在奇麟大数据业务系统的开发及使用过程中,例如OBS对象存储文件管理、流计算DSC依赖管理,经常会遇到上传文件这样的基础需求,一般情况下,前端上传文件就是new FormData,然后把文件 append 进去,然后post发送给后端就完事了,但是文件越大,上传的文件也就越长,在上传过程中,经常会遇到请求超时或者阻碍用户继续操作的情况,十分影响用户体验,因为把该文件直接在一个请求体中提交,会出现一些问题,以nginx为例:
其默认允许1MB以内的文件
超过1MB的文件,需要设置
client_max_body_size放开体积限制
一味地只放宽Nginx的限制,会出现一些问题,最明显的问题是服务器的存储和网络带宽压力都会非常大。
以奇麟云存储OBS对象存储文件管理中使用的常规上传解决方案为例展示
// 将目标文件转为FormData数据流function uploadRequest (params) { const file = params.file const form = new FormData() form.append('file', file) const config = { headers: { 'Content-Type': 'multipart/form-data', }, onUploadProgress: e => { // 上传进度百分比 if (e.total > 0) { e.percent = e.loaded / e.total * 100 } params.onProgress(e) }, timeout: 0, // 上传文件不设置超时时间 } await request({'XXXX','post', form, config} .then(res => { // 上传成功 params.onSuccess(res) }) .catch(err => { params.onError(err) }) .finally(() => {})}上传文件过大的情况,很容易出现网络超时导致接口报错的情况,且用户在当前操作页面无法终止,只能持续等待直至上传操作完成
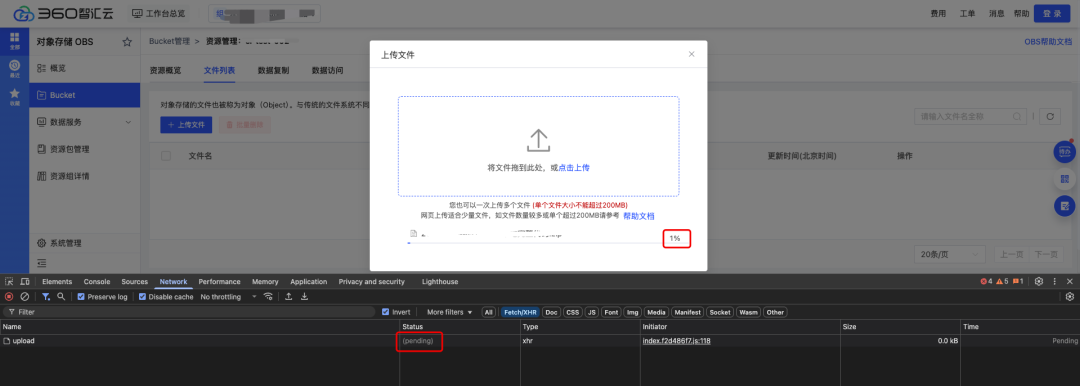
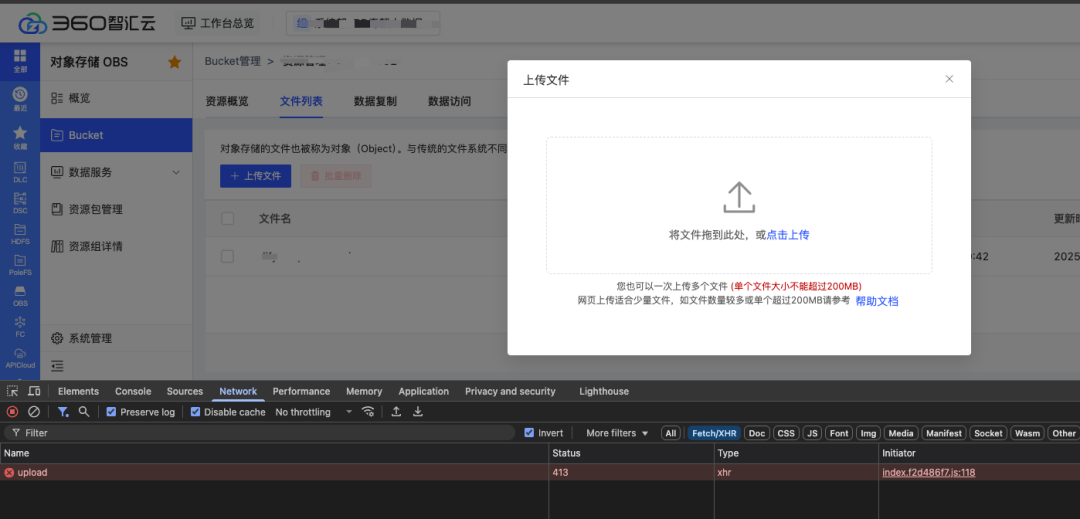
为了解决上述业务痛点,这里就需要寻求大文件上传的解决方案,核心是利用 Blob.prototype.slice 方法,和数组的 slice 方法相似,文件的 slice 方法可以返回 原文件的某个切片
提前定义好单个切片大小,将大文件切分为一个个小的切片,然后借助 http 的可并发性,同时上传多个切片。这样从原本传一个大文件,变成了并发传多个小的文件切片,可以大大减少上传时间
因为由于是并发请求传输,所以传输到服务端的切片文件顺序可能会发生变化,因此我们还需要给每个切片记录顺序
1、前端实现部分
前端使用 Vue 作为开发框架,组件库使用 Element-Plus 作为 UI 框架
1.1 上传控件
首先创建选择文件的控件并监听 change 事件,另外就是上传按钮
<template> <div class="upload-container"> <input type="file" @change="handleFileChange" /> <el-button @click="handleUpload">upload</el-button> </div></template><script setup>import { ref } from 'vue'const container = ref({ file: null})function handleFileChange(e) { const [file] = e.target.files; if (!file) return; container.value.file = file;}async handleUpload() { // ...}</script>1.2 请求逻辑
