实验在RHEL7中做,因为9中缺少了一个关键的高可用组件
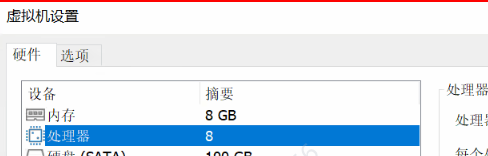
环境:两台数据库,内存和CPU要多一点
主流是MYSQL(开源),Oracle收费较贵
RHEL7中直接用make编译是有问题的,所以需要要gcc工具
做好前置准备:重新整理软件仓库,加入aliyun的地址源
用原来的数据源,可能仓库不够,下载不了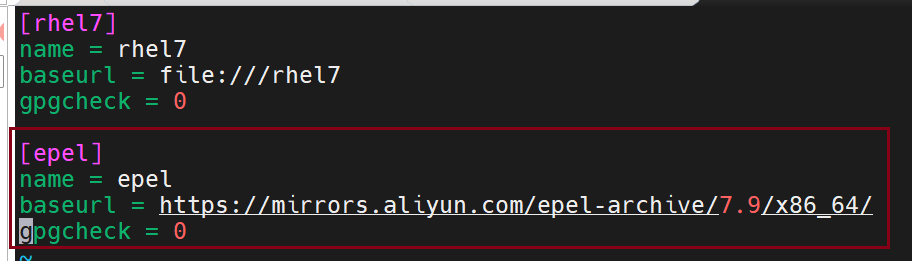
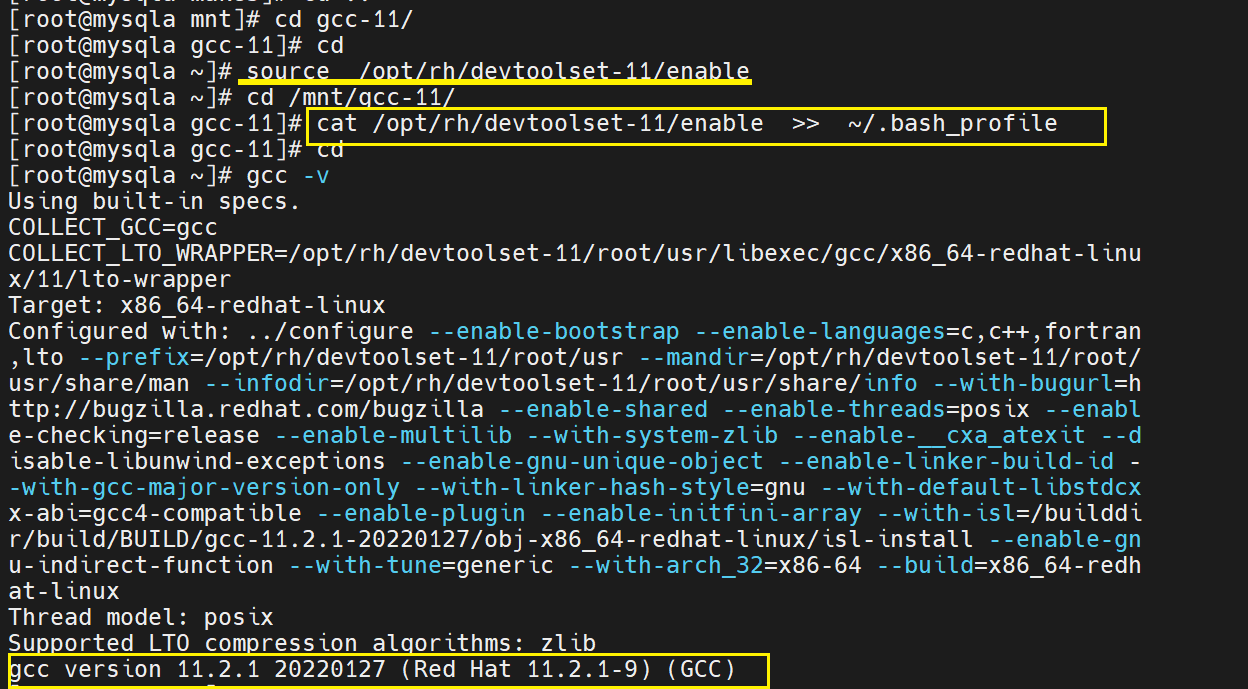
开始安装gcc
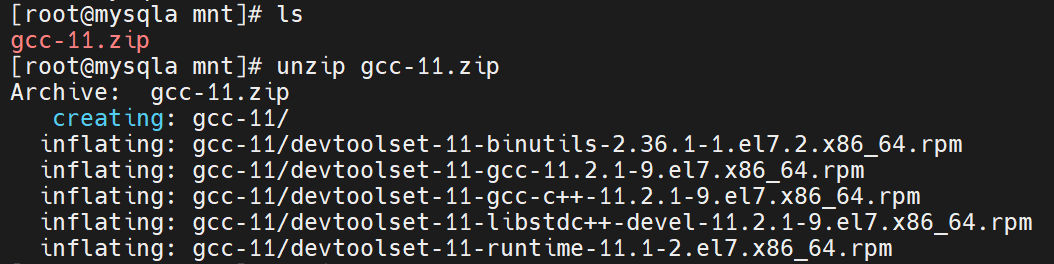
解压gcc.zip
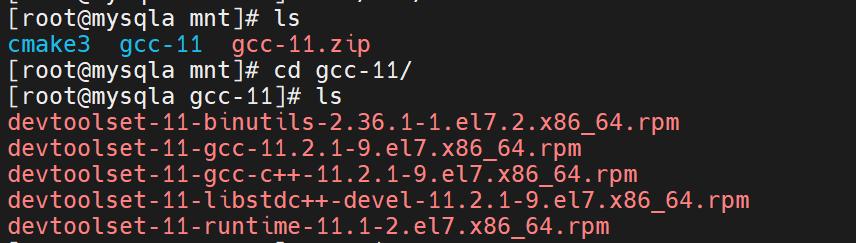
进入目录并检查内容是否齐全
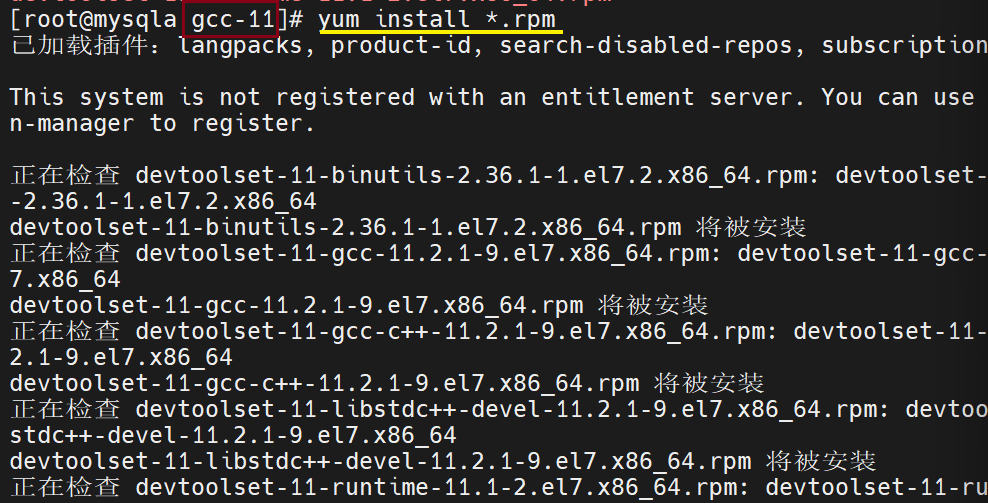
安装
检查版本
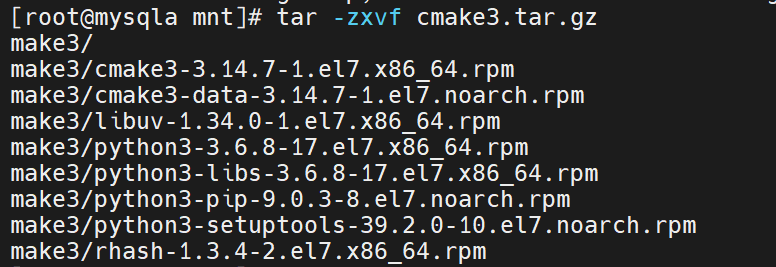
安装cmake3

解压缩安装包
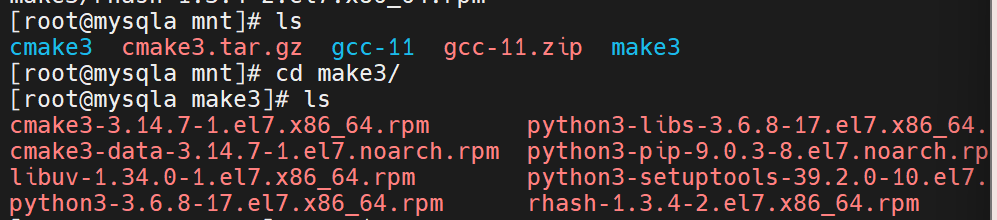
进入目录并查看
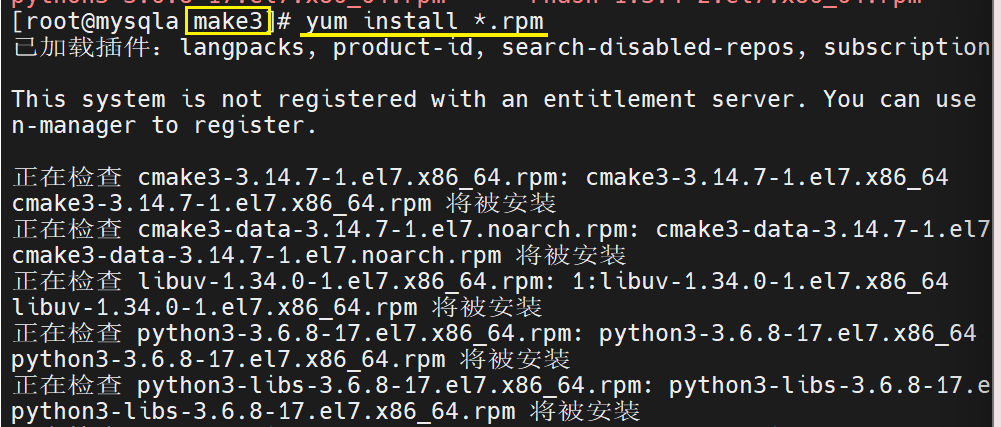

安装mysql
检查安装包是否完整

解压并查看
直接编译可能会污染当前目录,所以新建一个目录来存放编译后
开始编译
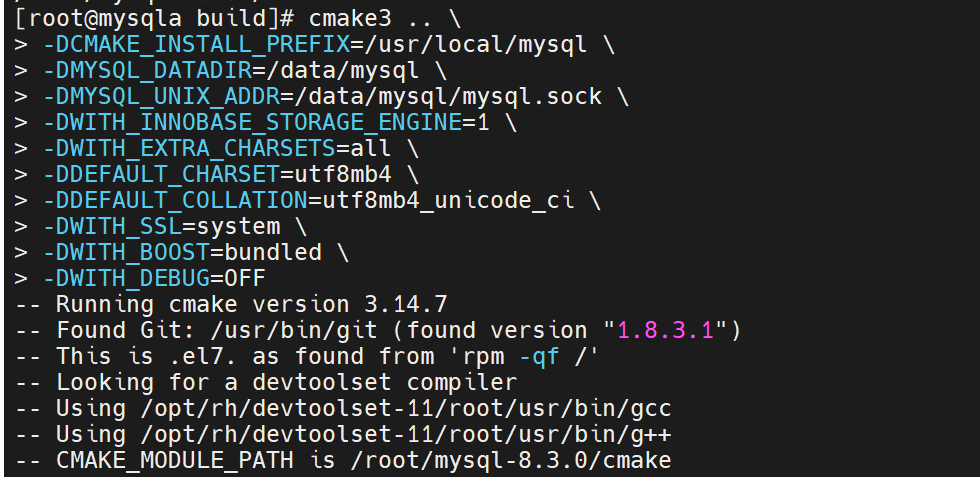
#源码编译参数详解 [root@mysql_node1 mysql-8.3.0]# mkdir build #建立编译目录 [root@mysql_node1 mysql-8.3.0]# cmake3 .. \ -DCMAKE_INSTALL_PREFIX=/usr/local/mysql \ #指定安装路径 -DMYSQL_DATADIR=/data/mysql \ #指定数据目录 -DMYSQL_UNIX_ADDR=/data/mysql/mysql.sock \ #指定套接字文件 -DWITH_INNOBASE_STORAGE_ENGINE=1 \ #指定启用INNODB存储引擎,默认用myisam -DWITH_EXTRA_CHARSETS=all \ #扩展字符集 -DDEFAULT_CHARSET=utf8mb4 \ #指定默认字符集 -DDEFAULT_COLLATION=utf8mb4_unicode_ci \ #指定默认校验字符集 -DWITH_SSL=system \ #指定MySQL 使用系统已安装的 SSL 库 -DWITH_BOOST=bundled \ #指定使用 MySQL 源码包中内置的Boost库 -DWITH_DEBUG=OFF #源码编译命令
[root@mysql_node1 build]# make -j2 #-j2 表示有几个核心就跑几个进程
之前为什么给比较大的运行内存和多核,就是在这里
如果运行内存小了,在编译过程中就会造成内存溢出,会导致失败
make -j4
运行之后等待完成就行
编译好了之后就别动了
重新下载,Mysql8.3并不能支持实验
前面都是一样的,下载需要的编译软件
gcc和cmake3
把mysql3.0的包移入,解压并make安装
mysql 3.0编译内容
cmake3 .. -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DMYSQL_DATADIR=/data/mysql -DMYSQL_UNIX_ADDR=/data/mysql/mysql.sock -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_EXTRA_CHARSETS=all -DDEFAULT_CHARSET=utf8mb4 -DDEFAULT_COLLATION=utf8mb4_unicode_ci -DWITH_SSL=system -DWITH_BOOST=/root/mysql-8.0.40/boost/boost_1_77_0/ -DWITH_DEBUG=OFF
新的主机双核cpu,4G内存就够用
后面的步骤都一样,等待安装完毕就行
网页下载mysql3.0的安装包的方法

编译过程决定安装路径
make && make install

编译之后会自动生成目录的


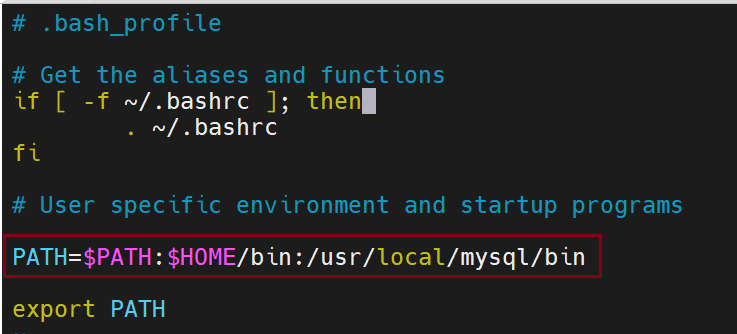
岁让此时有了bin目录,但是启动时还是不生效的,因为没有加入环境变量

![]()

编译时要求了存放数据的目录和用户,但是实际上是没有创建的

并且此时MySQL目录是由读和看的权限,没有执行权限

并且要使用,还要有初始化数据
复制启动脚本,但是无法启动,因为还没有初始化数据
![]()
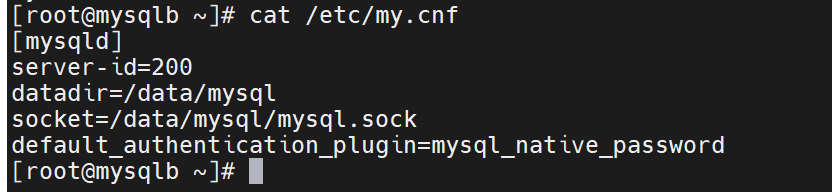
[mysqld]
server-id=10
datadir=/data/mysql
socket=/data/mysql/mysql.sock
default_authentication_plugin=mysql_native_password
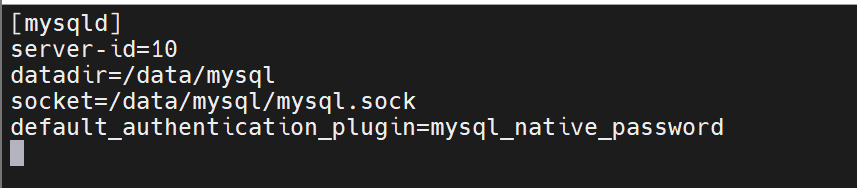 修改数据目录
修改数据目录
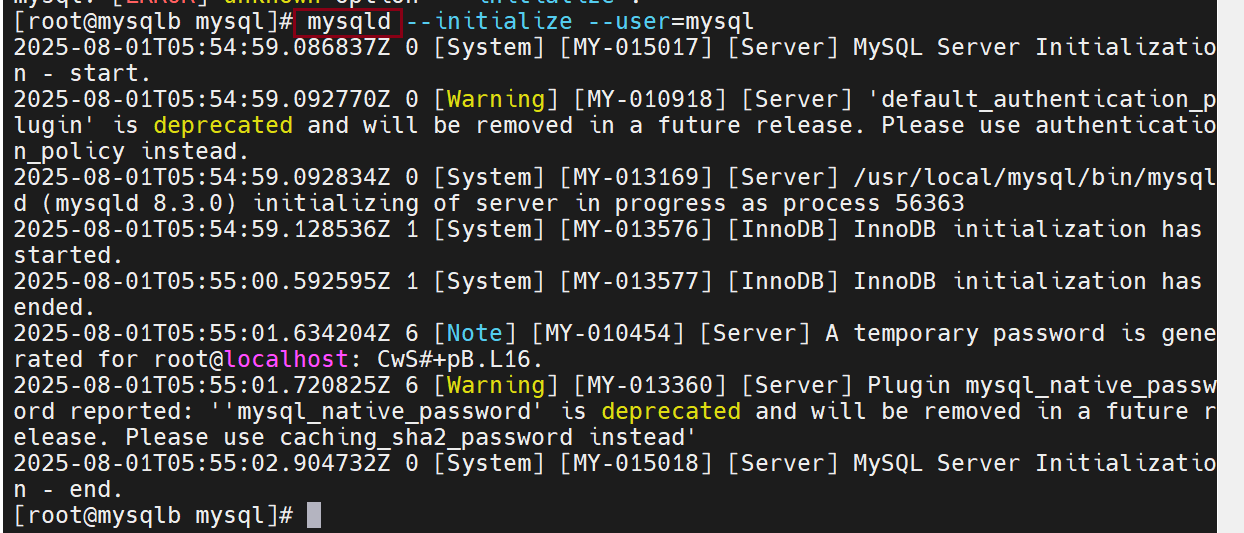
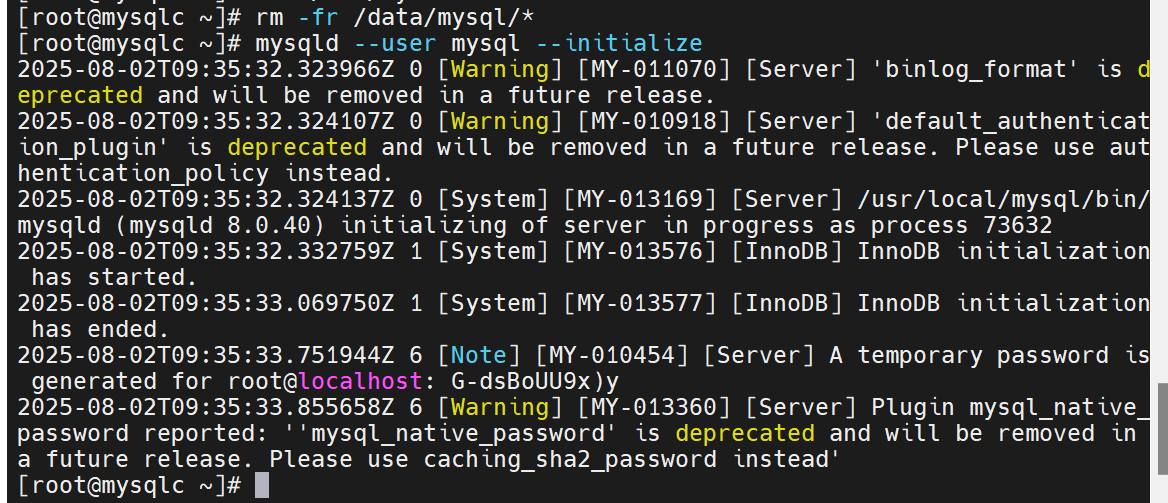
做初始化
初始化完成后会有一个初始密码,千万别忘记了

