目录
前言
一、模型规模爆炸:单卡GPU已难以承载
1.1 问题描述
1.2 面临挑战
1.3 解决方案:模型并行 (Model Parallelism)
1.4 类比理解:模型并行
1.5 模型并行的关键点
1.6 模型并行(Model Parallelism)的流程图和说明
1.7 一句话总结
二、计算资源需求庞大:分布式训练加速进程
2.1 问题描述
2.2 解决方案:数据并行 (Data Parallelism)
2.3 高效的数据并行与优化策略
2.4 类比理解:数据并行
2.5 一句话总结
三、内存瓶颈:不仅是模型,还有梯度和优化器状态
3.1 问题描述
3.2 内存压力来自哪里?
3.3 解决方案:ZeRO优化器与混合并行
3.3 显存压力缓解与内存优化技术
3.4 类别理解:ZeRO优化器与混合并行
3.5 场景模拟:从“爆炸”降到“可控”
3.6 一句话总结
四、总结:分布式训练,是通向大模型时代的基石
4.1 🚀 大模型训练三大核心挑战与对应解决方案总览表
4.2 🚀 大模型训练三种分布式技术对比表
4.3 🔍 数据并行 vs 模型并行:区别在哪?
4.4 🧠内存优化的具体工作流程

前言
近年来,人工智能取得了惊人的进展,尤其是在自然语言处理领域。从GPT-3到LLaMA,从PaLM到Claude,这些参数量动辄数百亿甚至上千亿的大模型正在推动智能应用的边界。然而,在这些成果背后,有一个关键的技术支撑功不可没——分布式训练。
本文将从模型规模、计算资源和内存瓶颈三个方面,深入解析为什么大模型的训练离不开分布式训练。
一、模型规模爆炸:单卡GPU已难以承载
1.1 问题描述
现代大模型的参数规模已经远远超出单张GPU的存储能力。例如:
GPT-3 拥有 1750 亿个参数
LLaMA-2 的最大版本参数超过 650 亿
GPT-4 推测模型规模更是成倍增长
以NVIDIA A100 40GB GPU为例,它能存储的模型参数量大约在100亿左右(仅存储模型参数,还未计算梯度、优化器状态等)。因此,一个完整的GPT-3模型根本无法放进一张显卡中,哪怕是最强的显卡。
1.2 面临挑战
存储需求超出单卡能力
一块高端 GPU(如 NVIDIA A100 80GB)的显存容量通常在 40GB 到 80GB 之间,而一个千亿级参数的模型,仅参数本身就可能占用数百 GB 的存储空间(以 FP16 格式计算,每个参数约占 2 字节)。此外,训练过程中还需要存储梯度、优化器状态(如 Adam 优化器的动量和方差),这些额外数据进一步加剧了存储压力。单卡 GPU 显然无法容纳如此庞大的数据量。
1.3 解决方案:模型并行 (Model Parallelism)
分布式训练通过将模型参数分布到多个 GPU 或计算节点上,解决了单卡显存不足的问题。例如,模型并行技术将模型的不同层或部分分配到不同设备上,每个设备只负责计算一部分模型。这种方式不仅突破了单卡显存的限制,还能有效利用多设备的计算能力。
将模型切分为多个部分,分别部署在不同GPU上
每张卡只负责计算一部分的前向和反向传播
常见的策略包括张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism)
1.4 类比理解:模型并行
想象一下:你家买了一个超大沙发,太长太重,一个人根本搬不动。怎么办?只能喊几个朋友一起来搬。
每个人负责搬沙发的一部分,配合好就能顺利搬进屋子里。
这就是“模型并行”的本质!
