
etcd 是一个开源的分布式键值存储系统,专注于提供高可用性、强一致性的数据存储与访问,广泛应用于分布式系统的服务发现、配置管理和协调任务。以下是其核心特性和应用场景的详细介绍。
接下来就看看Etcd如何实现服务注册,以及如何通过Raft算法保证服务的强一致性和高可用性,还有只针对存储数据的watch监听回调功能。
本文的etcd的版本是3.5.20,除此之外,学习归学习,如果真的在项目中用到了etcd,一定要准备好相关的知识。
常见的etcd相关问题如下:
- 为什么要使用 etcd,怎么用的?
- Raft 算法
- etcd 是如何保证强一致性的呢
- etcd分布式锁实现的基础机制是怎样的
- 能说一说用 etcd 时它处理请求的流程是怎样的吗
一.Etcd的基础知识
1.1 什么是Etcd?
Etcd是一个开源的分布式键值存储系统。
它的设计目的就是提供高可用性和强一致性的分布式数据管理服务,也就是CAP原理中的CP原理
让我们看看官网的介绍:
- 简单:etcd 的安装简单,且为用户提供了 HTTP API,用户使用起来也很简单
- 存储:etcd 的基本功能,数据分层存储在文件目录中,类似于我们日常使用的文件系统
- Watch 机制:Watch 指定的键、前缀目录的更改,并对更改时间进行通知
- 安全通信:SSL 证书验证
- 高性能:etcd 单实例可以支持 2k/s 读操作,官方也有提供基准测试脚本
- 一致可靠:基于 Raft 共识算法,实现分布式系统数据的高可用性、一致性
1.2 Etcd的应用场景有哪些?
Etcd的使用场景很多,比如:
- 作为配置中心
- 服务注册和发现
- 分布式锁
- Watch通知
等等还有很多,在后续会介绍它的几个常用的功能。
除此之外,还要知道Etcd还和Kubernetes深度集成,使用Etcd作为默认的元数据存储组件
1.3 核心概念学习
对于后续我们要学习的内容,这里做一个简单的说明:
- key-value存储
- Lease(租约),TTL
- Watch(监听机制)
- Revision/ModRevision(MVCC)
除此之外,etcd还自带一些命令以及事务操作哦,会简单的介绍一些相关内容
二.核心功能实现
在有了上述基础的了解,就开始进一步学习一些比较重要的核心功能吧
2.1 键值存储
ETCD的核心功能就是存储键值对,支持一些基础的命令。
主要是通过etcdctl命令行工具来操作键值的,如下:
PUT:插入或更新键值。GET:获取键值。DELETE:删除键值。WATCH:监听键值变化。
# 写入键值
etcdctl put /config/app1/log_level "debug"# 读取键值
etcdctl get /config/app1/log_level
# 输出:/config/app1/log_level debug# 监听键值变化(另开一个终端执行)
etcdctl watch /config/app1/log_level2.2 服务注册和发现
在分布式环境中,业务服务多实例部署,这个时候就会涉及到服务之间的调用,就不能简单使用编码的方式指定实例信息。
服务的注册和发现就是解决如何找到分布式集群中的一个服务(进程),并与之建立联系。
接下来就来讲讲这个服务注册和发现的过程
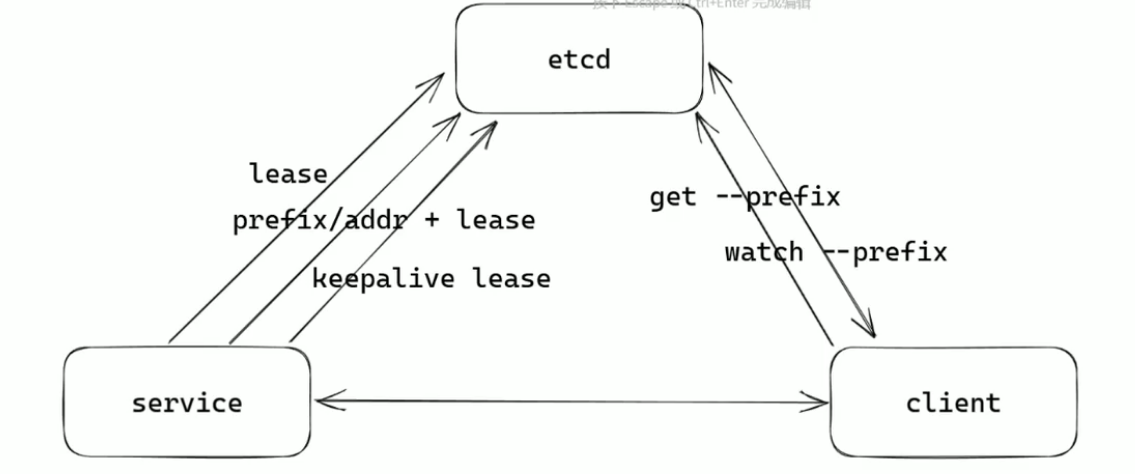
在这里说明一下:本质上键值对,租约和事务都是为这个操作服务的。
看一下服务注册的过程(带租约)
- 一开始启动服务,连接etcd
- 先向etcd发送一个请求,申请一个Lease(租约,TTL=10s)
- 在利用这个租约注册服务信息(eg:key = /services/{服务名}/{实例id})
- 后续在启动KeepAlive续租机制
- 若服务崩溃或者断线,则需要Lease失效,注册信息自动删除
服务发现的过程
- 客户端通过查询设置好的key,获取所有value
- 将这些kv保存
- 启动Watch,监听内容。做好变更
接下来,就来看一个go语言的实例
下面是我写的一个简单的案例,也是有瑕疵的,主要就是方便记忆和尝试
package etcimport ("UserServer/api/internal/config""context""fmt"clientv3 "go.etcd.io/etcd/client/v3""log""time"
)// 该服务发现是一个简单的服务发现,在发现服务之后就会关闭,结束协程
// 并不是动态监听地址的变化,不过一般也不需要,我只写了一个发现的逻辑
// 首先进行第一次的监听,如果没有发现就需要开启协程进行一个异步监听
// 如果监听到就给discover发送关闭消息,select接受到之后就会退出结束这个
// 服务发现的异步协程,释放资源
// 如果没有监听到,会进入超时,也会把这个协程释放var (discoverDone = make(chan struct{}) // 服务发现完成通知通道
)func Close() {close(discoverDone)
}// DiscoverEtcdService 阻塞式服务发现
