目录
一、Numpy
1.NumPy 是什么?
1.1安装numpy
1.2 导入numpy模块
2.NumPy 的核心:ndarray
2.1 什么是 ndarray?
2.2 ndarray 的创建方式
2.3 常见属性(用于查看数组结构)
2.4 ndarray 的切片与索引
2.5 ndarray 的运算(向量化)
2.6 ndarray 的形状变换
2.7 数据类型转换
3.NumPy 的常见功能
4.NumPy 的优势
5.使用场景
6.简单示例
二、Pandas
1.Pandas是什么?
1.1安装 Pandas
1.2 导入 Pandas 模块
2.核心数据结构
2.1 Series(一维标签数组)
2.1.1创建Series的常见方法
2.1.1.1 创建 Series 空对象
2.1.1.2 ndarray 创建 Series 对象
2.1.1.3 字典创建 Series 对象
2.1.2遍历Series
2.2 DataFrame(二维表格型数据)
2.2.1 创建 DataFrame 对象
2.2.1.1 创建空对象
2.2.1.2 列表嵌套字典
2.2.1.3 字典嵌套列表
2.2.1.4 使用Series
2.2.2 列索引操作
2.2.2.1 选取数据
2.2.2.2 添加数据
2.2.2.3 修改数据
2.2.2.4 删除数据
2.2.3 行索引操作
2.2.3.1 loc 选取数据
2.2.3.2 iloc 选取数据
2.2.3.3 切片多行选取
2.2.3.4 添加数据行
2.2.3.5 删除数据行
3.函数
3.1 常用的统计学函数
3.2 重置索引
3.3 遍历
3.3.1 DataFrame 遍历
3.4 排序
3.4.1 sort_values
3.5 去重
3.6 分组
3.7 合并
3.8 空值处理
3.8.1 检测空值
3.8.2 填充空值
3.8.3 删除空值
4. 读取CSV文件
4.1 to_csv()
4.2 read_csv()
5.Pandas绘图基础
5.1 折线图(默认)
5.2 柱状图
5.3 直方图(hist)
5.4 饼图(pie)
三、Matplotlib
1.概念
2.安装
3.应用场景
4.常用API
4.1 绘图类型
4.2 Image 函数
4.3 Axis 函数
4.4 Figure 函数
5.pylab 模块
6.常用函数
6.1 plot 函数
6.2 figure 函数
6.2.1 figure.add_axes()
6.2.2 axes.legend()
6.3 标题中文乱码
6.4 subplot 函数
6.5 subplots 函数
7.绘制图表
7.1 柱状图
7.2 直方图
7.3 饼图
7.4 折线图
7.5 散点图
7.6 图片读取
四、常见的镜像源网站
1.pip 常用镜像源网址
2.conda 常用镜像源网址(Anaconda)
一、Numpy
1.NumPy 是什么?
NumPy(Numerical Python) 是 Python 科学计算的基础包。它提供了:
高性能的 多维数组对象(ndarray)
广播功能(Broadcasting)
向量化运算(比 Python 原生循环更快)
丰富的 数学函数库
用于数值计算、线性代数、傅里叶变换、随机数等科学运算
1.1安装numpy
#安装numpy
pip install numpy大家可以自行添加合适的镜像源,常见的镜像源在之前的文章有介绍,在本文章末尾会再次介绍
1.2 导入numpy模块
import numpy as np习惯上使用 np 作为别名,方便简洁书写。
2.NumPy 的核心:ndarray
2.1 什么是 ndarray?
ndarray是 NumPy 的核心类,代表一个 多维数组对象全称是 N-dimensional array
用于存储同一种数据类型的元素(int、float、bool 等)
支持 向量化运算、广播机制、高效索引切片 等高级功能
2.2 ndarray 的创建方式
import numpy as np
a = np.array([1, 2, 3]) # 创建一维数组
b = np.array([[1, 2], [3, 4]]) # 创建二维数组
c = np.zeros((2, 3)) # 创建全 0 数组
d = np.ones((3, 3)) # 创建全 1 数组
e = np.arange(0, 10, 2) # 类似 range
f = np.linspace(0, 1, 5) # 线性间隔2.3 常见属性(用于查看数组结构)
| 属性名 | 说明 | 示例值 |
|---|---|---|
.ndim | 数组的维度 | 1、2、3... |
.shape | 各维度的大小(元组) | (2, 3) |
.size | 数组中元素总数 | 6 |
.dtype | 数组中元素的数据类型 | int32、float64 |
.itemsize | 每个元素的字节大小 | 4、8(视类型而定) |
.data | 指向实际数据的内存地址 | (一般不直接使用) |
示例:
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a.ndim) # 输出: 2
print(a.shape) # 输出: (2, 3)
print(a.size) # 输出: 6
print(a.dtype) # 输出: int642.4 ndarray 的切片与索引
和 Python 的列表类似,但功能更强大:
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a[0, 1]) # 取第一行第二列,输出:2
print(a[1, :]) # 第二行全部,输出:[4 5 6]
print(a[:, 0]) # 所有行第一列,输出:[1 4]2.5 ndarray 的运算(向量化)
普通运算将自动应用到所有元素(无需 for 循环):
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print(a + b) # 输出:[5 7 9]
print(a * 2) # 输出:[2 4 6]
print(np.sqrt(a)) # 输出:[1. 1.4142 1.7320]2.6 ndarray 的形状变换
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a.reshape(3, 2)) # 重塑形状为 3 行 2 列
print(a.T) # 转置
print(a.flatten()) # 转为一维数组2.7 数据类型转换
a = np.array([1.2, 3.4])
print(a.dtype) # float64
print(a.astype(int)) # 转换为整数型:[1 3]总结:为什么使用 ndarray?
-
高性能(基于 C 实现,避免 Python for 循环)
-
可用于处理大规模数据(图像、信号、机器学习等)
-
支持矩阵运算、广播机制、向量化计算等
-
是 Pandas、TensorFlow、Scikit-learn 等库的底层依赖
3.NumPy 的常见功能
| 功能类别 | 说明 | 示例函数或方法 |
|---|---|---|
| 数组创建 | 快速创建数组 | np.array(), np.zeros(), np.ones(), np.arange() |
| 数组操作 | 形状变换、转置、拼接、切片 | .reshape(), .T, np.concatenate() |
| 数学运算 | 对整个数组执行加减乘除、三角函数 | np.add(), np.sin(), np.mean() |
| 广播机制 | 自动扩展形状维度,使数组可运算 | 不同形状自动对齐操作 |
| 随机数生成 | 生成随机整数、浮点数 | np.random.randint(), np.random.rand() |
| 线性代数 | 矩阵乘法、求逆、特征值 | np.dot(), np.linalg.inv() |
| 文件读写 | 保存和加载 .npy, .txt 文件 | np.save(), np.load() |
4.NumPy 的优势
速度快:基于 C 实现,比 Python 原生循环快几十倍以上
代码简洁:一行代码即可实现复杂数学操作
兼容性强:是 Pandas、Matplotlib、Scikit-learn 等库的底层依赖
便于科学计算:适合处理大规模矩阵和向量数据
5.使用场景
数据预处理(如标准化)
图像处理(图像就是像素矩阵)
机器学习(数据矩阵运算)
数值模拟(如模拟股票、物理系统)
学术研究和工程应用
6.简单示例
import numpy as np
# 创建一个 3x3 的数组
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 求和、平均值、转置
print(np.sum(a)) # 输出:45
print(np.mean(a)) # 输出:5.0
print(a.T) # 输出转置矩阵
# 向量加法(广播)
b = np.array([1, 2, 3])
print(a + b)二、Pandas
1.Pandas是什么?