request({ url, method = "post", data, headers = {}, requestList }) { return new Promise(resolve => { const xhr = new XMLHttpRequest(); xhr.open(method, url); Object.keys(headers).forEach(key => xhr.setRequestHeader(key, headers[key]) ); xhr.send(data); xhr.onload = e => { resolve({ data: e.target.response }); }; });}1.3 上传切片
接着就要实现核心的上传功能,上传需要做两件事
对文件进行切片
将切片传输给服务端
<template> <div> <input type="file" @change="handleFileChange" /> <el-button @click="handleUpload">上传</el-button> </div></template><script setup>import { ref } from 'vue';// 设置默认切片大小 10MB const SIZE = 10 * 1024 * 1024; const data = ref([])const container = ref({ file: null})function request() { // ****}function handleFileChange() { // ***} // 生成文件切片 function createFileChunk(file, size = SIZE) { const fileChunkList = []; let cur = 0; while (cur < file.size) { fileChunkList.push({ file: file.slice(cur, cur + size) }); cur += size; } return fileChunkList; } // 上传切片 async function uploadChunks() { const requestList = data.value .map(({ chunk,hash }) => { const formData = new FormData(); formData.append("chunk", chunk); formData.append("hash", hash); formData.append("filename", container.value.file.name); return { formData }; }) .map(({ formData }) => request({ url: "http://localhost:8888", data: formData }) ); // 并发请求 await Promise.all(requestList); } async function handleUpload() { if (!container.value.file) return; const fileChunkList = createFileChunk(container.value.file); data.value = fileChunkList.map(({ file },index) => ({ chunk: file, // 文件名 + 数组下标 hash: container.value.file.name + "-" + index })); await uploadChunks(); }</script>用户点击上传按钮时,调用 createFileChunk方法 将文件切片,切片数量通过文件大小控制,这里设置 10MB,也就是说一个 100 MB 的文件会被分成 10 个 10MB 的切片
createFileChunk 内使用 while 循环和 slice 方法将切片放入 fileChunkList 数组中返回
在生成文件切片时,需要给每个切片一个标识作为 hash,这里暂时使用文件名 + 下标的标记方式,这样后端可以知道当前切片是第几个切片,用于之后的合并切片
随后调用 uploadChunks 上传所有的文件切片,将文件切片,切片 hash,以及文件名放入 formData 中,再调用上一步的 request 函数返回一个 proimise,最后调用 Promise.all 并发上传所有的切片