func DiscoverEtcdService(etcd *config.Etcd) {cli, err := clientv3.New(clientv3.Config{Endpoints: []string{"localhost:2379"},DialTimeout: 5 * time.Second,})if err != nil {log.Fatal("ETCD连接失败:", err)}defer cli.Close()// 对应注册的服务名key := "/services/" + etcd.Name// 来个上下文ctx, cancel := context.WithCancel(context.Background())// 首次查询resp, err := cli.Get(ctx, key)if !handleInitialDiscovery(resp, etcd, cancel) {log.Printf("服务 %s 未注册,启动监听...", etcd.Name)}// 启动异步监听go startServiceWatch(cli, key, etcd)// 阻塞等待直到发现服务地址select {case <-ctx.Done(): // 正常发现//这个阻塞的是监听,而下面那个是则是阻塞的整个服务log.Printf("成功发现服务地址: %s", etcd.Addr)select {case <-discoverDone:fmt.Println("关闭服务")}}
}// 处理初次服务发现
func handleInitialDiscovery(resp *clientv3.GetResponse, etcd *config.Etcd, cancel context.CancelFunc) bool {if len(resp.Kvs) > 0 {// 取第一个健康实例(实际生产环境应做健康检查)etcd.Addr = string(resp.Kvs[0].Value)cancel()return true}return false
}// 启动服务监听
func startServiceWatch(cli *clientv3.Client, key string, etcd *config.Etcd) {// 1. 创建 Watcher,监听指定 keywatchChan := cli.Watch(context.TODO(), key)// 2. 持续接收事件流for watchResp := range watchChan {// 3. 遍历每个事件for _, event := range watchResp.Events {// 4. 处理事件processWatchEvent(event, etcd)}}
}// 处理watch事件(返回是否完成发现)
func processWatchEvent(event *clientv3.Event, etcd *config.Etcd) {switch event.Type {case clientv3.EventTypePut:// 只取第一个发现的地址(根据需求可改为列表)newAddr := string(event.Kv.Value)if newAddr == "127.0.0.1:50051" {log.Printf("监听到服务地址: %s", newAddr)} else {log.Printf("监听服务地址发生改变: %s", newAddr)}etcd.Addr = newAddr//close(discoverDone) // 通知主流程继续执行case clientv3.EventTypeDelete:// 生产环境需要处理节点下线逻辑log.Printf("服务实例下线: %s", string(event.Kv.Key))}
}
package etcimport ("UserServer/rpc/internal/config""context""fmt"clientv3 "go.etcd.io/etcd/client/v3""log""os""os/signal""sync/atomic""syscall""time"
)// 写一个服务注册,rpc 服务端口为127.0.0.1:50051var (shutdownFlag int32 // 原子标记位用于优雅关闭控制
)func RegisterEtcdService(etcd config.Etcd) {// 注册etcd服务etcdCli, err := clientv3.New(clientv3.Config{Endpoints: []string{"localhost:2379"},DialTimeout: 5 * time.Second,})if err != nil {log.Fatal(err)}defer etcdCli.Close() // 确保关闭连接// etcd的键key := "/services/" + etcd.NameleaseID, err := registerWithRetry(etcdCli, key, etcd.Address, 3)if err != nil {log.Fatal("初始注册失败:", err)}// 心跳协程(带重试)// 信号处理 , 用于捕获操作系统发送的信号sigCh := make(chan os.Signal, 1)// 将指定的信号(SIGINT 和 SIGTERM)绑定到通道 sigChsignal.Notify(sigCh, syscall.SIGINT, syscall.SIGTERM)// 主循环for {select {case <-sigCh:atomic.StoreInt32(&shutdownFlag, 1)log.Println("接收到关闭信号,开始清理...")revokeAndDelete(etcdCli, key, leaseID)returncase <-time.After(5 * time.Second):// 定期检查租约状态(生产环境可选)}}}// registerWithRetry 注册逻辑(自带重试)