Pandas 是一个开源的第三方 Python 库,从 Numpy 和 Matplotlib 的基础上构建而来
Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分析)
Pandas 已经成为 Python 数据分析的必备高级工具,它的目标是成为强大、灵活、可以支持任何编程语言的数据分析工具
Pandas 是 Python 语言的一个扩展程序库,用于数据分析
Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域
Pandas 的出现使得 Python 做数据分析的能力得到了大幅度提升,它主要实现了数据分析的五个重要环节:加载数据、整理数据、操作数据、构建数据模型、分析数据
1.1安装 Pandas
pip install pandas大家可以自行添加合适的镜像源,常见的镜像源在之前的文章有介绍,在本文章末尾会再次介绍
建议搭配 numpy、jupyter、matplotlib 一起使用。
1.2 导入 Pandas 模块
import pandas as pd习惯上使用 pd 作为别名,方便简洁书写。
2.核心数据结构
2.1 Series(一维标签数组)
import pandas as pddata = pd.Series([10, 20, 30, 40], index=['a', 'b', 'c', 'd'])
print(data)特点:
类似于一维数组,但带有索引(标签);
支持 NumPy 的大多数操作;
可以通过标签或位置访问元素。
data['b'] # 通过标签
data[1] # 通过位置2.1.1创建Series的常见方法
2.1.1.1 创建 Series 空对象
import pandas as pd
# Series 空对象
def one():series_one = pd.Series(dtype='f8')print('空对象:\n', series_one)直接赋值创建Series 对象
series_one = pd.Series([1,2,3,4,5], dtype='f8')
print('Series对象:\n', series_one)2.1.1.2 ndarray 创建 Series 对象
import pandas as pd
import numpy as np
array_one = np.array(['小明', '小红', '小紫'])
series_one = pd.Series(data=array_one)
print('ndarray 创建 Series 对象:')
print(series_one)
# 输出:
0 小明
1 小红
2 小紫
dtype: object2.1.1.3 字典创建 Series 对象
import pandas as pd
# 字典创建 Series 对象
data = {"name": "zhangsan", "gender": "男"}
result = pd.Series(data=data)
print('字典创建 Series 对象:')
print(result)
# 输出:
name zhangsan
gender 男
dtype: object2.1.2遍历Series
使用 items()
import pandas as pd
# 创建一个示例 Series
series = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
for index, value in series.items():print(f"Index: {index}, Value: {value}")#输出:
Index: a, Value: 1
Index: b, Value: 2
Index: c, Value: 3使用 index 属性
import pandas as pd
# 创建一个示例 Series
series = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
# 遍历索引
for index in series.index:print(f"Index: {index}, Value: {series[index]}")#输出:
Index: a, Value: 1
Index: b, Value: 2
Index: c, Value: 3使用 values 属性
import pandas as pd
# 创建一个示例 Series
series = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
# 遍历值
for value in series.values:print(f"Value: {value}")# 输出:
Value: 1
Value: 2
Value: 32.2 DataFrame(二维表格型数据)
| 函数名 | 参数 |
|---|---|
| pd.DataFrame( data, index, columns, dtype, copy) | data:一组数据(ndarray、series, map, lists, dict 等类型) index:索引值,或者可以称为行标签 columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) dtype:数据类型 copy:默认为 False,表示复制数据 data |
Dataframe和Series的关系:
在 Pandas 中,DataFrame 的每一行或每一列都是一个 Series。
DataFrame 是一个二维表格,可以看作是由多个 Series 组成的。
如何区分行和列的 Series:
列的
Series:
标签是行索引。
值是该列的所有行数据。
行的Series:
标签是列名。
值是该行的所有列数据。
示例:
# 创建一个 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data)# 列的 Series
print(df['A']) # 标签是行索引,值是列 A 的所有行数据
# 行的 Series
print(df.loc[0]) # 标签是列名,值是第 0 行的所有列数据# 输出:
0 1
1 2
2 3
Name: A, dtype: int64
A 1
B 4
C 7
Name: 0, dtype: int642.2.1 创建 DataFrame 对象
创建 DataFrame 对象的方式:
2.2.1.1 创建空对象
import pandas as pd
# 创建 DataFrame 空对象
def one():result = pd.DataFrame()print(result)2.2.1.2 列表嵌套字典
案例:如果其中某个元素值缺失,也就是字典的 key 无法找到对应的 value,将使用 NaN 代替。
import pandas as pd
# 列表嵌套字典创建 DataFrame 对象
def four():data = [{'name': "张三", 'age': 18},{'name': "小红", 'gender': "男", 'age': 19}]result = pd.DataFrame(data=data)print(result)# 输出:name age gender
0 张三 18 NaN
1 小红 19 男2.2.1.3 字典嵌套列表
案例:
import pandas as pd
# 典创建 DataFrame 对象
def five():data = {"name":['小米','小红','小紫'],"age":[18,19,20]}result = pd.DataFrame(data=data)print(result)2.2.1.4 使用Series
案例:对于 one 列而言,此处虽然显示了行索引 'd',但由于没有与其对应的值,所以它的值为 NaN。
import pandas as pd
# Series 创建 DataFrame 对象
def seven():data = {'one': pd.Series([1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}result = pd.DataFrame(data=data)print(result)第一列Series比第二列少一个元素,则以NaN填充,数据类型转换为float
2.2.2 列索引操作
DataFrame 可以使用列索(columns index)引来完成数据的选取、添加和删除操作
2.2.2.1 选取数据
import pandas as pd
# 选取数据
def eight():data = {'one': pd.Series([1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}result = pd.DataFrame(data=data)print(result)print(result['one'])2.2.2.2 添加数据
案例1:添加新列,直接赋值添加
data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
result = pd.DataFrame(data=data)
# 直接赋值添加,注意:列表长度要和Dataframe的行数一致,否则报错
result['three'] = [1,2,3,4]
print(result)案例2:通过assign方法添加新列
assign 方法可以用于添加新列,并且可以链式调用。
data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
result = pd.DataFrame(data=data)
# 注意:列表长度要和Dataframe的行数一致,否则报错
result = result.assign(three = [1,2,3,4])
print(result)案例3:在指定的位置插入新列
使用insert方法在指定位置插入新列,参数:
# 创建一个 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd'])
# 使用 insert 方法在位置 1 插入新列 'D'
df.insert(1, 'D', [13, 14, 15, 16])
print("插入新列后的 DataFrame:")
print(df)2.2.2.3 修改数据
案例1:修改列的值
import pandas as pd
# 修改数据
def ten():data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}result = pd.DataFrame(data=data)print(result)result['two'] = pd.Series(data=[1,2,3],index=['a','b','c'])print("修改数据:")print(result)案例2:基于现有列的值修改列
data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
result = pd.DataFrame(data=data)
# 将one列的值加100赋给two列
result['two'] = result['one'] + 100
print(result)案例3:修改列名
data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
result = pd.DataFrame(data=data)
result.columns = ['A','B']
print(result)案例4:使用 rename 方法修改列名