1.4 发送合并请求
使用整体思路中提到的第二种合并切片的方式,即前端主动通知服务端进行合并
前端发送额外的合并请求,服务端接受到请求时合并切片
<template> <div> <input type="file" @change="handleFileChange" /> <el-button @click="handleUpload">upload</el-button> </div></template><script setup>import { ref } from 'vue';// 设置默认切片大小 10MB const SIZE = 10 * 1024 * 1024; const data = ref([])const container = ref({ file: null})function request() { // ****}function handleFileChange() { // ***}// 生成文件切片function createFileChunk(file, size = SIZE) { const fileChunkList = []; let cur = 0; while (cur < file.size) { fileChunkList.push({ file: file.slice(cur, cur + size) }); cur += size; } return fileChunkList;}// 上传切片async function uploadChunks() { const requestList = data.value .map(({ chunk,hash }) => { const formData = new FormData(); formData.append("chunk", chunk); formData.append("hash", hash); formData.append("filename", container.value.file.name); return { formData }; }) .map(({ formData }) => request({ url: "http://localhost:8888", data: formData }) ); // 并发请求 await Promise.all(requestList) // 合并切片 await mergeRequest()}async function handleUpload() { if (!container.value.file) return; const fileChunkList = createFileChunk(container.value.file); data.value = fileChunkList.map(({ file },index) => ({ chunk: file, // 文件名 + 数组下标 hash: container.value.file.name + "-" + index })); await uploadChunks() async function mergeRequest() { await request({ url: "http://localhost:8888/mergeFile", headers: { "content-type": "application/json" }, data: JSON.stringify({ filename: container.value.file.name }) }) }}</script>2、服务端部分,以NodeJs为例
服务端负责接受前端传输的切片,并在接收到所有切片后合并所有切片
这里又引伸出两个问题
服务端合并切片的时机,即切片什么时候传输完成?
如何进行切片合并,合并的规则是什么?
第一个问题需要前端配合,前端在每个切片中都携 带切片最大数量的信息,当服务端接受到这个数量的切片时自动合并。或者也可以额外发一个请求,主动通知服务端进行切片的合并
第二个问题,具体如何合并切片呢?这里可以使用 Nodejs 的 读写流(readStream/writeStream),将所有切片的流传输到最终文件的流里
