系统架构演变过程
一、单体架构
前后端都在一个项目中,包括我们现在的前后端分离开发,都可以看作是一个单体项目。
二、集群架构
把一个服务部署多次,可以解决服务不够的问题,但是有些不必要的功能也跟着部署多次。
三、垂直架构
把不同的模块进行拆分,可以单独的部署访问量大的模块,模块之间、服务之间没有统一的管理,各自都是独立的。
四、微服务架构
是一套完整的服务管理架构。
微服务的优势
1、独立开发:把服务进行拆分,不同的服务单独开发。
2、独立部署
3、故障隔离:一个服务可以部署多份,一台服务器瘫痪,不会影响全局。
4、混合技术堆栈
5、粒度缩放:单个组件可以根据需要进行缩放,无需将所有组件放在一起
微服务中需要考虑到的问题?
1、多个小服务,如何对他们进行管理?(服务治理)
2、多个小服务,服务之间如何通讯?(服务调用)
3、多个小服务,客户端如何访问?(服务网关)
4、多个小服务,一旦出现了问题,应该如何自处理?
5、多个小服务,一旦出现了问题,应该如何排查错误?(链路追踪)
微服务中常见的概念
服务治理
服务调用
服务网关
服务容错
链路追踪
MQ消息队列
分布式锁
分布式事务
服务治理
服务治理是服务注册中心,所有的服务启动后,都在注册中心进行注册,每一个服务都有一个自己的服务名称。
常见的注册中心:
Apache的Zookeeper、Spring Cloud的Eureka、Alibaba的Nacos
搭建Nacos环境
第一步:安装nacos,下载地址:https://github.com/alibaba/nacos/releases,安装nacos下载zip的格式的安装包,然后进行解压缩操作。
第二步:启动nacos
切换目录 :cd nacos/bin
命令启动:startup.cmd -m standalone
第三步:访问nacos
打开浏览器输入 http://localhost:8848/nacos,即可访问服务,默认密码是 nacos/nacos
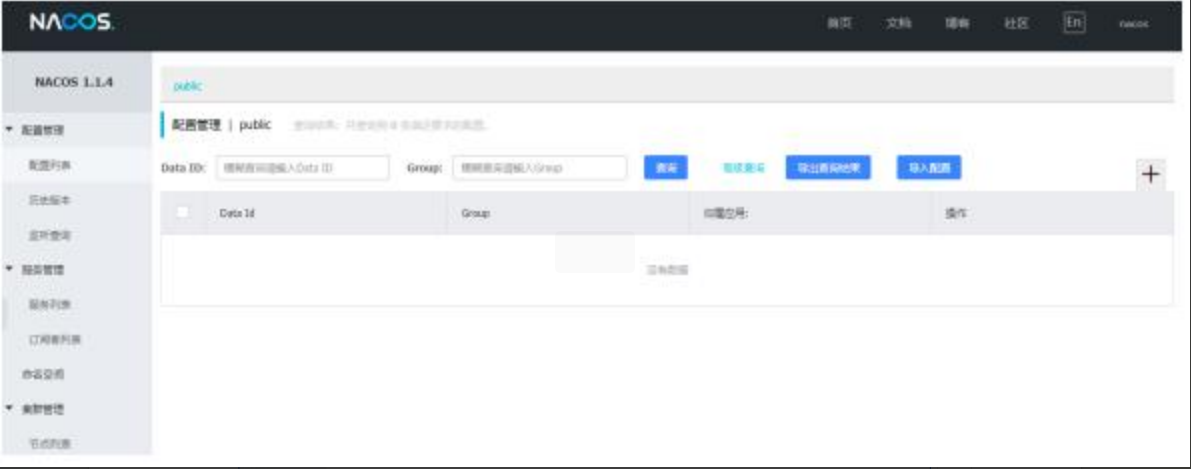
将用户微服务注册到nacos
接下来将其注册到nacos服务
1、在pom.xml中添加nacos依赖