🤖 类比到深度学习模型:
-
一个超大模型就像这个“超长沙发”;
-
一张显卡就像一个人;
-
模型太大,一张卡装不下(内存不足);
-
那就把模型切成几部分,分别放在不同的显卡上,每张显卡只负责“自己那一段”的计算。
比如:
| 显卡编号 | 负责的模型部分 |
|---|---|
| GPU1 | 输入层和前几层 Transformer |
| GPU2 | 中间几层 Transformer |
| GPU3 | 后几层 Transformer 和输出层 |
它们就像一个流水线,数据从头到尾传一遍,一起合作完成一次前向传播和反向传播。
1.5 模型并行的关键点
-
切模型:把大模型按层或按矩阵拆分;
-
传中间结果:不同显卡之间要传递计算结果,就像搬沙发时要互相配合;
-
节省显存:每张卡只负责一部分内容,显存压力大大减轻;
-
牺牲通信效率:因为多张卡之间要传数据,速度可能比只用一张卡慢一些。
1.6 模型并行(Model Parallelism)的流程图和说明
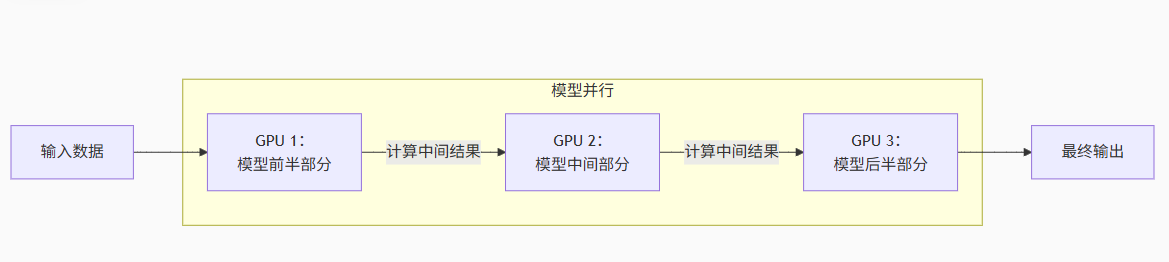
流程图解析:
1.输入数据流动
数据从左侧进入第一个 GPU(如 GPU 1)
GPU 1 计算自己负责的模型前半部分(例如神经网络的前几层)
生成中间结果传递给下一个 GPU
2.接力式计算
GPU 2 接收中间结果,计算模型中间部分(例如中间层)
再将新的中间结果传递给 GPU 3
3.输出结果
GPU 3 计算模型后半部分(例如最后几层)
生成最终输出(如预测结果)
关键特点:
-
模型被切分:单个大模型被拆解成多个子部分(如图中的前半/中间/后半)
-
设备协作:每个 GPU 只存储和计算模型的一小部分
-
顺序依赖:前一个 GPU 的计算结果是下一个 GPU 的输入(类似流水线)
-
适用场景:模型过大无法放入单张显卡时(如百亿参数大模型)
💡 对比数据并行
数据并行:每张 GPU 有完整模型副本,各自处理不同数据
模型并行:所有 GPU 合力拼成一个完整模型,共同处理同一份数据
实际应用中常结合两种技术(如 3D 并行),但模型并行核心思想始终是:拆分模型,设备协作。
1.7 一句话总结
模型并行 = 模型太大 → 切开分给多张显卡一起算,就像搬不动的大沙发找人帮忙抬
如果你觉得“数据并行”是“大家各自训练一份模型”,那“模型并行”就是“大家合力训练一个模型的不同部分”。
二、计算资源需求庞大:分布式训练加速进程
2.1 问题描述
大模型的训练不仅需要存储海量参数,还需要进行海量的计算操作。以 GPT-3 为例,其训练过程需要数万 GPU 小时的计算量,单卡训练可能需要数年时间才能完成。分布式训练通过并行计算显著加速了这一过程。
即使模型能勉强塞进显存,训练过程也极其耗时。例如:
GPT-3训练耗时:355 GPU 年(假设使用NVIDIA V100)
单卡训练将耗费数年时间,完全不可行
2.2 解决方案:数据并行 (Data Parallelism)
将训练数据划分成多个子集,每个子集在不同GPU上并行训练
每个GPU维护一个完整模型副本,仅处理自己的数据子集
每一轮训练后,通过梯度同步保持模型一致性
这种方式可以大大提升训练吞吐量,是目前工业界最常用的分布式训练范式之一。
2.3 高效的数据并行与优化策略
-
数据并行与批量处理
分布式训练中最常见的方式是数据并行,即将训练数据分成多个批次,分配到不同的 GPU 上并行计算梯度,然后通过梯度同步(如 AllReduce 操作)更新模型参数。这种方式能够充分利用多设备的计算能力,显著缩短训练时间。例如,假设单卡训练一个模型需要 100 天,使用 100 张 GPU 的数据并行可以将时间缩短到理论上的 1 天。 -
分布式优化
分布式训练还可以结合专门的优化算法,如 ZeRO(Zero Redundancy Optimizer),通过分片存储优化器状态和梯度,进一步减少内存开销,同时保持高效的计算性能。这种方法在大规模分布式训练中尤为重要,能够在数百甚至数千 GPU 上实现高效协作。
2.4 类比理解:数据并行
🍰 数据太多吃不完?那就“分蛋糕”
想象一下你和几个朋友面对一个超大的蛋糕(训练数据),要在一小时内吃完。
你一个人吃不过来,但如果把蛋糕切成几块,大家一起吃,是不是就快多了?
