力扣100分类
一、Java基础代码模板
1. 基础输入输出模板
import java.util.Scanner;class Solution {public static int linkedListOperation() {// 链表操作实现return 0;}public static void main(String[] args) {Scanner scanner = new Scanner(System.in);int n = scanner.nextInt(); // 读取整数int m = scanner.nextInt(); // 读取第二个整数scanner.nextLine(); // 清除换行符String str = scanner.nextLine(); // 读取整行文本System.out.println("输入的内容是:" + str);}
}
2. Scanner类常用方法
| 方法 | 描述 |
|---|---|
next() | 读取下一个字符串(空格分隔) |
nextLine() | 读取下一行文本 |
nextInt() | 读取下一个整数 |
nextDouble() | 读取下一个双精度浮点数 |
System 输出 System.out.print();不换行输出
System.out.println();换行输出
二、设计模式实现
单例模式实现
饿汉式单例
1、构造器私有化 private A(){} ==>防止外部通过new创建实例
2、定义一个类变量记住类的一个对象 private static A a = new A(); ==>类内部定义一个静态成员变量用于保存唯一实例
3、定义一个类方法返回,返回类对象public static A getObject() {return a;} ==>并提供一个公共的静态方法用于获取该实例,只会返回同一个a对象,因为第2步中a是类变量,只会开辟一处内存
public class Singleton {// 1. 私有化构造器private Singleton() {}// 2. 类加载时立即创建实例private static final Singleton instance = new Singleton();// 3. 提供全局访问点public static Singleton getInstance() {return instance;}
}懒汉式单例(线程安全版)
1、构造器私有化 private A(){} ==>防止外部通过new创建实例
2、定义一个静态成员变量 private static A; 没有创建对象
3、定义一个类方法返回,返回类对象 public static A getObject(){ if(a==null){a = new A();} return a; } ==>第一次调用方法时才创建对象,每次调用该方法,只会返回同一个a对象
public class Singleton {private static volatile Singleton instance;private Singleton() {}public static Singleton getInstance() {if (instance == null) {synchronized (Singleton.class) {if (instance == null) {instance = new Singleton();}}}return instance;}
}三、集合框架
数组
1、数组长度
int[][] changdu;
int m = changdu.length; ===> changdu[1].length; 行
int n = changdu[0].length; 列2、字符串转化为字符数组
String str = "Hellow";
char[] charArray = str.toCharArray();
System.out.println(Arrays.toString(charArray)); 3、字符串转为字符串数组
String str = "apple,banana,orange";
String[] strArray = str.split(",");
System.out.println(Arrays.toString(strArray)); 4、数组排序 Arrays.sort();5、数组输出 int[] nums
System.out.print(Arrays.toString(nums));int[] nums = {1,2,3,4}
System.out.print(Arrays.toString(nums));
int[][] nums = {{1,3},{2,6},{8,10},{15,18}};
System.out.print(Arrays.deepToString(nums));字符串 String
1、字符串长度String str;int n = str.length();2、转化为数组char[] charArray = str.toCharArray();3、获取索引位置的字符String char = str.charAt(int index);4、对字符串截取(左闭右开)String sub = str.substring(int beginIndex,int endIndex);动态数组 ArrayList
1、创建
ArrayList<Integer/String> list = new Arraylist<>(n); n为指定容量
2、添加元素
list.add("apple"); list.add(0,"banana")
3、访问元素
get(int index); index0f();返回元素首次出现位置
lastIndex0f();返回元素最后一次出现位置
4、删除元素
remove(int index); 删除指定位置元素
5、修改元素
list.set(1,"Mango"); 将索引为1的元素修改为“Mango“
6.长度
int n = list.size();动态链表 LinkedList 和ArrayList差不多
1、创建
LinkedList<Integer/String> list = new Linkedlist<>(n); n为指定容量
2、添加元素
list.add("apple");
list.add(0,"banana")
list.addFirst();
List.addLast();
3、访问元素
get(int index);
index0f();返回元素首次出现位置
lastIndex0f();返回元素最后一次出现位置
4、删除元素
remove(int index); 删除指定位置元素
5、修改元素
list.set(1,"Mango"); 将索引为1的元素修改为“Mango“
6.长度
int n = list.size(); `哈希 HashMap
1、创建
Map< String , Integer> map = new HashMap<>();
2、添加
map.put("Alice",90);
3、获取
int score = map.get("Alice");
4、移除
map.remove("Alice");哈希
两数之和

题目要求:两数之和,只有一个答案
思路: 建立Map哈希函数,将值与索引对应,判断目标值-当前值是否在哈希中,存在则返回 // 无参考意义
public int[] twoSum(int[] nums, int target) {// 创建一个哈希表来存储数字及其索引Map<Integer, Integer> numMap = new HashMap<>();// 遍历数组for (int i = 0; i < nums.length; i++) {int complement = target - nums[i]; // 计算目标值与当前数字的差// 如果差值在哈希表中,返回其索引和当前索引if (numMap.containsKey(complement)) {return new int[]{numMap.get(complement), i};}// 否则将当前数字及其索引存入哈希表numMap.put(nums[i], i);}// 如果没有找到结果,返回空数组(题目假设一定有解,所以实际不会触发)return new int[]{};}字母异位词分组

题目要求:字母异位词分组 将相同字母排列的放在同一个数组内
思路: 创建map哈希:String与List<String>,遍历字符串数组,对当前的字符串进行排序(字符串--字符串数组排序--字符串)判断不包含,新建动态数组。都加入map里面
基础知识:char 是单个字符(比如 'A'、'1'、'中')String 是一串字符组成的“字符串”(比如 "Hello"、"你好世界")
public List<List<String>> groupAnagrams(String[] strs) {Map<String,List<String>> map = new HashMap<>();for(String str:strs){// 字母排序 String - char[] - Stringchar[] chars = str.toCharArray();Arrays.sort(chars); // 返回的是void类型String sortedStr = new String(chars); // 将char[]转为String// 如果不包含,新建一个ArrayList队列if(!map.containsKey(sortedStr)){map.put(sortedStr,new ArrayList<>());}// 不管包不包含,都加入map.get(sortedStr).add(str);}// 把map的所有的值放在一个新的ArrayListreturn new ArrayList<>(map.values());}最长连续序列

最长连续序列:数组存在的最长连续序列长度,可间断,只要存在就行
思路: 先将数值放在Set哈希中,可以去重,然后遍历numSet先判断有没有比当前值小1的数,确认起始值,避免重复计算。再判断有没有比当前值大的数,whlie循环。
- Set:只存“唯一元素”,不记录顺序,也不带键值对
- Map:存“键值对”(key-value),每个 key 必须唯一,value 可重复
public int longestConsecutive(int[] nums) {// 去重Set<Integer> numSet = new HashSet<>();for(int num:nums){numSet.add(num);}int maxLength = 0;for(int num:numSet){int currLength= 1;// 判断有没有比当前值小1的数,确认起始值,避免重复计算if(!numSet.contains(num-1)){int currNum = num;// 再判断有没有比当前值大的数,whlie循环while (numSet.contains(currNum+1)){currNum++;currLength++;}}maxLength = Math.max(maxLength,currLength);}return maxLength;}双指针
移动零

将所有的0移动到末尾,保持非0位置相对顺序。换个想法,将非0的数移动到前面 不需要交换,直接设置为0。记录0的位置,与不为0交换
public void moveZeroes(int[] nums) {int n = nums.length;int j = 0; // 记录为0的位置for(int i =0;i<n;i++){if(nums[i] != 0){if(i>j){nums[j] = nums[i];nums[i] = 0;}j++;}}}盛最多水的容器
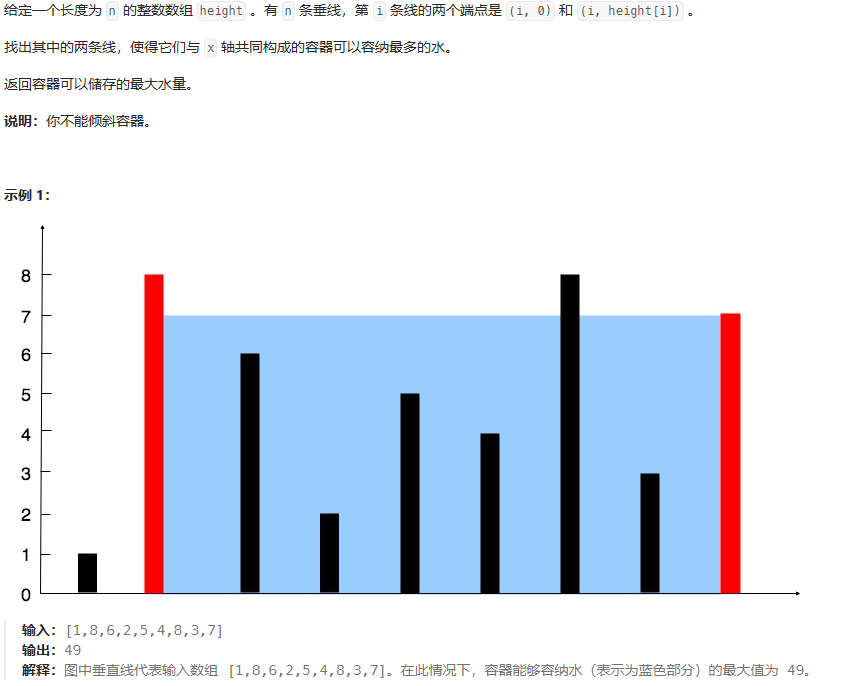
双端左右指针,判断面积。特殊,哪边小于另一边,则小边移动,本质是贪心?
public int maxArea(int[] height) {int n = height.length;int leff = 0;int right = n-1;int maxArea = 0;while (leff <right){int minHeight = Math.min(height[leff],height[right]);int width = right -leff;int curArea = minHeight*width;maxArea = Math.max(maxArea,curArea);if(height[leff]<height[right]){leff++;}else {right--;}}return maxArea;}三数之和
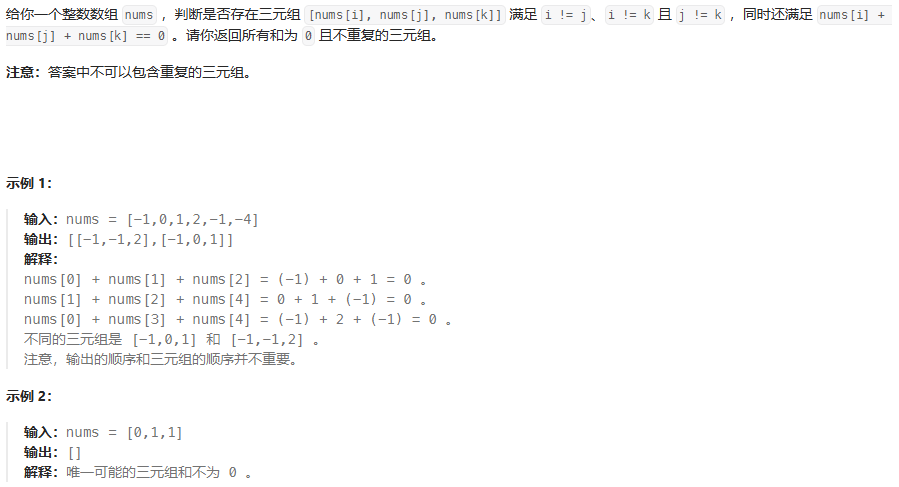
- 处理边界+重复条件:两次边界(整体边界+if边界)+两次重复(if循环单定点重复+while循环左右指针重复)
- 先将数组排序,将三数之和变成二数之和,先确定一个定点,然后用双端左右指针(左移动,右定点)确定和,判断指针移动
public List<List<Integer>> threeSum(int[] nums) {List<List<Integer>> ans = new ArrayList<>();// 处理边界条件if(nums == null || nums.length <3){return ans; // 初始为空}// 排序,从小到大Arrays.sort(nums);// 定点+双端左右指针(左移动,右定点)int n = nums.length;for(int i =0;i<n-2;i++){// 处理边界:当前位置>0,无法合成0if(nums[i] > 0){break;}if(i>0&&nums[i] == nums[i-1]){continue;}// 单次循环int target = -nums[i]; // nums[i]为负数,target肯定为正数int left = i+1; // 左移动int right = n-1; // 右定点while (left < right){int sum = nums[left]+nums[right];if(sum == target){// List<String> list = Arrays.asList("a", "b", "c"); 返还为字符串列表ans.add(Arrays.asList(nums[i],nums[left],nums[right]));// 去重符合条件两数之和while (left<right && nums[left] == nums[left+1]){left++;}while (left<right && nums[right] == nums[right-1]){right--;}left++;right--;}else if(sum < target){left++;}else {right--;}}}return ans;}接雨水

