引言:
- 本文总字数:约 8500 字
- 建议阅读时间:35 分钟
当订单表撑爆数据库,我们该怎么办?
想象一下,你负责的电商平台在经历了几个双十一后,订单系统开始频繁出现问题:数据库查询越来越慢,甚至在高峰期出现超时;运维团队每天都在抱怨数据库服务器负载过高;营销部门的数据分析报告总是延迟,因为全表扫描需要数小时。
这不是危言耸听,而是每个快速发展的业务都会面临的真实挑战。根据 MySQL 官方文档(https://dev.mysql.com/doc/refman/8.0/en/table-size-limit.html),单表数据量超过 1000 万行时,性能会显著下降。而对于订单表这种写入密集、查询频繁的核心业务表,这个阈值可能还要低得多。
分表分库(Sharding)技术正是解决这个问题的关键。它通过将一个大表的数据分散到多个小表、多个数据库中,从而提升系统的并发能力和查询效率。本文将从理论到实践,全方位解析订单表分表分库的设计与实现,让你不仅能理解其底层逻辑,更能直接应用到实际项目中。
一、分表分库核心概念:你必须理解的基础知识
1.1 什么是分表分库?
分表分库是一种数据库水平扩展技术,主要包括两种方式:
- 分表(Table Sharding):将一个大表按照某种规则拆分成多个小表,这些小表可以在同一个数据库中,也可以分布在不同的数据库中。
- 分库(Database Sharding):将一个数据库按照某种规则拆分成多个数据库,每个数据库可以部署在不同的服务器上。
用一个形象的比喻:如果把数据库比作仓库,表比作货架,那么分表就像是把一个长货架拆分成多个短货架,分库则是把一个大仓库分成多个小仓库。
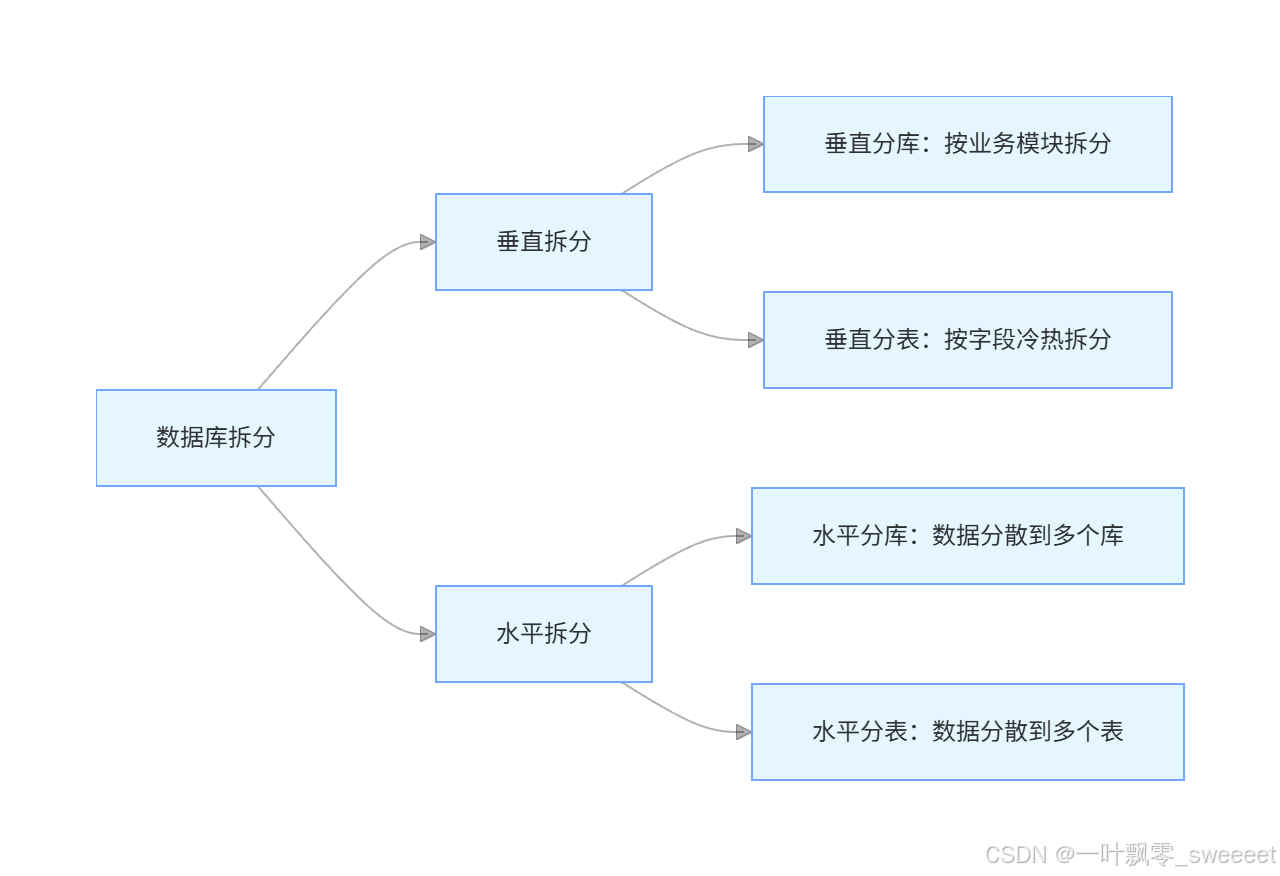
1.2 垂直拆分 vs 水平拆分
分表分库可以分为垂直和水平两种拆分策略:
-
垂直拆分:按照业务或数据的重要性进行拆分
- 垂直分库:将不同业务模块的数据拆分到不同的数据库,如订单库、用户库、商品库
- 垂直分表:将一个表中不常用的字段拆分到另一个表,如订单表中的基本信息和详细信息分离
-
水平拆分:按照某种规则将同一业务的数据分散存储
- 水平分库:将同一表的数据拆分到多个数据库
- 水平分表:将同一表的数据拆分到同一数据库的多个表中
对于订单表,我们通常采用水平拆分,因为订单数据具有天然的可拆分性,且随着业务增长,数据量会持续增加。
1.3 分表分库的优势与挑战
优势:
- 提升查询性能:小表的查询速度远快于大表
- 提高并发能力:分散到多个数据库,可同时处理更多请求
- 便于扩容:可以按需增加数据库服务器
- 提高可用性:单个库表故障不会导致整个系统不可用
挑战:
- 分布式事务:跨库操作需要特殊处理
- 跨库查询:JOIN 操作变得复杂
- 数据迁移:扩容时需要迁移数据
- 全局 ID:需要生成唯一的全局标识符
- 运维复杂度:管理多个库表增加了运维难度
二、订单表分表分库设计:从理论到方案
2.1 拆分策略选择:为什么订单表适合按时间和用户 ID 拆分?