这就是数据并行的思路!
🤖 类比到训练大模型:
模型是一个“厨师”,大家都用同一个食谱(模型结构一样);
数据是蛋糕,太多吃不完;
那就:每张显卡(每个朋友)复制一份相同的模型,然后用不同的训练数据来“喂”这个模型;
吃(训练)完一轮后,大家把学到的经验(梯度)合并在一起同步更新。
举个例子:
假设你有4张GPU,每个 batch 是128条数据:
把128条数据平均分成4份,每张GPU处理32条;
每张卡独立前向传播 + 反向传播,得到自己的梯度;
然后一起汇总梯度,大家同步更新模型参数;
所有卡上的模型参数保持一致。
✅ 优点:
简单易实现(PyTorch、DeepSpeed、FSDP都支持);
吞吐量大大提升(多个GPU同时干活);
各GPU模型结构一样,便于管理。
2.5 一句话总结
数据并行 = 每个显卡都用同一个模型,各自处理不同的数据,然后同步学习成果
就像一个班级每个人用同样的教材做不同的题,做完后互相讨论答案,然后统一修正知识点。
三、内存瓶颈:不仅是模型,还有梯度和优化器状态
3.1 问题描述
除了模型参数,训练过程中的内存瓶颈还来自于梯度和优化器状态。以 Adam 优化器为例,每个参数需要存储对应的梯度和两个优化器状态变量(一阶动量和二阶动量)。对于一个千亿参数的模型,这些数据的内存需求可能达到参数本身的数倍。
除了模型参数本身,训练过程中还需要存储:
梯度信息:反向传播中临时产生的值
优化器状态:如Adam优化器需要为每个参数维护一阶矩估计和二阶方差估计
激活缓存:用于反向传播的中间激活值
这些都会迅速耗尽显存。以GPT-3为例,仅优化器状态就需要占用模型参数两到三倍的显存。
3.2 内存压力来自哪里?
训练大模型时显存不够,主要是因为需要同时存:
| 内容 | 举例说明 |
|---|---|
| 模型参数 | 模型的“记忆体”,比如权重矩阵 |
| 梯度 | 反向传播中计算出来的误差值 |
| 优化器状态 | 比如 Adam 优化器要记录动量信息 |
| 激活值(中间输出) | 计算过程中暂存的结果,用于反向传播时用 |
这些加起来,占用显存远超你想象。比如:
训练一个65B参数的模型,可能需要超过400GB显存!
3.3 解决方案:ZeRO优化器与混合并行
-
ZeRO (Zero Redundancy Optimizer):通过切分优化器状态、梯度、参数等方式分布在多卡上,大幅降低显存开销
-
混合并行:结合数据并行、模型并行和流水线并行,实现更高效的资源利用
3.3 显存压力缓解与内存优化技术
-
显存的动态分配
在单卡训练中,显存需要同时容纳模型参数、梯度、优化器状态以及激活值(中间计算结果)。当模型规模过大时,激活值可能占用大量显存,尤其是在处理大批量数据或长序列数据时。分布式训练通过流水线并行(Pipeline Parallelism)将模型分成多个阶段,依次在不同设备上计算,减少了单设备的显存压力。 -
内存优化技术
分布式训练还引入了多种内存优化技术,如激活值重计算(Checkpointing)和显存卸载(Offloading)。激活值重计算通过在反向传播时重新计算前向传播的中间结果,减少显存占用;显存卸载则将部分数据(如优化器状态)存储到 CPU 或 NVMe 存储器中,进一步缓解 GPU 显存压力。
3.4 类别理解:ZeRO优化器与混合并行
🍲 比喻:显卡就像一个锅,煮饭的时候锅不够大就会溢出来
想象你在煮一大锅火锅:
你有好多材料(模型参数、梯度、优化器状态)要放进去;
锅(显卡显存)太小了,一下全放进去肯定会溢锅;
所以你得分批煮、精简材料,或者换个大锅;
但现实中,大显存的显卡又贵又难搞,所以更好的办法是——优化放材料的方式。
这就是我们说的**“内存瓶颈”问题**。
🎯 解决方案:怎么让锅看起来更大?