data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
result = pd.DataFrame(data=data)
result = result.rename(columns={'one':'A','two':'B'})
print(result)案例3与案例4不同:案例3直接修改dataframe的列名,案例4修改列名后生成一个副本,原dataframe不受影响
案例5:修改列的数据类型
data = {'one': pd.Series(data=[1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series(data=[1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
result = pd.DataFrame(data=data)
result['two'] = result['two'].astype(np.float32)
print(result)2.2.2.4 删除数据
. 通过drop方法删除 DataFrame 中的数据,默认情况下,drop() 不会修改原 DataFrame,而是返回一个新的 DataFrame。
语法:
DataFrame.drop(labels=None, axis=0, index=None, columns=None,level=None, inplace=False, errors='raise')参数:
labels:
类型:单个标签或列表。
描述:要删除的行或列的标签。如果 axis=0,则 labels 表示行标签;如果 axis=1,则 labels 表示列标签。
axis:
类型:整数或字符串,默认为 0。
描述:指定删除的方向。axis=0 或 axis='index' 表示删除行,axis=1 或 axis='columns' 表示删除列。
index:
类型:单个标签或列表,默认为 None。
描述:要删除的行的标签。如果指定,则忽略 labels 参数。
columns:
类型:单个标签或列表,默认为 None。
描述:要删除的列的标签。如果指定,则忽略 labels 参数。
level:
类型:整数或级别名称,默认为 None。
描述:用于多级索引(MultiIndex),指定要删除的级别。
inplace:
类型:布尔值,默认为 False。
描述:如果为 True,则直接修改原 DataFrame,而不是返回一个新的 DataFrame。
errors:
类型:字符串,默认为 'raise'。
描述:指定如何处理不存在的标签。'raise' 表示抛出错误,'ignore' 表示忽略错误。
案例1:删除列
import pandas as pd
result = pd.DataFrame()
result['one'] = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
result['two'] = pd.Series([5, 6, 7, 8], index=['a', 'b', 'c', 'd'])
print(result)
result1 = result.drop(['one'],axis=1)
print(result1)案例2:删除行
result = pd.DataFrame()
result['one'] = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
result['two'] = pd.Series([5, 6, 7, 8], index=['a', 'b', 'c', 'd'])
print(result)
result1 = result.drop(['a'],axis=0)
print(result1)案例3:直接删除原DataFrame和行或列
result = pd.DataFrame()
result['one'] = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
result['two'] = pd.Series([5, 6, 7, 8], index=['a', 'b', 'c', 'd'])
print(result)
result.drop(['a'], axis=0, inplace=True)
print(result)2.2.3 行索引操作
2.2.3.1 loc 选取数据
df.loc[] 只能使用标签索引,不能使用整数索引。当通过标签索引的切片方式来筛选数据时,它的取值前闭后闭,也就是只包括边界值标签(开始和结束)
loc方法返回的数据类型:
1.如果选择单行或单列,返回的数据类型为Series
2.选择多行或多列,返回的数据类型为DataFrame
3.选择单个元素(某行某列对应的值),返回的数据类型为该元素的原始数据类型(如整数、浮点数等)。
语法:
DataFrame.loc[row_indexer, column_indexer]参数:
案例:
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd'])
# 使用 loc 选择数据
print(df.loc['a']) # 选择行标签为 'a' 的行
print(df.loc['a':'c']) # 选择行标签从 'a' 到 'c' 的行
print(df.loc['a', 'B']) # 选择行标签为 'a',列标签为 'B' 的元素
print(df.loc[['a', 'c'], ['A', 'C']]) # 选择行标签为 'a' 和 'c',列标签为 'A' 和 'C' 的数据2.2.3.2 iloc 选取数据
iloc 方法用于基于位置(integer-location based)的索引,即通过行和列的整数位置来选择数据。
语法:
DataFrame.iloc[row_indexer, column_indexer]参数:
ignore_index: 如果为 True,则忽略原始索引并生成新的索引。
keys: 用于在连接结果中创建层次化索引。
levels: 指定层次化索引的级别。
names: 指定层次化索引的名称。
verify_integrity: 如果为 True,则在连接时检查是否有重复索引。
sort: 如果为 True,则在连接时对列进行排序。
copy: 如果为 True,则复制数据。
案例1:按行连接(垂直堆叠)
# 创建两个示例 DataFrame
df1 = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
})
df2 = pd.DataFrame({'A': [7, 8, 9],'B': [10, 11, 12]
})
# 按行连接 df1 和 df2
result = pd.concat([df1, df2], axis=0)
print(result)案例2:按列连接(水平堆叠)
# 创建两个示例 DataFrame
df1 = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
})
df2 = pd.DataFrame({'C': [7, 8, 9],'D': [10, 11, 12]
})
# 按列连接 df1 和 df2
result = pd.concat([df1, df2], axis=1)
print(result)案例3:使用 ignore_index
# 创建两个示例 DataFrame
df1 = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
})
df2 = pd.DataFrame({'A': [7, 8, 9],'B': [10, 11, 12]
})
# 按行连接 df1 和 df2,并忽略原始索引
result = pd.concat([df1, df2], axis=0, ignore_index=True)
print(result)案例4:使用 join='inner',按行合并
# 创建两个示例 DataFrame
df1 = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
}, index=[0, 1, 2])
df2 = pd.DataFrame({'A': [7, 8, 9],'B': [10, 11, 12],'D': [13, 14, 15]
}, index=[1, 2, 3])
# 按行合并,只匹配column相同的列,行被堆叠
result = pd.concat([df1, df2], axis=0, join='inner')
print(result)
# 按列合并,只匹配index相同的行,列被堆叠
result = pd.concat([df1, df2], axis=1, join='inner')
print(result)案例5:Dataframe和Series连接
# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
})
# 创建一个示例 Series
series = pd.Series([7, 8, 9], name='C')
# 按行连接 DataFrame 和 Series
result_row = pd.concat([df, series], axis=0)
# 按列连接 DataFrame 和 Series
result_col = pd.concat([df, series], axis=1)
print("按行连接结果:")
print(result_row)
print("\n按列连接结果:")
print(result_col)案例:
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd'])
# 使用 iloc 选择数据
print(df.iloc[0]) # 选择第 0 行的数据
print(df.iloc[0:2]) # 选择第 0 到 1 行的数据
print(df.iloc[0, 1]) # 选择第 0 行,第 1 列的元素
print(df.iloc[[0, 2], [0, 2]]) # 选择第 0 和 2 行,第 0 和 2 列的数据2.2.3.3 切片多行选取
通过切片的方式进行多行数据的选取
案例:
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd'])
# 使用 df[0:2] 选择前两行
result = df[0:2]
print(type(result)) # 输出: <class 'pandas.core.frame.DataFrame'>
print(result)切片获取行和通过iloc方法获取行从结果上没有区别,切片是基于位置的切片操作,iloc是基于位置的索引操作。
2.2.3.4 添加数据行
loc方法添加新行
# 创建一个 DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data, index=['a', 'b', 'c', 'd'])
# 添加新行 'e'
df.loc['e'] = [17, 18, 19, 20]
print("添加新行后的 DataFrame:")
print(df)concat拼接
语法:
pd.concat(objs, axis=0, join='outer', ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)参数:
objs: 要连接的 DataFrame 或 Series 对象的列表或字典。
axis: 指定连接的轴,0 或 'index' 表示按行连接,1 或 'columns' 表示按列连接。
