一、词向量与词嵌入
将文本语料分词后,接下来就可以让计算机学习这些词,理解这些词的含义。我们可以直接将文本数据输入到计算机中让计算机学习吗?不可以,计算机只能看懂数字,看不懂文字。所以我们需要将词语转成一串数字让计算机学习。
词向量(Word Vector):指通过某种方式将每个单词映射为一个固定维度的向量。每个向量的元素通常是浮点数,且这些元素通常不是独立的,而是通过一定的训练方式,使得相似的词向量在向量空间中相对较近。
词嵌入(Word Embedding):生成词向量的技术或方法。
二、one_hot

这12个词语用one hot的方法表示,我们只需要将对应单词,在一个拥有所有词语的词库中的对应位置标记1,其他位置标记0即可

所以说,one hot的维度是由词库的大小决定,词库有多少词,词向量就有多少维。
one hot的缺点:
- 维度灾难:有多少个词语,矩阵就需要扩大多少维,对于庞大的语料库来说计算量和存储量都是很大的问题。
- 无法度量词语之间的相似性:我们用余弦相似度来计算任意两个词语之间的相似度,结果都会是0。
三、Word2Vec
3.1、Word2Vec
由于one hot的种种问题,2013年科学家提出了Word2Vec的词向量训练算法。也就是将词语表现为一串数字,这些数字它可以取任意实数。这样一来,有限的维度的词向量,就可以表示无数的词语,16维的one hot只可以表示16个词语,而16维的词向量可以表示无数个词。
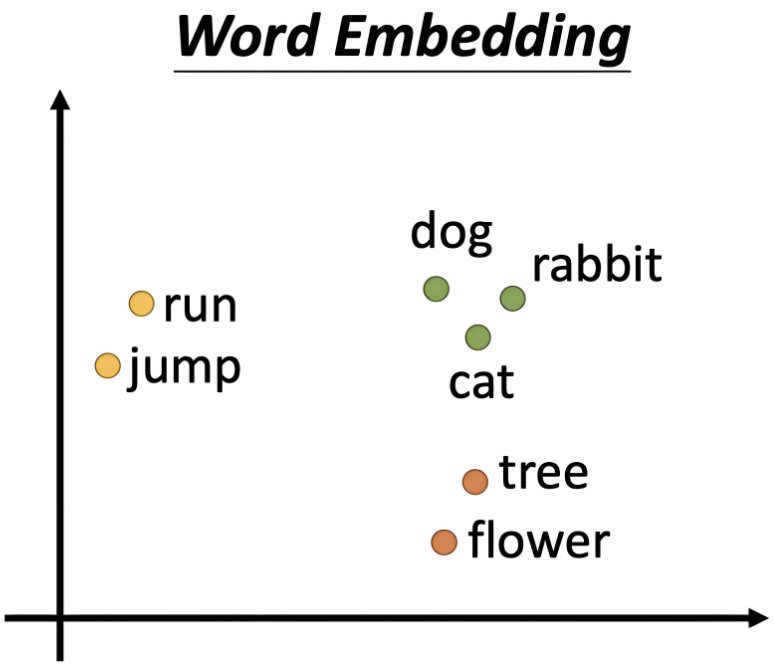
这就解决了one hot的维度灾难问题,同时Word2Vec也可以度量词语之间的相似性。我们以二维的Word2Vec模型举例:
