🚀 Kafka 高吞吐量架构实战:原理解析与性能优化全攻略
随着大数据技术在日志收集、埋点监控、订单流处理等场景的普及,Kafka 已成为流处理架构中的核心组件。它之所以能在海量数据场景下保持高吞吐、低延迟,源于其在架构层面和底层实现上的诸多巧思。
本文面向中高级 Java / 大数据开发者,深入剖析 Kafka 高性能背后的核心机制,结合实战经验,分享调优与排障技巧,助你构建更稳定、高效的消息系统。
文章目录
- 🚀 Kafka 高吞吐量架构实战:原理解析与性能优化全攻略
- ✨ 一、引言:Kafka 为什么这么快?
- 📦1.1 海量数据处理场景
- Kafka 常见的使用场景包括:
- 性能基准:
- 🤝1.2 高性能核心支柱
- 📡二、 ISR机制:高可用与数据一致性的平衡术
- 🧩2.1 副本角色解析
- 副本状态:
- ⚙️ 2.2 ISR工作机制
- 关键参数调优:
- 📥2.3 副本不一致处理
- ⚡三、 零拷贝 + 页缓存:I/O 性能的终极武器
- ❗3.1 传统文件传输 vs 零拷贝
- 性能对比:
- 🧱3.2 Kafka 零拷贝实现
- 页缓存优化:
- 📉3.3 页缓存风险与应对
- 风险场景:
- 解决方案:
- 🔄四、 Rebalance 机制:消费稳定的关键
- 📦4.1 Rebalance 策略演进
- 🆕 4.2 Rebalance 流程
- ⚙️4.3 手动分配分区
- ⏱️ 五、延迟队列实现方案
- 📉 5.1 原生限制与解决方案
- 🧪Kafka 限制:
- 🧪 常见方案对比:
- 🧭 实现方式 1:Redis ZSet + 轮询
- 🧭 实现方式 2:Kafka 分区 + 时间轮调度
