目录
摘要
Abstract
1 Schema
2 Prompt
3 KAG-Builder
3.1 reader
3.2 splitter
3.3 extractor
3.4 vectorizer
3.5 writer
3.6 可选组件
4 示例
总结
摘要
本周深入学习了 KAG 项目中的 Schema、Prompt 以及 KAG-Builder 相关代码知识,涵盖了其定义、功能以及在知识图谱构建中的应用。Schema定义了知识图谱的架构,Prompt用于引导模型生成符合预期的输出,而 KAG-Builder则是通过结构化信息获取、知识语义对齐和图存储写入来构建知识图谱,其中包含reader、splitter、extractor、vectorizer、writer等多个组件。
Abstract
This week, we have in-depth knowledge of the Schema, Prompt and KAG-Builder related code knowledge in the KAG project, covering their definitions, functions, and applications in the construction of knowledge graphs. The schema defines the architecture of the knowledge graph, the Prompt is used to guide the model to generate the expected output, and the KAG-Builder is to build the knowledge graph through structured information acquisition, knowledge semantic alignment, and graph storage writing, which includes multiple components such as reader, splitter, extractor, vectorizer, and writer.
1 Schema
Schema是定义知识图谱语义框架和数据组织结构的核心组件,它规定了知识图谱中数据的类型、关系及逻辑约束,是构建和管理知识图谱的基础,其中:
- 类型:定义一类物体的行为,类型与实例的关系可类比与java语言中类和对象的关系;包括实体类型(EntityType),概念类型(ConceptType),事件类型(EventType),标准类型等;
- 实例:类比于java语言中的对象,是在图数据库中的node此处要澄清,类型与实例只是SPG逻辑上的概念,在实际的图数据库存储中,都为node;
- 属性:实体中可定义属性,这与java类中的属性相似,注意,在SPG中某些属性会被处理成关系节点,如User类型下有一个phone的标准类型属性,在User实例的创建中,会生成一个phone标准类型的实例node,并创建一个由User实例指向phone实例的edge,这样做可以很好的解决知识图谱稀疏性的问题,也能提取共性属性;
- 关系:类比于图数据库中的edge,可以有属性,且可以增加多种限制;
- 规则:定义属性,关系时可定义相关规则,在规则中创建约束条件,如相反关系等。
概念类型:
- 实体从具体到一般的抽象,表述的是一组实体实例或事件实例的集合,是一种分类体系;
- 相对静态,也是常识知识,具有较强复用性,如人群标签、事件分类、行政区划分类等;
- 概念类型的关系只允许创建在7大类里定义的谓词,概念类型需定义上下谓词。
HospitalDepartment(科室): ConceptTypehypernymPredicate: isA实体类型(必须存在):
- 业务相关性比较强的客观对象,通多属性、多关系刻画的多元复合结构类型,如用户、企业、商户等;
- 所有类型会默认继承Thing类型,默认创建id、name和description属性。
Disease(疾病): EntityTypeproperties:desc(描述): Textindex: TextsemanticType(语义类型): Textindex: Textcomplication(并发症): Diseaseconstraint: MultiValuecommonSymptom(常见症状): Symptomconstraint: MultiValueapplicableMedicine(适用药品): Medicineconstraint: MultiValuehospitalDepartment(就诊科室): HospitalDepartmentconstraint: MultiValuediseaseSite(发病部位): HumanBodyPartconstraint: MultiValuerelations:abnormal(异常指征): Indicator事件类型:
- 加入时间、空间等约束的时空多元类型,如通过NLP、CV等抽取出来的行业事件、企业事件、诊疗事件或因购买、核销、注册等行为产生的用户行为事件;
- 事件类型必须有主题subject,可以有发生事件、地点等基础信息。
Event(医疗风险事件): EventTypeproperties:subject(主体): Doctortime(时间): Date2 Prompt
Prompt是引导LLM与知识图谱协同工作的核心指令,其设计融合了结构化知识约束和语义对齐能力,旨在提升垂直领域的决策精准性与逻辑严谨性。
在KAG中的Prompt主要要以下几类:
- 实体prompt:
"instruction": "作为一个图谱知识抽取的专家, 你需要基于定义了实体类型及对应属性的schema,从input字段的文本中抽取出所有的实体及其属性,schema中标记为List的属性返回list,未能提取的属性返回null。以标准json list格式输出,list中每个元素形如{category: properties},你可以参考example字段中给出的示例格式。注意实体属性的SemanticType指的是一个相比实体类型更具体且明确定义的类型,例如Person类型的SemanticType可以是Professor或Actor。","example": [{"input": "周杰伦(Jay Chou),1979年1月18日出生于台湾省新北市,祖籍福建省永春县,华语流行乐男歌手、音乐人、演员、导演、编剧,毕业于淡江中学。2000年,发行个人首张音乐专辑《Jay》 [26]。2023年凭借《最伟大的作品》获得第一届浪潮音乐大赏年度制作、最佳作曲、最佳音乐录影带三项大奖。","output": [{"category": "Person","properties": {"name": "周杰伦","semanticType": "Musician","description": "华语流行乐男歌手、音乐人、演员、导演、编剧",},},{"category": "GeographicLocation","properties": {"name": "台湾省新北市","semanticType": "City","description": "周杰伦的出生地",},},{"category": "GeographicLocation","properties": {"name": "福建省永春县","semanticType": "County","description": "周杰伦的祖籍",},},{"category": "Organization","properties": {"name": "淡江中学","semanticType": "School","description": "周杰伦的毕业学校",},},{"category": "Works","properties": {"name": "Jay","semanticType": "Album","description": "周杰伦的个人首张音乐专辑",},},{"category": "Works","properties": {"name": "最伟大的作品","semanticType": "MusicVideo","description": "周杰伦凭借此作品获得多项音乐大奖",},},],}],- 事件prompt:
"instruction": "作为一个知识图谱图谱事件抽取的专家, 你需要基于定义的事件类型及对应属性的schema,从input字段的文本中抽取出所有的事件及其属性,schema中标记为List的属性返回list,未能提取的属性返回null。以标准json list格式输出,list中每个元素形如{category: properties},你可以参考example字段中给出的示例格式。","example": {"input": "1986年,周星驰被调入无线电视台戏剧组;同年,他在单元情景剧《哥哥的女友》中饰演可爱活泼又略带羞涩的潘家伟,这也是他第一次在情景剧中担任男主角;之后,他还在温兆伦、郭晋安等人主演的电视剧中跑龙套。","output": [{"category": "Event","properties": {"name": "周星驰被调入无线电视台戏剧组","abstract": "1986年,周星驰被调入无线电视台戏剧组。","subject": "周星驰","time": "1986年","location": "无线电视台","participants": [],"semanticType": "调动",},},{"category": "Event","properties": {"name": "周星驰在《哥哥的女友》中饰演潘家伟","abstract": "1986年,周星驰在单元情景剧《哥哥的女友》中饰演可爱活泼又略带羞涩的潘家伟,这也是他第一次在情景剧中担任男主角。","subject": "周星驰","time": "1986年","location": None,"participants": [],"semanticType": "演出",},},{"category": "Event","properties": {"name": "周星驰跑龙套","abstract": "1986年,周星驰在温兆伦、郭晋安等人主演的电视剧中跑龙套。","subject": "周星驰","time": "1986年","location": None,"participants": ["温兆伦", "郭晋安"],"semanticType": "演出",},},],},- 实体标准化prompt:
"""
{"instruction": "input字段包含用户提供的上下文。命名实体字段包含从上下文中提取的命名实体,这些可能是含义不明的缩写、别名或俚语。为了消除歧义,请尝试根据上下文和您自己的知识提供这些实体的官方名称。请注意,具有相同含义的实体只能有一个官方名称。请按照提供的示例中的输出字段格式,以单个JSONArray字符串形式回复,无需任何解释。","example": {"input": "烦躁不安、语妄、失眠酌用镇静药,禁用抑制呼吸的镇静药。3.并发症的处理经抗菌药物治疗后,高热常在24小时内消退,或数日内逐渐下降。若体温降而复升或3天后仍不降者,应考虑SP的肺外感染,如腋胸、心包炎或关节炎等。治疗:接胸腔压力调节管+吸引机负压吸引水瓶装置闭式负压吸引宜连续,如经12小时后肺仍未复张,应查找原因。","named_entities": [{"name": "烦躁不安", "category": "Symptom"},{"name": "语妄", "category": "Symptom"},{"name": "失眠", "category": "Symptom"},{"name": "镇静药", "category": "Medicine"},{"name": "肺外感染", "category": "Disease"},{"name": "胸腔压力调节管", "category": "MedicalEquipment"},{"name": "吸引机负压吸引水瓶装置", "category": "MedicalEquipment"},{"name": "闭式负压吸引", "category": "SurgicalOperation"}],"output": [{"name": "烦躁不安", "category": "Symptom", "official_name": "焦虑不安"},{"name": "语妄", "category": "Symptom", "official_name": "谵妄"},{"name": "失眠", "category": "Symptom", "official_name": "失眠症"},{"name": "镇静药", "category": "Medicine", "official_name": "镇静剂"},{"name": "肺外感染", "category": "Disease", "official_name": "肺外感染"},{"name": "胸腔压力调节管", "category": "MedicalEquipment", "official_name": "胸腔引流管"},{"name": "吸引机负压吸引水瓶装置", "category": "MedicalEquipment", "official_name": "负压吸引装置"},{"name": "闭式负压吸引", "category": "SurgicalOperation", "official_name": "闭式负压引流"}]},"input": $input,"named_entities": $named_entities,
} """KAG中的Prompt是连接大模型与知识图谱的“语义桥梁”,通过结构化知识注入、符号逻辑引导和动态上下文适配,解决了传统大模型在垂直领域中的幻觉、逻辑混乱等问题。
3 KAG-Builder
构建器链为一个有向无环图,有三种类型的类,用于不同场景的知识图谱构建:
- 结构化构建器链:处理结构化数据(如数据库表、CSV文件),Mapping(映射器)->Vectorizer(向量器,可选)->Writer(写入器)
- mapping:将原始数据按预定义Schema转换为中间格式;
- vectorizer:将结构化数据编码为向量;
- writer:将处理后的数据持久化到存储系统。
@KAGBuilderChain.register("structured")
@KAGBuilderChain.register("structured_builder_chain")
class DefaultStructuredBuilderChain(KAGBuilderChain):def __init__(self,mapping: MappingABC,writer: SinkWriterABC,vectorizer: VectorizerABC = None,):self.mapping = mappingself.writer = writerself.vectorizer = vectorizerdef build(self, **kwargs):if self.vectorizer:chain = self.mapping >> self.vectorizer >> self.writerelse:chain = self.mapping >> self.writerreturn chain如下图所示,为KAG-Builder的处理非结构化数据的流程链:
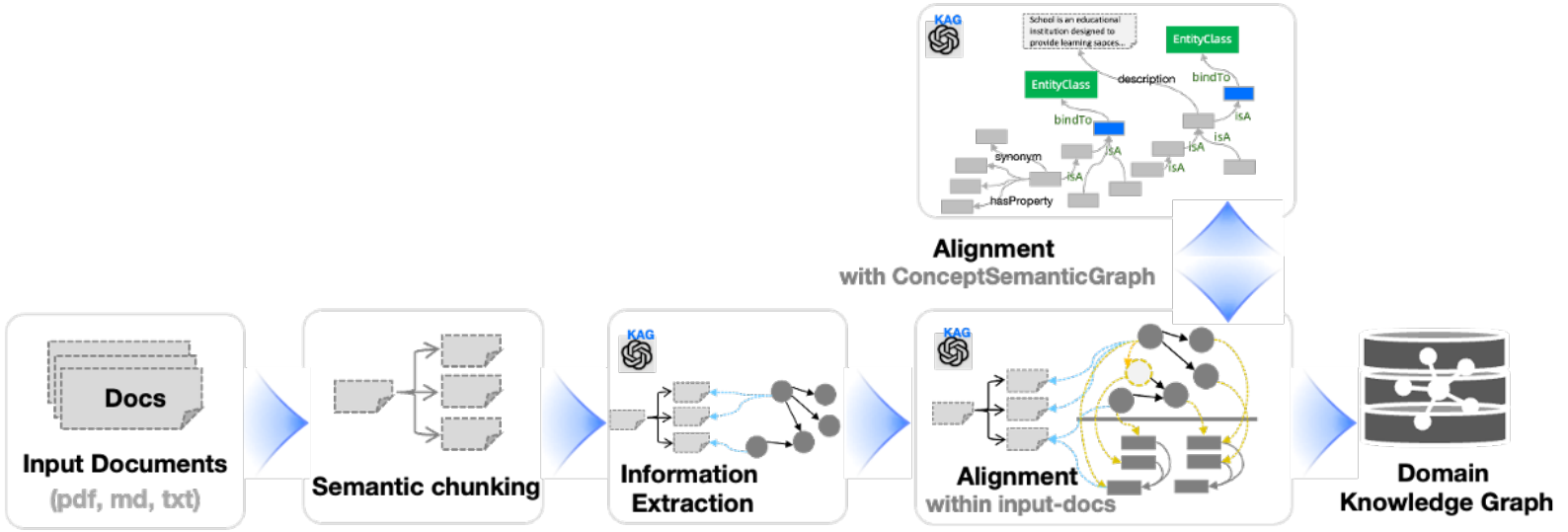
- 非结构化构建器链:处理非结构化文本(如 PDF、TXT),Reader(读取器)->Spliter(切分器)->Extractor(提取器)->Vectorizer(向量器)->PostProcess(后处理,可选)->Writer(写入器):
- reader:加载原始文件,生成Chunk或SubGraph;
- spliter:将大Chunk分割为更小的chunk;
- extractor:从文本中抽取实体、关系、事件,生成SubGraph;
- vectorizer:将文本或图谱编码为向量;
- post_process:优化图谱结构;
- writer:将构建好的知识图谱数据写入到指定的存储介质中。
@KAGBuilderChain.register("unstructured")
@KAGBuilderChain.register("unstructured_builder_chain")
class DefaultUnstructuredBuilderChain(KAGBuilderChain):def __init__(self,reader: ReaderABC,splitter: SplitterABC = None,extractor: ExtractorABC = None,vectorizer: VectorizerABC = None,writer: SinkWriterABC = None,post_processor: PostProcessorABC = None,):self.reader = readerself.splitter = splitterself.extractor = extractorself.vectorizer = vectorizerself.post_processor = post_processorself.writer = writerdef build(self, **kwargs):chain = self.reader >> self.splitterif self.extractor:chain = chain >> self.extractorif self.vectorizer:chain = chain >> self.vectorizerif self.post_processor:chain = chain >> self.post_processorif self.writer:chain = chain >> self.writerreturn chain-
