参考视频:1小时速通 - 从强化学习到RLHF - 简介_哔哩哔哩_bilibili
强化学习RL
RL的核心就是智能体Agent 与 环境Environment的交互。
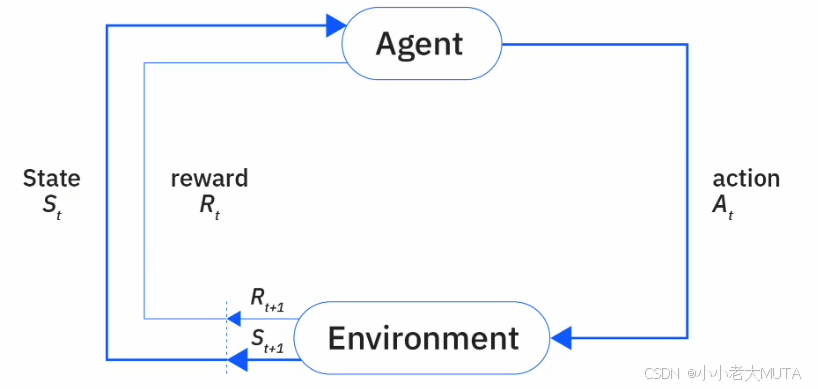
- 状态(State,s):环境在某一时刻的描述,表示当前情境。
- 动作(Action,a):智能体基于状态做出的选择或行为。
- 奖励(Reward,r):环境对智能体动作的反馈,用于评价动作好坏。
- 策略(Policy,π):智能体选择动作的策略,通常是状态到动作的映射函数。
- 价值函数(Value Function):评估某一状态或状态-动作对的长期价值,帮助智能体判断哪些状态或动作更有利。
- 环境转移概率(Transition Probability):环境状态转移的概率分布,描述给定当前状态和动作后,环境变到下一个状态的可能性。
RL的核心目标就是:学习一个最优策略π*,最大化从当前时刻开始未来累计获得的奖励期望,通常表示为最大化期望折扣累计奖励:
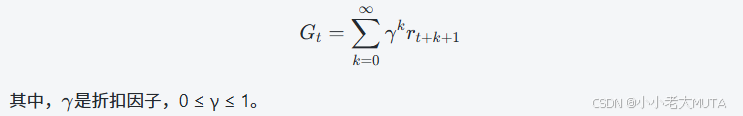
整体训练流程
初始化:
初始化环境,设定初始状态 s0。
初始化策略π(例如随机策略)及价值函数。
交互采样(采集经验):
智能体根据当前状态 stst 和策略 π 选择动作 atat。
环境根据动作执行,反馈奖励 rt+1 和下一个状态 st+1。
智能体将元组 (st,at,rt+1,st+1)存入经验池(某些算法使用)。
策略和价值函数更新:
根据采集的经验,智能体调整策略和/或价值函数,以更好地预测未来奖励,改进决策。
迭代训练:
重复交互采样和参数更新过程,通过不断试错和学习,策略逐渐完善,智能体表现提升。
终止条件:
达到预设的训练步数或收敛标准。
智能体学习到满意的最优或近似最优策略。
动态规划Dynamic Prigramming
动态规划是传统RL的一种经典方法。
动态规划方法是假设环境模型完全一致,也就是假设转移概率函数 p(s′,r∣s,a) 是已知的,即:
给定当前状态 s 和动作 a,我们完全知道环境转移到下一个状态 s′ 并获得奖励 r 的概率分布。
RL的目标是希望Agent能够去到获得奖励 r 高的状态或动作。这意味着,智能体要了解当前策略下哪些状态或动作的奖励较高,并且逐步改进策略,选择那些能带来更大奖励的路径。
智能体通过评估当前策略的价值,知道“哪里好”,然后调整策略,去“更好”的地方。
DP的核心步骤
策略评估(Policy Evaluation)
- 计算当前策略在各个状态下的价值函数(Value Function),即在遵循该策略时从该状态开始能期望获得的累计回报。
- 这一步是利用环境的转移概率和奖励函数,通过贝尔曼期望方程迭代求解或解析计算得到。
策略改进(Policy Improvement)
- 根据策略评估得到的价值函数,调整策略使其更优:在每个状态选择那个能获得最大价值的动作,即让策略“去到有最大价值的地方”。
- 这一步保证策略在每次改进后都是更好的。