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency>2、在启动类上添加@EnableDiscoveryClient注解
3、在每个application.yml中为每一个微服务定义服务名,并添加nacos地址
spring:application:name: service-user #服务名cloud:nacos:discovery:server-addr: 127.0.0.1:8848 #nacos 地址4、启动服务,观察nacos的控制面板上是否有注册上来的用户微服务
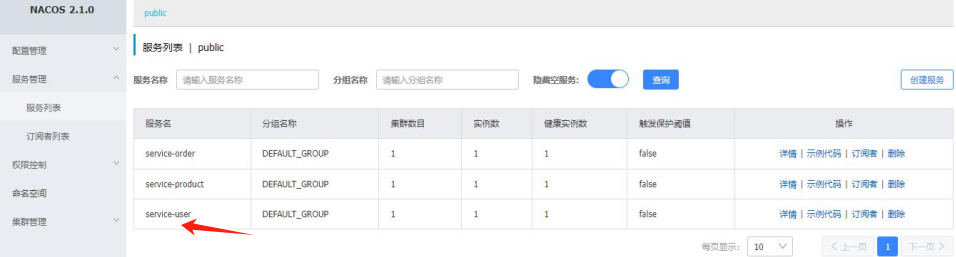
同样方法,将其他服务注册到nacos
服务调用
使用nacos客户端根据服务名动态获取服务地址和端口
@AutowiredDiscoveryClient discoveryClient;从nacos中获取服务地址
ServiceInstance serviceInstance =discoveryClient.getInstances("service-user").get(0);//getInstances获取对应服务名的服务返回的是List<ServiceInstance>集合,获取第0个服务
String purl = serviceInstance.getHost() + ":" +serviceInstance.getPort();
//使用
Product p = restTemplate.getForObject( "http://" + purl + "/product/get/"
+ pid, Product.class);服务调用负载均衡
什么是负载均衡?
就是将负载(工作任务,访问请求)进行分摊到多个操作单元(服务器,组件)上进行执行。
自定义实现负载均衡
通过修改端口启动两个商品服务
server:port: 8091
server:port: 8092

可以将获取服务的方式改为随机获取
//获取服务列表
List<ServiceInstance> instances =discoveryClient.getInstances("service-product");
//随机生成索引