外部知识注入链:将外部知识图谱(如 Wikidata)合并到当前图谱,ExternalGraphLoader(外部图谱加载器)->Vectorizer(向量器,可选)->Writer(写入器):
-
externalgraph:读取外部图谱数据;
-
vectorizer:编码外部图谱;
-
writer:将外部图谱与当前图谱融合。
-
@KAGBuilderChain.register("domain_kg_inject_chain")
class DomainKnowledgeInjectChain(KAGBuilderChain):def __init__(self,external_graph: ExternalGraphLoaderABC,writer: SinkWriterABC,vectorizer: VectorizerABC = None,):self.external_graph = external_graphself.writer = writerself.vectorizer = vectorizerdef build(self, **kwargs):if self.vectorizer:chain = self.external_graph >> self.vectorizer >> self.writerelse:chain = self.external_graph >> self.writerreturn chain
3.1 reader
reader基于抽象基类ReaderABC,用于将文件(pdf、txt、csv等类型)内容解析为Chunk对象,以下是Reader文件中TXTReader的代码:
@ReaderABC.register("txt")
@ReaderABC.register("txt_reader")
class TXTReader(ReaderABC):def _invoke(self, input: Input, **kwargs) -> List[Output]:if not input:raise ValueError("Input cannot be empty")try:if os.path.exists(input):with open(input, "r", encoding="utf-8") as f:content = f.read()else:content = inputexcept OSError as e:raise IOError(f"Failed to read file: {input}") from ebasename, _ = os.path.splitext(os.path.basename(input))chunk = Chunk(id=generate_hash_id(input),name=basename,content=content,)return [chunk]TXTReader为处理文本读取的主要方法,此方法读取输入的内容(可以是文件路径或文本内容)并将其转换为块,其中:
- 参数:
- input (输入):输入字符串,可以是文本文件或直接文本内容的路径。
- **kwargs:其他关键字参数,当前未使用,但保留以备将来扩展。
- 返回:
- List[Output]:包含 Chunk 对象的列表,每个对象代表读取的一段文本。
- 异常处理:
- ValueError:如果输入为空。
- IOError:如果读取输入指定的文件时出现问题。
3.2 splitter
splitter能够根据指定的长度和窗口大小将文本拆分为多个小块。它支持按句子边界拆分和严格按长度拆分两种模式,并且能够处理表格数据。
LengthSplitter类继承自 BaseTableSplitter,来实现根据文本长度和窗口大小将文本拆分为小块的功能。分为以下几个步骤:
- __init__:构造函数,初始化拆分长度、窗口长度和是否严格按长度拆分:
- split_length (int):每个 chunk 的最大长度;
- window_length (int):块之间的重叠长度;
- strict_length (bool):是否严格按长度拆分而不保留句子,默认为 False。
@SplitterABC.register("length")
@SplitterABC.register("length_splitter")
class LengthSplitter(BaseTableSplitter):def __init__(self,split_length: int = 500,window_length: int = 100,strict_length: bool = False,):super().__init__()self.split_length = split_lengthself.window_length = window_lengthself.strict_length = strict_length- input_types output_types:定义输入和输出类型均为Chunk:
@propertydef input_types(self) -> Type[Input]:return Chunk@propertydef output_types(self) -> Type[Output]:return Chunk- chunk_breakdown:递归地将文本块拆分为更小的块:
def chunk_breakdown(self, chunk):chunks = self.logic_break(chunk)if chunks:res_chunks = []for c in chunks:res_chunks.extend(self.chunk_breakdown(c))else:res_chunks = self.slide_window_chunk(chunk, self.split_length, self.window_length)return res_chunks- split_sentence:将文本按句子分隔符拆分为句子列表:
- 参数:content (str),需要拆分为句子的内容;
- 返回值:List[str],句子列表。
def split_sentence(self, content):sentence_delimiters = ".。??!!" if KAG_PROJECT_CONF.language == "en" else "。?!"output = []start = 0for idx, char in enumerate(content):if char in sentence_delimiters:end = idxtmp = content[start : end + 1].strip()if len(tmp) > 0:output.append(tmp.strip())start = idx + 1res = content[start:].strip()if len(res) > 0:output.append(res)return output- slide_window_chunk:使用滑动窗口方法将内容拆分为多个块:
- 参数:
- org_chunk (Chunk):要拆分的原始Chunk;
- chunk_size (int, optional):每个块的最大大小,默认值为2000;
- window_length (int,可选):块之间的重叠长度,默认值为300;
- sep (str,可选):用于连接句子的分隔符,默认为 “n”;
- 返回: List[Chunk],Chunk对象的列表。
- 参数:
def slide_window_chunk(self,org_chunk: Chunk,chunk_size: int = 2000,window_length: int = 300,sep: str = "\n",) -> List[Chunk]:if org_chunk.type == ChunkTypeEnum.Table:table_chunks = self.split_table(org_chunk=org_chunk, chunk_size=chunk_size, sep=sep)if table_chunks is not None:return table_chunks# 如果启用严格长度切分,不按句子切分if getattr(self, "strict_length", False):return self.strict_length_chunk(org_chunk)content = self.split_sentence(org_chunk.content)splitted = []cur = []cur_len = 0for sentence in content:if cur_len + len(sentence) > chunk_size:if cur:splitted.append(cur)tmp = []cur_len = 0for item in cur[::-1]:if cur_len >= window_length:breaktmp.append(item)cur_len += len(item)cur = tmp[::-1]cur.append(sentence)cur_len += len(sentence)if len(cur) > 0:splitted.append(cur)output = []for idx, sentences in enumerate(splitted):chunk = Chunk(id=generate_hash_id(f"{org_chunk.id}#{idx}"),name=f"{org_chunk.name}_split_{idx}",content=sep.join(sentences),type=org_chunk.type,chunk_size=chunk_size,window_length=window_length,**org_chunk.kwargs,)output.append(chunk)return output- strict_length_chunk:严格按长度将内容拆分为块,而不保留句子边界:
def strict_length_chunk(self,org_chunk: Chunk,) -> List[Chunk]:content = org_chunk.contenttotal_length = len(content)output = []position = 0chunk_index = 0while position < total_length:# 计算当前chunk的内容chunk_content = content[position : position + self.split_length]# 创建新的Chunk对象chunk = Chunk(id=generate_hash_id(f"{org_chunk.id}#{chunk_index}"),name=f"{org_chunk.name}_split_{chunk_index}",content=chunk_content,type=org_chunk.type,chunk_size=self.split_length,window_length=self.window_length,**org_chunk.kwargs,)output.append(chunk)# 更新位置和索引position = position + self.split_length - self.window_lengthchunk_index += 1# 确保不会出现负索引if position < 0:position = 0return output- _invoke:根据指定的长度和窗口大小调用输入块的拆分:
- 参数:
- input (Chunk):要拆分的chunk;
- **kwargs:其他关键字参数,当前未使用,但保留以备将来扩展。
- 返回: List[Output],拆分作生成的Chunk对象列表。
- 参数:
def _invoke(self, input: Chunk, **kwargs) -> List[Output]:cutted = []if isinstance(input, list):for item in input:cutted.extend(self.slide_window_chunk(item, self.split_length, self.window_length))else:cutted.extend(self.slide_window_chunk(input, self.split_length, self.window_length))return cutted3.3 extractor
extractor用于从文本中提取实体、关系和事件,并构建知识图谱的子图。
下面是基于架构约束extractor的相关代码,其中:
- 架构约束extractor的功能:执行知识提取以实施架构约束,包括实体、事件及其边缘,实体和事件的类型及其各自的属性会自动从项目的架构继承;
- __init__:构造函数,初始化实例;
- input_types:输入类型为splitter划分的文本块;
- output_types:输出类型为子图;
@ExtractorABC.register("schema_constraint")
@ExtractorABC.register("schema_constraint_extractor")
class SchemaConstraintExtractor(ExtractorABC):def __init__(self,llm: LLMClient,ner_prompt: PromptABC = None,std_prompt: PromptABC = None,relation_prompt: PromptABC = None,event_prompt: PromptABC = None,external_graph: ExternalGraphLoaderABC = None,):super().__init__()self.llm = llmself.schema = SchemaClient(host_addr=KAG_PROJECT_CONF.host_addr, project_id=KAG_PROJECT_CONF.project_id).load()self.ner_prompt = ner_promptself.std_prompt = std_promptself.relation_prompt = relation_promptself.event_prompt = event_promptbiz_scene = KAG_PROJECT_CONF.biz_sceneif self.ner_prompt is None:self.ner_prompt = init_prompt_with_fallback("ner", biz_scene)if self.std_prompt is None:self.std_prompt = init_prompt_with_fallback("std", biz_scene)self.external_graph = external_graph@propertydef input_types(self) -> Type[Input]:return Chunk@propertydef output_types(self) -> Type[Output]:return SubGraph- _named_entity_recognition_llm:调用语言模型,执行命名实体识别:
- 参数:passage,要处理的文本内容;
- 返回值:ner_result:命名实体识别的结果。
def _named_entity_recognition_llm(self, passage: str):ner_result = self.llm.invoke({"input": passage}, self.ner_prompt, with_except=False)return ner_result- _named_entity_recognition_process:对命名实体识别的结果进行去重和整合:
- 参数:
- passage:原始文本内容;
- ner_resulet:命名实体识别的结果。
- 返回值:output,处理后的实体列表,包含唯一的实体信息。
- 参数:
def _named_entity_recognition_process(self, passage, ner_result):if self.external_graph:extra_ner_result = self.external_graph.ner(passage)else:extra_ner_result = []output = []dedup = set()for item in extra_ner_result:name = item.nameif name not in dedup:dedup.add(name)output.append({"name": name,"category": item.label,"properties": item.properties,})for item in ner_result:name = item.get("name", None)category = item.get("category", None)if name is None or category is None:continueif not isinstance(name, str):continueif name not in dedup:dedup.add(name)output.append(item)return output- named_entity_recognition:对给定的文本段落执行命名实体识别:
- 参数: passage (str),要对其执行命名实体识别的文本;
- 返回值: 命名实体识别作的结果。
@retry(stop=stop_after_attempt(3),wait=wait_exponential(multiplier=10, max=60),reraise=True,)def named_entity_recognition(self, passage: str):ner_result = self._named_entity_recognition_llm(passage)return self._named_entity_recognition_process(passage, ner_result)- named_entity_standardization:对给定的文本段落和实体执行命名实体标准化:
- 参数:
- passage (str):文本段落;
- entities (List[Dict]):要标准化的实体列表。
- 返回值:命名实体标准化作的结果。
- 参数:
@retry(stop=stop_after_attempt(3),wait=wait_exponential(multiplier=10, max=60),reraise=True,)def named_entity_standardization(self, passage: str, entities: List[Dict]):return self.llm.invoke({"input": passage, "named_entities": entities},self.std_prompt,with_except=False,)- relations_extraction:对给定的文本段落和实体执行关系提取:
- 参数:
- passage (str):文本段落;
- entities (List[Dict]):实体列表。
- 返回值: 关系提取作的结果。
- 参数:
@retry(stop=stop_after_attempt(3),wait=wait_exponential(multiplier=10, max=60),reraise=True,)def relations_extraction(self, passage: str, entities: List[Dict]):if self.relation_prompt is None:logger.debug("Relation extraction prompt not configured, skip.")return []return self.llm.invoke({"input": passage, "entity_list": entities},self.relation_prompt,with_except=False,)- event_extraction: 对给定的文本段落执行事件提取:
- 参数:passage (str),文本段落;
- 返回:事件提取作的结果。
@retry(stop=stop_after_attempt(3),wait=wait_exponential(multiplier=10, max=60),reraise=True,)def event_extraction(self, passage: str):if self.event_prompt is None:logger.debug("Event extraction prompt not configured, skip.")return []return self.llm.invoke({"input": passage}, self.event_prompt, with_except=False)- parse_nodes_and_edges:从实体列表中解析节点和边:
- 参数:entities (List[Dict]),实体列表;
- 返回:Tuple[List[Node], List[Edge]],解析的节点和边。
def parse_nodes_and_edges(self, entities: List[Dict], category: str = None):graph = SubGraph([], [])entities = copy.deepcopy(entities)root_nodes = []for record in entities:if record is None:continueif isinstance(record, str):record = {"name": record}s_name = record.get("name", "")s_label = record.get("category", category)properties = record.get("properties", {})# 有时,名称和/或标签会放置在属性中。if not s_name:s_name = properties.pop("name", "")if not s_label:s_label = properties.pop("category", "")if not s_name or not s_label:continues_name = processing_phrases(s_name)root_nodes.append((s_name, s_label))tmp_properties = copy.deepcopy(properties)spg_type = self.schema.get(s_label)for prop_name, prop_value in properties.items():if prop_value is None:tmp_properties.pop(prop_name)continueif prop_name in spg_type.properties:prop_schema = spg_type.properties.get(prop_name)o_label = prop_schema.object_type_name_enif o_label not in BASIC_TYPES:# 弹出并将属性转换为节点和边if not isinstance(prop_value, list):prop_value = [prop_value](new_root_nodes,new_nodes,new_edges,) = self.parse_nodes_and_edges(prop_value, o_label)graph.nodes.extend(new_nodes)graph.edges.extend(new_edges)# 将当前节点连接到属性生成的节点for node in new_root_nodes:graph.add_edge(s_id=s_name,s_label=s_label,p=prop_name,o_id=node[0],o_label=node[1],)tmp_properties.pop(prop_name)record["properties"] = tmp_properties# 注意:对于转换为节点/边的属性,我们会保留原始属性值的副本。graph.add_node(id=s_name, name=s_name, label=s_label, properties=properties)if "official_name" in record:official_name = processing_phrases(record["official_name"])if official_name != s_name:graph.add_node(id=official_name,name=official_name,label=s_label,properties=dict(properties),)graph.add_edge(s_id=s_name,s_label=s_label,p="OfficialName",o_id=official_name,o_label=s_label,)return root_nodes, graph.nodes, graph.edges- add_relations_to_graph:根据关系和实体列表向子图添加边:
- 参数:
- sub_graph (SubGraph):要向其添加边的子图;