join: 指定连接方式,'outer' 表示并集(默认),'inner' 表示交集。
2.2.3.5 删除数据行
参考2.2.2.4 删除数据
3.函数
3.1 常用的统计学函数
| 函数名称 | 描述说明 |
|---|---|
| count() | 统计某个非空值的数量 |
| sum() | 求和 |
| mean() | 求均值 |
| median() | 求中位数 |
| std() | 求标准差 |
| min() | 求最小值 |
| max() | 求最大值 |
| abs() | 求绝对值 |
| prod() | 求所有数值的乘积 |
案例:
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3, 4, 5],'B': [10, 20, 30, 40, 50],'C': [100, 200, 300, 400, 500]
}
df = pd.DataFrame(data)
# 计算每列的均值
mean_values = df.mean()
print(mean_values)
# 计算每列的中位数
median_values = df.median()
print(median_values)
#计算每列的方差
var_values = df.var()
print(var_values)
# 计算每列的标准差
std_values = df.std()
print(std_values)
# 计算每列的最小值
min_values = df.min()
print("最小值:")
print(min_values)
# 计算每列的最大值
max_values = df.max()
print("最大值:")
print(max_values)
# 计算每列的总和
sum_values = df.sum()
print(sum_values)
# 计算每列的非空值数量
count_values = df.count()
print(count_values)注意:numpy的方差默认为总体方差,pandas默认为样本方差
总体方差:
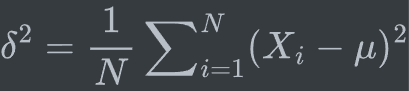
样本方差:
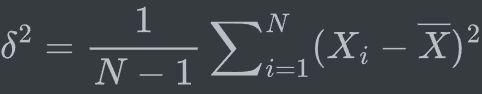
分母为n-1的样本方差的期望等于总体的方差,因此样本方差是总体方差的无偏估计。
3.2 重置索引
重置索引(reindex)可以更改原 DataFrame 的行标签或列标签,并使更改后的行、列标签与 DataFrame 中的数据逐一匹配。通过重置索引操作,您可以完成对现有数据的重新排序。如果重置的索引标签在原 DataFrame 中不存在,那么该标签对应的元素值将全部填充为 NaN。
reindex
reindex() 方法用于重新索引 DataFrame 或 Series 对象。重新索引意味着根据新的索引标签重新排列数据,并填充缺失值。如果重置的索引标签在原 DataFrame 中不存在,那么该标签对应的元素值将全部填充为 NaN。
语法:
DataFrame.reindex(labels=None, index=None, columns=None,
axis=None, method=None, copy=True, level=None,fill_value=np.nan, limit=None, tolerance=None)参数:
labels:
类型:数组或列表,默认为 None。
描述:新的索引标签。
index:
类型:数组或列表,默认为 None。
描述:新的行索引标签。
columns:
类型:数组或列表,默认为 None。
描述:新的列索引标签。
axis:
类型:整数或字符串,默认为 None。
描述:指定重新索引的轴。0 或 'index' 表示行,1 或 'columns' 表示列。
method:
类型:字符串,默认为 None。
描述:用于填充缺失值的方法。可选值包括 'ffill'(前向填充)、'bfill'(后向填充)等。
copy:
类型:布尔值,默认为 True。
描述:是否返回新的 DataFrame 或 Series。
level:
类型:整数或级别名称,默认为 None。
描述:用于多级索引(MultiIndex),指定要重新索引的级别。
fill_value:
类型:标量,默认为 np.nan。
描述:用于填充缺失值的值。
limit:
类型:整数,默认为 None。
描述:指定连续填充的最大数量。
tolerance:
类型:标量或字典,默认为 None。
描述:指定重新索引时的容差。
案例:
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
# 重新索引行
new_index = ['a', 'b', 'c', 'd']
df_reindexed = df.reindex(new_index)
print(df_reindexed)
# 重新索引列
new_columns = ['A', 'B', 'C', 'D']
df_reindexed = df.reindex(columns=new_columns)
print(df_reindexed)
# 重新索引行,并使用前向填充
# 新的行索引 ['a', 'b', 'c', 'd'] 包含了原索引中不存在的标签 'd',使用 method='ffill' 进行前向填充,因此 'd' 对应的行填充了前一行的值。
new_index = ['a', 'b', 'c', 'd']
df_reindexed = df.reindex(new_index, method='ffill')
print(df_reindexed)
# 重新索引行,并使用指定的值填充缺失值
new_index = ['a', 'b', 'c', 'd']
df_reindexed = df.reindex(new_index, fill_value=0)
print(df_reindexed)3.3 遍历
DataFrame 这种二维数据表结构,遍历会获取列标签
案例:
import pandas as pd
series_data = pd.Series(['a','b','c','d','e','f',None])
print('Series:')
for item in series_data:print(item, end=' ')#输出:
a b c d e f None 3.3.1 DataFrame 遍历
dataFrame_data = pd.DataFrame({'one': pd.Series([1, 2, 3], index=['a', 'b', 'c']),'two': pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
})
# 遍历dataframe得到的是列标签
print('DataFrame:')
for item in dataFrame_data:print(item, end=' ')
#输出:
one two 遍历行
itertuples() 方法用于遍历 DataFrame 的行,返回一个包含行数据的命名元组。
案例:
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
# 使用 itertuples() 遍历行
for row in df.itertuples():print(row)for i in row:print(i)
#输出:
Pandas(Index='a', A=1, B=4, C=7)
a
1
4
7
Pandas(Index='b', A=2, B=5, C=8)
b
2
5
8
Pandas(Index='c', A=3, B=6, C=9)
c
3
6
9
# 忽略索引
for row in df.itertuples(index=False):print(row)for i in row:print(i)itertuples() 是遍历 DataFrame 的推荐方法,因为它在速度和内存使用上都更高效。
遍历列
items() 方法用于遍历 DataFrame 的列,返回一个包含列名和列数据的迭代器。
案例:
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
# 使用 items() 遍历列
for column_name, column_data in df.items():print(f"Column Name: {column_name}, Column Data: {column_data}")
#输出:
Column Name: A, Column Data: a 1
b 2
c 3
Name: A, dtype: int64
Column Name: B, Column Data: a 4
b 5
c 6
Name: B, dtype: int64
Column Name: C, Column Data: a 7
b 8
c 9
Name: C, dtype: int64使用属性遍历
loc 和 iloc 方法可以用于按索引或位置遍历 DataFrame 的行和列。
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=['a', 'b', 'c'])
# 使用 loc 遍历行和列
for index in df.index:for column in df.columns:print(f"Index: {index}, Column: {column}, Value: {df.loc[index, column]}")# 输出:
Index: a, Column: A, Value: 1
Index: a, Column: B, Value: 4
Index: a, Column: C, Value: 7
Index: b, Column: A, Value: 2
Index: b, Column: B, Value: 5
Index: b, Column: C, Value: 8
Index: c, Column: A, Value: 3
Index: c, Column: B, Value: 6
Index: c, Column: C, Value: 93.4 排序
3.4.1 sort_values
sort_values 方法用于根据一个或多个列的值对 DataFrame 进行排序。
语法:
DataFrame.sort_values(by, axis=0, ascending=True,inplace=False, kind='quicksort', na_position='last')参数:
by:列的标签或列的标签列表。指定要排序的列。
axis:指定沿着哪个轴排序。默认为 0,表示按行排序。如果设置为 1,将按列排序。
ascending:布尔值或布尔值列表,指定是升序排序(True)还是降序排序(False)。可以为每个列指定不同的排序方向。
inplace:布尔值,指定是否在原地修改数据。如果为 True,则会修改原始数据;如果为 False,则返回一个新的排序后的对象。
kind:排序算法。默认为 'quicksort',也可以选择 'mergesort'(归并排序) 或 'heapsort'(堆排序)。
na_position:指定缺失值(NaN)的位置。可以是 'first' 或 'last'。
案例:
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [3, 2, 1],'B': [6, 5, 4],'C': [9, 8, 7]
}
df = pd.DataFrame(data, index=['b', 'c', 'a'])