Integer index = new Random().nextInt(instances.size());
//获取服务
ServiceInstance productService = instances.get(index);
//获取服务地址
String purl = productService.getHost() + ":" +productService.getPort();基于Ribbon实现负载均衡
Ribbon是Spring Cloud的一个组件,它可以让我们使用一个注解就能轻松的搞定负载均衡。
在商品服务的application.yml中
ribbon:ConnectTimeout: 2000 # 请求连接的超时时间ReadTimeout: 5000 # 请求处理的超时时间
service-product: # 调用的提供者的名称ribbon:NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule第一步:在RestTemplate的生产方法上添加一个@LoadBlanced注解
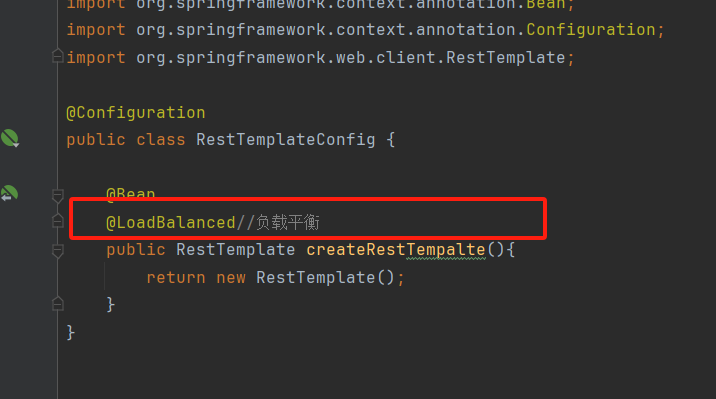
第二步:修改服务调用的方法
restTemplate.getForObject("http://服务名/product/get/"+pid, Product.class);七种负载均衡策略
1、轮询策略:RoundRobinRule,按照一定的顺序依次调用服务实例。比如一共3个服务,第一次调用服务1,第二次调用服务2,第三次调用服务3,依次类推。
2、权重策略:WeightedResponseTimeRule,根据每个服务提供者的响应时间分配一个权重,响应时间越长,权重越小,被选中的可能性也就越低。
实现原理是,刚开始使用轮询策略并开启一个计时器,每一段时间收集一次所有服务提供者的平均响应时间,然后再给每个服务提供者附上一个权重,权重越高被选中的概率越大。
3、随机策略:RandomRule,从服务提供者的列表中随机安排一个服务实例。
4、最小连接数策略:BestAvailableRule,也叫最小并发数策略,它是遍历服务者提供列表,选取连接数最小的服务实例。如果有相同的最小连接数,那么会调用轮询策略进行选取。
