一、Introduction
1.目前存在的问题:
(deep)Q-learning:在一些简单问题上表现不佳,可理解性差
基础的policy gradient算法:(如REINFORCE)鲁棒性差,需要大量数据
TRPO:复杂,在包含噪音(如dropout)或者权重共享机制的问题中不兼容
在扩展性、数据利用率以及鲁棒性上还有上升空间
二、背景知识:策略优化
1.策略梯度方法
策略梯度中常用的gradient estimator格式:
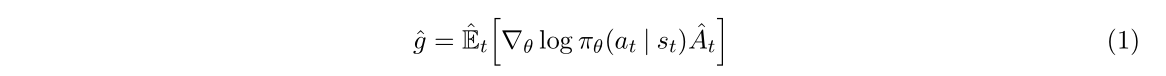
相对应的目标函数:
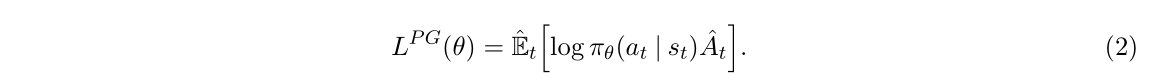
2.Trust Region方法(TRPO)
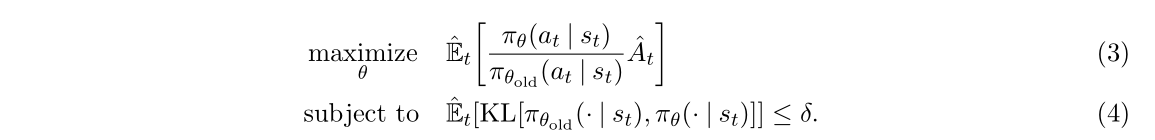
加入拉格朗日因子变成:
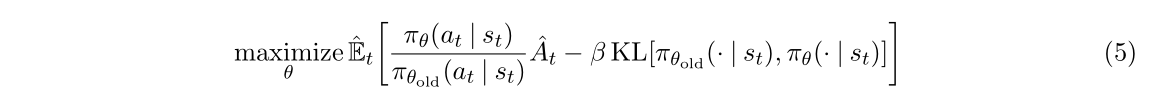
问题:很难选择一个确定的β在所有问题 甚至某一类问题上都表现的很好。
三、引入Clipped形式
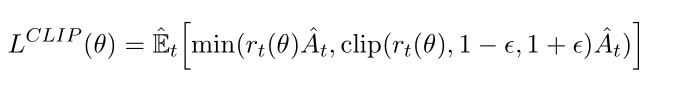
1.限制过度乐观:
这个式子的形式很巧妙,使用clip来防止结果过于激进:如A>0时如果r超过1+E就进行截断处理,A<0时如果r小于1-E就进行阶段处理。
当新策略试图对旧策略已经做得不错(A_t > 0)的地方进行过于激进的改进(r_t >> 1),或者对旧策略做得不好(A_t < 0)的地方进行过于激进的避免(r_t << 1)时,PPO会踩刹车(裁剪),防止策略突然偏离太远导致崩溃。
2.允许必要的悲观修正
但是不会阻止悲观的结果:如果A>0且r<1-E则不进行截断处理,A<0时r>1+E时不进行截断处理。这是为了激励模型积极学习,下面是解释:
- 情景一 (A_t>0, r_t<<1):
r_t*A_t是一个很小的正数(甚至可能变负),而clip(r_t, 1-ε, 1+ε)*A_t ≈ (1-ε)*A_t是一个较大的正数。所以min选择了很小的r_t*A_t。 - 情景二 (A_t<0, r_t>>1):
r_t*A_t是一个很大的负数(因为负的A_t被放大了),而clip(r_t, 1-ε, 1+ε)*A_t ≈ (1+ε)*A_t是一个较小的负数(负的A_t被缩小了)。所以min选择了很大的负数r_t*A_t。 目标函数的含义: PPO的目标是最大化这个
min(...)函数的值。梯度更新的方向: 为了最大化目标函数:
在情景一中,目标函数取了一个很小的值(甚至负值)。为了最大化它,优化器会强烈地推动策略参数 θ 朝着增加
r_t(θ)(即增加选择这个好动作的概率)的方向更新。在情景二中,目标函数取了一个很大的负值。为了最大化它(即让这个负值变得不那么负),优化器会强烈地推动策略参数 θ 朝着减少
r_t(θ)(即减少选择这个坏动作的概率)的方向更新。
“积极更新”的体现: 由于目标函数值在错误方向上非常差(很小或很负),优化器计算出的梯度(更新方向)的幅度会非常大。这导致参数 θ 会在这个方向上迈出相对较大的一步,迅速纠正这个错误。这就是“允许更积极地更新”的数学体现。
想象你在训练一个机器人走路(策略)。PPO的clip机制就像给机器人脚上装了带弹簧的限制器([1-ε, 1+ε])。
当机器人想迈出一个非常大的步子向前冲(乐观更新,可能跌倒)时,弹簧限制器会拉住它(裁剪),只允许它迈出安全的一步。
但当机器人不小心踩空,即将向后摔倒(严重错误,性能崩溃)时,弹簧限制器不会阻止它把脚快速收回来重新站稳(不裁剪,允许积极纠错)。如果这个时候限制器还强行拉住脚不让它收回来,机器人肯定会重重摔倒。PPO选择松开限制器,让机器人能迅速做出挽救动作
说白了就是允许严重的错误,而模型为了纠正这个错误会强烈推动策略参数的更新。
四、Adaptive KL Penalty Coefficient
论文中指出了一个替代或者补充方法,就是增加KL惩罚项,但是这个的表现明显比clip的糟糕。

五、算法完整过程
最终算法是要梯度上升下面这个式子来实现参数更新:

其中CLIP就是三中的式子,不再介绍。VF表示和target的损失函数,S表示熵奖励(为了提高模型中的探索性)。

这里解释一下VF:因为我在学习强化学习的时候感受到的强化学习和监督/无监督学习的主要区别就是解决的问题不同,监督/无监督学习主要是为了优化,是可以有固定的标签的,只是训练的时候给不给的问题(或者好不好获得),但强化学习是关于和环境交互学习策略的,是没有办法获得具体标签的,所以强化学习的目标是最大化state value而监督/无监督学习是最小化和target之间的loss函数。但是这里的VF感觉像是监督学习了。
答:虽然强化学习整理是“无监督” 的,但是在训练值函数的时候可以构造一个"伪标签"。也就是说这里的target不是环境直接给的target,而是我们基于经验计算的目标。
VF项的展开公式是![]() ,其中Vθ(st)是为了估计每个状态的价值而构建的值函数网络,训练时,我们用采样得到的经验去构造目标值 Vtarg,再用 均方误差(MSE) 来回归这个目标值。
,其中Vθ(st)是为了估计每个状态的价值而构建的值函数网络,训练时,我们用采样得到的经验去构造目标值 Vtarg,再用 均方误差(MSE) 来回归这个目标值。





)







——社交网络分析)