使用 http 模块搭建一个简单服务端
const http = require("http");const server = http.createServer();server.on("request", async (req, res) => { res.setHeader("Access-Control-Allow-Origin", "*"); res.setHeader("Access-Control-Allow-Headers", "*"); if (req.method === "OPTIONS") { res.status = 200; res.end(); return; }});server.listen(8888, () => console.log("listening port 8888"));2.1 接受切片
使用 multiparty 处理前端传来的 formData
在 multiparty.parse 的回调中,files 参数保存了 formData 中文件,fields 参数保存了 formData 中非文件的字段
const http = require("http");const path = require("path");const fse = require("fs-extra");const multiparty = require("multiparty");const server = http.createServer();// 大文件上传的临时存储目录const UPLOAD_DIR_NAME = path.resolve(__dirname, "..", "target");server.on("request", async (req, res) => { res.setHeader("Access-Control-Allow-Origin", "*"); res.setHeader("Access-Control-Allow-Headers", "*"); if (req.method === "OPTIONS") { res.status = 200; res.end(); return; } const multipart = new multiparty.Form(); multipart.parse(req, async (err, fields, files) => { if (err) { return; } const [chunk] = files.chunk; const [hash] = fields.hash; const [filename] = fields.filename; // 创建临时文件夹用于临时存储 chunk // 添加 chunkDir 前缀与文件名做区分 const chunkDir = path.resolve(UPLOAD_DIR_NAME, 'chunkDir' filename); if (!fse.existsSync(chunkDir)) { await fse.mkdirs(chunkDir); } // fs-extra 的 rename 方法 windows 平台会有权限问题 // 参考: https://github.com/meteor/meteor/issues/7852#issuecomment-255767835 await fse.move(chunk.path, `${chunkDir}/${hash}`); res.end("received file chunks"); });});server.listen(8888, () => console.log("listening port 8888"));查看 multiparty 处理后的 chunk 对象,path 是存储临时文件的路径,size 是临时文件大小,在 multiparty 文档中提到可以使用 fs.rename(这里换成了 fs.remove, 因为 fs-extra 的 rename 方法在 windows 平台存在权限问题)
在接受文件切片时,需要先创建临时存储切片的文件夹,以 chunkDir 作为前缀,文件名作为后缀