5、可用敏感性策略:AvailabilityFilteringRule,先过滤掉非健康的服务实例,然后再选择连接数较小的服务实例。
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.AvailabilityFilteringRule
6、区域敏感策略:ZoneAvoidanceRule,根据服务所在区域(Zone)的性能和服务的可用性来选择服务实例,在没有区域的环境下,该策略和轮询策略略类似。
7、重试策略:
Ribbon 的重试机制允许在服务请求失败时,根据预先设定的策略进行重试。重试机制能够显著提高系统的容错能力,尤其在网络波动和服务临时不可用的情况下,可以确保请求能够成功完成。
Ribbon 重试机制主要包括两种重试场景:
同一服务实例的重试:当请求某个服务实例时,如果请求失败,Ribbon 会在同一个服务实例上进行多次重试。
切换服务实例的重试:如果在同一服务实例上重试多次后仍然失败,Ribbon 会尝试切换到其他可用的服务实例进行重试
ribbon:ConnectTimeout: 2000 # 请求连接的超时时间ReadTimeout: 5000 # 请求处理的超时时间
service-product: # 调用的提供者的名称ribbon:MaxAutoRetries: 2 # 在同一个实例上的最大重试次数MaxAutoRetriesNextServer: 1 # 切换到下一个实例的最大重试次数OkToRetryOnAllOperations: true # 对所有操作(包括非GET)进行重试ReadTimeout: 2000 # 读超时ConnectTimeout: 1000 # 连接超时
基于Fegin实现服务调用
什么Fegin?
Fegin是Spring Cloud提供的一个声明式的伪Http客户端,它使得调用远程服务就像调用本地服务一样简单,只需要创建一个接口并添加一个注解即可。
Nacos很好的兼容了Fegin,Fegin默认集成了Ribbon,所以在Nacos下使用Fegin默认实现了负载均衡的效果。
Fegin的使用