我们可以将二维的Word2Vec向量中的第一个值作为x轴的值,第二个值作为y轴的值,那此时一个词就是二维空间中的一个点,意思越相近的词,向量越相似。通过计算两个向量夹角的余弦,余弦值越接近1,代表两个向量的夹角越小,两个向量越相似,代表这两个词的含义越相近;反之,余弦值越接近0,代表这两个词越无关。而在one hot表示法中,任何两个词向量的余弦值都是0。这就解决了one hot无法度量词语之间的相似性的问题。
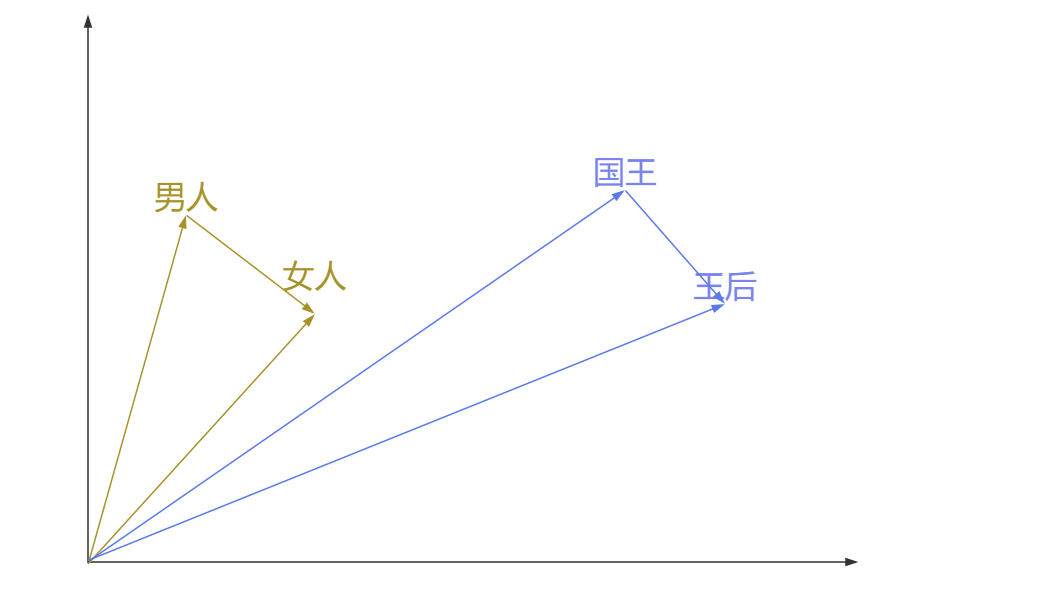
而使用Word2Vec向量还有这样一个好处,就是可以用向量的差值表示两个词之间的对应关系,比如男人到女人的向量,和国王到王后的向量,这两个向量非常相似。那么向量(男人-女人)就可以表示性别(男-->女),比如我们再想找到舅舅对应女性,我们只需要找到离(舅舅-(男人-女人))最近的词向量即可,大概率这个词是舅妈。所以对于Word2Vec的向量来说,维度越高,越能精确表示词与词之间的精确关系。
3.2、用途
| 应用领域 | 具体用途 | 技术实现 | 典型场景 |
|---|---|---|---|
| 语义相似度计算 | 量化词语/句子间的语义相似性 | 计算词向量的余弦相似度、欧氏距离 | 推荐系统、文档去重、同义词挖掘 |
| 文本分类 | 将文本表示为词向量组合(如均值、加权)后分类 | 词向量 + 分类模型(SVM、神经网络) | 情感分析、垃圾邮件检测、新闻分类 |
| 信息检索与问答系统 | 改进查询与文档的语义匹配 | 查询词和文档词向量相似度加权评分 | 搜索引擎、智能客服 |