// 参数介绍:参数是etcd的服务端+服务注册的key + 服务地址 + 重试次数
func registerWithRetry(cli *clientv3.Client, key, addr string, maxRetry int) (clientv3.LeaseID, error) {retryInterval := 1 * time.Secondfor i := 0; i < maxRetry; i++ {// 申请新租约leaseResp, err := cli.Grant(context.Background(), 15)if err != nil {log.Printf("租约申请失败(%d/%d): %v", i+1, maxRetry, err)time.Sleep(retryInterval)retryInterval *= 2 // 指数退避continue}// 注册服务if _, err = cli.Put(context.Background(), key, addr, clientv3.WithLease(leaseResp.ID)); err != nil {log.Printf("服务注册失败(%d/%d): %v", i+1, maxRetry, err)time.Sleep(retryInterval)retryInterval *= 2continue}fmt.Println("注册成功", leaseResp.ID)// 启动心跳协程go startKeepAlive(cli, leaseResp.ID, key, addr)//测试服务监听//time.Sleep(10 * time.Second)//NewLeaseResp, err := cli.Grant(context.Background(), 15)//if err != nil {// log.Printf("租约申请失败(%d/%d): %v", i+1, maxRetry, err)// time.Sleep(retryInterval)// retryInterval *= 2 // 指数退避// continue//}//if _, err = cli.Put(context.Background(), key, "127.0.0.1:50052", clientv3.WithLease(NewLeaseResp.ID)); err != nil {// log.Printf("服务注册失败(%d/%d): %v", i+1, maxRetry, err)// time.Sleep(retryInterval)// retryInterval *= 2// continue//}//fmt.Println(NewLeaseResp.ID)return leaseResp.ID, nil}return 0, fmt.Errorf("超过最大重试次数")
}// 保持心跳
func startKeepAlive(cli *clientv3.Client, leaseID clientv3.LeaseID, key, addr string) {retryCount := 0maxRetry := 3keepAliveCh, err := cli.KeepAlive(context.Background(), leaseID)if err != nil {log.Printf("心跳初始化失败: %v", err)return}for {select {case kaResp, ok := <-keepAliveCh:if atomic.LoadInt32(&shutdownFlag) == 1 {return}if !ok {log.Println("心跳通道异常关闭")if retryCount >= maxRetry {log.Fatal("连续心跳失败,终止服务")}// 尝试重新注册newLeaseID, err := registerWithRetry(cli, key, addr, maxRetry)if err != nil {retryCount++time.Sleep(time.Duration(retryCount) * time.Second)continue}log.Printf("新租约 %x 注册成功,终止旧心跳协程", newLeaseID)return}retryCount = 0log.Printf("租约 %x 心跳成功, TTL: %d", kaResp.ID, kaResp.TTL)}}
}// 清理注册信息