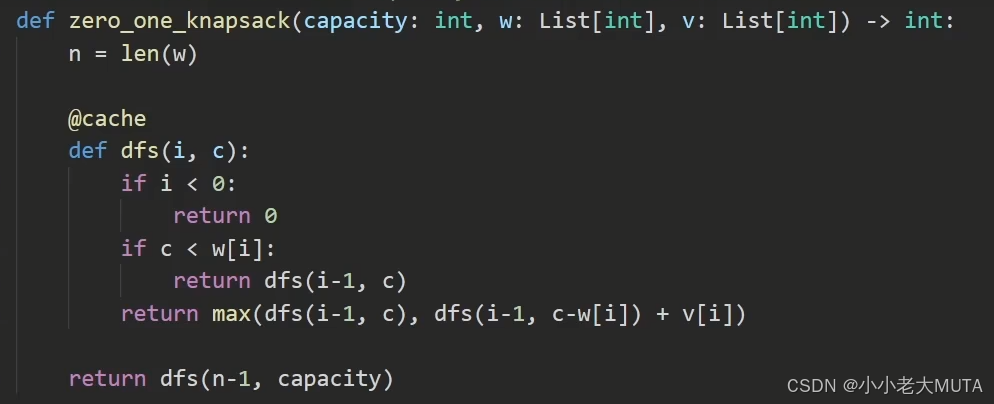
和01背包问题的关联
最近在刷leecode算法题,一看到DP就想到了01背包。

dp[i][w]=前i个物品,在容量为w的情况下的最大价值
- 通过递推式(状态转移方程)逐步求解,最终得到最优解。
- 这个动态规划过程是确定性和静态的,状态转移和价值计算都是确定的,没有涉及概率或环境交互。
DP数组的写法:
def zero_one_knapsack(capacity: int, w: List[int], v: List[int]) -> int:n = len(w)# dp[i][c] 表示前 i 个物品(0-based),容量为 c 时的最大价值dp = [[0] * (capacity + 1) for _ in range(n)]# 初始化第一件物品(i=0)的状态for c in range(w[0], capacity + 1):dp[0][c] = v[0]# 状态转移for i in range(1, n):for c in range(capacity + 1):if c < w[i]:dp[i][c] = dp[i-1][c]else:dp[i][c] = max(dp[i-1][c], dp[i-1][c - w[i]] + v[i])return dp[n-1][capacity]递归的写法:
RL中的DP用来求解最优策略,考虑的是决策过程中的状态转移和奖励,但状态转移和奖励是随机性的,由环境模型 p(s′,r∣s,a) 给出。
这里的动态规划不只是单纯求最大价值,而是求解贝尔曼方程,计算状态价值函数 Vπ(s),然后基于价值函数进行策略改进。
动态规划的核心是利用状态转移概率和奖励函数的期望来迭代计算价值函数,这是一个多阶段的序贯决策问题,状态和动作之间的转移关系类似于马尔可夫决策过程(MDP)的框架,而不只是单纯的一维或二维数组转移。
通过贝尔曼方程表达状态价值函数
状态价值函数 vπ(s) 表示在策略 π 下,从状态 s 开始,未来能够获得的期望累计奖励(通常带折扣因子)的期望值:

贝尔曼方程用递归的形式表达vπ(s):
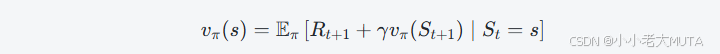
当前状态的价值等于:从当前状态采取策略 π 选择动作得到的即时奖励 Rt+1,加上折扣后的下一状态的期望价值 vπ(St+1)。
这个地方可以通过01背包的递归写法理解。

贝尔曼方程假设了已知环境动态(转移概率和奖励分布),也就是已知从当前状态s,采取动作a后转移到下一个状态s′并获得奖励r的概率。
贝尔曼方程成立的“理想环境”是指:
状态转移概率、奖励完全已知
环境严格满足马尔可夫性(状态转移只依赖当前状态和动作,不依赖历史)
状态/动作空间有限且可遍历
奖励函数明确
在现实强化学习场景中,这些条件往往难以全部满足:
- 环境模型未知:无法直接计算 p(s′,r∣s,a)。
- 状态空间巨大甚至连续,无法穷举。
- 状态观测不完全或环境非马尔可夫。