1、在使用Fegin的服务中导入Fegin依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>2、在启动类上添加Fegin的注解
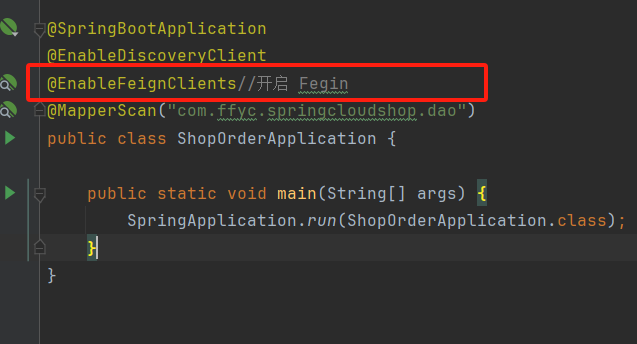
3、创建对应服务的接口,并使用Fegin实现微服务调用
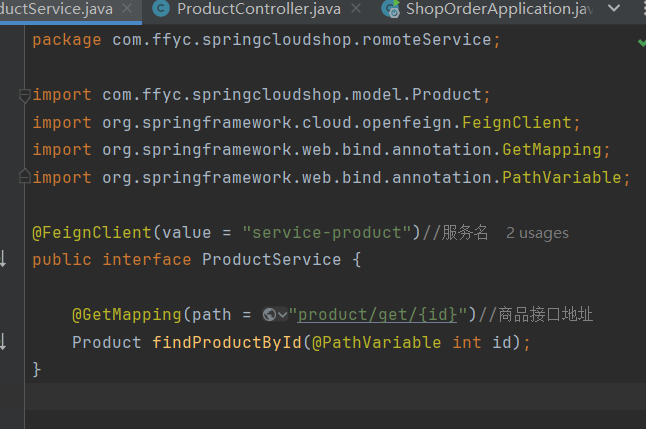
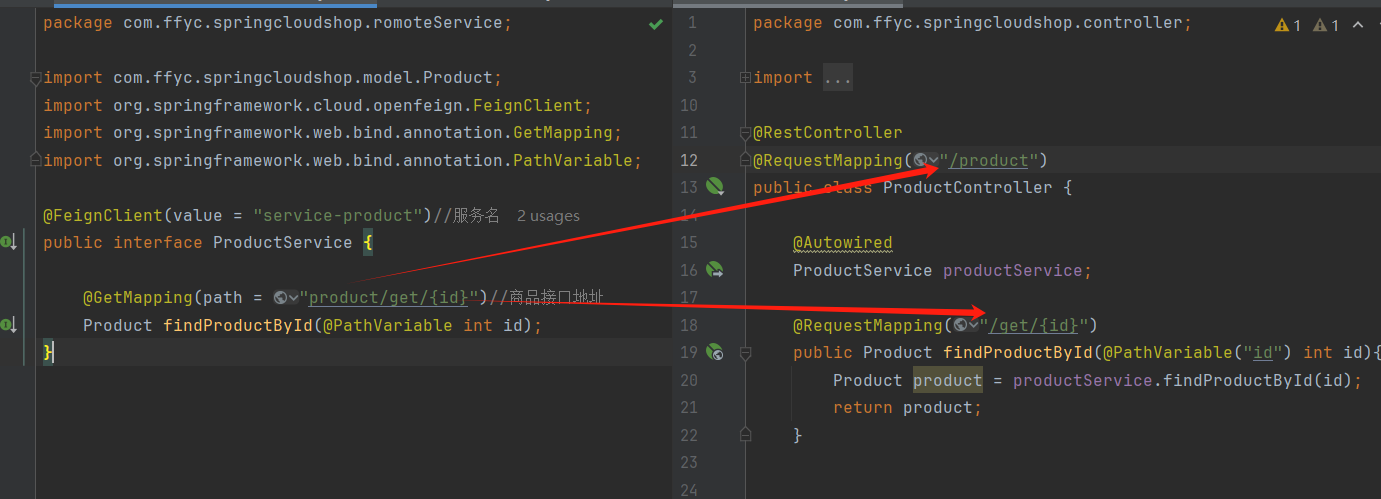
4、修改controller代码,并启动验证
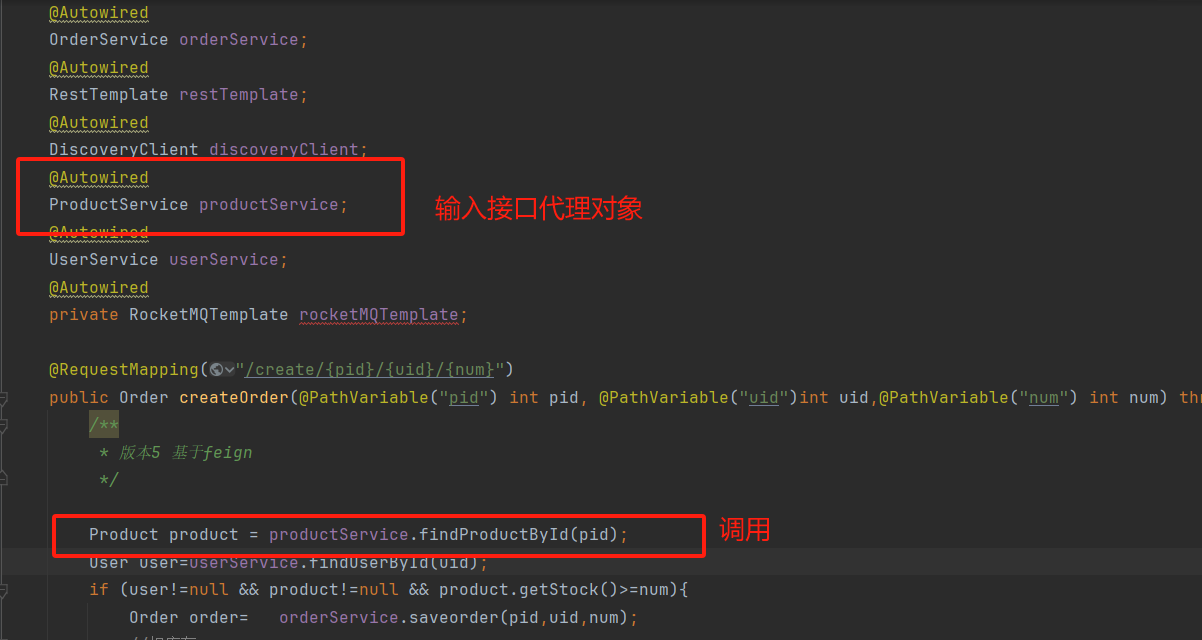
服务容错
高并发情况下,如果访问量过大,不加以控制,大量的请求堆积,会击跨整个服务。
需要在某些场景下,为了保证服务不宕机,使用jmeter测试工具,模拟多线程,向后端发起请求。
要对请求进行限制 限流
Sentinel
Sentinel的主要功能就是容错,主要体现在三个方面:
流量控制:限制每秒查询的访问量
熔断降级:当检测到调用链路中某个资源出现不稳定的表现,例如:请求响应时间长或异常比例升高的时候,则对这个资源的调用进行限制,让请求快速失败,避免影响到其他的资源而导致级联故障。
Sentinel对这个问题采用两种手段:
1、通过并发线程数进行限制
Sentinel 通过限制资源并发线程的数量,来减少不稳定资源对其它资源的 影响。当某个资源出现不稳定的情况下,例如响应时间变长,对资源的直接影响 就是会造成线程数的逐步堆积。当线程数在特定资源上堆积到一定的数量之后, 对该资源的新请求就会被拒绝。堆积的 线程完成任务后才开始继续接收请求。
2、响应时间对资源进行降级
除了对并发线程数进行控制以外,Sentinel 还可以通过响应时间来快速降 级不稳定的资源。当依赖的资源出现响应时间过长后,所有对该资源的访问都会 被直接拒绝,直到过了指定的时间窗口之后才重新恢复。
系统负载保护:
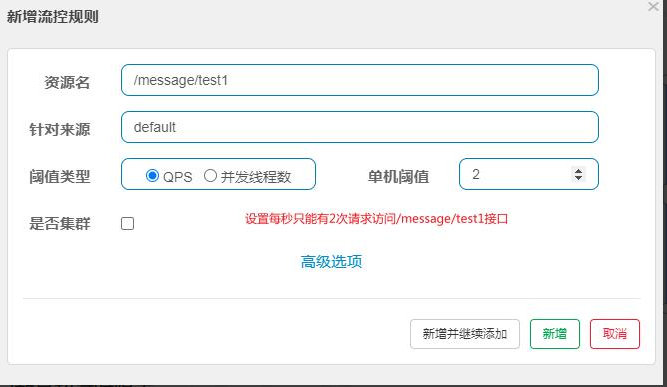
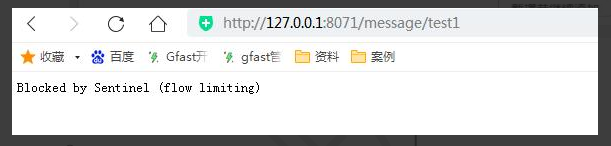
服务网关
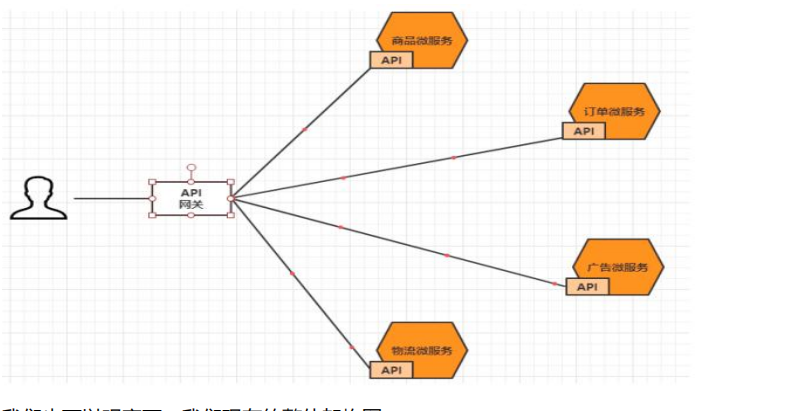
消息队列MQ
什么是MQ?
