Title
题目
ACOUSLIC-AI challenge report: Fetal abdominal circumferencemeasurement on blind-sweep ultrasound data from low-income countries
ACOUSLIC-AI挑战报告:基于低收入国家盲扫超声数据的胎儿腹围测量
01
文献速递介绍
胎儿生长受限(FGR)影响高达10%的妊娠,是导致围产期死亡和发病的关键因素(Bernstein等人,2000年;Gardosi等人,1992年;Martins等人,2020年;Unterscheider等人,2014年)。胎儿生长受限与死产密切相关,还可能导致早产,给母亲带来风险(Lawn等人,2011年,2023年)。这种情况通常是由于各种母体、胎儿和胎盘因素阻碍了胎儿的遗传生长潜力所致(Martins等人,2020年)。产前超声检查是通过生物测量评估胎儿大小的标准方法,包括腹围(AC),以及用于计算估计胎儿体重(EFW;Salomon等人,2019年)的其他参数,如双顶径、头围和股骨长度。当这些测量值小于预期时,可能表明存在胎儿生长受限,该病症与约60%的胎儿死亡有关(Lawn等人,2011年)。胎儿生长受限的诊断依赖于对胎儿腹围、预期胎儿体重或两者的重复测量。这些测量必须至少进行两次,两次之间的最短间隔为两周,才能做出可靠诊断(Morris等人,2024年),除非观察到极端值。在这种情况下,单次腹围或估计胎儿体重测量可能足以确认胎儿生长受限(Gordijn等人,2016年;Lees等人,2020年)。然而,在资源匮乏地区,用于腹围测量的常规产科生物测量超声检查受到限制,原因是超声设备成本高昂且训练有素的超声医师稀缺。 有人提出,在这些地区,让新手操作员使用低成本超声设备和标准化盲扫协议来获取产科数据(Abuhamad等人,2016年;DeStigter等人,2011年;Self等人,2022年;van den Heuvel等人,2018a)。盲扫采集协议的特点是操作员执行标准化的扫描动作,而不查看超声图像。这些协议会生成一系列二维超声帧,这些帧是在超声探头沿着妊娠腹部的特定轨迹移动时捕获的。与传统临床超声检查不同,在传统临床超声检查中,经验丰富的超声医师会寻找标准平面进行生物测量(Yasrab等人,2022年),盲扫数据带来了一系列独特的挑战。尽管以这种方式获取的数据质量有所降低,可能不包含标准平面,但事实证明,这些数据足以进行生物测量(van den Heuvel等人,2019年)。 越来越多的文献关注使用人工智能(AI)来自动化基于标准化协议获取的自由手超声序列的产前评估任务,从而无需专家的超声解释。这些任务包括胎儿生物测量(Arroyo等人,2022年;van den Heuvel等人,2019年)、孕龄估计(Gomes等人,2022年;Lee等人,2023年;Pokaprakarn等人,2022年;van den Heuvel等人,2019年;Viswanathan等人,2024年)和妊娠风险检测(Arroyo等人,2022年;Gleed等人,2023a,b;Gomes等人,2022年;Maraci等人,2017年;Schilpzand等人,2022年;Self等人,2020年)。正如Gomes等人(2022年)和Schilpzand等人(2022年)所展示的,这些人工智能解决方案有可能嵌入到移动设备中,提供完整、离线、低成本且便携的解决方案,适用于资源有限的环境。 据我们所知,此前没有研究调查过在盲扫数据上自动测量胎儿腹围的情况。虽然Płotka等人(2022年)推出了一种人工智能模型,能够从超声视频中自动选择的标准平面测量腹围以及其他胎儿生物测量参数,但这些图像是由经验丰富的超声医师获取的,他们得到的指示是确保每个成像序列都包含准确测量所需的标准平面。在随后的一项研究中,作者将他们的方法扩展到从腹部超声视频中自动估计胎儿体重(Płotka等人,2023年)。与他们早期的工作一样,这种方法是基于超声医师特意包含腹围标准平面的腹部视频开发和测试的。虽然这两项研究都表明,可以从超声扫查数据中估计胎儿腹围,并且这种测量足以监测胎儿生长受限,但由于依赖超声医师包含预定义的标准平面,可能会限制这些模型在资源受限环境中的通用性。 为了填补文献中的这一空白,并探索在低收入国家改善胎儿生长受限早期检测和管理的潜力,我们组织了ACOUSLIC-AI(使用人工智能在低收入国家进行操作员无关的腹围超声测量)挑战。与之前的挑战(如HC18、A-AFMA和PS-FH-AOP(Lu等人,2022年))专注于在临床环境中获取的超声成像数据不同,ACOUSLIC-AI挑战是首个将盲扫数据用于胎儿生物测量任务的挑战。该挑战旨在开发和基准测试用于从新手操作员获取的盲扫数据中自动测量胎儿腹围的人工智能模型,最终目标是改善资源有限地区的产前护理可及性。参与者的任务是确定最适合测量胎儿腹围的帧,并在与所选帧对应的超声图像上提供腹部的二元分割掩码。来自塞拉利昂三个公共卫生单位(PHUs)的训练数据由经验丰富的阅片者进行标注,并已公开。包含坦桑尼亚两个公共卫生单位和一家欧洲医院数据的私有验证集和测试集由专家阅片者标注,通过Grand-Challenge平台提供。挑战设计确保算法和代码可公开获取且可重复使用。在本文中,我们使用生物医学图像分析挑战(BIAS)方法(Maier-Hein等人,2020年)展示了ACOUSLIC-AI挑战中表现最佳的三个人工智能模型的结果,并根据临床标准评估了它们的性能。
Abatract
摘要
