本文参考视频[双语字幕]吴恩达深度学习deeplearning.ai_哔哩哔哩_bilibili
参考文章0.0 目录-深度学习第一课《神经网络与深度学习》-Stanford吴恩达教授-CSDN博客
1深度学习概论
1.举例介绍
lg房价预测:房价与面积之间的坐标关系如图所示,由线性回归可以在坐标上得出这样一条直线
由于房价非负,所以你把剩下的设置为0
右边的小圆圈就是一个神经元,这个神经元实现了输入面积输出房价的功能,这就是最简单的神经网络
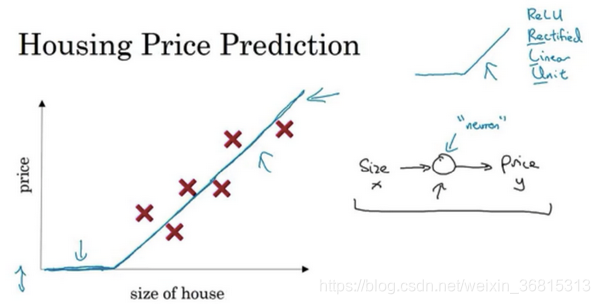
在有关神经网络的文献中,你经常看得到这个函数。从趋近于零开始,然后变成一条直线。这个函数被称作ReLU激活函数,它的全称是Rectified Linear Unit。rectify(修正)可以理解成max(0,x),这也是你得到一个这种形状的函数的原因。
这只是一个单神经元网络,你需要以此为单位搭建更大的神经网络
当然还有很多因素来影响房价,在图上每一个画的小圆圈都可以是ReLU的一部分,也就是指修正线性单元,或者其它稍微非线性的函数,中间的圈也叫做隐藏层
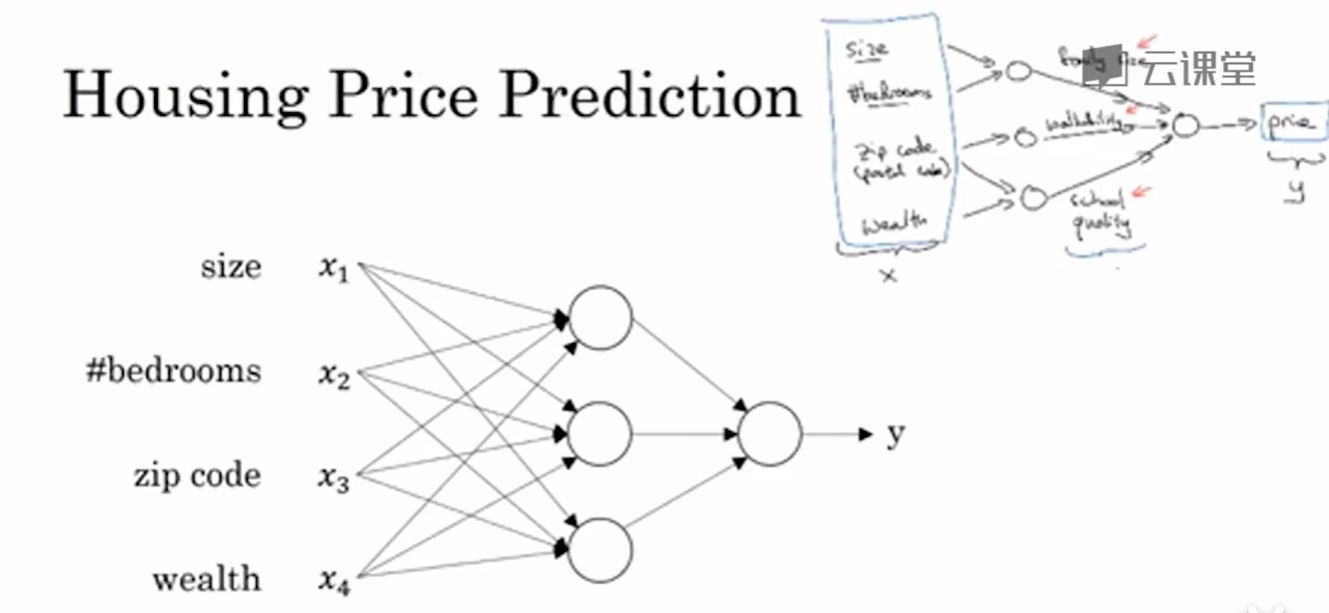
隐藏层是神经网络中的中间层,负责对输入数据进行特征提取和变换,为输出层提供高层次特征
所以神经网络的功能之一就是当你实现它之后,只要输入x就能输出y,因为他可以自己计算你训练集中的样本数目以及所有的中间过程,不管训练集有多大
2.用神经网络进行监督学习
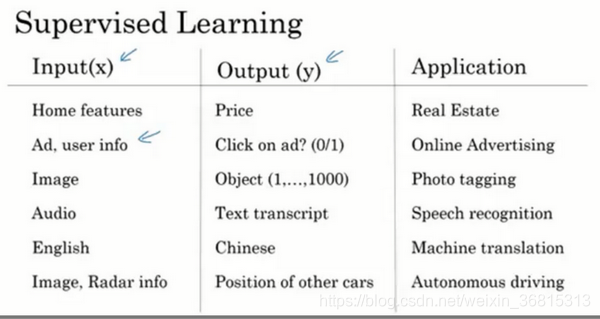
简单归类一下:
房地产和在线广告经常用到的是相对标准的神经网络
图像领域经常用到的是卷积神经网络(CNN)
序列数据(音频是一维时间序列,语言是最自然的序列数据)用的是递归神经网络RNN(S)
无人驾驶用的是混合神经网络结构
结构化数据基本上就是简单的数字数据
非结构化数据包括音频,图像,文本
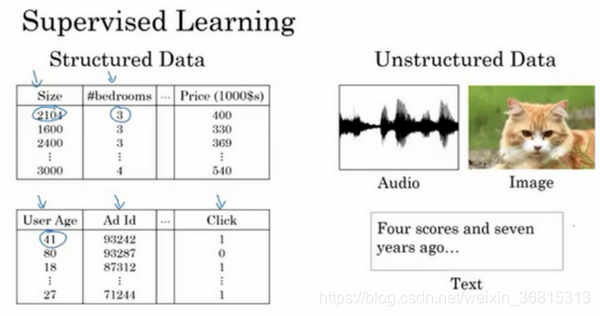
通过深度学习和神经网络,计算机可以更好地处理非结构化数据,并产生了语音识别、图像识别、自然语言文字处理等应用
2.神经网络基础
习题2.19 总结-深度学习-Stanford吴恩达教授_请考虑以下代码,c的维度是什么-CSDN博客
1.二元分类
首先我们从一个问题开始说起,这里有一个二分类问题的例子,如果识别这张图片为猫,则输出标签1作为结果;如果识别出不是猫,那么输出标签0作为结果。现在我们可以用字母来表示输出的结果标签,如下图:
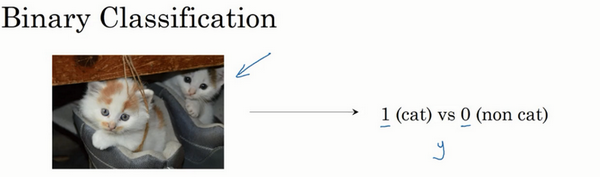
我们需要把像素值提取出来放到特征向量中x中,用nx或者n表示特征向量维度,在所有的二分类问题中,我们的目标是习得一个分类器,它以图片的特征向量作为1输入,然后预测y结果是1还是0