订单表的拆分策略需要结合业务查询模式。常见的拆分键(Sharding Key)选择有:
- 按用户 ID 拆分:适合需要查询某个用户所有订单的场景
- 按订单创建时间拆分:适合按时间范围查询的场景,如月度报表
- 按订单 ID 哈希拆分:数据分布均匀,但时间范围查询困难
对于大多数电商平台,我们推荐复合策略:先按时间范围(如月份)拆分,再在每个时间范围内按用户 ID 哈希拆分。这样既满足了按用户查询的需求,也方便了按时间归档数据。
阿里巴巴《Java 开发手册(嵩山版)》中明确建议:"分库分表时,拆分字段的选择至关重要,需要结合业务查询场景,尽量避免跨库跨表查询。"
2.2 分表分库粒度:多少数据量一个表合适?
单表数据量的阈值需要根据业务场景和硬件配置来确定,通常有以下参考:
- 并发查询较多的表:建议单表数据量控制在 500 万以内
- 以插入和简单查询为主的表:可以放宽到 1000 万 - 2000 万
订单表作为核心业务表,查询复杂且频繁,建议单表数据量控制在 500 万以内。根据预估的年订单量,可以计算出需要的表数量:
例如,若预计年订单量为 1 亿,单表 500 万,则每年需要 20 个表。如果按月份拆分,每月大约需要 2 个表,这意味着每个月内还需要再按用户 ID 进一步拆分。
2.3 数据库和表的命名规范
清晰的命名规范有助于维护和排查问题,建议如下:
- 分库命名:
order_db_${时间标识}_${分片序号}- 示例:
order_db_202310_00(2023 年 10 月的第 00 号订单库)
- 示例:
- 分表命名:
order_tbl_${时间标识}_${分片序号}- 示例:
order_tbl_202310_01(2023 年 10 月的第 01 号订单表)
- 示例:
时间标识可以是年份(如 2023)、年份 + 季度(如 2023Q4)或年份 + 月份(如 202310),根据数据量和查询频率选择合适的粒度。
2.4 全局 ID 生成策略
分表分库后,传统的自增 ID 无法保证全局唯一,需要全局 ID 生成策略:
- UUID/GUID:优点是简单,缺点是无序、占空间大
- 雪花算法(Snowflake):64 位 ID,包含时间戳、机器 ID 等,有序且唯一
- 数据库自增 ID 表:单独的数据库表生成 ID,可能成为瓶颈
- Redis 自增:利用 INCR 命令,性能好但依赖 Redis
对于订单 ID,推荐使用雪花算法,因为它生成的 ID 有序,有利于索引性能,且包含时间信息,便于定位数据所在的分片。
三、分表分库中间件选型:ShardingSphere 实战
3.1 主流分表分库中间件对比
目前主流的分表分库中间件有:
| 中间件 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| ShardingSphere | 功能全面,支持多种数据库,社区活跃 | 配置复杂 | 大多数企业级应用 |
| MyCat | 基于 MySQL 协议,透明接入 | 对新特性支持较慢 | 以 MySQL 为主的应用 |
| DRDS | 阿里云产品,运维简单 | 商业化,成本高 | 阿里云生态用户 |
Apache ShardingSphere(Apache ShardingSphere)是目前最受欢迎的开源分表分库解决方案,它包含 JDBC、Proxy 和 Sidecar 三个产品,本文将以 ShardingSphere-JDBC 为例进行讲解。
3.2 ShardingSphere 核心概念
- 逻辑表:拆分前的原表,如
order_tbl - 实际表:拆分后的物理表,如
order_tbl_202310_00 - 数据节点:由数据源和实际表组成,如
order_db_202310_00.order_tbl_202310_00 - 分片键:用于拆分的字段,如
user_id、create_time - 分片策略:如何将数据分配到不同的分片,包括分片算法和分片规则
3.3 项目环境搭建
3.3.1 Maven 依赖配置
首先,我们需要在pom.xml中添加必要的依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.2.0</version><relativePath/></parent><groupId>com.jam.order</groupId><artifactId>order-sharding</artifactId><version>1.0.0</version><properties><java.version>17</java.version><shardingsphere.version>5.4.0</shardingsphere.version><mybatis-plus.version>3.5.5</mybatis-plus.version><lombok.version>1.18.30</lombok.version><commons-lang3.version>3.14.0</commons-lang3.version><springdoc.version>2.1.0</springdoc.version></properties><dependencies><!-- Spring Boot 核心 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><!-- 数据库 --><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope></dependency><!-- ShardingSphere --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>${shardingsphere.version}</version></dependency><!-- MyBatis-Plus --><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>${mybatis-plus.version}</version></dependency><!-- Lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>${lombok.version}</version><scope>provided</scope></dependency><!-- 工具类 --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId><version>${commons-lang3.version}</version></dependency><!-- Swagger3 --><dependency><groupId>org.springdoc</groupId><artifactId>springdoc-openapi-starter-webmvc-ui</artifactId><version>${springdoc.version}</version></dependency><!-- 测试 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build>
</project>
3.3.2 数据库初始化脚本
我们需要创建分库分表的数据库和表结构。这里以按月分库,每个库按用户 ID 哈希分为 4 个表为例:
-- 创建2023年10月的订单库
CREATE DATABASE IF NOT EXISTS order_db_202310_00 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
CREATE DATABASE IF NOT EXISTS order_db_202310_01 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
CREATE DATABASE IF NOT EXISTS order_db_202310_02 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
CREATE DATABASE IF NOT EXISTS order_db_202310_03 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;-- 在每个库中创建4个订单表
DELIMITER $$
CREATE PROCEDURE create_order_tables(IN db_suffix CHAR(2))
BEGINDECLARE i INT DEFAULT 0;WHILE i < 4 DOSET @sql = CONCAT('CREATE TABLE IF NOT EXISTS order_db_202310_', db_suffix, '.order_tbl_202310_', i, ' (id BIGINT NOT NULL COMMENT \'订单ID\',user_id BIGINT NOT NULL COMMENT \'用户ID\',order_no VARCHAR(64) NOT NULL COMMENT \'订单编号\',total_amount DECIMAL(10,2) NOT NULL COMMENT \'订单总金额\',pay_amount DECIMAL(10,2) NOT NULL COMMENT \'实付金额\',freight DECIMAL(10,2) NOT NULL COMMENT \'运费\',order_status TINYINT NOT NULL COMMENT \'订单状态:0-待付款,1-待发货,2-已发货,3-已完成,4-已取消\',payment_time DATETIME COMMENT \'支付时间\',delivery_time DATETIME COMMENT \'发货时间\',receive_time DATETIME COMMENT \'确认收货时间\',comment_time DATETIME COMMENT \'评价时间\',create_time DATETIME NOT NULL COMMENT \'创建时间\',update_time DATETIME NOT NULL COMMENT \'更新时间\',PRIMARY KEY (id),KEY idx_user_id (user_id),KEY idx_create_time (create_time)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT=\'订单表\'');PREPARE stmt FROM @sql;EXECUTE stmt;DEALLOCATE PREPARE stmt;SET i = i + 1;END WHILE;