所以我们用贝尔曼方程作为理论基础,但算法上常常采用采样、逼近、估计等方式处理。
- Monte Carlo Methods
- Q-learning
- Temporal Difference (TD)
- Policy Gradient / REINFORCE algorithm
Policy Gradient策略梯度方法
用贝尔曼方程表达状态价值函数进而求解最大化期望折扣累计奖励的策略。
但是贝尔曼方程满足需要的条件很难达到,所以有了很多其他策略。
策略梯度方法是直接以最大化期望累计回报为目标,通过对策略参数进行优化,计算目标函数关于策略参数的梯度,并用梯度上升法更新。
实现直接优化策略而不是“间接”通过估计值函数。
策略梯度方法分为:
- 纯策略梯度法(如REINFORCE)只用采样的奖励,不显式用贝尔曼方程。
- 高级策略梯度法(如Actor-Critic、A2C、A3C等)会引入价值函数(critic),用贝尔曼方程逼近(如TD误差),减少方差、提升效率。
策略梯度公式通常如下:
![]()
- 其中 Qπ(s,a)就是贝尔曼方程定义的动作价值函数,它的准确估计往往依赖贝尔曼方程或其近似(如用TD方法估计)。
RL in LLMs
LLM问题的RL形式:
这部分内容的核心是:把语言模型的生成过程看作一个马尔可夫决策过程(MDP),用强化学习框架进行建模和优化。
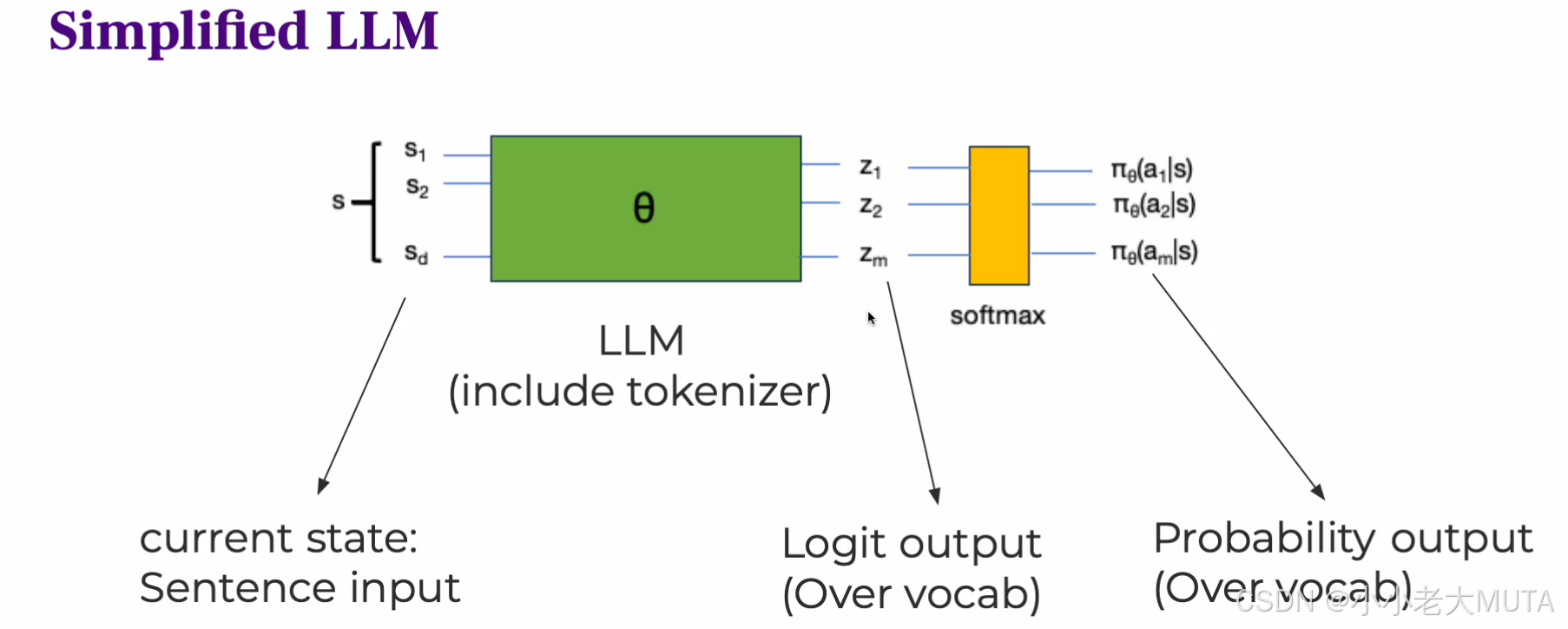

状态state
- 初始状态 S0 是提示词(prompt),即输入给模型的上下文。
- 随着生成过程,状态不断更新,StS表示当前提示词 + 已生成的所有token,也就是说状态包含了从初始到当前时间步生成的全部信息,作为决策依据。
动作空间action space
- 动作空间是词汇表(vocabulary),每一步动作是从词汇表中选择一个token。
- 动作 At 是在时间步 t 生成的具体token。
策略Policy
- 策略是模型的输出概率分布,也就是大语言模型(LLM)在给定当前上下文 St 时,生成下一个token At 的概率。
- 用参数 θ 表示模型的参数(比如transformer的权重)。
- 通过softmax把模型的logit 输出 zi 转化为概率。
回合终止(Episode end)
-
当生成了特殊token
<|end of text|>时,回合结束。 -
整个生成过程视为一个完整的episode。
奖励Reward
- 假设对每个生成的完整句子都能得到一个奖励信号(比如从人类反馈得到的评分,或者自动指标)。
- 强化学习目标是最大化期望累计奖励。
| 组成要素 | 对应RL元素 | 说明 |
|---|---|---|
| Prompt + 已生成tokens | 状态 St | 当前上下文,全信息 |
| Token vocabulary | 动作空间 A | 每步选择一个token作为动作 |
| 生成下一个token的概率分布 | 策略 πθ | LLM输出的softmax概率分布 |