# 按列 'A' 排序
df_sorted = df.sort_values(by='A')
print(df_sorted)
# 按列 'A' 和 'B' 排序
df_sorted = df.sort_values(by=['A', 'B'])
print(df_sorted)
# 按列 'A' 降序排序
df_sorted = df.sort_values(by='A', ascending=False)
print(df_sorted)
# 按列 'A' 和 'B' 排序,先按A列降序排序,如果A列中值相同则按B列升序排序
df = pd.DataFrame({'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],'Age': [25, 30, 25, 35, 30],'Score': [85, 90, 80, 95, 88]
})
df_sorted = df.sort_values(by=['Age', 'Score'], ascending=[False, True])
print(df_sorted)3.5 去重
drop_duplicates 方法用于删除 DataFrame 或 Series 中的重复行或元素。
语法:
drop_duplicates(by=None, subset=None, keep='first', inplace=False)
Series.drop_duplicates(keep='first', inplace=False)参数:
by:用于标识重复项的列名或列名列表。如果未指定,则使用所有列。
subset:与 by 类似,但用于指定列的子集。
keep:指定如何处理重复项。可以是:
'first':保留第一个出现的重复项(默认值)。
'last':保留最后一个出现的重复项。
False:删除所有重复项。
inplace:布尔值,指定是否在原地修改数据。如果为 True,则会修改原始数据;如果为 False,则返回一个新的删除重复项后的对象。
案例:
import pandas as pd
# 创建一个示例 DataFrame
data = {'A': [1, 2, 2, 3],'B': [4, 5, 5, 6],'C': [7, 8, 8, 9]
}
df = pd.DataFrame(data)
# 删除所有列的重复行,默认保留第一个出现的重复项
df_unique = df.drop_duplicates()
print(df_unique)
# 删除重复行,保留最后一个出现的重复项
df_unique = df.drop_duplicates(keep='last')
print(df_unique)3.6 分组
groupby 方法用于对数据进行分组操作,这是数据分析中非常常见的一个步骤。通过 groupby,你可以将数据集按照某个列(或多个列)的值分组,然后对每个组应用聚合函数,比如求和、平均值、最大值等。
语法:
DataFrame.groupby(by, axis=0, level=None, as_index=True,
sort=True, group_keys=True, squeeze=False, observed=False, **kwargs)参数:
by:用于分组的列名或列名列表。
axis:指定沿着哪个轴进行分组。默认为 0,表示按行分组。
level:用于分组的 MultiIndex 的级别。
as_index:布尔值,指定分组后索引是否保留。如果为 True,则分组列将成为结果的索引;如果为 False,则返回一个列包含分组信息的 DataFrame。
sort:布尔值,指定在分组操作中是否对数据进行排序。默认为 True。
group_keys:布尔值,指定是否在结果中添加组键。
squeeze:布尔值,如果为 True,并且分组结果返回一个元素,则返回该元素而不是单列 DataFrame。
observed:布尔值,如果为 True,则只考虑数据中出现的标签。
import pandas as pd
# 创建一个示例 DataFramedata = {'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C': [1, 2, 3, 4, 5, 6, 7, 8],'D': [10, 20, 30, 40, 50, 60, 70, 80]}df = pd.DataFrame(data)
# 按列 'A' 分组grouped = df.groupby('A')
# 查看分组结果for name, group in grouped:print(f"Group: {name}")print(group)print()
mean = df.groupby(['A']).mean()print(mean)#输出:C DA bar 4.0 40.0foo 4.8 48.0mean = grouped['C'].mean()print(mean)#输出:Abar 4.0foo 4.8# 在分组内根据C列求平均值# transform用于在分组操作中对每个组内的数据进行转换,并将结果合并回原始 DataFrame。mean = grouped['C'].transform(lambda x: x.mean())df['C_mean'] = meanprint(df)#输出:A B C D C_mean0 foo one 1 10 4.81 bar one 2 20 4.02 foo two 3 30 4.83 bar three 4 40 4.04 foo two 5 50 4.85 bar two 6 60 4.06 foo one 7 70 4.87 foo three 8 80 4.8
# 在分组内根据C列求标准差std = grouped['C'].transform(np.std)df['C_std'] = stdprint(df)
# 在分组内根据C列进行正太分布标准化norm = grouped['C'].transform(lambda x: (x - x.mean()) / x.std())df['C_normal'] = normprint(df)3.7 合并
merge 函数用于将两个 DataFrame 对象根据一个或多个键进行合并,类似于 SQL 中的 JOIN 操作。这个方法非常适合用来基于某些共同字段将不同数据源的数据组合在一起,最后拼接成一个新的 DataFrame 数据表。
函数:
pandas.merge(left, right, how='inner', on=None,left_on=None, right_on=None, left_index=False, right_index=False,
sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)参数:
left:左侧的 DataFrame 对象。
right:右侧的 DataFrame 对象。
how:合并方式,可以是 'inner'、'outer'、'left' 或 'right'。默认为 'inner'。
'inner':内连接,返回两个 DataFrame 共有的键。
'outer':外连接,返回两个 DataFrame 的所有键。
'left':左连接,返回左侧 DataFrame 的所有键,以及右侧 DataFrame 匹配的键。
'right':右连接,返回右侧 DataFrame 的所有键,以及左侧 DataFrame 匹配的键。
on:用于连接的列名。如果未指定,则使用两个 DataFrame 中相同的列名。
left_on 和 right_on:分别指定左侧和右侧 DataFrame 的连接列名。
left_index 和 right_index:布尔值,指定是否使用索引作为连接键。
sort:布尔值,指定是否在合并后对结果进行排序。
suffixes:一个元组,指定当列名冲突时,右侧和左侧 DataFrame 的后缀。
copy:布尔值,指定是否返回一个新的 DataFrame。如果为 False,则可能修改原始 DataFrame。
indicator:布尔值,如果为 True,则在结果中添加一个名为 __merge 的列,指示每行是如何合并的。
validate:验证合并是否符合特定的模式。
案例1:内连接
import pandas as pd
# 创建两个示例 DataFrame
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']
})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K4'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']
})
# 内连接
result = pd.merge(left, right, on='key')
print(result)
#输出:K3、K4被忽略key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2案例2:左连接
import pandas as pd
# 创建两个示例 DataFrame
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']
})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K4'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']
})
# 左连接,以左侧表为准
result = pd.merge(left, right, on='key', how='left')
print(result)
# 输出:key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 NaN NaN3.8 空值处理
3.8.1 检测空值
isnull()用于检测 DataFrame 或 Series 中的空值,返回一个布尔值的 DataFrame 或 Series。
notnull()用于检测 DataFrame 或 Series 中的非空值,返回一个布尔值的 DataFrame 或 Series。
案例1:
import pandas as pd
import numpy as np
# 创建一个包含空值的示例 DataFrame
data = {'A': [1, 2, np.nan, 4],'B': [5, np.nan, np.nan, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
# 检测空值
is_null = df.isnull()
print(is_null)
# 检测非空值
not_null = df.notnull()
print(not_null)案例2:
import pandas as pd
'''isnull() 和 nonull() 用于检测 Series 中的缺失值isnull():如果为值不存在或者缺失,则返回 Truenotnull():如果值不存在或者缺失,则返回 False
'''
def eight():result = pd.Series(['a','b','c','d','e','f',None])print("isnull()如果为值不存在或者缺失,则返回 True:")print(result.isnull())print("notnull()如果值不存在或者缺失,则返回 False:")print(result.notnull())#过滤掉缺失值print(result[result.notnull()])输出:
isnull()如果为值不存在或者缺失,则返回 True:
0 False
1 False
2 False
3 False
4 False