Fetal growth restriction, affecting up to 10% of pregnancies, is a critical factor contributing to perinatalmortality and morbidity. Ultrasound measurements of the fetal abdominal circumference (AC) are a key aspectof monitoring fetal growth. However, the routine practice of biometric obstetric ultrasounds is limited in lowresource settings due to the high cost of sonography equipment and the scarcity of trained sonographers. Toaddress this issue, we organized the ACOUSLIC-AI (Abdominal Circumference Operator-agnostic UltraSoundmeasurement in Low-Income Countries) challenge to investigate the feasibility of automatically estimatingfetal AC from blind-sweep ultrasound scans acquired by novice operators using low-cost devices. Training datacollected from three Public Health Units (PHUs) in Sierra Leone are made publicly available. Private validationand test sets, containing data from two PHUs in Tanzania and a European hospital, are provided throughthe Grand-Challenge platform. All sets were annotated by experienced readers. Sixteen international teamsparticipated in this challenge, with six teams submitting to the Final Test Phase. In this article, we present theresults of the three top-performing AI models from the ACOUSLIC-AI challenge, which are publicly accessible.We evaluate their performance in fetal abdomen frame selection, segmentation, abdominal circumferencemeasurement, and compare their performance against clinical standards for fetal AC measurement. Clinicalcomparisons demonstrated that the limits of agreement (LoA) for A2 in fetal AC measurements are comparableto the interobserver LoA reported in the literature. The algorithms developed as part of the ACOUSLIC-AIchallenge provide a benchmark for future algorithms on the selection and segmentation of fetal abdomenframes to further minimize fetal abdominal circumference measurement variability
胎儿生长受限影响高达10%的妊娠,是导致围产期死亡和发病的关键因素。胎儿腹围(AC)的超声测量是监测胎儿生长的重要方面。然而,在资源匮乏地区,由于超声设备成本高昂且训练有素的超声医师稀缺,常规的产科生物测量超声检查受到限制。为解决这一问题,我们组织了ACOUSLIC-AI(低收入国家腹围操作员无关超声测量)挑战,旨在研究由新手操作员使用低成本设备获取的盲扫超声图像中自动估算胎儿腹围的可行性。 来自塞拉利昂三个公共卫生单位(PHUs)的训练数据已公开。包含坦桑尼亚两个公共卫生单位和一家欧洲医院数据的私有验证集和测试集通过Grand-Challenge平台提供。所有数据集均由经验丰富的阅片者进行标注。16个国际团队参与了此次挑战,其中6个团队进入最终测试阶段。 在本文中,我们展示了ACOUSLIC-AI挑战中表现最佳的三个人工智能模型的结果,这些模型可公开获取。我们评估了它们在胎儿腹部图像帧选择、分割、腹围测量方面的性能,并将其与胎儿腹围测量的临床标准进行了比较。临床对比表明,A2在胎儿腹围测量中的一致性限度(LoA)与文献中报道的观察者间一致性限度相当。作为ACOUSLIC-AI挑战的一部分开发的算法,为未来用于胎儿腹部图像帧选择和分割的算法提供了基准,以进一步减少胎儿腹围测量的变异性。
Results
结果