接雨水(方块化) 容器固定,而不是求最大的容器容量
思路:双端左右指针+最大单边左右指针+单边雨水容量
靠高边,算低边(移动),底边:最大-当前。左右高边相当于外墙
public int trap(int[] height) {// 双端左右指针+单边最大左右指针+单边雨水int left = 0;int right = height.length-1;int leftmax = 0;int rightmax = 0;int total = 0;// 靠高边,算低边,底边:最大-当前while (left <right){// 确认当前最大单边leftmax = Math.max(leftmax,height[left]);rightmax = Math.max(rightmax,height[right]);// 移动底边if(height[left] < height[right]){total += leftmax - height[left];left++;}else {total += rightmax - height[right];right--;}}return total;}滑动窗口(定点左右指针):
无重复字符的最长子串(动态窗口)

思路:特点就是Set<Character> 建立,定点左右指针移动,判断是否包含在内,如果在内,则去除字符,移动左指针。反之则添加字符
public class Solution {public int lengthOfLongestSubstring(String s) {Set<Character> res = new HashSet<>();int maxlength = 0;int left = 0;for(int right =0;right<s.length();right++){char currentChar = s.charAt(right);if(res.contains(currentChar)){res.remove(s.charAt(left));left++;}res.add(currentChar);maxlength = Math.max(maxlength,right-left+1);}return maxlength;}public static void main(String[] args){Solution solution = new Solution();String s = "abcabcbb";int result = solution.lengthOfLongestSubstring(s);System.out.print(result);}
}找到字符串中所有字母异位词(固定窗口)

思路:分别为两个字符串创建字母表,当相应的位置值相等时,则判断为异位词。此位置的定点左右指针为固定窗口值
public class Solution {public List<Integer> findAnagrams(String s, String p) {List<Integer> ans = new ArrayList<>();// 建立一个字母表统计出现次数int[] countP = new int[26];int[] countS = new int[26];for(int i =0;i<p.length();i++){countP[p.charAt(i) - 'a']++;}// 定点左右指针移动for(int right=0;right<s.length();right++){// 统计s字母出现的次数countS[s.charAt(right) - 'a']++;int left = right-p.length()+1;if(left < 0){continue; // 结束此次循环}// 此处只能用equals进行比较if(Arrays.equals(countP,countS)){ans.add(left);}countS[s.charAt(left) - 'a']--;}return ans;}public static void main(String[] args){Solution solution = new Solution();String s = "cbaebabacd";String p = "abc";List<Integer> result = solution.findAnagrams(s,p);System.out.print(result);}
}滑动窗口最大值(固定窗口)

Deque(双端队列):
- 前端:移除超出窗口范围的旧元素
- 后端:添加新元素并维护递减顺序
peek是查看 poll推出
思路:使用双端队列Deque,队头和队尾查看以及移出方便。记在队列记录的是索引的值。使用定点左右指针,只有left>=0,才开始记录队列的最大值。
- 第一次while循环,如果队列的队头索引<当前左指针索引,那么就移除队头,直到大于左指针索引
- 第二次while循环,如果队列的队尾索引对应的值<当前右指针对应的值,移除队尾,直到其值大于右指针对应的值,保存队列是递减的,这样队列的队头就是最大值索引,可以直接出队。
public class Solution {public int[] maxSlidingWindow(int[] nums, int k) {if( nums == null || nums.length == 0 || k<=0){return new int[0];}int n = nums.length;int[] result = new int[n-k+1];// 存储的是索引值Deque<Integer> deque = new ArrayDeque<>();// 定点左右指针for (int right =0;right<n;right++){int left = right-k+1; // 固定长度// 移除超出窗口范围的元素while (!deque.isEmpty() && deque.peekFirst() < left){deque.pollFirst(); // 出队队首}// 移除比当前元素小的元素,保持队列递减// 出队是区间最大元素while (!deque.isEmpty() && nums[deque.peekLast()] < nums[right]){deque.pollLast(); // 出队队尾}deque.addLast(right); //记录索引位置if(left>=0){result[left] = nums[deque.peekFirst()];}}return result;}public static void main(String[] args) {Solution solution = new Solution();int[] nums = {1, 3, -1, -3, 5, 3, 6, 7};int k = 3;int[] result = solution.maxSlidingWindow(nums, k);System.out.println(Arrays.toString(result));// 输出: [3, 3, 5, 5, 6, 7]}
}
子串
和为k的子数组

题目复述:数组中和为k的子数组连续非空序列,
思路:两次遍历循环判断
public class Solution {public int subarraySum(int[] nums, int k) {int maxSum = 0;for(int i =0;i<nums.length;i++){int sum = 0;for(int j =i;j<nums.length;j++){sum += nums[j];if(sum == k){// 不需要打破当前循环题,万一下一位是0maxSum++;}}}return maxSum;}public static void main(String[] args) {Solution solution = new Solution();int[] nums = {1,1,1};int k =2;int result = solution.subarraySum(nums,k);System.out.print(result);}
}
最小覆盖子串(动态窗口)

思路:两个字符串覆盖问题,注意这种里面的覆盖是可以包含其它字母的,求得是最小子串。建立两个字母表,判断是否可以覆盖(cntS字母次数>=cntT字母次数,其他字母)
public class Solution {public String minWindow(String S, String t) {int[] cntS = new int[128];int[] cntT = new int[128];// 记录t出现的字母次数for(char c:t.toCharArray()){cntT[c]++; // 自动类型转化,能自动识别字母对应的索引位置}char[] s = S.toCharArray();int m = s.length;// 初始化最大覆盖长度// 本来应该是0:m-1,但这样无法判断s没有包含t的情况,因此范围扩大int ansleft = -1;int ansright = m;int left = 0;for(int right =0;right<m;right++){cntS[s[right]]++;// 在覆盖范围内的最小值,起始情况while (isCovered(cntS,cntT)){if(right-left<ansright-ansleft){ansleft = left;ansright = right;}cntS[s[left]]--;left++;}}if(ansleft >=0){return S.substring(ansleft,ansright+1);}else {return "";}}private boolean isCovered(int[] cntS,int[] cntT){// cntS的出现的字母肯定要比cntT多// 所以存在cntS字母次数>=cntT字母次数for(int i = 'a';i<='z';i++){if(cntS[i] < cntT[i]){return false;}}for(int i = 'A';i<='Z';i++){if(cntS[i] < cntT[i]){return false;}}return true;}public static void main(String[] args) {Solution solution = new Solution();String s = "ADOBECODEBANC";String t = "ABC";String result = solution.minWindow(s,t);System.out.println(result);}
}
普通数组
最大子数组合(动规)

// 不推荐,时间复杂度太高了public int maxSubArray(int[] nums) {int maxSum = Integer.MIN_VALUE;int n = nums.length;for(int i =0;i<n;i++){int sum = 0;for(int j=i;j<n;j++){sum += nums[j];maxSum = Math.max(maxSum,sum);}}return maxSum;}public int maxSubArray(int[] nums) {int maxSum = nums[0];int curSum = nums[0];int n = nums.length;for(int i =0;i<n;i++){// 如果当前值>其累加和,重置位置// 本质是动规curSum = Math.max(nums[i],curSum+nums[i]);maxSum = Math.max(maxSum,curSum);}return maxSum;}轮转数组(三次翻转法)

public void rotate(int[] nums, int k) {int n = nums.length;// 区间范围压缩到0:n-1k = k%n;reverse(nums,0,n-1);reverse(nums,0,k-1);reverse(nums,k,n-1);}private void reverse(int[] nums,int left,int right){while (left<right){int temp = nums[left];nums[left] = nums[right];nums[right] = temp;left++;right--;}}除自身以外数组的乘积(正/倒乘法)
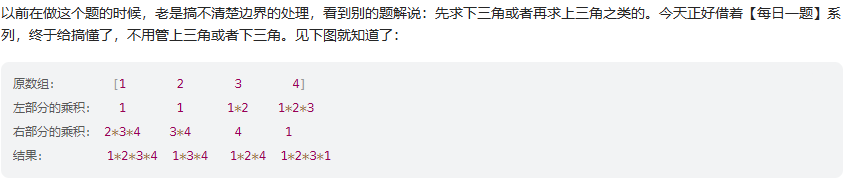
思路:移一位乘法
public int[] productExceptSelf(int[] nums) {int n = nums.length;int[] ans = new int[n];ans[n-1] = 1;// 0:n-1区间 倒乘法:当前值=后面相乘for(int i = n-2;i>=0;i--){ans[i] = ans[i+1]*nums[i+1];}// 正乘法:当前值 = 前面相乘int pre = 1;for(int i =0;i<n;i++){ans[i] = ans[i]*pre;pre *= nums[i];}return ans;}
缺失的第一个正数(索引和值对应)

思路:将队列长度范围内的索引位置与值对应上,这样遍历寻找对应。记得是while循环,直到当前位置值与索引对上或不在范围跳出循环。

public int firstMissingPositive(int[] nums) {int n = nums.length;// 另类排序确认范围内的索引与值对应// 如果没有,说明最小值为1// 如果有,遍历找到它for(int i =0;i<n;i++){// 在区间范围内,将值与索引对应 注意:0不是正数// 记录当前值大于0且小于队列长度且当前值不等于当前值位置本来值// 直到当前位置值与索引对上,否有不在范围跳出循环while(nums[i]>0&&nums[i]<n+1&&nums[nums[i]-1]!=nums[i]){int temp = nums[nums[i]-1];nums[nums[i]-1] = nums[i];nums[i] = temp;}}for(int i = 0;i<n;i++){if(nums[i]!=i+1){return i+1;}}return n+1;}
合并区间(int[][] 列表用法):

基础知识:对于这种区间带区间类型int[][] nums,可以这样考虑for(int[] p : nums) 这里的p代表的单个区间的索引:例如p[0] = 1 p[1] = 3;区间起始位置排序 Array.sort(nums,(p,q) -> p[0]-q[0])Arrays.deepToString(result)
return ans.toArray(new int[ans.size()][]);
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;public class Solution {public static int[][] merge(int[][] nums){// 比较两个区间起始位置,从小到大排列Arrays.sort(nums,(p,q)->p[0]-q[0]);List<int[]> ans = new ArrayList<>();// 增强型for循环for(int[] p:nums){int m = ans.size();if(m>0 && p[0] <= ans.get(m-1)[1]){ans.get(m-1)[1] = Math.max(ans.get(m-1)[1],p[1]);}else{ans.add(p);}}// List列表转为数组return ans.toArray(new int[ans.size()][]);}public static void main(String[] args){Solution solution = new Solution();int[][] nums = {{1,3},{2,6},{8,10},{15,18}};int[][] result = solution.merge(nums);System.out.println(Arrays.deepToString(result));}}
动规定义
动态规划:每一个状态一定是由上一个状态推导出来
动归5部曲
- 确定dp数组(dp table)以及下标的含义
- 确定递推公式
- dp数组如何初始化
- 确定遍历顺序
- 举例推导dp数组
单轴
爬楼梯、最小代价爬楼梯
图型--路径
不同路径、不同路径Ⅱ
爬楼梯
思路:首先确定dp[n]代表的含义是第n个楼层的到达方法,已知一次只能走1~2个台阶,则推导出公式dp[n]=dp[n-1]+dp[n-2]。确定初始条件n>=2,以及dp[0]=1,dp[1]=1
package 动态规划;public class Solution {public static int climbStairs2(int n){int[] dp = new int[n+1];dp[0] = 1;dp[1] = 1;for(int i = 2;i<=n;i++){dp[i] = dp[i-1]+dp[i-2];}return dp[n];}public static void main(String[] args){int n = 1;Solution solution = new Solution();int result = solution.climbStairs2(n);System.out.println(result);}
}
一次可以跨m个台阶,到达n个楼层的多少路径
package 动态规划;public class Solution {public static int climbStairs(int m,int n){int[] dp = new int[n + 1];dp[0] = 1; // 初始化:地面有1种方法for (int i = 1; i <= n; i++) {for (int j = 1; j <= m; j++) {if (i >= j) {dp[i] += dp[i - j];}}}return dp[n];}public static void main(String[] args){int m = 3;int n = 4;Solution solution = new Solution();int result = solution.climbStairs(m,n);System.out.println(result);}
}杨辉三角
思路:要明白输出类型List<List<Integer>>,其次发现从第1行开始(存在0行),开始和结尾都是1,可以写出num.add(1),最后是动规,从j=1开始到i-1结束
给定一个非负整数 numRows,生成「杨辉三角」,的前 numRows 行。

public static List<List<Integer>> generate(int numRows){List<List<Integer>> nums = new ArrayList<>();// 初始化nums.add(List.of(1));for(int i =1;i<numRows;i++){List<Integer> num = new ArrayList<>();num.add(1);for(int j =1;j<i;j++){num.add(nums.get(i-1).get(j-1)+nums.get(i-1).get(j));}num.add(1);nums.add(num);}return nums;}打家截舍
思路:dp[n]代表到达n间房,得到的最大数(注意第n间房可以不偷)。所以其最大值可以是
dp[n]=dp[n-1]或dp[n-2]+nums[n-1](注意nums.length = n,索引最大为n-1)