由于前端在发送每个切片时额外携带了唯一值 hash,所以以 hash 作为文件名,将切片从临时路径移动切片文件夹中,最后的结果如下
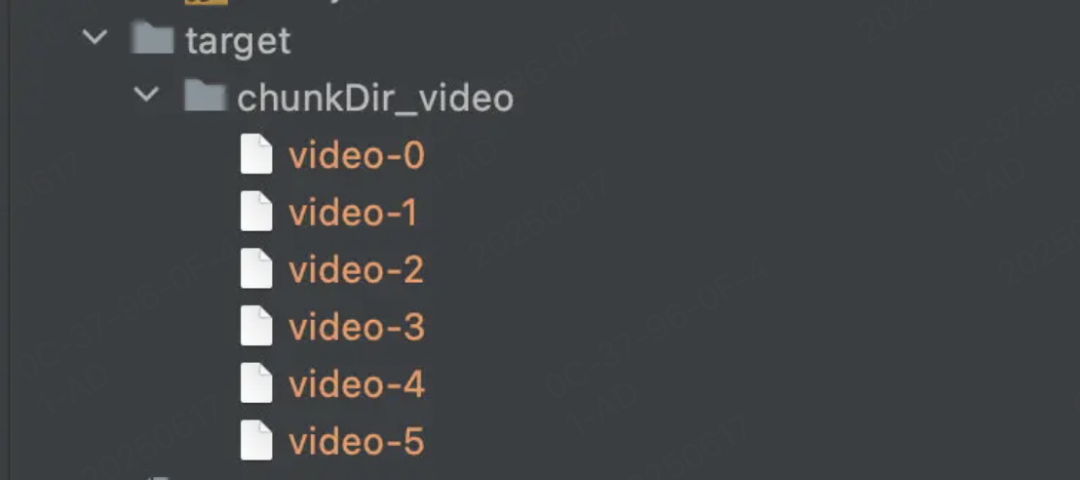
2.2 合并切片
在接收到前端发送的合并请求后,服务端将文件夹下的所有切片进行合并
const http = require("http");const path = require("path");const fse = require("fs-extra");const server = http.createServer();const UPLOAD_DIR_NAME = path.resolve(__dirname, "..", "target");+ const resolvePost = req =>+ new Promise(resolve => {+ let chunk = "";+ req.on("data", data => {+ chunk += data;+ });+ req.on("end", () => {+ resolve(JSON.parse(chunk));+ });+ });+ // 写入文件流+ const pipeStream = (path, writeStream) =>+ new Promise(resolve => {+ const readStream = fse.createReadStream(path);+ readStream.on("end", () => {+ fse.unlinkSync(path);+ resolve();+ });+ readStream.pipe(writeStream);+ });// 合并切片+ const mergeFileChunk = async (filePath, filename, size) => {+ const chunkDir = path.resolve(UPLOAD_DIR_NAME, 'chunkDir' + filename);+ const chunkPaths = await fse.readdir(chunkDir);+ // 根据切片下标进行排序+ // 否则直接读取目录的获得的顺序会错乱+ chunkPaths.sort((a, b) => a.split("-")[1] - b.split("-")[1]);+ // 并发写入文件+ await Promise.all(+ chunkPaths.map((chunkPath, index) =>+ pipeStream(+ path.resolve(chunkDir, chunkPath),+ // 根据 size 在指定位置创建可写流+ fse.createWriteStream(filePath, {+ start: index * size,+ })+ )+ )+ );+ // 合并后删除保存切片的目录+ fse.rmdirSync(chunkDir);+};server.on("request", async (req, res) => { res.setHeader("Access-Control-Allow-Origin", "*"); res.setHeader("Access-Control-Allow-Headers", "*"); if (req.method === "OPTIONS") { res.status = 200; res.end(); return; }+ if (req.url === "/mergeFile") {+ const data = await resolvePost(req);+ const { filename,size } = data;+ const filePath = path.resolve(UPLOAD_DIR_NAME, `${filename}`);+ await mergeFileChunk(filePath, filename);+ res.end(+ JSON.stringify({+ code: 0,+ message: "file merged success"+ })+ );+ }});server.listen(8888, () => console.log("listening port 8888"));由于前端在发送合并请求时会携带文件名,服务端根据文件名可以找到上一步创建的切片文件夹,接着使用 fs.createWriteStream 创建一个可写流,可写流文件名就是上传时的文件名,随后遍历整个切片文件夹,将切片通过 fs.createReadStream 创建可读流,传输合并到目标文件中。