在python中表示的是X.shape =(nx,m)和Y.shape=(1,m)
2.logistic回归
y^(预测结果)=wT(逻辑回归的参数,特征权重,维度与x一致)x+b(实数,表示偏差)即y^=wTx+b,这是一个线性回归得到的线性函数,由于y只能取1或者0,而wTx+b不能保证这一点,所以应该等于wTx+b作为自变量的sigmoid函数,即y^=σ(wTx+b)以此将线性转为非线性

下图是sigmoid函数的图像,如果我把水平轴作为 z zz 轴,那么关于 z zz 的sigmoid函数是这样的,它是平滑地从0走向1,让我在这里标记纵轴,这是0,曲线与纵轴相交的截距是0.5,这就是关于的sigmoid函数的图像。
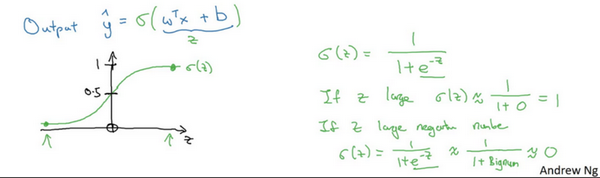
3.logistic回归损失函数
为什么需要损失函数:通过训练迭代来得到参数w和b

上标(i)指明数据表示x或者y的第i个训练样本
损失函数又叫误差函数,用来衡量输出值和实际值有多接近,Loss function:L(y^,y)
和平方误差损失函数一个效果,如果y等于1,就要让y^尽可能变大,反之。。
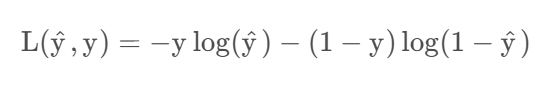
以上是单个样本定义的损失函数,需要一个整体训练集的损失函数(整体训练集的损失函数称为代价函数):
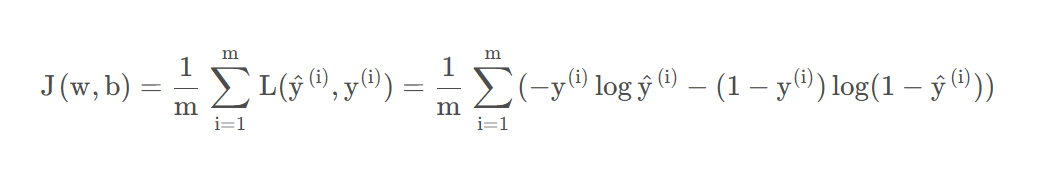
损失函数或者代价函数的目的是:衡量模型的预测能力的好坏。两者区别在于前者是定义在单个训练样本上的,后者是整个训练集
4.梯度下降法
梯度下降法的作用是:在测试集上通过最小化损失函数J(w,b)来训练参数w和b
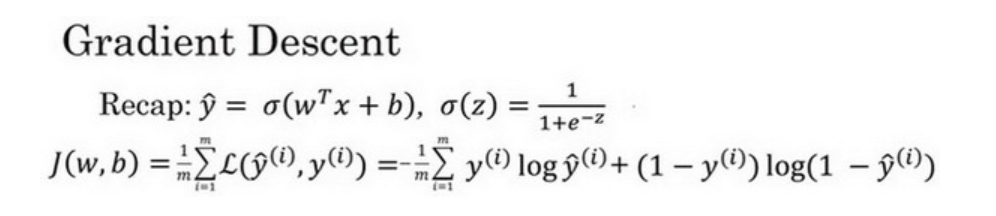
形象化说明:
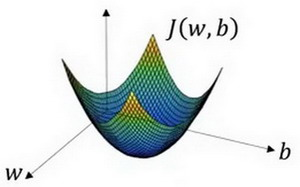
J(w,b)是水平轴w和b上的曲面,使J(w,b)最小,找到对应的w和b
由于J(w,b)的特性,我们必须定义代价函数(成本函数) J ( w , b ) 为凸函数。
1.初始化 w和 b (可以随机初始化,因为无论在哪里初始化,凸函数应该能达到同一1.点或者大致相同的点)
2.朝最抖的下坡走,不断迭代
3.直到走到全局最优解或者接近全局最优解的地方
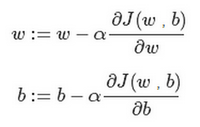

