摘要
新能源工厂明明用着风电、光伏等清洁能源,碳排放数据却依旧居高不下?某锂电池厂耗费百万升级设备,碳足迹却难以精准追踪,能源调度全靠经验“拍脑袋”,导致成本飙升。而隔壁企业通过可视化碳中和实验,碳足迹看板实时“揪出”高排放环节,能源调度仿真系统让每度电都用在刀刃上,年度碳排放量直降35%,成本降低20%。新能源工厂如何用可视化技术实现碳中和目标?本文将拆解碳足迹追踪与能源调度仿真的实战路径,揭秘数据如何驱动绿色生产变革。
一、新能源工厂为何需要可视化碳中和实验?
1. 碳中和目标下的现实困境
新能源工厂虽以“绿色”为标签,却暗藏三大痛点:
- 碳足迹模糊不清:生产环节复杂,从原料加工到产品运输,碳排放数据分散在多个系统,人工统计误差超20%。某光伏组件厂曾因漏算物流环节碳排放,导致碳核算报告与实际值偏差巨大。
- 能源调度低效:依赖人工经验分配电力,无法实时响应风光发电的波动性。例如风电过剩时,仍使用储能设备供电,造成能源浪费。
- 决策缺乏依据:管理层难以直观掌握碳排放与能源消耗的关系,制定减排策略如同“盲人摸象”。

2. 可视化技术的破局价值
可视化碳中和实验就像给工厂装上“智慧大脑”:
- 数据透明化:通过碳足迹追踪看板,将隐性碳排放转化为直观图表,异常数据自动标红预警;
- 策略科学化:能源调度仿真系统模拟不同策略效果,提前预判节能减排潜力;
- 效率最大化:实时监控能源流向,动态调整生产计划,降低能源浪费。
3. 新能源工厂的特殊需求
需求维度 | 传统方式局限 | 可视化碳中和方案优势 |
碳排放监测 | 人工报表滞后,难以定位源头 | 秒级更新,精准定位高碳环节 |
能源波动性应对 | 无法匹配风光发电不稳定特性 | 实时调整能源分配,提升消纳率 |
减排策略验证 | 依赖经验,试错成本高 | 仿真模拟,量化评估策略效果 |
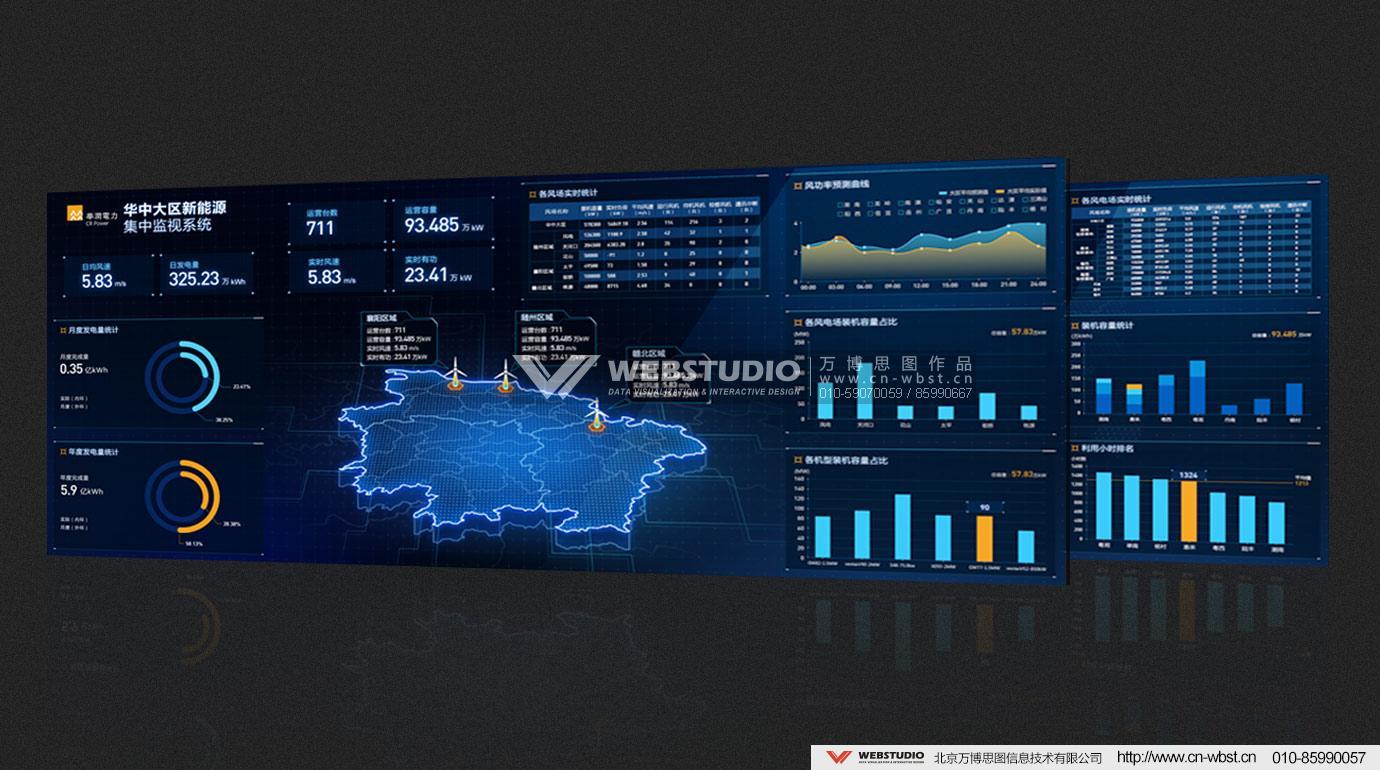
二、碳足迹追踪看板:让碳排放“无处遁形”
1. 数据采集与计算逻辑
- 全链路数据采集:在生产设备、运输车辆、仓储环节部署传感器,采集电力消耗、燃油使用、物料流转等数据。例如,通过电表实时获取车间耗电量,结合排放因子计算碳排放量。
- 碳排放核算模型:采用“活动数据×排放因子”公式,将不同环节碳排放分类汇总。公式示例:

- 数据校验机制:建立历史数据对比、相邻工序数据交叉验证规则,确保数据准确性。若某生产线碳排突然激增100%,系统自动触发人工复核。
2. 看板可视化设计
- 核心指标展示:
- 总碳排放量:用动态柱状图展示每日/月变化趋势;
- 高碳环节TOP3:以热力图高亮显示碳排放占比超30%的工序;
- 碳强度:对比行业标杆值,用仪表盘显示达标进度。
- 交互功能设计:点击图表可下钻查看详细数据,如某设备的每小时碳排放曲线;支持时间筛选,对比不同时段减排效果。
3. 案例:某氢能工厂的碳足迹革命
某氢能工厂通过碳足迹看板发现:制氢环节碳排放占比65%,其中电解槽能耗过高是主因。通过优化电解参数,单月碳排放量降低18吨,相当于种植900棵成年树木的固碳量。
三、能源调度策略仿真:用数据“彩排”节能方案
1. 仿真系统核心原理
能源调度仿真就像给工厂“虚拟彩排”,通过构建数字孪生模型,模拟不同能源分配策略的效果:
- 模型构建:将风光发电、储能设备、生产线等要素数字化,设定设备参数(如风机发电效率曲线)和约束条件(如生产线最低供电需求)。
- 策略模拟:输入不同调度方案(如优先使用光伏电、储能优先放电等),系统计算能耗、碳排放、成本等指标。
- 结果评估:对比各方案数据,输出最优策略建议,例如“在光照充足时段,生产线100%使用光伏发电”。
2. 实施步骤详解
- 数据建模:收集历史能源数据、设备参数,搭建仿真模型;
- 场景设计:预设典型场景(晴天/阴天、峰谷电价时段),设计10种以上调度策略;
- 仿真运行:利用Python或专用仿真软件(如AnyLogic)运行模型,生成数据报告;
- 策略落地:将最优方案同步至能源管理系统,实现自动调度。
3. 效果对比:某锂电池厂的能源转型
指标 | 人工调度 | 仿真优化后 | 提升幅度 |
能源利用率 | 75% | 92% | 22.7% |
单位产品能耗 | 15kWh | 12kWh | 20% |
日碳排放量 | 50吨 | 32吨 | 36% |
四、从实验到落地:新能源工厂的实施指南
1. 前期准备工作
- 明确目标:确定核心需求,如优先降低碳排放量还是能源成本;
- 数据摸底:梳理现有数据采集渠道,评估数据完整性;
- 技术选型:选择成熟的可视化平台(如ThingJS、帆软)和仿真软件。
2. 系统建设与调试
- 硬件部署:加装智能电表、物联网传感器,打通数据传输链路;
- 看板开发:设计界面原型,经业务部门确认后开发上线;
- 仿真验证:在测试环境运行模型,邀请工程师参与策略优化。
3. 持续优化与迭代
- 动态监控:每日分析看板数据,及时发现新的高碳点;
- 策略更新:每季度根据生产计划调整仿真模型参数;
- 员工培训:开展系统使用培训,确保一线人员能反馈优化建议。
总结
新能源工厂的可视化碳中和实验,通过碳足迹追踪看板与能源调度策略仿真的双轮驱动,让减排从模糊目标变为可操作的具体行动。某氢能工厂、锂电池厂的实践证明,这种数据驱动的绿色生产方式,不仅能显著降低碳排放和能源成本,更能为企业可持续发展提供坚实支撑。从数据采集到策略落地,每个环节都需要科学规划与持续优化。未来,随着物联网、人工智能技术的发展,可视化碳中和将在新能源行业发挥更大价值,助力企业在绿色转型浪潮中抢占先机。




采用分布式哈希表优化区块链索引结构,提高区块链检索效率)
配置元件详解01)


)
--Cartographer在Gazebo仿真环境下的建图以及建图与定位阶段问题(实车也可参考))



)





