redis就是用c语言写,但redis的string并没有直接用c语言的string,而是自己搞了一个 SDS 结构体来表示字符串。
SDS 的全称是 Simple Dynamic String,中文叫做“简单动态字符串”。
想知道为什么这么做,我们先看看c语言的string是什么样的。
C语言的string
- 本质:是 char 类型的一维数组。
- 结尾:必须以 \0 结束,表示字符串终止。
- 长度判断:靠遍历字符直到 \0 来判断长度。

c语言的string存在着以下缺点,并且也是redis不使用其的原因:
- 判断长度时不方便:
- 通过遍历到末尾的空格进行判断,复杂度为O(n)
- 扩容时不方便:
- 因为没有预分配的内存,所以每次追加数据时就得重新申请一块内存空间,十分消耗资源。并且在C语言中需要程序员手动分配内存进行扩容,若操作不当可能发生内存溢出。
- 特殊数据无法处理(二进制安全):
- 因为末尾时以结束符结尾,那么我实际要存储的数据如果末尾也是结束符,两个空格末尾就会发生冲突。而二进制数据中会很经常出现结束符,所以叫作二进制安全。
这些缺点不符合redis的高性能,为了避免这些缺点,redis自己搞了一个 SDS 结构体来表示字符串。
redis中的string
当你 set abc abcdefg 时,这个 set 命令会创建出两个 sds,一个存 key:abc,一个存 value:abcdefg。
key 和 value 在 redisDb 的 dict 中通过键值对哈希表进行映射。
sds结构如下:
struct attribute ((packed)) sdshdr8 {uint8_t len; // 字符串长度,不包含结束标示uint8_t alloc; // 分配空间unsigned char flags; // SDS类型char buf[]; // 字符数组(实际数据)
};
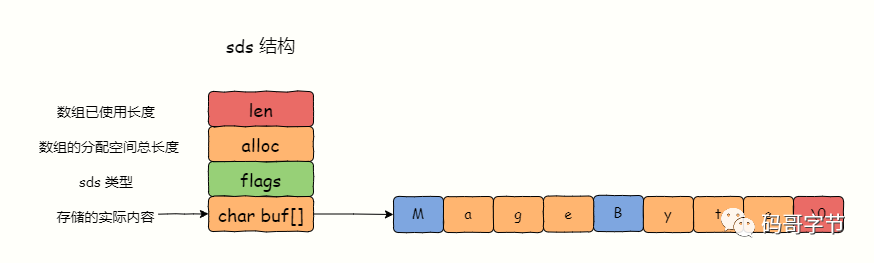
len字段的作用:
维护buf[]数组的长度,用于快速O(1)获取字符串的长度(因为字符串内容实际上存储在数组里,字符串长度等价于数组长度)。
若没有len字段维护的长度,当我们每次要获取字符串长度时,都需要从头到尾遍历得到O(n)。
alloc字段的作用:
alloc 表示预分配的内存,也就是为了容纳新增元素而预留的空间。
想象一下,若没有预分配的内存,每次新增元素时,数组会因为空间不足,去重新申请一块内存空间,十分消耗资源。
有了预分配内存后,若当前剩余的预分配内存足够容纳新增元素时,我们就不需要再去分配内存空间,这样可以大幅度减少内存分配次数,提高性能。
flags字段的作用:
表示 type(4位) 和 encoding(4位) 两个字段,加起来 8 位,用位域实现。
其中 type 表示对象的逻辑类型,例如 string、list、set 等。这里的 type 是 string;encoding 表示对象的底层编码方式,比如 int、embstr、raw 等。
buf[]字段的作用:
用于存储字符串实际内容。
扩容策略
当你要“写入数据”导致 len + 新增数据长度 > alloc 时,就会触发扩容机制。