END$$
DELIMITER ;-- 调用存储过程创建表
CALL create_order_tables('00');
CALL create_order_tables('01');
CALL create_order_tables('02');
CALL create_order_tables('03');-- 创建订单_item表(略,结构类似)
3.4 ShardingSphere 配置
下面是application.yml的配置,实现按时间(月份)分库,按用户 ID 哈希分表:
spring:shardingsphere:datasource:names: db-202310-00, db-202310-01, db-202310-02, db-202310-03db-202310-00:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/order_db_202310_00?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghaiusername: rootpassword: rootdb-202310-01:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/order_db_202310_01?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghaiusername: rootpassword: rootdb-202310-02:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/order_db_202310_02?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghaiusername: rootpassword: rootdb-202310-03:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/order_db_202310_03?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghaiusername: rootpassword: rootrules:sharding:tables:order_tbl:actual-data-nodes: db-202310-${0..3}.order_tbl_202310-${0..3}database-strategy:standard:sharding-column: create_timesharding-algorithm-name: order-db-inlinetable-strategy:standard:sharding-column: user_idsharding-algorithm-name: order-tbl-inlinekey-generate-strategy:column: idkey-generator-name: snowflakesharding-algorithms:order-db-inline:type: INLINEprops:algorithm-expression: db-202310-${create_time.toString('yyyyMM') % 4}order-tbl-inline:type: INLINEprops:algorithm-expression: order_tbl_202310-${user_id % 4}key-generators:snowflake:type: SNOWFLAKEprops:worker-id: 1data-center-id: 1props:sql-show: truequery-with-cipher-column: truemybatis-plus:mapper-locations: classpath*:mapper/**/*.xmlglobal-config:db-config:id-type: ASSIGN_IDlogic-delete-field: deletedlogic-delete-value: 1logic-not-delete-value: 0configuration:map-underscore-to-camel-case: truelog-impl: org.apache.ibatis.logging.stdout.StdOutImplspringdoc:api-docs:path: /api-docsswagger-ui:path: /swagger-ui.htmloperationsSorter: methodpackages-to-scan: com.jam.order.controller
四、订单表分表分库核心代码实现
4.1 实体类设计
package com.jam.order.entity;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import io.swagger.v3.oas.annotations.media.Schema;
import lombok.Data;import java.math.BigDecimal;
import java.time.LocalDateTime;/*** 订单实体类** @author 果酱*/
@Data
@TableName("order_tbl")
@Schema(description = "订单信息")
public class Order {/*** 订单ID*/@TableId(type = IdType.ASSIGN_ID)@Schema(description = "订单ID")private Long id;/*** 用户ID*/@Schema(description = "用户ID")private Long userId;/*** 订单编号*/@Schema(description = "订单编号")private String orderNo;/*** 订单总金额*/@Schema(description = "订单总金额")private BigDecimal totalAmount;/*** 实付金额*/@Schema(description = "实付金额")private BigDecimal payAmount;/*** 运费*/@Schema(description = "运费")private BigDecimal freight;/*** 订单状态:0-待付款,1-待发货,2-已发货,3-已完成,4-已取消*/@Schema(description = "订单状态:0-待付款,1-待发货,2-已发货,3-已完成,4-已取消")private Integer orderStatus;/*** 支付时间*/@Schema(description = "支付时间")private LocalDateTime paymentTime;/*** 发货时间*/@Schema(description = "发货时间")private LocalDateTime deliveryTime;/*** 确认收货时间*/@Schema(description = "确认收货时间")private LocalDateTime receiveTime;/*** 评价时间*/@Schema(description = "评价时间")private LocalDateTime commentTime;/*** 创建时间*/@Schema(description = "创建时间")private LocalDateTime createTime;/*** 更新时间*/@Schema(description = "更新时间")private LocalDateTime updateTime;
}
4.2 Mapper 接口
package com.jam.order.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jam.order.entity.Order;
import org.apache.ibatis.annotations.Param;import java.time.LocalDateTime;
import java.util.List;/*** 订单Mapper接口** @author 果酱*/
public interface OrderMapper extends BaseMapper<Order> {/*** 根据用户ID查询订单列表** @param userId 用户ID* @param startTime 开始时间* @param endTime 结束时间* @return 订单列表*/List<Order> selectByUserIdAndTimeRange(@Param("userId") Long userId,@Param("startTime") LocalDateTime startTime,@Param("endTime") LocalDateTime endTime);/*** 根据订单状态查询订单数量** @param orderStatus 订单状态* @param startTime 开始时间* @param endTime 结束时间* @return 订单数量*/Long countByStatusAndTimeRange(@Param("orderStatus") Integer orderStatus,@Param("startTime") LocalDateTime startTime,@Param("endTime") LocalDateTime endTime);