5.计算图及其导数计算
一个神经网络的计算,都是按照前向或反向传播过程组织的。首先我们计算出一个新的网络的输出(前向过程),紧接着进行一个反向传输操作。后者我们用来计算出对应的梯度或导数。计算图解释了为什么我们用这种方式组织这些计算过程
计算图组织计算的形式是用从左到右的计算
在反向传播算法中的术语,我们看到,如果你想计算最后输出变量的导数,使用你最关心的变量对的导数,那么我们就做完了一步反向传播,在这个流程图中是一个反向步骤。
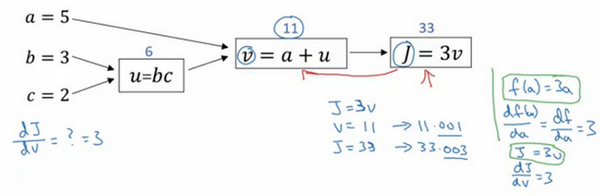
再看一个例子:将变量a变为5.001,通过啊的变化,j会变化为33.003,增加了0.003,所以 J 的增量是3乘以 a 的增量,意味着这个导数是3。
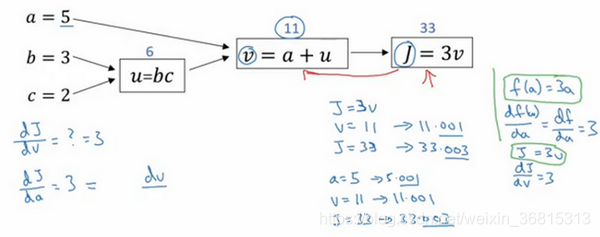
链式法则:a的增加引起v增加,v的增加又会引起j的增加,J 的变化量就是当你改变 a aa 时,v 的变化量乘以改变 v 时 J 的变化量,在微积分里这叫链式法则

现在我想介绍一个新的符号约定,当你编程实现反向传播时,通常会有一个最终输出值是你要关心的,最终的输出变量,你真正想要关心或者说优化的。在这种情况下最终的输出变量是 J ,就是流程图里最后一个符号,所以有很多计算尝试计算输出变量的导数,所以输出变量对某个变量的导数,我们就用dvar 命名,如dj_dvar
下面是其他变量的导数:
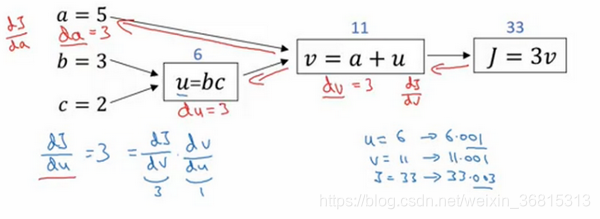
程序中,dx表示为
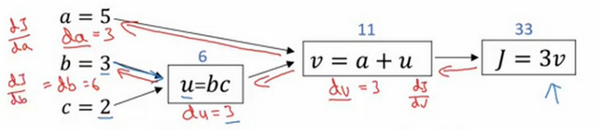
所以这是一个计算流程图,就是正向或者说从左到右的计算来计算成本函数 J JJ ,你可能需要优化的函数,然后反向从右到左计算导数
6.logistic回归的梯度下降法
为了计算z,输入参数w1,w2,b以及x1,x2
逻辑回归:,其中,
,
损失函数:
代价函数:
若只考虑单个样本,其代价函数:,其中a是逻辑回归的输出,y是样本的标签值
在梯度下降法中,w和b的修正量可以表达如下:
为了使得逻辑回归中最小化代价函数 L ( a , y ) L(a,y)L(a,y) ,我们需要做的仅仅是修改参数 w ww 和 b bb 的值。前面我们已经讲解了如何在单个训练样本上计算代价函数的前向步骤。现在让我们来讨论通过反向计算出导数
通过链式法则可知:
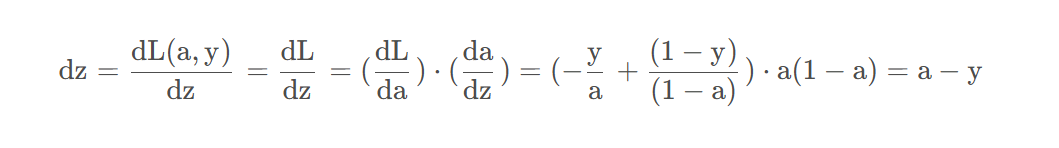

