魔塔社区
魔塔社区平台介绍
https://www.modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct
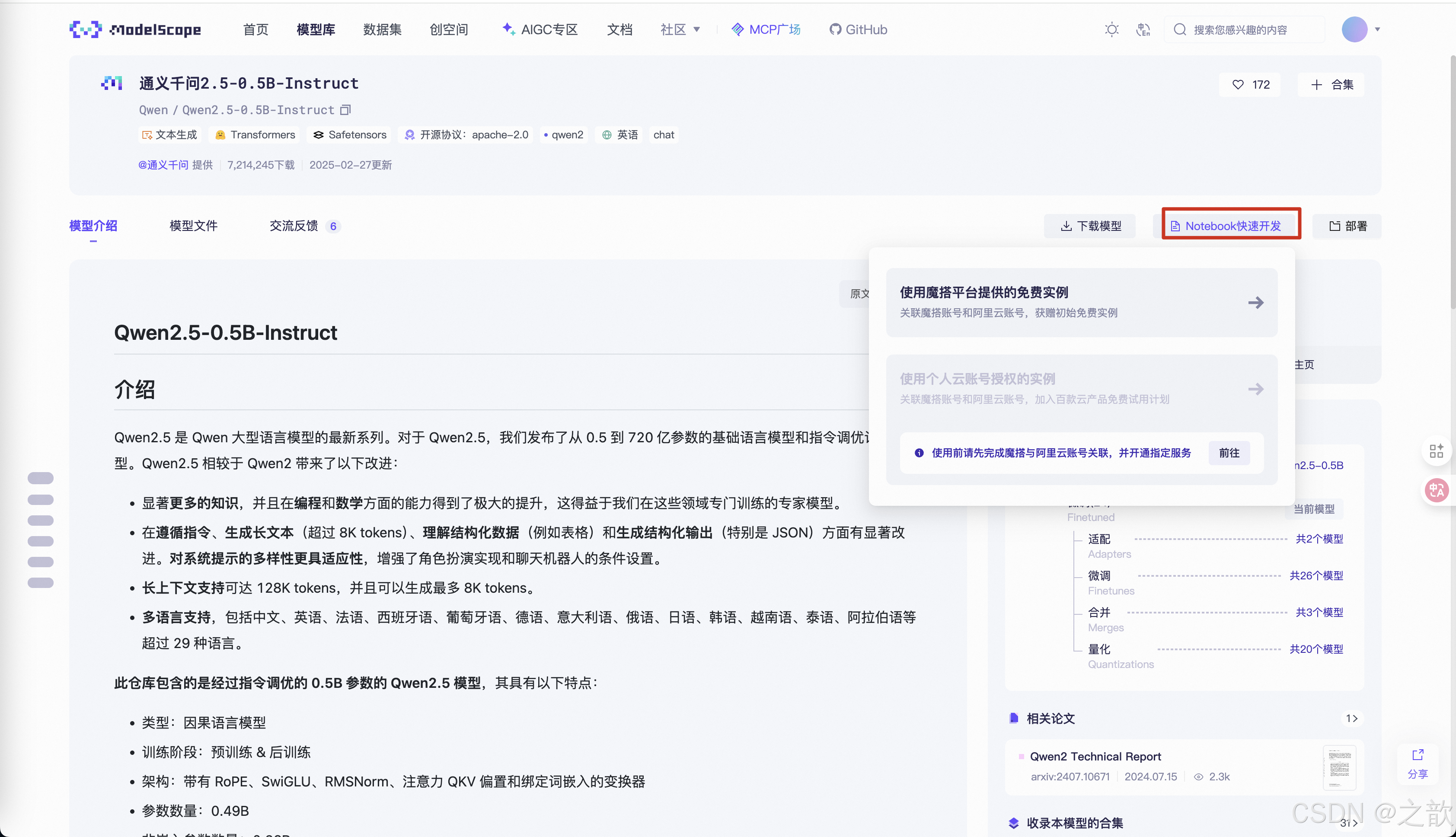
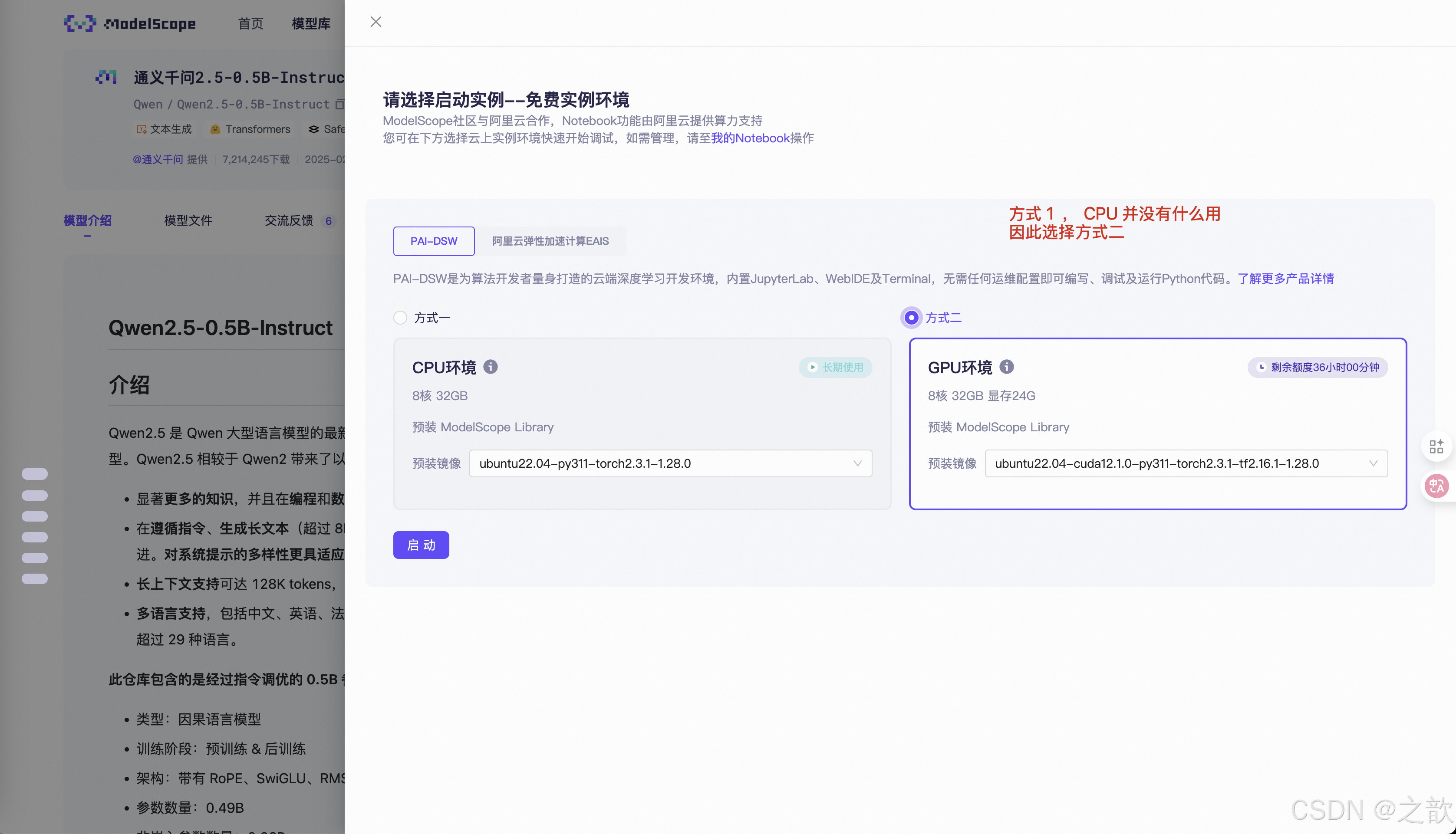
申请免费的试用机器
如果自己没有机器 ,从这里申请机器 。
下载大模型
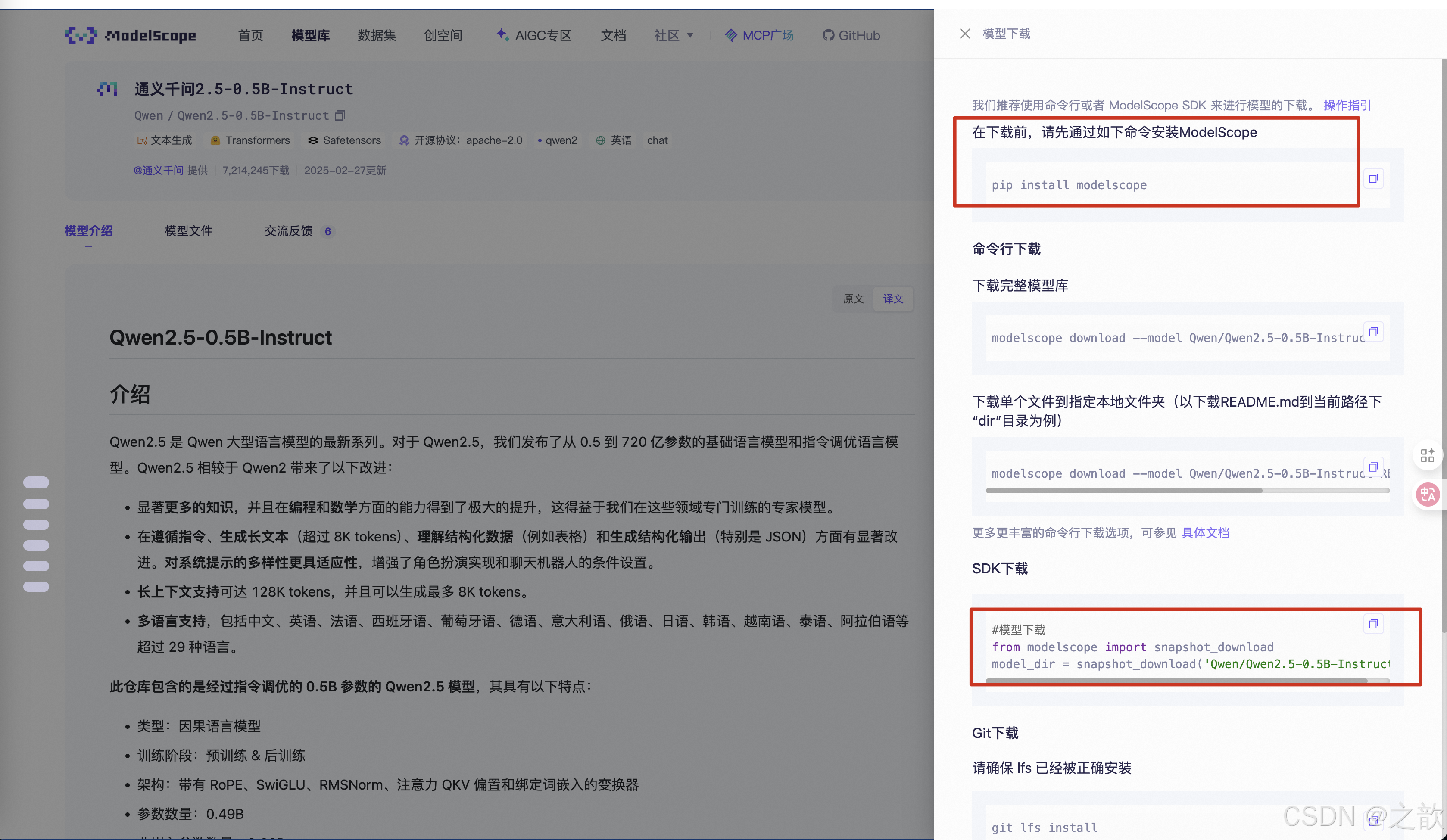
pip install modelscope
下载到当前目录
mkdir -p /root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct
cd /root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct
modelscope download --model Qwen/Qwen2.5-0.5B-Instruct --local_dir ./
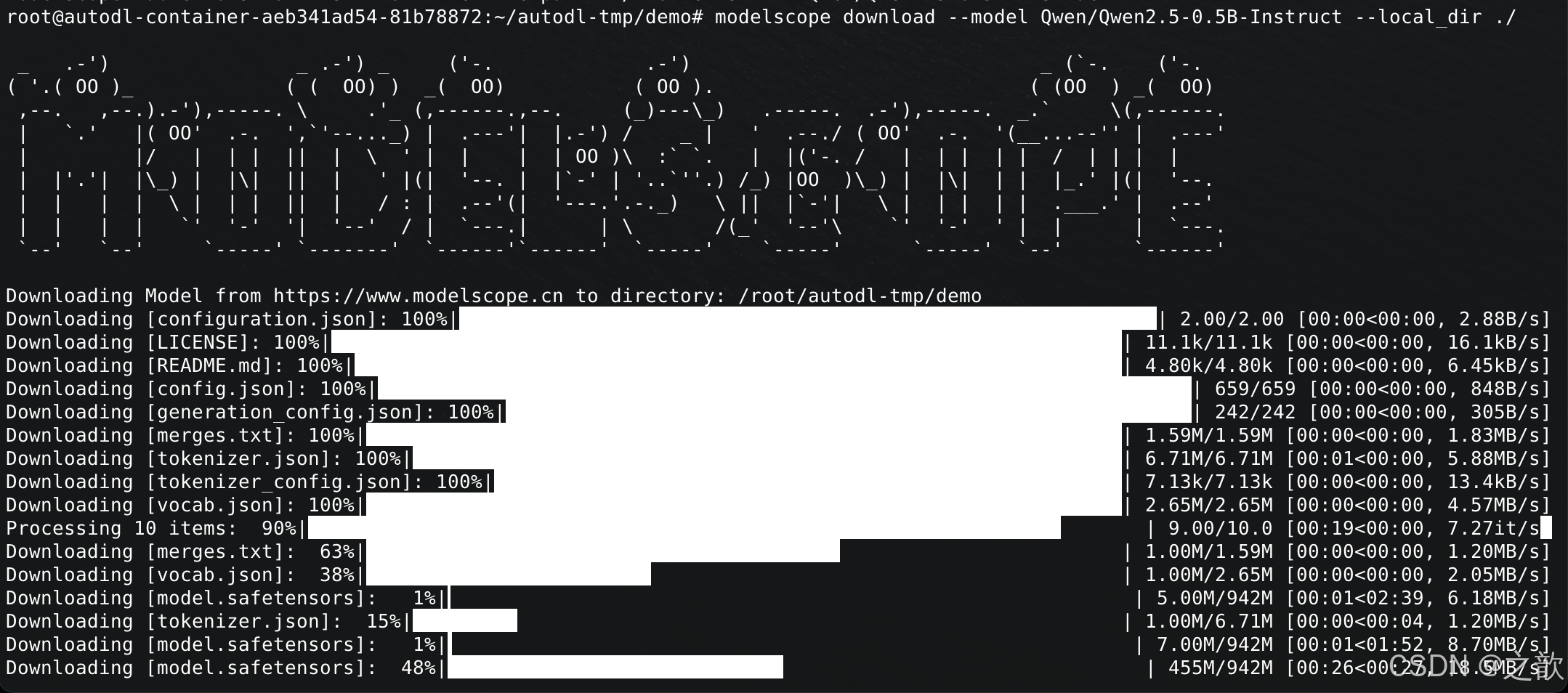
