TRAE调教指南:用6A工作流项目规则+5S敏捷个人规则打造高效AI开发流程
- 引言:从"AI瞎写"到"精准交付"的实战手册
- 一、什么是Rules:让AI"听话"的底层逻辑
- 1. 告别重复指令疲劳
- 2. 实现"千人千面"的个性化适配
- 3. 构建"项目级"的约束边界
- 二、TRAE规则配置使用指南:从"配置"到"生效"的全流程
- 三、6A工作流项目规则:给AI套上"项目管理紧箍咒"
- 1. 6A工作流项目规则介绍
- 阶段1:Align(对齐)
- 阶段2:Architect(架构)
- 阶段3:Atomize(原子化)
- 阶段4:Approve(审批)
- 阶段5:Automate(自动化执行)
- 阶段6:Assess(评估)
- 2. 附6A工作流项目规则:project_rules.md(即拿即用)
- 四、5S敏捷开发个人规则:让自己成为"AI驯兽师"
- 1. 5S敏捷开发个人规则介绍
- 1S:文档管理(核心中的核心)
- 2S:开发流程(顺序化思考,拒绝跳步)
- 3S:问题解决(官方文档是爹,搜索引擎是儿子)
- 4S:执行约束(三大"绝不允许")
- 5S:环境与输出(细节决定成败)
- 2.附5S敏捷开发个人规则:user_rules.md(即拿即用)
- 五、6A+5S协同:1+1>10的实战效果
- 六、常见问题
- 结语:从"被AI带跑"到"驾驭AI"
引言:从"AI瞎写"到"精准交付"的实战手册
最近带团队做一个电商后台重构,让AI帮忙开发用户权限模块,结果差点把我送走——AI上来就直接写代码,完全没考虑我们现有架构的权限模型;改了三次还是不对,一问才发现它连数据库表结构都没搞清楚。这种"需求对齐靠猜、代码质量靠蒙"的开发模式,相信很多用过AI编程的同学都感同身受。
直到半年前接触了TRAE的规则配置功能,我才找到破局之道:用6A工作流管项目流程,用5S规则规范个人执行,两者结合让AI从"野生程序员"变身"可控助手"。今天就把这套实战经验分享出来,带你彻底摆脱AI开发的混乱状态。
一、什么是Rules:让AI"听话"的底层逻辑
很多人把TRAE的Rules功能简单理解为"提示词模板",这就大错特错了!Rules 是一项强大的代码规范管理工具 ,它允许团队或开发者自定义并强制执行代码风格和最佳实践。它解决了三个核心痛点:
1. 告别重复指令疲劳
刚开始用AI时,我每天要重复输入"用Python 3.9语法"“遵循PEP8规范”“注释要包含参数校验说明”,直到配置了Rules,这些要求被"固化"到AI行为中。现在不管是新同事还是老员工,调用AI时都不用再强调基础规范,效率直接提升40%。
2. 实现"千人千面"的个性化适配
