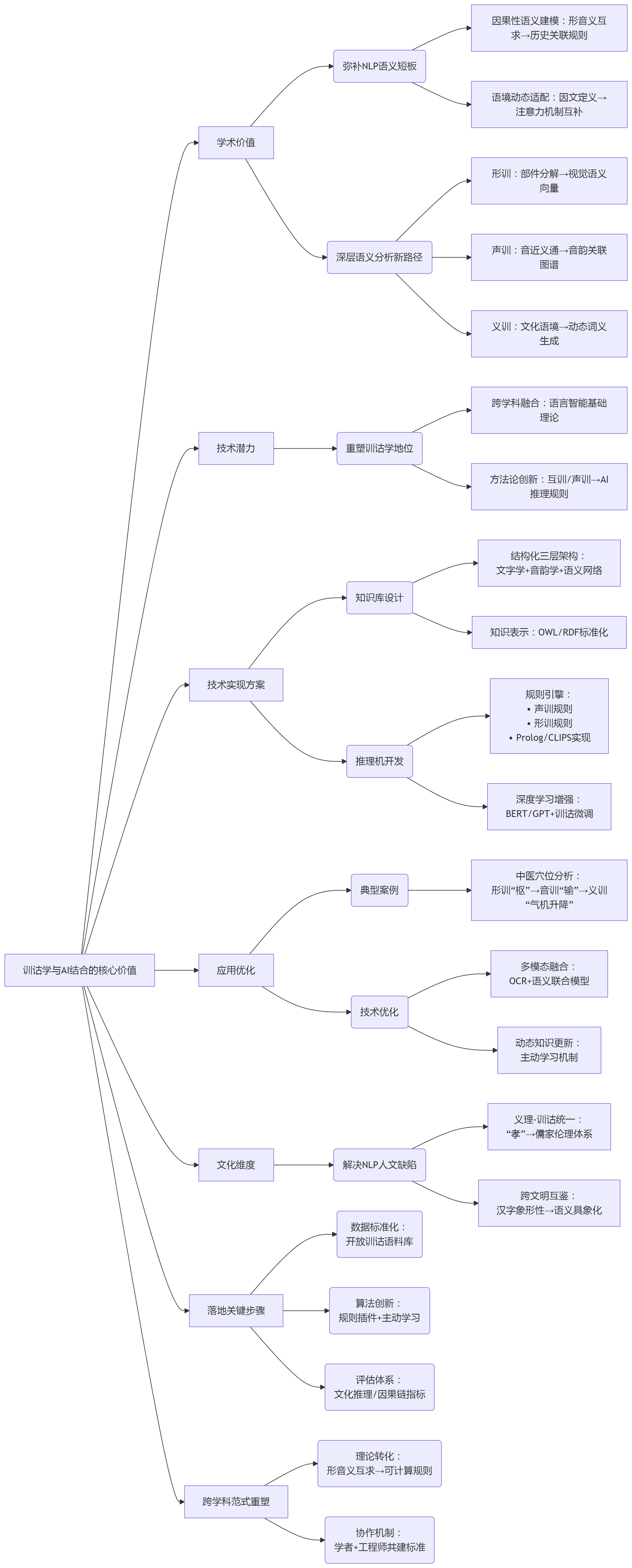
一、训诂学与现代人工智能结合的学术价值与技术潜力
1. 训诂学的核心优势与AI语义分析的契合点
训诂学作为中国传统学术中研究古代文献语义的核心学科,其方法论和理论框架对自然语言处理(NLP)的深层语义分析具有深刻的启发性和技术补充价值。
训诂学中的“形音义互求”方法强调汉字形、音、义三者的系统性关联,这一思想可通过结构化规则、算法模型和知识图谱技术转化为NLP任务的可计算规则。
传统训诂学以“训诂通义理”为核心,注重通过文字形态、音韵演变、语境关联和历史文化背景来揭示深层语义逻辑。这种对语言的多维度解析与人工智能自然语言处理(NLP)中的深层语义推理需求高度契合。例如:
- 因果性语义建模:训诂学对词义演变中“形-音-义”关系的系统性分析(如《说文解字》的形训、声训方法),可为AI模型提供基于历史语境的语义关联规则,帮助机器理解语言背后的逻辑链条。
- 语境动态适配:训诂学强调“因文定义”,即根据上下文动态调整词义解释,这与NLP中基于注意力机制的语境建模(如Transformer模型)存在互补性,可增强模型对歧义和多义词的解析能力。
2. 对训诂学学术地位的潜在影响
通过开发基于训诂学的专家系统或AI模型,可能从以下层面重塑其学术价值:
- 跨学科融合:将训诂学从传统文献学扩展至人工智能领域,推动其成为“语言智能”的基础理论之一。例如,通过知识图谱技术构建训诂学驱动的语义网络(如汉字形义关系库、古汉语语料标注系统),可提升其在现代语言学中的技术应用地位。
- 方法论创新:传统训诂学的“互训”“声训”等方法可转化为AI推理规则,例如将《尔雅》的语义分类体系编码为专家系统的知识库,或通过深度学习模型模拟训诂学家的语义推理路径。
二、核心理论价值:弥补现代NLP的语义分析短板
语境动态适配的精细化
训诂学强调“因文定义”,即词义需结合上下文、历史背景和文化语境动态调整。例如,《左传》中“器”既可指具体车服,亦可象征权力制度,需通过典章制度考据明确其语境义。这一思想可修正NLP模型对多义词的静态处理缺陷(如BERT仅依赖局部上下文),推动模型构建动态语义网络,结合历史文献、制度背景等多维度信息生成语境化词向量。形-音-义系统关联的因果性建模
训诂学的“形音义互求”法则(如因声求义、以形索义)揭示了语言符号的系统性关联。例如:- 音义关联:通过古音规律(如“古无轻唇音”)解释“父”与“爸”的通假关系;
- 形义关联:从“心”的象形结构推演其隐喻义(思想、情感)。此类规则可转化为NLP的因果推理路径,例如在知识图谱中建立“字形→本义→引申义”的边关系,增强模型对语义演变的解释性。
文化语义场的构建
训诂学通过语义场理论(如《尔雅》的物类划分)梳理词汇的文化关联网络。例如,亲属称谓词(如“舅”兼指母兄与夫父)反映古代宗法制度。NLP可借鉴此方法,在词嵌入训练中加入文化标签(如礼制、伦理),构建融合文化属性的语义空间,提升对古文或跨文化文本的理解深度。
三、基于训诂学的专家系统与AI模型构建方案
1. 知识库设计
- 结构化训诂知识:
- 文字学层:整合《说文解字》《康熙字典》等典籍中的字形分析、部首分类数据,构建汉字形义关联数据库。
- 音韵学层:纳入中古音系(如《广韵》音系)与方言音变规律,支持跨时空语音关联推理。