注意:int[] m = {1,2,3,4};这里是大括号不是中括号
public class Solution {public static int rob(int[] nums){int n = nums.length;if(n == 0){return 0;}int[] dp = new int[n+1];dp[0] = 0;dp[1] = nums[0];for(int i = 2;i<=n;i++) {dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i - 1]);}return dp[n];}public static void main(String[] args){int[] m = {1,2,3,4,5};Solution solution = new Solution();int result = solution.rob(m);System.out.println(result);}
}
完全平方数
思路:dp[n]代表和为n的完全平方数最小数量,dp[i] = Math.min(dp[i],dp[i-j*j]+1),赋值dp[i]最大为i。初始条件dp[0]=0,i-j*j>=0.遍历顺序1<=i<=n,1<=j.

public static int numSquares(int n){int[] dp = new int[n+1];dp[0] = 0;for(int i =1;i<=n;i++){dp[i] = i;for(int j=1;i-j*j>=0;j++){dp[i] = Math.min(dp[i],dp[i-j*j]+1);}}return dp[n];}零钱兑换
思路:dp[n]代表合为n所需要的最小硬币数,dp[i] = Math.min(dp[i],dp[i-coins[j]]+1)
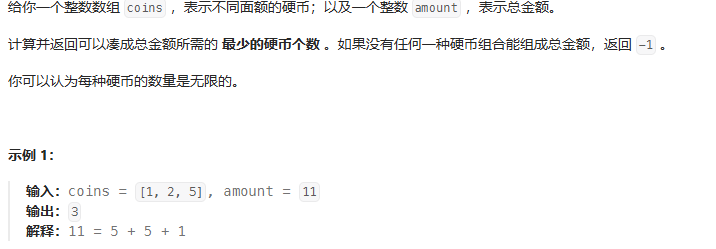
public static int coinChange(int[] coins,int amount){int n = coins.length;int[] dp = new int[amount+1];// dp[i] = Math.min(dp[i],dp[i-coins[j]]+1)for(int i =1;i<=amount;i++){dp[i] = amount+1;for(int j=0;j<n;j++){if(i-coins[j]>=0) {dp[i] = Math.min(dp[i], dp[i - coins[j]] + 1);}}}if(dp[amount] == amount+1){return -1;}else {return dp[amount];}}单词拆分(偏,定点双指针)
思路:dp[n]代表字符数s是否由字符串列表wordDict拼接而成,定点双指针,判断条件
if(dp[j] && wordSet.contains(s.substring(j,i+1)))

public static boolean wordBreak(String s,List<String> wordDict){Set<String> wordSet = new HashSet<>(wordDict); // 将字典转为哈希集合,方便快速查找int n = s.length();boolean[] dp = new boolean[n+1];dp[0] = true;for(int i =0;i<n;i++){for(int j =0;j<=i;j++){// substring 左闭右开if(dp[j] && wordSet.contains(s.substring(j,i+1))){dp[i+1] = true;break;}}}return dp[n];}最长递增子序列(定点双指针)
思路:dp[n]代表在n处,最长子序列的长度。定点双指针,dp[i] = Math.max(dp[i], dp[j] + 1);
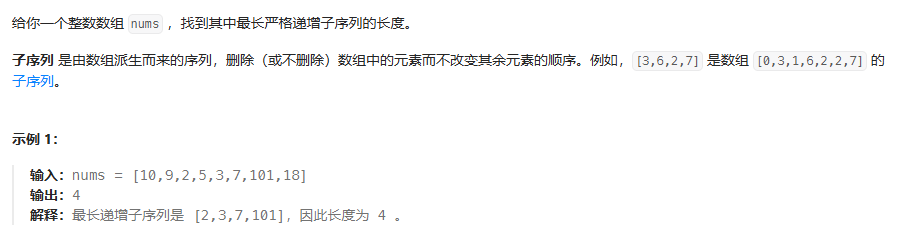
public int lengthOfLIS(int[] nums) {int n = nums.length;if (n == 0) return 0;int[] dp = new int[n]; // dp[i] 表示以 nums[i] 结尾的 LIS 长度int maxLength = 1; // 至少为 1(单个元素)for (int i = 0; i < n; i++) {dp[i] = 1; // 初始化为 1(只有自己)for (int j = 0; j < i; j++) {if (nums[j] < nums[i]) {dp[i] = Math.max(dp[i], dp[j] + 1);}}maxLength = Math.max(maxLength, dp[i]);}return maxLength;}乘积最大数组(非传统动规)
思路:从数组挑元素这种类型,都要动规自身。这种采用最大,最小变量以及结果变量,如果当前值为负,则互换最大最小值,max = Math.max(num,max*num); min = Math.min(num,min*num); result = Math.max(result,max);

public static int maxProduct(int[] nums){int n = nums.length;if(n == 0){return 0;}// 维护两个变量,最大最小int min = nums[0];int max = nums[0];int result = nums[0];for(int i =1;i<n;i++){int num = nums[i];// 当前值为负,交换最大最小值if(num < 0){int temp = max;max = min;min = temp;}max = Math.max(num,max*num);min = Math.min(num,min*num);result = Math.max(result,max);}return result;}分割等和子集
思路:看起来像0-1背包客问题,求目标和,相当于从数组中挑选元素使与之相等,挑选问题要动规自身,由因为dp[i]不能超过其自身i的值==>dp[i]<=i;因此dp[i]要与数组比较最大:dp[j] = Math.max(dp[j], dp[j - nums[i]] + nums[i]);dp[j - nums[i]]表示:在j - nums[i]的数值。最后是反向遍历,保证每个数字只能用一次。


class Solution {public boolean canPartition(int[] nums) {if(nums == null || nums.length == 0) return false;int n = nums.length;int sum = 0;for(int num : nums) {sum += num;}//总和为奇数,不能平分if(sum % 2 != 0) return false;int target = sum / 2;int[] dp = new int[target + 1];// 此处没有初始化dp数组,即全部为0for(int i = 0; i < n; i++) {// 反向遍历保证每个数字只用一次for(int j = target; j >= nums[i]; j--) {//物品 i 的重量是 nums[i],其价值也是 nums[i]dp[j] = Math.max(dp[j], dp[j - nums[i]] + nums[i]);}//剪枝一下,每一次完成內層的for-loop,立即檢查是否dp[target] == target,優化時間複雜度(26ms -> 20ms)if(dp[target] == target)return true;}return dp[target] == target;}
}
class Solution {public boolean canPartition(int[] nums) {int n = nums.length;// 如果n为0,1划分不了if (n < 2) {return false;}//如果sum为奇数,划分不了int sum = 0, maxNum = 0;for (int num : nums) {sum += num;//求数组里面的最大值maxNum = Math.max(maxNum, num);}if (sum % 2 != 0) {return false;}//判断数组最大值与sumint target = sum / 2;if (maxNum > target) {return false;}//0-1背包客 俩个数位// 在boolea中,dp没有设置,全为falseboolean[][] dp = new boolean[n][target + 1];//可以省略 从j = 0开始for (int i = 0; i < n; i++) {dp[i][0] = true;}dp[0][nums[0]] = true;// 因为i-1>0,所以 i起始为1for (int i = 1; i < n; i++) {int num = nums[i];for (int j = 1; j <= target; j++) {if (j >= num) {dp[i][j] = dp[i - 1][j] | dp[i - 1][j - num];} else {dp[i][j] = dp[i - 1][j];}}if(dp[i][target]){return true;}}return false;//return dp[n - 1][target];}
}最长有效括号
思路:

class Solution {/*** 计算最长有效括号子串的长度(动态规划解法)* @param str 包含'('和')'的字符串* @return 最长有效括号子串的长度*/public static int longestValidParentheses(String str) {char[] s = str.toCharArray();// dp[i]表示以i位置字符结尾的最长有效括号子串长度int[] dp = new int[s.length];int maxLen = 0; // 记录全局最大值// 从第1个字符开始遍历(第0个字符无法形成有效对)for (int i = 1, pre; i < s.length; i++) {// 只有遇到')'才需要处理if (s[i] == ')') {// 计算可能与当前')'匹配的'('位置pre = i - dp[i - 1] - 1;// 检查pre位置是否是'('if (pre >= 0 && s[pre] == '(') {// 核心状态转移方程:// 当前有效长度 = 前一个有效长度 + 2(当前匹配对) + pre前一段的有效长度dp[i] = dp[i - 1] + 2 + (pre > 0 ? dp[pre - 1] : 0);// 更新全局最大值maxLen = Math.max(maxLen, dp[i]);}}}return maxLen;}
}
整数拆分(力扣343)
给定一个正整数 n ,将其拆分为 k 个 正整数 的和( k >= 2 ),并使这些整数的乘积最大化。
返回 你可以获得的最大乘积 。
class Solution {public int integerBreak(int n) {//dp[i] 为正整数 i 拆分后的结果的最大乘积int[] dp = new int[n+1];dp[2] = 1;for(int i = 3; i <= n; i++) {for(int j = 1; j <= i-j; j++) {// 这里的 j 其实最大值为 i-j,再大只不过是重复而已,//并且,在本题中,我们分析 dp[0], dp[1]都是无意义的,//j 最大到 i-j,就不会用到 dp[0]与dp[1]dp[i] = Math.max(dp[i], Math.max(j*(i-j), j*dp[i-j]));// j * (i - j) 是单纯的把整数 i 拆分为两个数 也就是 i,i-j ,再相乘//而j * dp[i - j]是将 i 拆分成两个以及两个以上的个数,再相乘。}}return dp[n];}
}不同二叉搜索树(力扣96)
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
class Solution {public int numTrees(int n) {//初始化 dp 数组int[] dp = new int[n + 1];//初始化0个节点和1个节点的情况dp[0] = 1;dp[1] = 1;for (int i = 2; i <= n; i++) {for (int j = 1; j <= i; j++) {//对于第i个节点,需要考虑1作为根节点直到i作为根节点的情况,所以需要累加//一共i个节点,对于根节点j时,左子树的节点个数为j-1,右子树的节点个数为i-jdp[i] += dp[j - 1] * dp[i - j];}}return dp[n];}
}背包理论
import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);int n = scanner.nextInt();int bagweight = scanner.nextInt();int[] weight = new int[n];int[] value = new int[n];for (int i = 0; i < n; ++i) {weight[i] = scanner.nextInt();}for (int j = 0; j < n; ++j) {value[j] = scanner.nextInt();}int[][] dp = new int[n][bagweight + 1];for (int j = weight[0]; j <= bagweight; j++) {dp[0][j] = value[0];}for (int i = 1; i < n; i++) {for (int j = 0; j <= bagweight; j++) {if (j < weight[i]) {dp[i][j] = dp[i - 1][j];} else {dp[i][j] = Math.max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);}}}System.out.println(dp[n - 1][bagweight]);}
}分割子集---一维背包客解法
一维度背包客解法本质上来说就是重新覆盖原有的数组位数
| 你疑惑点 | 解答 |
|---|---|
| “价值”和“重量”都是自身? | 是的,但本题只关心是否能组成目标和,不关心价值累计,所以“价值”可以忽略,数值=重量即可 |

class Solution {public boolean canPartition(int[] nums) {if(nums == null || nums.length == 0) return false;int n = nums.length;int sum = 0;for(int num : nums) {sum += num;}//总和为奇数,不能平分if(sum % 2 != 0) return false;int target = sum / 2;int[] dp = new int[target + 1];for(int i = 0; i < n; i++) {for(int j = target; j >= nums[i]; j--) {//物品 i 的重量是 nums[i],其价值也是 nums[i]dp[j] = Math.max(dp[j], dp[j - nums[i]] + nums[i]);}//剪枝一下,每一次完成內層的for-loop,立即檢查是否dp[target] == target,優化時間複雜度(26ms -> 20ms)if(dp[target] == target)return true;}return dp[target] == target;}
}代码输入输入模型
class Solution{public static int dangli(){}public static void mian(String[] args){Scanner scanner = new Scanner();int m = scanner.nextInt();int n = sacnner.nextInt();}}多动态
不同路径
思路:
- 状态定义:dp[i][j]表示:抵达ij位置的不同路径、dp[i][j] = dp[i-1][j]+dp[i][j-1];
- 初始化 dp[0][j]= 1 dp[i][j] = 1;

class Solution {public int uniquePaths(int m, int n) {int[][] dp = new int[m+1][n+1];// 初始化for(int i = 1;i<=m;i++){dp[i][1] = 1;}for(int j =1;j<=n;j++){dp[1][j] = 1;}//计算for(int i=2;i<=m;i++){for(int j =2;j<=n;j++){dp[i][j] = dp[i-1][j]+dp[i][j-1];}}return dp[m][n];}
}最小路径和
思路:
- 背包客问题 dp[i][j]表示在ij出最小的路径和
- 公式:dp[i][j] = Math.min(dp[i-1][j],dp[i-1][j])+grid[i][j];
- 初始化 dp[i][0]= dp[i-1][0]+grid[i][0] dp[0][j] = dp[0][j-1] + grid[0][j]; dp[0][0] = grid[0][0]