| 生成过程 | Episode | 直到结束token,构成一个完整episode |
| 句子质量评价 | 奖励函数 R | 反馈生成句子的好坏,指导学习 |
RLHF 基于人类反馈的强化学习
RLHF是在强化学习框架中引入人类反馈作为奖励信号的强化学习方法。
通过人类专家或用户对智能体行为的评价(正向或负向反馈),来训练或指导策略,使其行为更符合人类期望。
| 方面 | 强化学习(RL) | 基于人类反馈的强化学习(RLHF) |
|---|---|---|
| 奖励信号来源 | 预定义的环境奖励函数(明确、可计算) | 不直接用环境奖励,奖励来自人类反馈训练的奖励模型 |
| 目标 | 最大化环境定义的累积奖励 | 最大化符合人类偏好的累积奖励 |
| 训练过程 | 智能体与环境交互,用环境奖励更新策略 | 智能体与环境交互,用人类反馈训练的奖励模型指导策略 |
| 适用场景 | 多用于有明确目标和环境反馈的问题 | 多用于人类主观评价难以明确表达的任务,如文本生成 |
| 关键挑战 | 设计合适的奖励函数 | 收集高质量的人类反馈,训练准确的奖励模型 |
RLHF的整体流程:
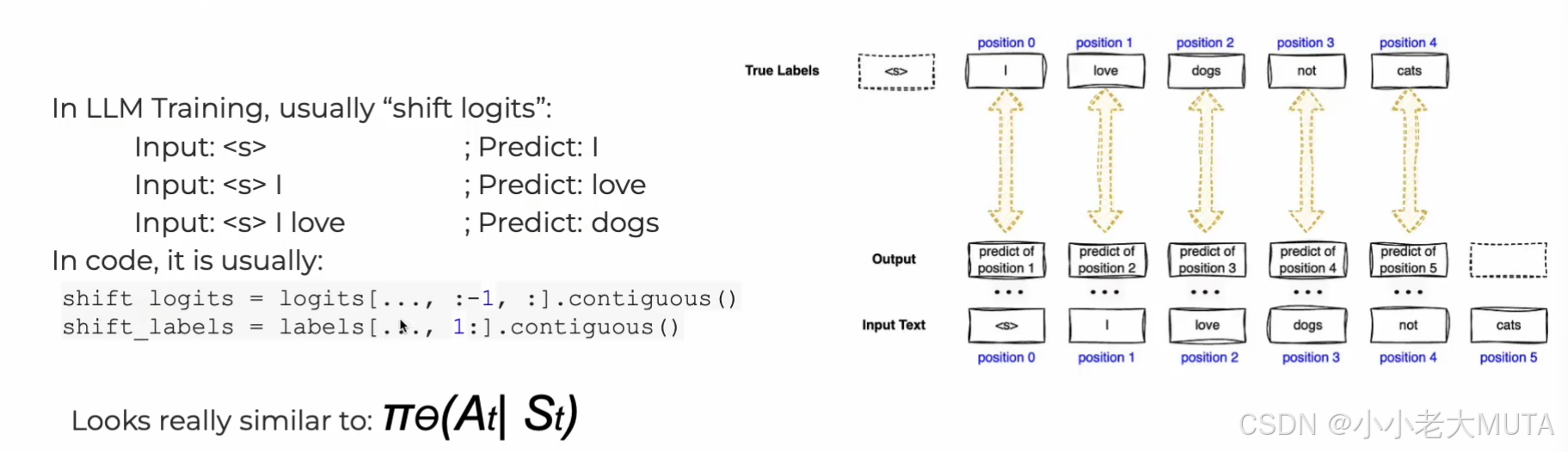
1. 监督微调(Supervised Fine-Tuning,SFT)
目的:通过有标注的示例(人类书写的示范回答)对基础预训练模型进行微调。
步骤:
- 收集大量人类撰写的问答对(Prompt + 理想回答)。
- 使用监督学习(最大似然估计)训练模型生成更符合人类示范风格的回答。
结果:模型初步具备生成较高质量回答的能力。
如上图,整个流程就像是给定之前的单词(state),预测下一个单词(action)
训练:
<prompter>表示提问者(用户)的身份角色。<assistant>表示回答者(模型)的身份角色。<|endoftext|>表示这条对话的结束。推理:模型从
<assistant>开始,预测接下来合理的回答内容。
2. 训练奖励模型(Reward Model,RM)
目的:从人类反馈数据中训练一个模型,能够给模型生成的回答打分,表示人类对回答的偏好程度。
步骤:
- 收集大量人类评分数据,通常是偏好对比:给出两个模型回答,让人类选择更好的那个。(偏好数据)
- 训练奖励模型,使其能对任意回答给出一个“奖励分数”,反映人类偏好。
模型:奖励模型通常是基于基础语言模型的编码器+回归头,输出一个标量分数。
意义:这个模型是RL训练阶段的“代理奖励函数”,替代难以明确定义的人工奖励。
采用对比学习的思想,定义损失函数:
- rϕ(x,y) 是奖励模型对输入-回答对的评分。
- σ 是sigmoid函数,将分数差转换成概率。
- 期望是对数据集中的所有偏好对进行平均。
直观理解:鼓励奖励模型给更优回答更高分,使得 rϕ(x,yw)>rϕ(x,yl)。
3. 基于奖励模型的强化学习(Policy Optimization)
目的:用强化学习算法,以奖励模型的评分为优化目标,进一步提升模型策略。
技术细节:
- 使用策略梯度算法,如PPO(Proximal Policy Optimization)。
- 训练时,智能体(语言模型)采样回答,奖励模型给出评分,策略据此调整参数。
限制:同时用KL散度约束限制新策略与原策略差异,保证稳定性防止过拟合奖励模型。
结果:模型输出更符合人类偏好、质量更高、更安全。
RLHF中的策略优化(Policy Optimization)方法
在RLHF中,第三步,用强化学习算法,以奖励模型的评分为优化目标,调整参数。
这中间的优化过程,就需要使用一些策略优化算法。
经典方法如下:
| 方法 | 关键点 | 备注 |
|---|---|---|
| PPO | 稳定性强,利用Critic和Advantage | OpenAI主流选择 |
| GRPO | 基于组内相对表现,KL约束 | 适合多策略协作 |
| DPO | 无需奖励模型,直接优化偏好数据 | 简化训练流程 |
PPO(Policy Proximity Optimation)
这部分公式推导详看:
PPO原理详解 | 公式推导-CSDN博客
PPO的训练过程(伪代码)-CSDN博客
PPO的核心思想就是:
优化新策略时,不要让其与旧策略差异过大(Proximity),保持“接近性”以保证稳定和安全。
Proximity 指的是:每次策略更新时,限制新策略和旧策略之间的变化幅度。
如果策略变化太大,可能会导致模型行为不稳定或者性能急剧下降。因此,PPO用剪切(clipping)或KL散度等技术来约束策略更新。
PPO-Clip的算法流程

输入:
- 初始策略参数 θ0
- 初始价值函数参数 ϕ0 (价值函数用于评估当前状态/动作的“好坏”,为优势函数计算提供依据)
主循环:


- Importance sampling:通过概率比校正数据分布,兼容on-policy和小范围off-policy。
- Advantage:策略更新主导方向。
- Clip函数:保证邻近性,训练稳定。

RL-->RLHF-->PPO
RL:在传统强化学习中,通过最大化累计奖励,也就是价值函数,进而优化策略函数。
RLHF:通过引入奖励模型,给模型输出进行打分,从而量化模型输出的好坏。奖励模型替代了RL中环境真实奖励,通过最大化模型评分,直接优化策略函数。
如果是直接纯策略梯度例如Reinforce方法,就没有价值函数;如果是高级策略梯度法(如Actor-Critic)会引入价值函数(critic),减少策略梯度方差,用贝尔曼方程逼近(如TD误差)。
PPO:在RLHF的基础上,为了提升训练的问题,首先引入了clip或者KL散度,保证了每次策略更新幅度有限,不要离旧策略太远。然后优化策略使用的actor-critic,所以实质上还是通过引入价值函数的策略优化方法,去优化奖励模型,从而优化策略函数。
在策略梯度更新的过程中,原本是最大化奖励,为了训练的问题,引入了基线,这个过程合并成了优势函数(奖励-当前策略期望获得的累计回报)。
而优势函数通过一系列变换,其实可以用价值函数表示。
所以整体本质上, PPO是在优化价值函数和奖励函数,进而优化策略函数。