| 机器翻译 | 增强源语言和目标语言的词对齐 | 双语词向量映射(如跨语言 Word2Vec) | 神经机器翻译(NMT) |
| 命名实体识别(NER) | 提升实体边界和类别的识别准确性 | 词向量作为 BiLSTM-CRF 等模型的输入特征 | 抽取人名、地名、医学术语 |
| 生成任务 | 为生成模型提供语义化的词表示 | 词向量作为 Seq2Seq、Transformer 的输入 | 文本摘要、对话生成、AI 写作 |
| 拼写纠错与自动补全 | 根据上下文推测正确词或补全句子 | 结合词向量和语言模型(如 n-gram、BERT) | 输入法提示、搜索框补全 |
3.3、缺点
上下文无关
传统的词向量是静态的,一个词无论出现在什么上下文中,其向量都是固定的。比如bank在“河岸”和“银行”中有不同的意义,但其词向量是相同的。
对未登录词的处理不足
对于未在训练数据中出现的词,传统词向量模型无法生成向量。
词间关系单一
词向量捕捉的是线性关系,但无法直接表达复杂的语义关系(如因果关系、否定关系)。
窗口的长度有限,它只能考虑周围的几个词语,没有办法考虑全局的文本信息,这个我们后面讲Word2Vec的训练就会提到
3.4、训练流程
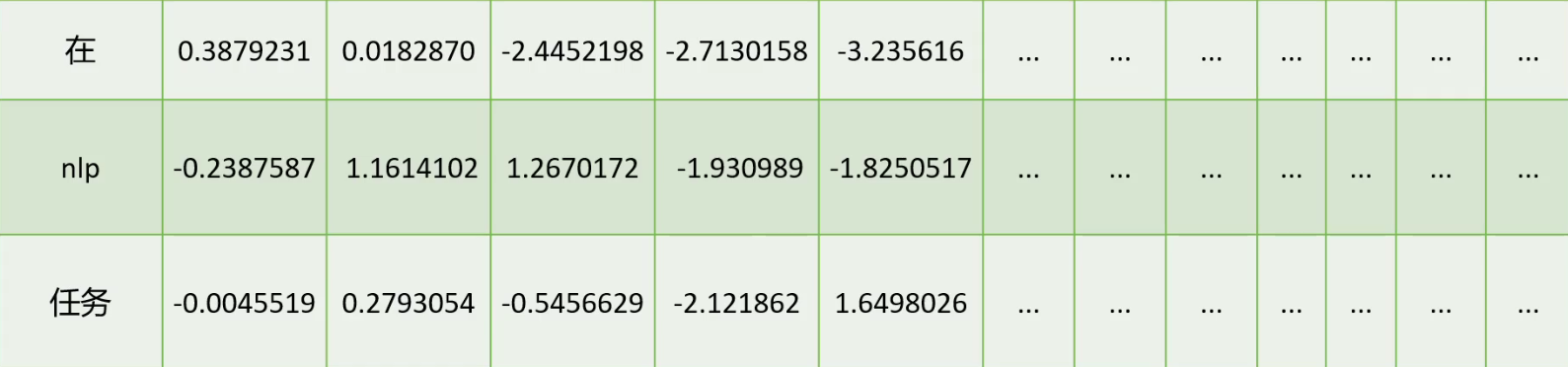
我们通过神经网络模型可以对词向量进行训练,首先随机初始化语料库中所有词语的向量值,并且随机一个权重参数矩阵。比如说我们想训练英文的词向量,就需要准备所有的英文单词,随机初始化每一个单词的词向量。

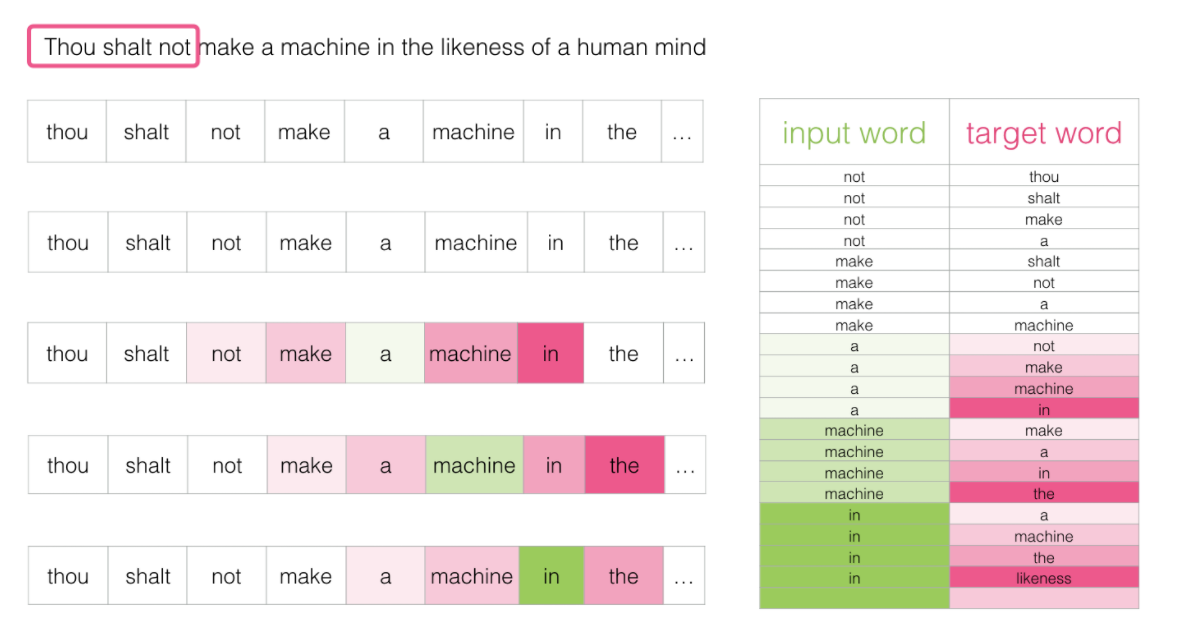