通过计算图的知识点,我们需要做的就是如下事情:
dz=(a-y)计算dz,dw1=x1*dz1计算dw1,更新,同理w2
db=dz计算db,更新
7.m个样本的梯度下降
带有求和的全局代价函数,实际上是1到 m 项各个损失的平均。 所以它表明全局代价函数对 w1的微分,对w1的微分也同样是各项损失对w1微分的平均。
代码与初始化:
J=0;dw1=0;dw2=0;db=0;
for i = 1 to mz(i) = wx(i)+b;a(i) = sigmoid(z(i));J += -[y(i)log(a(i))+(1-y(i))log(1-a(i));dz(i) = a(i)-y(i);dw1 += x1(i)dz(i);dw2 += x2(i)dz(i);db += dz(i);
J/= m;
dw1/= m;
dw2/= m;
db/= m;
w=w-alpha*dw
b=b-alpha*db
如果有多个特征w1,w2....wn,需要再加一个循环
8.向量化
因为深度学习算法处理大数据集效果很好,所以你的代码运行速度非常重要,否则如果在大数据集上,你的代码可能花费很长时间去运行,你将要等待非常长的时间去得到结果。所以在深度学习领域,运行向量化是一个关键的技巧。
向量化实现将会非常直接计算代码如下:z=np.dot(w,x)+b
import numpy as np #导入numpy库
a = np.array([1,2,3,4]) #创建一个数据a
print(a)
# [1 2 3 4]
import time #导入时间库
a = np.random.rand(1000000)
b = np.random.rand(1000000) #通过round随机得到两个一百万维度的数组
tic = time.time() #现在测量一下当前时间
#向量化的版本
c = np.dot(a,b)
toc = time.time()
print(“Vectorized version:” + str(1000*(toc-tic)) +”ms”) #打印一下向量化的版本的时间
#继续增加非向量化的版本
c = 0
tic = time.time()
for i in range(1000000):c += a[i]*b[i]
toc = time.time()
print(c)
print(“For loop:” + str(1000*(toc-tic)) + “ms”)#打印for循环的版本的时间
为了计算 +[bb ⋯ b],numpy命令是Z=np.dot(w.T,x)+b。这里在Python中有一个巧妙的地方,这里 b 是一个实数,或者你可以说是一个1*1矩阵,只是一个普通的实数。但是当你将这个向量加上这个实数时,Python自动把这个实数b 扩展成一个1∗m 的行向量。所以这种情况下的操作似乎有点不可思议,它在Python中被称作广播
不需要for循环,利用m 个训练样本一次性计算出小写 z 和小写 a ,用一行代码即可完成。
Z = np.dot(w.T,X) + b
这一行代码:A = [ a ( 1 ) , a ( 2 ) , ⋯ , a ( m ) ] = σ ( Z ),通过恰当地运用 σ 一次性计算所有a 。这就是在同一时间内你如何完成一个所有m 个训练样本的前向传播向量化计算。
如何同时计算 m mm 个数据的梯度,并且实现一个非常高效的逻辑回归算法:
通过dz=a-y的原理实现计算dZ=A−Y=[a(1)−y(1),a(2)−y(2),⋯,a(m)−y(m)]
db=m1∗np.sum(dZ)代替循环
A.sum(axis = 0)中的参数axis。axis用来指明将要进行的运算是沿着哪个轴执行,在numpy中,0轴是垂直的,也就是列,而1轴是水平的,也就是行。
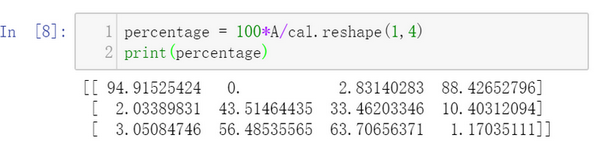
而第二个A/cal.reshape(1,4)指令则调用了numpy中的广播机制。这里使用3∗4 的矩阵 A 除以 1∗4 的矩阵 cal 。技术上来讲,其实并不需要再将矩阵cal reshape(重塑)成 1∗4 ,因为矩阵 cal 本身已经是1∗4 了。但是当我们写代码时不确定矩阵维度的时候,通常会对矩阵进行重塑来确保得到我们想要的列向量或行向量。重塑操作reshape是一个常量时间的操作,时间复杂度是O(1),它的调用代价极低。
3.浅层神经网络
习题3.12 总结-深度学习-Stanford吴恩达教授_对于隐藏单元,tanh激活通常比-CSDN博客
1.神经网络表示
我们首先关注一个例子,本例中的神经网络只包含一个隐藏层。这是一张神经网络的图片,让我们给此图的不同部分取一些名字。
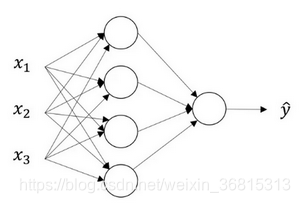
输入层:x1,x2,x3....
隐藏层:图中的四个节点,中间结点的准确值我们是不知道到的,也就是说你看不见它们在训练集中应具有的值。你能看见输入的值,你也能看见输出的值,但是隐藏层中的东西,在训练集中你是无法看到的
输出层:只有一个节点的层,负责产生预测值
这里用表示输入层,
表示隐藏层,隐藏层中的节点用
表示(n是第n个的意思),
表示输出层
上述表示方法的原因是当我们计算网络的层数时,输入层是不算入总层数内,所以隐藏层是第一层,输出层是第二层。第二个惯例是我们将输入层称为第零层,所以在技术上,这仍然是一个三层的神经网络,因为这里有输入层、隐藏层,还有输出层。但是在传统的符号使用中,如果你阅读研究论文或者在这门课中,你会看到人们将这个神经网络称为一个两层的神经网络,因为我们不将输入层看作一个标准的层。
最后,我们要看到的隐藏层以及最后的输出层是带有参数的,这里的隐藏层将拥有两个参数W和b ,我将给它们加上上标 和
,表示这些参数是和第一层这个隐藏层有关系的。之后在这个例子中我们会看到 W 是一个4x3的矩阵,而 b 是一个4x1的向量,第一个数字4源自于我们有四个结点或隐藏层单元,然后数字3源自于这里有三个输入特征,输出层同理
,从维数上来看,它们的规模分别是1x4以及1x1。1x4是因为隐藏层有四个隐藏层单元而输出层只有一个单元。
不管在哪一层,权重W的形状是(输出维度,输入维度),偏置b的形状与输出维度一致,即(输出维度,1)
2.计算神经网络输出
逻辑回归的计算有两个步骤,首先你按步骤计算出z ,然后在第二步中你以sigmoid函数为激活函数计算z得出a ,一个神经网络只是这样子做了好多次重复计算。
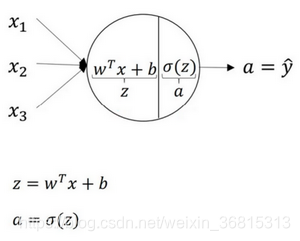
向量化后有:,
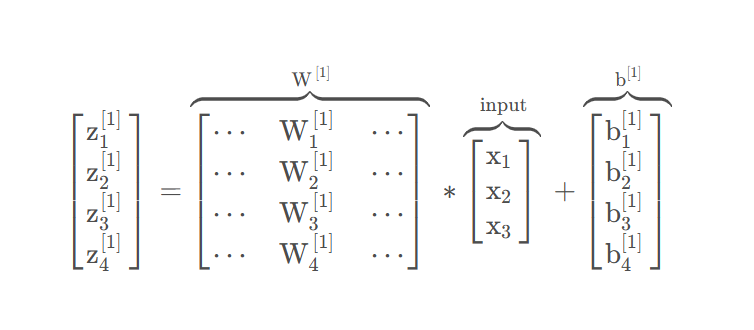 第n层的输入为
第n层的输入为,输出为
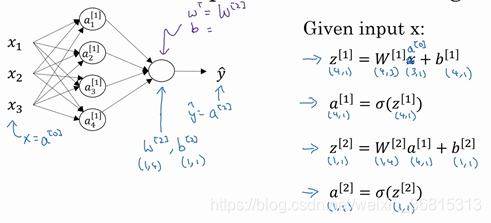
3.多个例子中的向量化
规定,(i)是第i个训练样本,[2]是第二层