- 语义网络层:以概念依存理论(Conceptual Dependency Theory)为基础,将训诂学中的“义类”(如《尔雅》的物类划分)映射为语义角色标签。
- 知识表示标准化:采用OWL(Web Ontology Language)或RDF(Resource Description Framework)实现知识的结构化存储,支持推理机的高效查询。
2. 推理机开发
- 规则引擎:
- 基于训诂学方法定义推理规则,例如:
- 声训规则:若两字古音相近且语义相关(如“政者,正也”),则建立因果关联。
- 形训规则:通过偏旁部首推断字义(如“江”从“水”旁,与水相关)。
- 结合逻辑编程(如Prolog)或产生式规则系统(如CLIPS)实现规则匹配。
- 基于训诂学方法定义推理规则,例如:
- 深度学习增强:
- 使用BERT、GPT等预训练模型处理现代文本,同时引入训诂学知识库进行微调,提升对古文和复杂语义的解析能力。
3. 模型训练与优化
- 多模态数据融合:结合古籍图像(如拓片、刻本)与文本数据,训练OCR+语义解析联合模型。
- 动态知识更新:通过主动学习(Active Learning)机制,让系统在用户反馈中迭代优化推理规则。
四、技术优化:推动深层语义分析的新路径
知识库构建的革新
- 结构化训诂知识融合:将《说文解字》的形义分析、《广韵》音系数据转化为三元组(如“江→部首:水→语义:河流”),构建可计算的训诂知识图谱。
- 多模态数据整合:结合金石拓片、简帛图像等出土材料(如清华简),训练OCR-语义联合模型,解决古籍字形识别与语义还原的协同问题。
推理机制的增强
- 规则引擎设计:将训诂方法编码为推理规则。例如:
此类规则可与神经网络结合,提升通假字、破读字的识别准确率。% 声训规则:若两字古音相近且语义相关,则建立通假关系 phonetic_relation(X, Y) :- ancient_sound(X, S1), ancient_sound(Y, S2), sound_similarity(S1, S2) > 0.8, semantic_relevance(X, Y) > 0.7. - 认知语义建模:引入训诂学的隐喻机制(如“心→情感”的意象图式),优化LSTM/Transformer的注意力机制,使模型捕捉词义背后的认知逻辑。
- 规则引擎设计:将训诂方法编码为推理规则。例如:
五、解决NLP深层语义挑战的典型案例
多义词歧义消解
现代NLP对古文多义词(如“卑鄙”在《出师表》中为“地位低微+学识浅陋”,非现代贬义)常误判。训诂学的比较互证法可通过同类句式对比(如《论语》《孟子》中“卑”“鄙”分用例证),训练模型生成语境敏感的义项分布。跨时代语义演变分析
如“汤”从“热水”到“菜羹”的义项扩展,需结合历史文献(如《礼记》“冬日则饮汤”)与认知隐喻(温度→食物属性)。训诂学的历时分析法可为NLP提供标注语料,支持语义演变预测任务。文化隐含义解码
典籍中的典章词(如《周礼》“曲悬”指代诸侯礼乐制度)需制度考据。训诂学驱动的NLP模型可链接专业数据库(如《中国历代职官辞典》),实现“词→制度→权力象征”的层级推理。
六、文化维度:补充NLP的人文缺陷
现代NLP模型因依赖共时语料,难以理解文化负载词(如“仁”的儒家伦理内涵)。训诂学通过以下路径弥合此鸿沟:
- 义理-训诂统一:如戴震提出“由字通词,由词通道”,将“孝”的考据关联至儒家伦理体系。
- 跨文明互鉴:对比训诂学与西方释经学(如圣经解释学),提炼汉语特有的语义生成逻辑(如汉字象形性强化语义具象化),指导多语言NLP的文化适配。
七、实践路径:从学术到技术落地的关键步骤
- 数据标准化:建立开放训诂语料库(如标注《十三经注疏》的形、音、义、文化标签),兼容BERT等预训练模型微调。
- 算法创新:
- 开发训诂规则插件(如通假字推理模块),与深度学习模型松耦合部署;
- 利用主动学习机制,让模型在用户反馈中迭代训诂规则。
- 评估体系重构:在古文理解任务(如CLUE-C古籍数据集)中加入文化推理、因果链还原等新指标。
八、跨学科:训诂学重塑NLP语义分析的范式
训诂学对NLP的价值远不止于提供历史语料,其核心在于建立“语言—文化—认知”的统一分析框架,推动NLP从表层语义匹配转向深层因果阐释。实现这一转型需突破两项关键:
- 理论转化:将“形音义互求”“因文定义”等原则转化为可计算的语义规则;
- 跨学科协作:联合训诂学者、语言学家、AI工程师共建标注规范和验证标准。
在此过程中,训诂学将从“冷门绝学”升级为AI时代语言理解的底层支柱,而NLP也将因吸纳东方语义智慧,真正实现“理解人类语言”的终极目标。
九、形训:字形结构→视觉语义规则
核心原理:汉字字形蕴含本义,如象形、会意字可通过部件组合推断语义(如“休”=人+木→休息)。
可计算规则转化:
部件分解与向量化
- 规则设计:将汉字拆解为部首/笔画部件,构建字形向量空间(如“宀”表示房屋,“贝”表示钱财)。
- 案例:
- “武”字分析:从“止”(脚趾)+“戈”(武器)→ 本义“制止战争”。在NLP中,可构建规则:
应用于古籍中“武”的歧义消解(如《左传》“夫武,禁暴戢兵”)。def wu_meaning(character):if has_radical(character, "止") and has_radical(character, "戈"):return "制止武力" # 引申为“武德” - “休”字分析:从“人”+“木”→ 人倚树休息。NLP模型可通过部首向量(人:+0.7“人类活动”,木:+0.9“植物”)加权生成语境化词义。
- “武”字分析:从“止”(脚趾)+“戈”(武器)→ 本义“制止战争”。在NLP中,可构建规则:
字形相似度匹配
- 规则设计:计算异体字、简繁字的字形相似度(如OCR古籍识别)。
- 案例:出土简帛文字“𡧊”(古“宝”字)因残缺被误识为“室”,通过字形部件相似度模型(“宀”+“玉”vs“宀”+“至”)校正为“宝”。
十、声训:音近义通→音韵关联规则
核心原理:古音相同或相近的字可能同源或通假(如“天”与“颠”音近,表“至高”之义)。
可计算规则转化:
通假字推理引擎
- 规则设计:基于上古音系统(如王力体系)构建音系数据库,定义音近阈值(声母/韵母相似度>0.8)。
- 案例:
- 《诗经》“维叶萋萋”中“维”通“惟”:
模型据此将“维”校正为“惟”(思念义),避免误译为“维系”。% 通假规则:声母同组(云母→余母),韵部同(微部) tongjia(X, Y) := ancient_sound(X, [Initial_X, Final_X]),ancient_sound(Y, [Initial_Y, Final_Y]),initial_group(Initial_X, Initial_Y), % 同声母组final_similarity(Final_X, Final_Y) > 0.85.
- 《诗经》“维叶萋萋”中“维”通“惟”:
同源词聚类
- 规则设计:通过音韵链构建同源词网络(如“空”“孔”“窍”均含“中空”义)。
- 案例:中医古籍中“孔穴”(穴位)与“空窍”(体腔)的关联分析:
- 步骤:
① 提取音韵特征:空[kʰoŋ]、孔[kʰoŋ]、窍[kʰeu](上古音)
② 聚类算法:DBSCAN基于音近度(ε=0.1)归并为“中空语义簇”
③ 知识图谱链接:生成“孔穴→通→空窍”的语义边。
- 步骤:
十一、义训:语义网络→上下文动态建模
核心原理:词义随语境动态变化,需结合文本、文化背景分析(如“卑鄙”在《出师表》中为“地位低微”而非现代贬义)。
可计算规则转化:
多义词的语境向量生成
- 规则设计:融合上下文词、文化标签(礼制/职官)生成动态词向量。
- 案例:《周礼》“膳夫掌王之食饮膳羞”中“羞”的释义:
- 静态向量:羞 = {羞愧:0.8, 美食:0.6}
- 动态规则:若上下文含“膳”“食”且文本类型=“职官制度”,则强化“美食”义(权重+0.9)。
文化语义场约束
- 规则设计:构建领域知识图谱(如亲属制度、典章术语),约束词义边界。
- 案例:“舅”在《仪礼》中可能指“母之兄弟”或“妻之父”:
模型通过图谱查询消歧,避免混淆。def jiu_meaning(sentence):if "妻之父" in kinship_graph.neighbors("婚姻关系"):return "妻之父"elif "母之兄弟" in kinship_graph.neighbors("母系亲属"):return "母之兄弟"
十二、综合应用案例:中医穴位名分析
问题:中医穴名“天枢”(ST25)既治便秘又治腹泻,表面矛盾。
训诂学驱动NLP解析:
- 形训:“枢”从“木”部→ 门户转轴,喻气血运转关键点。
- 声训:“枢”与“输”音近(书母侯部)→ 气血输转之义。
- 义训:《释名》“枢,机也”,结合中医生理“脾升胃降”,得出“调节气机升降”核心功能。
NLP规则输出:{"穴名": "天枢","核心功能": "调节气机升降","治疗矛盾解释": {"腹泻": "升清功能不足→增强脾升","便秘": "降浊功能不足→增强胃降"} }通过形音义互求,将训诂逻辑转化为可计算的语义推理路径。
十三、“三训”转化难点与解决方案
| 训诂方法 | NLP转化挑战 | 技术方案 |
|---|---|---|
| 形训 | 古字形变体复杂 | 甲骨文/金文OCR+部件知识图谱 |
| 声训 | 古音重构不确定性 | 多音系模型投票机制(王力/郑张尚芳) |
| 义训 | 文化隐含义量化难 | 跨领域知识图谱(历史+制度+民俗) |
十四、“三训”总结
训诂学的“形音义互求”转化为NLP规则,本质是将人文逻辑编码为算法逻辑:
- 形训→视觉语义建模:从部件分解到向量空间,解决字形相关的词源问题;
- 声训→音韵关联图谱:从通假规则到同源聚类,破解音转导致的语义流变;