列出系统中那些系统是启动的
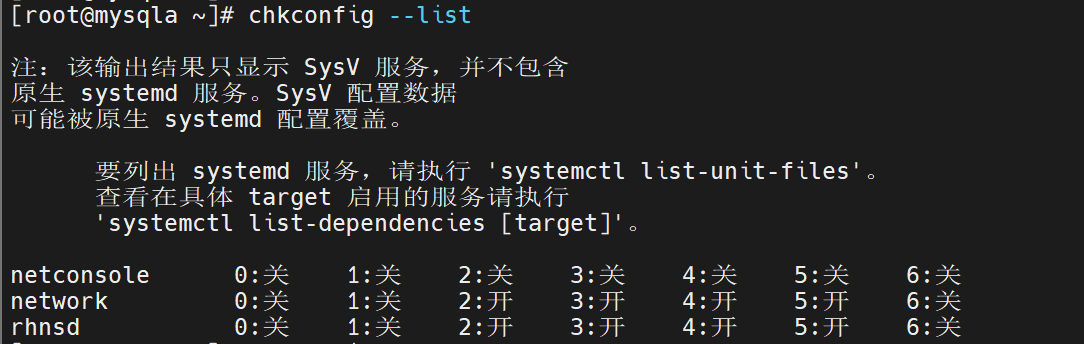
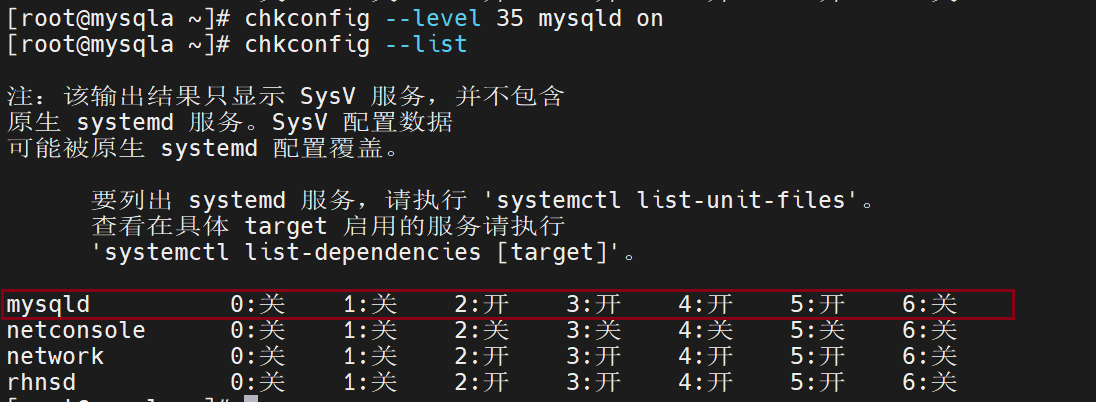
做数据库的开启启动

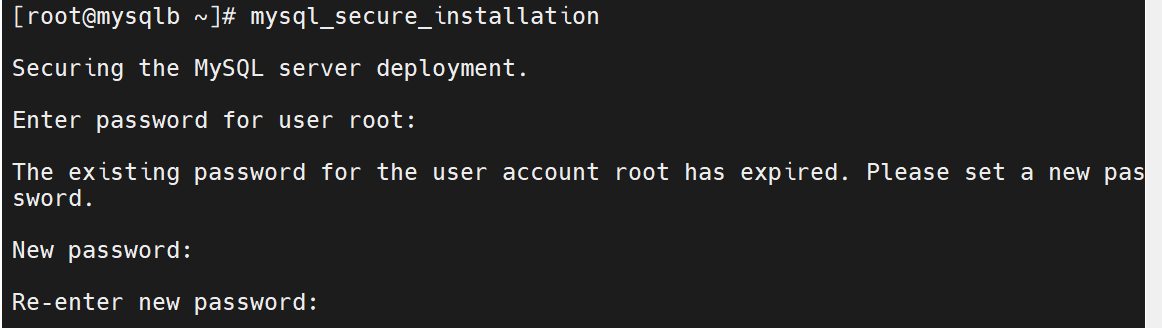
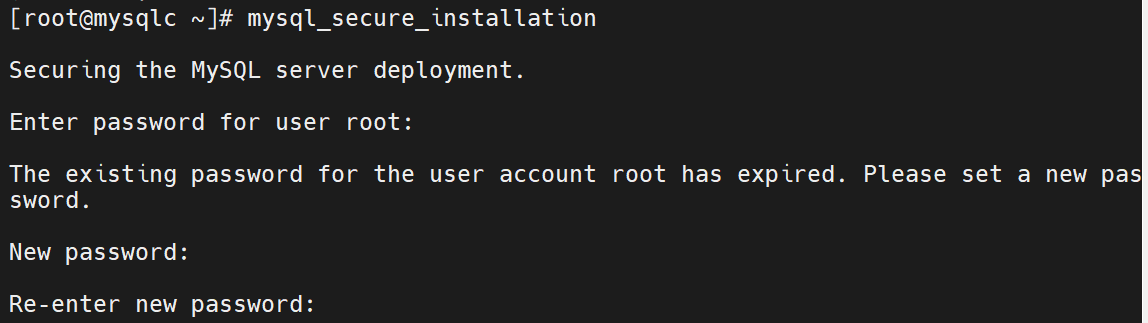
直接登录什么也做不了,要先做安全初始化
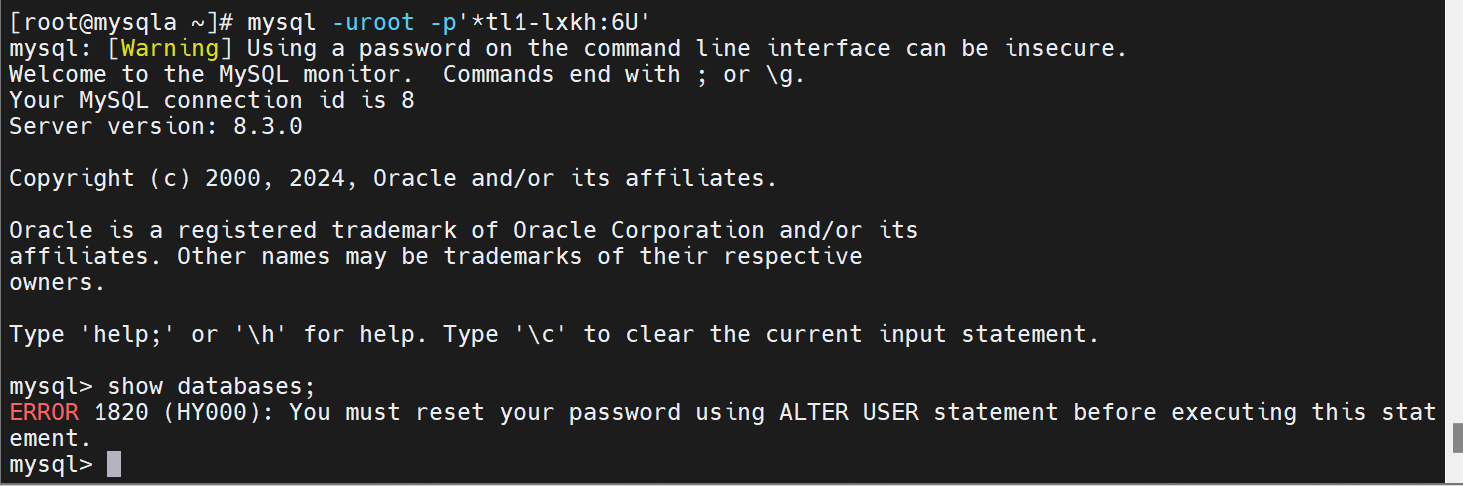
重新输入密码
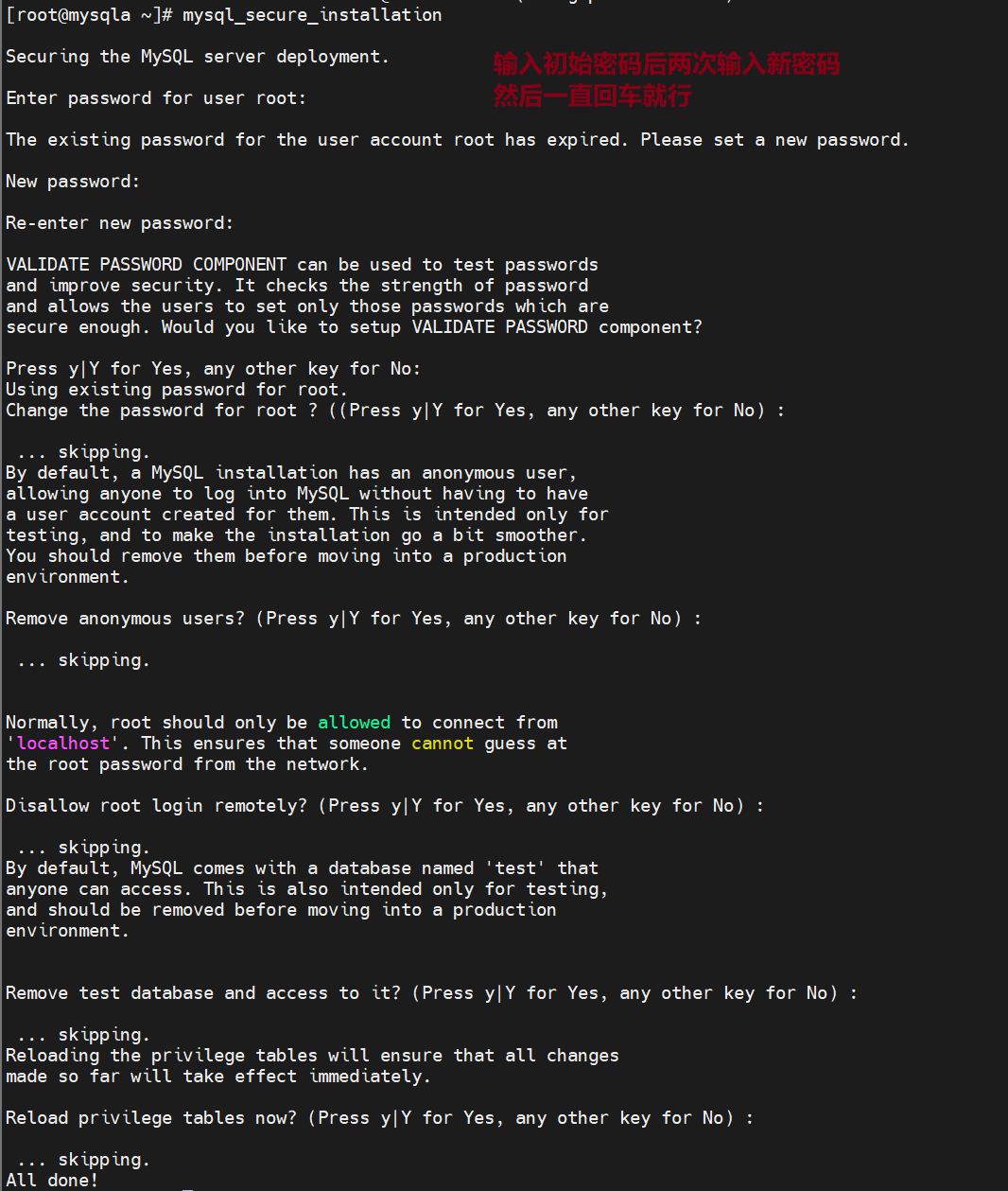
一路回车
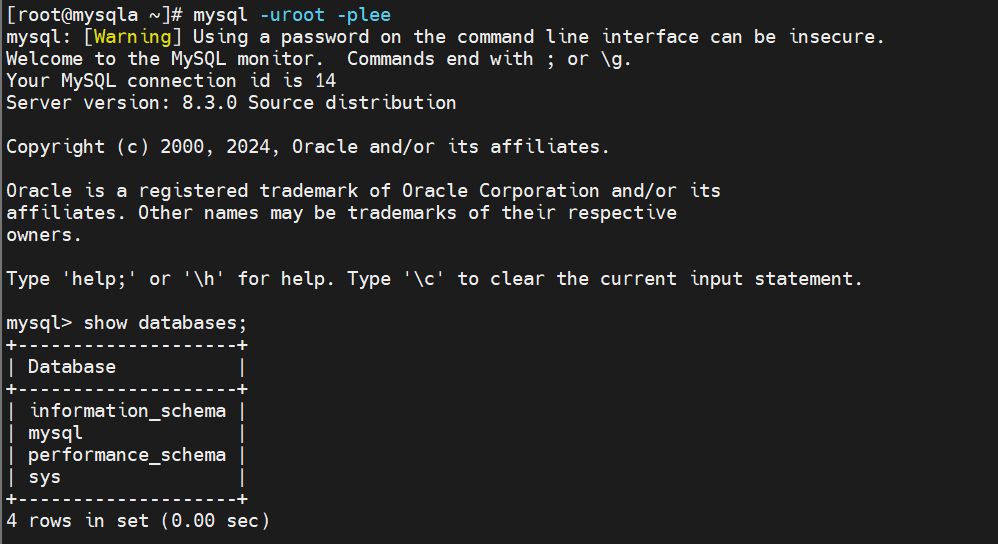
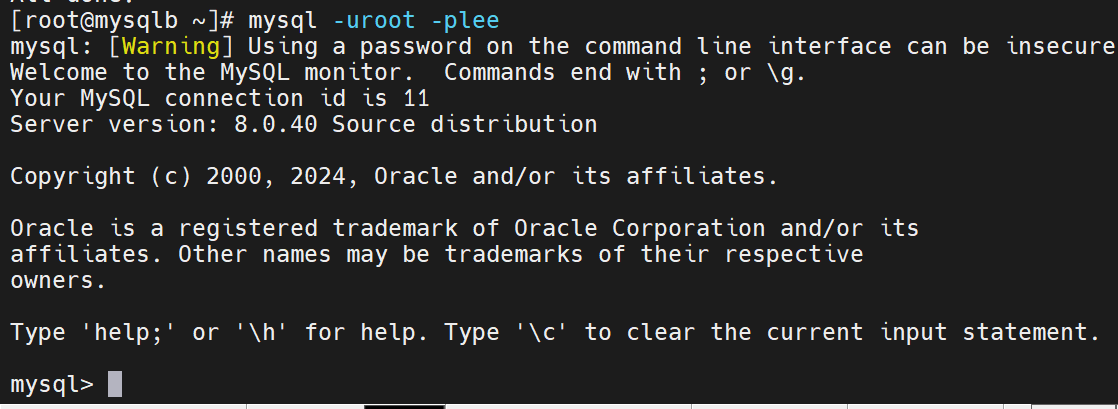
现在就可以正常使用了
要重新删除下载的话,要先停止服务,再次删除
(第一台从数据库)mysqlb上的操作

关闭rhel7的图形
重启之后就关闭图形,直接用终端了

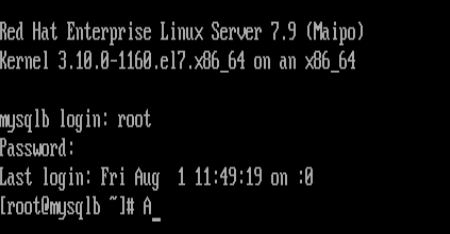
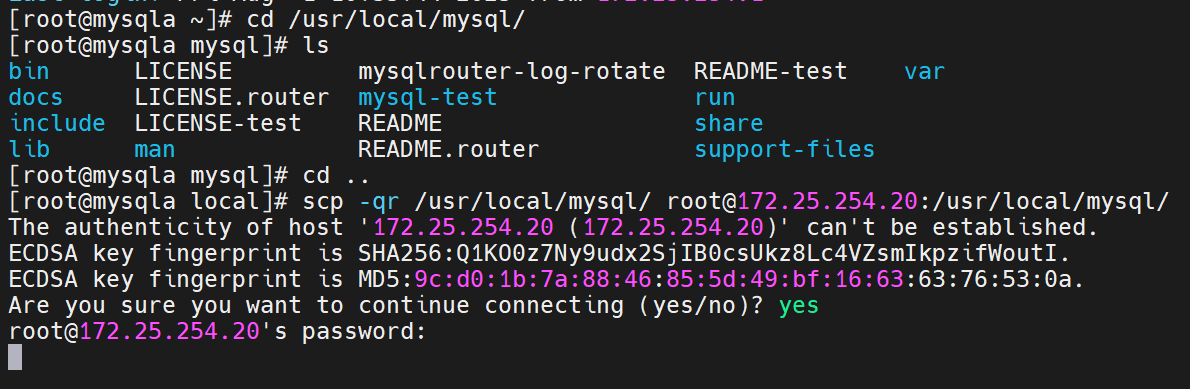
可以直接从mysqla中直接复制到mysqlb上
拷贝完整目录


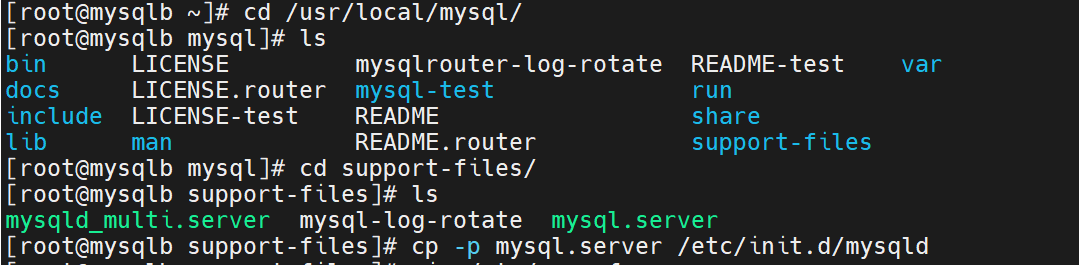
复制启动文件
![]()

![]()
![]()
![]()
初始化,默认认证
启动mysql

修改数据库初始密码
![]()
MYSQL主从复制
数据很重要,有备份才无患
查看官方文档来学习主从复制
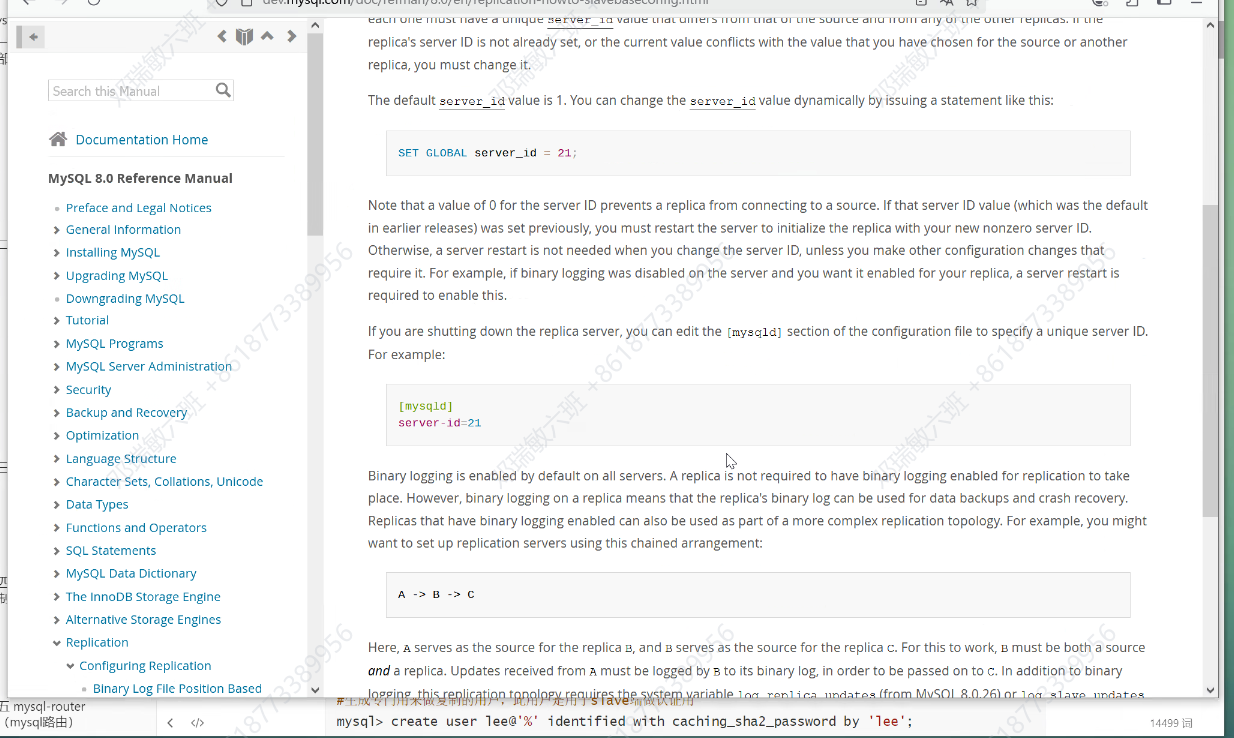
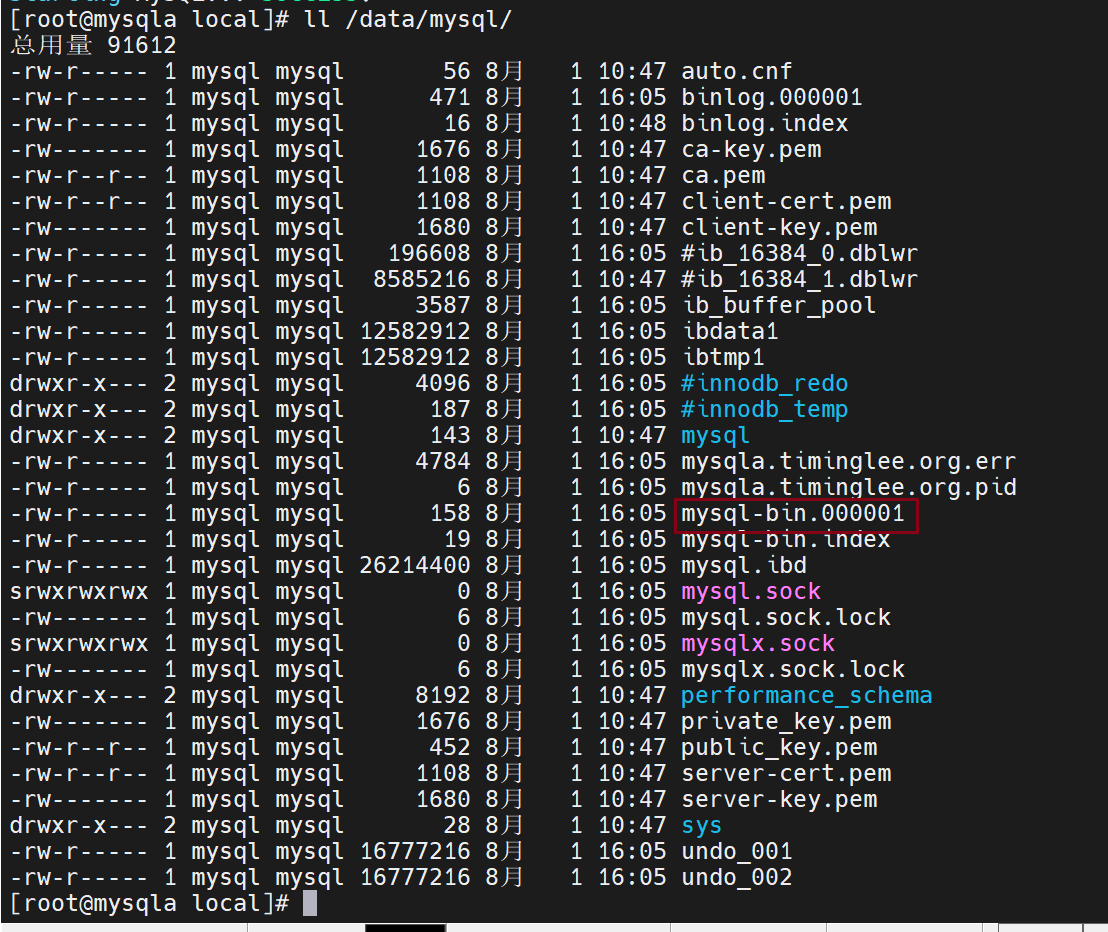
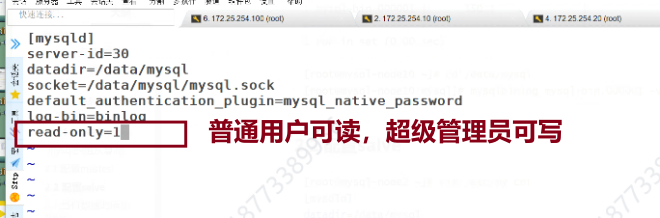
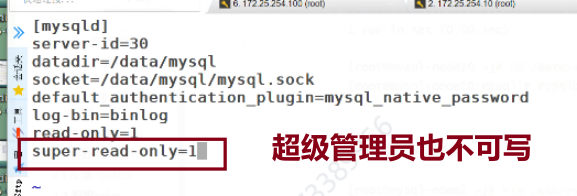
默认二进制日志是没有打开的,要在配置文件里修改,现在打开后会修改前缀
在主数据库上
![]()
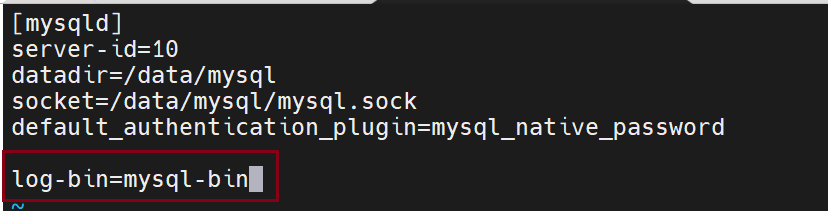