值得注意的是每次可读流都会传输到可写流的指定位置,这是通过 createWriteStream 的第二个参数 start 控制的,目的是能够并发合并多个可读流至可写流中,这样即使并发时流的顺序不同,也能传输到正确的位置。所以还需要让前端在请求的时候提供之前设定好的 size 给服务端,服务端根据 size 指定可读流的起始位置
async mergeRequest() { await request({ url: "http://localhost:8888/mergeFile", headers: { "content-type": "application/json" }, data: JSON.stringify({+ size: SIZE, filename: container.value.file.name }) }); }其实也可以等上一个切片合并完后再合并下个切片,这样就不需要指定位置,但传输速度会降低,所以使用了并发合并的手段
接着只要保证每次合并完成后删除这个切片,等所有切片都合并完毕后最后删除切片文件夹即可
至此一个简单的大文件上传就完成了,接下来我们在此基础上扩展一些额外的功能
2.3 总进度条
将每个切片已上传的部分累加,除以整个文件的大小,就能得出当前文件的上传进度,所以这里使用 Vue 的计算属性
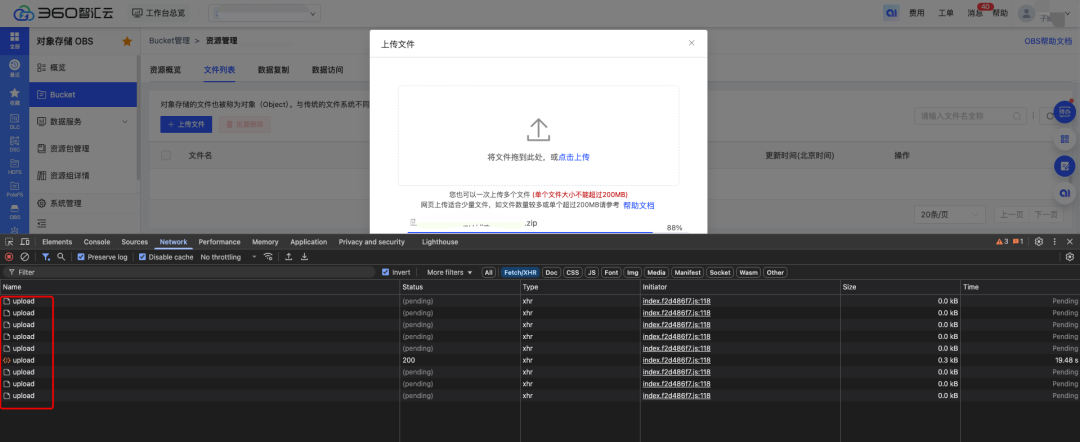
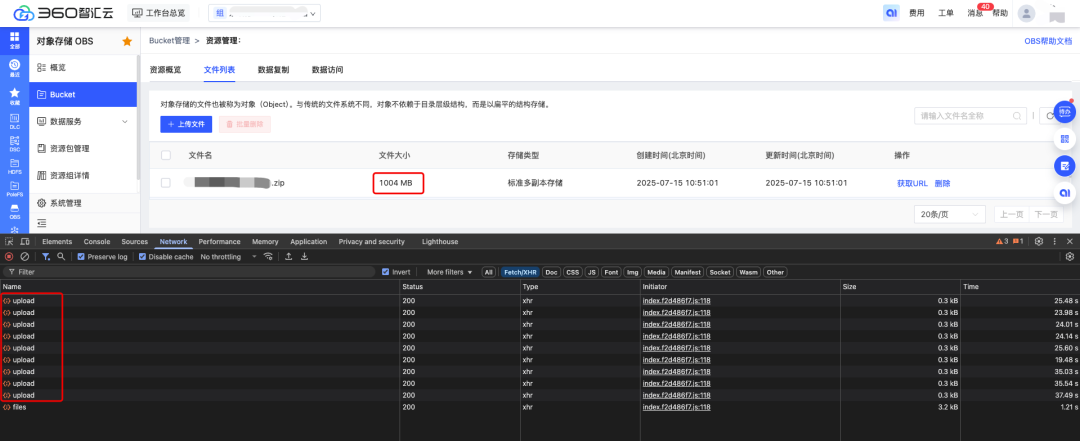
computed: { uploadPercentage() { if (!container.value.file || !data.value.length) return 0; const loaded = data.value .map(item => item.size * item.percentage) .reduce((acc, cur) => acc + cur); return parseInt((loaded / container.value.file.size).toFixed(2)); } }经过切片逻辑改造之后,切片的每块文件都能分别统计到上传进度,如下图所示:
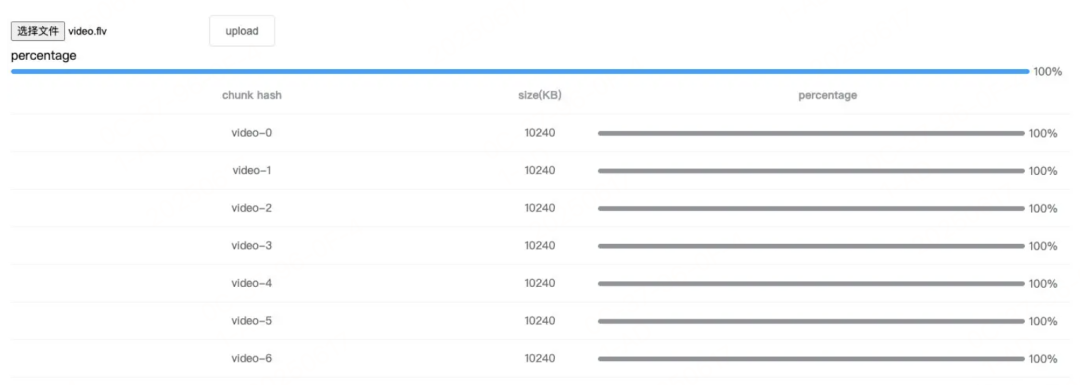
改造之后的大文件上传效果展示:
3. 总结
大文件上传
前端上传大文件时使用 Blob.prototype.slice 将文件切片,并发上传多个切片,最后发送一个合并的请求通知服务端合并切片
服务端接收切片并存储,收到合并请求后使用流将切片合并到最终文件
原生 XMLHttpRequest 的 upload.onprogress 对切片上传进度的监听
使用 Vue 计算属性根据每个切片的进度算出整个文件的上传进度
用户等待上传时间大大缩减,改善用户的体验
更多技术干货,
请关注“360智汇云开发者”👇
360智汇云官网:https://zyun.360.cn(复制在浏览器中打开)
更多好用又便宜的云产品,欢迎试用体验~
添加工作人员企业微信👇,get更快审核通道+试用包哦~





![[特殊字符] Spring Boot 常用注解全解析:20 个高频注解 + 使用场景实例](http://pic.xiahunao.cn/[特殊字符] Spring Boot 常用注解全解析:20 个高频注解 + 使用场景实例)
)








)
类和类的方法(基础教程介绍)(Python基础教程))


![[AI风堇]基于ChatGPT3.5+科大讯飞录音转文字API+GPT-SOVITS的模拟情感实时语音对话项目](http://pic.xiahunao.cn/[AI风堇]基于ChatGPT3.5+科大讯飞录音转文字API+GPT-SOVITS的模拟情感实时语音对话项目)