-
RLHF = RL + 人工奖励模型
-
PPO = 为RLHF设计的稳定策略优化算法
-
Actor-Critic + PPO clip机制 = 高效且稳定的策略训练
-
优势函数 = 价值函数和奖励信号结合的关键桥梁
这里有一个很容易理解错误的点就是,其实RL中所指的价值函数和PPO中所致的价值函数不完全一致:
虽然他们的定义和数学意义是一样的,都是期望累计回报函数:
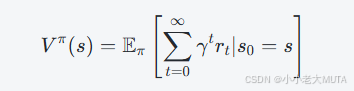
但是两者的用途和训练方式有所不同:
- 传统RL中,价值函数是策略改进过程中的中间环节,主要用来评价策略。
- Actor-Critic中,价值函数是辅助网络,主要作用是平滑策略梯度,降低方差,并通过与Actor协同训练实现策略优化。
Actor-Critic策略梯度方法
Actor-Critic是RL中一种兼具策略优化和价值i评估的“策略梯度方法”,结合了两类方法的优点:
- Actor(策略网络):负责决策,输出在每个状态下采取各个动作的概率(策略),参数记为 θ;
- Critic(价值网络):负责评估当前策略的好坏,估算当前状态的价值(或状态-动作价值),参数记为 ϕ。
Critic负责“评分”,Actor负责“改进行为”。
原理:
强化学习的目标是最大化期望累计回报,策略梯度法是直接对策略参数求导来求得最大期望累计回报的参数。
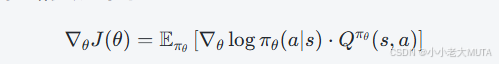
直接用实际回报![]() 估计会有很大的方差,训练不稳定,价值函数就用来降低方差(就是baseline),也就是用价值函数来表达优势函数。
估计会有很大的方差,训练不稳定,价值函数就用来降低方差(就是baseline),也就是用价值函数来表达优势函数。
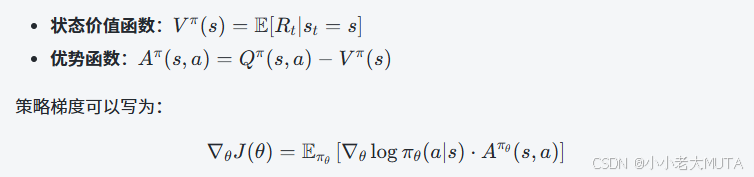
所以Actor-Critic结构就是:
- Actor:输出策略 πθ(a∣s)(通常是softmax或高斯分布参数)。
- Critic:估算 Vϕ(s) 或 Qϕ(s,a)。
Critic帮助估算优势函数(Advantage),指导Actor的更新。
伪代码如下:
for iteration in range(total_iterations):# 1. 用当前策略与环境交互,收集经验(batch)batch = collect_experience(policy=actor, env=env)# 2. 更新Criticfor (s_t, a_t, r_t, s_{t+1}) in batch:target = r_t + gamma * V_phi(s_{t+1})loss_C = (V_phi(s_t) - target) ** 2Critic优化(loss_C, phi)# 3. 计算优势Advantage = target - V_phi(s_t)# 4. 更新Actorloss_A = -log_pi_theta(a_t | s_t) * AdvantageActor优化(loss_A, theta)