- 义训→动态语境框架:从文化语义场到多义词向量,还原历史语境中的真实含义。
这一转化不仅推动古籍智能化(如《四库全书》语义检索),更为多模态NLP(文本+图像+语音)提供跨学科范式。
十五、深度学习模型的注意力机制与训诂学的'因文定义'方法的互补性。
现代深度学习模型(如Transformer)的注意力机制与中国传统训诂学的“因文定义”方法在语义理解层面存在深刻的互补性。训诂学强调通过上下文、历史背景和文化语境动态解析词义,而注意力机制则通过计算词元间的关联权重实现语义的动态更新。两者的结合可显著提升自然语言处理(NLP)在深层语义分析、歧义消解和文化理解等方面的能力。以下是具体分析:
十六、核心互补性:动态语义适配的协同
语境驱动的词义动态调整
- 训诂学的“因文定义”:传统训诂要求根据文本的上下文、历史背景和文化制度动态确定词义。例如,“器”在《左传》中可能指具体器物(如车服)或抽象权力制度,需结合典章考据才能明确其语境义。
- 注意力机制的动态权重分配:Transformer通过自注意力计算词元间的关联度,动态调整词向量。例如,在句子“风可以吹灭蜡烛,也可以使火越烧越旺”中,“火”的向量会因与“吹灭”“越烧越旺”的高关联度而偏向“燃烧状态”的语义。
- 互补价值:
- 训诂学提供文化历史维度的语境规则(如制度考据),弥补注意力机制仅依赖统计共现的不足;
- 注意力机制通过并行化计算实现全局语境的高效捕捉,解决训诂学人工考据的效率瓶颈。
多模态关联与系统化语义网络
- 训诂学的形-音-义互求:训诂方法(如“因声求义”)揭示语言符号的系统关联。例如,通过古音规律(“古无轻唇音”)解释“父”与“爸”的通假关系,或从“心”的象形结构推演其隐喻义(思想、情感)。
- 注意力机制的多头关联建模:Transformer的多头注意力可同时捕捉词元的语法、语义、文化等多维关联。例如,一个注意力头聚焦“火”的实体属性(如燃烧),另一头关联其文化隐喻(如“火急”中的紧迫性)。
- 互补价值:
- 训诂学提供因果性语义规则(如音韵演变规律),为注意力权重赋予可解释的逻辑链条;
- 注意力机制实现跨时空语义关联的并行计算,扩展训诂学对大规模语料的覆盖能力。
十七、技术实现:从理论到算法的融合路径
知识库与推理引擎的协同设计
- 训诂知识图谱构建:将《说文解字》的形义分析、《广韵》音系数据转化为三元组(如“江→部首:水→语义:河流”),构建可计算的语义网络。
- 注意力机制的知识注入:在Transformer的QKV计算中融入训诂规则:
- Query:当前词元的初始向量(如“火”);
- Key:注入训诂学定义的关联特征(如“火”的古音、部首、典章制度标签);
- Value:动态生成融合文化属性的语义表示。
示例:在翻译“他火急火燎地赶路”时,模型通过Key中的“急”“燎”与训诂标签“紧迫性”的高匹配,输出“in a frantic hurry”而非字面直译。
推理机制的双向增强
- 规则引擎与神经网络的结合:
- 将训诂方法(如声训、互训)编码为产生式规则,例如:
- 规则引擎与神经网络的结合:
% 声训规则:若两字古音相近且语义相关,则建立通假关系