其次,设定好输入值和输出值,设置输入和输出值的方法有很多,后面我们会提到,基本都是输入值的是文本中的某些词,输出值的是输入值文本周围的某些词。例如学习这么一句话:

Word2Vec 的训练过程本质上是通过神经网络学习词语之间的分布式表示。其核心思想基于一个重要的语言学假设:在文本中相邻出现的词语往往具有语义上的关联性。具体来说,当我们在训练时输入一个中心词(如"NLP"),模型会尝试预测其周围可能出现的上下文词(如"任务"、"处理"、"语言"等)。这个预测过程通过神经网络架构实现:输入层接收词语的one-hot编码,经过隐藏层的线性变换后得到对应的词向量表示,再通过输出层的Softmax激活函数计算上下文词的概率分布。
在训练过程中,模型会不断比较预测结果与真实上下文之间的差异,通过损失函数(通常是负对数似然)量化这种差异,并利用反向传播算法同时更新两个关键部分:一是隐藏层的权重矩阵(即词向量查找表本身),二是输出层的权重参数。这种双重更新机制是Word2Vec的一个重要特性,它使得词向量在训练过程中能够动态调整。随着训练的进行,语义相关或功能相似的词语(如"任务"和"NLP")在向量空间中的距离会逐渐靠近,表现为它们的词向量夹角减小、余弦相似度增高。
值得注意的是,这种学习过程完全是无监督的,仅依赖于文本中词语的自然分布规律。最终训练得到的词向量能够捕捉丰富的语义关系,不仅能使相关词语在向量空间中聚集,还能保持诸如"国王-男性+女性≈女王"这样的线性类比关系。这种特性使得Word2Vec成为许多NLP任务的基础工具,从简单的语义相似度计算到复杂的文本分类和生成任务都能发挥重要作用。词向量的质量很大程度上取决于训练语料的规模和质量,以及模型参数的合理设置,如向量维度、上下文窗口大小等。