This section presents the results of the top three solutions submittedduring the Final Test Phase (see Section 4.1): A1, A2, and A3. Inaccordance with the challenge rules, each team submitted a single entryto this phase. These solutions achieved ranking score metric values(mean ± SD) of 0.71 ± 0.54, 0.65 ± 0.52, and 0.64 ± 0.52, respectively.Sections 6.1, 6.2, and 6.3 respectively evaluate their performance infetal abdomen frame selection, fetal abdomen segmentation, and fetalabdominal circumference measurement on the test set. Furthermore,Section 6.4 analyses their accuracy in abdominal circumference measurement compared to clinical standards and examines the agreementbetween blind-sweep AC reference measurements and those obtainedin clinical practice
本节介绍最终测试阶段(见 4.1 节)提交的前三名解决方案的结果,分别为 A1、A2 和 A3。根据挑战赛规则,每个团队在该阶段仅提交一份参赛作品。这些解决方案获得的排名评分指标值(均值 ± 标准差)分别为 0.71±0.54、0.65±0.52 和 0.64±0.52。6.1 节、6.2 节和 6.3 节分别评估了它们在测试集上的胎儿腹部帧选择、胎儿腹部分割和胎儿腹围测量方面的性能。此外,6.4 节分析了它们在腹围测量方面与临床标准相比的准确性,并检验了盲扫腹围参考测量值与临床实践中获得的测量值之间的一致性。
Figure
图
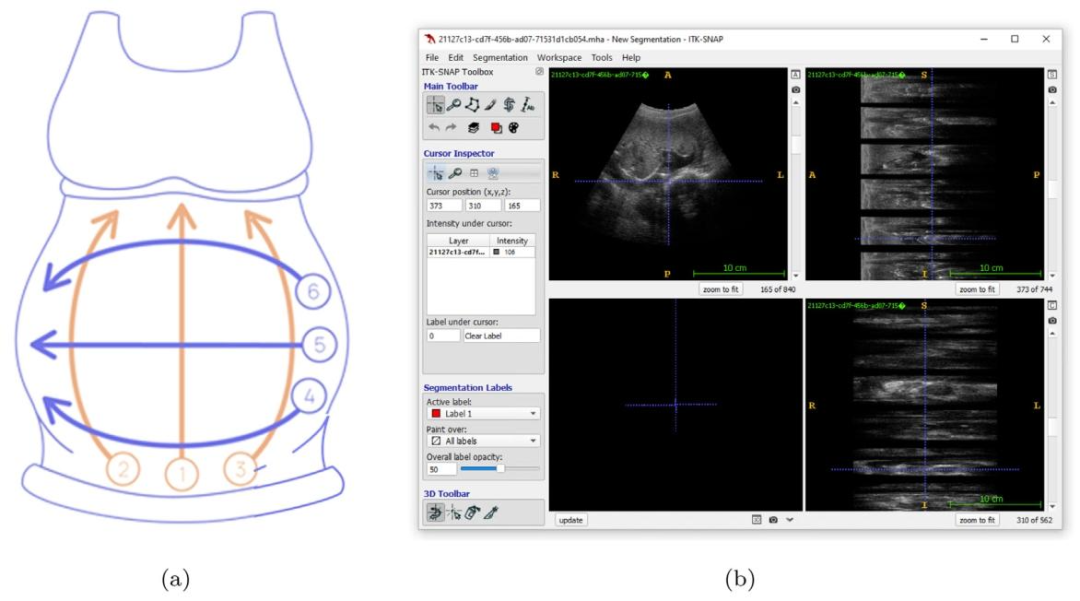
Fig. 1. The Obstetric Sweep Protocol (OSP). (a) OSP sweep trajectories. In orange, transverse sweeps (1–3); in violet, sagittal sweeps (4–6). (b) Example visualization (usingITK-SNAP for display) of ultrasound sweep data acquired following the OSP protocol. To the right, the top and bottom views each display a stack of six grey rectangles withsmaller black ones interspersed between them. This is a visual representation of the sweep image data, showing the individual frames in a compact manner. The main imagepanel, located in the top left corner, displays a single frame in the stack.
图1. 产科扫查协议(OSP)。(a) OSP扫查轨迹。橙色部分为横向扫查(1-3);紫色部分为矢状面扫查(4-6)。(b) 遵循OSP协议获取的超声扫查数据的示例可视化(使用ITK-SNAP软件显示)。右侧的顶部视图和底部视图各展示了一叠六个灰色矩形,矩形之间穿插着较小的黑色矩形。这是扫查图像数据的可视化呈现,以简洁的方式展示了各个帧。位于左上角的主图像面板显示了该叠帧中的单个帧。
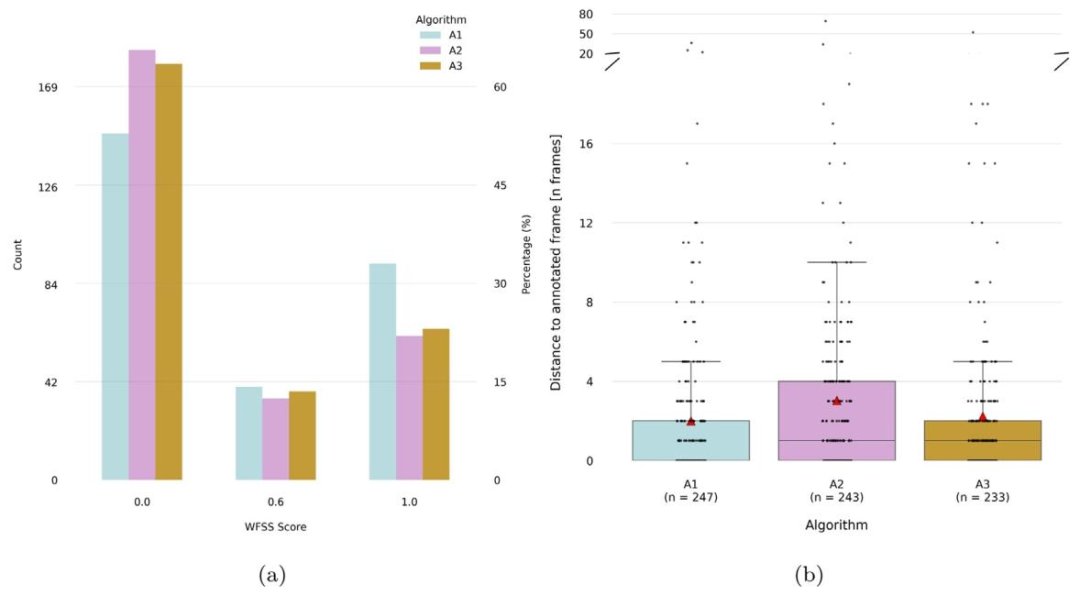
Fig. 2. Frame selection results for algorithms A1, A2 and A3 on the test set (n = 282). (a) Weighted frame selection score (WFSS) counts and percentages per value. WFSS is acustom metric designed to assess the accuracy of frame selection, with higher scores awarded for correctly identified clinically relevant frames. A value of 0 is given if the frameselected was not annotated, a value of 0.6 if the frame selected was annotated as sub-optimal, while optimal frames were available, and a value of 1 if the frame selected wasamong the best available according to annotations. (b) Distance to the nearest annotated frame within the same sweep (in frames, provided for comparison only, this was notused in the challenge metrics). Cases without any annotations in the same sweep were excluded. The total number of valid cases per algorithm is indicated as n. The red trianglesindicate mean distances.