✅ 方法1:ZeRO优化器(Zero Redundancy Optimizer)
就像大家合伙煮火锅,每个人只负责一种材料:
GPU1 保存模型参数的一部分
GPU2 保存梯度的一部分
GPU3 保存优化器状态的一部分
最终拼在一起就能完成训练,但每个GPU的负担减轻很多。
这就是 ZeRO 的核心思想:分而治之,减少重复。
✅ 方法2:梯度检查点(Gradient Checkpointing)
这就像:不记住每一道菜怎么做,反正能重新做就行。
中间的激活值不保存了,需要时再重新计算;
换空间为时间,显存省了,但训练稍慢一点;
非常适合大模型。
✅ 方法3:混合精度训练(FP16 / BF16)
就像食材切小一点,更容易煮熟:
把浮点精度从32位降到16位;
内存占用立减一半,速度还可能变快;
现在已经是标准操作(NVIDIA A100,H100支持很好)。
3.5 场景模拟:从“爆炸”降到“可控”
1、实验模型设定
我们假设有一个如下的 Transformer 模型:
模型参数量:65B(650亿)
使用的优化器:Adam
默认使用 FP32(32位精度)
Batch Size:32
使用 GPU:A100 40GB
2、各组成部分的显存占用(单位:GB)
组成部分 占用显存(FP32) 说明 模型参数 260GB 65B × 4B(每个参数用4字节存储) 梯度(grad) 260GB 每个参数对应一个梯度 优化器状态(Adam) 520GB m 和 v,各需要各1份(两倍模型参数大小) 激活值 ~100GB 跟 Batch Size 和层数相关,粗略估算 总计 1140GB+ 无优化时远超单张 GPU 显存(40GB) 是不是非常夸张?显存直接爆炸。
3、引入优化:ZeRO Stage 3 + 混合精度 + 梯度检查点
优化项 优化后占用估算 降低原因说明 模型参数切片(ZeRO) ↓到约 10–20GB 参数分布到多卡上,每卡只保留一部分 梯度切片(ZeRO) ↓到约 10–20GB 只存自己负责那部分梯度 优化器状态切片(ZeRO) ↓到约 20GB m 和 v 也切片,负担减轻 混合精度(FP16/BF16) 总体再减半 每个变量只占 2 字节,精度仍可接受 梯度检查点 激活值省一半或更多 训练时不保留中间激活,反向传播再算一遍 总计(单卡) 20–30GB 左右 控制在 A100 40GB 的范围内,训练可行
4、整体对比
优化级别 显存使用(单卡估算) 是否可训练? 无优化(纯FP32) >1000GB ❌ 完全爆炸 仅混合精度(FP16) ~500–600GB ❌ 爆炸 加ZeRO(Stage 1/2) ~100–200GB ⚠️ 需8–16张A100协作 全部优化(ZeRO-3+FP16+CP) 20–30GB ✅ 单卡可运行
✅ 结论:
原本训练 65B 模型需要上千GB显存,优化后可以压缩到几十GB,甚至单张 A100 就能运行,这就是分布式训练 + 内存优化的威力!
#
3.6 一句话总结
内存瓶颈 = 显卡显存太小,装不下训练中需要的数据,得想办法“分摊、删减、压缩”来省空间。
📌 类比总结:显存压力的三座大山
| 问题 | 比喻 | 解决方法 |
|---|---|---|
| 模型太大 | 锅太小煮不下材料 | 模型并行 / ZeRO分片 |
| 激活值太多 | 太多中间步骤要暂存 | 梯度检查点 |
| 数据太精细 | 食材太重太大 | 混合精度 / 量化 |
四、总结:分布式训练,是通向大模型时代的基石
分布式训练不是“锦上添花”,而是大模型训练的必要条件。它解决了硬件限制下的三大核心问题:
模型太大放不下?→ 模型并行
计算太慢来不及?→ 数据并行
内存不够撑不住?→ ZeRO优化与混合并行
随着模型规模的不断增长,分布式训练也在持续进化,从早期的简单数据并行,到今天集成张量并行、流水线并行、ZeRO、异构计算等技术的复杂系统。
未来的AI,将建立在更强大、更智能的分布式训练架构之上。而理解它的意义,是每一位AI工程师迈向未来的重要一步。
4.1 🚀 大模型训练三大核心挑战与对应解决方案总览表
| 问题类别 | 通俗比喻 | 原因描述 | 解决方案(技术名) | 效果说明 |
|---|---|---|---|---|
| 模型太大模型并行 | 沙发太长一个人抬不动→找多人合力抬 | 模型参数总量太大,单张显卡装不下模型结构 | 模型并行(张量并行、流水线并行) | 每张卡只存模型的一部分,减轻显存压力 |