Message Queue:消息队列,是一个组件,是一种提供消息队列服务的中间件,也称消息中间件,是一套提供了消息生产、存储、消费全过程API的软件系统(消息即数据),简单来说就是一个先进先出的数据结构。
常见的MQ应用场景:
异步解耦:
常见的一个场景是用户注册后,需要发送邮件和短信通知,已告知用户注册成功。传统的做法如下:
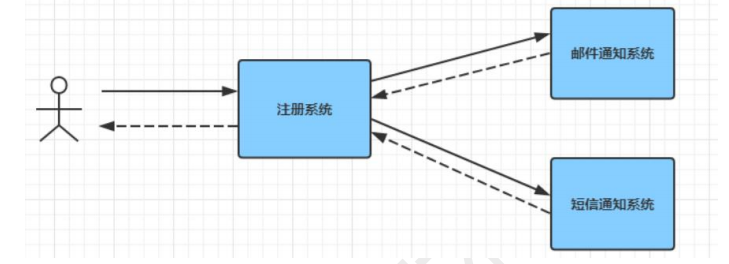
此架构下注册、邮件、短信三个任务全部完成后,才会注册结构到客户端,用户才可以使用账号登录。但是对与用户来说,注册功能实际只需要注册系统存储用户的信息后,用户就可以登录,而后续的注册短信和邮件不是及时需要关注的,所以实际当数据写入注册系统后,注册系统就可以把其他的操作放入对应的消息队列MQ中然后返回用户结果,有消息队列MQ异步进行其他操作。
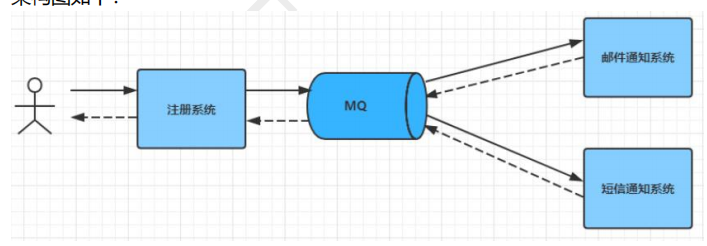
异步解耦是消息队列MQ的主要特点,主要目的是减少请求响应时间和解耦。主要的使用场景就是将比叫消耗时间且不需要及时同步返回结果的操作放入消息队列。同时,由于使用了消息队列MQ,只要保证消息格式不变,消息的发送方和接收方并不需要彼此联系,也不需要接收对方的影响,即解耦。
RocketMQ架构
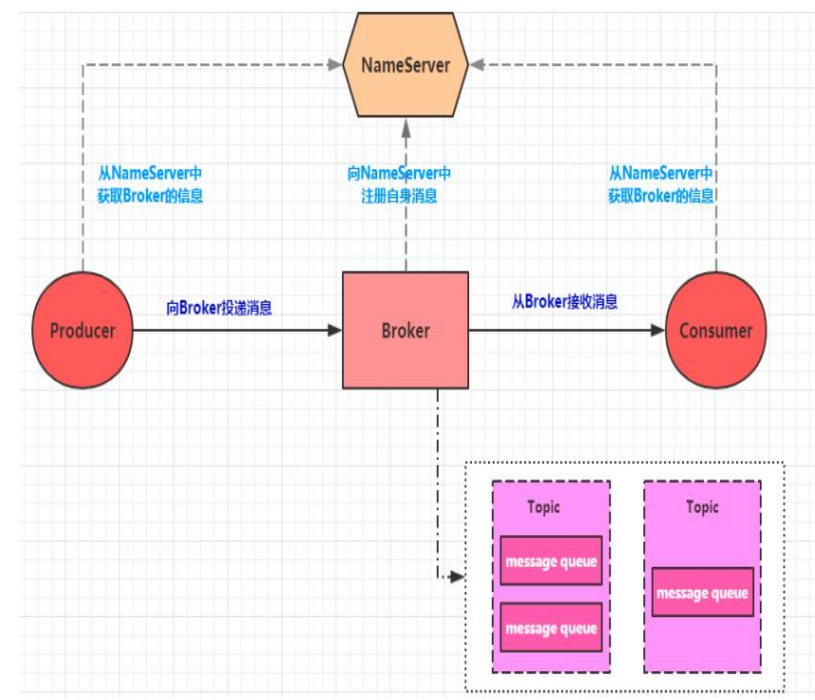
NameServer:消息队列的协调者,Broker向它注册路由信息,同时Producer和Consumer向其获取路由信息
Broker:是RocketMQ的核心,负责消息的接收,存储,发送等功能
Producer:消息的生产者,需要从NameServer获取Boker的信息,然后与Broker建立连接,向Broker发送消息
Consumer:消息的接收者,需要从NameServer获取Broker信息,然后与Broker建立连接,从Broker中获取消息。
Topic:用来区分不同类型的消息,发送和接收消息前都需要先创建Topic,针对Topic来发送和接收消息
Message Queue:为了提高性能和吞吐量,引入了Message Queue,一个Topic可以设置一个或多个Message Queue,这样消息就可以并行往各个Message Queue发送消息,消费者也可以并行的从多个Message Queue读取消息。就是消息的载体。
Producer Group:生产者组,简单来说就是多个发送同一类消息的生产者。
Consumer Group:接收者组,接收同一类消息的多个consumer实例组成的。
java代码演示消息发送和接收
导入依赖
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.0.2</version>
</dependency>发送消息:
1、创建消息生产者,指定生产者所属的组名
2、指定NameServer地址
3、启动生产者
4、创建消息对象,指定主题、标签、消息体。
5、发送消息
6、关闭生产者
package org.example;import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.common.message.Message;public class Productor {public static void main(String[] args) throws Exception {
//1. 创建消息生产者, 指定生产者所属的组名DefaultMQProducer producer = new DefaultMQProducer("myproducer-group");
//2. 指定 Nameserver 地址producer.setNamesrvAddr("127.0.0.1:9876");
//3. 启动生产者producer.start();
//4. 创建消息对象,指定主题、标签和消息体Message msg = new Message("myTopic", "myTag",("RocketMQ Message哇哇哇哇").getBytes());Message msg2 = new Message("myTopic", "myTa",("RocketMQ Message哇哇哇哇222").getBytes());