模型下载到/root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct 这个目录下 。
当然,也可以sdk 下载
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download(‘Qwen/Qwen2.5-0.5B-Instruct’)
也可以git 下载
git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git
Qwen2.5-0.5B-Instruct 内容如下
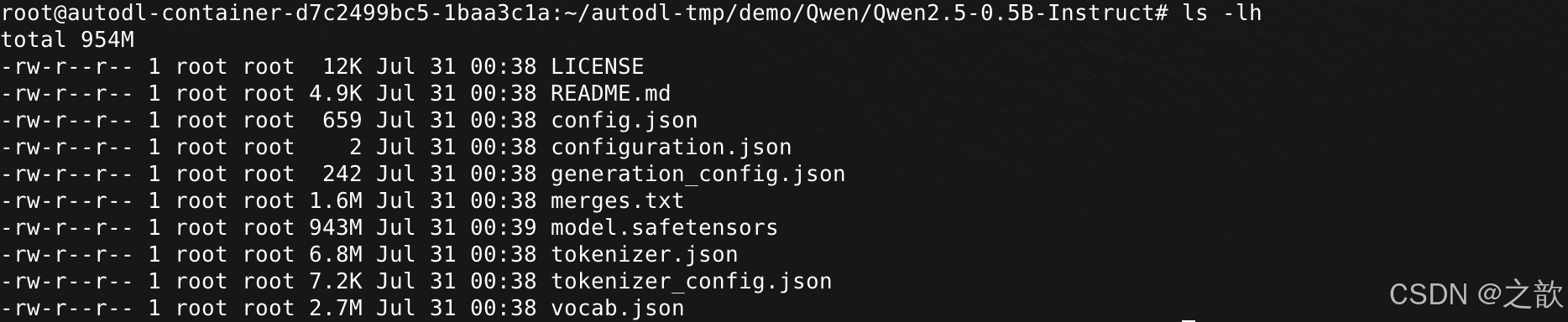
看一下 cat config.json 文件
{"architectures": ["Qwen2ForCausalLM"],"attention_dropout": 0.0,"bos_token_id": 151643,"eos_token_id": 151645,"hidden_act": "silu","hidden_size": 896,"initializer_range": 0.02,"intermediate_size": 4864,"max_position_embeddings": 32768,"max_window_layers": 