图2. 算法A1、A2和A3在测试集(n = 282)上的帧选择结果。(a) 加权帧选择分数(WFSS)的数量及各分数值所占百分比。加权帧选择分数是一种用于评估帧选择准确性的自定义指标,正确识别出临床相关帧会获得更高分数:若所选帧未被标注,得分为0;若所选帧被标注为次优帧(且存在最优帧),得分为0.6;若所选帧属于标注中的最佳可用帧,得分为1。(b) 同一扫查序列中与最近的标注帧的距离(以帧数为单位,仅作比较用,未用于挑战的评分指标)。排除了同一扫查序列中无任何标注的案例。每个算法的有效案例总数标注为n。红色三角形表示平均距离。
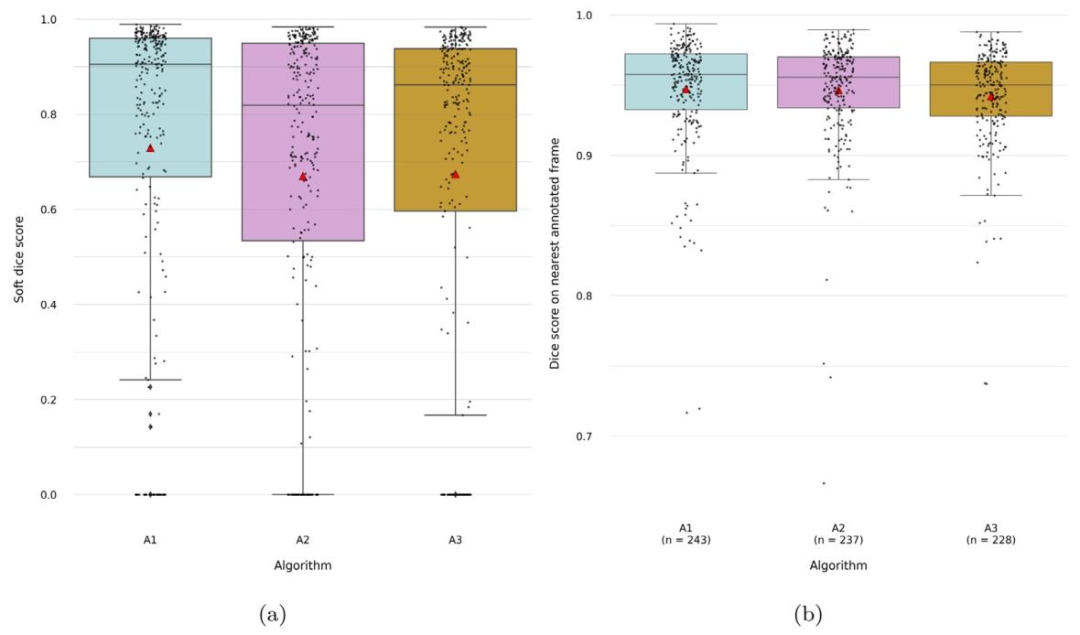
Fig. 3. Results for the segmentation of the fetal abdomen for algorithms A1, A2 and A3 on the test set (n = 282). (a) Soft dice score — overlap is computed on the nearestannotated frame within the same sweep, within 15 frames of distance, weighted by the distance to the frame. (b) Dice score — computed on the nearest annotated frame withinthe same sweep, within 15 frames of distance (provided for comparison only, this was not used in the challenge metrics). Cases with predictions located more than 15 framesaway from the nearest annotation or in sweeps without any annotations were excluded. The total number of valid cases per algorithm is indicated as n. The red triangles indicatemean values
图3. 算法A1、A2和A3在测试集(n = 282)上的胎儿腹部分割结果。(a) 软Dice评分——基于同一扫查序列中距离在15帧以内的最近标注帧计算重叠度,并根据与该帧的距离进行加权。(b) Dice评分——基于同一扫查序列中距离在15帧以内的最近标注帧计算(仅作比较用,未用于挑战的评分指标)。排除了预测帧与最近标注帧距离超过15帧或所在扫查序列无任何标注的案例。每个算法的有效案例总数标注为n。红色三角形表示平均值。
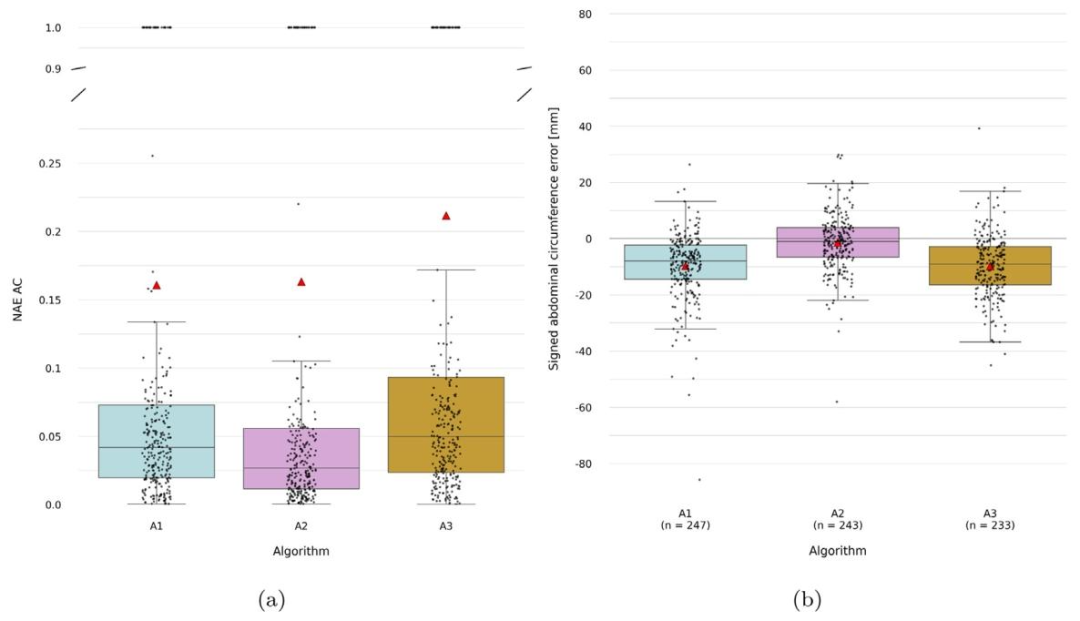