- 🧭 实现方式 3:Kafka + Timer Server 中间件
- 5.2 🧪 选型对比
- 🚧六、 消息积压处理实战指南
- 🔧6.1 积压原因排查
- 🛠️排查工具:
- 🧪6.2 应急处理方案
- 扩容消费者:
- 分区扩容:
- 📉6.3 监控体系搭建
- Prometheus + Grafana 监控:
- 关键监控指标:
- 🏆七、 总结与最佳实践
- 🧠 7.1 Kafka 高吞吐核心
- 🧠7.2 角色优化建议
- ❌7.3 不适用场景
- 八、📚 进阶阅读推荐
✨ 一、引言:Kafka 为什么这么快?
Apache Kafka 被广泛用于日志收集、埋点采集、订单流处理、风控预警等高吞吐场景,凭借其出色的横向扩展能力和毫秒级延迟,成为主流的大数据消息引擎。
📦1.1 海量数据处理场景
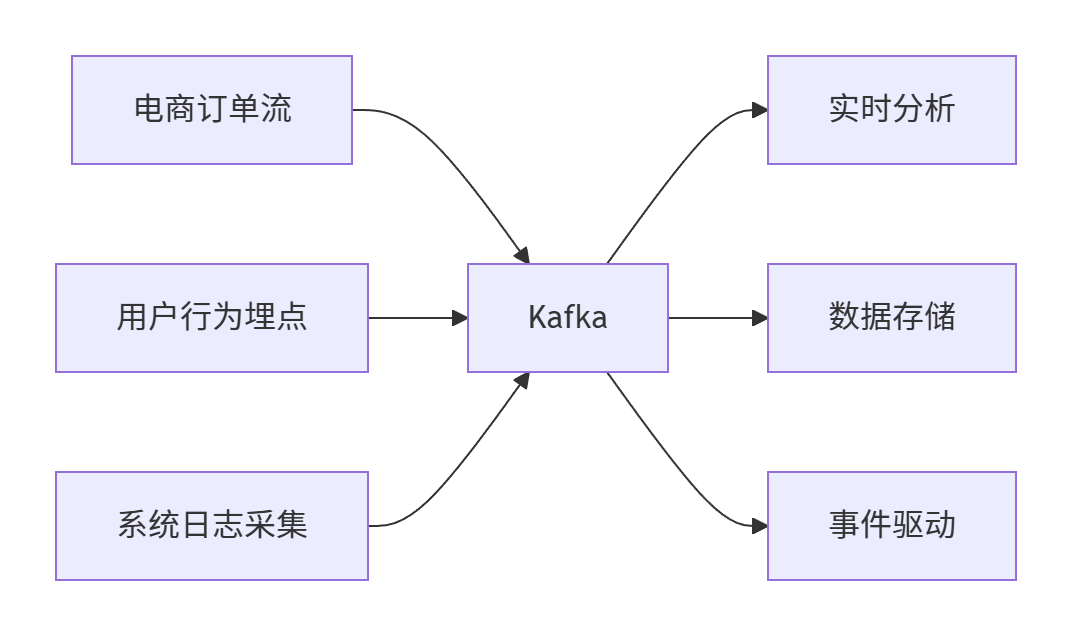
Kafka 常见的使用场景包括:
- 用户行为埋点实时收集
- 日志平台的异步投递
- 订单流的异步处理与分析
- 实时数据管道(CDC)等
性能基准:
- 单集群:百万级 TPS(每秒消息数)
- 延迟:毫秒级 端到端延迟
- 扩展性:线性扩容 能力
🤝1.2 高性能核心支柱
public class KafkaHighPerformancePillars {// 四大性能支柱String[] pillars = {"ISR副本机制", // 高可用"零拷贝传输", // 低延迟"顺序磁盘写入", // 高吞吐"批处理与压缩" // 高效率};
}
那么问题来了:Kafka 是如何实现百万级 TPS 的?
📡二、 ISR机制:高可用与数据一致性的平衡术
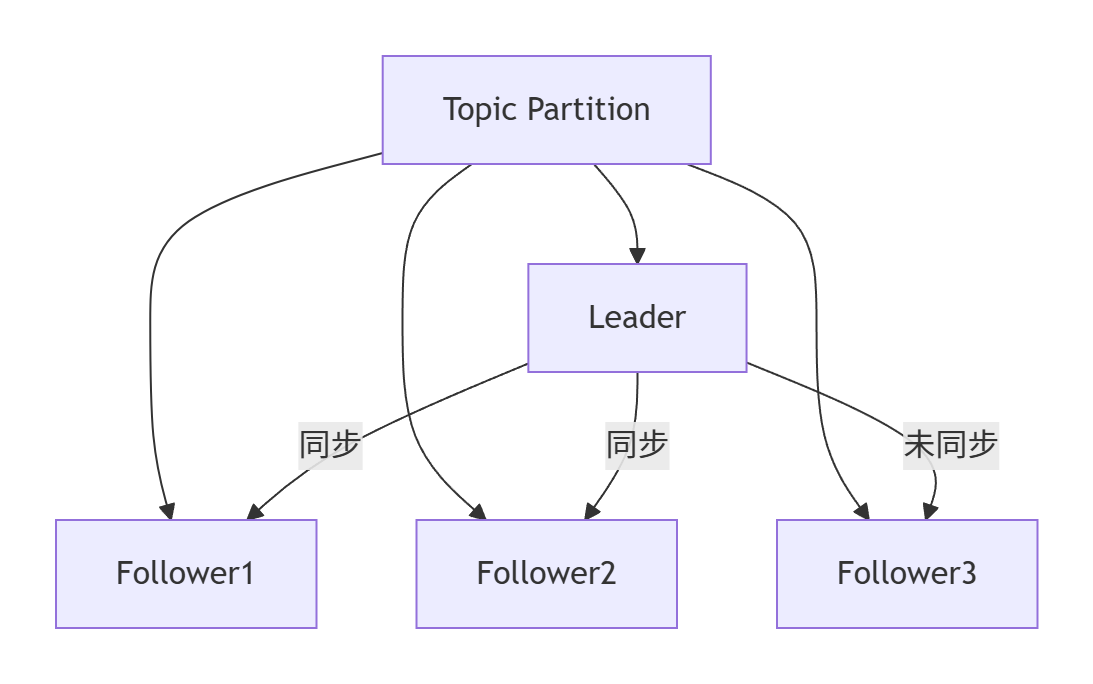