class Solution {public int minPathSum(int[][] grid) {int m = grid.length; //行数int n = grid[0].length;//列数int[][] dp = new int[m][n];dp[0][0] = grid[0][0];for(int i=1;i<m;i++){dp[i][0] = dp[i-1][0]+ grid[i][0];}for(int j=1;j<n;j++){dp[0][j] = dp[0][j-1]+ grid[0][j];}for(int i=1;i<m;i++){for(int j=1;j<n;j++){dp[i][j] = Math.min(dp[i-1][j],dp[i][j-1])+grid[i][j];}}return dp[m-1][n-1];}
}最长回文子串
思路:
- 定义状态:另类动归 boolean dp[l][r] 这里的lr代表的是定点左右指针 整体表示:l与r区间是否为回文子串
- 公式:dp[l][r]为真的判定条件:(dp[l+1][r-1]为真或l-r<=2单回文和双回文)且当前s.charAt(r) == s.charAt(l) r-l+1>maxLen
- 初始化: 1<=r<s.length(),0<=l<r

class Solution {public String longestPalindrome(String s) {if (s == null || s.length() < 2) {return s;}int strLen = s.length();int maxStart = 0; //最长回文串的起点int maxEnd = 0; //最长回文串的终点int maxLen = 1; //最长回文串的长度boolean[][] dp = new boolean[strLen][strLen];for (int r = 1; r < strLen; r++) {for (int l = 0; l < r; l++) {if (s.charAt(l) == s.charAt(r) && (r - l <= 2 || dp[l + 1][r - 1])) {dp[l][r] = true;if (r - l + 1 > maxLen) {maxLen = r - l + 1;maxStart = l;maxEnd = r;}}}}return s.substring(maxStart, maxEnd + 1);}}编辑距离
思路:
- 定义状态:另类递归 dp[i][j] 字符串str1与字符串str2最小操作数
- 递归公式: 当str1[i-1] == str2[j-1] 不需要编辑 dp[i-1][j-1]
- 当str1[i-1] != str2[j-1] 需要编辑(增删改) min(dp[i-1][j],dp[i][j-1],dp[i-1][j-1])+1
- dp[i-1][j] str1删除元素 dp[i][j-1] str2删除元素==str1增加一个元素 dp[i-1][j-1] str1替换元素
- 初始化: dp[i][0] = i; dp[0][j] = j; str1 删除 i个元素变成 str2(为空) str2 删除j个元素会变成str1(str1为空)

class Solution {public int minDistance(String word1, String word2) {int m = word1.length();int n = word2.length();int[][] dp = new int[m + 1][n + 1];// 初始化边界情况for (int i = 0; i <= m; i++) {dp[i][0] = i;}for (int j = 0; j <= n; j++) {dp[0][j] = j;}// 动态规划填表for (int i = 1; i <= m; i++) {for (int j = 1; j <= n; j++) {// 计算插入、删除、替换操作的最小值dp[i][j] = Math.min(dp[i - 1][j - 1], Math.min(dp[i - 1][j], dp[i][j - 1])) + 1;// 如果字符相等,不需要替换操作if (word1.charAt(i - 1) == word2.charAt(j - 1)) {dp[i][j] = Math.min(dp[i][j], dp[i - 1][j - 1]);}}}return dp[m][n];}
}
最长公共子序列
思路:
- 另类动归 dp[i][j] 表示text1[0:i-1]和text2[0:j-1]的最长公共子序列
- 递归公式: 当text1[i-1] == text2[j-1],说明公共序列长度相等,dp[i][j] = dp[i-1][j-1] +1;
- // 当text1[i-1] != text2[j-1], dp[i][j] = Math.max(dp[i-1][j],dp[i][j-1]);
- // 这里的思路就是一个定点,一个从头循环.如果这个定点没有找到text2循环找到相同的,那么最长序列应该是上一个定点的长度。 找到text2的相同点,但在前面,dp[i][j-1]
- 初始条件: dp[i][0] = 0; dp[0][j] = 0; ==>dp 数组本身初始化就是为 0 因此不需要写代码

class Solution {public int longestCommonSubsequence(String text1, String text2) {int m = text1.length();int n = text2.length();// DP 数组:dp[i][j] 表示 text1[0...i-1] 和 text2[0...j-1] 的 LCS 长度int[][] dp = new int[m + 1][n + 1];// 逐个填充 DP 表for (int i = 1; i <= m; i++) {for (int j = 1; j <= n; j++) {if (text1.charAt(i - 1) == text2.charAt(j - 1)) {dp[i][j] = dp[i - 1][j - 1] + 1;} else {dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);}}}return dp[m][n];}
}
图论
岛屿数量

class Solution {public int numIslands(char[][] grid) {int a = 0;for (int i = 0; i < grid.length; i++) {for (int j = 0; j < grid[0].length; j++) {if (grid[i][j] == '1') { // 检查是否为陆地dao(grid, i, j); // 调用DFS,将整个岛屿标记为已访问a++; // 每发现一个新岛屿,岛屿计数加1}}}return a;}public void dao(char[][] grid, int r, int c) {// 如果超出边界,或者当前格子不是陆地,则返回if (!inArea(grid, r, c) || grid[r][c] != '1') {return;}// 标记当前格子为已访问grid[r][c] = '2';// 递归遍历上下左右四个方向dao(grid, r - 1, c); // 上dao(grid, r + 1, c); // 下dao(grid, r, c - 1); // 左dao(grid, r, c + 1); // 右}public boolean inArea(char[][] grid, int r, int c) {// 判断是否在合法范围内return 0 <= r && r < grid.length && 0 <= c && c < grid[0].length;}
}
腐烂橘子