}
4.3 Service 层实现
package com.jam.order.service;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.jam.order.entity.Order;
import com.jam.order.mapper.OrderMapper;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;import java.time.LocalDateTime;
import java.util.List;
import java.util.Objects;/*** 订单服务实现类** @author 果酱*/
@Slf4j
@Service
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements OrderService {/*** 创建订单** @param order 订单信息* @return 订单ID*/@Override@Transactional(rollbackFor = Exception.class)public Long createOrder(Order order) {// 参数校验Objects.requireNonNull(order, "订单信息不能为空");Objects.requireNonNull(order.getUserId(), "用户ID不能为空");StringUtils.hasText(order.getOrderNo(), "订单编号不能为空");Objects.requireNonNull(order.getTotalAmount(), "订单总金额不能为空");// 设置默认值LocalDateTime now = LocalDateTime.now();order.setCreateTime(now);order.setUpdateTime(now);order.setOrderStatus(0); // 默认为待付款状态// 保存订单boolean saveResult = save(order);if (!saveResult) {log.error("创建订单失败,订单信息:{}", order);throw new RuntimeException("创建订单失败");}log.info("创建订单成功,订单ID:{},订单编号:{}", order.getId(), order.getOrderNo());return order.getId();}/*** 根据用户ID查询订单列表** @param userId 用户ID* @param startTime 开始时间* @param endTime 结束时间* @return 订单列表*/@Overridepublic List<Order> getOrdersByUserId(Long userId, LocalDateTime startTime, LocalDateTime endTime) {Objects.requireNonNull(userId, "用户ID不能为空");Objects.requireNonNull(startTime, "开始时间不能为空");Objects.requireNonNull(endTime, "结束时间不能为空");log.info("查询用户订单,用户ID:{},时间范围:{}至{}", userId, startTime, endTime);return baseMapper.selectByUserIdAndTimeRange(userId, startTime, endTime);}/*** 更新订单状态** @param orderId 订单ID* @param orderStatus 订单状态* @return 是否更新成功*/@Override@Transactional(rollbackFor = Exception.class)public boolean updateOrderStatus(Long orderId, Integer orderStatus) {Objects.requireNonNull(orderId, "订单ID不能为空");Objects.requireNonNull(orderStatus, "订单状态不能为空");Order order = new Order();order.setId(orderId);order.setOrderStatus(orderStatus);order.setUpdateTime(LocalDateTime.now());// 根据状态更新对应的时间switch (orderStatus) {case 1: // 待发货,说明已支付order.setPaymentTime(LocalDateTime.now());break;case 2: // 已发货order.setDeliveryTime(LocalDateTime.now());break;case 3: // 已完成order.setReceiveTime(LocalDateTime.now());break;case 4: // 已取消break;default:log.error("不支持的订单状态:{}", orderStatus);throw new IllegalArgumentException("不支持的订单状态");}boolean updateResult = updateById(order);log.info("更新订单状态,订单ID:{},新状态:{},结果:{}", orderId, orderStatus, updateResult);return updateResult;}/*** 统计指定状态的订单数量** @param orderStatus 订单状态* @param startTime 开始时间* @param endTime 结束时间* @return 订单数量*/@Overridepublic Long countOrdersByStatus(Integer orderStatus, LocalDateTime startTime, LocalDateTime endTime) {Objects.requireNonNull(orderStatus, "订单状态不能为空");Objects.requireNonNull(startTime, "开始时间不能为空");Objects.requireNonNull(endTime, "结束时间不能为空");log.info("统计订单数量,状态:{},时间范围:{}至{}", orderStatus, startTime, endTime);return baseMapper.countByStatusAndTimeRange(orderStatus, startTime, endTime);}
}
4.4 Controller 层实现
package com.jam.order.controller;import com.jam.order.entity.Order;
import com.jam.order.service.OrderService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;import java.time.LocalDateTime;
import java.util.List;
import java.util.Objects;/*** 订单控制器** @author 果酱*/
@Slf4j
@RestController
@RequestMapping("/api/v1/orders")
@Tag(name = "订单管理", description = "订单相关的CRUD操作")
public class OrderController {private final OrderService orderService;public OrderController(OrderService orderService) {this.orderService = orderService;}/*** 创建订单** @param order 订单信息* @return 订单ID*/@PostMapping@Operation(summary = "创建订单", description = "创建新的订单")public ResponseEntity<Long> createOrder(@RequestBody Order order) {Long orderId = orderService.createOrder(order);return ResponseEntity.ok(orderId);}/*** 查询订单详情** @param orderId 订单ID* @return 订单详情*/@GetMapping("/{orderId}")@Operation(summary = "查询订单详情", description = "根据订单ID查询订单详情")public ResponseEntity<Order> getOrderDetail(@Parameter(description = "订单ID", required = true)@PathVariable Long orderId) {Order order = orderService.getById(orderId);return ResponseEntity.ok(order);}/*** 根据用户ID查询订单列表** @param userId 用户ID* @param startTime 开始时间* @param endTime 结束时间* @return 订单列表*/@GetMapping("/user/{userId}")@Operation(summary = "查询用户订单", description = "根据用户ID和时间范围查询订单列表")public ResponseEntity<List<Order>> getOrdersByUserId(@Parameter(description = "用户ID", required = true)@PathVariable Long userId,@Parameter(description = "开始时间", required = true)@RequestParam LocalDateTime startTime,@Parameter(description = "结束时间", required = true)@RequestParam LocalDateTime endTime) {List<Order> orders = orderService.getOrdersByUserId(userId, startTime, endTime);return ResponseEntity.ok(orders);}/*** 更新订单状态** @param orderId 订单ID* @param orderStatus 订单状态* @return 是否更新成功*/@PutMapping("/{orderId}/status")@Operation(summary = "更新订单状态", description = "根据订单ID更新订单状态")public ResponseEntity<Boolean> updateOrderStatus(@Parameter(description = "订单ID", required = true)@PathVariable Long orderId,@Parameter(description = "订单状态:0-待付款,1-待发货,2-已发货,3-已完成,4-已取消", required = true)@RequestParam Integer orderStatus) {boolean result = orderService.updateOrderStatus(orderId, orderStatus);return ResponseEntity.ok(result);}/*** 统计指定状态的订单数量** @param orderStatus 订单状态* @param startTime 开始时间* @param endTime 结束时间* @return 订单数量*/@GetMapping("/count")@Operation(summary = "统计订单数量", description = "统计指定状态和时间范围内的订单数量")public ResponseEntity<Long> countOrdersByStatus(@Parameter(description = "订单状态:0-待付款,1-待发货,2-已发货,3-已完成,4-已取消", required = true)@RequestParam Integer orderStatus,@Parameter(description = "开始时间", required = true)@RequestParam LocalDateTime startTime,@Parameter(description = "结束时间", required = true)@RequestParam LocalDateTime endTime) {Long count = orderService.countOrdersByStatus(orderStatus, startTime, endTime);return ResponseEntity.ok(count);}
}
4.5 自定义分片算法
上面的配置使用了 ShardingSphere 的内置 INLINE 算法,对于更复杂的场景,我们可以实现自定义分片算法:
package com.jam.order.sharding;import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm;import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Collection;
import java.util.HashSet;
import java.util.Properties;
import java.util.Set;/*** 订单表数据库分片算法(按时间)** @author 果酱*/
public class OrderDatabaseShardingAlgorithm implements StandardShardingAlgorithm<LocalDateTime> {private static final DateTimeFormatter FORMATTER = DateTimeFormatter.ofPattern("yyyyMM");private static final int DB_COUNT = 4;@Overridepublic String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<LocalDateTime> shardingValue) {LocalDateTime createTime = shardingValue.getValue();String month = createTime.format(FORMATTER);int dbIndex = Integer.parseInt(month) % DB_COUNT;String targetName = "db-" + month + "-" + String.format("%02d", dbIndex);if (availableTargetNames.contains(targetName)) {return targetName;}throw new IllegalArgumentException("未找到匹配的数据库:" + targetName);}@Overridepublic Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<LocalDateTime> shardingValue) {// 处理范围查询,如between andSet<String> result = new HashSet<>();// 获取时间范围LocalDateTime lower = shardingValue.getValueRange().lowerEndpoint();LocalDateTime upper = shardingValue.getValueRange().upperEndpoint();// 遍历时间范围内的所有月份LocalDateTime current = lower;while (!current.isAfter(upper)) {String month = current.format(FORMATTER);for (int i = 0; i < DB_COUNT; i++) {String targetName = "db-" + month + "-" + String.format("%02d", i);if (availableTargetNames.contains(targetName)) {result.add(targetName);}}// 月份加1current = current.plusMonths(1);}return result;}@Overridepublic void init(Properties props) {// 初始化配置}@Overridepublic String getType() {return "ORDER_DATABASE_SHARDING";}
}
对应的表分片算法:
package com.jam.order.sharding;import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm;import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Collection;
import java.util.HashSet;
import java.util.Properties;
import java.util.Set;/*** 订单表分片算法(按用户ID)** @author 果酱*/
public class OrderTableShardingAlgorithm implements StandardShardingAlgorithm<Long> {private static final int TABLE_COUNT = 4;@Overridepublic String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {Long userId = shardingValue.getValue();// 获取逻辑表名,如order_tblString logicTableName = shardingValue.getLogicTableName();// 从数据源名中提取月份信息,如db-202310-00 -> 202310String month = extractMonthFromDataSourceName(shardingValue.getDataSourceName());int tableIndex = Math.toIntExact(userId % TABLE_COUNT);String targetTableName = logicTableName + "_" + month + "_" + tableIndex;if (availableTargetNames.contains(targetTableName)) {return targetTableName;}throw new IllegalArgumentException("未找到匹配的表:" + targetTableName);}@Overridepublic Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {// 处理范围查询Set<String> result = new HashSet<>();// 从数据源名中提取月份信息String month = extractMonthFromDataSourceName(shardingValue.getDataSourceName());// 对于范围查询,可能需要查询所有表for (int i = 0; i < TABLE_COUNT; i++) {String targetTableName = shardingValue.getLogicTableName() + "_" + month + "_" + i;if (availableTargetNames.contains(targetTableName)) {result.add(targetTableName);}}return result;}/*** 从数据源名中提取月份信息** @param dataSourceName 数据源名,如db-202310-00* @return 月份,如202310*/private String extractMonthFromDataSourceName(String dataSourceName) {// 数据源名格式:db-202310-00String[] parts = dataSourceName.split("-");if (parts.length < 3) {throw new IllegalArgumentException("无效的数据源名:" + dataSourceName);}return parts[1];}@Overridepublic void init(Properties props) {// 初始化配置}@Overridepublic String getType() {return "ORDER_TABLE_SHARDING";}
}
然后在配置文件中使用自定义算法:
spring:shardingsphere:rules:sharding:tables:order_tbl:actual-data-nodes: db-202310-${0..3}.order_tbl_202310-${0..3}database-strategy:standard:sharding-column: create_timesharding-algorithm-name: order-db-customtable-strategy:standard:sharding-column: user_idsharding-algorithm-name: order-tbl-customkey-generate-strategy:column: idkey-generator-name: snowflakesharding-algorithms:order-db-custom:type: ORDER_DATABASE_SHARDINGprops:# 自定义属性order-tbl-custom:type: ORDER_TABLE_SHARDINGprops:# 自定义属性
五、分表分库高级问题解决方案
5.1 分布式事务处理
分表分库后,跨库操作会导致事务问题。目前主流的分布式事务解决方案有:
- 2PC(两阶段提交):强一致性,但性能较差
- TCC(Try-Confirm-Cancel):业务侵入性强,性能好
- SAGA 模式:长事务支持好,实现复杂
- 本地消息表:可靠性高,实现简单
- 事务消息:基于消息队列,如 RocketMQ 的事务消息
对于订单系统,推荐使用本地消息表或事务消息,因为它们既能保证最终一致性,又不会对性能造成太大影响。
下面是一个基于本地消息表的分布式事务示例:
package com.jam.order.service;import com.jam.order.entity.Order;
import com.jam.order.entity.OrderMessage;
import com.jam.order.enums.MessageStatus;
import com.jam.order.mapper.OrderMapper;
import com.jam.order.mapper.OrderMessageMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;import java.time.LocalDateTime;
import java.util.UUID;/*** 基于本地消息表的分布式事务示例** @author 果酱*/
@Slf4j
@Service
public class OrderTransactionService {private final OrderMapper orderMapper;private final OrderMessageMapper orderMessageMapper;private final RabbitTemplate rabbitTemplate;public OrderTransactionService(OrderMapper orderMapper, OrderMessageMapper orderMessageMapper,RabbitTemplate rabbitTemplate) {this.orderMapper = orderMapper;this.orderMessageMapper = orderMessageMapper;this.rabbitTemplate = rabbitTemplate;}/*** 创建订单并发送消息* 本地事务:创建订单 + 记录消息表*/@Transactional(rollbackFor = Exception.class)public Long createOrderWithMessage(Order order) {// 1. 创建订单orderMapper.insert(order);// 2. 记录消息到本地消息表OrderMessage message = new OrderMessage();message.setId(UUID.randomUUID().toString());message.setOrderId(order.getId());message.setContent("订单创建:" + order.getOrderNo());message.setStatus(MessageStatus.PENDING);message.setCreateTime(LocalDateTime.now());message.setUpdateTime(LocalDateTime.now());orderMessageMapper.insert(message);// 3. 发送消息到MQ(非事务操作,可能失败)try {rabbitTemplate.convertAndSend("order.exchange", "order.created", message);// 发送成功,更新消息状态message.setStatus(MessageStatus.SENT);message.setUpdateTime(LocalDateTime.now());orderMessageMapper.updateById(message);} catch (Exception e) {log.error("发送消息失败", e);// 发送失败,消息状态还是PENDING,由定时任务重试}return order.getId();}/*** 定时任务重试发送失败的消息*/@Transactional(rollbackFor = Exception.class)public void retryFailedMessages() {// 查询状态为PENDING且创建时间超过5分钟的消息LocalDateTime fiveMinutesAgo = LocalDateTime.now().minusMinutes(5);List<OrderMessage> messages = orderMessageMapper.selectByStatusAndCreateTimeBefore(MessageStatus.PENDING, fiveMinutesAgo);if (CollectionUtils.isEmpty(messages)) {return;}for (OrderMessage message : messages) {// 限制重试次数,避免无限重试if (message.getRetryCount() >= 3) {message.setStatus(MessageStatus.FAILED);message.setUpdateTime(LocalDateTime.now());orderMessageMapper.updateById(message);continue;}try {rabbitTemplate.convertAndSend("order.exchange", "order.created", message);// 发送成功,更新消息状态message.setStatus(MessageStatus.SENT);message.setRetryCount(message.getRetryCount() + 1);message.setUpdateTime(LocalDateTime.now());orderMessageMapper.updateById(message);} catch (Exception e) {log.error("重试发送消息失败,消息ID:{}", message.getId(), e);// 更新重试次数message.setRetryCount(message.getRetryCount() + 1);message.setUpdateTime(LocalDateTime.now());orderMessageMapper.updateById(message);}}}
}
5.2 跨库查询解决方案
分表分库后,跨库查询变得复杂,常见的解决方案有:
- 应用层聚合:在应用层查询多个分片,然后聚合结果
- 视图聚合:在数据库层创建视图,聚合多个分片的数据
- 中间件支持:使用 ShardingSphere 等中间件自动处理跨库查询
- 读写分离 + 只读库:将数据同步到只读库,在只读库上进行跨库查询
对于订单查询,推荐使用中间件支持+读写分离的方案:
package com.jam.order.service;import com.jam.order.entity.Order;
import com.jam.order.mapper.OrderMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;/*** 跨库查询示例** @author 果酱*/
@Slf4j
@Service
public class CrossDbQueryService {private final OrderMapper orderMapper;private final ReadOnlyOrderMapper readOnlyOrderMapper;public CrossDbQueryService(OrderMapper orderMapper, ReadOnlyOrderMapper readOnlyOrderMapper) {this.orderMapper = orderMapper;this.readOnlyOrderMapper = readOnlyOrderMapper;}/*** 查询指定时间段内的所有订单(跨库查询)* 使用只读库进行查询,避免影响主库性能*/public List<Order> queryOrdersByTimeRange(LocalDateTime startTime, LocalDateTime endTime) {Objects.requireNonNull(startTime, "开始时间不能为空");Objects.requireNonNull(endTime, "结束时间不能为空");log.info("跨库查询订单,时间范围:{}至{}", startTime, endTime);// 使用只读库进行跨库查询return readOnlyOrderMapper.selectByTimeRange(startTime, endTime);}/*** 应用层聚合示例(如果中间件不支持跨库查询)*/public List<Order> queryOrdersByTimeRangeWithAppAggregation(LocalDateTime startTime, LocalDateTime endTime) {Objects.requireNonNull(startTime, "开始时间不能为空");Objects.requireNonNull(endTime, "结束时间不能为空");log.info("应用层聚合查询订单,时间范围:{}至{}", startTime, endTime);List<Order> result = new ArrayList<>();// 遍历所有可能的分片,查询并聚合结果// 实际应用中需要根据分片规则计算需要查询的分片for (int dbIndex = 0; dbIndex < 4; dbIndex++) {for (int tableIndex = 0; tableIndex < 4; tableIndex++) {List<Order> orders = orderMapper.selectByTimeRangeAndShard(startTime, endTime, dbIndex, tableIndex);result.addAll(orders);}}return result;}
}
5.3 数据迁移与扩容
随着业务增长,原有的分表分库策略可能需要调整,这时候就需要进行数据迁移和扩容。
数据迁移的步骤:
- 准备新的分片:创建新的数据库和表
- 双写数据:同时向旧分片和新分片写入数据
- 迁移历史数据:将旧分片的历史数据迁移到新分片
- 切换路由:将查询路由到新分片
- 验证数据:确认新分片数据正确
- 下线旧分片:移除旧的数据库和表
下面是一个数据迁移工具类的示例:
package com.jam.order.util;import com.jam.order.entity.Order;
import com.jam.order.mapper.OrderMapper;
import com.jam.order.mapper.OrderNewMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;import java.time.LocalDateTime;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;/*** 订单数据迁移工具** @author 果酱*/
@Slf4j
@Component
public class OrderDataMigrationTool {private final OrderMapper orderMapper;private final OrderNewMapper orderNewMapper;// 线程池,用于并行迁移数据private final ExecutorService executorService = Executors.newFixedThreadPool(4);public OrderDataMigrationTool(OrderMapper orderMapper, OrderNewMapper orderNewMapper) {this.orderMapper = orderMapper;this.orderNewMapper = orderNewMapper;}/*** 迁移指定时间范围内的订单数据** @param startTime 开始时间* @param endTime 结束时间* @param batchSize 批次大小*/public void migrateOrders(LocalDateTime startTime, LocalDateTime endTime, int batchSize) {log.info("开始迁移订单数据,时间范围:{}至{},批次大小:{}", startTime, endTime, batchSize);long totalCount = orderMapper.countByCreateTimeRange(startTime, endTime);log.info("需要迁移的订单总数:{}", totalCount);long totalPages = (totalCount + batchSize - 1) / batchSize;log.info("总批次数:{}", totalPages);for (long page = 0; page < totalPages; page++) {long currentPage = page;executorService.submit(() -> {migrateOrderBatch(startTime, endTime, currentPage, batchSize);});}// 等待所有任务完成executorService.shutdown();try {boolean finished = executorService.awaitTermination(24, TimeUnit.HOURS);if (finished) {log.info("所有订单数据迁移完成");} else {log.error("订单数据迁移超时未完成");}} catch (InterruptedException e) {log.error("订单数据迁移被中断", e);Thread.currentThread().interrupt();}}/*** 迁移单批次订单数据*/@Transactional(rollbackFor = Exception.class)public void migrateOrderBatch(LocalDateTime startTime, LocalDateTime endTime, long page, int batchSize) {try {log.info("开始迁移批次:{},时间范围:{}至{}", page, startTime, endTime);// 查询旧表数据List<Order> orders = orderMapper.selectByCreateTimeRangeWithPage(startTime, endTime, page * batchSize, batchSize);if (CollectionUtils.isEmpty(orders)) {log.info("批次:{} 没有数据需要迁移", page);return;}// 迁移到新表int insertCount = orderNewMapper.batchInsert(orders);log.info("批次:{} 迁移完成,迁移数量:{}", page, insertCount);} catch (Exception e) {log.error("批次:{} 迁移失败", page, e);// 可以记录失败的批次,以便重试}}/*** 验证迁移后的数据是否正确*/public void verifyMigration(LocalDateTime startTime, LocalDateTime endTime) {log.info("开始验证迁移结果,时间范围:{}至{}", startTime, endTime);// 统计旧表数据量long oldCount = orderMapper.countByCreateTimeRange(startTime, endTime);// 统计新表数据量long newCount = orderNewMapper.countByCreateTimeRange(startTime, endTime);if (oldCount != newCount) {log.error("数据量不一致,旧表:{},新表:{}", oldCount, newCount);return;}log.info("数据量验证通过,旧表和新表数据量均为:{}", oldCount);// 随机抽查部分数据int sampleSize = 100;List<Order> oldSamples = orderMapper.selectRandomSamples(startTime, endTime, sampleSize);for (Order oldOrder : oldSamples) {Order newOrder = orderNewMapper.selectById(oldOrder.getId());if (newOrder == null) {log.error("数据缺失,订单ID:{}", oldOrder.getId());continue;}// 比较订单关键字段if (!oldOrder.getOrderNo().equals(newOrder.getOrderNo()) ||!oldOrder.getUserId().equals(newOrder.getUserId()) ||!oldOrder.getTotalAmount().equals(newOrder.getTotalAmount())) {log.error("数据不一致,订单ID:{},旧数据:{},新数据:{}", oldOrder.getId(), oldOrder, newOrder);}}log.info("数据验证完成");}