func revokeAndDelete(cli *clientv3.Client, key string, leaseID clientv3.LeaseID) {// 1. 撤销租约if _, err := cli.Revoke(context.Background(), leaseID); err != nil {log.Printf("租约撤销失败: %v", err)} else {log.Println("租约已撤销")}// 2. 删除键if _, err := cli.Delete(context.Background(), key); err != nil {log.Printf("键删除失败: %v", err)} else {log.Println("服务键已删除")}
}
2.3 基于Etcd的分布式锁
分布式锁的实现除了使用redis之外,使用Etcd也是可以实现的。
由于Etcd是基于Raft算法,实现分布式集群的一致性,存储到etcd集群中的值必然是一致的,因此基于etcd非常容易实现分布式锁。
这里说一下它实现的基本原理:
首先是加锁
- 创建一个唯一的key,使用put + withLease + if-not-exists
- 申请租约,分配一个TTL
- 之后定期KeepAlive,防止失效
解锁
解锁相对就比较简单了,直接删除就可以。
除此之外,还可以写成监听回调性(使用etcd的Watch机制)
来看一个简单的案例
func Lock(cli *clientv3.Client, key, value string, ttl int64) (clientv3.LeaseID, int64, error) {// 1. 创建租约leaseResp, err := cli.Grant(context.TODO(), ttl)if err != nil {return 0, 0, err}leaseID := leaseResp.ID// 2. 事务加锁(key 不存在就写入)txn := cli.Txn(context.TODO())txnResp, err := txn.If(clientv3.Compare(clientv3.CreateRevision(key), "=", 0),).Then(clientv3.OpPut(key, value, clientv3.WithLease(leaseID)),).Commit()if err != nil {return 0, 0, err}if !txnResp.Succeeded {return 0, 0, fmt.Errorf("lock failed: key already exists")}// 3. 从 Put 返回中获取 CreateRevision(用于解锁校验)putResp := txnResp.Responses[0].GetResponsePut()createRev := putResp.Header.Revisionreturn leaseID, createRev, nil
}
//返回的 createRev 你可以保存到结构体中,在解锁时使用。
func Unlock(cli *clientv3.Client, key string, createRev int64) error {txn := cli.Txn(context.TODO())txnResp, err := txn.If(clientv3.Compare(clientv3.CreateRevision(key), "=", createRev),).Then(clientv3.OpDelete(key),).Commit()if err != nil {return err}if !txnResp.Succeeded {return fmt.Errorf("unlock failed: not lock owner")}return nil
}
在后续过程中会详细介绍这个过程,可以先简单过一下。
除此之外,ETCD也提供了官方的分布式锁
go get go.etcd.io/etcd/client/v3/concurrency它的优点就是自动续期,阻塞排队,顺序节点,无需手动处理租约,还可以避免死锁,可靠性高。
import ("go.etcd.io/etcd/client/v3""go.etcd.io/etcd/client/v3/concurrency"
)func main() {cli, _ := clientv3.New(clientv3.Config{Endpoints: []string{"localhost:2379"},DialTimeout: 5 * time.Second,})defer cli.Close()// 创建 Session(带租约)session, _ := concurrency.NewSession(cli)defer session.Close()// 创建一个分布式锁对象mutex := concurrency.NewMutex(session, "/my-lock/")// 加锁(阻塞直到成功)fmt.Println("Acquiring lock...")mutex.Lock(context.TODO())fmt.Println("Got lock!")// 模拟业务处理time.Sleep(3 * time.Second)// 解锁mutex.Unlock(context.TODO())fmt.Println("Released lock.")