- entities (List[Dict]): 实体列表,用于查找类别信息;
- relations (List[list]): 一个关系列表,每个关系代表要添加到子图中的一个关系。
- 返回:构造的子图。
- 参数:
@staticmethoddef add_relations_to_graph(sub_graph: SubGraph, entities: List[Dict], relations: List[list]):for rel in relations:if len(rel) != 5:continues_name, s_category, predicate, o_name, o_category = rels_name = processing_phrases(s_name)sub_graph.add_node(s_name, s_name, s_category)o_name = processing_phrases(o_name)sub_graph.add_node(o_name, o_name, o_category)edge_type = to_camel_case(predicate)if edge_type:sub_graph.add_edge(s_name, s_category, edge_type, o_name, o_category)return sub_graph- add_chunk_to_graph:将 Chunk 对象与子图关联,将其添加为节点并将其与现有节点连接:
- 参数:
- sub_graph (SubGraph):要向其添加数据块信息的子图;
- chunk (Chunk):包含文本和元数据的 chunk 对象。
- 返回:构造的子图。
- 参数:
@staticmethoddef add_chunk_to_graph(sub_graph: SubGraph, chunk: Chunk):for node in sub_graph.nodes:sub_graph.add_edge(node.id, node.label, "source", chunk.id, CHUNK_TYPE)sub_graph.add_node(id=chunk.id,name=chunk.name,label=CHUNK_TYPE,properties={"id": chunk.id,"name": chunk.name,"content": f"{chunk.name}\n{chunk.content}",**chunk.kwargs,},)sub_graph.id = chunk.idreturn sub_graph- assemble_subgraph:从给定的 chunk、entities、events 和 relations 中组装一个 subgraph:
- 参数:
- chunk (Chunk):块对象;
- entities (List[Dict]):实体列表;
- events (List[Dict]): 事件列表。
- 返回:构造的子图。
- 参数:
def assemble_subgraph(self,chunk: Chunk,entities: List[Dict],relations: List[list],events: List[Dict],):graph = SubGraph([], [])_, entity_nodes, entity_edges = self.parse_nodes_and_edges(entities)graph.nodes.extend(entity_nodes)graph.edges.extend(entity_edges)_, event_nodes, event_edges = self.parse_nodes_and_edges(events)graph.nodes.extend(event_nodes)graph.edges.extend(event_edges)self.add_relations_to_graph(graph, entities, relations)self.add_chunk_to_graph(graph, chunk)return graph- append_official_name:将正式名称附加到实体:
- 参数:
- source_entities (List[Dict]):源实体的列表;
- entities_with_official_name (List[Dict]):具有正式名称的实体列表。
- 参数:
def append_official_name(self, source_entities: List[Dict], entities_with_official_name: List[Dict]):tmp_dict = {}for tmp_entity in entities_with_official_name:name = tmp_entity["name"]category = tmp_entity["category"]official_name = tmp_entity["official_name"]key = f"{category}{name}"tmp_dict[key] = official_namefor tmp_entity in source_entities:name = tmp_entity["name"]category = tmp_entity["category"]key = f"{category}{name}"if key in tmp_dict:official_name = tmp_dict[key]tmp_entity["official_name"] = official_name- postprocess_graph:通过合并具有相同名称和标签的节点来对图形进行后处理:
- 参数:graph (SubGraph),要后处理的图形;
- 返回:后处理图。
def postprocess_graph(self, graph):try:all_node_properties = {}for node in graph.nodes:id_ = node.idname = node.namelabel = node.labelkey = (id_, name, label)if key not in all_node_properties:all_node_properties[key] = node.propertieselse:all_node_properties[key].update(node.properties)new_graph = SubGraph([], [])for key, node_properties in all_node_properties.items():id_, name, label = keynew_graph.add_node(id=id_, name=name, label=label, properties=node_properties)new_graph.edges = graph.edgesreturn new_graphexcept:return graph- _invoke:在给定的输入上调用提取器:
- 参数:
- input (Input):输入数据;
- **kwargs:其他关键字参数。
- 返回: List[Output],输出结果的列表。
- 参数:
def _invoke(self, input: Input, **kwargs) -> List[Output]:title = input.namepassage = title + "\n" + input.contentout = []entities = self.named_entity_recognition(passage)events = self.event_extraction(passage)named_entities = []for entity in entities:named_entities.append({"name": entity["name"], "category": entity["category"]})relations = self.relations_extraction(passage, named_entities)std_entities = self.named_entity_standardization(passage, named_entities)self.append_official_name(entities, std_entities)subgraph = self.assemble_subgraph(input, entities, relations, events)out.append(self.postprocess_graph(subgraph))logger.debug(f"input passage:\n{passage}")logger.debug(f"output graphs:\n{out}")return out其中,_named_entity_recognition_llm、named_entity_recognition、named_entity_standardization、relations_extraction、event_extraction、_invoke等方法除了上述的同步方法外,还有对应的异步方法。