Crtic价值函数的更新:
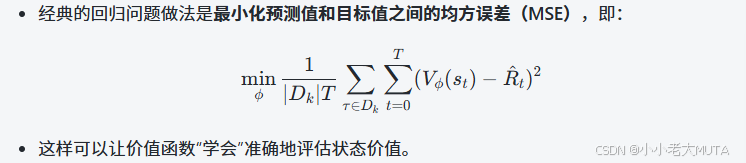
GRPO (Group Relative Policy Optimization)
GRPO是在PPO基础上的一种改进,重点在于将奖励和优势函数的计算基于一组(group)内部的归一化比较,而不是全局的绝对奖励。这在某些任务中,比如多样本、多目标、多任务的情形,能缓解奖励尺度不一致的问题,增强训练稳定性和泛化能力。
将PPO 和 GRPO 两个目标函数公式放在一起对比:
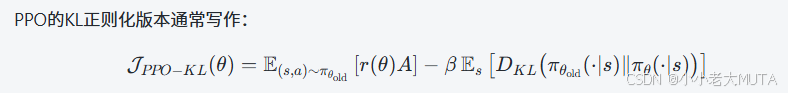




GPRO在PPO的基础上,做了以下改动:
1. 多输出组优化:一次采样一组大小为G的输出 {oi},对组内平均目标求期望。
2. 优势函数Ai采用组内奖励归一化:
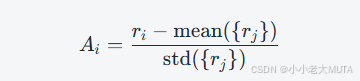
我们对比PPO 和 GRPO的公式发现,PPO 只是用了一个正则化手段,要是是KL散度要么是Clip(Clip用的最多);但是在GRPO公式中,既有Clip又有KL散度计算。Why?
- clip机制的作用:限制单步策略概率比
在 [1−ϵ,1+ϵ] 范围内波动,防止策略在某一步骤骤变。
- KL散度的作用:直接限制新旧策略整体分布的差异,理论上更严谨、整体更稳定,但计算和调控相对复杂。
GRPO中的设计:
- clip裁剪:对单个输出的概率比进行限制,防止单个输出概率跳变过大。
- KL散度正则:对整个策略分布(针对组输出)进行整体正则,控制新策略与参考策略(不一定是旧策略)之间的分布差异。
GRPO针对的是多输出组的采样和优化,优势函数是组内归一化相对优势,这带来:
- 奖励尺度和样本间差异更复杂,clip限制单个样本的局部更新幅度,防止极端概率比出现。
- 整体策略分布的控制更加关键,KL散度限制策略整体分布的更新幅度,防止整体策略迁移过大。
DPO Direct Preference Optimization
这部分公式推导可详看:DPO原理 | 公式推导-CSDN博客
DPO的核心思想:直接优化模型生成结果的偏好概率,不依赖传统单独训练的奖励模型。
LLM本身被“隐式”视为奖励模型,模型直接通过人类偏好数据来调整生成策略。
其目标是最大化模型生成更偏好输出的概率,相当于“最大化偏好的对数似然”。
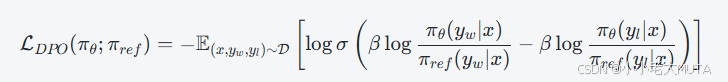

公式含义
- 计算当前模型生成优选输出跟参考模型生成优选输出的对数概率比,减去对应的劣选输出的对数概率比。
- 通过Sigmoid函数,将该差异转化为一个概率值,表示当前策略更偏好生成 yw而非 yl 的置信度。
- 对数之后取负期望,等价于最大化“当前模型在偏好对上的正确排序概率”,即训练模型使其更倾向于生成被偏好的输出。






Spring Cloud Alibaba 2023.x:微服务接口文档统一管理与聚合)

)
,Y Pos(Y位置))
)