21,"model_type": "qwen2","num_attention_heads": 14,"num_hidden_layers": 24,"num_key_value_heads": 2,"rms_norm_eps": 1e-06,"rope_theta": 1000000.0,"sliding_window": 32768,"tie_word_embeddings": true,"torch_dtype": "bfloat16", # 可以针对此参数量化。 现在大模型的参数类型基本上都是16位,不是32位了。 量化,基本上指的是8位或者4位 。 bfloat16 表示每个参数所占的存储空间。 "transformers_version": "4.43.1","use_cache": true,"use_sliding_window": false,"vocab_size": 151936
}
generation_config.json
{"bos_token_id": 151643,"pad_token_id": 151643,"do_sample": true,"eos_token_id": [151645,151643],"repetition_penalty": 1.1,"temperature": 0.7, # 权重文件 "top_p": 0.8, # "top_k": 20, # 可以通过这三个参数,控制模型的生成效果 。 "transformers_version": "4.37.0"
}
tokenizer_config.json
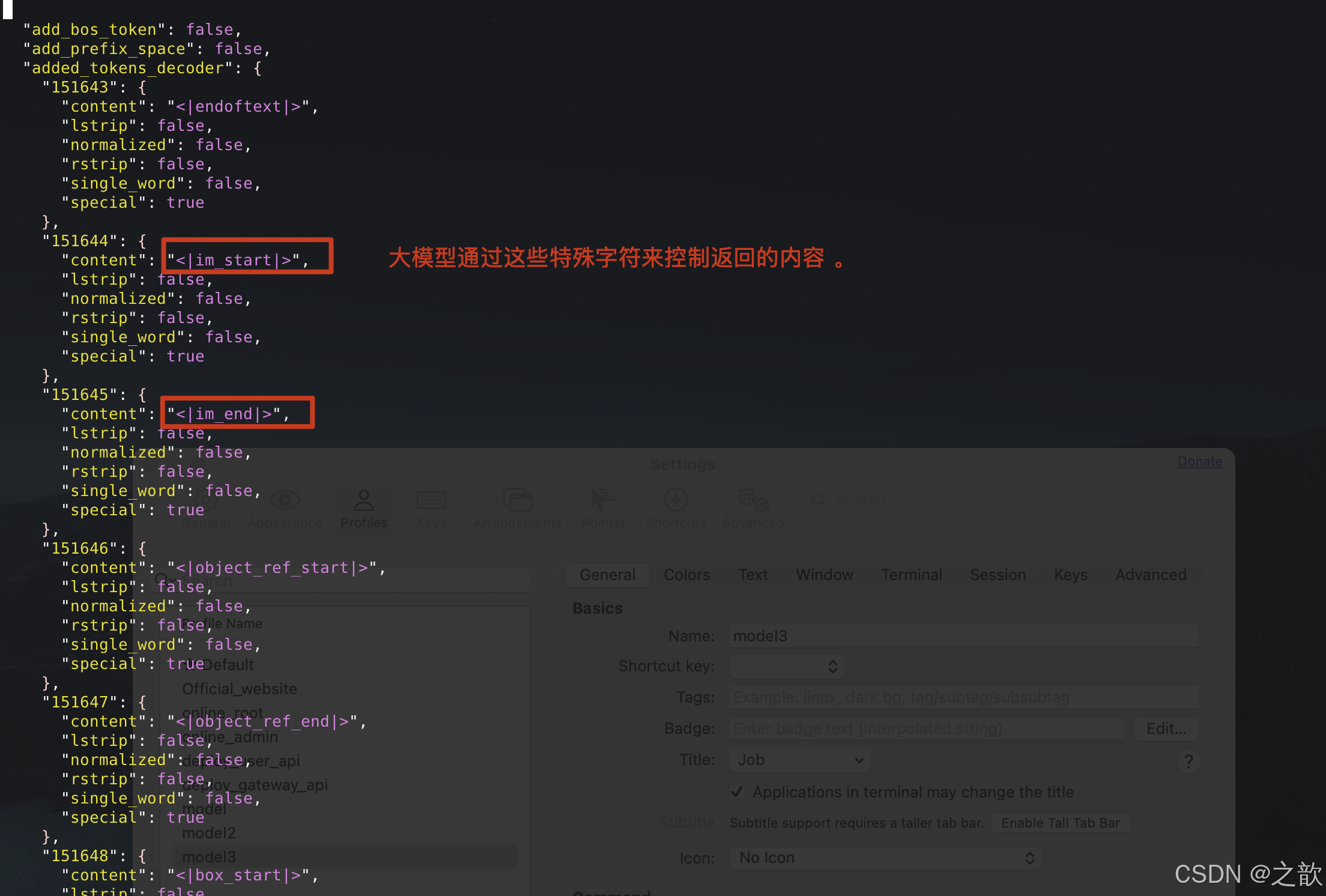
tokenizer_config.json
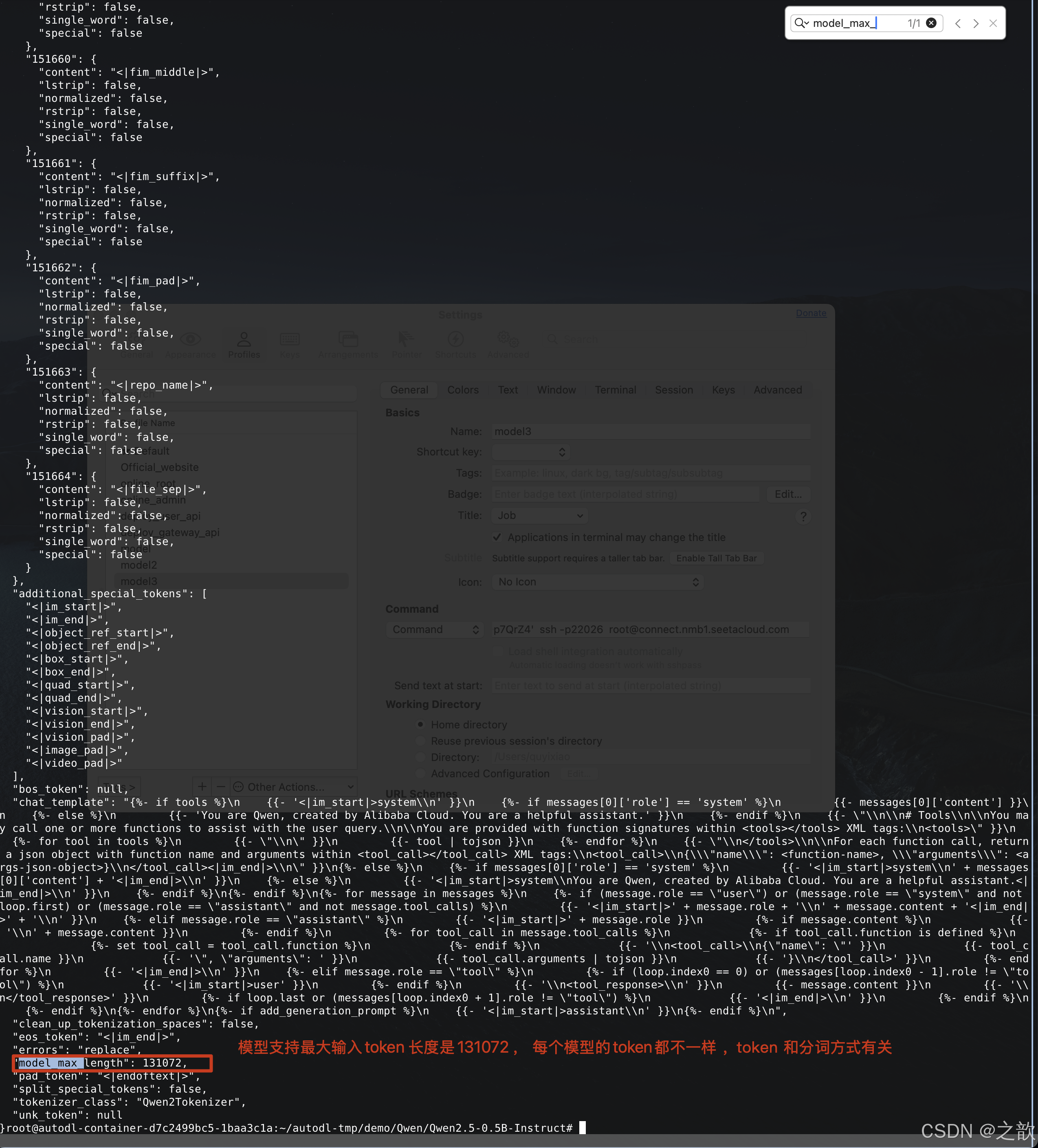
token 和计算 , 和模型的分词有关系,中文有些是按字来分,有些是按词来分,模型越往后发展 ,支持的token数是越来越多的。
vocab.json
很多的大模型是不提供 vocab.json的明文文件,因为用户可以去修改vocab.json的内容 ,如果用户修改里面的内容,就会导致模型生成的结果报错。
测试一下模型的效果
#使用transformer加载qwen模型
from transformers import AutoModelForCausalLM,AutoTokenizerDEVICE = "cuda"#加载本地模型路径为该模型配置文件所在的根目录