//5. 发送消息SendResult sendResult = producer.send(msg, 10000);SendResult send = producer.send(msg2, 10000);System.out.println(sendResult);System.out.println(send);
//6. 关闭生产者producer.shutdown();}
}
接收消息
1、创建消息接收者,指定消费者所属的组名
2、指定NameServer地址
3、指定接收者订阅的主题和标签
4、设置回调函数,编写处理消息的方法
5、启动消息接收者
package org.example;import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyContext;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.common.message.MessageExt;import java.util.List;public class Comsumer {public static void main(String[] args) throws Exception {
//1. 创建消息消费者, 指定消费者所属的组名DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("myconsumergroup");
//2. 指定 Nameserver 地址consumer.setNamesrvAddr("127.0.0.1:9876");
//3. 指定消费者订阅的主题和标签consumer.subscribe("myTopic", "*");
//4. 设置回调函数,编写处理消息的方法consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {System.out.println("Receive New Messages: " + new String(msgs.get(0).getBody()));//返回消费状态return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}});
//5. 启动消息消费者consumer.start();System.out.println("Consumer Started.");}
}
在微服务中RocketMQ的使用
订单服务是发送消息
添加依赖
<!--rocketmq-->
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.4.0</version>
</dependency>添加配置
rocketmq:
name-server: 127.0.0.1:9876 #rocketMQ 服务的地址
producer:
group: shop-order # 生产者组编写测试代码
@Autowired
private RocketMQTemplate rocketMQTemplate;//主题,消息
rocketMQTemplate.convertAndSend("order-topic", order);用户服务接收消息
添加依赖
<!--rocketMQ-->
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.4.0</version>
</dependency>修改配置文件
rocketmq:
name-server: 127.0.0.1:9876编写消息接收服务
@Service
@RocketMQMessageListener(consumerGroup = "shop-user", topic = "order-topic")
public class SmsService implements RocketMQListener<Order> {
@Override
public void onMessage(Order order) {
System.out.println("收到一个订单信息:"+ JSON.toJSONString(order)+",接
下来发送短信");
}
}启动服务,执行下单操作,查看控制台
成功接收到消息。
Redis实现分布式锁
什么是分布式锁?
即分布式系统中的锁,在单体项目中我们通过Java中的锁解决多线程访问共享资源的问题,而分布式锁,解决了分布式系统中控制共享资源访问的问题。与单体项目不同的是,分布式系统中竞争共享资源的最小粒度从线程升级到了进程。
为什么需要分布式锁?