在从数据库上
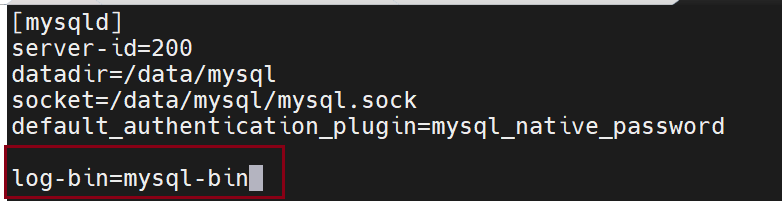
记得重启服务

此时查看日志前缀,改完之后就会从默认前缀变成mysql-bin
先做主数据库
在数据库中查看用户
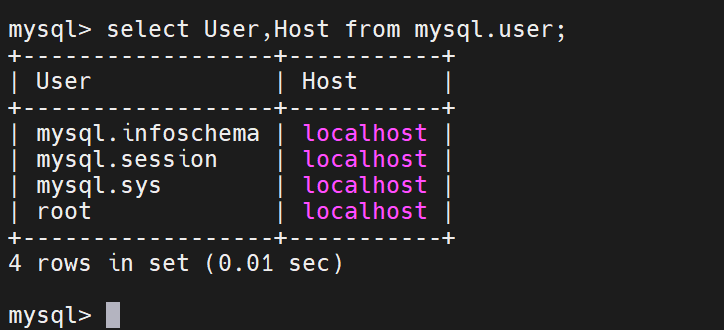
用root来做并不好
我们需要新增一个用户



新增用户后一定要授权,刚刚新增的用户是谁就给谁授权
查看授权信息
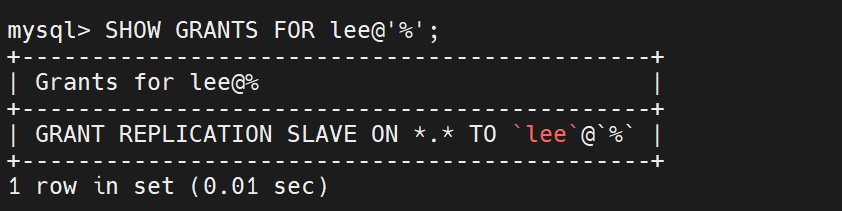
查看日志情况(后面从数据库认证要用到)
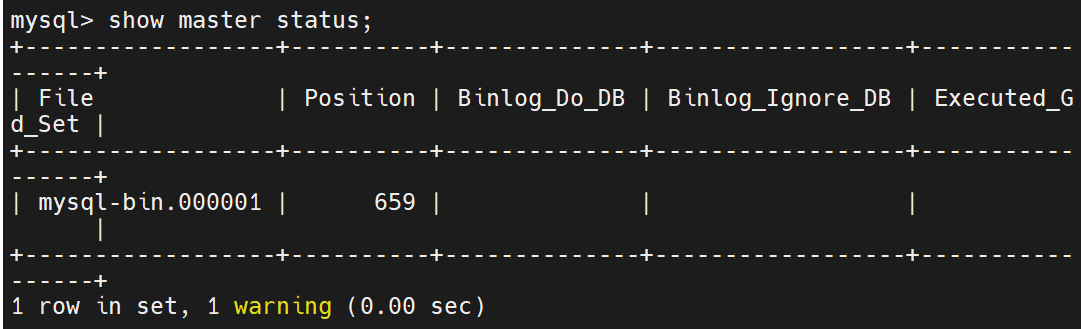
在生产环境中,要做主从复制,先要把数据从主中拉取出来给从,让他们现在数据相同
但是现在是实验,没有数据在其中
从数据库
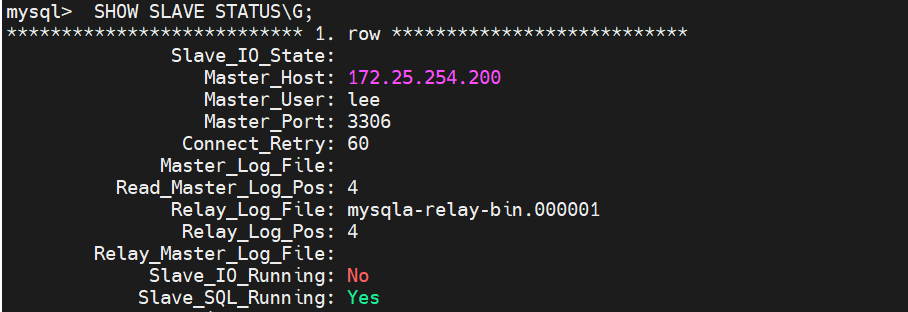
要把mastaer制定到哪里,用户ip,用户名,用户密码,日志文件名,日志id(这些都要和主数据库一样)

如果写错了,可以刷掉之前写的

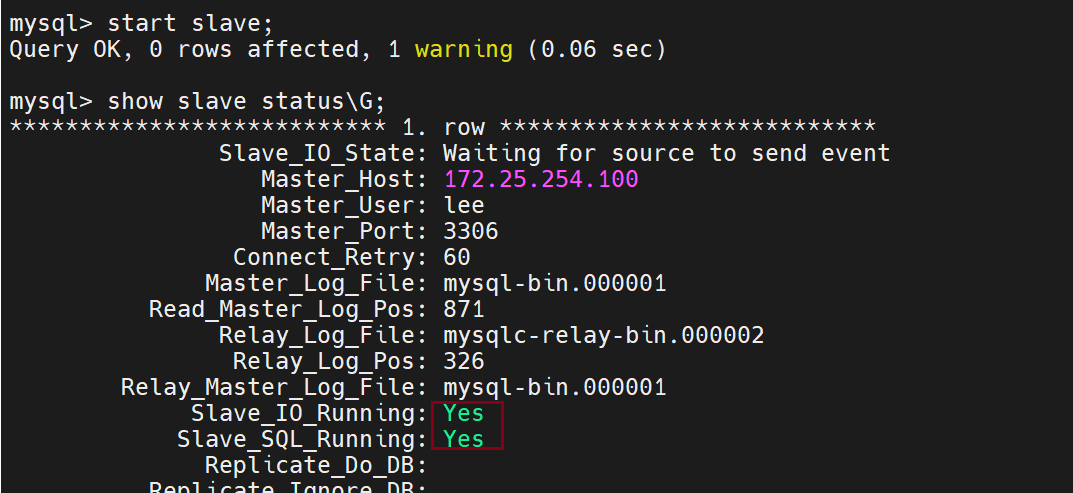
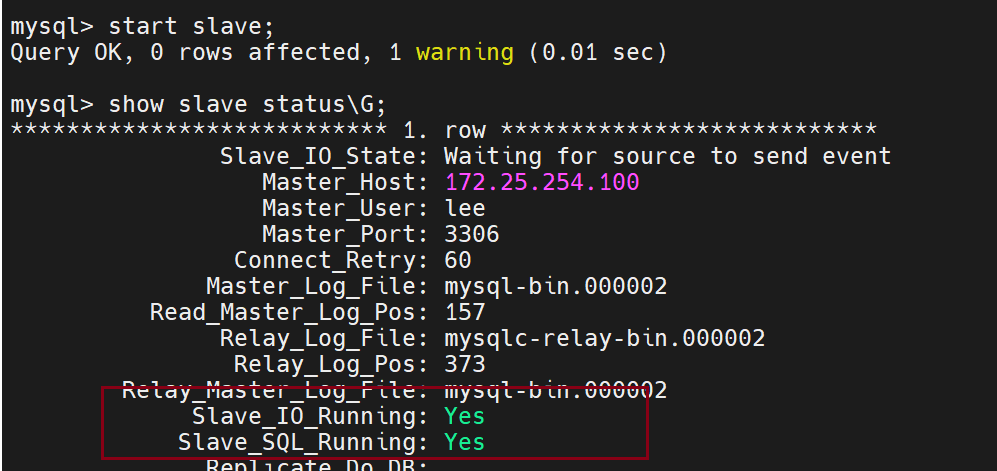
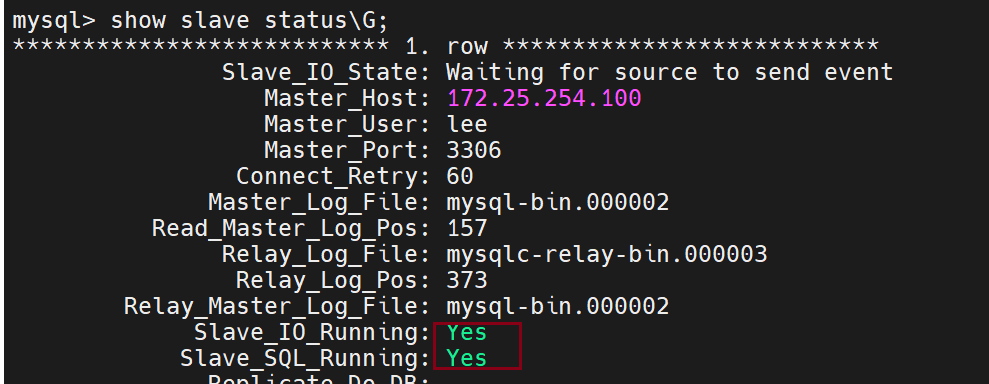
打开服务的命令

查看是否开启的命令

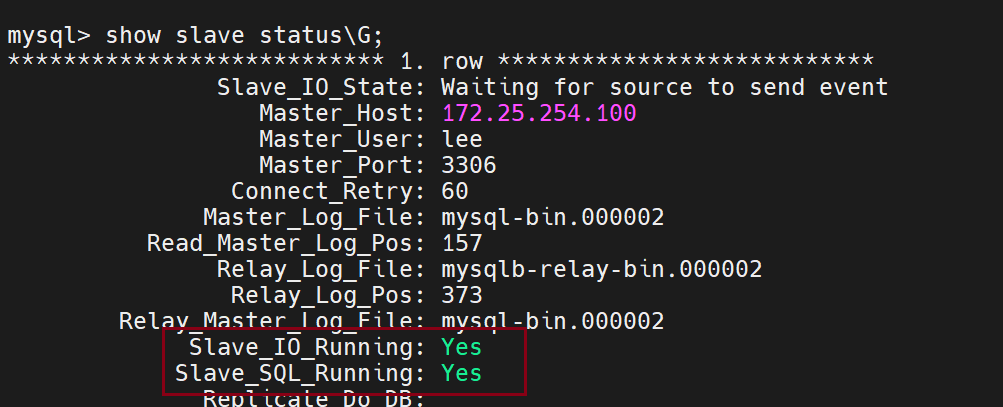
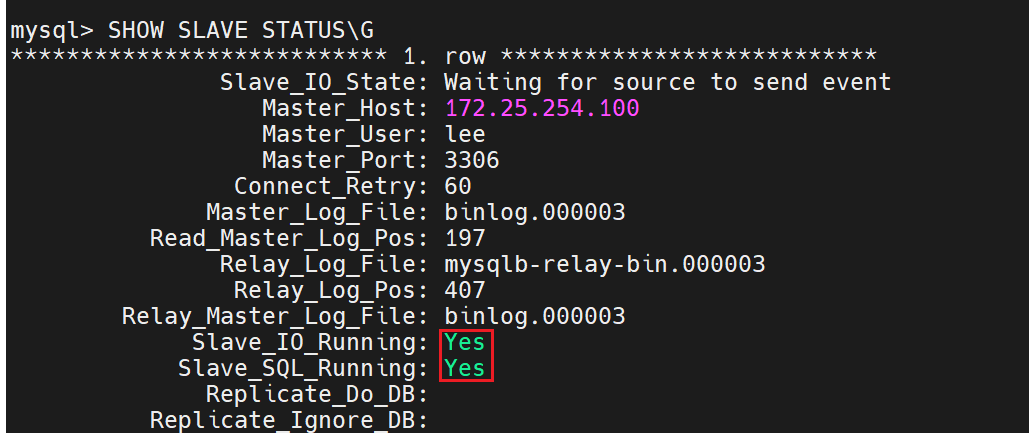
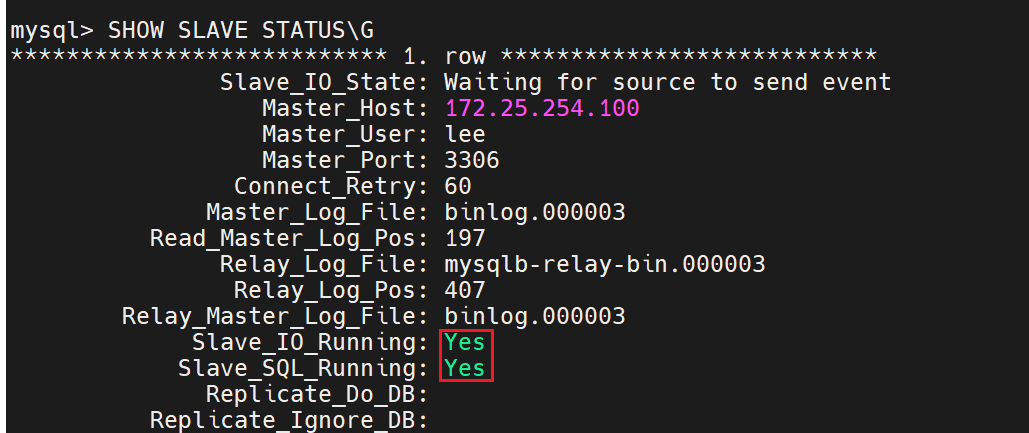
Slave_IO_Running用来传输日志信息
Slave_SQL_Running用来回放日志信息
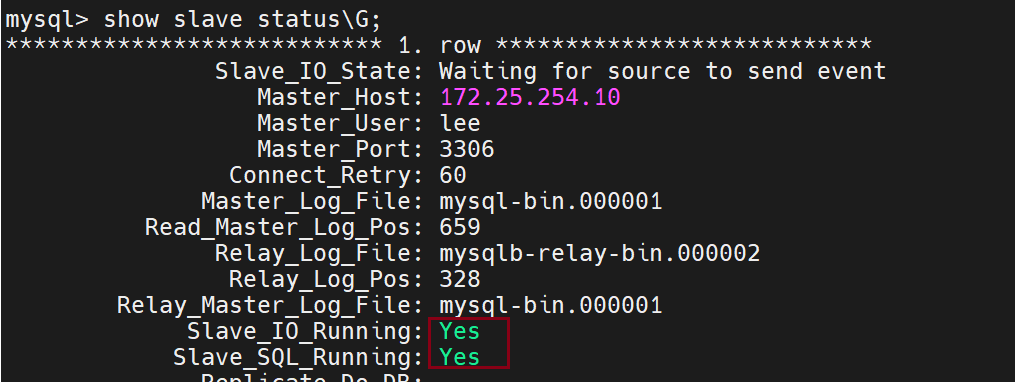
测试主从同步:
在从数据库上监控:watch -n 1 'mysql -uroot -plee -e "select * from lee.userlist;" 2>/dev/null'
要是想删掉这个error
在主数据库上中
此时从数据库上error就没了


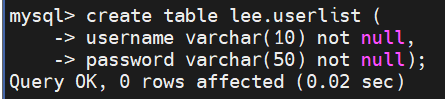

在主数据库上

主从生效了的话,在主数据库上输入这个数据的时候,从数据库中立刻也要有接受反馈
在从数据库上

一主双从模式
再新加一台主机,这台主机要追平之前的主从,该怎么做?
先安装一台主机,步骤和之前一样
![]()
![]()
![]()
![]()


![]()


![]()
安装好之后
此时之前的实验中,主从里已经有数据了
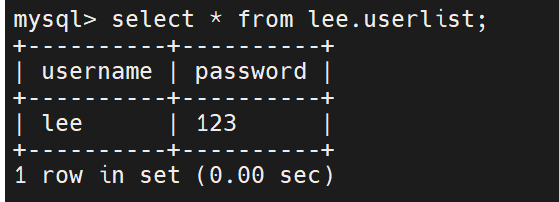
先导出之前的数据
在主数据库上:mysqldump -uroot -plee lee > lee.sql

在导入到新主机里

在实际环境中在备份导出前要先锁库和锁表
要在lee库里恢复,没有库要新建

然后导入数据

查看是否导入成功
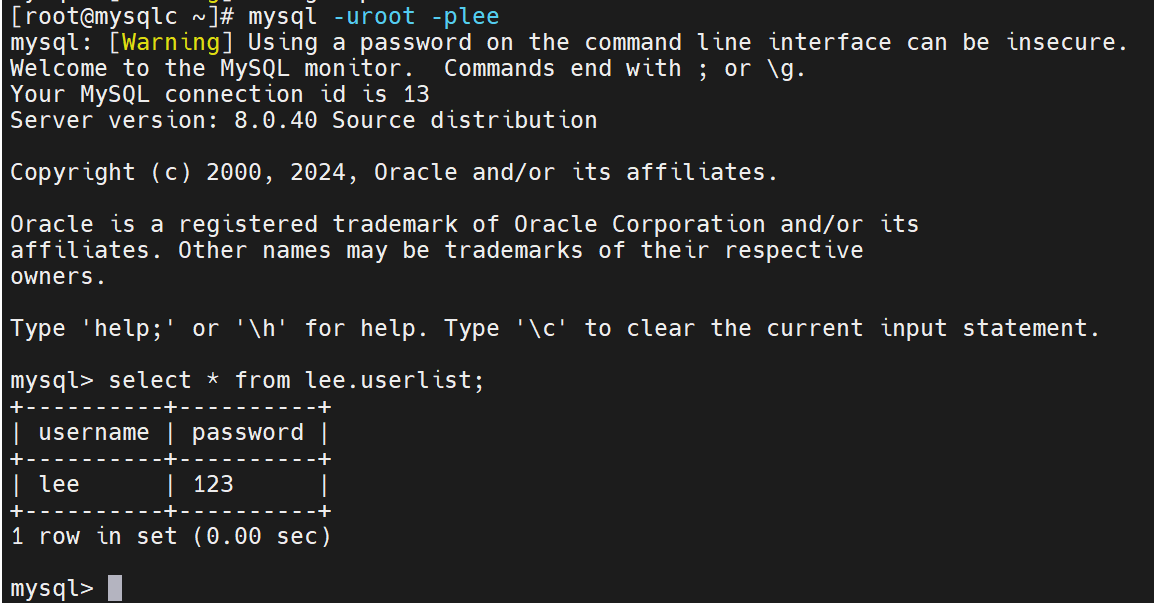
当数据拉平了,再做主从
确认清楚认证,确认是否有变化
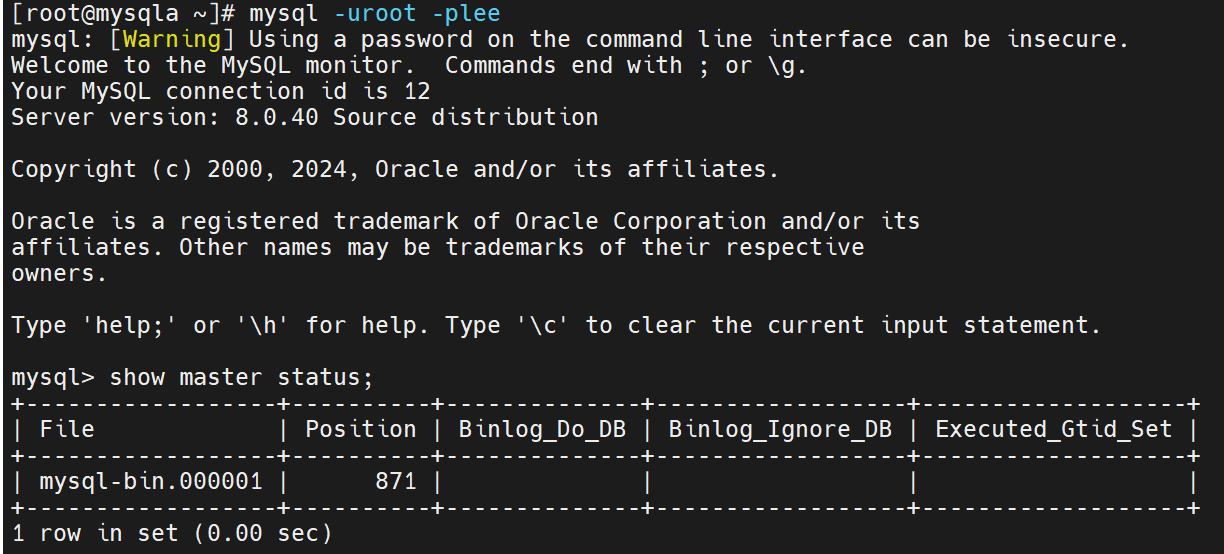
在MySQLC中做认证,连上主数据库

