无恶意采集,取部分图片用来做相册测试的😄
效果图
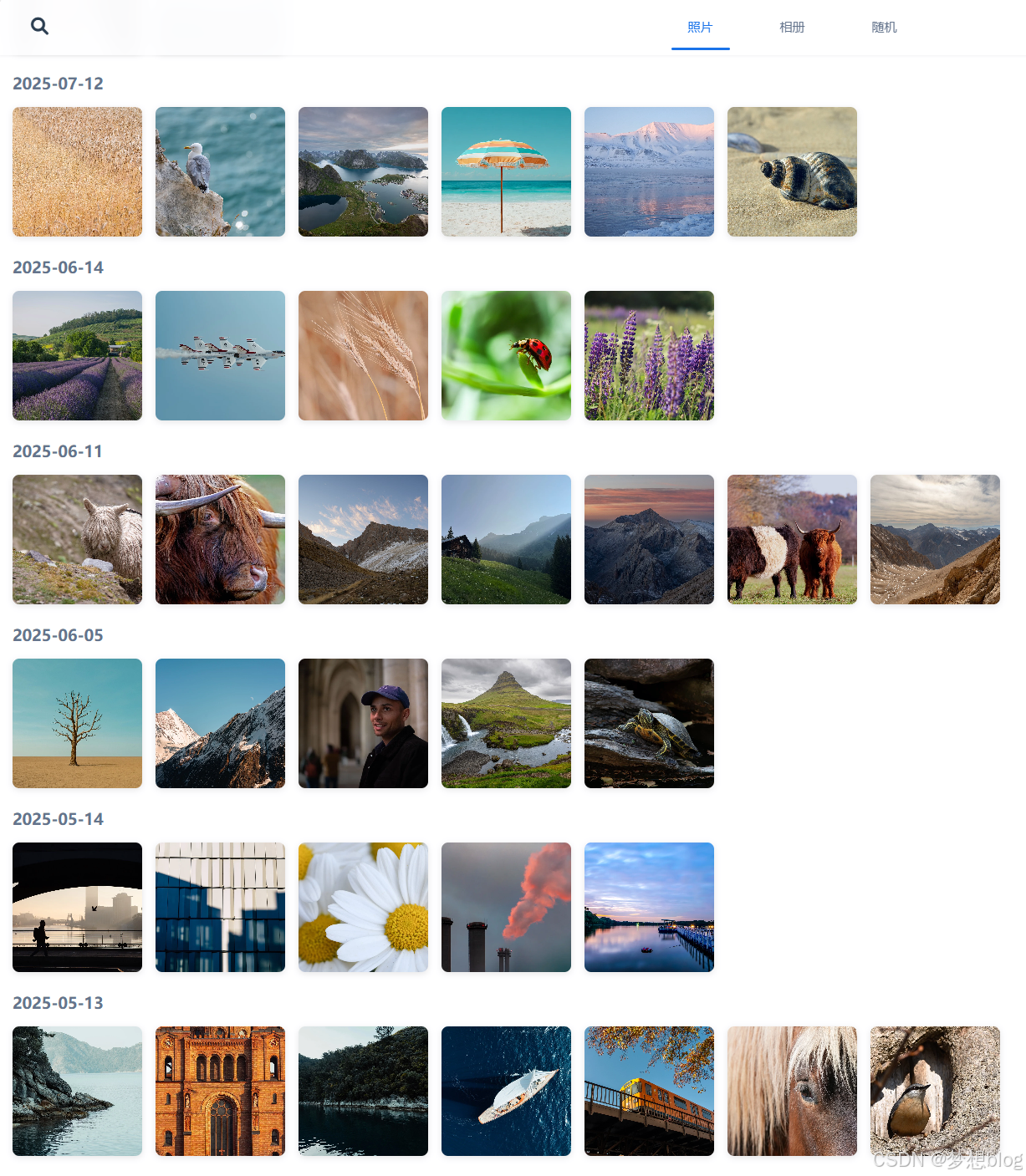
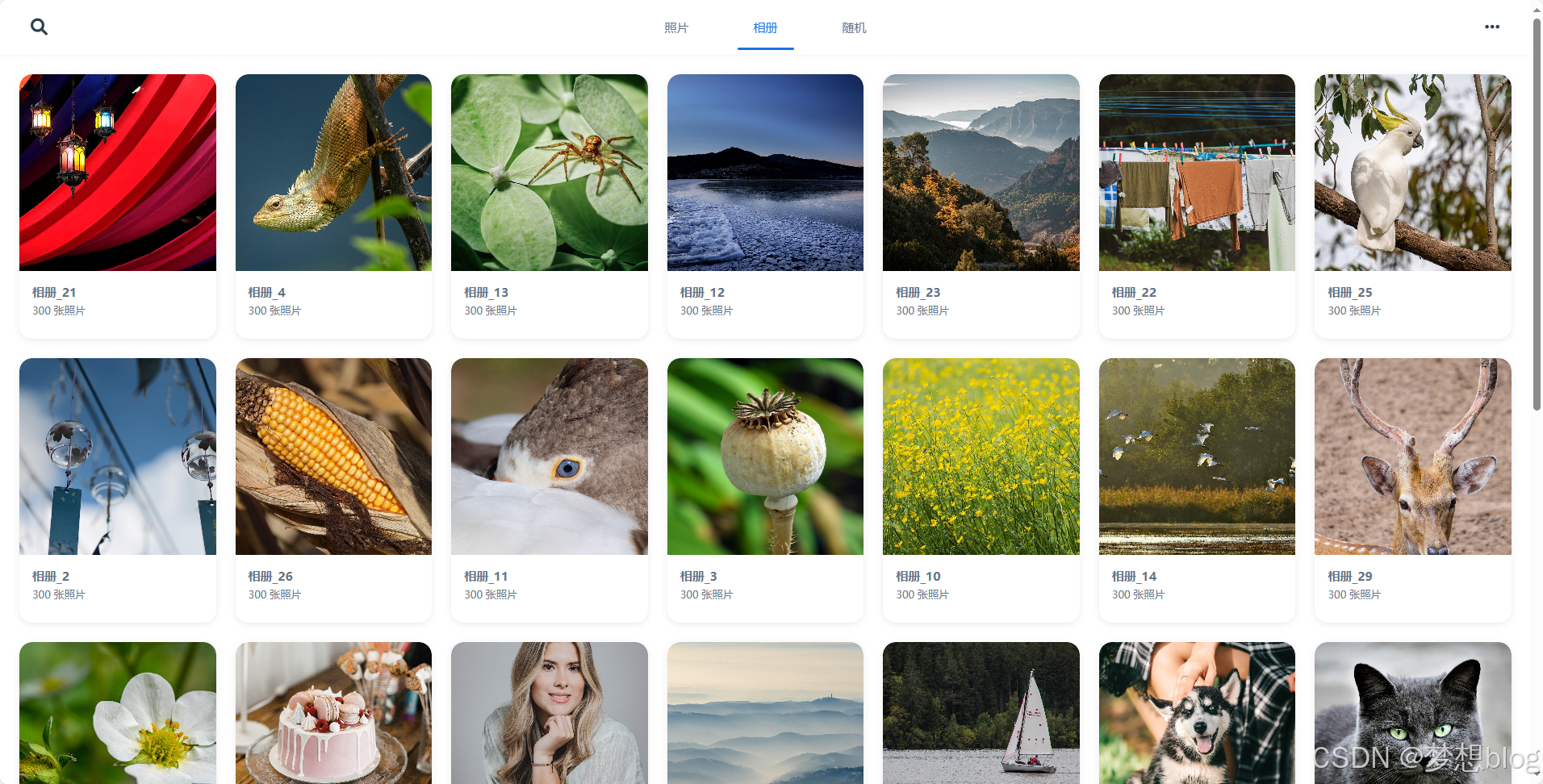
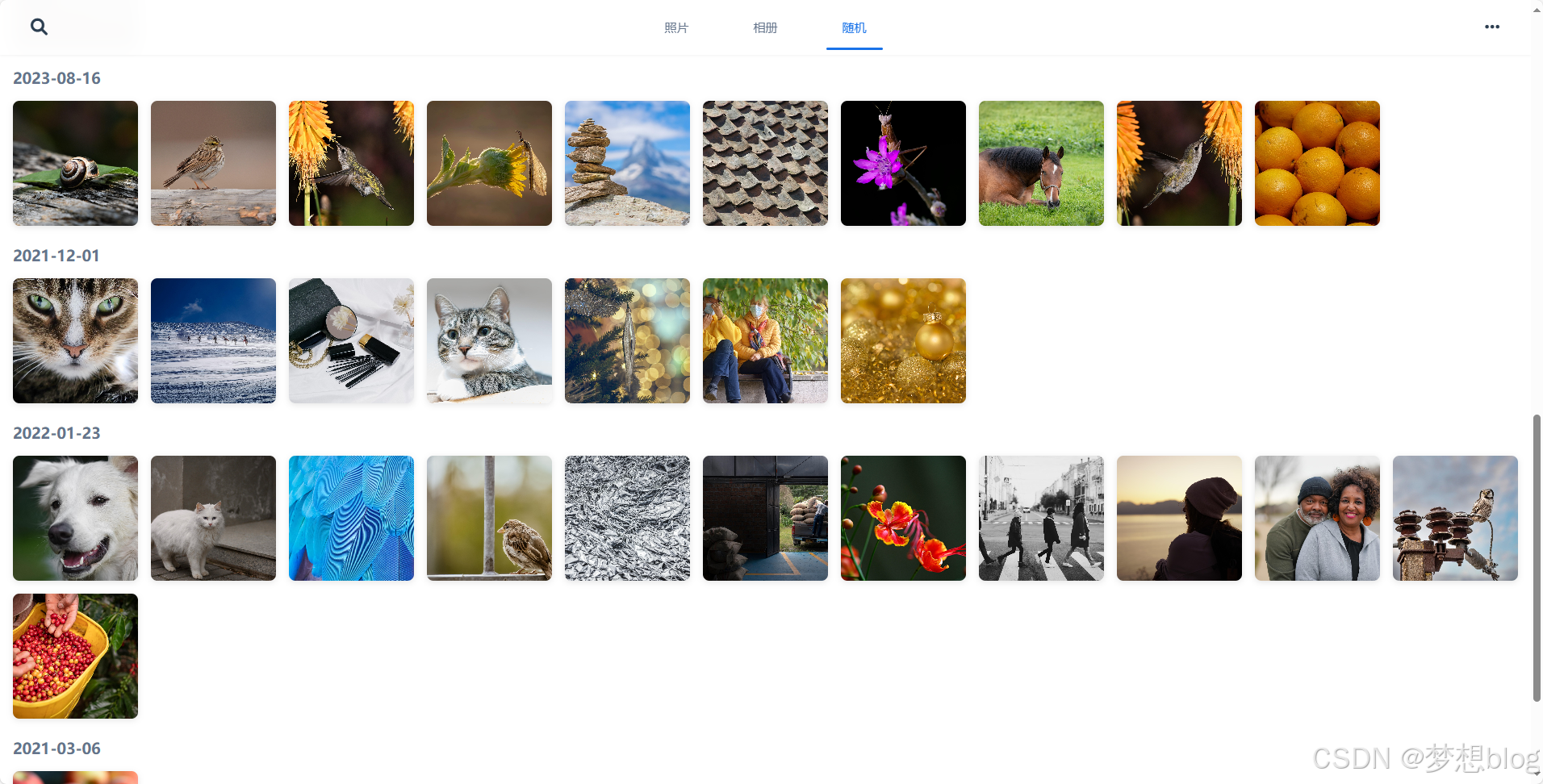
import cn.hutool.core.io.FileUtil;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONUtil;
import com.la.selenium.utils.SeleniumUtil;
import lombok.extern.slf4j.Slf4j;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;/*** 功能描述** @author jason*/
@Slf4j
public class ImageSpider {private static String url;private static final String imagePath = "/data/pixabay/photos/image_url.txt";public static void main(String[] args) {// String url = "https://pixabay.com/zh/illustrations/search/?order=ec";// String url = "https://pixabay.com/zh/illustrations/search/?order=ec&pagi=2";String urlTemplate = "https://pixabay.com/zh/photos/search/?order=ec&pagi={page}";FileUtil.writeUtf8String("", imagePath);SeleniumUtil.exec((webDriver) -> {for (int i = 1; i <= 100; i++) {int finalI = i;url = StrUtil.format(urlTemplate, new HashMap<String, Object>() {{put("page", finalI);}});if (i == 1) {url = StrUtil.replace(url, "&pagi=1", "");}List<String> imageList = spiderImage(webDriver, url);FileUtil.appendUtf8Lines(imageList, imagePath);}});log.info("采集完成");}public static List<String> spiderImage(WebDriver driver, String url) {driver.get(url);WebDriverWait wait = new WebDriverWait(driver, 10);By locator = By.xpath("//*[@id=\"app\"]/div[1]/div/div[2]/div[2]/div/div");wait.until(ExpectedConditions.visibilityOfAllElementsLocatedBy(locator));// String pageSource = driver.getPageSource();
// System.out.println(pageSource);WebElement webElement1 = driver.findElement(locator);List<WebElement> webElement2 = webElement1.findElements(By.className("column--HhhwH"));List<String> imageList = new ArrayList<>();webElement2.forEach(webElement3 -> {List<WebElement> webElement4 = webElement3.findElements(By.className("cell--UMz-x"));webElement4.forEach(webElement5 -> {String webElement5Html = webElement5.getAttribute("outerHTML");// 获取里面的 JSON 字符串Document doc = Jsoup.parse(webElement5Html);Elements scriptElements = doc.select("script[type=application/ld+json]");String scriptJson = scriptElements.first().html();// 获取 contentUrlString contentUrl = JSONUtil.parseObj(scriptJson).getStr("contentUrl");log.info("采集链接:{}", contentUrl);imageList.add(contentUrl);});});return imageList;}}

上网不稳定解决办法(无法上网)(将宿主机设置固定ip并配置dns))


)

)

)

)

)

)