5 False
6 True
dtype: bool
notnull()如果值不存在或者缺失,则返回 False:
0 True
1 True
2 True
3 True
4 True
5 True
6 False
dtype: bool
0 a
1 b
2 c
3 d
4 e
5 f
dtype: object3.8.2 填充空值
fillna() 方法用于填充 DataFrame 或 Series 中的空值。
案例:
# 创建一个包含空值的示例 DataFrame
data = {'A': [1, 2, np.nan, 4],'B': [5, np.nan, np.nan, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
# 用 0 填充空值
df_filled = df.fillna(0)
print(df_filled)3.8.3 删除空值
dropna() 方法用于删除 DataFrame 或 Series 中的空值。
案例:
# 创建一个包含空值的示例 DataFrame
data = {'A': [1, 2, np.nan, 4],'B': [5, np.nan, np.nan, 8],'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
# 删除包含空值的行
df_dropped = df.dropna()
print(df_dropped)
#输出:A B C
0 1.0 5.0 9
3 4.0 8.0 12
# 删除包含空值的列
df_dropped = df.dropna(axis=1)
print(df_dropped)
#输出:C
0 9
1 10
2 11
3 124. 读取CSV文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本);
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
4.1 to_csv()
to_csv() 方法将 DataFrame 存储为 csv 文件
案例:
import pandas as pd
# 创建一个简单的 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# 将 DataFrame 导出为 CSV 文件
df.to_csv('output.csv', index=False)4.2 read_csv()
read_csv() 表示从 CSV 文件中读取数据,并创建 DataFrame 对象。
案例:
import pandas as pd
df = pd.read_csv('output.csv')
print(df)5.Pandas绘图基础
Pandas 在数据分析、数据可视化方面有着较为广泛的应用,Pandas 对 Matplotlib 绘图软件包的基础上单独封装了一个plot()接口,通过调用该接口可以实现常用的绘图操作;
Pandas 之所以能够实现了数据可视化,主要利用了 Matplotlib 库的 plot() 方法,它对 plot() 方法做了简单的封装,因此您可以直接调用该接口;
只用 pandas 绘制图片可能可以编译,但是不会显示图片,需要使用 matplotlib 库,调用 show() 方法显示图形。
5.1 折线图(默认)
import pandas as pd
import matplotlib.pyplot as pltdf = pd.DataFrame({ 'Year': [2020, 2021, 2022],
'Sales': [200, 250, 300] })
df.plot(x='Year', y='Sales', kind='line')5.2 柱状图
import pandas as pd
import matplotlib.pyplot as pltdf.plot(kind='bar', x='Year', y='Sales')5.3 直方图(hist)
import pandas as pd
import matplotlib.pyplot as pltdf['Sales'].plot(kind='hist', bins=5)5.4 饼图(pie)
import pandas as pd
import matplotlib.pyplot as pltdf = pd.DataFrame({ 'Product': ['A', 'B', 'C'],
'Sales': [100, 200, 150] })
df.set_index('Product').plot(kind='pie', y='Sales', autopct='%1.1f%%')注意: 绘图前建议加上
import matplotlib.pyplot as plt和plt.show()以保证图形显示(特别是非 Jupyter 环境):
三、Matplotlib
1.概念
Matplotlib 库:是一款用于数据可视化的 Python 软件包,支持跨平台运行,它能够根据 NumPy ndarray 数组来绘制 2D 图像,它使用简单、代码清晰易懂
Matplotlib 图形组成:
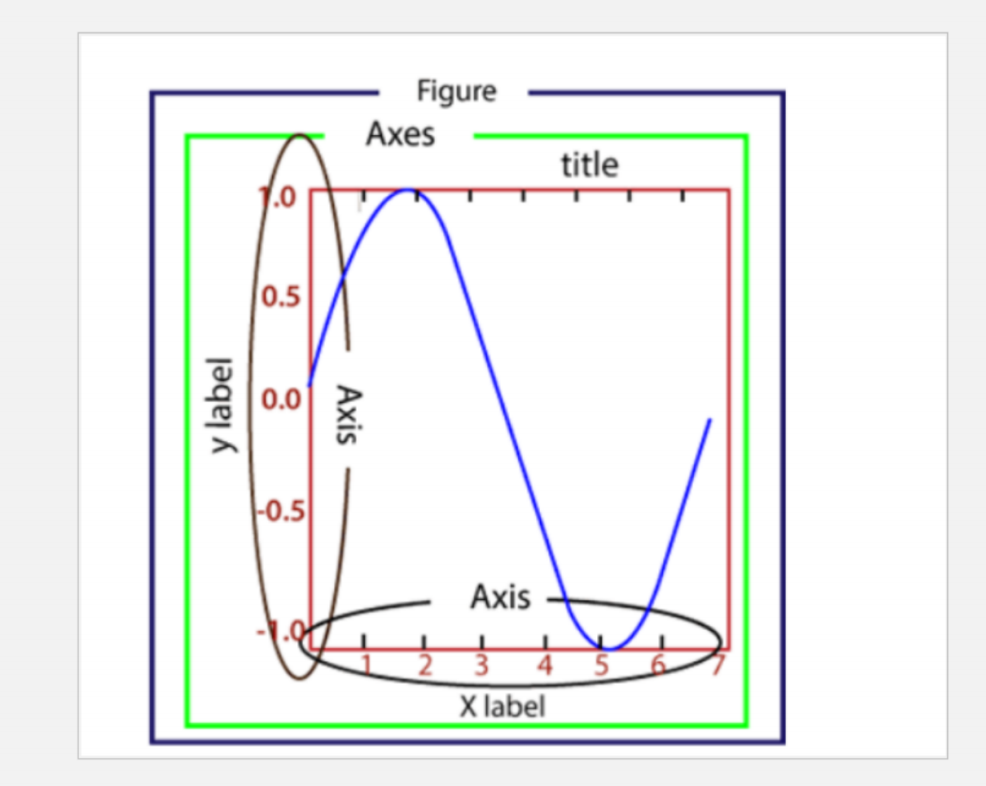
-
Figure:指整个图形,您可以把它理解成一张画布,它包括了所有的元素,比如标题、轴线等
-
Axes:绘制 2D 图像的实际区域,也称为轴域区,或者绘图区
-
Axis:指坐标系中的垂直轴与水平轴,包含轴的长度大小(图中轴长为 7)、轴标签(指 x 轴,y轴)和刻度标签
-
Artist:您在画布上看到的所有元素都属于 Artist 对象,比如文本对象(title、xlabel、ylabel)、Line2D 对象(用于绘制2D图像)等
-
Matplotlib 功能扩展包:许多第三方工具包都对 Matplotlib 进行了功能扩展,其中有些安装包需要单独安装,也有一些允许与 Matplotlib 一起安装。常见的工具包如下:
-
Basemap:这是一个地图绘制工具包,其中包含多个地图投影,海岸线和国界线
-
Cartopy:这是一个映射库,包含面向对象的映射投影定义,以及任意点、线、面的图像转换能力
-
Excel tools: 这是 Matplotlib 为了实现与 Microsoft Excel 交换数据而提供的工具
-
Mplot3d:它用于 3D 绘图
-
Natgrid:这是 Natgrid 库的接口,用于对间隔数据进行不规则的网格化处理
-
2.安装
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple/3.应用场景
数据可视化主要有以下应用场景:
企业领域:利用直观多样的图表展示数据,从而为企业决策提供支持
股票走势预测:通过对股票涨跌数据的分析,给股民提供更合理化的建议
商超产品销售:对客户群体和所购买产品进行数据分析,促使商超制定更好的销售策略
预测销量:对产品销量的影响因素进行分析,可以预测出产品的销量走势
4.常用API
4.1 绘图类型
| 函数名称 | 描述 |
|---|---|
| Bar | 绘制条形图 |
| Barh | 绘制水平条形图 |
| Boxplot | 绘制箱型图 |
| Hist | 绘制直方图 |
| his2d | 绘制2D直方图 |
| Pie | 绘制饼状图 |
| Plot | 在坐标轴上画线或者标记 |
| Polar | 绘制极坐标图 |
| Scatter | 绘制x与y的散点图 |
| Stackplot | 绘制堆叠图 |
| Stem | 用来绘制二维离散数据绘制(又称为火柴图) |
| Step | 绘制阶梯图 |
| Quiver | 绘制一个二维按箭头 |
4.2 Image 函数
| 函数名称 | 描述 |
|---|---|
| Imread | 从文件中读取图像的数据并形成数组 |
| Imsave | 将数组另存为图像文件 |
| Imshow | 在数轴区域内显示图像 |
4.3 Axis 函数
| 函数名称 | 描述 |
|---|---|
| Axes | 在画布(Figure)中添加轴 |
| Text | 向轴添加文本 |
| Title | 设置当前轴的标题 |
| Xlabel | 设置x轴标签 |
| Xlim | 获取或者设置x轴区间大小 |
| Xscale | 设置x轴缩放比例 |
| Xticks | 获取或设置x轴刻标和相应标签 |
| Ylabel | 设置y轴的标签 |
| Ylim | 获取或设置y轴的区间大小 |
| Yscale | 设置y轴的缩放比例 |
| Yticks | 获取或设置y轴的刻标和相应标签 |
4.4 Figure 函数
| 函数名称 | 描述 |
|---|---|
| Figtext | 在画布上添加文本 |
| Figure | 创建一个新画布 |
| Show | 显示数字 |
| Savefig | 保存当前画布 |
| Close | 关闭画布窗口 |
5.pylab 模块
PyLab 是一个面向 Matplotlib 的绘图库接口,其语法和 MATLAB 十分相近。
pylab 是 matplotlib 中的一个模块,它将 matplotlib.pyplot 和 numpy 的功能组合在一起,使得你可以直接使用 numpy 的函数和 matplotlib.pyplot 的绘图功能,而不需要显式地导入 numpy 和 matplotlib.pyplot。
优点
方便快捷:pylab 的设计初衷是为了方便快速绘图和数值计算,使得你可以直接使用 numpy 的函数和 matplotlib.pyplot 的绘图功能,而不需要显式地导入 numpy 和 matplotlib.pyplot。
简化代码:使用 pylab 可以减少导入语句的数量,使代码更简洁。
缺点
命名空间污染:pylab 将 numpy 和 matplotlib.pyplot 的功能组合在一起,可能会导致命名空间污染,使得代码的可读性和可维护性降低。
不适合大型项目:对于大型项目或需要精细控制的项目,pylab 可能不够灵活。
pyplot 是 matplotlib 中的一个模块,提供了类似于 MATLAB 的绘图接口。它是一个更底层的接口,提供了更多的控制和灵活性。
使用 pyplot 需要显式地导入 numpy 和 matplotlib.pyplot,代码量相对较多。例如:
import matplotlib.pyplot as plt
import numpy as np6.常用函数
6.1 plot 函数
pylab.plot 是一个用于绘制二维图形的函数。它可以根据提供的 x 和 y 数据点绘制线条和/或标记。
语法:
pylab.plot(x, y, format_string=None, **kwargs)参数:
x: x 轴数据,可以是一个数组或列表。
y: y 轴数据,可以是一个数组或列表。
format_string: 格式字符串,用于指定线条样式、颜色等。
**kwargs: 其他关键字参数,用于指定线条的属性。
plot 函数可以接受一个或两个数组作为参数,分别代表 x 和 y 坐标。如果你只提供一个数组,它将默认用作 y 坐标,而 x 坐标将默认为数组的索引。
格式字符串:
格式字符串由颜色、标记和线条样式组成。例如:
颜色:
'b':蓝色 'g':绿色 'r':红色 'c':青色 'm':洋红色 'y':黄色 'k':黑色 'w':白色
标记:
'.':点标记
',':像素标记
'o':圆圈标记
'v':向下三角标记
'^':向上三角标记
'<':向左三角标记
'>':向右三角标记
's':方形标记
'p':五边形标记
'*':星形标记
'h':六边形标记1
'H':六边形标记2
'+':加号标记
'x':叉号标记
'D':菱形标记
'd':细菱形标记
'|':竖线标记
'_':横线标记