开启服务并查看
一主两从的情况,在实际生产环境中,最好从数据库都只能读,只有主数据库来写数据
写入的数据大于读时主数据库多
读的数据大于写的时候从数据库多
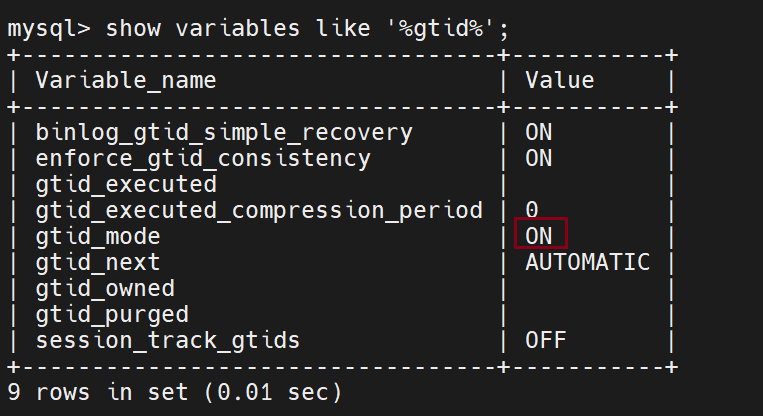
gtid模式
用二进制日志,有一些缺点
如果是做了高可用,有一台主机挂了,需要选择一个新的master,要选一个与之前的主机数据差距最小的主机,现在的二进制日志是无法找到的
用gtid模式来做,唯一标识,每个主机都有一个固定的id,要选举时,直接比较就行
在master端的写入时多用户读写,在slave端的复制时单线程日志回放,所以slave端一定会延迟与master端
这种延迟在slave端的延迟可能会不一致,当master挂掉后slave接管,一般会挑选一个和master延迟日志最接近的充当新的master
那么为接管master的主机继续充当slave角色并会指向到新的master上,作为其slave
这时候按照之前的配置我们需要知道新的master上的pos的id,但是我们无法确定新的master和slave之间差多少
当激活GITD之后
当master出现问题后,slave2和master的数据最接近,会被作为新的master
slave1指向新的master,但是他不会去检测新的master的pos id,只需要继续读取自己gtid_next即可
实验:
停止从数据库(两个从都要做)
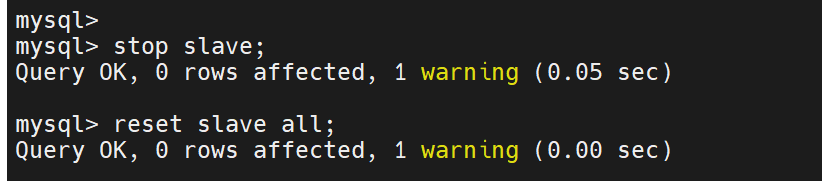

启动gtid模式(主从都做)
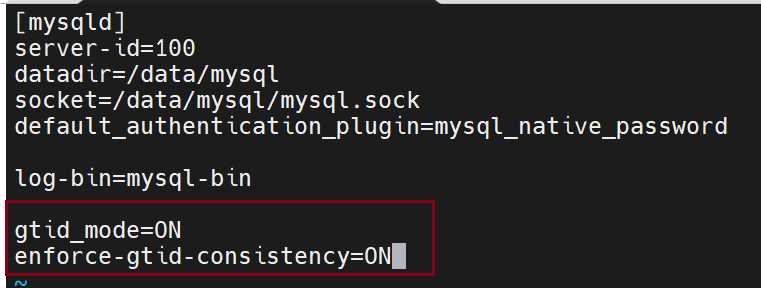
启动gtid模式 gtid——mode=on
必须保持强一致性 enforce-gtid-consistency=on
重启所有mysql服务

在主数据库上查看是否开启
在从数据库上,做gtid认证


慢查询日志
此时慢日志还未打开,查看log的状态是OFF
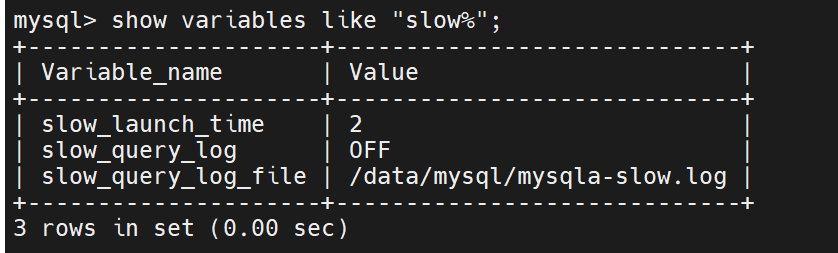
那此时在数据库中查找这个log,是不会被查找到
打开慢查询模式

此时再查看
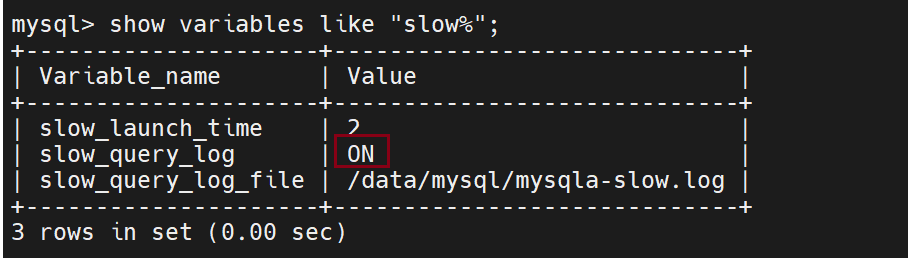
测试:
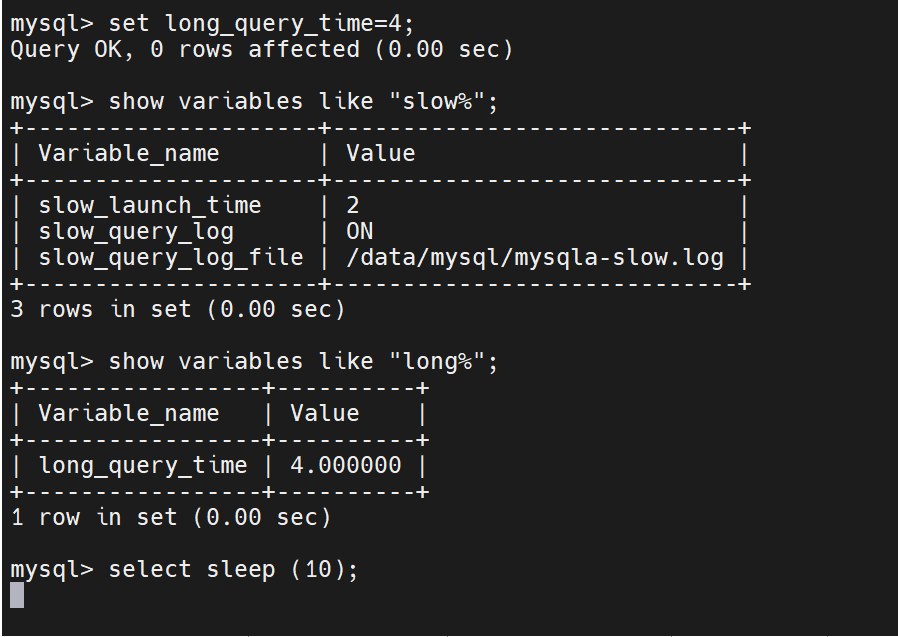
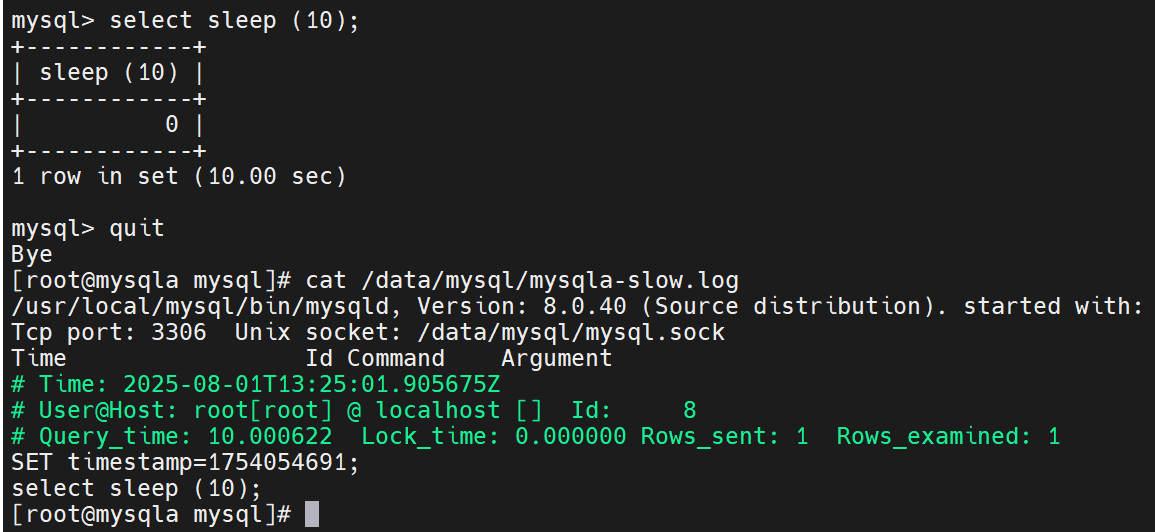
此时查看日志就可以看到信息了
mysql的并行复制
谁要做日志传输和日志回放
默认情况下slave中使用的是sql单线程回放
在master中时多用户读写,如果使用sql单线程回放那么会造成组从延迟严重
开启MySQL的多线程回放可以解决上述问题
查看slave中的线程信息
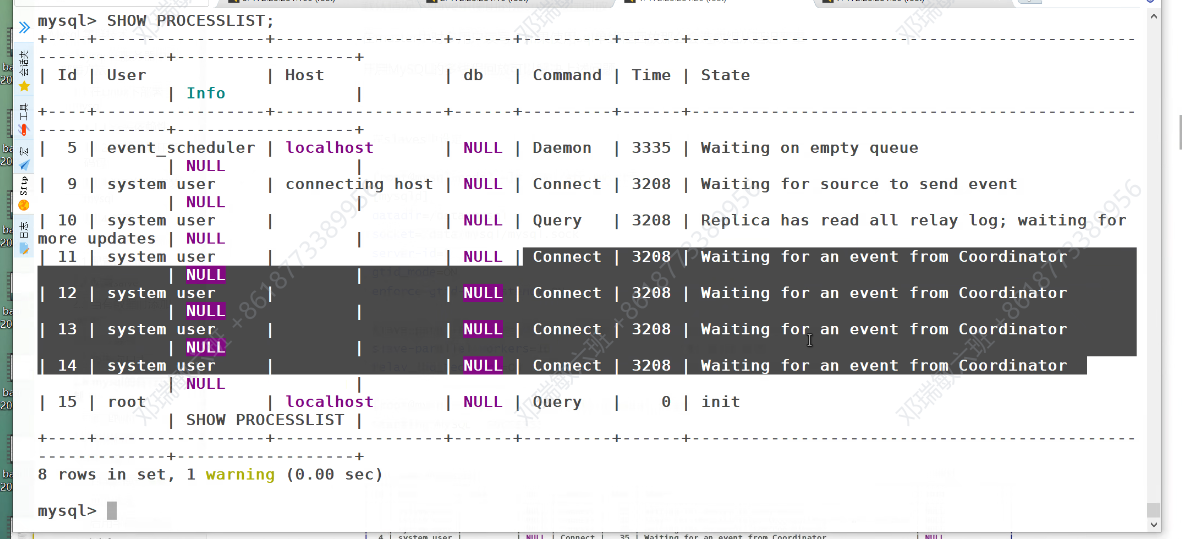
在从数据库中
编写多线程
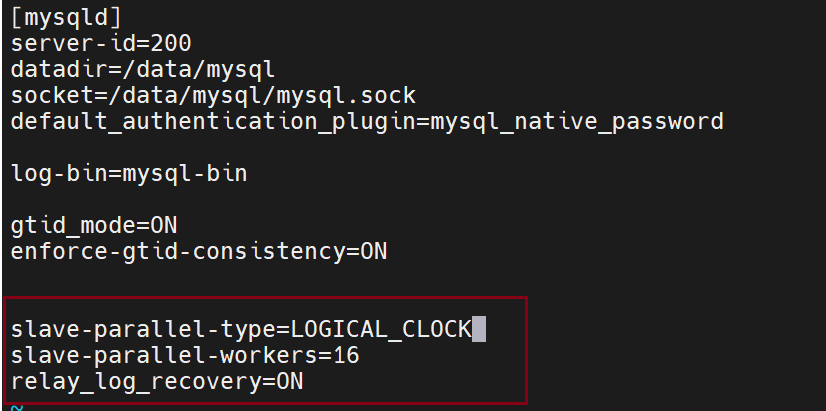
![]()
重新查看后,此时sql线程转化为协调线程,16个worker负责处理sql协调线程发送过来的处理请求
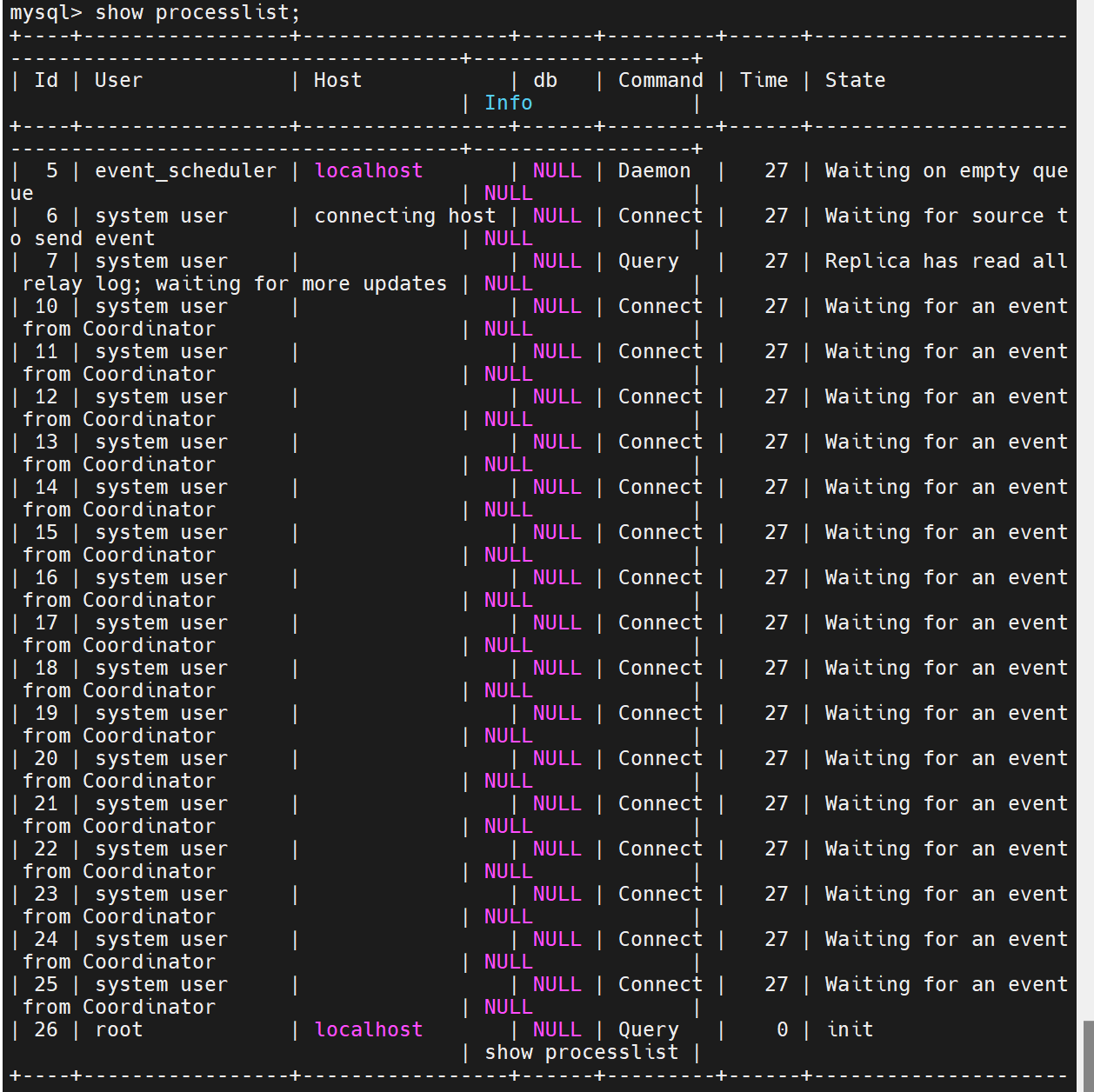
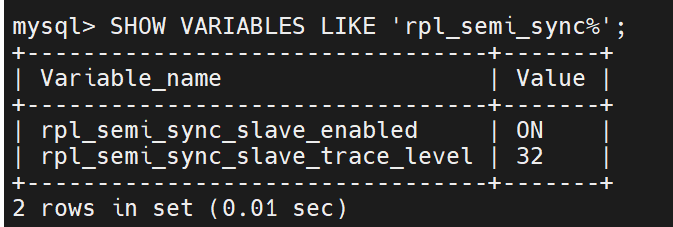
半同步模式
1.半同步模式原理
mysql的主备库通过binlog日志保持一致,主库本地执行完事务,binlog日志落盘后即返回给用户;备库通过拉取主库binlog日志来同步主库的操作。默认情况下,主库与备库并没有严格的同步,因此存在一定的概率备库与主库的数据是不对等的。半同步特性的出现,就是为了保证在任何时刻主备数据一致的问题。相对于异步复制,半同步复制要求执行的每一个事务,都要求至少有一个备库成功接收后,才返回给用户。实现原理也很简单,主库本地执行完毕后,等待备库的响应消息(包含最新备库接收到的binlog(file,pos)),接收到备库响应消息后,再返回给用户,这样一个事务才算真正完成。在主库实例上,有一个专门的线程(ack_receiver)接收备库的响应消息,并以通知机制告知主库备库已经接收的日志,可以继续执行。
只在gtid模式下可用
核心是slave的通知机制,数据发送过来,slave会发ack来确认
在从中
在配置文件中写
但是没有插件,开不了
在主中
![]()
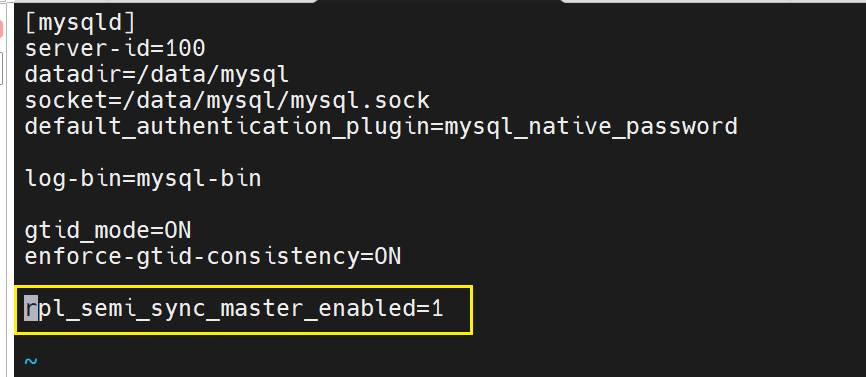
不要重启,没有插件,开不了
安装模块