class Solution {
public int orangesRotting(int[][] grid) {int M = grid.length;int N = grid[0].length;Queue<int[]> queue = new LinkedList<>();int count = 0; // count 表示新鲜橘子的数量for (int r = 0; r < M; r++) {for (int c = 0; c < N; c++) {if (grid[r][c] == 1) {count++;} else if (grid[r][c] == 2) {queue.add(new int[]{r, c});}}}int round = 0; // round 表示腐烂的轮数,或者分钟数while (count > 0 && !queue.isEmpty()) {round++;int n = queue.size();for (int i = 0; i < n; i++) {int[] orange = queue.poll();int r = orange[0];int c = orange[1];if (r-1 >= 0 && grid[r-1][c] == 1) {grid[r-1][c] = 2;count--;queue.add(new int[]{r-1, c});}if (r+1 < M && grid[r+1][c] == 1) {grid[r+1][c] = 2;count--;queue.add(new int[]{r+1, c});}if (c-1 >= 0 && grid[r][c-1] == 1) {grid[r][c-1] = 2;count--;queue.add(new int[]{r, c-1});}if (c+1 < N && grid[r][c+1] == 1) {grid[r][c+1] = 2;count--;queue.add(new int[]{r, c+1});}}}if (count > 0) {return -1;} else {return round;}
}
}
链表
首先记住链表是以节点的形式存在,链表循环一般用while,每次循环要根据循环条件来判断
基础代码知识
定义ListNode节点
class ListNode {int val;ListNode next;ListNode(int val) {this.val = val;}ListNode(int val, ListNode next) {this.val = val;this.next = next;}
}创捷节点
ListNode pre = new ListNode(-1);
ListNode prev = pre;创建新的链表一般有种形式
链表靠节点连接创捷 ==>prev.next = l1;
链表靠自己创建节点 ==>prev.next = new ListNode();
链表删除倒数某节点 ==>在自身连接上删除也可创建新的链表
链表复制(随机指针)
链表排序判断while的循环条件==看传递参数
多链表
&&符号 ==>while(l1 != null&&l2 !=null) ==>不需要在循环里面判断l1和l2是否为空
||符号 ==>while(l1 != null||l2 !=null) ==>需要在循环里面判断l1和l2是否为空单链表
while(head !=null && head.next !=null) ==> 用于交换节点例子
合并有序链表==>额外情况 l1长度!=l2 ==> 续接上去
两数相加 ==>额外判断while(l1 != null||l2 !=null||count !=0)
相邻节点互换==>pre.next = head; 防止出现节点为单数情况相交链表
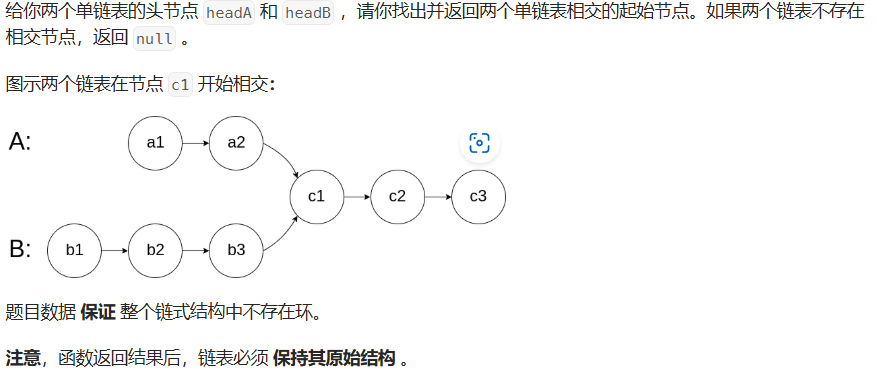
public class Solution {public ListNode getIntersectionNode(ListNode headA, ListNode headB) {if(headA == null || headB == null) return null;ListNode pA = headA,pB = headB;while(pA != pB){if (pA == null) {pA = headB; // 切换到链表B的头部} else {pA = pA.next; // 继续遍历链表A}if (pB == null) {pB = headA; // 切换到链表B的头部} else {pB = pB.next; // 继续遍历链表A}}return pA;}
}两数相加
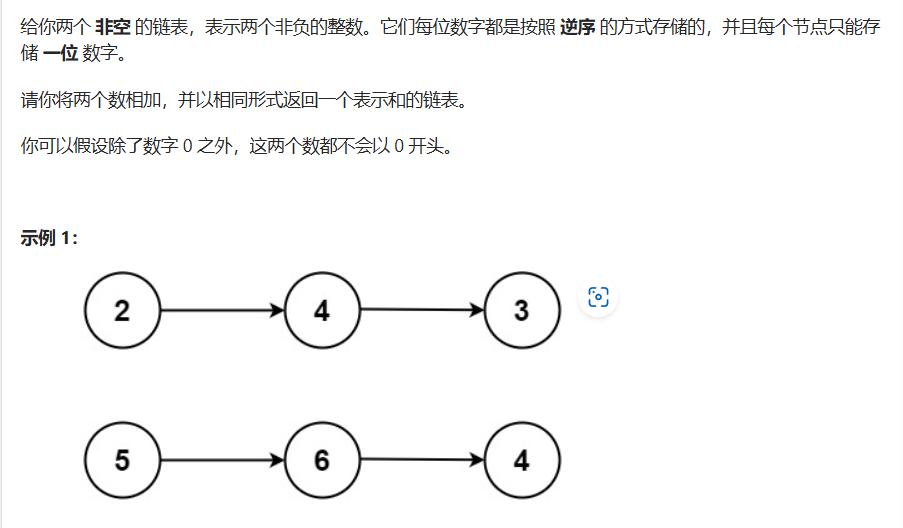
class Solution {public ListNode addTwoNumbers(ListNode l1, ListNode l2) {ListNode dummy = new ListNode(-1);ListNode cur = dummy;int count = 0;//只要存在l1或l2或count不符合条件,就继续执行while( l1!=null||l2!=null||count!=0){int sum = count;if(l1 != null){sum += l1.val;l1 = l1.next;}if(l2 != null){sum += l2.val;l2 = l2.next;}count = sum/10;cur.next = new ListNode(sum%10);cur = cur.next;}return dummy.next;}
}合并两个有序链表
class Solution{public ListNode mergeTwoLists(ListNode l1,ListNode l2){ListNode pre = new ListNode(-1);ListNode prev = pre;while(l1 != null && l2 != null){if(l1.val <= l2.val){prev.next = l1;l1 = l1.next; }else{prev.next = l2;l2 = l2.next;}prev = prev.next;}if( l1 == null){prev.next = l2;}else{prev.next = l1;}return pre.next;}
}K个一组链表反转(定点双指针+单指针循环)
思路:在while条件最后节点end不为null,遍历到k组最后end节点,断开连接,虚拟节点连接反转k组,两个链表表头连接
反转:创造虚拟节点,当前节点指向虚拟节点(断开了与下一节点的连接),当前节点转为下一节点,循环(当前节点不为null)
class Solution {public ListNode reverseKGroup(ListNode head, int k) {ListNode dummy = new ListNode(-1);dummy.next = head;ListNode pre = dummy;ListNode end = dummy;while(end.next != null){for(int i =0;i<k&&end!=null;i++){end = end.next;}if(end == null){break;}ListNode start = pre.next;ListNode start1 = end.next;end.next = null;pre.next = reverse(start);start.next = start1;pre = start;end = start;}return dummy.next;}private ListNode reverse(ListNode head) {ListNode pre = null;ListNode curr = head;while (curr != null) {ListNode temp = curr.next;curr.next = pre; //断开下一节点连接,指向虚拟节点// 指向下一节点pre = curr;curr = next;}return pre;}}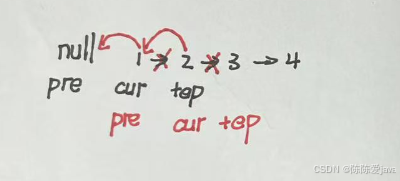
两两节点互换(单指针+循环)
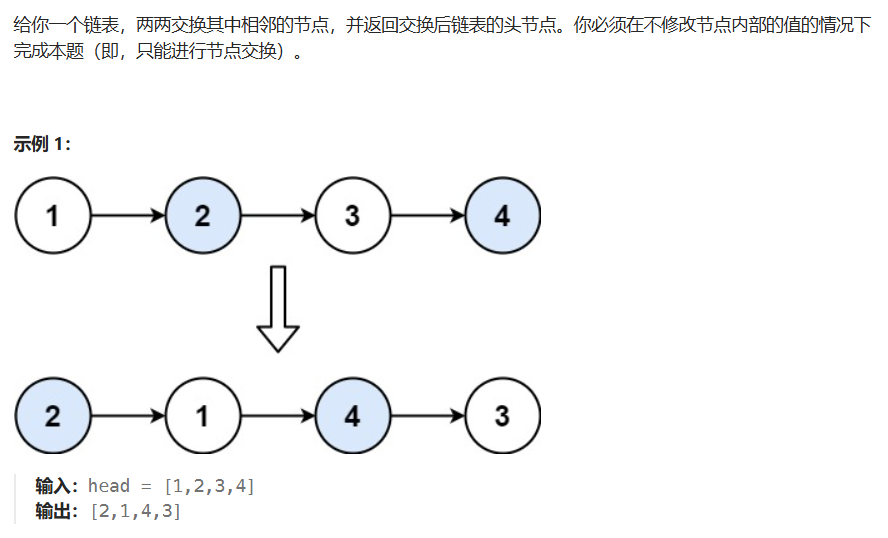
class Solution{public ListNode swapPairs(ListNode head){ListNode pre = new ListNode(-1);pre.next = head;//防止为空情况发生ListNode prev = pre;while(head !=null && head.next !=null){ListNode first = head;ListNode second = head.next;prev.next = second;first.next = second.next;second.next = first;prev =first;head = first.next;}return pre.next;}}环形链表Ⅱ(快慢指针)
思路:快慢指针确定环形是否存在,如果快慢指针重合,那么一定存在。在重合基础上,慢指针与头节点一起出发,相遇即为环形节点入口
class Solution {public ListNode detectCycle(ListNode head) {ListNode slow = head, fast = head;while (fast != null && fast.next != null) {slow = slow.next;fast = fast.next.next;//判断相遇点,是否为环形表if (fast == slow) {//判断是否为环形链路点while (slow != head) {slow = slow.next;head = head.next;}return slow;}}return null;}
}
回文链表(转数组或快慢指针+反转链表)
思路:创建列表存储节点值,遍历链接节点,取值。使用左右指针判断说法为回文链表
class Solution {public boolean isPalindrome(ListNode head) {List<Integer> vals = new ArrayList<Integer>();ListNode currentNode = head;while(currentNode != null){vals.add(currentNode.val);currentNode = currentNode.next;}int left = 0;int right =vals.size()-1;while(left < right){if (!vals.get(left).equals(vals.get(right))) {return false;}left++;right--;}return true;}
}链表复制(随机指针)
class Node {int val;Node next;Node random;public Node(int val) {this.val = val;this.next = null;this.random = null;}
}
class Solution{public Node copyRandomList(Node head){if(head == null){return null;}Node cur = head;//本质来说创建节点对应关系,牢记是两个节点//第一个节点是老的,第二个节点是新建的//一个节点包含多个键值对==>b+树类似的==>引申key为节点Map<Node,Node> map = new HashMap<>();//第一次遍历,复制节点值while(cur!=null){Node newNode = new Node(cur.val);map.put(cur,newNode);cur = cur.next;}//第二次遍历,设置节点的next和randomcur = head;//重置cur,恢复起始位置while( cur!= null){Node newNode = map.get(cur);newNode.next = map.get(cur.next);newNode.random = map.get(cur.random);cur = cur.next}return map.get(head);}
}删除链表倒数第n个节点(得链表长度跳过)
思路:先得到链表的长度,然后遍历到length-k,之后节点指向跳过此节点,curr.next = curr.next.next
class ListNode {int val;ListNode next;// 构造函数ListNode() {}ListNode(int val) {this.val = val;}ListNode(int val, ListNode next) {this.val = val;this.next = next;}
}class Solution {//思路:确定节点的链表长度,循环到那一步直接跳过public ListNode removeNthFromEnd(ListNode head, int n) {ListNode dummy = new ListNode(-1);ListNode cur = dummy;cur.next = head;ListNode temp = head;int length = 0;while(temp != null){temp = temp.next;length++;}for(int i =0;i<length - n;i++){cur = cur.next;}cur.next = cur.next.next;return dummy.next;}public static void main(String[] args) {// 构造链表:1 -> 2 -> 3 -> 4 -> 5ListNode head = new ListNode(1,new ListNode(2,new ListNode(3,new ListNode(4,new ListNode(5)))));int n = 2; // 要删除倒数第2个节点(值为4)Solution solution = new Solution();ListNode result = solution.removeNthFromEnd(head, n);// 打印删除后的链表while (result != null) {System.out.print(result.val);if (result.next != null) System.out.print(" -> ");result = result.next;}}
}
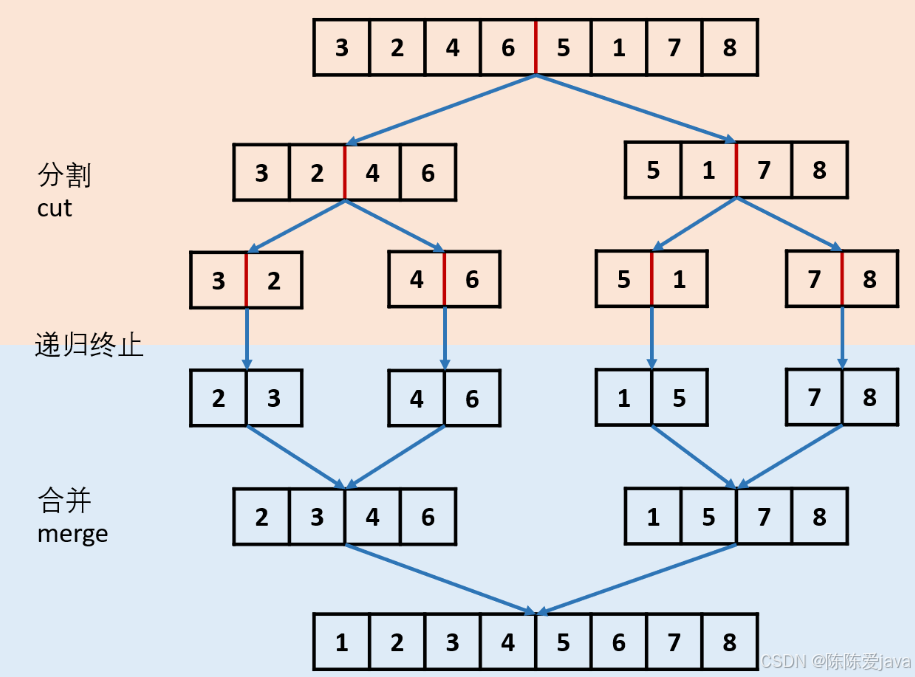
链表排序(递归法+归进算法)
思路:先使用快慢指针确定中点位置,然后中点位置断开连接,分别使用两个新链表递归,最后合并链表。
快慢指针==>一般用来确定链表中点的位置(慢指针)
ListNode fast = head.next,slow = head;
// 快慢指针寻找链表的中点
while(fast != null && fast.next != null ){slow = slow.next;fast = fast.next.next;
}得出中点位置,断开连接,为两个链表(无序)==>两个链表(有序)递归==>合并两个有序链表
class Solution{public ListNode sortList(ListNode head){//特殊情况if(head == null || head.next == null){return head;}//快慢指针寻找中点,并划分两个列表ListNode slow = head;ListNode fast = head;while( fast.next != null && fast.next.next != null){slow = slow.next;fast = fast.next.next;}ListNode tmp = slow.next;//新链表头部slow.next = null;//断开//列表递归排序ListNode left = sortList(head);ListNode right = sortList(tmp);//合并两个有序列表ListNode pre = new ListNode(-1);ListNode prev = pre;while( left!=null && right!=null){if(left.val <= right.val){prev.next = left;left = left.next;}else{prev.next = right;right = right.next;}prev = prev.next;}if(left != null){prev.next = left;}else{prev.next = right;}return pre.next; }public static void main(String[] args) {// 构建链表 4 -> 2 -> 1 -> 3ListNode head = new ListNode(4, new ListNode(2, new ListNode(1, new ListNode(3))));Solution solution = new Solution();ListNode sorted = solution.sortList(head);// 输出排序后的链表while (sorted != null) {System.out.print(sorted.val);if (sorted.next != null) System.out.print(" -> ");sorted = sorted.next;}}
}
链表排序(冒泡原链表排序)
思路:使用boolean类型作为while的循环条件,以当前节点为主,再次while循环(下个节点不为null),两两比较,大于则交换节点值。然后大while循环curr为下一节点
class ListNode {int val;ListNode next;ListNode(int val) { this.val = val; }
}public class LinkedListBubbleSort {public ListNode bubbleSort(ListNode head) {if (head == null) return null;boolean swapped = true; // 初始设为true以进入循环while (swapped) {swapped = false; // 重置交换标志ListNode curr = head;while (curr.next != null) {if (curr.val > curr.next.val) {// 交换节点值int temp = curr.val;curr.val = curr.next.val;curr.next.val = temp;swapped = true;}curr = curr.next;}}return head;}public static void main(String[] args) {// 测试代码与之前相同}
}合成K个升序链表