Fig. 4. Fetal abdominal circumference measurement results for algorithms A1, A2 and A3 on the test set (*n*=282). (a) Normalized absolute error in abdominal circumference(scale-independent, with values from 0–1) (b) Signed abdominal circumference error (for comparison only, this was not used in the challenge metrics). Cases without a referencemeasurement in the same sweep were excluded for this metric. The total number of valid cases per algorithm is indicated as n. The red triangles indicate mean values.
图4. 算法A1、A2和A3在测试集(n=282)上的胎儿腹围测量结果。(a) 腹围的归一化绝对误差(与尺度无关,取值范围为0-1)。(b) 腹围的有符号误差(仅作比较用,未用于挑战的评分指标)。本指标排除了同一扫查序列中无参考测量值的案例。每个算法的有效案例总数标注为n。红色三角形表示平均值。
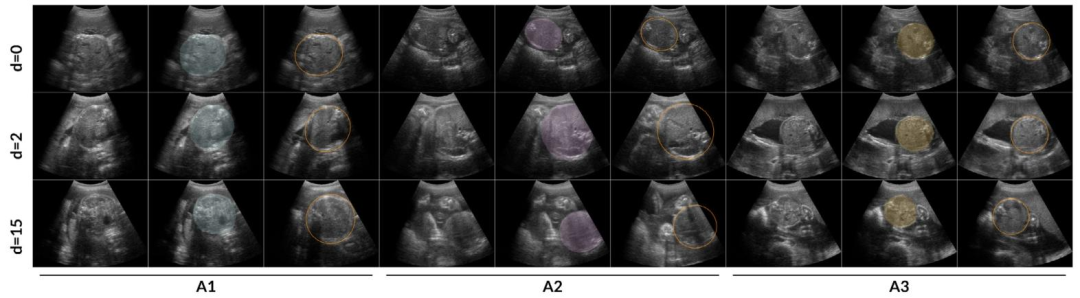
Fig. 5. Comparison of fetal abdominal frame selection and segmentation by algorithms A1, A2 and A3 against OSP reference annotated frames in randomly selected cases from theAfrican cohort test set. The leftmost three columns correspond to algorithm A1, the middle three to A2, and the rightmost three to A3. For each algorithm, the columns display,from left to right: the selected frame, the selected frame with an overlay of the fetal abdomen segmentation, and the most suitable OSP reference frame with its correspondingellipse. The rows present comparisons at increasing frame distances — 0, 2, and 15 — from the nearest annotated frame, presented from top to bottom.