惰性空间释放
当sds的字符串缩短了,sds的buf内会多出来一些空间,这个空间并不会马上被回收,而是暂时留着以防再用的时候进行多余的内存分配。这个是惰性空间释放的策略
SDS的优势:
优化获取字符串长度:
C语言要想获取字符串长度必须遍历整个字符串的每一个字符,然后自增做累加,时间复杂度为O(n);sds直接维护了一个len变量,时间复杂度为O(1)。
减少内存分配:
当我们对一个字符串类型进行追加的时候,可能会发生两种情况:
- 当前剩余空间(剩余空间 = alloc - len)足够容纳追加内容时,我们就不需要再去分配内存空间,这样可以减少内存分配次数。
- 当前剩余空间不足以容纳追加内容,我们需要重新为其申请内存空间。
惰性释放空间
当你对一个 Redis 字符串执行缩短操作(比如删掉部分字符)时,Redis 只更新 len 字段,而不会立刻缩小 alloc 所占的内存,多余的空间会被保留,等待将来复用,这样就避免了频繁的内存申请。
(如果你依旧想释放多余空间,Redis 提供了手动释放函数供调用。)
上面的SDS只是字符串类型中存储字符串内容的结构,Redis中的字符串分为两种存储方式,分别是embstr和raw。
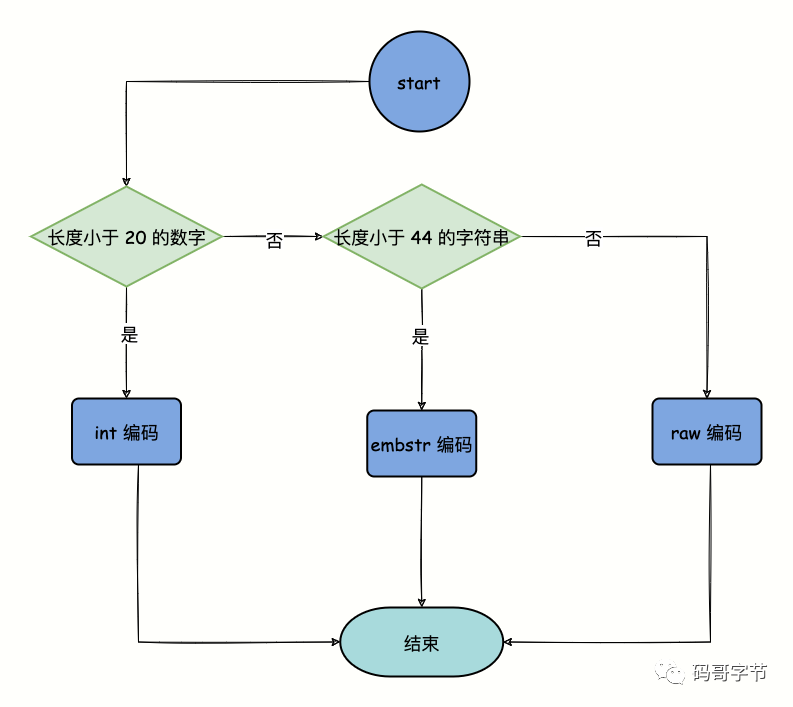
String的三种编码格式(encoding)
String 在 Redis 中有三种编码方式: int、embstr、raw 。
其中 raw 和 embstr 类型,都是基于动态字符串(SDS)实现的。
embstr
果存储在 SDS 中的数据小于等于 44 字节,则会采用 EMBSTR 编码,此时 RedisObject 与 SDS 是一段连续空间。而不是像 RAW 的编码方式一样,由 ptr 指向另外一片空间,申请内存时只需要调用一次内存分配函数,效率更高。