class Solution {// 特殊情况、划分+合并public ListNode mergeKLists(ListNode[] lists) {if (lists == null || lists.length == 0) {return null;}return merge(lists, 0, lists.length - 1);}public ListNode merge(ListNode[] lists, int left, int right) {if (left == right) {return lists[left];}int mid = left + (right - left) / 2;ListNode l1 = merge(lists, left, mid);ListNode l2 = merge(lists, mid + 1, right);ListNode dummy = new ListNode(-1);ListNode cur = dummy;while (l1 != null && l2 != null) {if (l1.val < l2.val) {cur.next = l1;l1 = l1.next;} else {cur.next = l2;l2 = l2.next;}cur = cur.next;}if (l1 != null) {cur.next = l1;} else {cur.next = l2;}return dummy.next;}
}LRU缓存
思路:定义-->双向节点,容量,虚拟节点,MAP函数(Interge,Node)
方法-->get(int key),put(key,value),getNode,remove,pushFront
双向链表节点问题
//删除某节点(本质是越过)
x.prev.next = x.next;
x.next.prev = x.prev;
//添加某节点到表头
x.prev = dummy;
x.next = dummy.next;
x.prev.next = x;
x.next.prev = x;
class LRUCache(Solution) {//双向链表+哈希+哨兵节点private static class Node{int key,value;Node prev,next;Node(int k,int v){this.key = key;this.value = value;}}//创捷全局变量private final int capacity;private final Node dummy = new Node(-1,-1);private final Map<Integer,Node> map = new HashMap<>();public LRUCache(int capacity) {this.capacity = capacity;//节点初始化dummy.prev = dummy;dummy.next = dummy;}public int get(int key) {Node node = getNode(key);if(node != null){return node.value;}else{return -1;}}public void put(int key, int value) {Node node = getNode(key);if(node != null){node.value = value;//更新值return;//不需要返回}//否则新建节点node = new Node(key,value); //为空节点赋值map.put(key,node);//添加到哈希表pushFront(node);//移动表头//判断是否超容if(map.size() > capacity){Node backNode = dummy.prev;//确定表尾节点map.remove(backNode.key);//去除哈希表尾数据remove(backNode);//链表去除尾节点}}//判断是否存在链表,存在更新表头,否则返回为空public Node getNode(int key){if(!map.containsKey(key)){//contain==>containsKey表示在key里查询return null;}//更新表头Node node = map.get(key);//确定对应的节点remove(node); //移除链表的节点pushFront(node); //更新为表头//确认存在,不为空return node; }//辅助函数//移除节点private void remove(Node node){node.prev.next = node.next;node.next.prev = node.prev;}//更新为表头private void pushFront(Node node){node.prev = dummy;node.next = dummy.next;dummy.next = node;node.next.prev = node;}public static void main(String[] args) {LRUCache cache = new LRUCache(2); // 缓存容量 2cache.put(1, 1);cache.put(2, 2);System.out.println(cache.get(1)); // 返回 1cache.put(3, 3); // 使 key 2 作废System.out.println(cache.get(2)); // 返回 -1 (未找到)cache.put(4, 4); // 使 key 1 作废System.out.println(cache.get(1)); // 返回 -1 (未找到)System.out.println(cache.get(3)); // 返回 3System.out.println(cache.get(4)); // 返回 4}
}定义ListNode节点
class ListNode {int val;ListNode next;// 构造函数ListNode() {}ListNode(int val) {this.val = val;}ListNode(int val, ListNode next) {this.val = val;this.next = next;}
}二叉树算法
基础知识
二叉树类型:
- 满二叉树:节点有两个子节点,且每一层都填满
- 完全二叉树:左顺序二叉树,每一层节点从最左节点依次开始
- 二叉搜索树:有序二叉树,节点的左子树节点<节点值<节点的右子树节点
- 平衡二叉搜索树:二叉搜索树+平衡(左右子树高度差<=1)
存储方式:链表/数组
遍历方式:
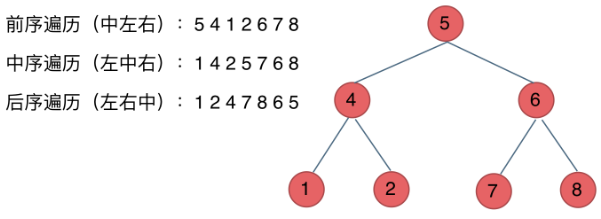
深度优先遍历DFS(递归法,迭代法):先往深处走,遇到空节点再往回走 数据结构:栈,先进后出(递归法,迭代法)
- 前序遍历:中左右
- 中序遍历:左中右
- 后序遍历:左右中
观察:前中后,分别对应中的位置不同,其次一左一右;
广度优先遍历BFS(迭代法):一层一层遍历 数据结构:队列 先进先出
- 层次遍历
节点定义
class TreeNode{int val;TreeNode left,right;TreeNode(){}TreeNode(int val){this.val = val;}TreeNode(int val,TreeNode left,TreeNode right){this.val = val;this.left = left;this.right = right;}}算法思路:
- 确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
- 确定终止条件: 写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
- 确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
DFS
二叉树的前中后序遍历
public List<Integer> inorderTraversal(TreeNode root){// 1.递归参数和返回值 入参 root 出参 resList<Integer> res = new ArrayList<Integer>();inorder(root,res);return res;}public void inorder(TreeNode root,List<Integer> res){// 2.终止条件 遇到节点if(root == null){return;}// 3.单层递归逻辑res.add(root.val); // 前序遍历inorder(root.left, res);
// res.add(root.val); // 中序遍历inorder(root.right,res);
// res.add(root.val); // 后序遍历}二叉树的最大深度
返还数值的一般都是全局单独定义
private int ans = 0;public int maxDepth(TreeNode root){// 1.递归的入参和出参dfs(root,0);return ans;}public void dfs(TreeNode root,int depth){// 2.终止条件if(root == null){return;}// 3。单层递归逻辑depth++;ans = Math.max(ans,depth);dfs(root.left,ans);dfs(root.right,ans);}翻转二叉树
public TreeNode invertTree(TreeNode root){dfs(root);return root;}public void dfs(TreeNode root){if(root == null){return;}// 节点互换TreeNode temp = root.left;root.left = root.right;root.right = temp;// 递归dfs(root.left);dfs(root.right);}对称二叉树
public boolean isSymmetric(TreeNode root){if(root == null){return true;}else {return dfs(root.left,root.right);}}public boolean dfs(TreeNode left,TreeNode right){if(left == null && right == null){return true;}if(left == null || right == null || left.val!=right.val){return false;}return dfs(left.right,right.left) && dfs(left.left,right.right);}二叉树直径
思路:
private int ans;public int diameterOfBinaryTree(TreeNode root){dfs(root);return ans;}private int dfs(TreeNode root){if(root == null){return -1;}int leftLen = dfs(root.left)+1;int rightLen = dfs(root.right)+1;ans = Math.max(ans,leftLen+rightLen);return Math.max(leftLen,rightLen);}有序数组转二叉搜索树(前序遍历)
思路:
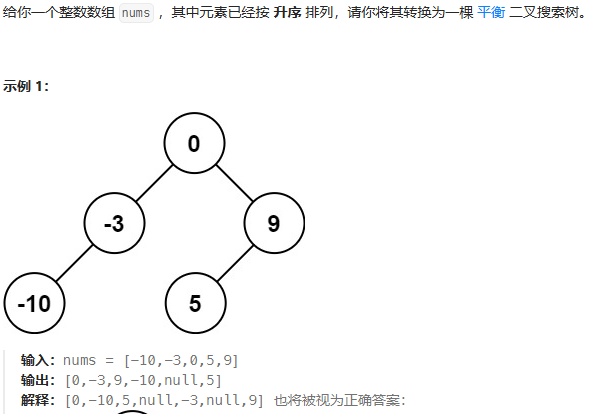
public TreeNode sortedArrayToBST(int[] nums){return dfs(nums,0,nums.length-1);}public TreeNode dfs(int[] nums,int left,int right){if(left > right){return null;}int mid = left+(right-left)/2;TreeNode root = new TreeNode(nums[mid]);root.left = dfs(nums,left,mid-1);root.right = dfs(nums,mid+1,right);return root;}验证二叉搜索树
思路:
class Solution {public boolean isValidBST(TreeNode root) {return dfs(root, null, null); // 初始时无边界限制}private boolean dfs(TreeNode node, Integer min, Integer max) {if (node == null) {return true;}// 检查当前节点值是否在 (min, max) 范围内if ((min != null && node.val <= min) || (max != null && node.val >= max)) {return false;}// 递归检查左子树(最大值限制为当前节点值)// 递归检查右子树(最小值限制为当前节点值)return dfs(node.left, min, node.val) && dfs(node.right, node.val, max);}
}二叉搜索树第k小的树
思路:将二叉树转化为数组,并对数组排序,遍历数组到k-1(从0索引)位置;
k--与--k前者先比较后减 后者先减后比较
应该是利用搜索树特性
class Solution {// 用一个列表按顺序存储遍历到的节点值List<Integer> res = new ArrayList<>();public int kthSmallest(TreeNode root, int k) {// 直接中序遍历整棵树,把结果存起来inOrderTraversal(root);// 因为中序遍历结果是升序的,所以第k小的就是列表里第k-1个位置的数return res.get(k - 1);}// 标准的中序遍历函数private void inOrderTraversal(TreeNode node) {if (node == null) {return;}// 1. 先遍历左子树inOrderTraversal(node.left);// 2. 再访问当前节点(把值加到列表里)res.add(node.val);// 3. 最后遍历右子树inOrderTraversal(node.right);}
}路径和Ⅲ
思路:把每个节点都当作根节点,根节点向下递归寻找符合条件的单边和
双递归
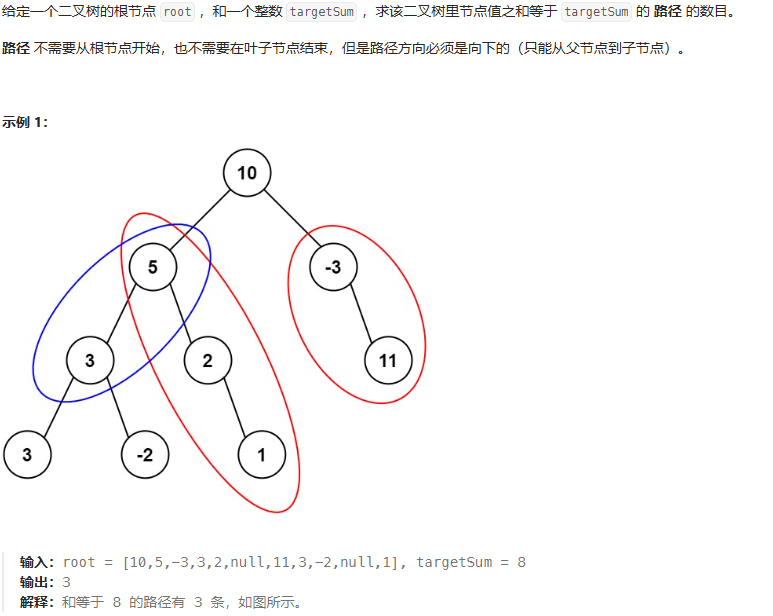
class Solution {public int pathSum(TreeNode root, long targetSum) {if(root == null){return 0;}int ret = rootSum(root,targetSum);ret += pathSum(root.left, targetSum);ret += pathSum(root.right, targetSum);return ret;}public int rootSum(TreeNode root ,long targetSum){int ret = 0;if(root == null){return 0;}int sum = root.val;if(sum == targetSum){ret++;}ret += rootSum(root.left, targetSum - sum);ret += rootSum(root.right, targetSum - sum);return ret;}}二叉树最近公共先祖
思路:确认节点的左右单边是否包含p或q节点,包含则返回该节点,否则返回为空。
因为单边找不到只能向下继续递归,可已经走到头了,没有节点了,所以其左右子节点为空返回。

class Solution {public TreeNode lowestCommonAncestor(TreeNode root,TreeNode p,TreeNode q){return dfs(root,p,q);}public TreeNode dfs(TreeNode node, TreeNode p, TreeNode q){// 隐含了如果找不到对应的p,q节点就返还为空// 因为找不到,就会向下继续左右子节点,但二者或单者不存在,因此就返还为空if(node == null){return null;}// 确定p,q所在的节点if(node.val == q.val || node.val == p.val){return node;}TreeNode left = dfs(node.left,p,q);TreeNode right = dfs(node.right,p,q);// 返还公共祖先if( left != null && right != null){return node;}// 返还单边值if(left != null){return left;}else {return right;}}
}二叉树最大路径和
思路:最大路径和,返还的是int 类型的数,可以定义一个全局变量。确认单边最大值,要与0比较,防止出现负数。当前节点左右单边的最大路径,返回最大左右单边值+当前节点值。
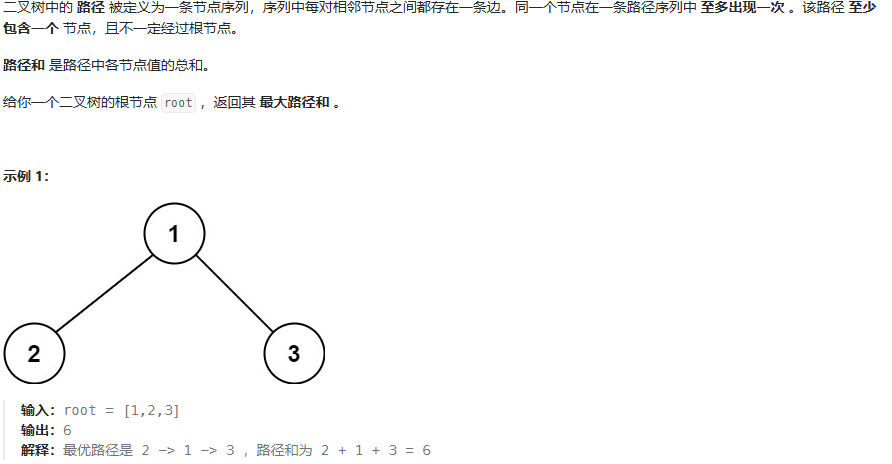
class Solution {public int max = Integer.MIN_VALUE;public int maxPathSum(TreeNode root){dfs(root);return max;}public int dfs(TreeNode root){if(root == null){return 0;}// 递归计算左右子树的最大贡献值(如果为负则舍弃)int left = Math.max(0,dfs(root.left));int right = Math.max(0,dfs(root.right));// 更新全局最大值(当前节点 + 左右子树)int currentMax = root.val+left+right;max = Math.max(max,currentMax);// 返回当前节点的最大贡献值(只能选择左或右子树的一条路径)return root.val+Math.max(left,right);}
}BFS
适用场景:「层序遍历」、「最短路径」
// 二叉树的层序遍历
void bfs(TreeNode root) {Queue<TreeNode> queue = new ArrayDeque<>();queue.add(root);while (!queue.isEmpty()) {int n = queue.size();for (int i = 0; i < n; i++) { // 变量 i 无实际意义,只是为了循环 n 次TreeNode node = queue.poll();if (node.left != null) {queue.add(node.left);}if (node.right != null) {queue.add(node.right);}}}
}二叉树层序遍历
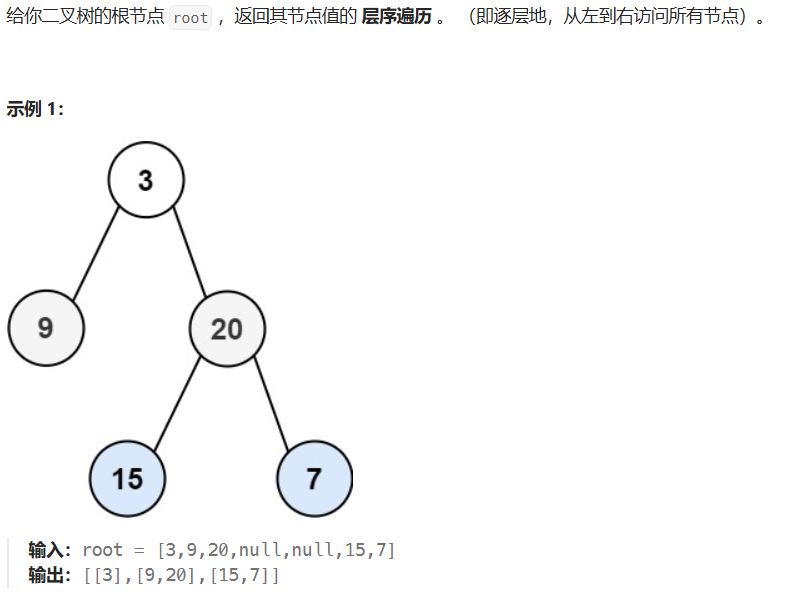
public List<List<Integer>> levelOrder(TreeNode root){List<List<Integer>> res = new ArrayList<>();Queue<TreeNode> queue = new ArrayDeque<>();if(root != null){queue.add(root);}while (!queue.isEmpty()){int n = queue.size();List<Integer> level = new ArrayList<>();for(int i =0;i<n;i++){TreeNode node = queue.poll();level.add(node.val);if(node.left!=null){queue.add(node.left);}if(node.right!=null){queue.add(node.right);}}res.add(level);}return res;}
二叉树最短路径
回溯算法
全排列
思路:
回溯 定义 | 入参类型:int[] nums,int nums.length,int depth,boolean[] used(初始化为false),List<Integer> path 出参类型:因为还要再写一个调用dfs所有定义一个全局出参变量 |
终止 条件 | depth == length res.add(new ArrayList(path)) |
回溯 遍历 | 递归遍历:遍历nums的每个元素,将当前元素添加到path,并将其对应的used改为true,dfs递归 回溯撤销:当前元素对应的为false,移除元素 |
理解 | [1,2,3]变成[1,3,2]的过程 第一次循环(i=1),递归到第二次循环(i=2,因为used(i=1)=true),递归到第三次循环(i=3,因为used(i=2)=true),第四次递归,无循环depth == len,res.add();开始回溯撤销,第三次循环:used(i=3)=false,继续回到第二次循环used(i=2)=false,开始i=2 -- >i=3;从1-3-2 |