查看是否安装好
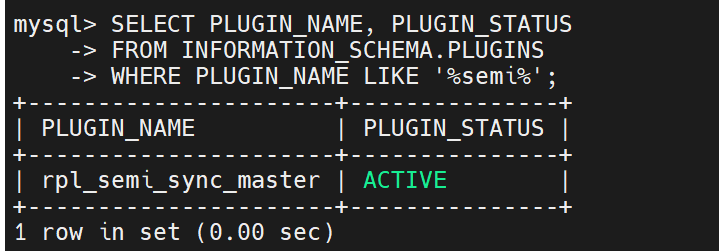
加载完成之后,才可以启动
启动

产看模式是否开启
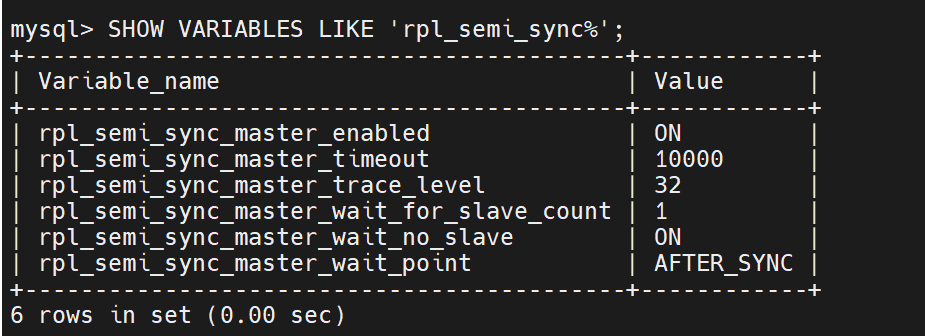
查看同步的信息,暂时还没有
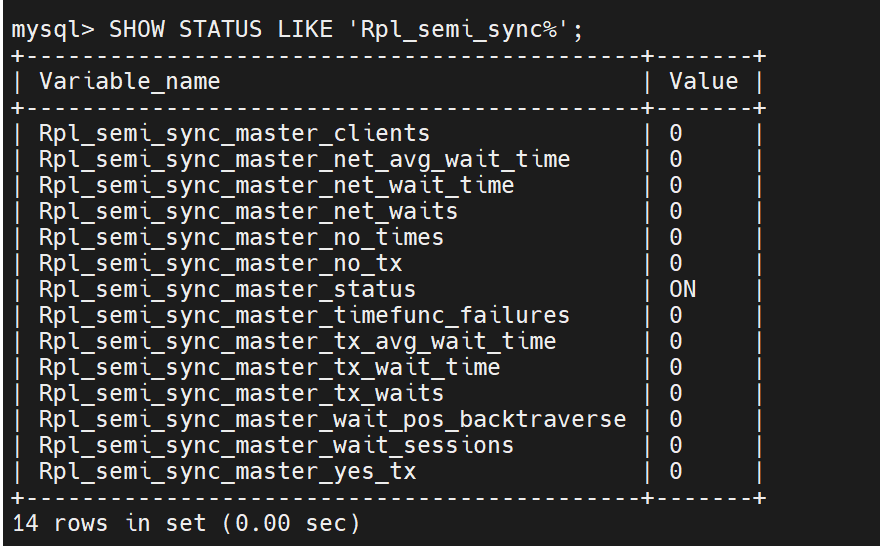
在从中
和主中配置不一样
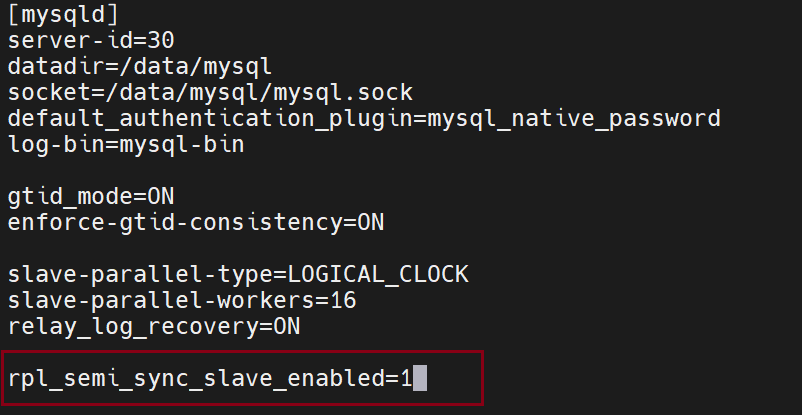
不要重启,没有加载插件
安装

查看是否安装
![]()

启动

产看是否开启
测试:
在从中,关闭线程在打开,刷新
两边都要查看
在主中

测试:
在200从中关闭接受日志的线程

在主中
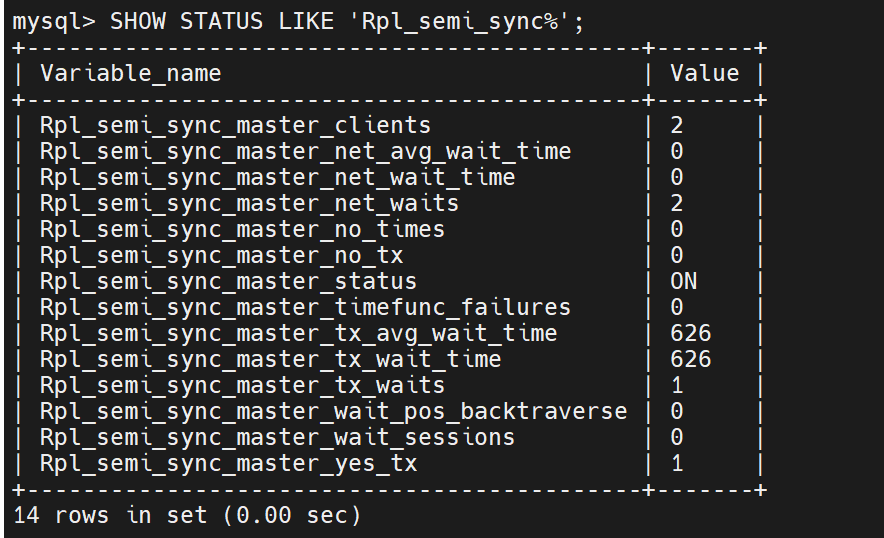
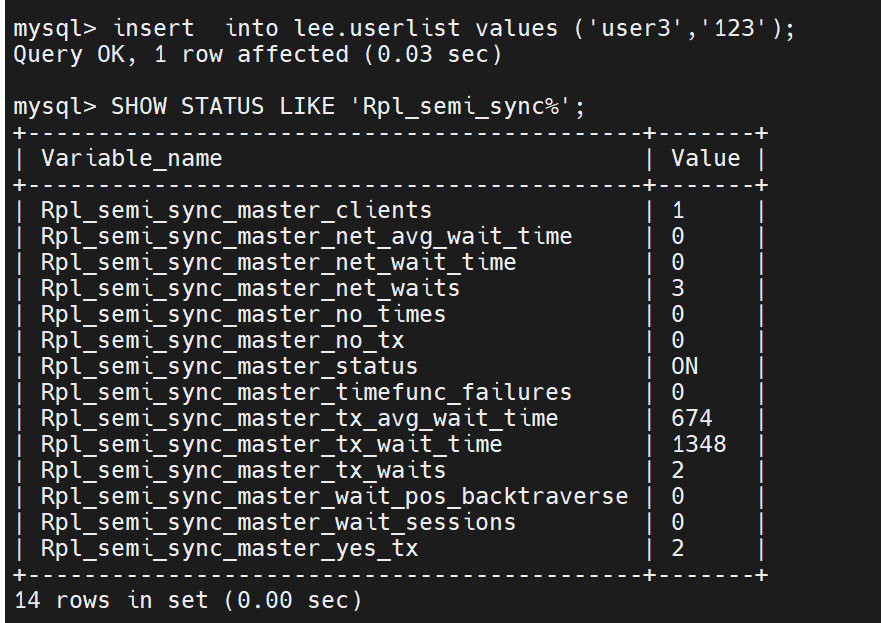
关闭一台,半同步还在继续
此时关闭两个了


其实还是会传输,但是会在10秒后转变成异步
此时你再查看会发现,有两笔是半同步传输的,一笔是异步传输的
半同步自动关闭,转成异步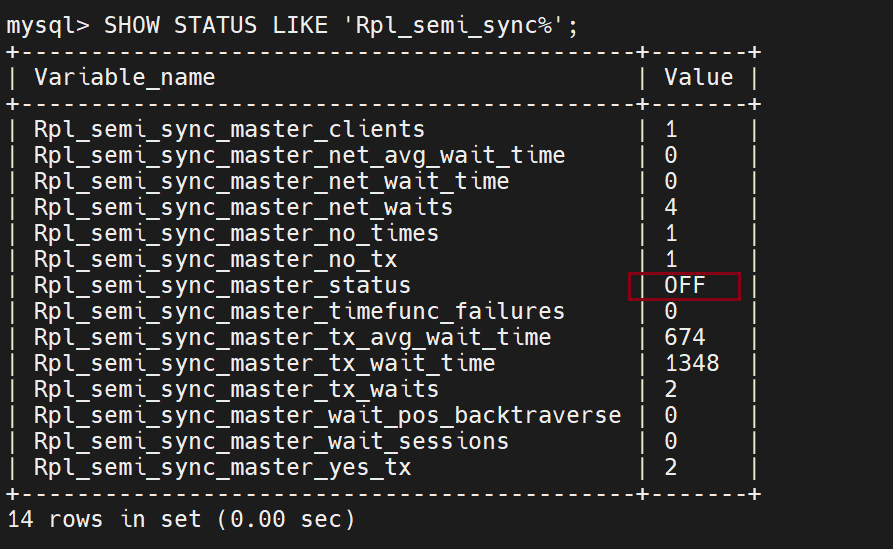
恢复一台就可以使ack恢复了

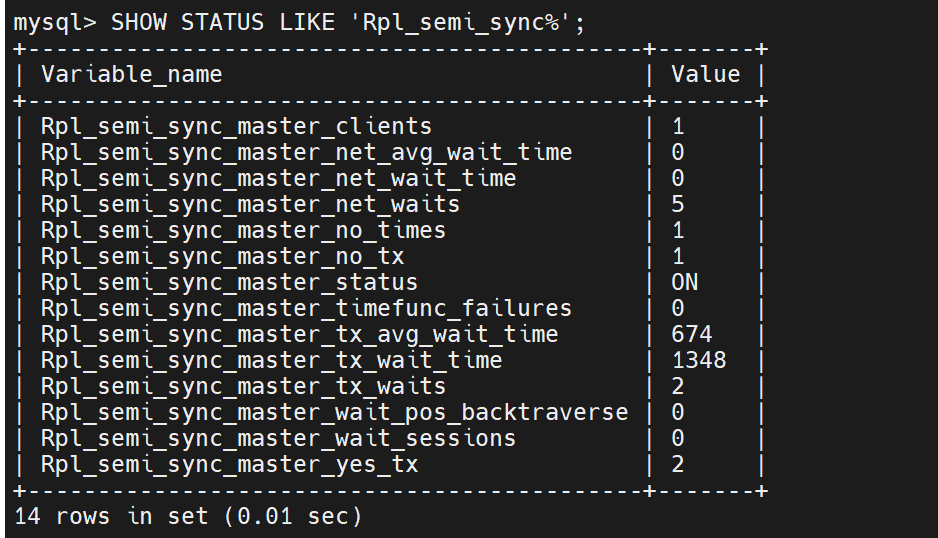
检查是否开启

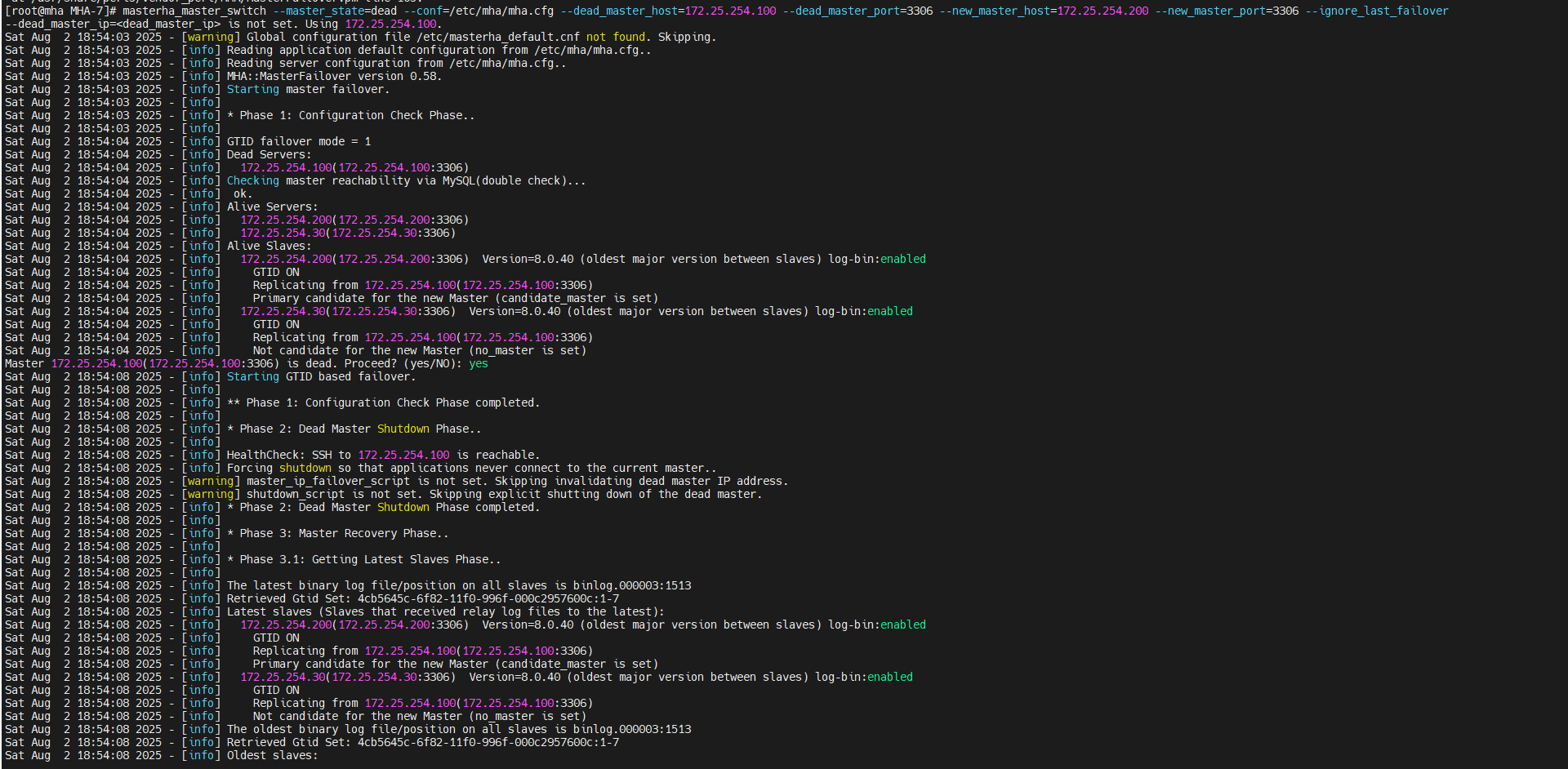
主挂了,要怎么知道
主挂了,从要怎么转变成主
mysql高可用之MHA
工作原理:
会定期检测
master出现故障时,可以自动切换最新数据的slave为master
前提:一主两从的模式
环境:四台虚拟机
新增一台MHA的虚拟机
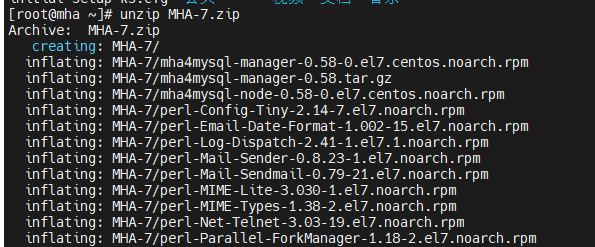
安装所有rpm
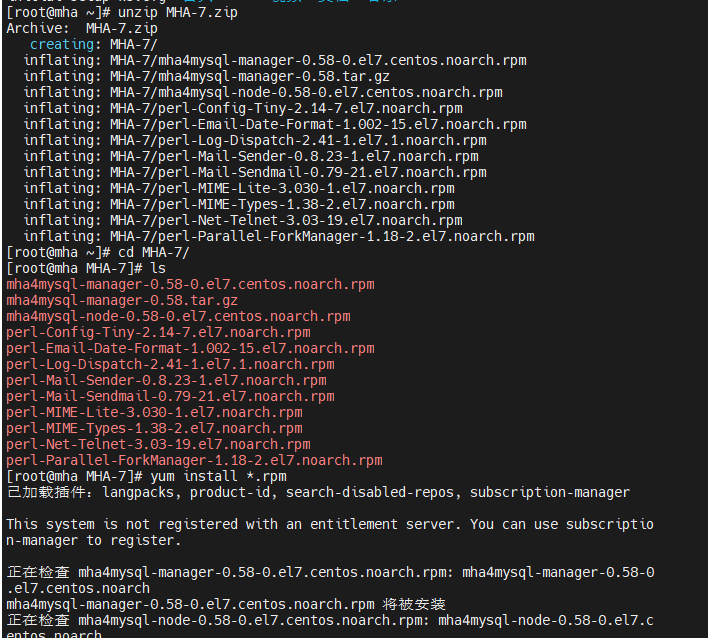
并且所有数据库都要安装node检测的软件,所以直接复制过去
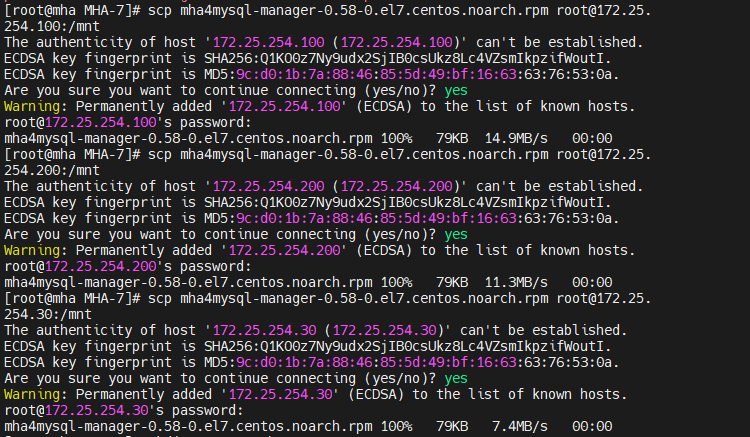
三台数据库都要做
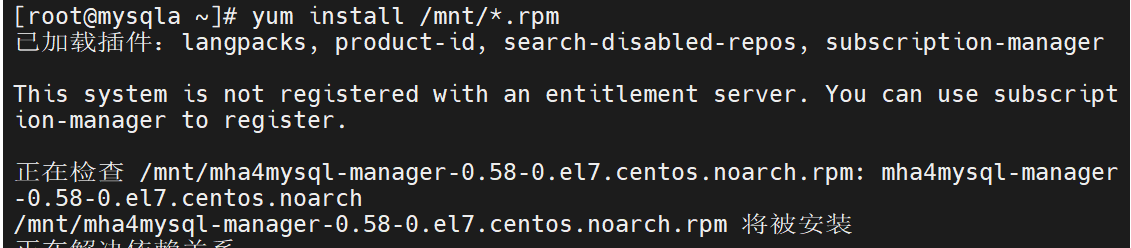
这里面是模版

![]()
将模版移动到新目录中

复制到是主体和对于主机控制的内容
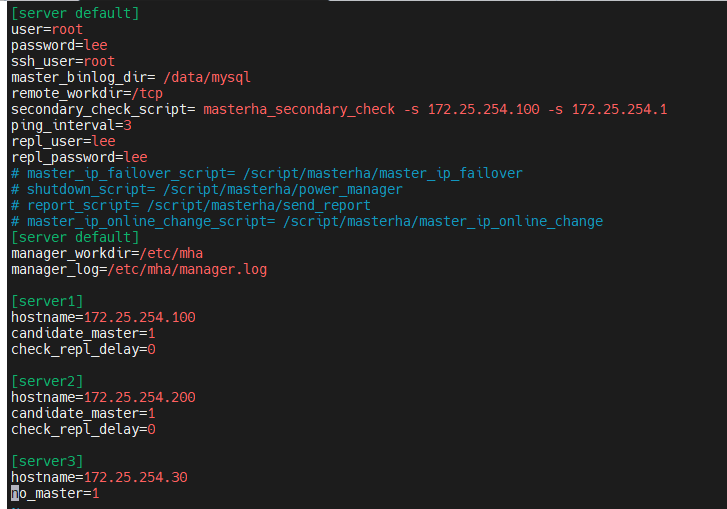
ping_interval=3:做3次都失败了,就宣告这台master已经失效了
在编辑文件中写,master的设定用户是root
要查看是否能远程登录root
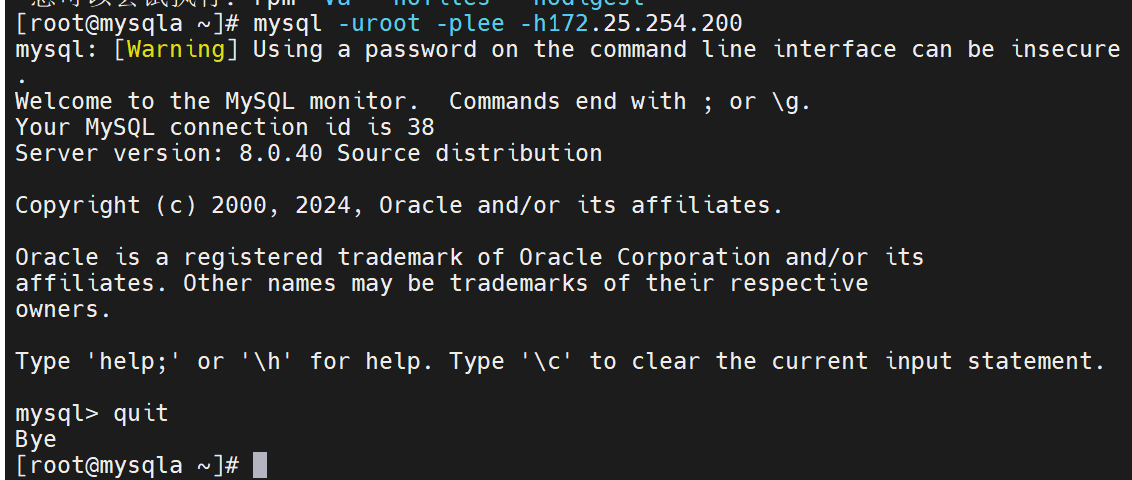
三台数据库都要做
建立能够远程登录的用户
这里设立的超级用户