3.4 vectorizer
vectorizer用于为知识图谱中的节点属性生成嵌入向量,可以增强知识图谱的语义表示,为后续的查询和推理提供支持。
其中,BatchVectorizer用于为SubGraph中的节点属性批量生成嵌入向量的类,通过批量处理提高了效率,并支持同步和异步操作模式。
BatchVectorizer属性:
- project_id (int):与SubGraph关联的工程的ID;
- vec_meta (defaultdict):SubGraph中向量字段的元数据;
- vectorize_model (VectorizeModelABC):用于生成嵌入向量的模型;
- batch_size (int):处理节点的批处理的大小,默认值为 32。
@VectorizerABC.register("batch")
@VectorizerABC.register("batch_vectorizer")
class BatchVectorizer(VectorizerABC):def __init__(self,vectorize_model: VectorizeModelABC,batch_size: int = 32,disable_generation: Optional[List[str]] = None,):super().__init__()self.project_id = KAG_PROJECT_CONF.project_id# self._init_graph_store()self.vec_meta = self._init_vec_meta()self.vectorize_model = vectorize_modelself.batch_size = batch_sizeself.disable_generation = disable_generationdef _init_vec_meta(self):vec_meta = defaultdict(list)schema_client = SchemaClient(host_addr=KAG_PROJECT_CONF.host_addr, project_id=self.project_id)spg_types = schema_client.load()for type_name, spg_type in spg_types.items():for prop_name, prop in spg_type.properties.items():if prop_name == "name" or prop.index_type in [# if prop.index_type in [IndexTypeEnum.Vector,IndexTypeEnum.TextAndVector,]:vec_meta[type_name].append(get_vector_field_name(prop_name))return vec_meta_generate_embedding_vectors:为输入 SubGraph 中的节点生成嵌入向量:
- 参数:input_subgraph (SubGraph),要为其生成嵌入向量的 SubGraph。
- 返回:SubGraph,带有生成的嵌入向量的修改后的 SubGraph。
@retry(stop=stop_after_attempt(3), reraise=True)def _generate_embedding_vectors(self, input_subgraph: SubGraph) -> SubGraph:node_list = []node_batch = []for node in input_subgraph.nodes:if not node.id or not node.name:continueproperties = {"id": node.id, "name": node.name}properties.update(node.properties)node_list.append((node, properties))node_batch.append((node.label, properties.copy()))generator = EmbeddingVectorGenerator(self.vectorize_model, self.vec_meta, self.disable_generation)generator.batch_generate(node_batch, self.batch_size)for (node, properties), (_node_label, new_properties) in zip(node_list, node_batch):for key, value in properties.items():if key in new_properties and new_properties[key] == value:del new_properties[key]node.properties.update(new_properties)return input_subgraph_invoke:调用输入 SubGraph 的嵌入向量的生成:
- 参数:
- input_subgraph (Input):要为其生成嵌入向量的 SubGraph;
- **kwargs:其他关键字参数,当前未使用,但保留以备将来扩展。
- 返回:List[Output],包含修改后的 SubGraph 和生成的嵌入向量的列表。
def _invoke(self, input_subgraph: Input, **kwargs) -> List[Output]:modified_input = self._generate_embedding_vectors(input_subgraph)return [modified_input]3.5 writer
writer用于将子图写入知识图谱存储,在知识图谱构建流程中负责最终的数据持久化。
KGWriter是用于将 SubGraph 写入知识图 (KG) 存储的类。此类继承自 SinkWriterABC,并提供将 SubGraph 写入知识图存储系统的功能,它支持upsert和delete等操作:
class AlterOperationEnum(str, Enum):Upsert = "UPSERT"Delete = "DELETE"@SinkWriterABC.register("kg", as_default=True)
@SinkWriterABC.register("kg_writer", as_default=True)
class KGWriter(SinkWriterABC):def __init__(self, project_id: int = None, delete: bool = False, **kwargs):super().__init__(**kwargs)if project_id is None:self.project_id = KAG_PROJECT_CONF.project_idelse:self.project_id = project_idself.client = GraphClient(host_addr=KAG_PROJECT_CONF.host_addr, project_id=project_id)self.delete = delete@propertydef input_types(self) -> Type[Input]:return SubGraph@propertydef output_types(self) -> Type[Output]:return Noneformat_label:通过添加项目命名空间(如果尚不存在)来设置标签的格式:
- 参数: label (str),需要格式化的标签;
- 返回: str,格式化的标签。
def format_label(self, label: str):namespace = KAG_PROJECT_CONF.namespaceif label.split(".")[0] == namespace:return labelreturn f"{namespace}.{label}"-
standarlize_graph:标准化子图,格式化标签并将非字符串属性转换为JSON字符串:
def standarlize_graph(self, graph):for node in graph.nodes:node.label = self.format_label(node.label)for edge in graph.edges:edge.from_type = self.format_label(edge.from_type)edge.to_type = self.format_label(edge.to_type)for node in graph.nodes:for k, v in node.properties.items():if k.startswith("_"):continueif not isinstance(v, str):node.properties[k] = json.dumps(v, ensure_ascii=False)for edge in graph.edges:for k, v in edge.properties.items():if k.startswith("_"):continueif not isinstance(v, str):edge.properties[k] = json.dumps(v, ensure_ascii=False)return graph_invoke:在图形存储上调用指定的作(upsert 或 delete)。
- 参数:
- input (Input):表示要作的子图的 input 对象;
- alter_operation (str):要执行的作类型(Upsert 或 Delete),默认为 Upsert;
- lead_to_builder (bool):启用潜在客户到事件推断生成器,默认为 False。
- 返回:List[Output],输出对象列表(当前始终为 [None])。
def _invoke(self,input: Input,alter_operation: str = AlterOperationEnum.Upsert,lead_to_builder: bool = False,**kwargs,) -> List[Output]:if self.delete:self.client.write_graph(sub_graph=input.to_dict(),operation=AlterOperationEnum.Delete,lead_to_builder=lead_to_builder,)else:input = self.standarlize_graph(input)logger.debug(f"final graph to write: {input}")self.client.write_graph(sub_graph=input.to_dict(),operation=alter_operation,lead_to_builder=lead_to_builder,)return [input]invoke:处理输入数据并调用_invoke执行写入操作,支持检查点功能:
def invoke(self, input: Input, **kwargs) -> List[Union[Output, BuilderComponentData]]:if isinstance(input, BuilderComponentData):input_data = input.datainput_key = input.hash_keyelse:input_data = inputinput_key = Noneif self.inherit_input_key:output_key = input_keyelse:output_key = Nonewrite_ckpt = kwargs.get("write_ckpt", True)if write_ckpt and self.checkpointer:# found existing data in checkpointerif input_key and self.checkpointer.exists(input_key):return []# not foundoutput = self._invoke(input_data, **kwargs)# We only record the data key to avoid embeddings from taking up too much disk space.if input_key:self.checkpointer.write_to_ckpt(input_key, input_key)return [BuilderComponentData(x, output_key) for x in output]else:output = self._invoke(input_data, **kwargs)return [BuilderComponentData(x, output_key) for x in output]_handle:为 SPGServer 提供的调用接口:
- 参数:
- input (Dict):表示要作的子图的输入字典;
- alter_operation (str):要执行的作类型(Upsert 或 Delete);
- **kwargs:其他关键字参数。
- 返回:None,此方法当前返回 None。
def _handle(self, input: Dict, alter_operation: str, **kwargs):_input = self.input_types.from_dict(input)_output = self.invoke(_input, alter_operation) # noqareturn None3.6 可选组件
除了上述的常用组件外,KAG-Builder还提供一些可选组件,例如:
- post_processor:对构建好的知识图谱进行后处理,如数据清洗、格式转换、质量评估等;
- mapping:实现不同数据源、不同格式之间的映射和转换;
- scanner:对数据进行快速扫描和预处理,识别数据中的关键信息和结构;
- external_graph:用于与外部知识图谱进行交互和融合,可以导入或导出知识图谱数据。
4 示例
如下图所示:
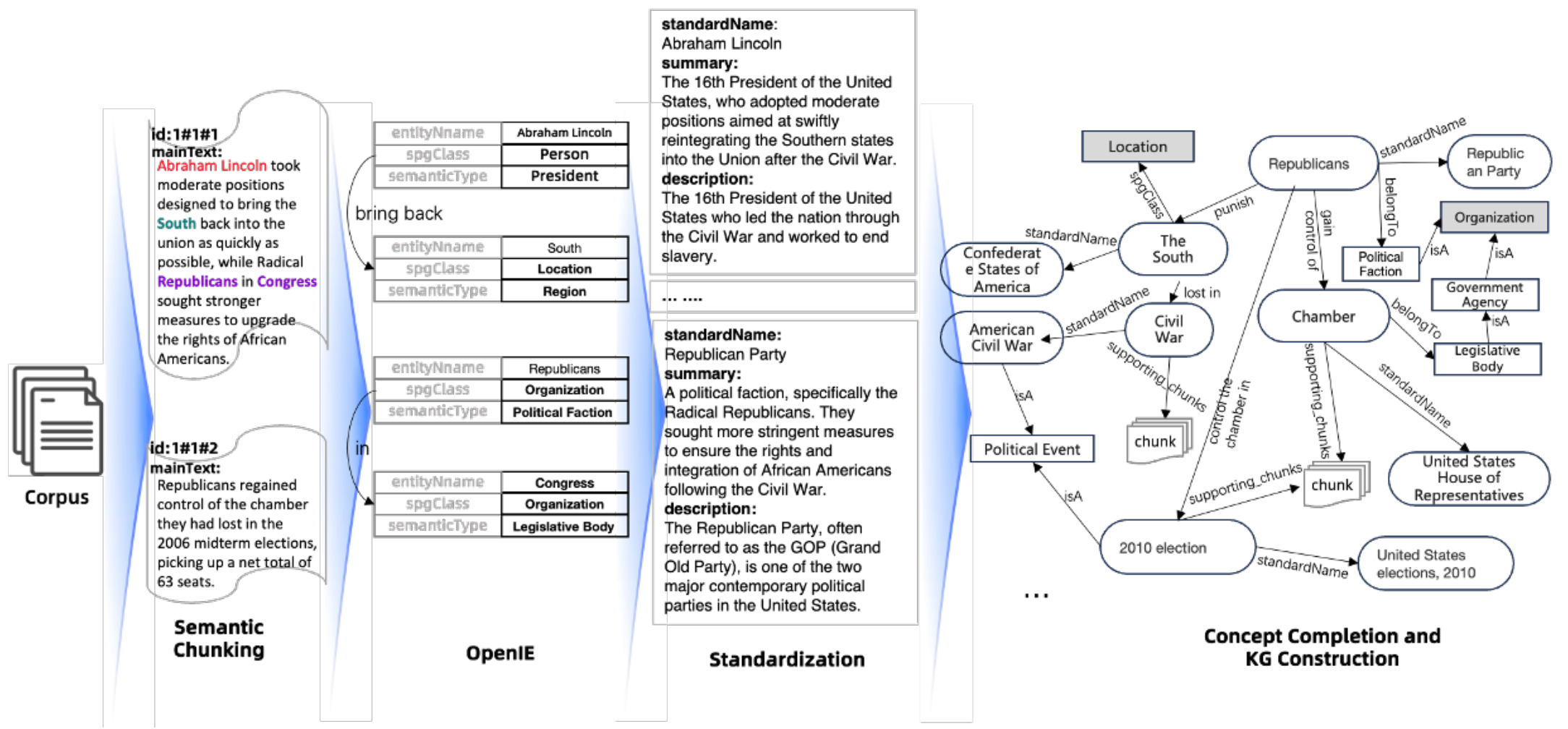
当给KAG一个txt的文本文件,
- 首先,reader将这个文件读入chunk中,例如:
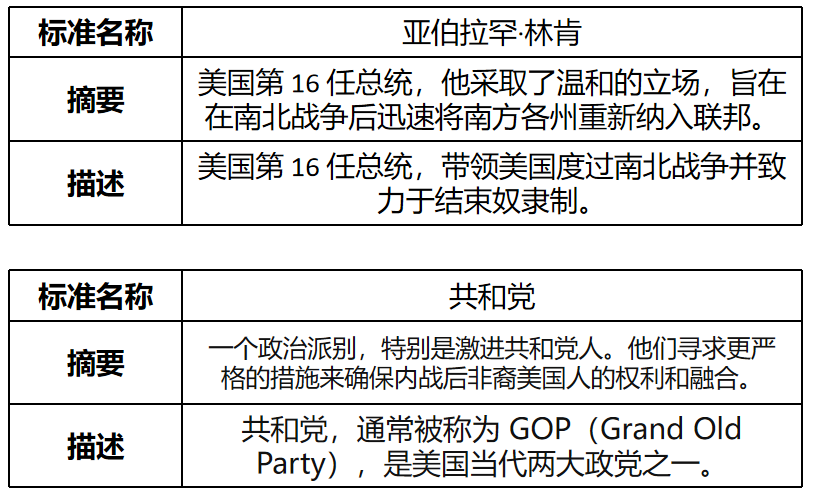
亚伯拉罕·林肯采取了温和的立场,旨在尽快使南方回归联邦,而国会中的激进共和党人则寻求更强有力的措施来提升非裔美国人的权利。共和党重新夺回了他们在2006年中期选举中失去的众议院控制权,净增了63个席位。
- splitter再将这个大chunk,分为更小的chunk:
亚伯拉罕·林肯采取了温和的立场,旨在尽快使南方回归联邦,而国会中的激进共和党人则寻求更强有力的措施来提升非裔美国人的权利。
共和党重新夺回了他们在2006年中期选举中失去的众议院控制权,净增了63个席位。
- 然后,由extractor进行信息提取,从切分后的文本中提取实体、关系等知识图谱的核心元素:
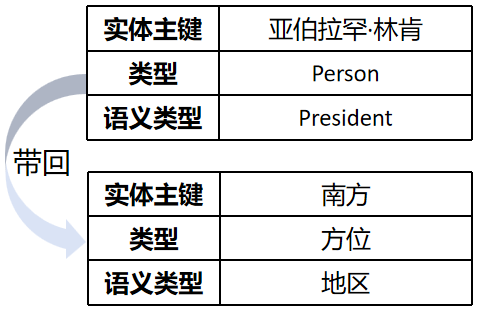
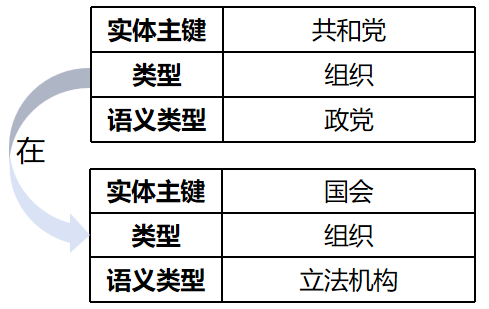
- 再由aligner进行知识对齐,将提取器结果与语义架构标准化对齐,包括文档语义对齐和概念语义图对齐:
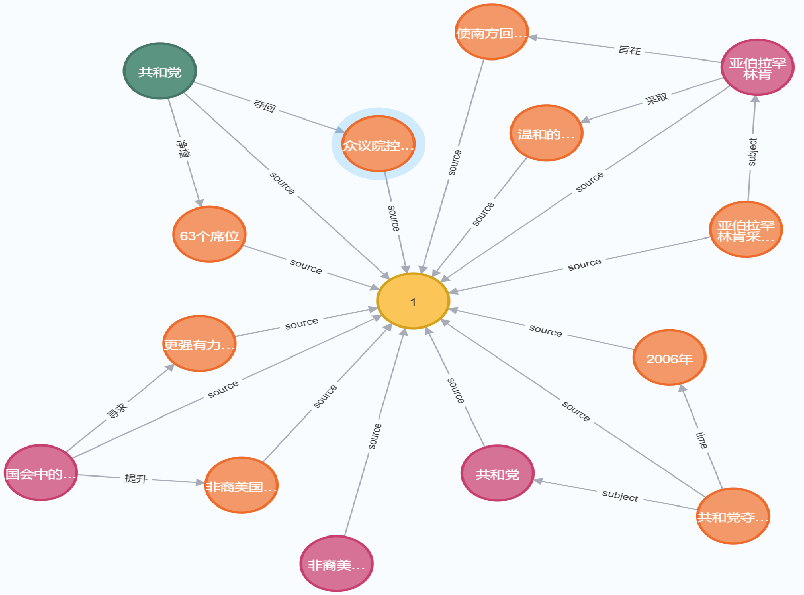
- 最后,vectorizer将结果向量化,再由writer进行图谱写入,将子图写入图存储数据库:
总结
通过对 Schema、Prompt 以及 KAG-Builder 的学习,我对知识图谱构建过程中的数据定义、语言模型引导和构建流程管理有了更深入的理解:
- Schema是定义知识图谱语义框架和数据组织结构的核心组件,Schema 是知识图谱的架构定义,它描述了实体和关系的类型及其属性。
- Prompt 是自然语言处理任务中用于引导模型生成符合预期输出的模板。在 KAG项目中,Prompt 被广泛应用于各种任务,如命名实体识别(NER)、关系抽取、事件抽取等。通过设计合适的 Prompt,可以有效地指导语言模型理解任务要求并生成准确的结构化输出。
- KAG-Builder 是 KAG 项目中用于构建知识图谱的核心组件,它由多个功能模块组成,包括 Reader(读取器)、Splitter(切分器)、Extractor(提取器)、Vectorizer(向量化器)、PostProcessor(后处理器)和 Writer(写入器)。这些模块通过构建链(Builder Chain)连接成一个完整的工作流程,负责从数据读取到知识图谱构建的全过程。







进行简单服务端与客户端通信)

显存管理)
/ 曹冲养猪)

·消息队列)


)
)