| 数据太多数据并行 | 蛋糕太大一个人吃不完→分给多人一起吃 | 数据量太大,单卡训练太慢,GPU利用率低 | 数据并行(DDP, FSDP 等) | 每张卡处理不同数据,吞吐量提升,训练更快 |
| 内存撑不住内存优化 | 火锅太大锅装不下→分批煮、切菜小点 | 不仅有模型参数,还有梯度、优化器状态、激活值等占显存 | ZeRO 优化器、混合精度、梯度检查点 | 多卡切片 + 精度优化 + 激活重算,将显存从 TB 级降到几十 GB |
4.2 🚀 大模型训练三种分布式技术对比表
| 特点 | 模型并行 | 数据并行 | 内存优化(ZeRO / 混合精度等) |
|---|---|---|---|
| 目标 | 模型太大,卡装不下 | 数据太多,卡处理不过来 | 参数 + 梯度 + 优化器状态太大,显存撑不住 |
| 方法 | 拆模型,分到多张卡 | 复制模型,分数据到多张卡 | 切片参数/梯度/状态,+ 混合精度 + 激活重算 |
| 显存压力 | 每张卡只存部分模型 | 每张卡都存完整模型 | 显存需求大幅下降,可从TB降至几十GB |
| 通信开销 | 卡之间需要频繁通信(中间结果) | 每轮训练后同步梯度 | 高,需同步梯度、优化器状态、参数(尤其ZeRO-3) |
| 实现复杂度 | 实现复杂(如 Megatron-LM) | 实现相对简单(如 DDP/FSDP) | 中等至复杂,需使用 DeepSpeed/FSDP 等框架 |
| 典型场景 | 超大模型,单卡装不下结构(如GPT-3) | 大数据集,训练加速(如BERT预训练) | 超大模型显存爆炸,需要强力优化 |
4.3 🔍 数据并行 vs 模型并行:区别在哪?
| 项目 | 数据并行 | 模型并行 |
|---|---|---|
| 分担内容 | 每张卡处理不同数据子集,模型完全一致 | 每张卡处理模型的一部分,模型被拆开了 |
| 每张卡的模型 | 一模一样,完整复制 | 每张卡只负责部分结构 |
| 适合场景 | 模型能放下,但数据太多 / 训练太慢 | 模型太大,单卡放不下 |
| 通信方式 | 每轮训练后同步梯度(少量通信) | 每个前/反向过程都需要频繁通信 |
| 例子 | BERT、RoBERTa 预训练 | GPT-3、PaLM、LLaMA 65B/70B |
数据并行是“复制模型、分数据”;
模型并行是“拆模型、分卡算”。
4.4 🧠内存优化的具体工作流程
内存优化的核心是:把模型训练过程中占显存的部分,尽量切、压、懒加载,主要有三种手段:
1️⃣ ZeRO:把显存负担“拆开装”
问题:
原始做法下,每张卡都保存完整的:
模型参数
梯度
优化器状态(例如 Adam 的动量信息)
ZeRO 做的事:
ZeRO 阶段 拆的内容 Stage 1 切分优化器状态(比如 Adam 的 m 和 v) Stage 2 进一步切分梯度 Stage 3 连模型参数都切分,只在需要时加载 这样每张卡只负责一部分,整体显存占用成倍下降。
📌 额外补充: DeepSpeed 和 FSDP(Fully Sharded Data Parallel)都实现了类似机制。
2️⃣ 混合精度训练(FP16 / BF16)
问题:
默认使用 FP32(32位浮点),占内存大,速度慢。优化方法:
用 FP16(16位浮点) 或 BF16 表示参数、激活、梯度
内存使用几乎减半
训练速度更快
精度在大多数任务中几乎没有影响(甚至有时更稳)
3️⃣ 梯度检查点(Gradient Checkpointing)
问题:
训练过程中会缓存很多激活值(中间结果),用于反向传播。占了大量显存。优化方法:
只保存关键激活值,其他的到了反向传播时再重新计算(反正能算出来)
把显存开销换成计算时间
显著节省内存,尤其适合超深模型(如上百层 Transformer)
🧩 三者配合后的效果是:
项目 优化前 优化后(全部组合) 模型参数 每卡存全部 分布到各卡,仅存一部分 梯度 每卡存全部 分布存储或重计算 优化器状态 每卡存全部 分布存储或低精度表示 激活值 所有中间层都存 部分存,部分重算 数据精度 FP32 FP16 / BF16 总显存占用(单卡) 上百GB甚至超1TB 20~30GB内可运行(A100) 模型并行是“模型太大,切开算”;
数据并行是“数据太多,分批算”;
内存优化是“显存太小,精打细算”。


 Spring AI 1.0版本 + 千问大模型+RAG)




——攻击者使用什么漏洞获取了服务器的配置文件?)

)



结构型:桥接模式详解)
)
)