线条样式:
'-':实线 '--':虚线 '-.':点划线 ':':点线
案例:
# 导入 pylab 库
import pylab
# 创建数据,使用 linspace 函数
# pylab.linspace 函数生成一个等差数列。这个函数返回一个数组,数组中的数值在指定的区间内均匀分布。
x = pylab.linspace(-6, 6, 40)
# 基于 x 构建 y 的数据
y = x**2
# 绘制图形
pylab.plot(x,y,'r:')
# 展示图形
pylab.show()警告日志关闭
import logging
logging.captureWarnings(True)6.2 figure 函数
figure() 函数来实例化 figure 对象,即绘制图形的对象,可以通过这个对象,来设置图形的样式等
参数:
figsize:指定画布的大小,(宽度,高度),单位为英寸
dpi:指定绘图对象的分辨率,即每英寸多少个像素,默认值为80
facecolor:背景颜色
dgecolor:边框颜色
frameon:是否显示边框
6.2.1 figure.add_axes()
Matplotlib 定义了一个 axes 类(轴域类),该类的对象被称为 axes 对象(即轴域对象),它指定了一个有数值范围限制的绘图区域。在一个给定的画布(figure)中可以包含多个 axes 对象,但是同一个 axes 对象只能在一个画布中使用。
参数:
是一个包含四个元素的列表或元组,格式为 [left, bottom, width, height],其中:
left 和 bottom 是轴域左下角的坐标,范围从 0 到 1。
width 和 height 是轴域的宽度和高度,范围从 0 到 1。
案例:
# 创建一个新的图形
fig = pl.figure()
# 添加第一个轴域
ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
x = pl.linspace(0, 10, 100)
y = pl.sin(x)
ax.plot(x, y)
# 显示图形
pl.show()6.2.2 axes.legend()
legend 函数用于添加图例,以便识别图中的不同数据系列。图例会自动显示每条线或数据集的标签。
参数:
labels 是一个字符串序列,用来指定标签的名称
loc 是指定图例位置的参数,其参数值可以用字符串或整数来表示
handles 参数,它也是一个序列,它包含了所有线型的实例
案例:
x = pl.linspace(0, 10, 100)
y1 = pl.sin(x)
y2 = pl.cos(x)
# 创建图形和轴域
fig, ax = pl.subplots()
# 绘制数据
line1 = ax.plot(x, y1)
line2 = ax.plot(x, y2)
# 添加图例,手动指定标签
ax.legend(handles=[line1, line2], labels=['Sine Function', 'Cosine Function'],loc='center')
# 显示图形
pl.show()
也可以将label定义在plot方法中,调用legend方法时不用再定义labels,会自动添加labelx = pl.linspace(0, 10, 100)
y1 = pl.sin(x)
y2 = pl.cos(x)
# 创建图形和轴域
fig, ax = pl.subplots()
# 绘制数据
line1, = ax.plot(x, y1, label='Sine Function')
line2, = ax.plot(x, y2, label='Cosine Function')
# 添加图例,手动指定标签
ax.legend(handles=[line1, line2], loc='center')
# 显示图形
pl.show()legend() 函数 loc 参数:
| 位置 | 字符串表示 | 整数数字表示 |
|---|---|---|
| 自适应 | best | 0 |
| 右上方 | upper right | 1 |
| 左上方 | upper left | 2 |
| 左下 | lower left | 3 |
| 右下 | lower right | 4 |
| 右侧 | right | 5 |
| 居中靠左 | center left | 6 |
| 居中靠右 | center right | 7 |
| 底部居中 | lower center | 8 |
| 上部居中 | upper center | 9 |
| 中部 | center | 10 |
6.3 标题中文乱码
如果标题设置的是中文,会出现乱码
局部处理:
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False全局处理:
首先,找到 matplotlibrc 文件的位置,可以使用以下代码:
import matplotlib
print(matplotlib.matplotlib_fname())然后,修改 matplotlibrc 文件,找到 font.family 和 font.sans-serif 项,设置为支持中文的字体,如 SimHei。
同时,设置 axes.unicode_minus 为 False 以正常显示负号。
修改完成后,重启pyCharm。如果不能解决,尝试运行以下代码来实现:
from matplotlib.font_manager import _rebuild
_rebuild()6.4 subplot 函数
subplot 是一个较早的函数,用于创建并返回一个子图对象。它的使用比较简单,通常用于创建网格状的子图布局。subplot 的参数通常是一个三位数的整数,其中每个数字代表子图的行数、列数和子图的索引。
add_subplot 是一个更灵活的函数,它是 Figure类的一个方法,用于向图形容器中添加子图。推荐使用 add_subplot,因为它提供了更好的灵活性和控制。
语法:
fig.add_subplot(nrows, ncols, index)案例:
import matplotlib.pyplot as plt
import numpy as np
# 创建数据
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
y3 = np.tan(x)
# 创建图形,figsize=(宽度, 高度),单位是英寸,图形宽度为 12 英寸,高度为 4 英寸
fig = plt.figure(figsize=(12, 4))
# 第一个子图
ax1 = fig.add_subplot(1, 3, 1)
ax1.plot(x, y1, label='sin(x)')
ax1.set_title('Sine Wave')
ax1.set_xlabel('X-axis')
ax1.set_ylabel('Y-axis')
ax1.legend()
# 第二个子图
ax2 = fig.add_subplot(1, 3, 2)
ax2.plot(x, y2, label='cos(x)')
ax2.set_title('Cosine Wave')
ax2.set_xlabel('X-axis')
ax2.set_ylabel('Y-axis')
ax2.legend()
# 第三个子图
ax3 = fig.add_subplot(1, 3, 3)
ax3.plot(x, y3, label='tan(x)')
ax3.set_title('Tangent Wave')
ax3.set_xlabel('X-axis')
ax3.set_ylabel('Y-axis')
ax3.legend()
# 显示图形
plt.tight_layout()
plt.show()6.5 subplots 函数
subplots 是 matplotlib.pyplot 模块中的一个函数,用于创建一个包含多个子图(subplots)的图形窗口。subplots 函数返回一个包含所有子图的数组,这使得你可以更方便地对每个子图进行操作。
语法:
fig, axs = plt.subplots(nrows, ncols, figsize=(width, height))参数:
nrows: 子图的行数。
ncols: 子图的列数。
figsize: 图形的尺寸,以英寸为单位。
案例:
import matplotlib.pyplot as plt
import numpy as np
# 创建数据
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
y3 = np.tan(x)
# 创建图形和子图
fig, axs = plt.subplots(1, 3, figsize=(12, 4))
# 第一个子图
axs[0].plot(x, y1, label='sin(x)')
axs[0].set_title('Sine Wave')
axs[0].set_xlabel('X-axis')
axs[0].set_ylabel('Y-axis')
axs[0].legend()
# 第二个子图
axs[1].plot(x, y2, label='cos(x)')
axs[1].set_title('Cosine Wave')
axs[1].set_xlabel('X-axis')
axs[1].set_ylabel('Y-axis')
axs[1].legend()
# 第三个子图
axs[2].plot(x, y3, label='tan(x)')
axs[2].set_title('Tangent Wave')
axs[2].set_xlabel('X-axis')
axs[2].set_ylabel('Y-axis')
axs[2].legend()
# 显示图形
plt.tight_layout()
plt.show()7.绘制图表
7.1 柱状图
柱状图(Bar Chart)是一种常用的数据可视化工具,用于展示分类数据的分布情况。
语法:
ax.bar(x, height, width=0.8, bottom=None, align='center', **kwargs)参数:
x: 柱状图的 X 轴位置。
height: 柱状图的高度。
width: 柱状图的宽度,默认为 0.8。
bottom: 柱状图的底部位置,默认为 0。
align: 柱状图的对齐方式,可以是 'center'(居中对齐)或 'edge'(边缘对齐)。
**kwargs: 其他可选参数,用于定制柱状图的外观,如 color、edgecolor、linewidth 等。
案例1:
from matplotlib import pyplot as plt
import numpy as np
# 数据
categories = ['A', 'B', 'C', 'D']
values = [20, 35, 30, 25]
# 创建图形和子图
fig, ax = plt.subplots()
# 绘制柱状图
ax.bar(categories, values, color='skyblue', linewidth=1.5, width=0.6)
# 设置标题和标签
ax.set_title('Customized Bar Chart')
ax.set_xlabel('Categories')
ax.set_ylabel('Values')
# 显示图形
plt.show()案例2:堆叠柱状图
# 数据
categories = ['A', 'B', 'C', 'D']
values1 = [20, 35, 30, 25]
values2 = [15, 25, 20, 10]
# 创建图形和子图
fig, ax = plt.subplots()