raw
raw 是 string 的基本编码方式,基于简单动态字符串(SDS)实现,存储上限为512mb。当一个字符串采用 raw 的编码方式的时候,它的结构如图所示。
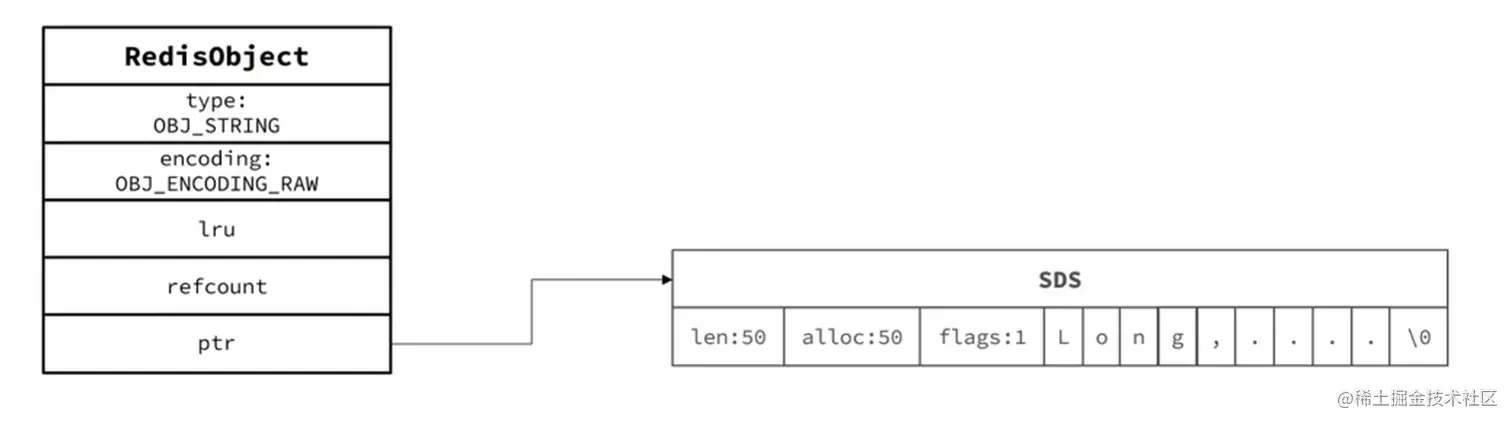
embstr的存储方式是将RedisObject对象头和SDS结构放在内存中连续的空间位置,也就是使用malloc方法一次分配,而raw需要两次malloc,分别分配对象头和SDS的空间。释放空间也一样,embstr释放一次,raw释放两次,所以embstr是一种优化,
(malloc函数用于申请内存空间)
int
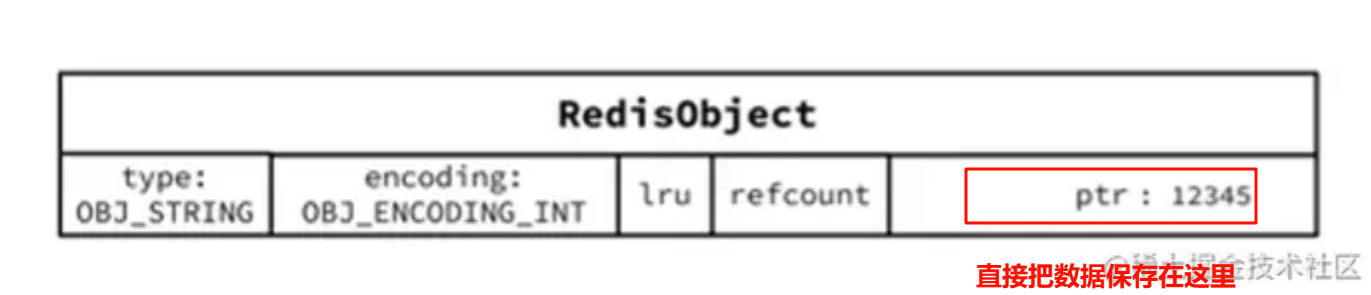
如果存储的字符串是整数值,并且大小在 LONG MAX 范围内,则会采用 INT 编码。将字符串内容转为 long,redisObject的对象 ptr 指向该long,并将 encoding 设置为 int,这样就不需要重新开辟空间,算是长整形的一个优化。直接将数据保存在 RedisObject 的 ptr 指针位置(刚好8字节),不再需要SDS了。
为什么是44字节?
原因:对象头占16字节,空的sdshdr占用4字节,也就是一个数据至少占用16+4=20字节。
其次操作系统使用jmalloc和tmalloc进行内存的分配,而内存分配的单位都是2的N次方,所以是 2,4,8,16,32,64 等字节,但是redis如果采取32的话,那么32-25=7,也太他妈少了,所以Redis采取的是64字节,所以:64-20=44。
尽量使用embstr和int编码
在使用 string 类型时,尽可能让其长度小于 44 字节,或者使用整数表示,使其使用 EMBSTR 和 INT 编码。






:Matplotlib 绘图)

)
![[2025CVPR:图象合成、生成方向]WF-VAE:通过小波驱动的能量流增强视频 VAE 的潜在视频扩散模型](http://pic.xiahunao.cn/[2025CVPR:图象合成、生成方向]WF-VAE:通过小波驱动的能量流增强视频 VAE 的潜在视频扩散模型)