在分布式微服务架构中,一个应用往往需要开启多个服务(每一个服务都是一个独立的进程),这样依赖Java中的锁synchronized和Lock失效了,只有在同一个进程是有效的。
如何实现分布式锁
可以通过redis实现分布式锁,在redis中存放一个标志,当一个请求到达时修改标志
方式一:redis+setnx命令,自己实现一个分布式锁,虽然可以实现,在一些简单的场景下,没有问题的,在复杂的情况下还是会出现问题的。
setnx key value 设置键值时,会先判断键是否存在,键如果不存在,设置成功,键如果存在,就设置失败
如果不将锁释放当代finally中,就会造成死锁,原因是1、程序处理逻辑出现了问题,没有及时释放锁2、进程挂了,没有机会释放锁。
@RequestMapping("/sub")public void sub(){// 使用redis,以及redis中的setnx命令实现分布式锁// setnx key value 设置键值时,会先判断键是否存在,键如果不存在,设置成功,键如果存在,就设置失败//设置失效时间,第一个线程进来后就会,就会获取锁,第一个线程执行的业务超过失效时间,key就会失效,其他线程进来获取锁//第一个线程业务执行完之后就回去释放锁,那么锁就会释放成其他线程的锁,所以设置失效时间也是会出现问题的。try{// 针对进程可能挂掉的情况,为ket设置一个失效时间,即使服务挂了,也会删除keyboolean res = redisTemplate.opsForValue().setIfAbsent("lock",10, TimeUnit.SECONDS);if (!res){return;}// 从数据库查询一下库存Integer stock = (Integer) redisTemplate.opsForValue().get("");// 如果库存>0,就扣库存if (stock>0){Integer real = stock-1;redisTemplate.opsForValue().set("stock", real); // 把释放锁写在finally中,即使出现异常也,会释放锁System.out.println("成功");}else {System.out.println("扣库存失败");}}finally {redisTemplate.delete("lock");}}在finally中释放锁以及设置键的失效时间,也是会出现问题的。
例如:程序的业务逻辑执行时间大于失效时间,那么锁就会失效,其他线程就会进来,这时,当第一个线程执行完成之后,会误删除第二个线程的锁的,导致其他线程的锁失效。
解决办法:为每一个线程添加一个版本号,删除锁时判断版本号。
@RequestMapping("/sub")public void sub(){// 使用redis,以及redis中的setnx命令实现分布式锁// setnx key value 设置键值时,会先判断键是否存在,键如果不存在,设置成功,键如果存在,就设置失败//设置失效时间,第一个线程进来后就会,就会获取锁,第一个线程执行的业务超过失效时间,key就会失效,其他线程进来获取锁//第一个线程业务执行完之后就回去释放锁,那么锁就会释放成其他线程的锁,所以设置失效时间也是会出现问题的。String createId = UUID.randomUUID().toString();//生产一个32位不重复的字符串,版本号try{// 针对进程可能挂掉的情况,为ket设置一个失效时间,即使服务挂了,也会删除keyboolean res = redisTemplate.opsForValue().setIfAbsent("lock",createId ,10, TimeUnit.SECONDS);if (!res){return;}// 从数据库查询一下库存Integer stock = (Integer) redisTemplate.opsForValue().get("");// 如果库存>0,就扣库存if (stock>0){Integer real = stock-1;redisTemplate.opsForValue().set("stock", real); // 把释放锁写在finally中,即使出现异常也,会释放锁System.out.println("成功");}else {System.out.println("扣库存失败");}}finally {String lock=(String)redisTemplate.opsForValue().get("lock");if (createId.equals(lock)){//版本号相同,可以释放锁,不一样则说明已经过期了,则不需要管了。redisTemplate.delete("lock");}}}方式2:使用redisson
导入依赖
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.6.5</version></dependency>创建redisson对象
package com.ffyc.springcloudshop.config;import org.redisson.Redisson;
import org.redisson.config.Config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class RedissonConfig {//创建 Redisson 对象@Beanpublic Redisson getRedisson(){Config config = new Config();config.useSingleServer().setAddress("redis://127.0.0.1:6379").setDatabase(0);return (Redisson)Redisson.create(config);}}使用redisson实现加锁释放锁
@RequestMapping("/sub")public void sub(){RLock lock=redisson.getLock("stock-lock");//定义redis中锁的标志keytry {lock.lock(30,TimeUnit.SECONDS);//获取锁// 从数据库查询一下库存Integer stock = (Integer) redisTemplate.opsForValue().get("stock");// 如果库存>0,就扣库存if (stock>0){Integer real = stock-1;redisTemplate.opsForValue().set("stock", real); // 把释放锁写在finally中,即使出现异常也,会释放锁System.out.println("成功");}else {System.out.println("扣库存失败");}}finally {lock.unlock();//释放锁}}为什么要使用redisson?
- 可靠性优先:Redisson 解决了原生
SETNX的核心缺陷(如非原子性、误释放、超时问题),确保锁在复杂场景下的正确性。 - 开发效率优先:无需重复造轮子,直接使用成熟的分布式锁实现,专注业务逻辑开发。
- 扩展性优先:支持多种锁类型、高可用架构(主从 / 集群)、监控功能,适应微服务、分布式系统的复杂需求。

)








--异常处理,命名空间,多继承与虚继承)

免费证书的技术指南)