public List<List<Integer>> res = new ArrayList<>();public List<Integer> path = new ArrayList<>();public List<List<Integer>> permute (int[] nums){int length = nums.length;boolean[] used = new boolean[length];List<Integer> path = new ArrayList<>();dfs(nums,length,0,used);return res;}public void dfs(int[] nums,int len,int depth,boolean[] used){if(depth == len){res.add(new ArrayList(path));return;}for(int i=0;i<len;i++){if(!used[i]){path.add(nums[i]);used[i] = true;dfs(nums,len,depth+1,used);used[i] = false;path.remove(path.size()-1);}}}子集
思路:
思路 | 选中和没选中回溯递归 |
回溯定义 | 入参类型:int[] nums,len,0,path 出参类型:list<list<integer>> res |
终止条件 | depth == len |
回溯遍历 | 递归遍历:没有选中dfs(depth+1) 选中dfs(depth+1) path.add(nums[depth]) 回溯撤销:path.remove |

List<List<Integer>> res = new ArrayList<>();List<Integer> path = new ArrayList<>();public List<List<Integer>> subsets(int[] nums){int length = nums.length;dfs(nums,length,0);return res;}public void dfs(int[] nums,int len,int depth){if(depth == len){res.add(new ArrayList<>(path));return;}// 没有选中dfs(nums,len,depth+1);// 选中path.add(nums[depth]);dfs(nums,len,depth+1);path.remove(path.size()-1);}电话号码的字母组合
思路:
回溯定义 | 入参类型:char[] digitsChars,List<string> ans,0,char[] path 出参类型:list<string> ans |
终止条件 | depth == digitsChars.length ans.add(new string(path)) |
回溯遍历 | 递归遍历: for(char c:MAPPING[digitChars[depth]-'0'].toCharArray()) 回溯撤销: 这个不需要回溯,直接覆盖原本值 |

class Solution{private String MAPPING[] = new String[]{"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};public List<String> letterCombinations(String digits){int n = digits.length();if(n == 0){return List.of();}List<String> ans = new ArrayList<>();char[] path = new char[n];char[] digitChars = digits.toCharArray();dfs(digitChars,ans,path,0);return ans;}private void dfs(char[] digitChars, List<String> ans,char[] path,int depth){if(depth == digitChars.length){ans.add(new String(path));return;}for(char c:MAPPING[digitChars[depth]-'0'].toCharArray()){path[depth] = c;dfs(digitChars,ans,path,depth+1);}}}组合总和
思路:
| 思路 | 起始点 向下遍历 |
| 回溯定义 | 入参类型:res,path,sum,起始点 start,candidates,target 出参类型:res |
| 终止条件 | 此处有点特殊 sum == target 终止并res.add sum > target 只终止 |
| 回溯遍历 | 递归遍历:从起始点向下递归,start<=i<candidates.length , dfs(,i,sum+candidates[i],) 回溯撤销:path.remove(path.size()-1) |

List<List<Integer>> res = new ArrayList<>();List<Integer> path = new ArrayList<>();public List<List<Integer>> combinationSum(int[] candidates,int target){if(candidates.length == 0){return List.of();// 是返回系列为null}dfs(0,0,candidates,target);return res;}public void dfs(int sum,int start,int[] candidates,int target){if(sum == target){res.add(new ArrayList<>(path));return;}if(sum > target){return;}// 此处之所以是start,是因为向下遍历,防止重复for(int i = start;i<candidates.length;i++){path.add(candidates[i]);dfs(sum+candidates[i], i, candidates, target);path.remove(path.size()-1);}}分割回文串
思路:
回溯定义 | 全局变量:res,path 入参类型:s,start 出参类型:res |
终止条件 | start == length res.add |
回溯遍历 | 递归遍历:for(int i =start;i<s.length();i++) // 如果是回文子串,继续向下递归 // path.add(s.substring(start,i+1)); // dfs(s,i+1); 回溯撤销:path.remove(path.size()-1); 回文子串:已知字符串的范围,从两边向内递归 // s.charAt(left++) != s.charAt(right--) |

public List<List<String>> res = new ArrayList<>();public List<String> path = new ArrayList<>();public List<List<String>> partition(String s) {dfs(s,0);return res;}public void dfs(String s,int start){if(start == s.length()){res.add(new ArrayList<>(path));return;}for(int i =start;i<s.length();i++){if(huiwen(s,start,i)){path.add(s.substring(start,i+1));dfs(s,i+1);path.remove(path.size()-1);}}}public boolean huiwen(String s,int left,int right){while (left<right){if(s.charAt(left++) != s.charAt(right--)){return false;}}return true;}
贪心算法
贪心的本质是:选择每一阶段的局部最优,从而达到全局最优
做题的时候,只要想清楚 局部最优 是什么,如果推导出全局最优,其实就够了。
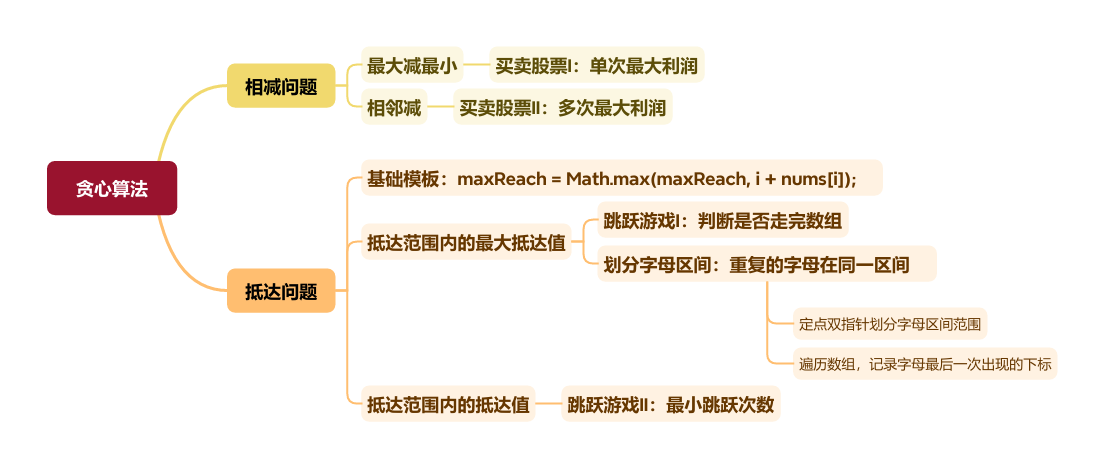
相减问题(怎么相减利润最大化)
买卖股票的最佳实际
思路:如果第i天卖出股票,则最大利润为(该天的股价-前面天数中最小的股价),然后与已知的最大利润比较,如果大于则更新当前最大利润的值
只要找到一个最低买入价
minPrice,然后在后面找到最大差价。遍历价格数组,同时维护:
当前最小价格
minPrice当前最大利润
maxProfit = max(maxProfit, prices[i] - minPrice)

class Solution {public int maxProfit(int[] prices) {// 初始化最大利润为0,最低价格为第一个价格int maxProfit = 0;int minPrice = 100000;// 遍历价格数组for (int price : prices) {// 更新最低价格minPrice = Math.min(minPrice, price);// 更新最大利润maxProfit = Math.max(maxProfit, price - minPrice);}return maxProfit;}
}
买卖股票的最佳实际Ⅱ
遍历整个股票交易日价格列表 price,并执行贪心策略:所有上涨交易日都买卖(赚到所有利润),所有下降交易日都不买卖(永不亏钱)。
- 设 tmp 为第 i-1 日买入与第 i 日卖出赚取的利润,即 tmp = prices[i] - prices[i - 1] ;
- 当该天利润为正 tmp > 0,则将利润加入总利润 profit;当利润为 0 或为负,则直接跳过;
- 遍历完成后,返回总利润 profit。
等价于每天都与前一天做交易,赚才去买

class Solution {public int maxProfit(int[] prices) {int profit = 0;for (int i = 1; i < prices.length; i++) {int tmp = prices[i] - prices[i - 1];if (tmp > 0) profit += tmp;}return profit;}
}
抵达问题(抵达范围内是否出现更大的抵达范围)
跳跃游戏
此处i比较“原本范围内出现的最大抵达值”,由原本起始点字母出现的最大抵达范围一直在更新
思路:就是从起点出发,能够达到的最大点位,如果小于抵达不了则错误
- 如果某一个作为 起跳点 的格子可以跳跃的距离是 3,那么表示后面 3 个格子都可以作为 起跳点
- 可以对每一个能作为 起跳点 的格子都尝试跳一次,把 能跳到最远的距离 不断更新
- 如果可以一直跳到最后,就成功了

class Solution {public boolean canJump(int[] nums) {int maxReach = 0; // 记录能到达的最远索引int n = nums.length;for (int i = 0; i < n; i++) {// 如果当前位置 i 已经超出最大可达范围,则说明无法继续前进if (i > maxReach) {return false;}// 更新最大可达范围maxReach = Math.max(maxReach, i + nums[i]);// 如果最大可达范围已经超过或等于最后一个索引,则返回 trueif (maxReach >= n - 1) {return true;}}return false;}
}
跳跃游戏Ⅱ(判断跳不跳)
此处i比较“原本出现范围的最大值”
思路:注意这个肯定是可以抵达到的 所以不需要判断 i > maxReach 无法抵达情况
可以这样想:判断当前节点能够抵达最大范围,在这范围内都要可以跳跃的,只有抵达范围边界,才会jumps加1, // 并选取当前节点抵达范围内的范围节点最大抵达范围,如果最大抵达范围大于nums.length长度,返回jumps
维护两个变量:
curEnd:当前跳跃可达的最远边界。curFarthest:在当前跳跃范围内能到达的最远位置。
从左到右遍历数组(不包含最后一个元素,因为到达最后一个元素就结束):
- 不断更新
curFarthest = max(curFarthest, i + nums[i])。 - 当
i到达curEnd时,说明当前跳跃范围已经用完,需要增加一次跳跃次数jumps++,并更新curEnd = curFarthest。
如果 curEnd 已经到达或超过末尾,返回 jumps。
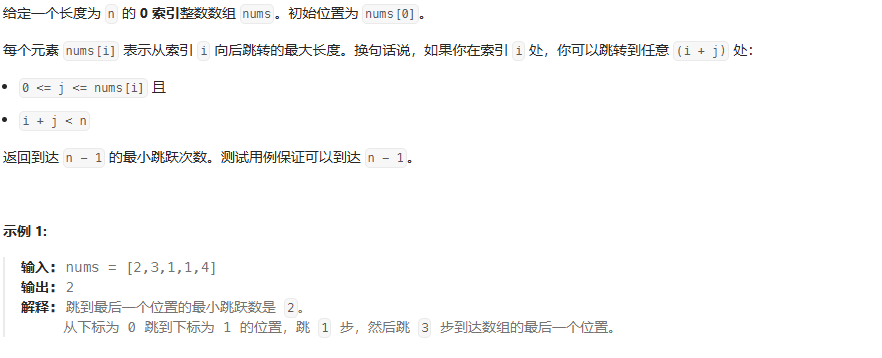
public int jump(int[] nums) {int jumps = 0;int curEnd = 0;int curFarthest = 0;for (int i = 0; i < nums.length - 1; i++) {curFarthest = Math.max(curFarthest, i + nums[i]);if (i == curEnd) { jumps++;curEnd = curFarthest;if (curEnd >= nums.length - 1) {break;}}}return jumps;
}
划分字母区间
此处i比较“原本范围内出现的最大抵达值”,由原本起始点字母出现的最大抵达范围一直在更新
思路: 重复的字母只能出现在同一区间,那么建立字母表,记录字母出现的最大下表。就可以将问题转为抵达问题 // 即使在抵达范围内的元素出现了更大的抵达值,就直到指针到达该最大抵达值位置