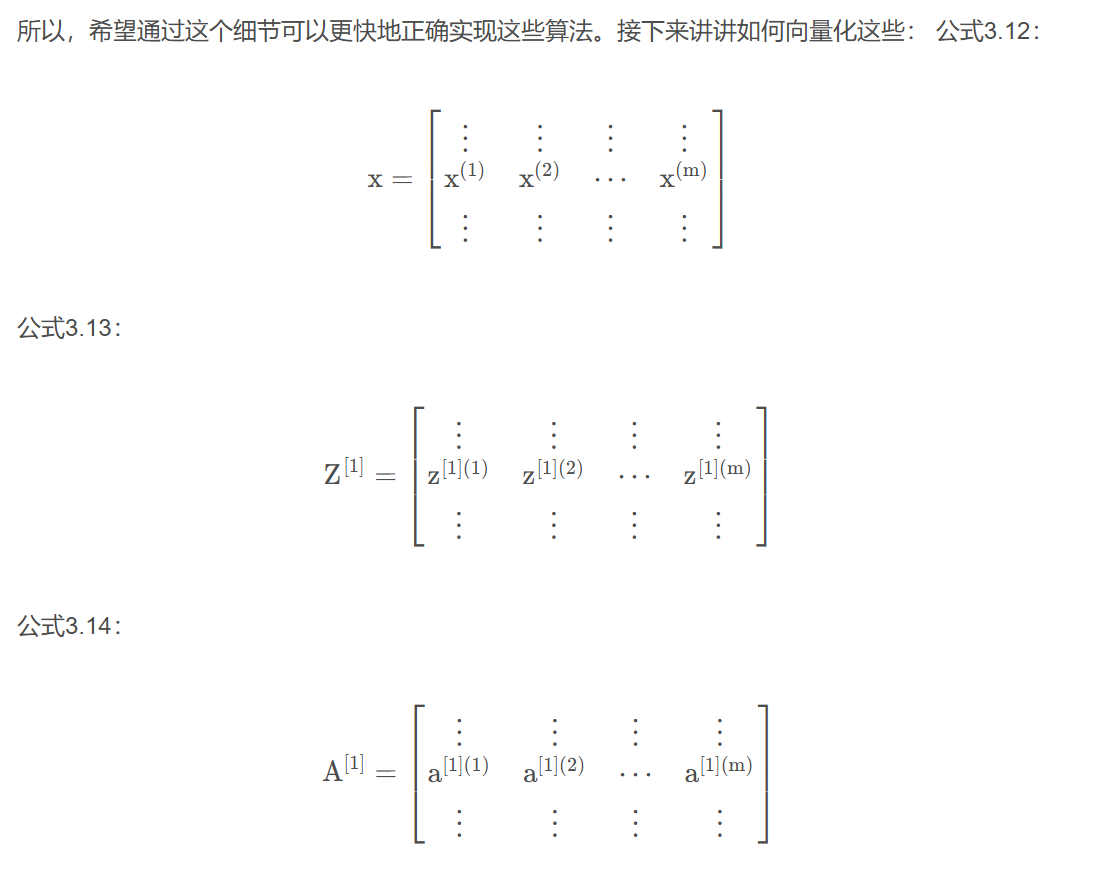
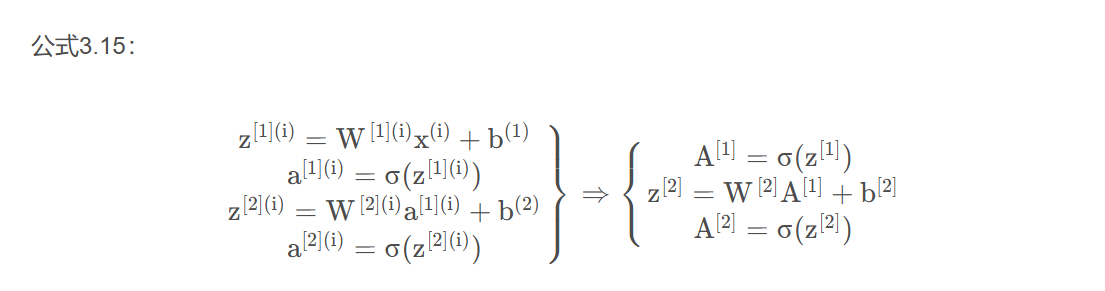
即第n层的输入为,输出为
4.激活函数
使用一个神经网络时,需要决定使用哪种激活函数用隐藏层上,哪种用在输出节点上。到目前为止只用过sigmoid激活函数,但是,有时其他的激活函数效果会更好
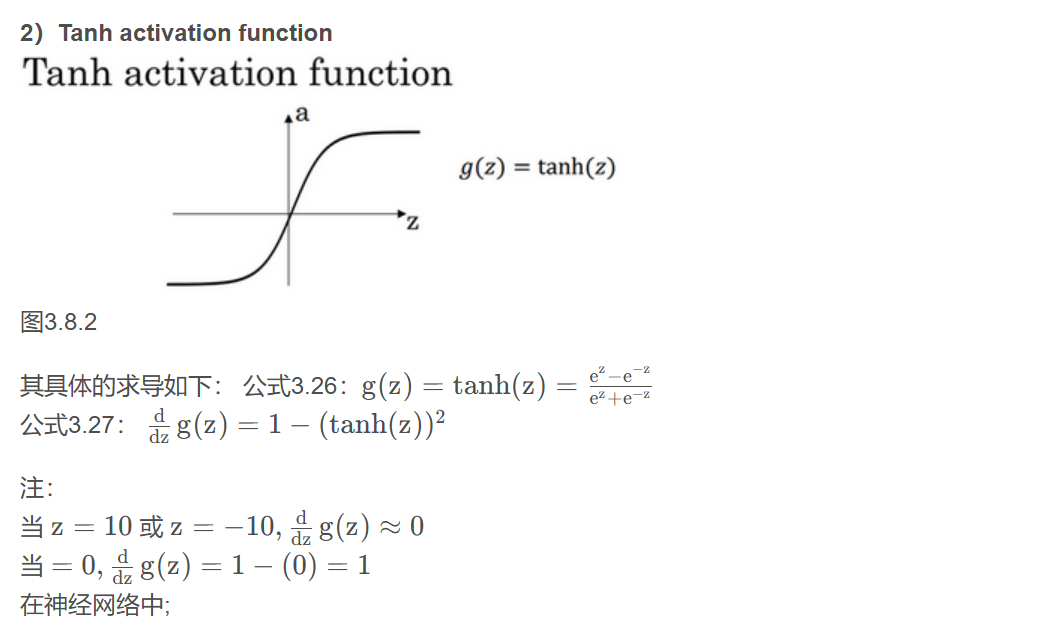
在讨论优化算法时,有一点要说明:基本已经不用sigmoid激活函数了,tanh函数在所有场合都优于sigmoid函数。(二分类由于1需要让输出层在0-1间还是采用sigmoid函数)
选择激活函数的经验法则:
如果输出是0、1值(二分类问题),则输出层选择sigmoid函数,然后其它的所有单元都选择Relu函数(z正值时输出恒等于1,其他为0)。
这是很多激活函数的默认选择,如果在隐藏层上不确定使用哪个激活函数,那么通常会使用Relu激活函数。有时,也会使用tanh激活函数,但Relu的一个优点是:当z是负值的时候,导数等于0。