对新增用户做授权
我们这里设定是超级管理员,所有的功能都要能做
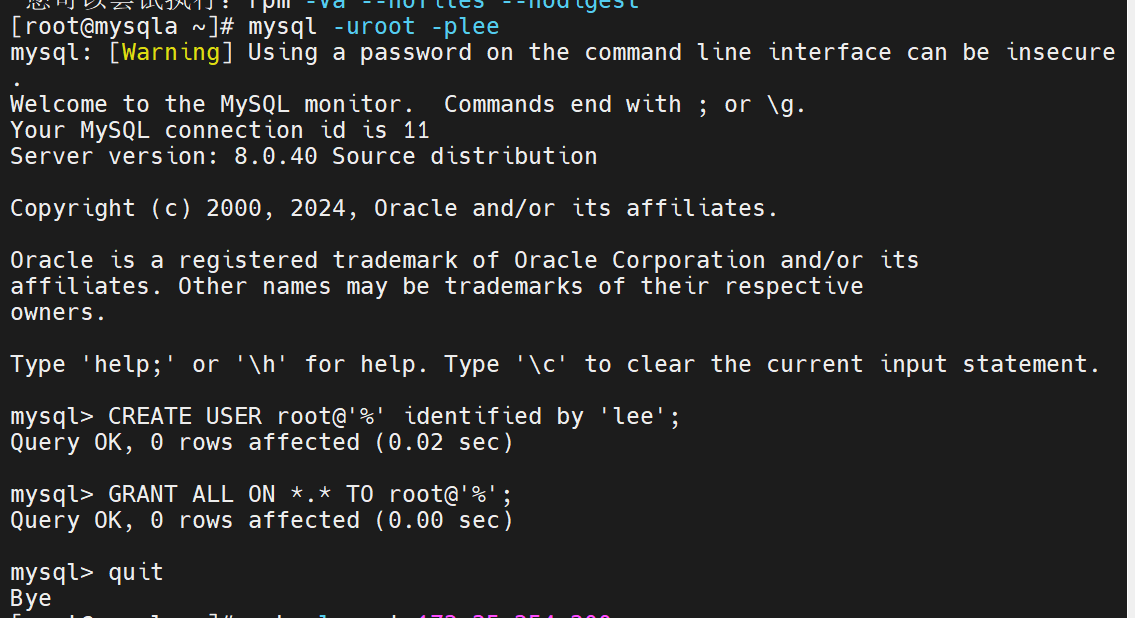
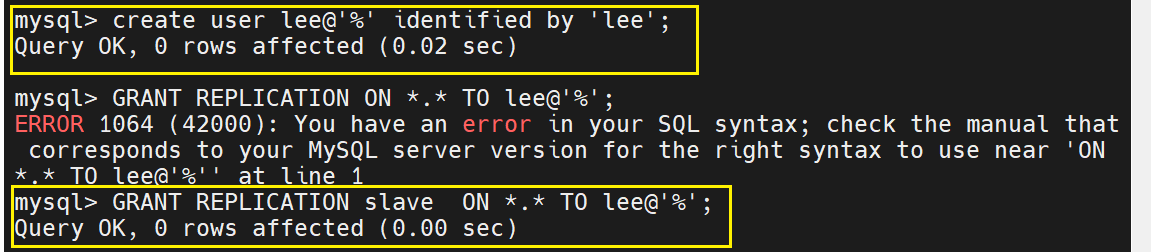
在原先的master中有一个用于数据同步的用户lee
但是在第一台有可能变为主的从数据库中,是没有这个用户的,但是这个数据库是有变为主的可能性的
第一台从数据库还缺少一个变为主的条件,
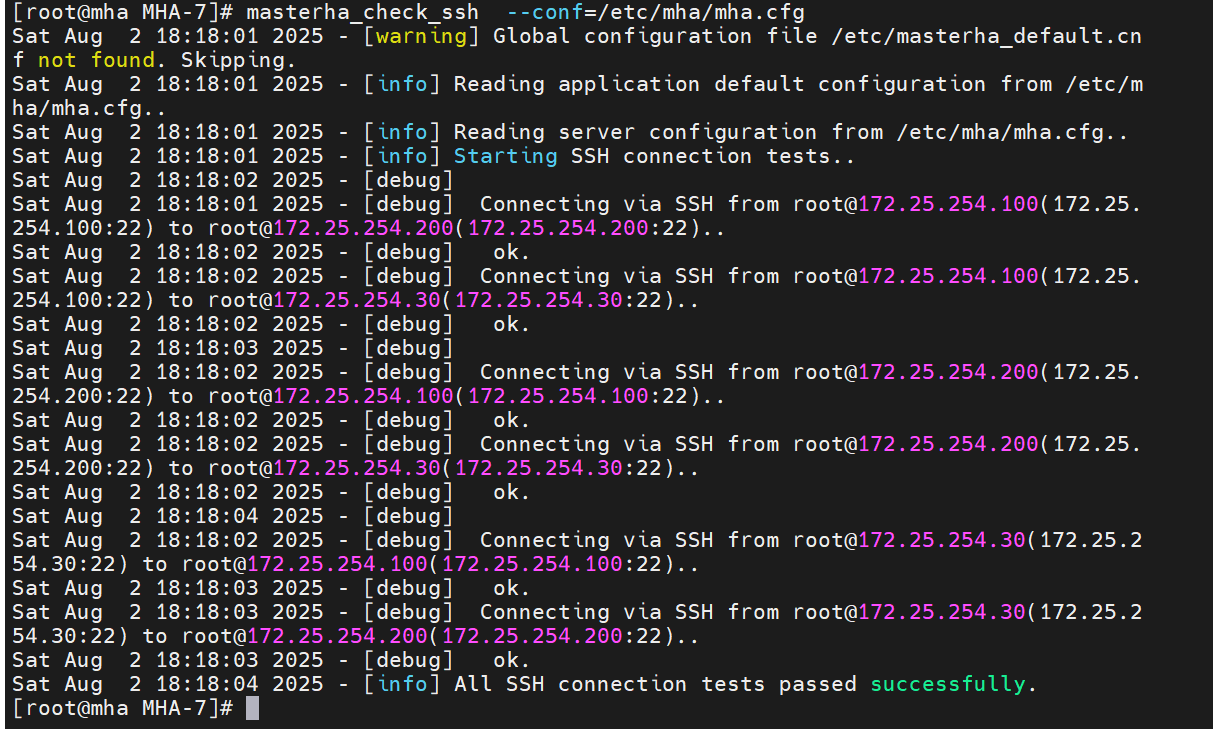
这四台主机之间要实现免密,因为在切换时,要能直接切换,不受阻碍
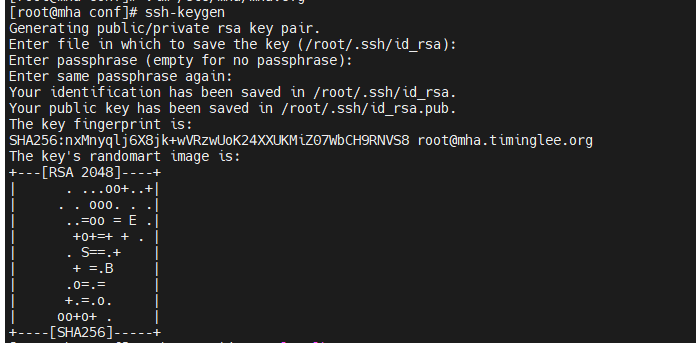
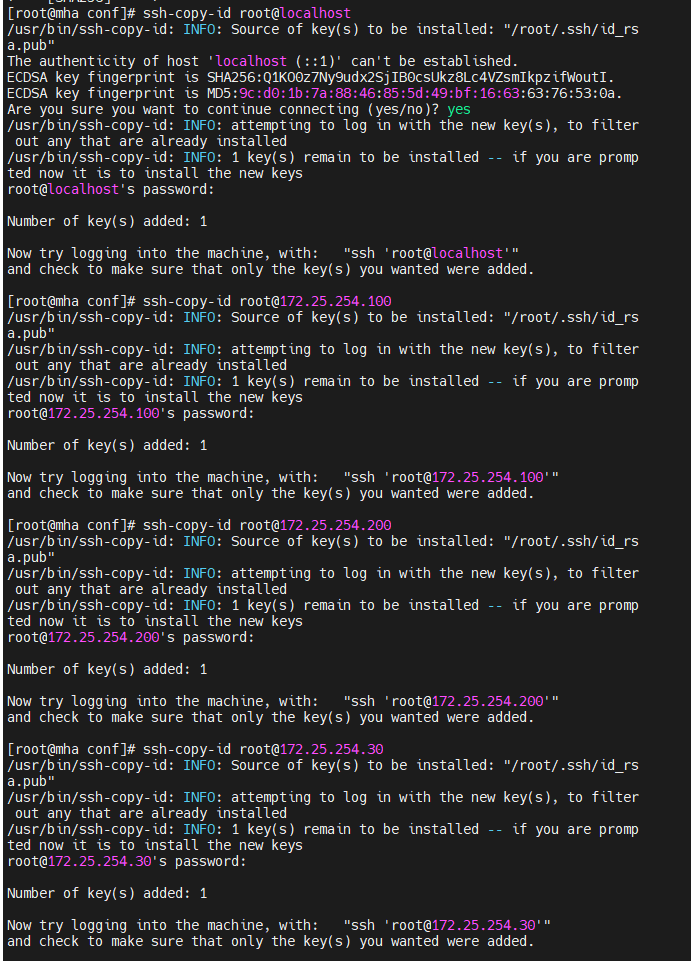
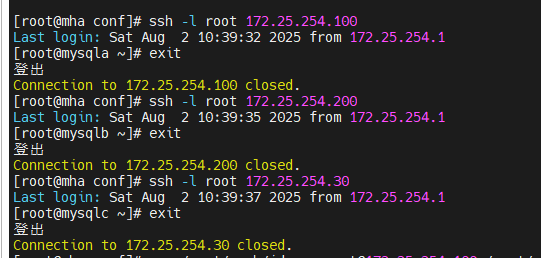

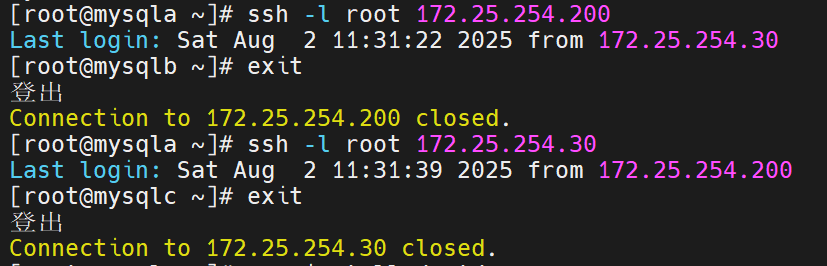
检测当前架构免密是否成功
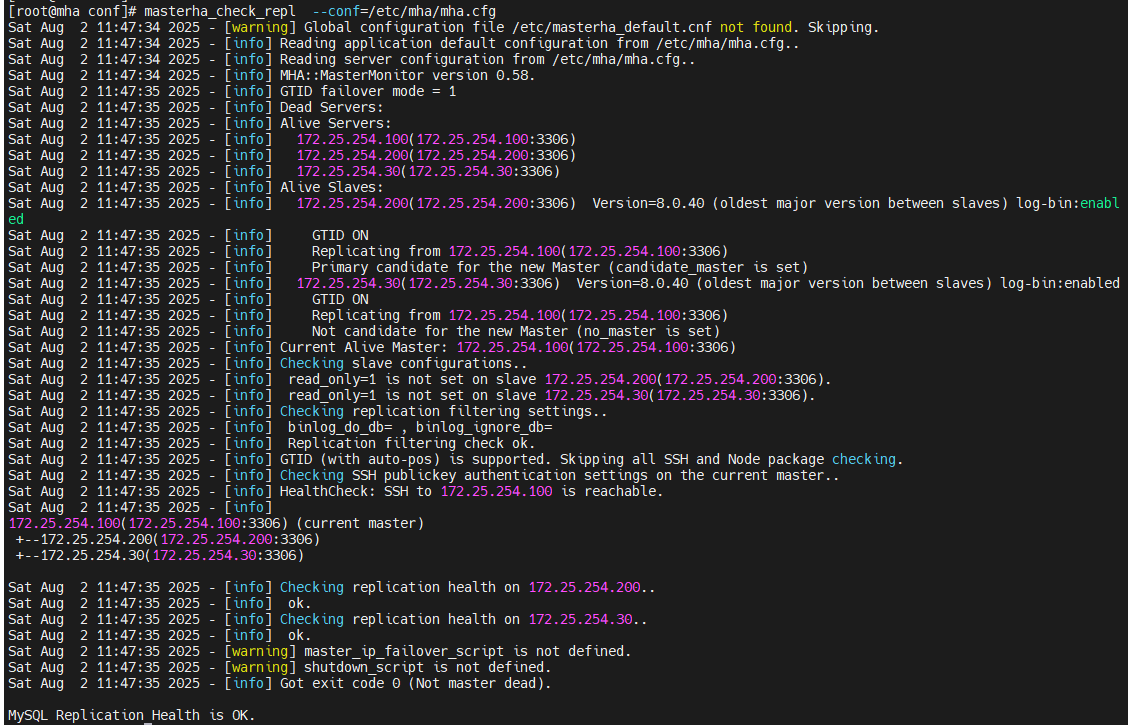
检测主从同步情况
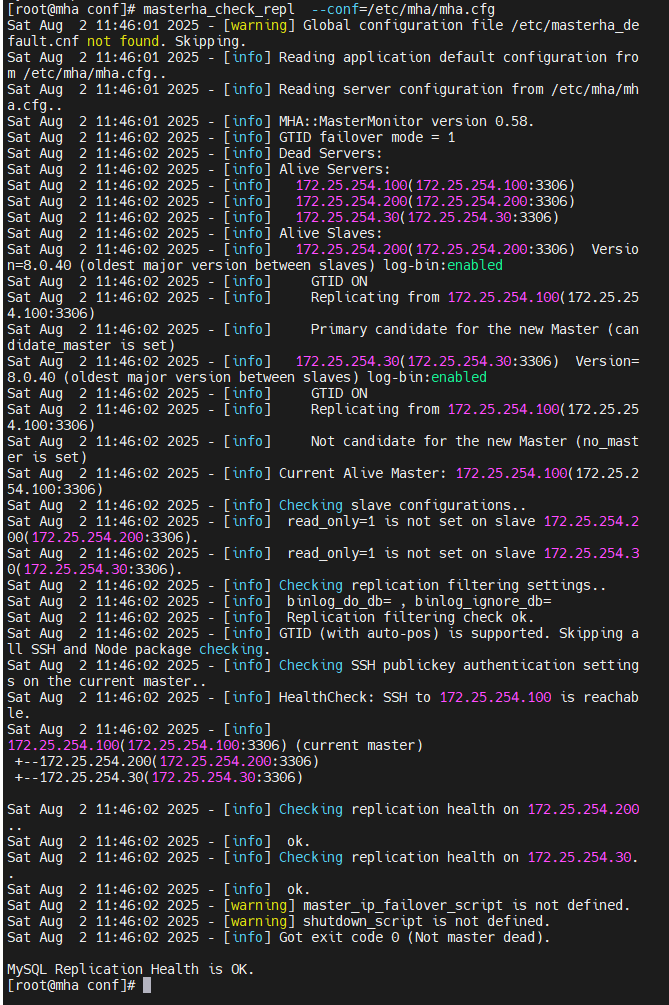
master未出现故障手动切换
这个实验先把半同步关闭,试验完成后再打开
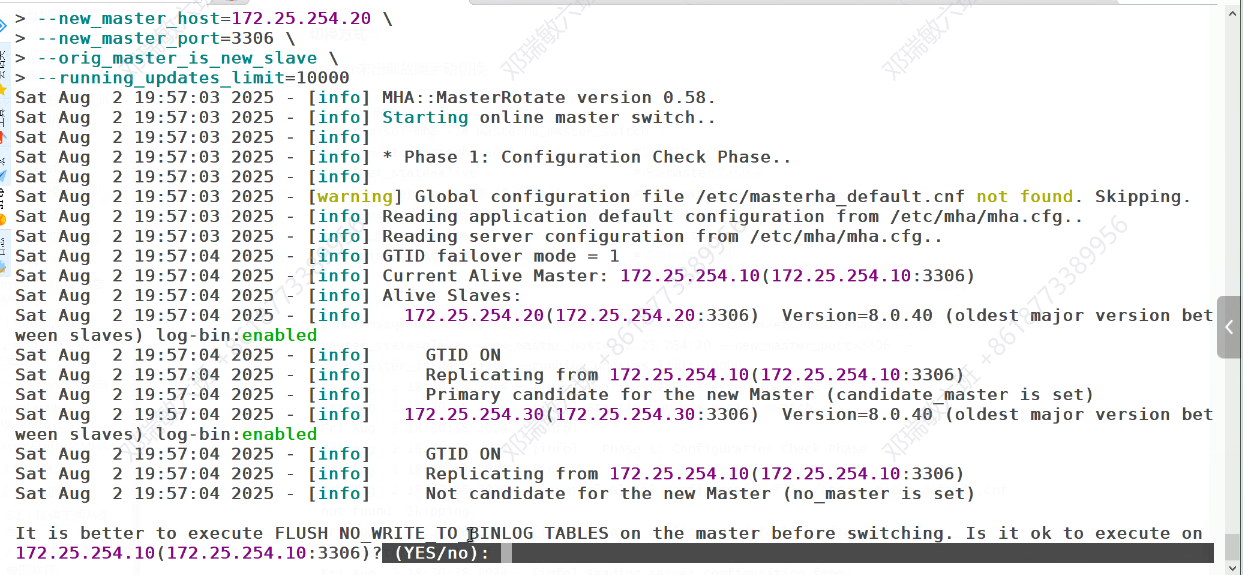
问要不要做切换要
master要不要从100切换到200
保持功能 要
同步中断了
排错过程
还不行
重做
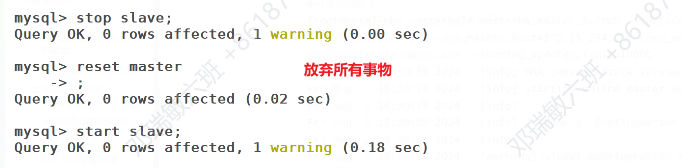
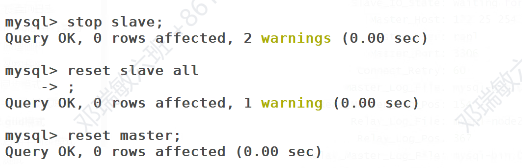
删除之前所有的认证
日志还原
所有都:


组复制MGR
前面开启一个协议层,写东西时会先进入协议层,协议层会去询问数据库能不能做,如果超过两个以上回复不能做,就不能做(少数服从多数)
单主
![]()
多主
任何一个主机写入时,所有的数据库都会同步
所有的数据库服务都关闭



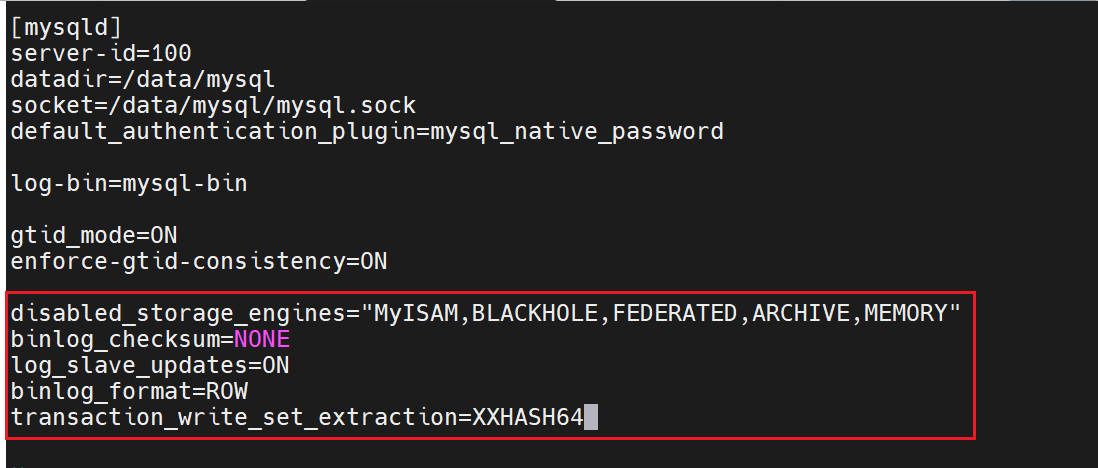
在配置文件中
![]()
禁止这些模式的存储机制

禁止二进制日志的校验

使用行日志格式
把mysql的文件都删掉
![]()
![]()
![]()
域名解析:

做初始化
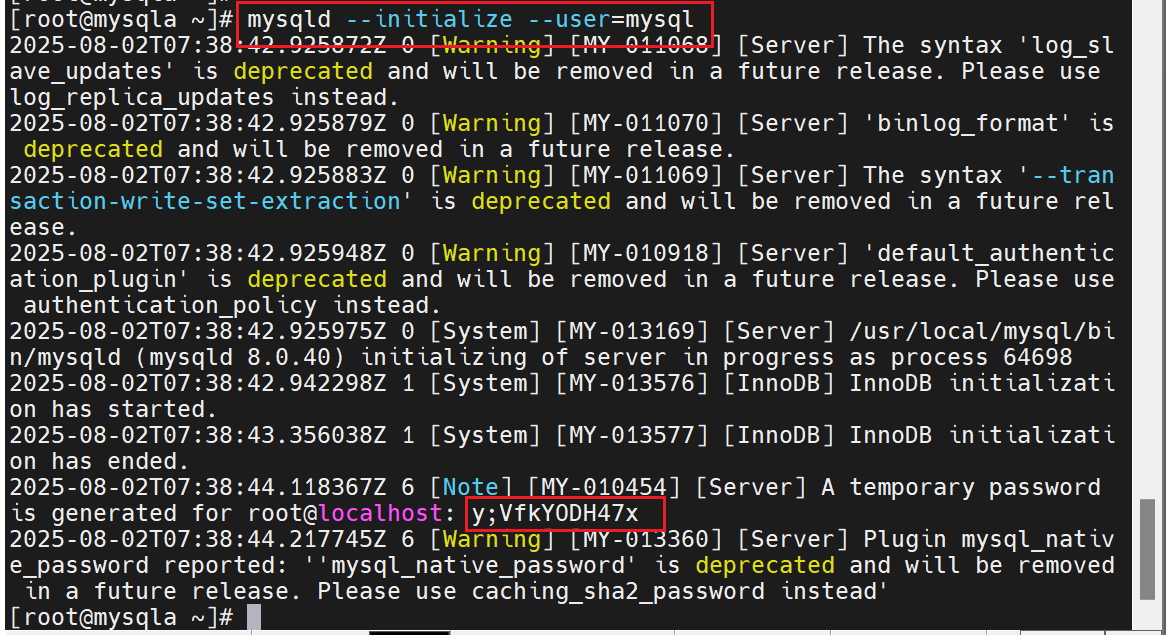
完成后不要启动数据库
继续编辑编辑文件
对于插件来说是不能做初始化的,所以不能启动
plugin_load_add='group_replication.so'
group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
group_replication_start_on_boot=off
group_replication_local_address="172.25.254.30:33061"
group_replication_group_seeds="172.25.254.100:33061,172.25.254.200:33061,172.25.254.30:33061"
group_replication_ip_whitelist="172.25.254.0/24,127.0.0.1/8"
group_replication_bootstrap_group=off
group_replication_single_primary_mode=OFF
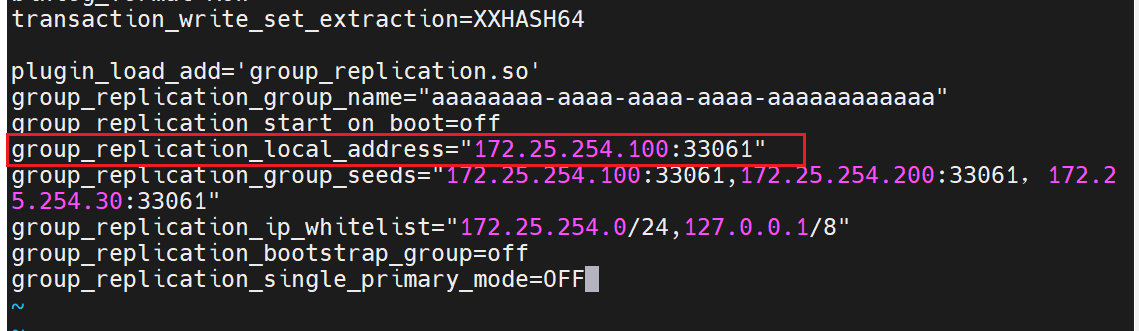
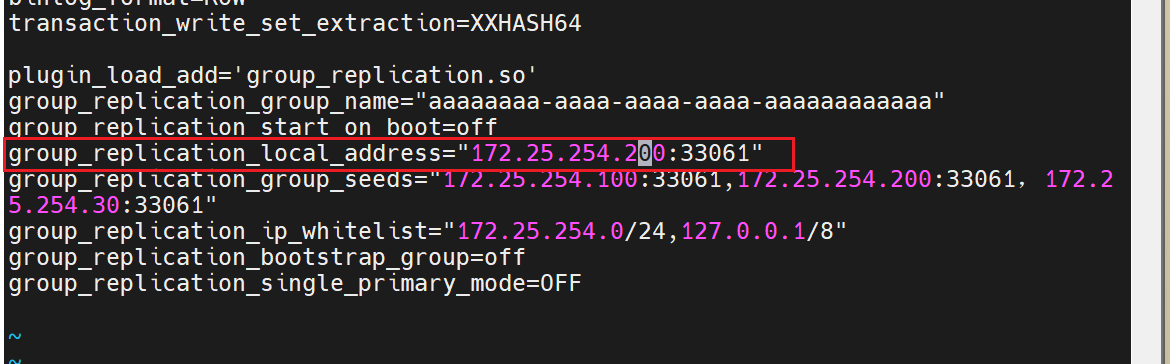
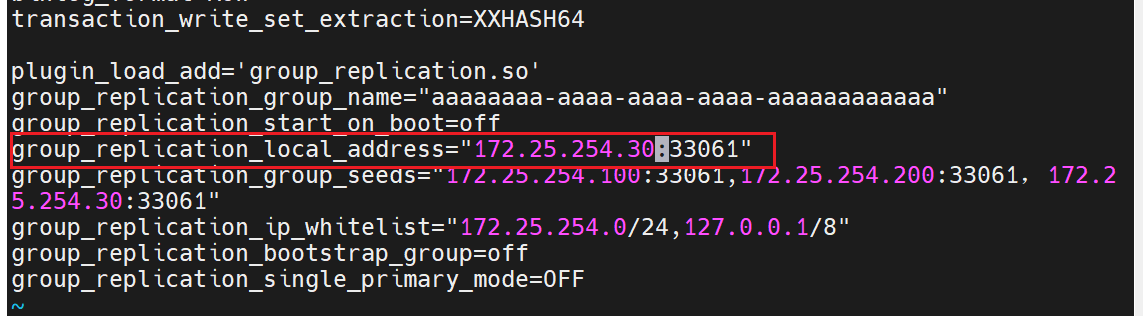
最后再启动



不要安全初始化,直接进入
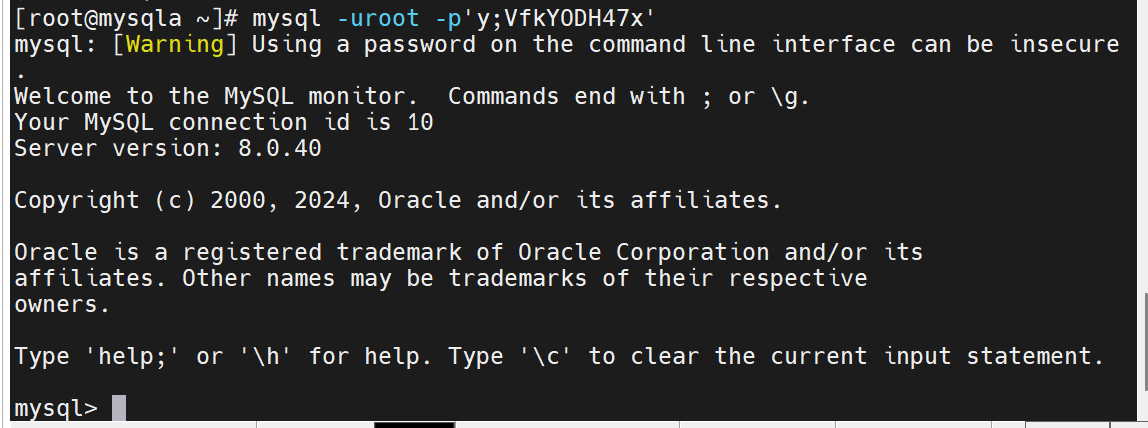
修改超级用户密码,不然无法操作了

关闭日志,后面的操作不需要记录到日志中

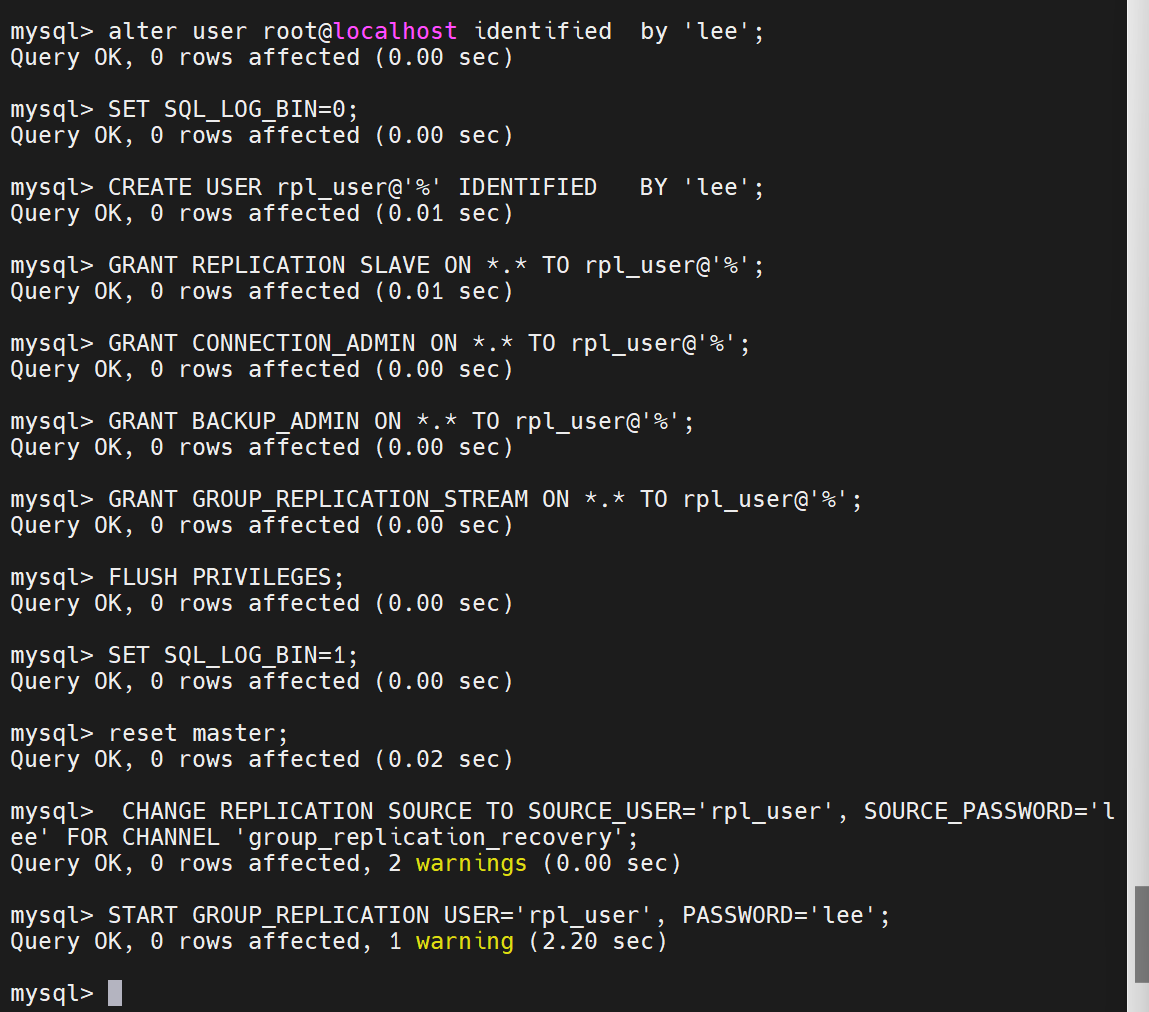
创建用户

授权







把自己加入组中

手动打开组复制模式

打开服务,再关闭模式

查看组情况
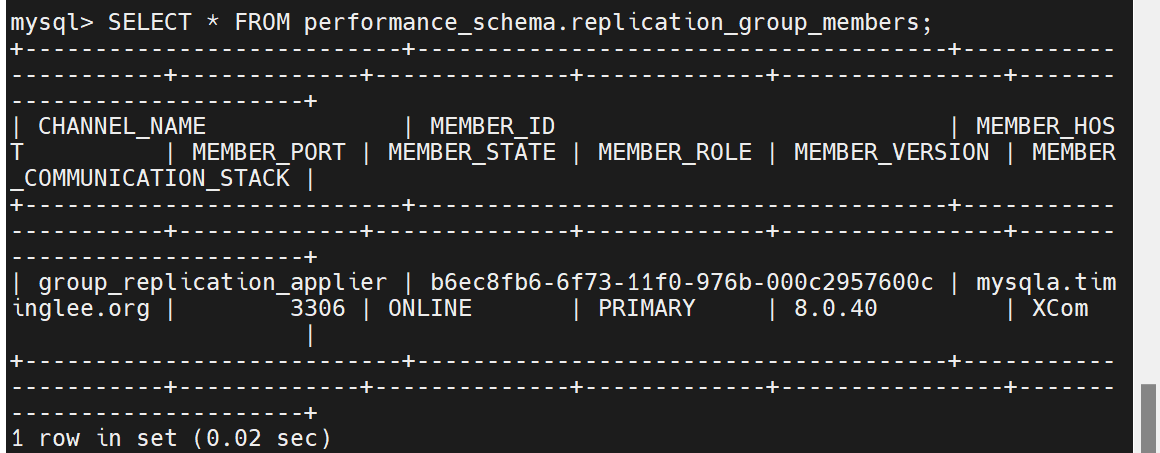

加入后两台数据库到组中
第一台从
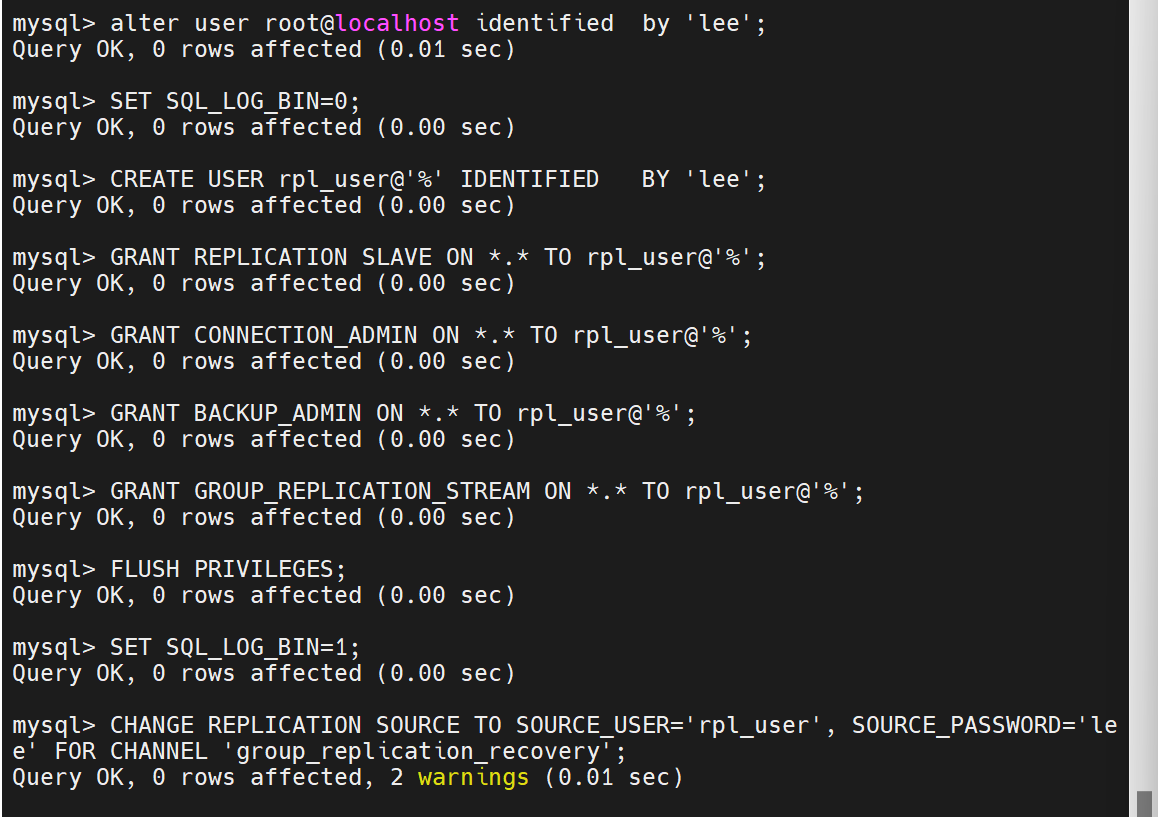
数据之间有差异

开之前,把这台主机里面之前所有的日志文件都刷新
![]()

再次查看组
recoe没好
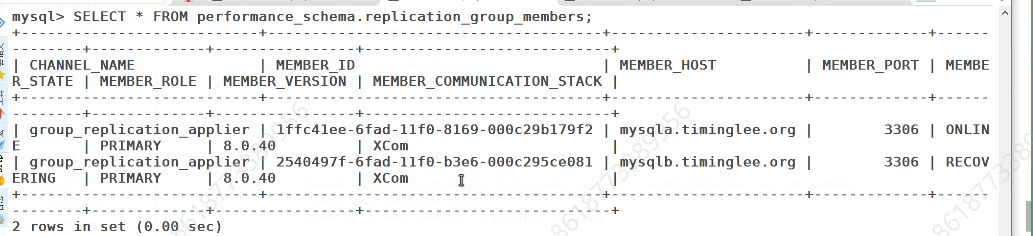
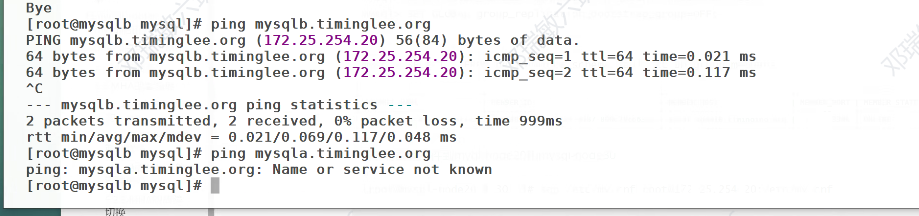
测试呢能不能连
ping不同
要做域名解析
等待一段时间
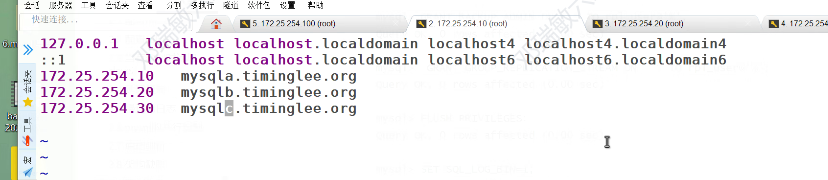

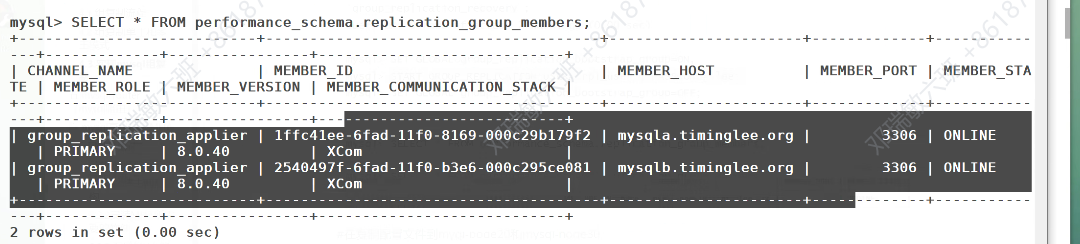

此时再查看

第二台
继续上一步
再去查看,此时有三个

测试:
在主上建立数据库

在从上查看
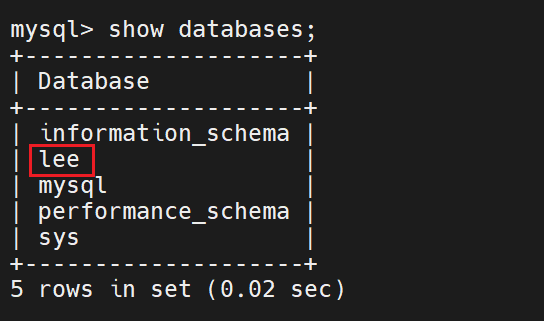
在从上建表

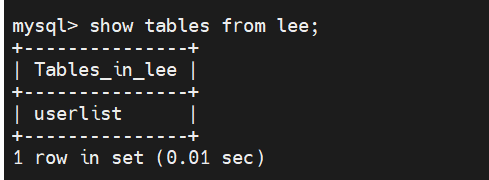
在第二台从上看

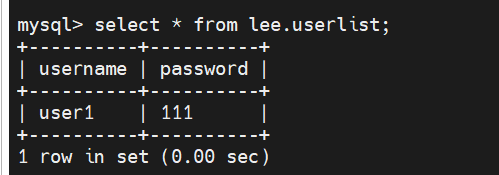
在主上看
现在关闭一台数据库


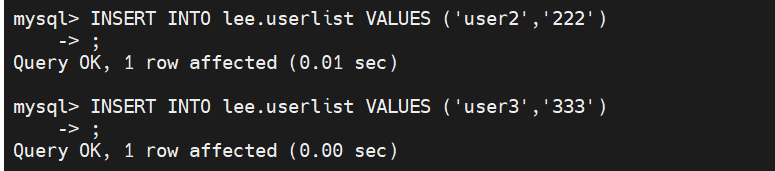
还是能正常输入数据
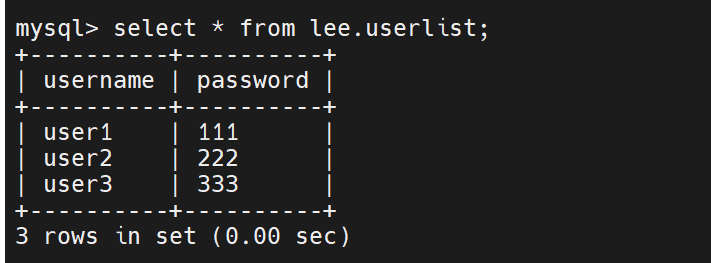
此时两台都挂了


此时写了也不能进入磁盘

重新登录
不能自动上线,要手动开启




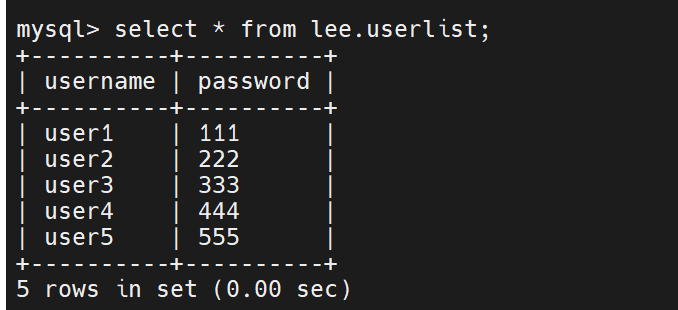
MHA
在主数据库上

先要开启gtid模式
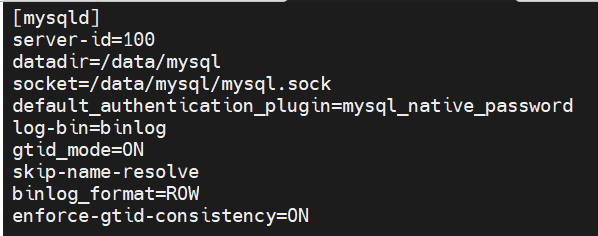
执行它之前,一定要关闭mysql
![]()