图5. 在非洲队列测试集中随机选择的案例中,算法A1、A2和A3的胎儿腹部帧选择和分割结果与产科扫查协议(OSP)参考标注帧的对比。最左侧三列对应算法A1,中间三列对应A2,最右侧三列对应A3。对于每个算法,从左到右的列依次显示:所选帧、叠加了胎儿腹部分割结果的所选帧,以及最合适的OSP参考帧及其对应的椭圆。各行从上到下展示了与最近标注帧的帧距离分别为0、2和15时的对比情况。
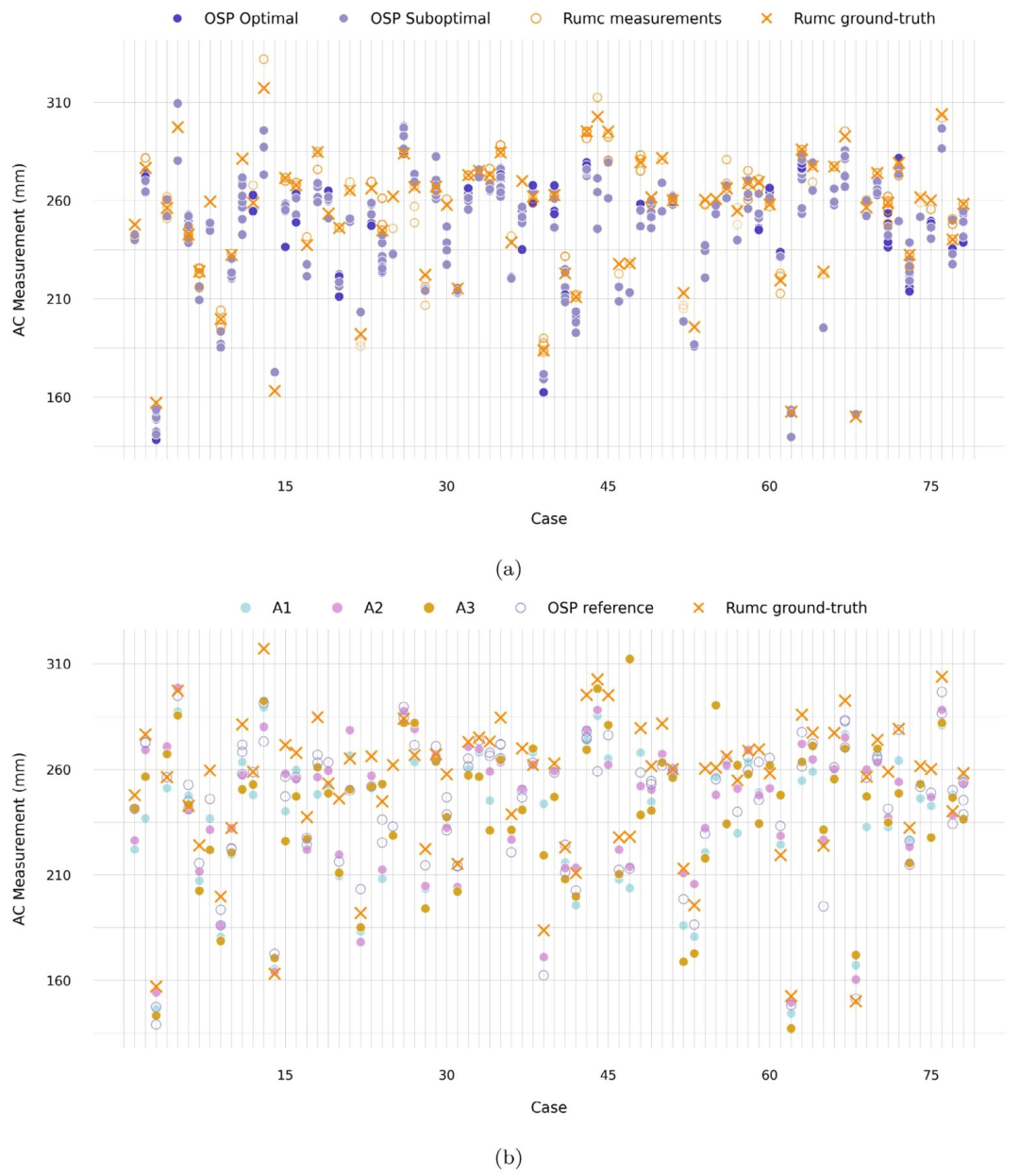
Fig. 6. Abdominal circumference (AC) measurements for each case in the Radboudumc cohort test set data (n=78). (a) Comparison of raw OSP reference measurements withclinical measurements obtained during standard care on the same day. In the clinical setting, sonographers perform multiple measurements (Rumc measurements) and select oneas the accepted value (Rumc ground-truth). Raw ellipse measurements are depicted as OSP reference measurements. (b) Comparison of AC measurements from algorithms A1, A2,and A3 with reference measurements from OSP and the clinical ground truth. The OSP reference values correspond to the sweep average AC derived from reference annotations.