}
2.4 Revision
这里要介绍一下:Etcd是一个多版本并发控制的一个强一致性的KV存储,她会为每次写入操作都分配一个单调递增的Revision,每个key都会带有两个重要字段如下:
字段 | 含义 |
CreateRevision | 该 key 第一次被创建时的 revision |
ModRevision | 该 key 最近一次被修改时的 revision |
Version | 该 key 被修改了几次(包括创建) |
如果这个key不存在就表示它的createRevision=0
还记得之前的简单的分布式锁案例吗,我们回过头来看看
func Lock(cli *clientv3.Client, key, value string, ttl int64) (clientv3.LeaseID, int64, error) {// 1. 创建租约leaseResp, err := cli.Grant(context.TODO(), ttl)if err != nil {return 0, 0, err}leaseID := leaseResp.ID// 2. 事务加锁(key 不存在就写入)txn := cli.Txn(context.TODO())txnResp, err := txn.If(clientv3.Compare(clientv3.CreateRevision(key), "=", 0),).Then(clientv3.OpPut(key, value, clientv3.WithLease(leaseID)),).Commit()if err != nil {return 0, 0, err}if !txnResp.Succeeded {return 0, 0, fmt.Errorf("lock failed: key already exists")}// 3. 从 Put 返回中获取 CreateRevision(用于解锁校验)putResp := txnResp.Responses[0].GetResponsePut()createRev := putResp.Header.Revisionreturn leaseID, createRev, nil
}
//返回的 createRev 你可以保存到结构体中,在解锁时使用。Compare(CreateRevision(key), "=", 0) 这个函数就是一个比较函数,返回bool类型
这个操作就相当于:如果这个key不存在,才可以加锁。
加锁完成之后,拿到它的createRev,以确保这把锁的主人,可以写一个结构体,让他得到这些信息,这样的话,解锁的时候也可以方便一些。
这里可能有同学会好奇,为啥不用ModRev呢?