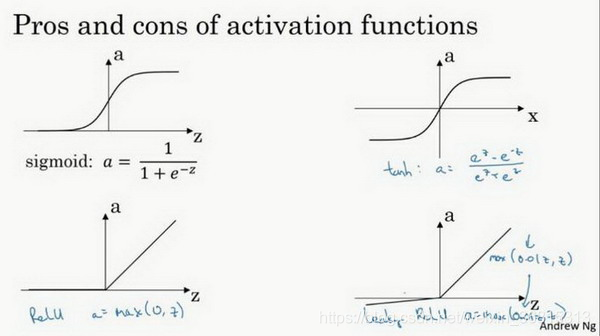
快速概括一下不同激活函数的过程和结论:
sigmoid激活函数:除了输出层是一个二分类问题基本不会用它。
tanh激活函数:tanh是非常优秀的,几乎适合所有场合。
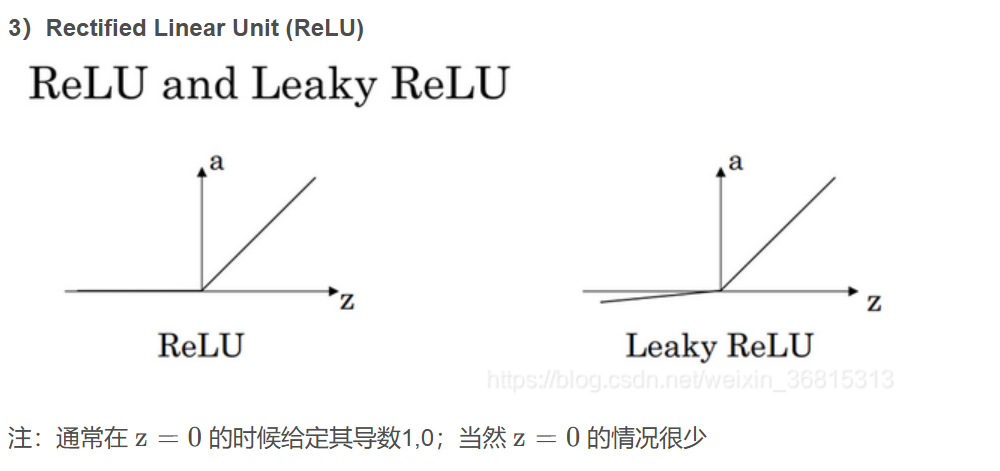
ReLu激活函数:最常用的默认函数,如果不确定用哪个激活函数,就使用ReLu或者Leaky ReLu。a=max(0.01z,z) 为什么常数是0.01?当然,可以为学习算法选择不同的参数。
5.为什么需要非线性激活函数
如果你是用线性激活函数或者叫恒等激励函数,那么神经网络只是把输入线性组合再输出(可自行推导)
不能在隐藏层用线性激活函数,可以用ReLU或者tanh或者leaky ReLU或者其他的非线性激活函数,唯一可以用线性激活函数的通常就是输出层
6.激活函数的导数
针对以下四种激活,求其导数如下:


7.神经网络的梯度下降法
训练参数需要做梯度下降,在训练神经网络的时候,随机初始化参数很重要,而不是初始化成全零。当你参数初始化成某些值后,每次梯度下降都会循环计算以下预测值:,(i=1,2,3,...,m)
其实就是把之前的公式带到每一层里面去


上述是反向传播的步骤,注:这些都是针对所有样本进行过向量化,Y 是 1∗m 的矩阵;这里np.sum是python的numpy命令,axis=1表示水平相加求和,keepdims是防止python输出那些古怪的秩数(n,) ,加上这个确保矩阵 这个向量输出的维度为(n,1)这样的标准形式
目前为止,我们计算的都和Logistic回归十分相似,但当你开始计算反向传播时,你需要计算,是隐藏层函数的导数
8.随机初始化
当你训练神经网络时,权重随机初始化是很重要的。对于逻辑回归,把权重初始化为0当然也是可以的。但是对于一个神经网络,如果你把权重或者参数都初始化为0,那么梯度下降将不会起作用
如果你把权重都初始化为0,那么由于隐含单元开始计算同一个函数,所有的隐含单元就会对输出单元有同样的影响。一次迭代后同样的表达式结果仍然是相同的,即隐含单元仍是对称的。通过推导,两次、三次、无论多少次迭代,不管你训练网络多长时间,隐含单元仍然计算的是同样的函数。因此这种情况下超过1个隐含单元也没什么意义,因为他们计算同样的东西。

你也许会疑惑,这个常数从哪里来,为什么是0.01,而不是100或者1000。我们通常倾向于初始化为很小的随机数。因为如果你用tanh或者sigmoid激活函数,或者说只在输出层有一个Sigmoid,如果(数值)波动太大,当你计算激活值时
如果W 很大,z 就会很大或者很小,因此这种情况下你很可能停在tanh/sigmoid函数的平坦的地方,这些地方梯度很小也就意味着梯度下降会很慢,因此学习也就很慢。
事实上有时有比0.01更好的常数,当你训练一个只有一层隐藏层的网络时(这是相对浅的神经网络,没有太多的隐藏层),设为0.01可能也可以。但当你训练一个非常非常深的神经网络,你可能要试试0.01以外的常数
4.深层神经网络
习题4.9 总结-深度学习第一课《神经网络与深度学习》-Stanford吴恩达教授_在前向传播期间,在层l的前向传播函数中,您需要知道层l中的激活函数(sigmoid,tanh,rel-CSDN博客
1.深层神经网络
区别于浅层,深层拥有更多的隐藏层,重要特征就是网络的层数多,因此能携带更大的数据,可以实现更复杂的数据关系映射。
记住当我们算神经网络的层数时,我们不算输入层,我们只算隐藏层和输出层。
2.深层的前向传播
向量化的过程可以写成:
3.核对矩阵的维度
W的维度是(下一层的维数,前一层的维数),即
b的维度是(下一层的维数,1),即
维度相同,
维度相同,且w和b向量化维度不变,但z,a以及x的维度会向量化后发生改变