3.5、训练细节
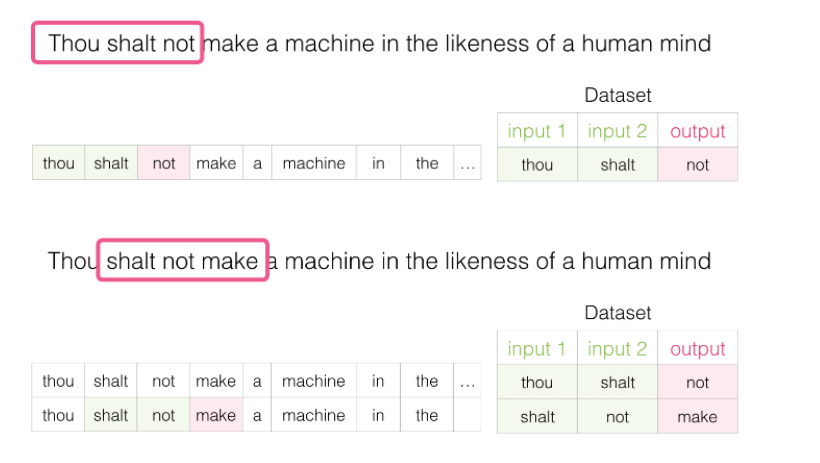
假如每次训练读取三个单词,前两个单词是输入,第3个单词是输出,这3个单词要怎么选择呢?我们通过窗体滑动的方式进行选择,第一次选择第123个单词,让这3个单词产生关联;第二次选择第234个单词,让这3个单词产生关联;第三词选择第345个单词,让这3个单词产生关联...之后每次训练向后滑动一个词,直到学习完所有资料,这就是窗口滑动。
3.5.1、CBOW(连续词袋模型)
通过上下文词预测中心词的模型。即输入是上下文词,输出是中心词,目标是让其上下文词的向量能够准确中心词。
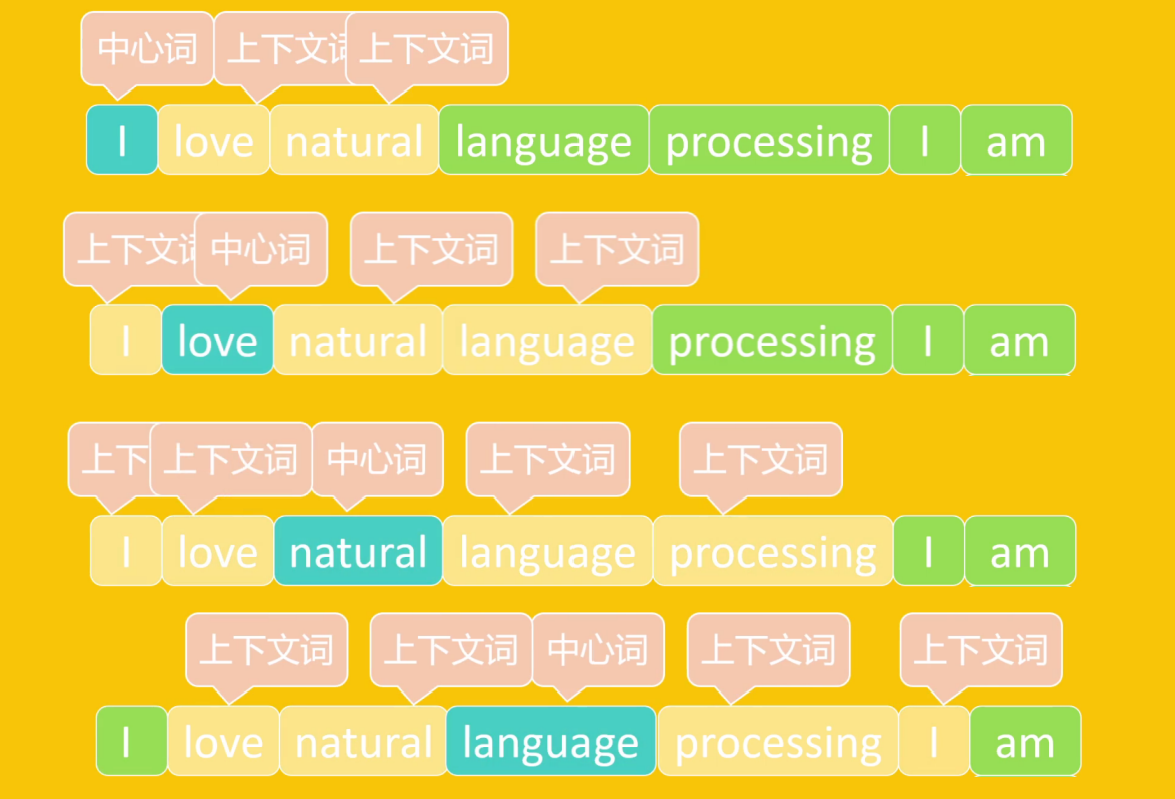
3.5.2、Skip-gram(跳字模型)
通过中心词预测上下文词的模型。输入是中心词,输出是上下文词,目标是让目标词的向量能够准确预测其上下文。Skip-gram计算量要大于CBOW,但对稀有词的训练效果要好于CBOW。
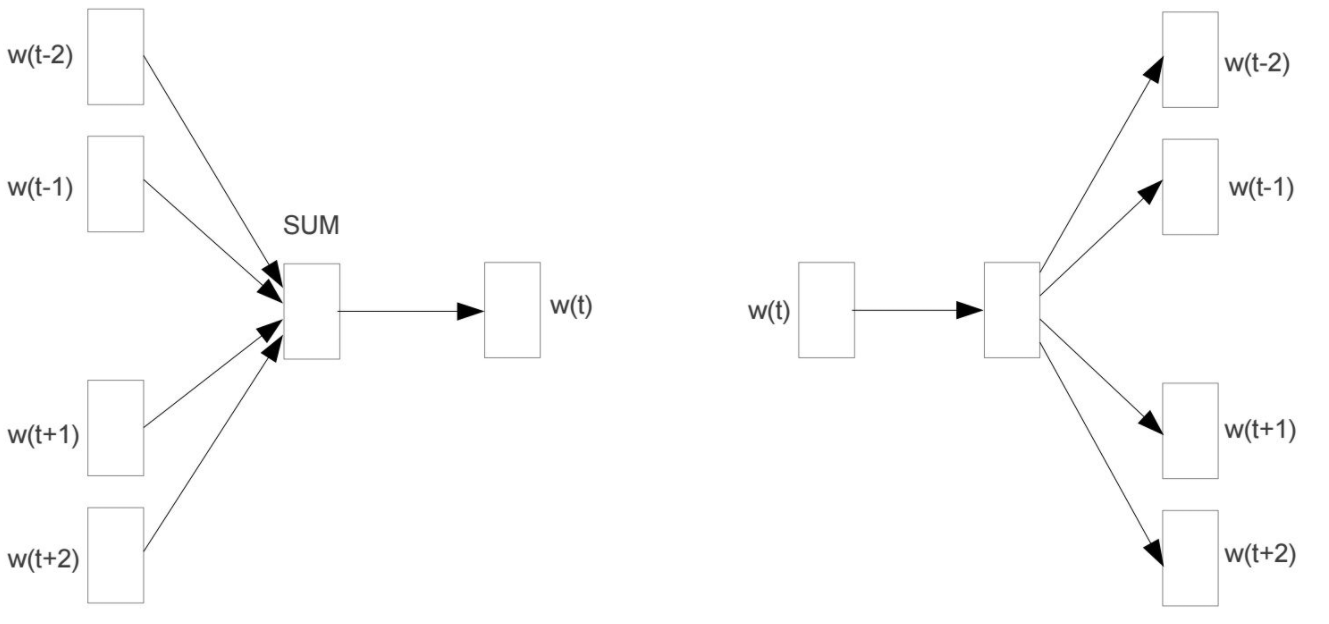
CBOW通过上下文预测中心词,计算效率较高,适合常见词的训练
Skip-gram通过中心词预测上下文,计算复杂度较高,但对稀有词效果更好。
四、负采样模型
负采样(Negative Sampling)是Word2Vec模型中用于优化训练效率的关键技术,它通过改进传统Softmax的计算方式,使模型能够高效地学习词向量表示。该技术的核心思想是将复杂的多分类问题转化为一系列二分类问题,从而大幅降低计算复杂度。