我带的团队里,前端同学喜欢AI给出"代码+效果图"的完整方案,后端同学只要"核心逻辑+测试用例"。通过个人Rules区分这些偏好后,AI输出的内容精准度提高了80%,再也不会出现"前端要UI示例,AI只给代码"的尴尬。
3. 构建"项目级"的约束边界
去年做支付系统时,AI擅自使用了已废弃的requests库旧API,导致线上bug。现在通过项目Rules明确"禁止使用requests<2.25.0版本",这类问题直接从源头杜绝。规则就像给AI装了"护栏",确保它在安全范围内发挥能力。
二、TRAE规则配置使用指南:从"配置"到"生效"的全流程
TRAE IDE(0.5.1+版本)支持两类规则,我总结为"个人规则定风格,项目规则定标准",两者配合使用效果最佳。
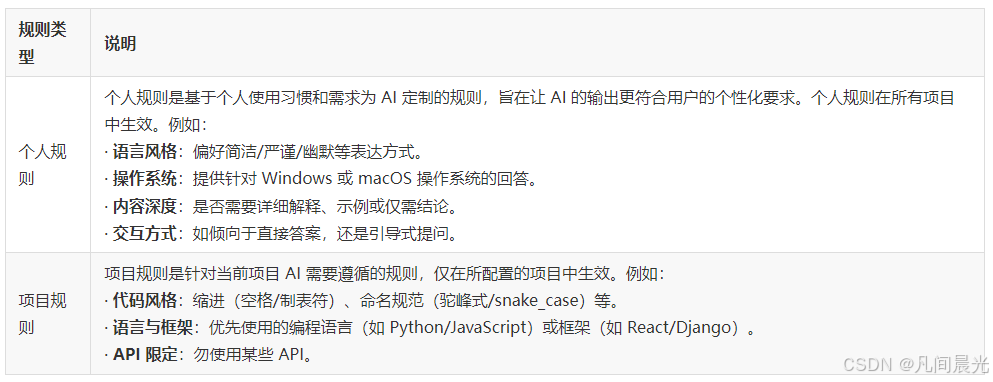
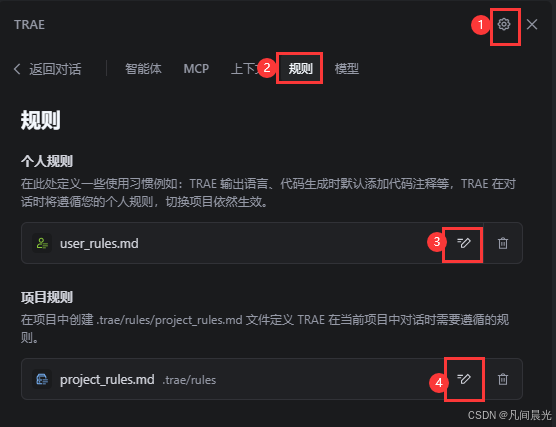
ps:规则冲突怎么办?
遇到"个人规则要求简洁,项目规则要求详细"的冲突时,TRAE会优先遵循项目规则。我的建议是:个人规则聚焦表达风格,项目规则专注技术约束,这样能从根本上减少冲突。
三、6A工作流项目规则:给AI套上"项目管理紧箍咒"
6A工作流(Align-Architect-Atomize-Approve-Automate-Assess)是TRAE最核心的项目规则体系,本质是通过标准化流程让AI"不敢偷懒、不能瞎写"。我带团队落地3个月,项目返工率直接从40%降到5%,这背后每个阶段都有"反AI偷懒"的小心机。
1. 6A工作流项目规则介绍
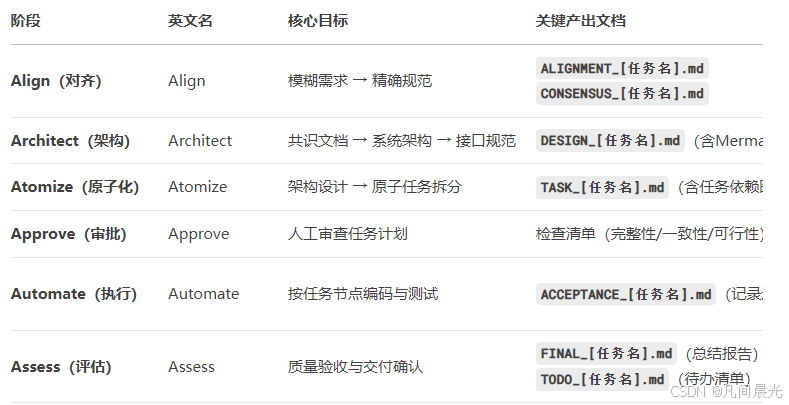
阶段1:Align(对齐)
把模糊需求锤成"钢印级"规范,杜绝AI"我以为"式开发。 记住:需求边界不清,后面全是坑。
阶段2:Architect(架构)
从共识文档到系统架构,Align阶段确认需求后,AI会自动生成DESIGN_任务名.md,用mermaid画架构图,拒绝AI"拍脑袋写代码"。
阶段3:Atomize(原子化)
拆分任务到AI"不可能失败"的粒度,复杂任务拆成20行内代码块。
阶段4:Approve(审批)
拿着TASK_任务名.md逐条检查,重点看"验收标准是否可测试"——比如"用户注册接口"不能写"功能正常",必须写"输入重复手机号返回code=1001错误"
阶段5:Automate(自动化执行)
AI按任务顺序执行,每写完一个函数必须先写单元测试(我加了规则:测试不通过不准提交代码)
阶段6:Assess(评估)
最终生成FINAL_任务名.md,包含代码质量评分(用SonarQube扫描)、测试覆盖率(要求≥80%)、遗留TODO(比如"性能优化待后续迭代")