图6. 拉德堡德大学医学中心(Radboudumc)队列测试集数据中每个案例的腹围(AC)测量结果(n=78)。(a) 原始产科扫查协议(OSP)参考测量值与同一天标准护理中获得的临床测量值的对比。在临床环境中,超声医师会进行多次测量(Rumc测量值)并选择其中一个作为认可值(Rumc基准值)。原始椭圆测量值被视为OSP参考测量值。(b) 算法A1、A2和A3的腹围测量值与OSP参考测量值及临床基准值的对比。OSP参考值对应于源自参考标注的扫查平均腹围。
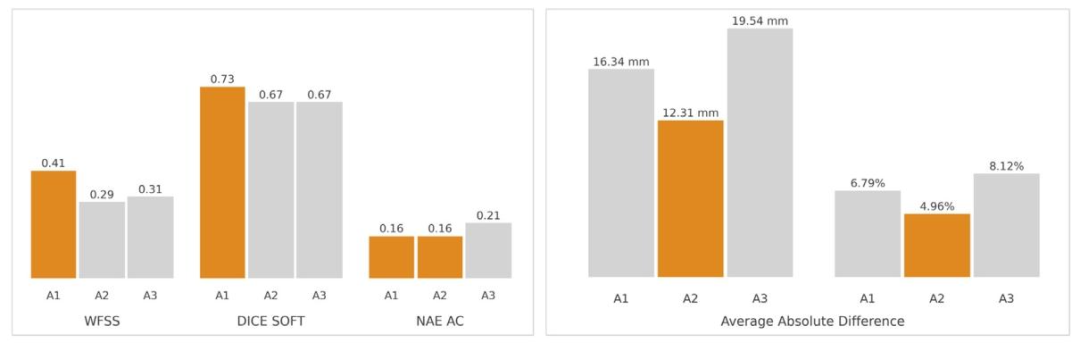
Fig. 7. Summary of challenge outcomes and clinical performance for algorithms A1, A2 and A3. The left panel presents the mean values for the WFSS, Dice Soft, and NAE ACmetrics used in the challenge evaluation for the whole test set (African and Radboudumc cohorts). These metrics respectively assess performance in fetal abdomen frame selection,abdomen segmentation, and abdominal circumference measurement. The right panel shows the average absolute differences in fetal abdominal circumference measurements foreach algorithm relative to the clinical ground truth for cases in the Radboudumc cohort, expressed in millimetres (mm) and percentages (%). Percentage differences were calculatedas a proportion of the mean measurement to account for fetal size variability. The best-performing algorithms for each metric are highlighted in orange.
图7. 算法A1、A2和A3的挑战结果与临床性能总结。左图展示了整个测试集(非洲队列和拉德堡德大学医学中心队列)在挑战评估中使用的加权帧选择分数(WFSS)、软Dice评分(Dice Soft)和腹围归一化绝对误差(NAE AC)的平均值。这些指标分别评估胎儿腹部帧选择、腹部分割和腹围测量的性能。右图显示了在拉德堡德大学医学中心队列案例中,每个算法的胎儿腹围测量值与临床基准值的平均绝对差异,以毫米(mm)和百分比(%)表示。百分比差异以平均测量值的比例计算,以考虑胎儿大小的变异性。每项指标的最佳性能算法以橙色突出显示。
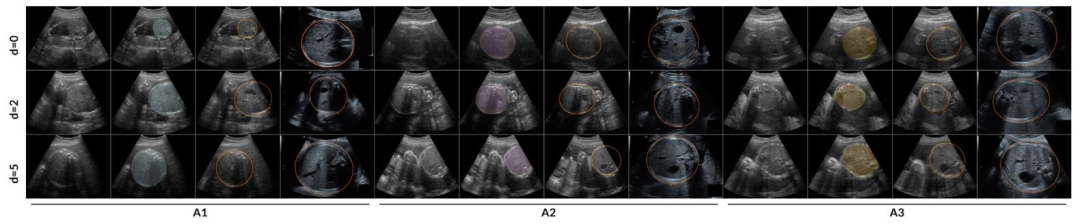
Fig. 8. Comparison of fetal abdominal frame selection and segmentation by algorithms A1, A2, and A3 against OSP reference annotated frames and clinical standard planes fromrandomly selected cases in the Radboudumc cohort test set. The leftmost four columns correspond to Algorithm A1, the middle four to A2, and the rightmost four to A3. Foreach algorithm, the columns display, from left to right: the selected frame, the selected frame with an overlay of the fetal abdomen segmentation, the most suitable OSP referenceframe with its corresponding ellipse, and the AC standard plane acquired in clinical practice. The rows present comparisons at increasing frame distances — 0, 2, and 5 — fromthe nearest annotated frame, presented from top to bottom. Images corresponding to the standard plane were zoomed in prior to capture, as is common practice during clinicalassessments.