# 绘制第一个数据集的柱状图
ax.bar(categories, values1, color='skyblue', label='Values 1')
# 绘制第二个数据集的柱状图,堆叠在第一个数据集上
ax.bar(categories, values2, bottom=values1, color='lightgreen', label='Values 2')
# 设置标题和标签
ax.set_title('Stacked Bar Chart')
ax.set_xlabel('Categories')
ax.set_ylabel('Values')
# 添加图例
ax.legend()
# 显示图形
plt.show()说明:
bottom=values1:绘制第二个数据集的柱状图,堆叠在第一个数据集上
案例3:分组柱状图
# 数据
categories = ['A', 'B', 'C', 'D']
values1 = [20, 35, 30, 25]
values2 = [15, 25, 20, 10]
# 创建图形和子图
fig, ax = plt.subplots()
# 计算柱状图的位置
x = np.arange(len(categories))
width = 0.35
# 绘制第一个数据集的柱状图
ax.bar(x - width/2, values1, width, color='skyblue', label='Values 1')
# 绘制第二个数据集的柱状图
ax.bar(x + width/2, values2, width, color='lightgreen', label='Values 2')
# 设置 X 轴标签
ax.set_xticks(x)
ax.set_xticklabels(categories)
# 设置标题和标签
ax.set_title('Grouped Bar Chart')
ax.set_xlabel('Categories')
ax.set_ylabel('Values')
# 添加图例
ax.legend()
# 显示图形
plt.show()7.2 直方图
直方图(Histogram)是一种常用的数据可视化工具,用于展示数值数据的分布情况。
语法:
ax.hist(x, bins=None, range=None, density=False,
weights=None, cumulative=False, **kwargs)参数:
x: 数据数组。
bins: 直方图的柱数,可以是整数或序列。
range: 直方图的范围,格式为 (min, max)。
density: 是否将直方图归一化,默认为 False。
weights: 每个数据点的权重。
cumulative: 是否绘制累积直方图,默认为 False。
**kwargs: 其他可选参数,用于定制直方图的外观,如 color、edgecolor、linewidth 等。
案例:
from matplotlib import pyplot as plt
import numpy as np
# 生成随机数据,生成均值为 0,标准差为 1 的标准正态分布的随机样本
data = np.random.randn(1000)
# 创建图形和子图
fig, ax = plt.subplots()
# 绘制直方图
ax.hist(data, bins=30, color='skyblue', edgecolor='black')
# 设置标题和标签
ax.set_title('Simple Histogram')
ax.set_xlabel('Value')
ax.set_ylabel('Frequency')
# 显示图形
plt.show()7.3 饼图
饼图(Pie Chart)是一种常用的数据可视化工具,用于展示分类数据的占比情况。
语法:
ax.pie(x, explode=None, labels=None, colors=None, autopct=None,
shadow=False, startangle=0, **kwargs)参数:
x: 数据数组,表示每个扇区的占比。
explode: 一个数组,表示每个扇区偏离圆心的距离,默认为 None。
labels: 每个扇区的标签,默认为 None。
colors: 每个扇区的颜色,默认为 None。
autopct: 控制显示每个扇区的占比,可以是格式化字符串或函数,默认为 None。
shadow: 是否显示阴影,默认为 False。
startangle: 饼图的起始角度,默认为 0。
**kwargs: 其他可选参数,用于定制饼图的外观。
案例:
from matplotlib import pyplot as plt
import numpy as np
# 数据
labels = ['A', 'B', 'C', 'D']
sizes = [15, 30, 45, 10]
# 创建图形和子图
fig, ax = plt.subplots()
# 绘制饼图
ax.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=90)
# 设置标题
ax.set_title('Simple Pie Chart')
# 显示图形
plt.show()7.4 折线图
使用 plot 函数
案例:
from matplotlib import pyplot as plt
# 创建数据
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
# 创建图形和子图
fig, ax = plt.subplots()
# 绘制多条折线图
ax.plot(x, y1, label='sin(x)', color='blue')
ax.plot(x, y2, label='cos(x)', color='red')
# 设置标题和标签
ax.set_title('Multiple Line Charts')
ax.set_xlabel('X-axis')
ax.set_ylabel('Y-axis')
# 添加图例
ax.legend()
# 显示图形
plt.show()7.5 散点图
散点图(Scatter Plot)是一种常用的数据可视化工具,用于展示两个变量之间的关系。
语法:
ax.scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None,
vmin=None, vmax=None, alpha=None, linewidths=None, edgecolors=None, **kwargs)参数:
x: X 轴数据。
y: Y 轴数据。
s: 点的大小,可以是标量或数组。
c: 点的颜色,可以是标量、数组或颜色列表。
marker: 点的形状,默认为 'o'(圆圈)。
cmap: 颜色映射,用于将颜色映射到数据。
norm: 归一化对象,用于将数据映射到颜色映射。
vmin, vmax: 颜色映射的最小值和最大值。
alpha: 点的透明度,取值范围为 0 到 1。
linewidths: 点的边框宽度。
edgecolors: 点的边框颜色。
**kwargs: 其他可选参数,用于定制散点图的外观。
案例:
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
fig = plt.figure()
axes = fig.add_axes([.1,.1,.8,.8])
x = ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
data = [[120, 132, 101, 134, 90, 230, 210],[220, 182, 191, 234, 290, 330, 310],
]
y0 = data[0]
y1 = data[1]
axes.scatter(x,y0,color='red')
axes.scatter(x,y1,color='blue')
axes.set_title('散点图')
axes.set_xlabel('日期')
axes.set_ylabel('数量')
plt.legend(labels=['Email', 'Union Ads'],)
plt.show()marker常用的参数值:
'o': 圆圈
's': 正方形
'D': 菱形
'^': 上三角形
'v': 下三角形
'>': 右三角形
'<': 左三角形
'p': 五边形
'*': 星形
'+': 加号
'x': 叉号
'.': 点
',': 像素
'1': 三叉戟下
'2': 三叉戟上
'3': 三叉戟左
'4': 三叉戟右
'h': 六边形1
'H': 六边形2
'd': 小菱形
'|': 竖线
'_': 横线
7.6 图片读取
plt.imread 是 Matplotlib 库中的一个函数,用于读取图像文件并将其转换为 NumPy 数组。这个函数非常方便,可以轻松地将图像加载到 Python 中进行处理或显示。
参数
fname: 图像文件的路径(字符串)。
format: 图像格式(可选)。如果未指定,imread会根据文件扩展名自动推断格式。返回值
返回一个 NumPy 数组,表示图像的像素数据。数组的形状取决于图像的格式:
对于灰度图像,返回一个二维数组
(height, width)。对于彩色图像,返回一个三维数组
(height, width, channels),其中channels通常是 3(RGB)或 4(RGBA)。
案例:
from matplotlib import pyplot as plt
import numpy as np
import os
def read_img():dirpath = os.path.dirname(__file__)print(dirpath)
filepath = os.path.relpath(os.path.join(dirpath, 'leaf.png'))print(filepath)
img = plt.imread(filepath)print(img.shape)plt.imshow(img)plt.show()
img1 = np.transpose(img, (2, 0, 1))for channel in img1:plt.imshow(channel)plt.show()
if __name__ == '__main__':read_img()四、常见的镜像源网站
1.pip 常用镜像源网址
| 镜像源 | 镜像地址 URL | 说明 |
|---|---|---|
| 清华大学 | https://pypi.tuna.tsinghua.edu.cn/simple | ⭐稳定、推荐使用 |
| 阿里云 | https://mirrors.aliyun.com/pypi/simple/ | |
| 中国科技大学 | https://pypi.mirrors.ustc.edu.cn/simple/ | |
| 华中理工大学 | https://pypi.hustunique.com/simple/ | 偶尔维护 |
| 豆瓣(douban) | https://pypi.douban.com/simple/ | 曾一度关闭,谨慎使用 |
2.conda 常用镜像源网址(Anaconda)
| 镜像源 | 镜像配置命令 |
|---|---|
| 清华大学 | https://mirrors.tuna.tsinghua.edu.cn/anaconda/ |
| 中科大 | https://mirrors.ustc.edu.cn/anaconda/ |
| 阿里云 | https://mirrors.aliyun.com/anaconda/ |



)




网络层 路由协议)
Pytorch中求逆torch.inverse和解线性方程组torch.linalg.solve有什么关系)



)

图片比对)