🧩2.1 副本角色解析
副本状态:
- Leader:处理所有读写请求
- Follower:被动复制Leader数据
- ISR(In-Sync Replicas):与Leader保持同步的副本集合
⚙️ 2.2 ISR工作机制
// Kafka副本管理器核心逻辑
class ReplicaManager {// ISR维护逻辑void updateISR() {for (Follower follower : followers) {if (follower.lastOffset >= leader.highWatermark - maxLag) {isr.add(follower);} else {isr.remove(follower);}}}// 生产者ACK机制void handleProducerRequest() {if (acks == ALL) {// 等待所有ISR副本确认waitForIsrAcks();}}
}
关键参数调优:
# server.properties
min.insync.replicas=2 # 最小ISR副本数
unclean.leader.election.enable=false # 禁止落后副本成为Leader
replica.lag.time.max.ms=30000 # 副本最大滞后时间
📥2.3 副本不一致处理
场景:Follower 长时间未同步
解决方案:
- Leader 将滞后副本移出 ISR
- 副本恢复后追赶日志
- 重新加入 ISR
💡 最佳实践:生产环境设置 min.insync.replicas=2 并禁用 unclean.leader.election
⚡三、 零拷贝 + 页缓存:I/O 性能的终极武器
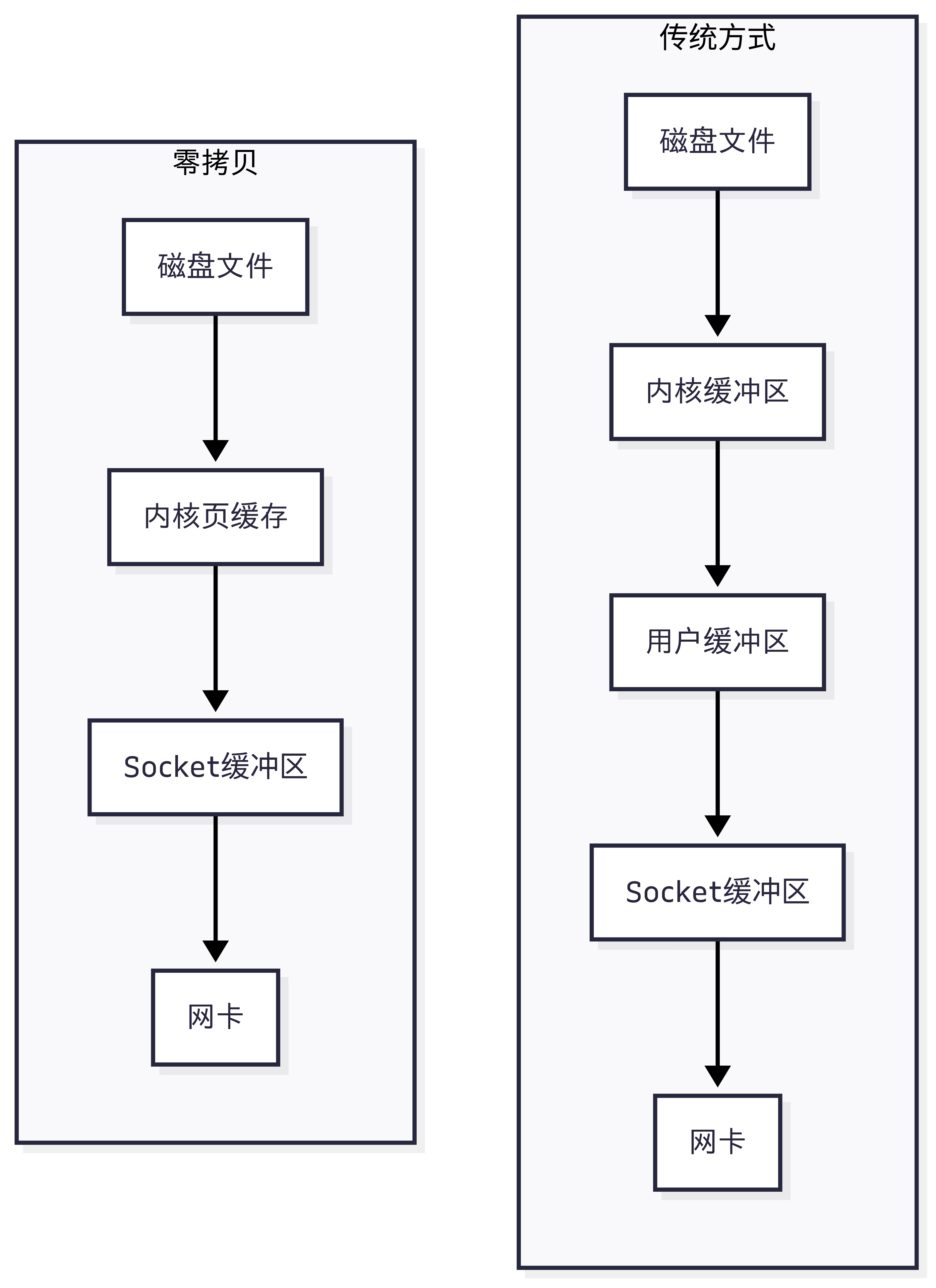
❗3.1 传统文件传输 vs 零拷贝
性能对比:
- 传统:4次上下文切换 + 4次数据拷贝
- 零拷贝:2次上下文切换 + 2次数据拷贝
🧱3.2 Kafka 零拷贝实现
// Kafka 文件传输核心代码
public long transferFrom(FileChannel fileChannel, long position, long count) {return fileChannel.transferTo(position, count, socketChannel);
}
页缓存优化:
# 操作系统优化
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
vm.swappiness = 1
📉3.3 页缓存风险与应对
风险场景:
- 突发流量导致页缓存被冲刷
- 日志文件过大影响缓存命中率
解决方案:
- 预留足够内存给页缓存
- 使用 SSD 提升随机读性能
- 合理设置 log.segment.bytes(默认1GB)
🔄四、 Rebalance 机制:消费稳定的关键
📦4.1 Rebalance 策略演进
| 策略 | 特点 | 适用场景 |
|---|---|---|
| Range | 按分区范围分配 | 分区数固定 |
| RoundRobin | 轮询分配 | 分区均匀 |
| Sticky | 尽量保持原分配 | 减少迁移 |
🆕 4.2 Rebalance 流程
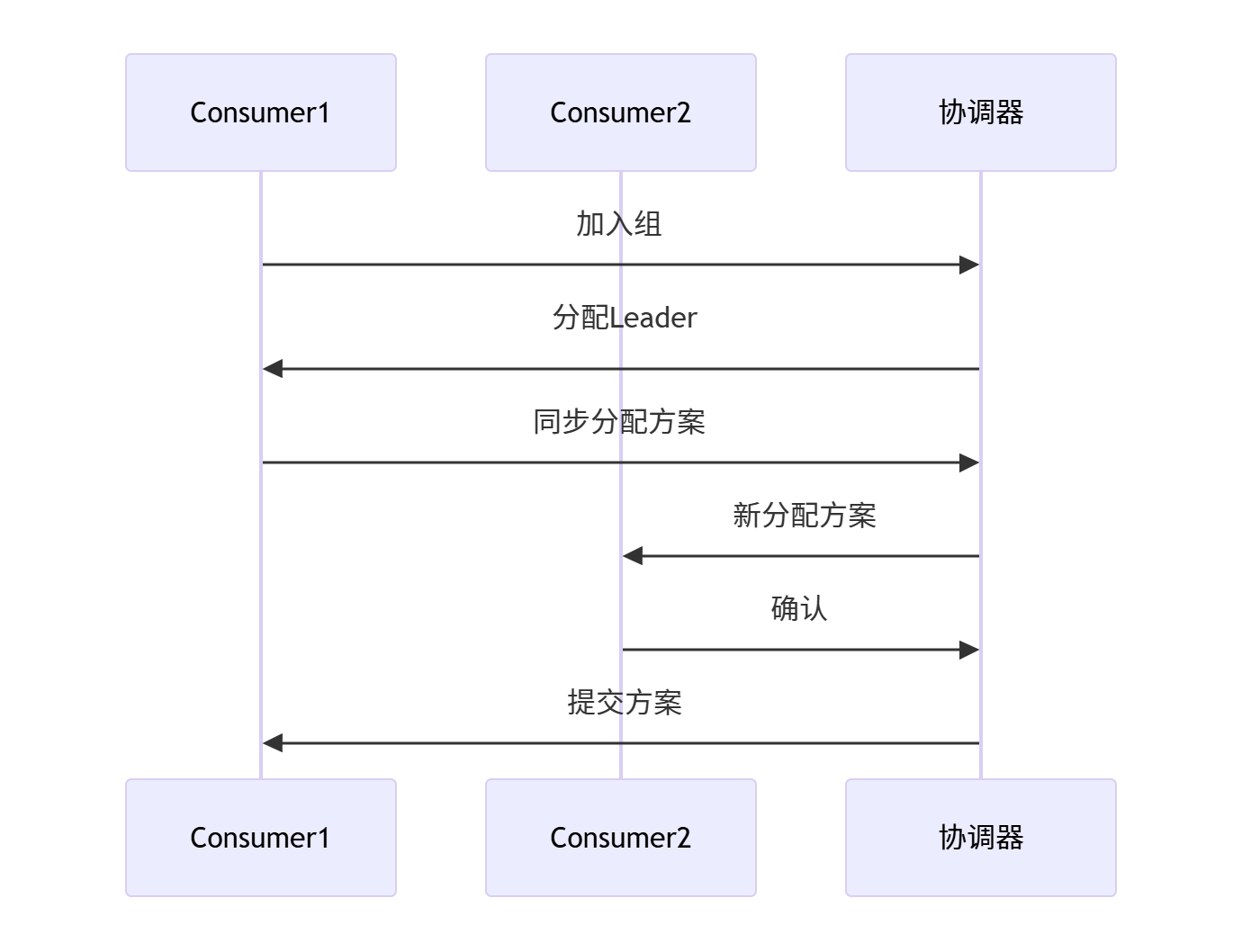