}
六、分表分库监控与运维
6.1 监控指标设计
为了确保分表分库系统的稳定运行,需要监控以下关键指标:
-
数据库指标:
- 各分片的 CPU、内存、磁盘使用率
- 连接数、慢查询数量
- 读写吞吐量、响应时间
-
应用指标:
- 分表分库相关操作的成功率、响应时间
- 跨库查询的比例和性能
- 分布式事务的成功率
-
数据均衡性指标:
- 各分片的数据量差异
- 各分片的 QPS 差异
下面是一个简单的监控数据收集工具类:
package com.jam.order.monitor;import com.jam.order.entity.ShardingMetrics;
import com.jam.order.mapper.ShardingMetricsMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;import java.time.LocalDateTime;
import java.util.List;
import java.util.Map;/*** 分表分库监控数据收集器** @author 果酱*/
@Slf4j
@Component
public class ShardingMonitor {private final ShardingMetricsMapper metricsMapper;private final DatabaseMonitorClient databaseMonitorClient;public ShardingMonitor(ShardingMetricsMapper metricsMapper, DatabaseMonitorClient databaseMonitorClient) {this.metricsMapper = metricsMapper;this.databaseMonitorClient = databaseMonitorClient;}/*** 每5分钟收集一次监控数据*/@Scheduled(fixedRate = 300000)public void collectMetrics() {log.info("开始收集分表分库监控数据");try {// 获取所有分片信息List<String> shardNames = databaseMonitorClient.getAllShardNames();for (String shardName : shardNames) {// 收集数据库指标Map<String, Object> dbMetrics = databaseMonitorClient.getDatabaseMetrics(shardName);// 收集表指标List<String> tableNames = databaseMonitorClient.getTablesInShard(shardName);for (String tableName : tableNames) {Map<String, Object> tableMetrics = databaseMonitorClient.getTableMetrics(shardName, tableName);// 保存监控数据ShardingMetrics metrics = new ShardingMetrics();metrics.setShardName(shardName);metrics.setTableName(tableName);metrics.setCollectTime(LocalDateTime.now());metrics.setRowCount(((Number) tableMetrics.get("rowCount")).longValue());metrics.setReadQps(((Number) tableMetrics.get("readQps")).doubleValue());metrics.setWriteQps(((Number) tableMetrics.get("writeQps")).doubleValue());metrics.setAvgQueryTime(((Number) tableMetrics.get("avgQueryTime")).doubleValue());metrics.setCpuUsage(((Number) dbMetrics.get("cpuUsage")).doubleValue());metrics.setMemoryUsage(((Number) dbMetrics.get("memoryUsage")).doubleValue());metrics.setConnectionCount(((Number) dbMetrics.get("connectionCount")).intValue());metricsMapper.insert(metrics);}}log.info("分表分库监控数据收集完成");} catch (Exception e) {log.error("收集分表分库监控数据失败", e);}}/*** 检测数据均衡性*/@Scheduled(cron = "0 0 1 * * ?") // 每天凌晨1点执行public void checkDataBalance() {log.info("开始检测数据均衡性");try {// 获取各分片的数据量List<Map<String, Object>> shardDataCount = metricsMapper.selectShardDataCount();if (CollectionUtils.isEmpty(shardDataCount)) {log.info("没有分片数据,无需检测均衡性");return;}// 计算平均值和标准差long total = 0;for (Map<String, Object> data : shardDataCount) {total += ((Number) data.get("totalCount")).longValue();}double avg = total / (double) shardDataCount.size();double variance = 0;for (Map<String, Object> data : shardDataCount) {long count = ((Number) data.get("totalCount")).longValue();variance += Math.pow(count - avg, 2);}variance /= shardDataCount.size();double stdDev = Math.sqrt(variance);// 计算变异系数(标准差/平均值)double cv = stdDev / avg;log.info("数据均衡性检测结果:平均值={}, 标准差={}, 变异系数={}", avg, stdDev, cv);// 如果变异系数大于0.2,说明数据分布不均匀if (cv > 0.2) {log.warn("数据分布不均匀,变异系数:{},建议进行数据重平衡", cv);// 可以发送告警通知} else {log.info("数据分布均匀,变异系数:{}", cv);}} catch (Exception e) {log.error("检测数据均衡性失败", e);}}
}
6.2 常见问题排查
分表分库系统可能遇到的常见问题及排查方法:
-
数据不一致:
- 检查分片键是否正确
- 检查分布式事务实现是否正确
- 对比新旧数据,找出差异点
-
查询性能差:
- 检查是否使用了分片键查询
- 检查是否有大量跨库查询
- 检查索引是否合理
-
数据倾斜:
- 分析分片键的分布情况
- 调整分片算法
- 进行数据重平衡
-
扩容困难:
- 检查数据迁移工具是否正常工作
- 优化迁移策略,减少停机时间
- 考虑使用自动化迁移工具
七、参考
- 单表数据量阈值:参考 MySQL 官方文档(https://dev.mysql.com/doc/refman/8.0/en/table-size-limit.html)
- 分库分表命名规范:参考阿里巴巴《Java 开发手册(嵩山版)》
- 分片键选择原则:参考 Apache ShardingSphere 官方文档(https://shardingsphere.apache.org/documentation/5.4.0/en/concepts/sharding/)
- 分布式事务解决方案:参考《Designing Data-Intensive Applications》(Martin Kleppmann 著)
- 数据迁移策略:参考 AWS 数据库迁移最佳实践(https://aws.amazon.com/cn/dms/best-practices/)
- 监控指标设计:参考 Prometheus 官方文档(Metric types | Prometheus)
Modbus)


)
- Weblogic SSRF漏洞)


)

)



![[光学原理与应用-422]:非线性光学 - 计算机中的线性与非线性运算](http://pic.xiahunao.cn/[光学原理与应用-422]:非线性光学 - 计算机中的线性与非线性运算)
—剪枝】)


)

