i + 1)plt.title(label[i].item())plt.axis("off")plt.imshow(image[i].permute(1, 2, 0))plt.show()

torchvision.datasets.CocoDetection举例
需要把数据集的下载地址换掉,换成你的 COCO数据集地址
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
import torch
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torchvision.transforms import functional as F
import randomdef collate_fn_coco(batch):return tuple(zip(*batch))coco_det = datasets.CocoDetection(root="./COCO2017/train2017",annFile="./COCO2017/annotations/instances_train 2017.json")sampler = torch.utils.data.SequentialSampler(coco_det) # RandomSampler
batch_sampler = torch.utils.data.BatchSampler(sampler, 1, drop_last=True)
data_loader = torch.utils.data.DataLoader(coco_det,batch_sampler=batch_sampler,collate_fn=collate_fn_coco)# 可视化
iterator = iter(data_loader)
imgs, gts = next(iterator)
img, gts_one_img = imgs[0], gts[0]bboxes = []
ids = []
for gt in gts_one_img:bboxes.append([gt['bbox'][0],gt['bbox'][1],gt['bbox'][2],gt['bbox'][3]])ids.append(gt['category_id'])fig, ax = plt.subplots()
for box, id in zip(bboxes, ids):x = int(box[0])y = int(box[1])w = int(box[2])h = int(box[3])rect = plt.Rectangle((x, y), w, h, edgecolor='r', linewidth=2, facecolor='none')ax.add_patch(rect)ax.text(x, y, id, backgroundcolor="r")plt.axis("off")
plt.imshow(img)
plt.show()



安装及使用:多台电脑共用鼠标键盘)









——社区人脸识别出入管理系统设计与实现)
)

基于量子重加密技术构建区块链数据共享解决方案)

、SUM(数值求和)、AVG(平均值)、MAX/MIN(极值)深度指南)