图8. 在拉德堡德大学医学中心(Radboudumc)队列测试集中随机选择的案例中,算法A1、A2和A3的胎儿腹部帧选择及分割结果与产科扫查协议(OSP)参考标注帧和临床标准平面的对比。最左侧四列对应算法A1,中间四列对应A2,最右侧四列对应A3。对于每个算法,从左到右的列依次显示:所选帧、叠加了胎儿腹部分割结果的所选帧、最合适的OSP参考帧及其对应的椭圆,以及临床实践中获取的腹围标准平面。各行从上到下展示了与最近标注帧的帧距离分别为0、2和5时的对比情况。与标准平面对应的图像在截取前进行了放大,这是临床评估中的常见操作。
Table
表
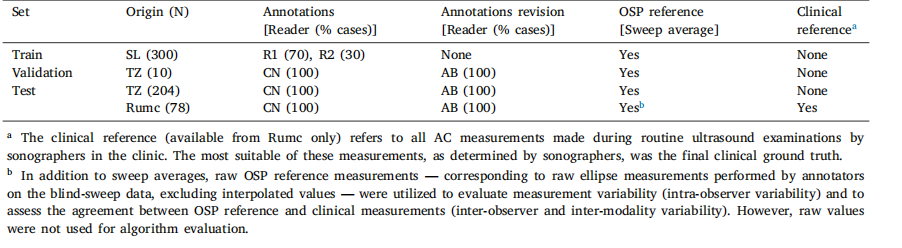
Table 1Description of the ACOUSLIC-AI datasets. SL: Sierra Leone, TZ: Tanzania, Rumc: Radboudumc in the Netherlands. R1, R2, CN and AB denotethe four different readers annotating the data.
表1 ACOUSLIC-AI数据集说明。SL:塞拉利昂,TZ:坦桑尼亚,Rumc:荷兰拉德堡德大学医学中心。R1、R2、CN和AB分别表示对数据进行标注的四位不同阅片者。
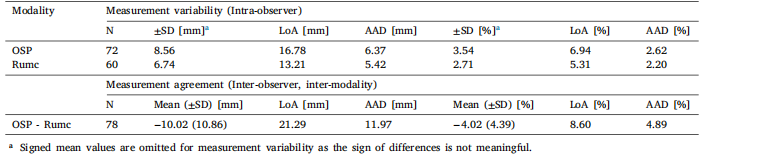
Table 2Measurement variability (intra-observer) and measurement agreement (inter-observer and inter-modality) for fetal abdominal circumferencemeasurements in the Radboudumc cohort test set (n = 78). LoA denotes the ±1.96 SD limits of agreement. AAD denotes Average AbsoluteDifference. Measurement variability assesses the absolute differences between measurements in cases with multiple observations. This analysisincludes raw reference measurements from OSP data and multiple same-day measurements obtained during standard clinical care (Rumc).Measurement agreement evaluates the differences between the average raw OSP measurements derived from blind-sweep data and the averageRumc measurements taken in the standard pl
表2 拉德堡德大学医学中心(Radboudumc)队列测试集(n = 78)中胎儿腹围测量的变异性(观察者内)和一致性(观察者间及模态间)。LoA表示±1.96标准差的一致性限度。AAD表示平均绝对差。测量变异性用于评估存在多次观测的案例中测量值之间的绝对差异。本分析包括来自产科扫查协议(OSP)数据的原始参考测量值,以及标准临床护理中获取的同一天多次测量值(Rumc)。测量一致性用于评估源自盲扫数据的OSP原始测量平均值与标准平面获取的Rumc测量平均值之间的差异。
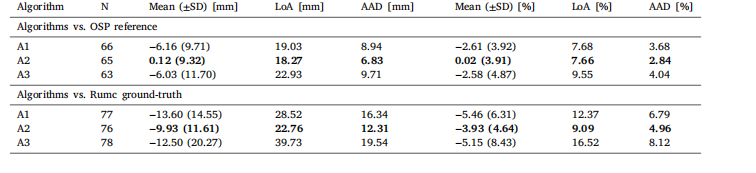
Table 3Comparison of algorithm performance in fetal abdominal circumference measurements on the Radboudumc cohort (n = 78). LoA denotes the±1.96 SD limits of agreement. AAD denotes Average Absolute Difference. The top section compares the algorithms’ measurements to the meanOSP reference measurements on the predicted sweep, while the bottom section evaluates their performance against the Radboudumc clinicalground-truth. N denotes the total number of valid predicted circumferences considered for each analysis: when comparing to the OSP reference,only circumference measurements with a reference measurement in the same sweep were considered; when comparing to the Radboudumcground-truth, all predicted circumference measurements were considered (missing values correspond to cases where the algorithms found nogood frame for measurement). The best performance for each metric is highlighted in bold
表3 算法在拉德堡德大学医学中心(Radboudumc)队列(n = 78)中胎儿腹围测量的性能对比。LoA表示±1.96标准差的一致性限度。AAD表示平均绝对差。上半部分将算法测量值与预测扫查序列的OSP参考测量平均值进行比较,下半部分评估算法测量值与拉德堡德大学医学中心临床基准值的一致性。N表示每项分析中纳入的有效预测腹围总数:与OSP参考值比较时,仅纳入同一扫查序列中有参考测量值的腹围测量结果;与拉德堡德大学医学中心基准值比较时,纳入所有预测腹围测量结果(缺失值对应算法未找到适合测量的帧的案例)。每项指标的最佳性能以粗体突出显示。



可以保证消费不被重复消费吗,可以多个消费者,但是需要保证同一个消息,不会被投递给多个消费者)









编程示例程序)