public List<Integer> partitionLabels(String s){char[] sChar = s.toCharArray();int n = s.length();int[] last = new int[26];for(int i = 0;i<n;i++){last[sChar[i] - 'a'] = i;// 每个字母出现的最后下标}List<Integer> ans = new ArrayList<>();int left = 0;int right = 0;for(int i =0;i<n;i++){right = Math.max(right,last[sChar[i]-'a']); // 当前字母可以抵达最大范围if(i == right){ans.add(right-left+1);left = right+1;}}return ans;}矩阵
堆
数组中第K个最大元素

public int findKthLargest(int[] nums, int k) {int n = nums.length;// 转换为找第n-k小的元素(从0开始)return quickselect(nums, 0, n - 1, n - k);}// 使用Hoare分区方案的快速选择算法private int quickselect(int[] nums, int left, int right, int k) {if (left == right) return nums[k]; // 基线条件// 随机选择pivot避免最坏情况int pivotIndex = left + new Random().nextInt(right - left + 1);int pivotValue = nums[pivotIndex];// 分区 每次循环只交换一次// 初始化左右指针int i = left - 1, j = right + 1;while (i < j) {// 从左找到第一个不小于pivot的元素do i++; while (nums[i] < pivotValue); // 先执行循环体,再检查条件// 从右找到第一个不大于pivot的元素do j--; while (nums[j] > pivotValue);// 交换这两个元素if (i < j) {int tmp = nums[i];nums[i] = nums[j];nums[j] = tmp;}}// 根据k的位置决定处理哪一部分// j停止的位置就是小于midValue范围if (k <= j) {return quickselect(nums, left, j, k);} else {return quickselect(nums, j + 1, right, k);}}快排解法(随机选元素)
private Random rand = new Random();public int findKthLargest (int[] nums,int k){int n = nums.length;return quickSelect(nums,0,n-1,n-k);}private int quickSelect(int[] nums,int left,int right,int targetIndex){int pivotIndex = partiton(nums,left,right);if(pivotIndex == targetIndex){return nums[pivotIndex];}else if(pivotIndex > targetIndex){return quickSelect(nums,left,pivotIndex-1,targetIndex);}else {return quickSelect(nums, pivotIndex+1, right, targetIndex);}}private int partiton(int[] nums,int left,int right){int pivotIndex = left + rand.nextInt(right-left+1); // 随机选取节点int pivotValue = nums[pivotIndex]; // 该节点值swap(nums,pivotIndex,right); // 将该值放到末尾int storeIndex = left;for(int i = left;i<right;i++){ // 单指针划分小于/大于pivotValue区间if(nums[i]<pivotValue){swap(nums,storeIndex,i);storeIndex++;}}swap(nums,storeIndex,right); // 再把中位值互换回来return storeIndex;}private void swap(int[] nums,int i,int j){int temp = nums[i];nums[i] = nums[j];nums[j] = temp;}
这个不太行,标准应该是快速排序
public int findKthLargest(int[] nums, int k) {// 1. 定义桶数组,大小 20001,表示存储 [-10000, 10000] 范围内的整数频率int[] buckets = new int[20001];int n = nums.length;// 2. 统计每个数字出现的次数for (int i = 0; i < n; i++) {// nums[i] + 10000 是为了将负数映射到 0~20000 的索引范围buckets[nums[i] + 10000]++;}// 3. 从大到小遍历桶(即从最大值到最小值)for (int i = 20000; i >= 0; i--) {// 每访问一个桶,就相当于从最大值开始往下数 k 个k -= buckets[i];if (k <= 0) {// 桶索引还原为原值:i - 10000return i - 10000;}}return 0; // 理论上不会走到这里
}
快速排序
递归+分区+互换值
// 分治快排
class QuickSort {public void quickSort(int[] nums, int left, int right) {if (left >= right) return; // 递归结束条件 索引int pivotIndex = partition(nums, left, right); // 找到 pivot 位置quickSort(nums, left, pivotIndex - 1); // 排序左半部分quickSort(nums, pivotIndex + 1, right); // 排序右半部分}// 分区函数private int partition(int[] nums, int left, int right) {int pivot = nums[right]; // 选取最后一个元素作为 pivotint i = left; // i 指向比 pivot 小的区域的末尾for (int j = left; j < right; j++) {if (nums[j] < pivot) { // 如果当前元素比 pivot 小swap(nums, i, j);i++;}}swap(nums, i, right); // pivot 放到中间return i; // 返回 pivot 位置}// 交换值函数private void swap(int[] nums, int i, int j) {int temp = nums[i];nums[i] = nums[j];nums[j] = temp;}// 测试public static void main(String[] args) {int[] arr = {3, 6, 8, 10, 1, 2, 1};QuickSort qs = new QuickSort();qs.quickSort(arr, 0, arr.length - 1);for (int num : arr) {System.out.print(num + " ");}}
}
栈
Stack<Integer> stack = new Stack<>();有效括号

class Solution {public boolean isValid(String s) {//特殊情况if(s.isEmpty()){return true;}//创建栈,字符类型Stack<Character> stack = new Stack<Character>();for(char c:s.toCharArray()){if(c == '('){stack.push(')');}else if(c == '{'){stack.push('}');}else if(c=='['){stack.push(']');}// 要先判断是否为空,再判断出栈else if(stack.empty() || c!=stack.pop()){return false;}}if(stack.empty()){return true;}return false;}
}每日温度
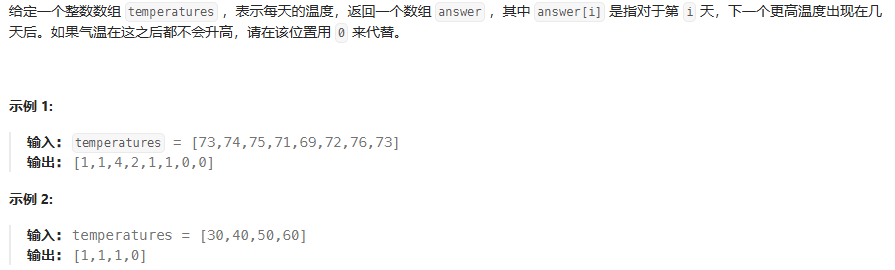
stack.peek() 返回栈顶元素,但不弹出(空栈会抛出异常)
class Solution {public int[] dailyTemperatures(int[] temperatures) {int n = temperatures.length;int[] result = new int[n];Stack<Integer> stack = new Stack<>(); // 单调递减栈,存索引for (int i = 0; i < n; i++) {// 如果当前温度比栈顶索引的温度高,则计算等待天数while (!stack.isEmpty() && temperatures[i] > temperatures[stack.peek()]) {int prevIndex = stack.pop();result[prevIndex] = i - prevIndex;}// 当前索引入栈stack.push(i);}return result;}
}
字节面试题
多线程交替打印0-100
2个线程交替打印0-100
public class Main {private static final Object LOCK = new Object();private static volatile int count = 0;private static final int MAX = 100;public static void main(String[] args) {Thread thread = new Thread(new Seq(0));Thread thread1 = new Thread(new Seq(1));thread.start();thread1.start();}static class Seq implements Runnable {private final int index;public Seq(int index) {this.index = index;}@Overridepublic void run() {// Run方法只要执行结束了,线程就结束了while (count < MAX) {// 同步代码块,一个时刻只能有一个线程获取到锁synchronized (LOCK) {// 获取到锁就进来判断,当前是否轮到该线程打印while (count % 2 != index) {// 不是当前线程打印,那么就让当前线程去wait,它会自动释放锁,所以其他线程可以进来try {LOCK.wait();// 当线程被唤醒时,会尝试重新进入synchronized代码块} catch (Exception e) {e.printStackTrace();}}// 是当前线程打印, 但count>MAXif (count > MAX) {LOCK.notifyAll();return;}System.out.println("Thread-" + index + ":" + count);count++;LOCK.notifyAll();}}}}
}
public class Main {private static final Object LOCK = new Object();private static volatile int count = 0;private static final int MAX = 100;public static void main(String[] args) {Thread thread = new Thread(new Seq(0));Thread thread1 = new Thread(new Seq(1));Thread thread2 = new Thread(new Seq(2));thread.start();thread1.start();thread2.start();}static class Seq implements Runnable {private final int index;public Seq(int index) {this.index = index;}@Overridepublic void run() {// Run方法只要执行结束了,线程就结束了while (count < MAX) {// 同步代码块,一个时刻只能有一个线程获取到锁synchronized (LOCK) {// 获取到锁就进来判断,当前是否轮到该线程打印while (count % 3 != index) {// 不是当前线程打印,那么就让当前线程去wait,它会自动释放锁,所以其他线程可以进来try {LOCK.wait();// 当线程被唤醒时,会尝试重新进入synchronized代码块} catch (Exception e) {e.printStackTrace();}}// 是当前线程打印, 但count>MAXif (count > MAX) {LOCK.notifyAll();return;}System.out.println("Thread-" + index + ":" + count);count++;LOCK.notifyAll();}}}}
}多线程交替打印ABC
import java.util.concurrent.Semaphore;
// 多线程打印ABC
public class Printer {private final Semaphore semA = new Semaphore(1); // 信号量A设置为1,从A开始打印private final Semaphore semB = new Semaphore(0);private final Semaphore semC = new Semaphore(0);private static int n = 3; // 打印轮次public static void main(String[] args) {Printer printer = new Printer();new Thread(()->printer.print('A',printer.semA,printer.semB)).start();new Thread(()->printer.print('B',printer.semB,printer.semC)).start();new Thread(()->printer.print('C',printer.semC,printer.semA)).start();}public void print(char ch, Semaphore current, Semaphore next) {try {for (int i = 0; i < n; i++) {current.acquire(); // 获取当前信号量System.out.println(Thread.currentThread().getName() + ": " + ch);next.release(); // 释放下一个信号量}} catch (InterruptedException e) {e.printStackTrace();}}
}奇偶交换
给定数组,奇数在前,偶数在后
import java.util.Arrays;
public class Solution {public static int[] jiaohuang(int[] nums){if(nums.length<2||nums == null){return nums;}int left = 0;int right = nums.length-1;while (left<right){// 选定偶数while (left<right && nums[left] % 2 !=0){left++;}// 选定奇数while (left<right && nums[right]%2 == 0){right--;}if(left < right){int temp = nums[left];nums[left] = nums[right];nums[right] = temp;left++;right--;}}return nums;}public static void main(String[] args){Solution solution = new Solution();int[] nums = {1,2,3,4};int[] result = solution.jiaohuang(nums);System.out.print(Arrays.toString(nums));}
}
字典序的第k小数字

// 字典序:数字的前缀进行排序,如10<9,因为10的前缀是1<9
// 数组{1,2,-,9,10,11,12}-->{1,10,11,12,2,--,9}
// 思路:当前指针+前缀数(非指针概念),当成一个(key,value)形式,cur为key,value = 前缀数
// 如果当前指针<目标指针,while循环,
// 计算当前数的节点数(如1-201,那么在1和2之间隔着10-19,100-199:节点数为1+10+10*10)
// 如果 当前指针 + 当前前缀节点 <=k,即不在k的范围内,那么当前指针(下个前缀节点) = 当前指针 + 当前前缀节点,前缀数++
// else,在k的范围内,那么当前指针 = cur指针+1,前缀数*10更加细分
//(其实这里有点无限迭代的意思,判断在10-19区间还是继续细分在100-109~190-199区间,但n是固定的,有限迭代)
public int findKthNumber(int n, int k) {long cur = 1; // 当前指针对应long prix = 1; // 当前前缀数,可以把当成一个(key,value)形式,cur为key,value = 前缀数while (cur < k){long prixNum = getCount(prix,n);// 当前前缀节点数量// k不在当前前缀数if(cur+prixNum <= k){cur+=prixNum; // 下个指针 = 当前指针+节点数prix++; // 前缀数++}else {cur++; // 在当前前缀循环,从1变成10,指针从索引0(1)到索引1(10)prix*=10; // 前缀细分}}return (int)prix;}// 当前前缀下的所有子节点数总和=下一个前缀的起点-当前前缀的起点public long getCount(long prix,long n){long count = 0;// 节点数量long prixNext = prix+1; // 下一个前缀数while (prix <= n){count += Math.min(n-1,prixNext)-prix;prix*=10;prixNext*=10;}return count;}


)
的全流程深度解析)

)






:ChatClient详解,优雅的流式API设计)
预处理详解)
)