2. 附6A工作流项目规则:project_rules.md(即拿即用)
下载地址:TRAE通用开发规则配置之6A工作流项目规则和敏捷开发5S个人规则
四、5S敏捷开发个人规则:让自己成为"AI驯兽师"
6A解决了项目流程问题,但个人执行不到位还是白搭。我总结的5S个人规则,专治"AI依赖症"和"开发拖延症"。
1. 5S敏捷开发个人规则介绍
1S:文档管理(核心中的核心)
血泪教训:去年有个项目文档没及时更新,接手的同事不知道"用户表已添加last_login字段",结果新功能上线直接报错。现在我团队强制:
- 创建时机:新项目第一天必须建
说明文档.md,包含"项目规划+实施方案+进度记录" - 更新要求:每次开发前先读文档,改一行代码就同步更新文档,完成任务后必须写"结果说明"
2S:开发流程(顺序化思考,拒绝跳步)
用分析法拆解需求,比如开发"商品列表页":
- 先写接口文档(输入参数、返回格式)
- 再写单元测试(边界条件:空列表、分页越界)
- 最后实现功能
关键原则:完成一个任务打勾一个,绝不允许"这个功能差不多了,先做下个"。我见过有人同时开5个文件改代码,最后自己都不知道改了啥。
3S:问题解决(官方文档是爹,搜索引擎是儿子)
AI不是万能的!上次遇到Python的asyncio问题,AI给的代码有bug,查也没解决。最后翻Python官方文档才发现是"事件循环策略"用错了。现在我定了规矩:
- 技术问题先查,解决不了必须翻官方文档(Python查Python.org,Java查Oracle)
- 严禁"百度一下复制粘贴",谁用非官方方案谁背锅
4S:执行约束(三大"绝不允许")
这是我从军队管理学来的——用铁律杜绝侥幸心理:
- 绝不允许项目延期:提前3天识别风险,延期必须同步更新文档并说明原因
- 绝不允许超出计划:加功能可以,但必须先改规划文档,评估影响
- 绝不允许出错:编译错误、测试不通过、文档不一致,这三类错误零容忍
5S:环境与输出(细节决定成败)
- 开发环境:例如全团队统一用Windows(避免Linux/macOS路径分隔符坑),IDE插件版本锁定(比如Prettier用2.8.0)
- 代码输出:所有函数必须加注释,格式固定为:
def login(username: str, password: str) -> dict: """ 用户登录接口 :param username: 用户名(长度6-20位) :param password: 密码(包含大小写+数字) :return: {code:0,data:{token:str,user:dict}} """
2.附5S敏捷开发个人规则:user_rules.md(即拿即用)
下载地址:TRAE通用开发规则配置之6A工作流项目规则和敏捷开发5S个人规则
五、6A+5S协同:1+1>10的实战效果
单独用6A或5S效果有限,但结合起来简直是"降维打击"。我带的电商项目用这套组合拳后:
- 返工率:从40%→5%(Align阶段解决需求偏差,5S文档避免信息断层)
- 开发效率:单人日产出从3个功能点→8个(Atomize拆分后AI执行更快,5S顺序执行减少切换成本)
- 代码质量:SonarQube问题数从平均20个/千行→3个(Automate阶段强制测试,5S约束注释规范)
举个真实案例:最近开发"优惠券系统",6A确保架构对齐现有营销系统,5S让每个开发按"文档→测试→代码"顺序执行,结果提前5天上线,零bug。
六、常见问题
Q:6A 工作流会不会太复杂?小项目能用吗?
A:初期可能感觉步骤多,但相比后期的返工和维护成本,绝对值得!而且 AI 会自动执行,你只需要确认关键节点。
Q:适合什么规模的项目?
A:从小功能到大项目都适用。小项目可以简化某些阶段,大项目则能充分发挥威力。
Q:如何说服团队使用?
A:先在一个小项目上试用,效果立竿见影,自然就能说服大家。
结语:从"被AI带跑"到"驾驭AI"
工欲善其事,必先利其器。AI编程的终极目标不是让AI替我们干活,而是用规则把AI变成"超级工具"。
6A工作流管项目流程,5S个人规则管执行细节,两者结合才能真正释放AI威力。 通过系统化的流程管理,我们可以:
✅ 让 AI 按照专业流程工作
✅ 确保需求理解准确无误
✅ 保证代码质量和可维护性
✅ 建立完善的文档体系
✅ 实现高效的团队协作
最后送大家一句话:好的AI助手不是天生的,是调教出来的。现在就打开Trae IDE,配置你的第一条规则吧!

)
)
:GPIO 输入之光敏传感器控制蜂鸣器)








:雨骑古莲村游记)

TCP拥塞控制与拥塞控制算法深度剖析)
)



![矿物分类系统开发笔记(二):模型训练[删除空缺行]](http://pic.xiahunao.cn/矿物分类系统开发笔记(二):模型训练[删除空缺行])