问题:Rebalance 期间消费暂停
优化方案:
- 使用 StickyAssignor 减少分区迁移
- 增加 session.timeout.ms(默认10s)
- 避免频繁重启消费者
⚙️4.3 手动分配分区
// 手动分配分区示例
List<TopicPartition> partitions = Arrays.asList(new TopicPartition("orders", 0),new TopicPartition("orders", 1)
);consumer.assign(partitions);
⏱️ 五、延迟队列实现方案
📉 5.1 原生限制与解决方案
🧪Kafka 限制:
消息立即可见,不支持延迟投递
🧪 常见方案对比:
🧭 实现方式 1:Redis ZSet + 轮询
利用 Redis ZSet 的 score 存储时间戳;
定时轮询执行延迟任务。
🧭 实现方式 2:Kafka 分区 + 时间轮调度
不同分区代表不同延迟级别;
消费端用时间轮轮询判断是否该消费。
🧭 实现方式 3:Kafka + Timer Server 中间件
Kafka 存消息,TimerServer 控制投递时间;
优点:高吞吐、解耦清晰。
5.2 🧪 选型对比
| 方案 | 吞吐 | 精度 | 成本 |
|---|---|---|---|
| Redis | 中 | 高 | 中 |
| Kafka+时间轮 | 高 | 中 | 低 |
| Kafka+TimerServer | 高 | 高 | 中高 |
🚧六、 消息积压处理实战指南
🔧6.1 积压原因排查
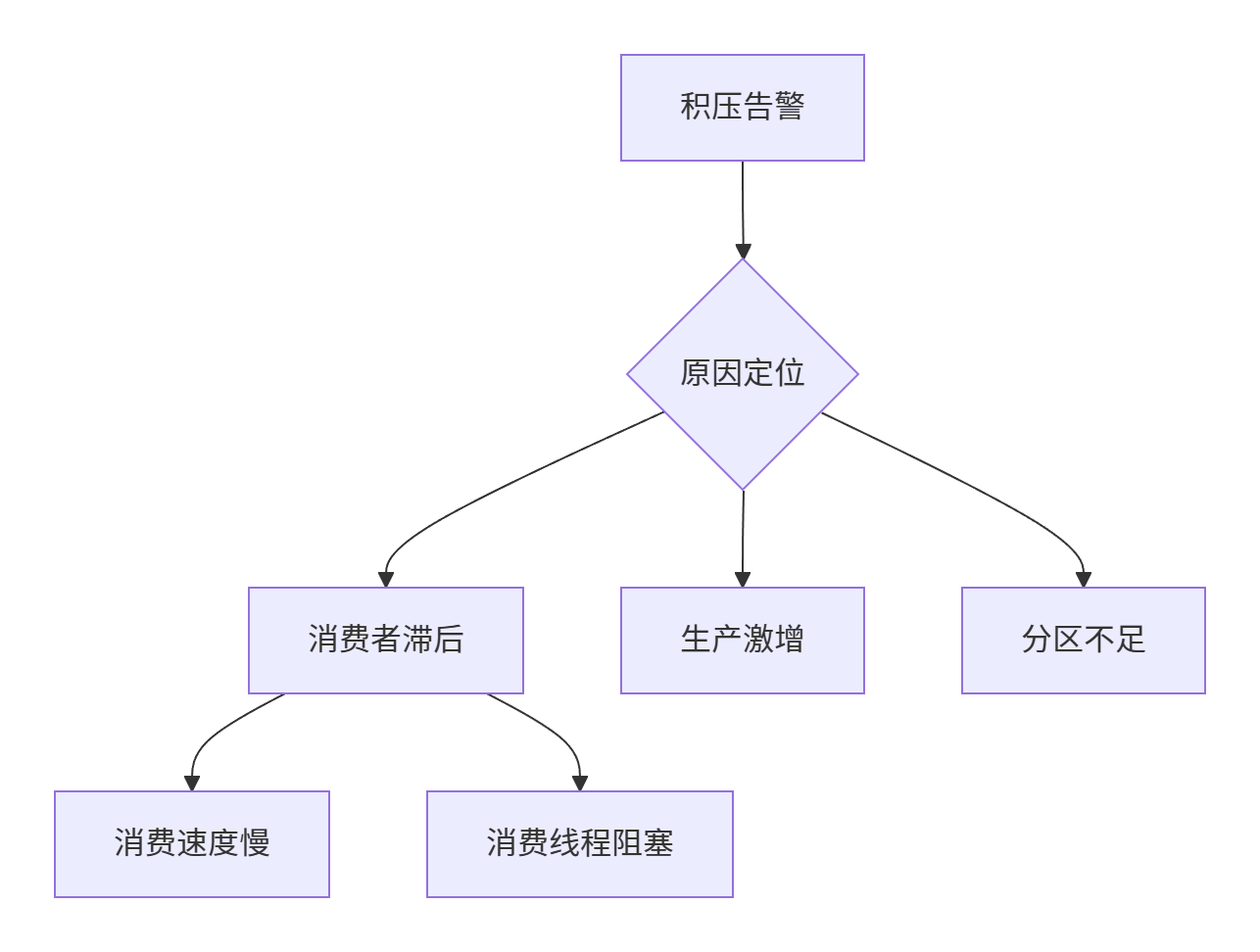
🛠️排查工具:
# 查看消费滞后
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group# 输出示例
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG
orders 0 10000 50000 40000
🧪6.2 应急处理方案
扩容消费者:
// 增加消费线程
Properties props = new Properties();
props.put("max.poll.records", "1000"); // 默认500
props.put("max.partition.fetch.bytes", "1048576"); // 默认1MB// 创建多线程消费者
ExecutorService executor = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {executor.submit(() -> {KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Collections.singletonList("orders"));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));// 处理记录}});
}
分区扩容:
bin/kafka-topics.sh --alter --topic orders \
--partitions 10 \ # 新分区数
--bootstrap-server localhost:9092
📉6.3 监控体系搭建
Prometheus + Grafana 监控:
# prometheus.yml 配置
scrape_configs:- job_name: 'kafka'static_configs:- targets: ['kafka-broker1:7071']- job_name: 'kafka_consumer'static_configs:- targets: ['consumer-app:7072']
关键监控指标:
- kafka_consumer_lag:消费滞后
- kafka_server_brokertopicmetrics_bytesin_total:流入流量
- kafka_network_requestmetrics_totaltimems:请求处理时间
🏆七、 总结与最佳实践
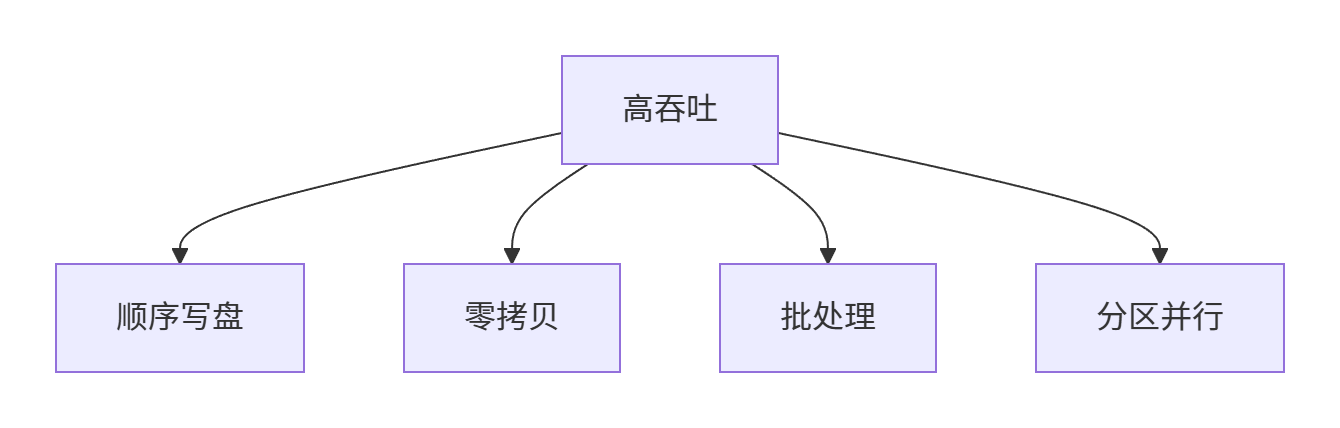
🧠 7.1 Kafka 高吞吐核心
🧠7.2 角色优化建议
| 角色 | 优化重点 |
|---|---|
| 架构师 | 分区设计、副本规划、集群拓扑 |
| 开发者 | 生产者批处理、消费者并发、错误处理 |
| 运维 | 监控告警、参数调优、容量规划 |
❌7.3 不适用场景
- 强事务系统:需额外实现事务机制
- 强顺序场景:仅保证分区内有序
- 小消息高频:建议合并消息
八、📚 进阶阅读推荐
- MirrorMaker 2.0 跨集群同步实战
- Kafka vs RocketMQ 对比剖析
- Kafka + Flink 实时流处理最佳实践
讨论话题:你在使用 Kafka 时遇到的最大挑战是什么?
👇 欢迎评论区分享实战经验!




)


)
- 数据结构】数组和特殊矩阵)






)

)