在具体实现上,负采样采用了一种对比学习的策略。对于每个训练样本(中心词和真实上下文词组成的正样本),模型会随机采样若干个非上下文词作为负样本。这种设计使得模型只需要区分正样本和负样本,而无需计算整个词汇表的概率分布。例如,在处理"NLP-任务"这个正样本时,模型可能会采样"足球"、"电影"等无关词汇作为负样本,通过Sigmoid函数计算每个样本的得分并优化损失函数。
负采样的数学表达式采用了逻辑回归的形式,其目标函数由两部分组成:最大化正样本的相似度得分,同时最小化负样本的得分。这种设计不仅显著提高了训练速度(计算量从O(V)降低到O(k),其中V是词汇表大小,k是负样本数量),还能保
持较好的词向量质量。实验表明,当负样本数量k=5-15时,模型效果与完整Softmax相当。
在实际应用中,负采样通常采用频率加权的采样策略,即高频词被选为负样本的概率更高,但会通过次采样(subsampling)技术来平衡高频词的影响。这种技术上的改进使得Word2Vec能够有效处理大规模语料库,同时捕捉到词语之间丰富的语义关系。负采样的成功应用不仅限于Word2Vec,其思想也被广泛应用于推荐系统、图嵌入等其他表示学习领域。
五、训练模型效果
安装工具包
pip install jieba=0.42.1
pip install gensim==4.3.1
代码
import jieba # 中文分词库
import gensim # 自然语言处理库
import re # 正则表达式库
from gensim.models import Word2Vec # Word2Vec词向量模型# 打开并读取《三国演义》白话文文本文件