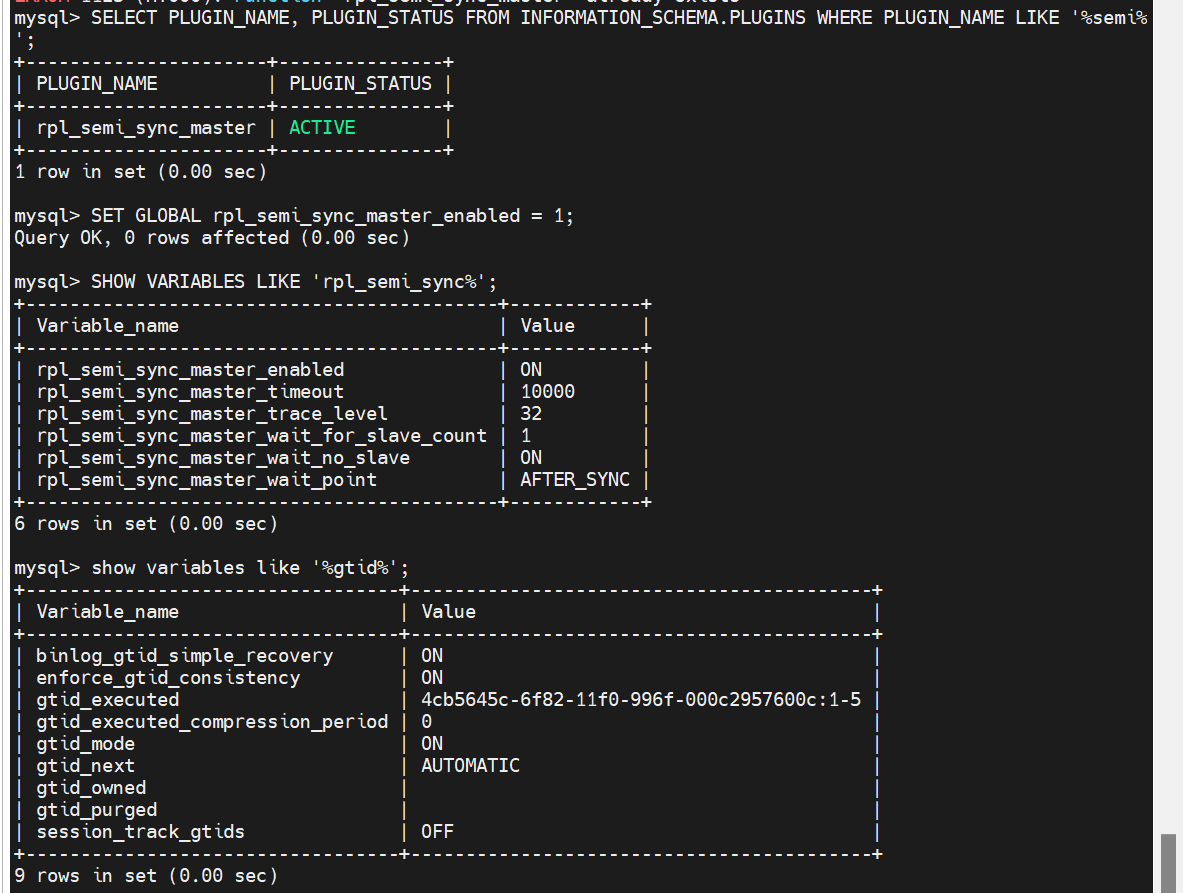
等从数据库完成gtid模式后
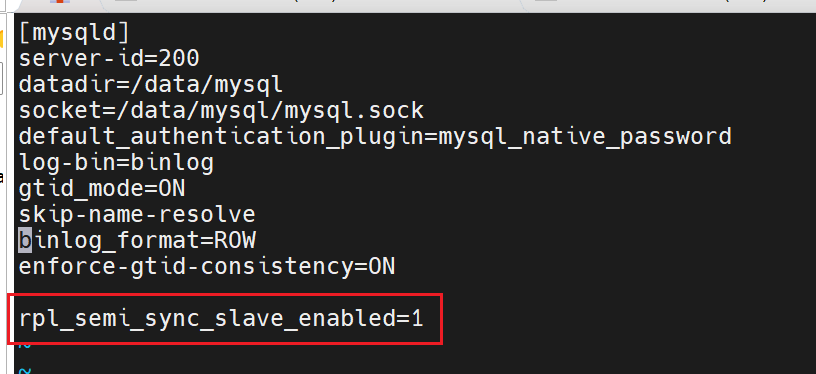
在master端配置启用半同步模式
#安装半同步插件
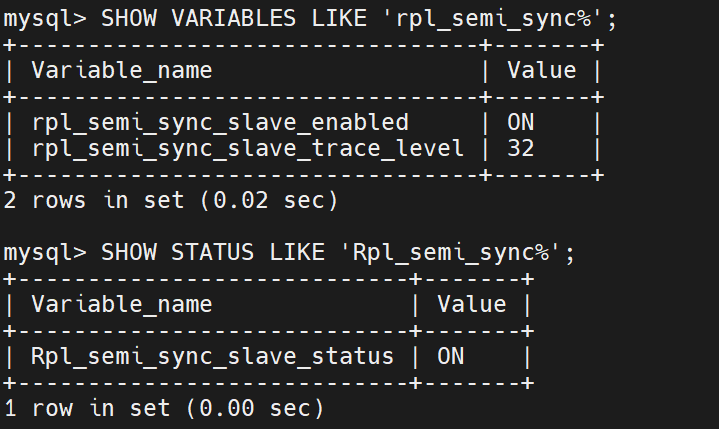
查看插件情况
打开半同步功能
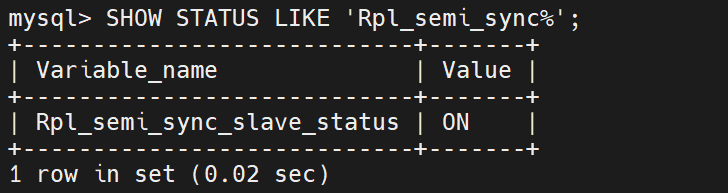
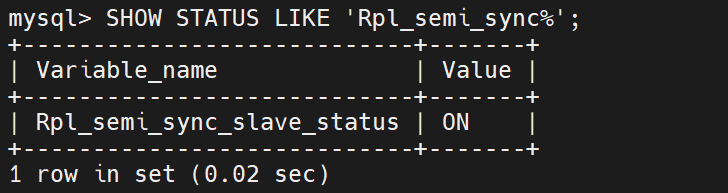
查看半同步功能状态
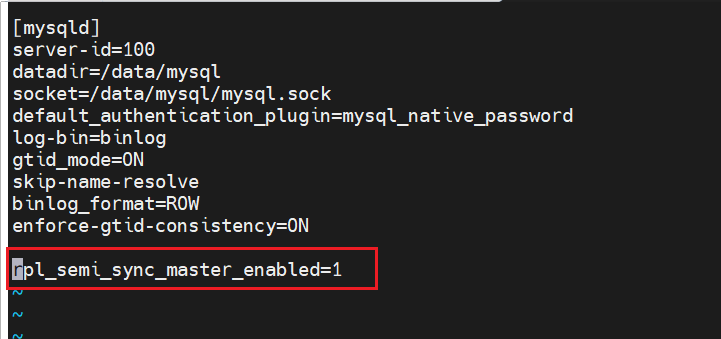

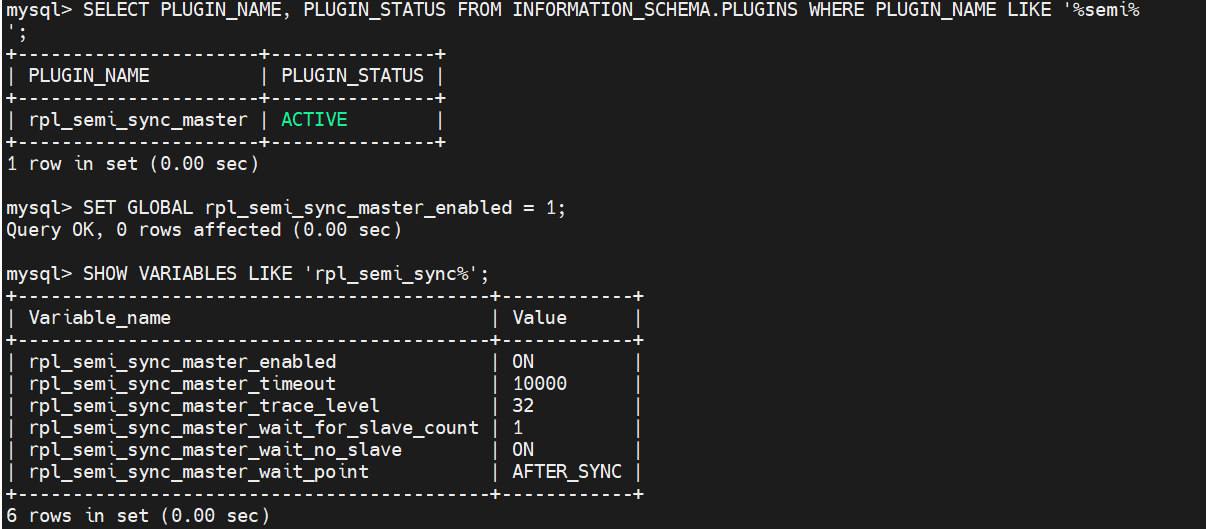
MYSQL开启时自动安装模块
在编辑文档里写
建立用于做数据同步的用户
 这里是手动开启的
这里是手动开启的
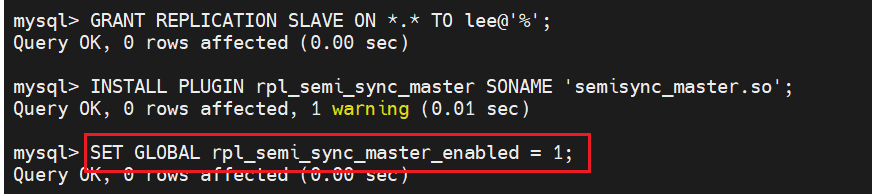
在从中


编辑文档
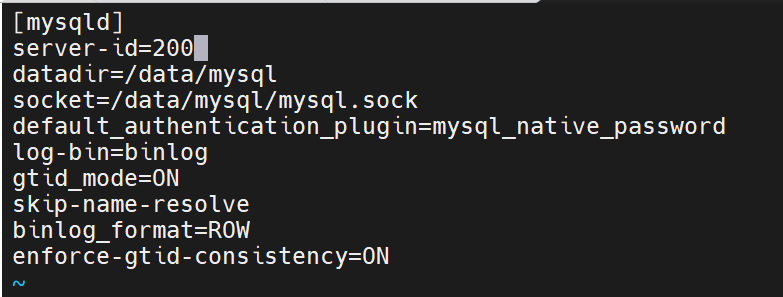
[mysqld]
server-id=200
datadir=/data/mysql
socket=/data/mysql/mysql.sock
default_authentication_plugin=mysql_native_password
log-bin=binlog
gtid_mode=ON
skip-name-resolve
binlog_format=ROW
enforce-gtid-consistency=ON


首先要做gtid模式


开启slave端的gtid




在主数据库完成半同步模式后
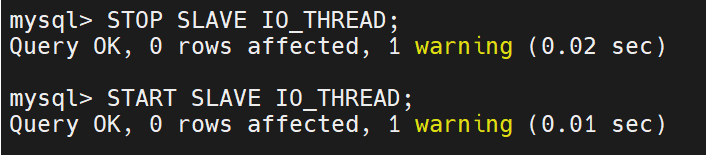
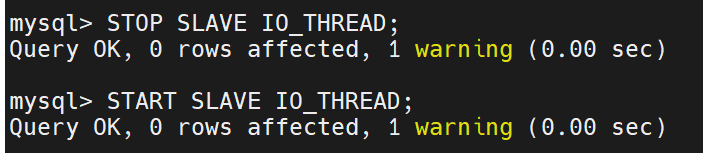
mysql> STOP SLAVE IO_THREAD; #重启io线程,半同步才能生效
Query OK, 0 rows affected (0.00 sec)mysql> START SLAVE IO_THREAD; ##重启io线程,半同步才能生效
Query OK, 0 rows affected (0.00 sec)


安装














在主服务器上也做:

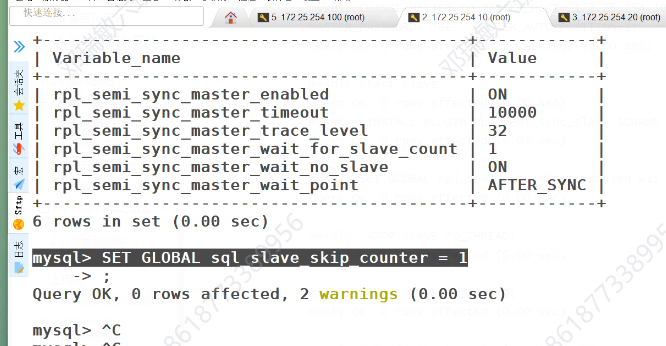
MHA上:

在其他3台数据库
![]()
![]()
设定root远程登录功能

检测配置:
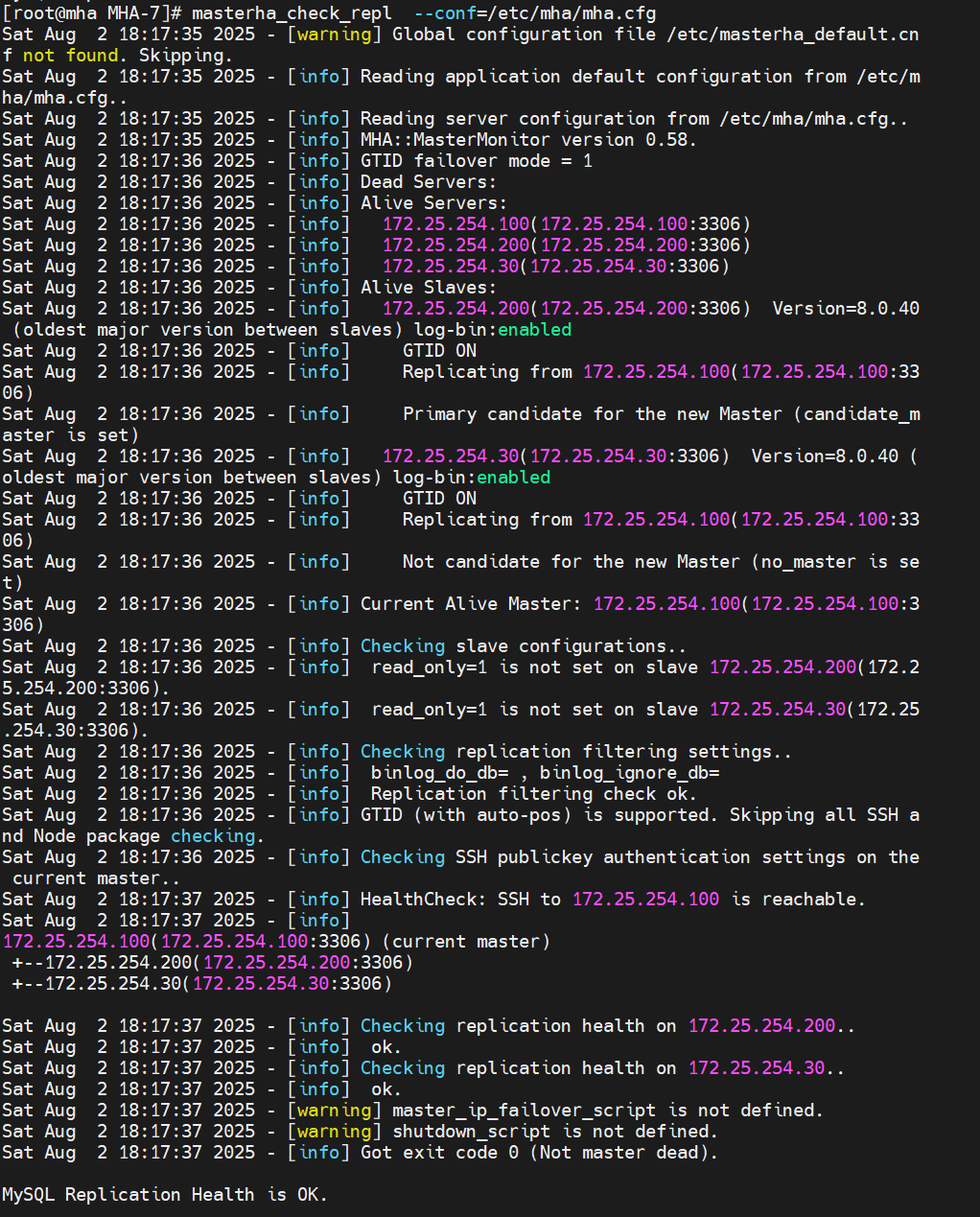
测试:
master未出现故障手动切换
masterha_master_switch --conf=/etc/mha/mha.cfg --master_state=alive --new_master_host=172.25.254.200 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
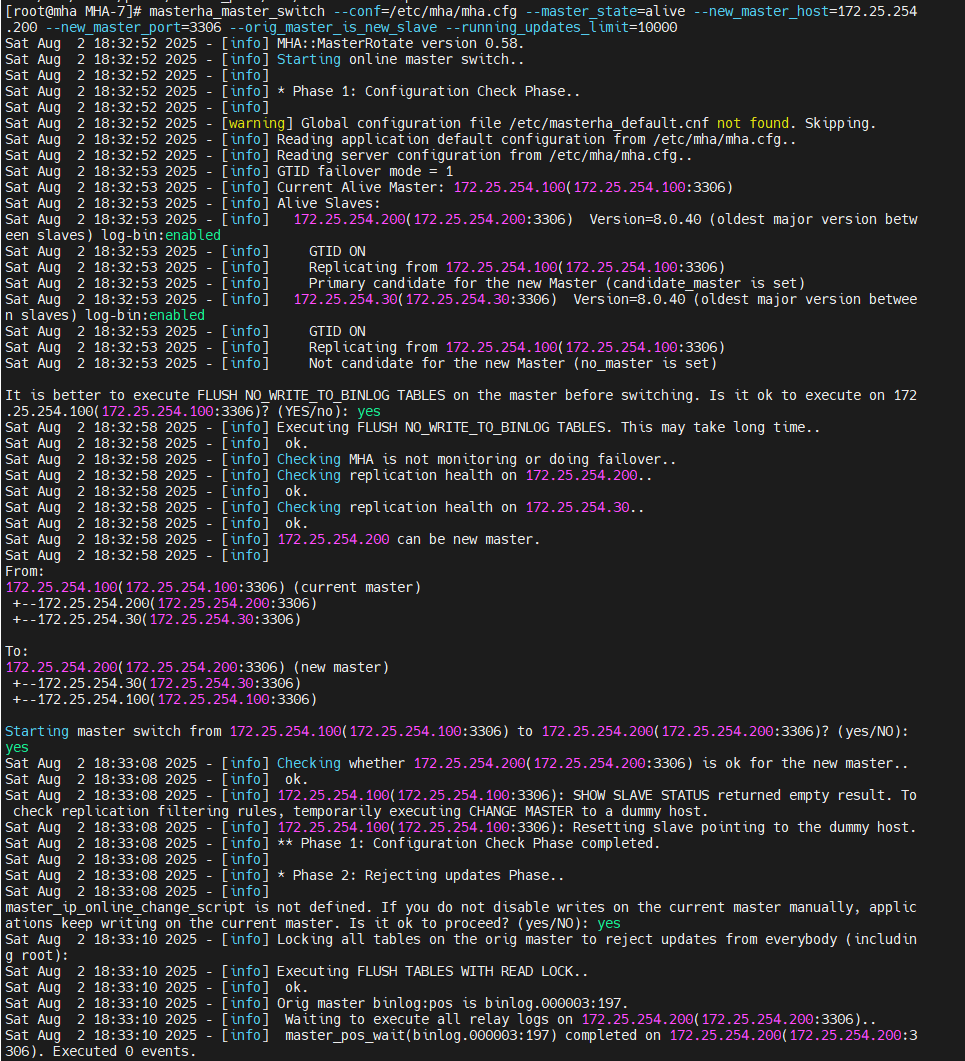
在从数据中看
之前:
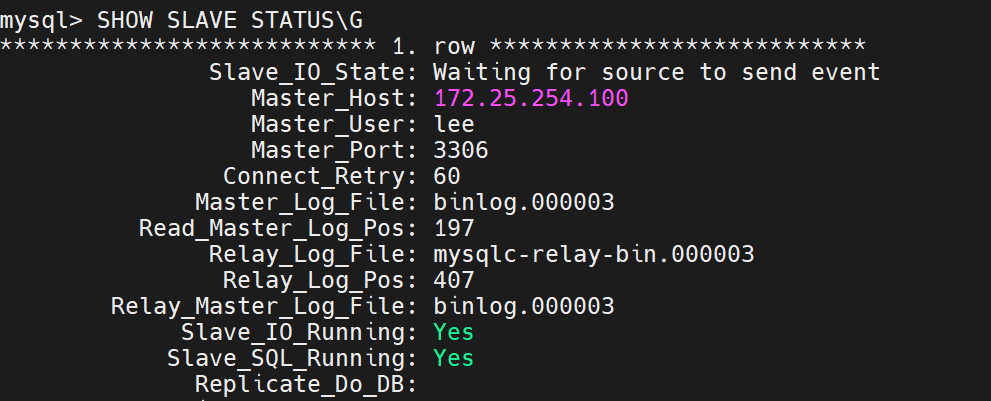
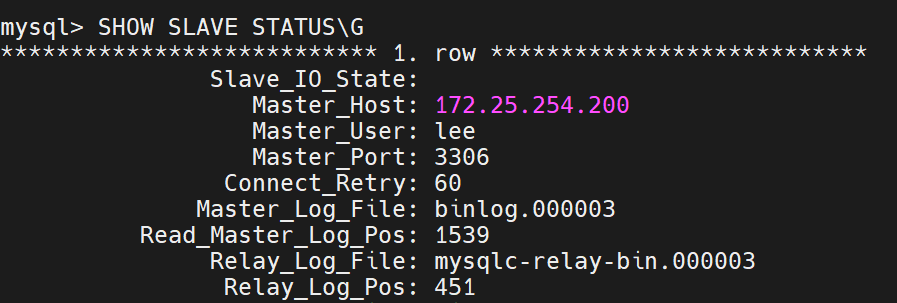
现在:
master故障手动切换




-组件)

