这是因为
- 如果你续租时也可能更新 key 的值(比如写入心跳信息或更新时间戳),那么
ModRevision会发生变化。 - 这时候不能用
ModRevision来判断锁的归属权,否则续租一次就“失去了身份”。 - 但如果你只是用租约续租,而不更新 key 的值(只续租 Lease 本身),那么
ModRevision不会变,此时它也可以用来判断锁归属。
三.ETCD集群架构与高可用设计
3.1 Etcd集群的核心架构
Etcd通常采用多节点集群架构,每个节点通过Raft共识算法实现数据同步。集群中的节点分为一下角色:
- Leader:负责接收客户端请求、管理日志复制和提交操作。
- Follower:被动接收 Leader 的日志并同步数据。
- Candidate:在 Leader 失效时参与选举的临时角色。
一般情况下,集群的最小规模:
为保证高可用性,ETCD集群至少需要3个节点。
四.Raft共识算法
Raft是一种分布式共识算法,广泛被应用于分布式系统中的一致性维护场景,比如:etcd等
该章节会大致说一下Raft的一些核心内容。
先说说Raft是解决什么问题的----答案显而易见就是解决分布式场景下数据不一致的问题。
接下来看看他是如何解决的吧
4.1 原理概述
Raft这些分布式共识算法就是用来多个节点之间达成共识的,其可以解决一定的一致性问题
遵循Raft算法的分布式集群中每个节点扮演三种角色,在之前也提到过:
- leader:领导者,其负责和客户端通信,接收来自客户端的命令并将其转发给follower
- follower:跟随者,其一丝不苟的执行来自leader的命令
- candidate:候选者,当follower长时间没收到 leader的消息就会揭竿而起成为候选者,抢夺成为leader的资格
从上面的描述我们可以看到节点的角色不是固定的,其会在三个角色中转换。



假设说现在有三个节点ABC,一开始都处于follower的状态。
注:在Raft算法中,所有节点会被分配不同的超时时间,时间限定在150ms~300ms之间。
为什么这么设置?
是因为如果设置相同的超时时间就会导致所有节点同时过期会导致迟迟选不出leader,看到后面就会明白。
这里150ms过去之后,A会发现怎么leader没跟我联络联络感情,是不是leader已经寄了?王侯将相宁有种乎!于是A成为候选人给自己投了一票并开创自己的时代时期 1,并给其他还没过期的follower发送信息请求它们支持自己当leader。
节点B和C在收到来自A的消息之后,又没有收到其他要求称王者的信息,于是就选择支持A节点,加入A的时代并刷新自己的剩余时间。
之后 A 得到了超过一半的节点支持,成为leader,并定时给B和C联络联络感情(心跳信息)目的是防止有节点因为长时间收不到开始反叛成candidate。
之后整个分布式集群就可以和客户端开始通信了,客户端会发送消息给leader,之后leader会保证集群的一致性并且当整个集群中的一半节点都完成客户端发送的命令之后才会真正的返回给客户端,表示完成此次命令。
上述的描述只是一个raft算法的一个概述,只是冰山一角,我们还缺少亿点点细节:
- 选举时的特殊情况
- 日志复制
在这里说一下选举时会遇见的一些特殊情况
- 新加入节点
- leader掉线
- 多个follower同时过期等
4.2 日志复制
当我们的集群完成选举之后,Leader负责接收客户端写请求,然后转化为log复制命令,发送并通知其它节点完成日志复制请求。每个日志复制请求包括状态机命令,任期号,同时还有前一个日志的任期号和日志索引。
- 状态机命令表示客户端请求的数据操作指令。
- 任期号表示 leader 的当前任期,任期也就是上图中的时期。
说一下流程:
- 客户端请求发送到 Leader。
- Leader 将请求封装为日志条目,追加到本地日志。
- Leader 并行向所有 Follower 发送 AppendEntries(携带日志)。
- 若多数 Follower 成功写入,则日志被“提交”(commit)。
- Leader 向客户端返回结果,并将日志应用到状态机。
Follower 持久化日志后返回成功,失败则 Leader 重试。
看一下Follower收到日志复制命令需要执行的处理流程:
- follower 会使用前一个日志的任期号和日志索引来对比自己的数据:
- 如果相同,接收复制请求,回复 ok;
- 否则回拒绝复制当前日志,回复 error;
- leader 收到拒绝复制的回复后,继续发送节点日志复制请求,不过这次会带上更前面的一个日志任期号和索引;
- 如此循环往复,直到找到一个共同的任期号&日志索引。此时 follower 从这个索引值开始复制,最终和 leader 节点日志保持一致;
这里为什么不直接用任期号来判断的原因:任期号只是单调递增但不唯一标识日志,他只只是表示时期,但不是表示日志
)





)





 集成阿里云短信验证码)





策略模式:思维链CoT和ReAct)