f = open('三国演义白话文.txt', 'r', encoding='utf-8')# 初始化一个空列表,用于存储处理后的分词结果
lines = []# 逐行处理文本
for line in f:# 使用jieba进行分词temp = jieba.lcut(line)words = [] # 临时存储处理后的词语# 对每个分词结果进行清洗处理for word in temp:# 使用正则表达式去除标点符号和特殊字符i = re.sub("[\s+\.\!\/_,$%^*(+\"\'””《》]+|[+——!,。?、~@#¥%……&*():;‘]+", "", word)# 只保留非空词语if len(i) > 0:words.append(i)# 只添加包含有效词语的行if len(words) > 0:lines.append(words)# 使用处理后的语料训练Word2Vec模型
# 参数说明:
# lines: 分词后的语料库(列表的列表)
# vector_size: 词向量维度(20维)
# window: 上下文窗口大小(取中心词前后各2个词)
# min_count: 最低词频(出现次数少于3次的词将被忽略)
# epochs: 训练轮数(整个语料库训练10次)
# sg: 训练算法(1表示使用skip-gram,0表示CBOW)
model = Word2Vec(lines, vector_size=20, window=2, min_count=3, epochs=10, sg=1)# 保存训练好的模型(可选)
# model.save("word2vec.model")# 加载已保存的模型(可选)
# model = Word2Vec.load("word2vec.model")# 获取"孔明"的词向量并打印
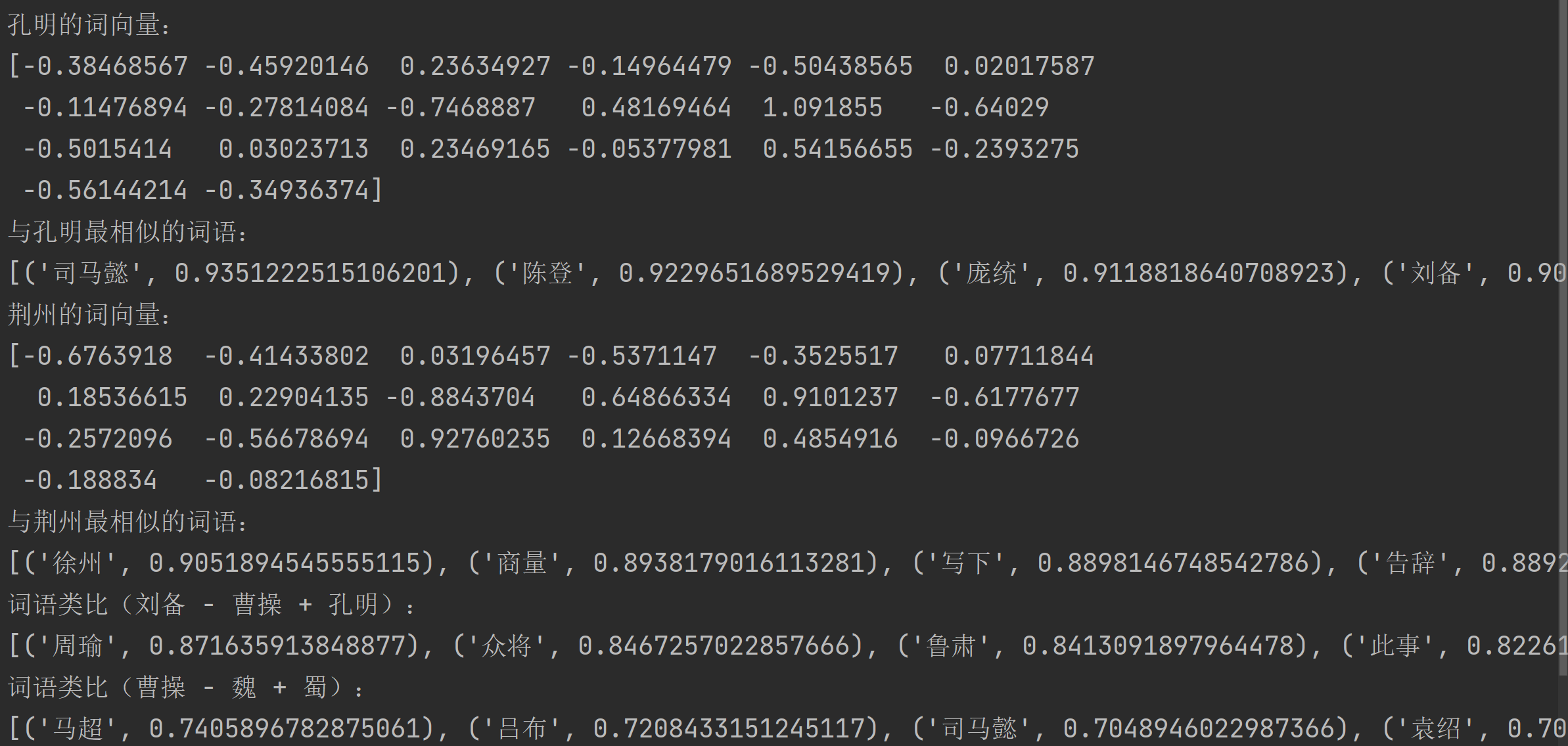
print("孔明的词向量:")
print(model.wv.get_vector('孔明'))# 查找与"孔明"最相似的20个词
print("\n与孔明最相似的词语:")
print(model.wv.most_similar('孔明', topn=20))# 获取"荆州"的词向量并打印
print("\n荆州的词向量:")
print(model.wv.get_vector('荆州'))# 查找与"荆州"最相似的20个词
print("\n与荆州最相似的词语:")
print(model.wv.most_similar('荆州', topn=20))# 词语类比:刘备 - 曹操 + 孔明 ≈ ?
# 相当于"刘备"加上"孔明"减去"曹操"的结果
print("\n词语类比(刘备 - 曹操 + 孔明):")
words = model.wv.most_similar(positive=['刘备', '孔明'], negative=['曹操'], topn=10)
print(words)# 词语类比:曹操 - 魏 + 蜀 ≈ ?
# 相当于"曹操"加上"蜀"减去"魏"的结果
print("\n词语类比(曹操 - 魏 + 蜀):")
words = model.wv.most_similar(positive=['曹操', '蜀'], negative=['魏'], topn=10)
print(words)







)
)

(腾讯地图))
)