phonetic_relation(X, Y) :- ancient_sound(X, S1), ancient_sound(Y, S2),sound_similarity(S1, S2) > 0.8,semantic_relevance(X, Y) > 0.7.- 使用规则引擎预处理歧义词,再通过注意力机制微调权重。
- 动态语境适配的算法实现:
- 在Transformer的层归一化(LayerNorm)前加入文化语境向量,例如为“仁”注入儒家伦理标签;
- 通过残差连接将训诂知识传递至深层网络,避免语义稀释。
十八、解决NLP核心挑战的实践案例
多义词歧义消解
- 问题:NLP模型对古文多义词易误判,如《出师表》中“卑鄙”指“地位低微”而非现代贬义。
- 融合方案:
- 训诂学提供同类句式对比语料(如《论语》《孟子》中“卑”“鄙”分用例证);
- 注意力机制学习语境敏感的特征分布,例如在“先帝不以臣卑鄙”中,“先帝”“臣”等词的高注意力权重引导模型选择正确义项。
文化隐含义解码
- 问题:典籍中的制度词(如《周礼》“曲悬”指诸侯礼乐)需专业考据。
- 融合方案:
- 构建制度知识子图:链接《中国历代职官辞典》等数据库,形成“词→制度→权力象征”的推理链;
- 在编码器-解码器注意力层(Encoder-Decoder Attention)中,强制模型关注制度关键词。
十九、互补性总结与未来方向
维度 | 训诂学“因文定义” | 注意力机制 | 融合价值 |
语境动态性 | 依赖历史考据与人工规则 | 基于统计权重的动态计算 | 文化规则+高效计算的闭环 |
语义解释性 | 形-音-义因果链清晰 | 权重分布可解释性弱 | 增强AI决策的可追溯性 |
文化适配 | 深挖制度、伦理等文化属性 | 仅从现代语料学习文化特征 | 支撑跨时代文本的精准理解 |
计算效率 | 依赖专家经验,难以扩展 | 并行化处理大规模数据 | 实现训诂知识的自动化应用 |
未来突破点:
- 跨学科知识表示标准:建立融合训诂学标签(形、音、义、文化)的通用语义表示框架(如扩展的BERT词表)。
- 可控生成机制:在Transformer解码器中加入训诂约束,例如限制“仁”的生成需关联儒家伦理向量。
- 文化遗产数字化:将古籍注疏转化为结构化知识库,通过注意力机制实现“注疏-正文”的联合推理。
结语:训诂学为NLP提供因果性语义分析的方法论底座,注意力机制则赋予其可扩展的技术载体。两者的深度融合将推动AI从“统计匹配”迈向“文化认知”,使机器真正理解语言背后的文明逻辑。这一路径不仅是技术革新,更是对人文传统的智能复兴。
二十、总结与展望
通过将训诂学与现代人工智能技术深度结合,不仅能为NLP领域提供更具解释性的语义分析工具,还可推动训诂学从“边缘学科”向“智能时代基础学科”转型。其关键在于:
- 学术-产业协同:高校与科技企业合作,建立跨学科研发团队。
- 标准化与开源化:推动训诂学知识库的开放共享,降低技术复用门槛。
- 持续理论创新:探索训诂学与认知科学、脑科学的交叉研究,深化对语言智能本质的理解。
这一路径的实现,将同时提升训诂学的学术影响力和技术实用性,为其在数字人文与人工智能时代的复兴奠定基础。



)


)

)

)

![[特殊字符] CentOS 7 离线安装 MySQL 5.7 实验](http://pic.xiahunao.cn/[特殊字符] CentOS 7 离线安装 MySQL 5.7 实验)