在你做深度神经网络的反向传播时,一定要确认所有的矩阵维数是前后一致的,可以大大提高代码通过率
4.为什么使用深层表示
为什么需要这么多的隐藏层:较早的前几层学习一些低层次的简单特征,等到后面几层,就能把简单的特征结合起来,取探测更加复杂的东西
另外一个,关于神经网络为何有效的理论,来源于电路理论,它和你能够用电路元件计算哪些函数有着分不开的联系。根据不同的基本逻辑门,譬如与门、或门、非门。在非正式的情况下,这些函数都可以用相对较小,但很深的神经网络来计算,小在这里的意思是隐藏单元的数量相对比较小,但是如果你用浅一些的神经网络计算同样的函数,也就是说在我们不能用很多隐藏层时,你会需要成指数增长的单元数量才能达到同样的计算结果。
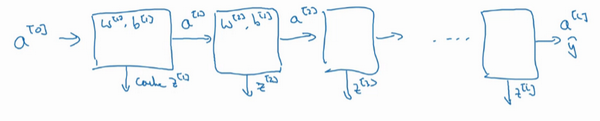
5.搭建深层神经网络块
如果实现了这两个函数(正向和反向),神经网络的计算过程会是这样的:
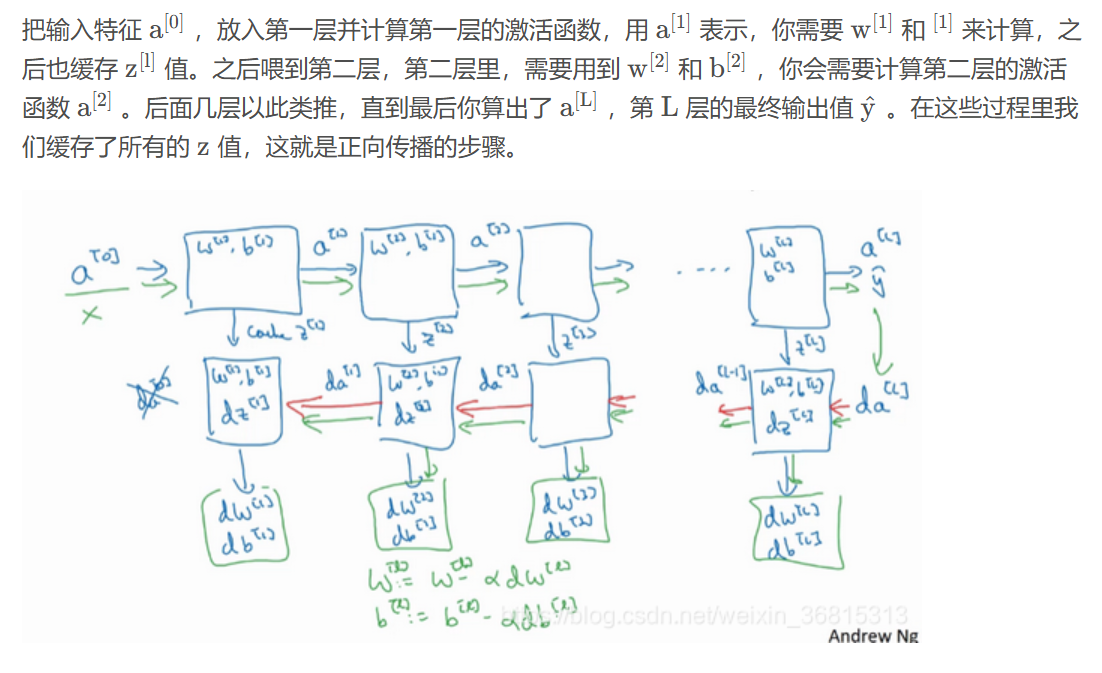

6.前向和反向传播
前向传播向量化的过程可以写成:
这里的Z又称为前向和反向传播的缓存
反向传播的步骤:输入为,输出为


7.参数和超参数
详解可见还搞不懂什么是参数,超参数吗?三分钟快速了解参数与超参数的概念和区别!!!-CSDN博客
想要你的深度神经网络起到很好的效果,需要好好地规划你的参数和超参数
参数一般是模型中可被学习和调整的参数,通常是通过训练集数据来自动学习的
超参数是在算法运行之前就设置好的,用于控制模型的行为和性能
如学习率,迭代次数,隐藏层数目,隐藏层单元数目,激活函数的选择。。。
寻找超参数的最优值:通过idea-code-experiment-idea循环,尝试各种不同的参数,实现模型并观察是否成功,然后再迭代。



】KNN算法与模型评估调优)




:Python 的函数——函数的参数)