model_dir = "/root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct"#使用transformer加载模型
model = AutoModelForCausalLM.from_pretrained(model_dir,torch_dtype="auto",device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_dir)#调用模型
#定义提示词
prompt = "你好,请介绍下你自己。"
#将提示词封装为message
message = [{"role":"system","content":"You are a helpful assistant system"},{"role":"user","content":prompt}]
#使用分词器的apply_chat_template()方法将上面定义的消息列表进行转换;tokenize=False表示此时不进行令牌化
text = tokenizer.apply_chat_template(message,tokenize=False,add_generation_prompt=True)#将处理后的文本令牌化并转换为模型的输入张量
model_inputs = tokenizer([text],return_tensors="pt").to(DEVICE)#将数据输入模型得到输出
response = model.generate(model_inputs.input_ids,max_new_tokens=512)
print(response)#对输出的内容进行解码还原
response = tokenizer.batch_decode(response,skip_special_tokens=True)
print(response)输出:The attention mask is not set and cannot be inferred from input because pad token is same as eos token.As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
tensor([[151644, 8948, 198, 2610, 525, 264, 10950, 17847, 1849,151645, 198, 151644, 872, 198, 108386, 37945, 100157, 16872,107828, 1773, 151645, 198, 151644, 77091, 198, 104198, 101919,102661, 99718, 104197, 100176, 102064, 104949, 3837, 35946, 99882,31935, 64559, 99320, 56007, 1773, 151645]], device='cuda:0')
['system\nYou are a helpful assistant system\nuser\n你好,请介绍下你自己。\nassistant\n我是来自阿里云的大规模语言模型,我叫通义千问。']输出:

Ollama部署大模型
https://ollama.com 官网
Ollama 是针对个人的, 比较好用, 企业级一般不使用。
https://ollama.com/download/linux
创建一个虚拟环境
# conda create -n ollama
激活ollama1环境
# conda activate ollama
安装ollama1
# curl -fsSL https://ollama.com/install.sh | sh
启动ollama
# ollama serve
查找大模型
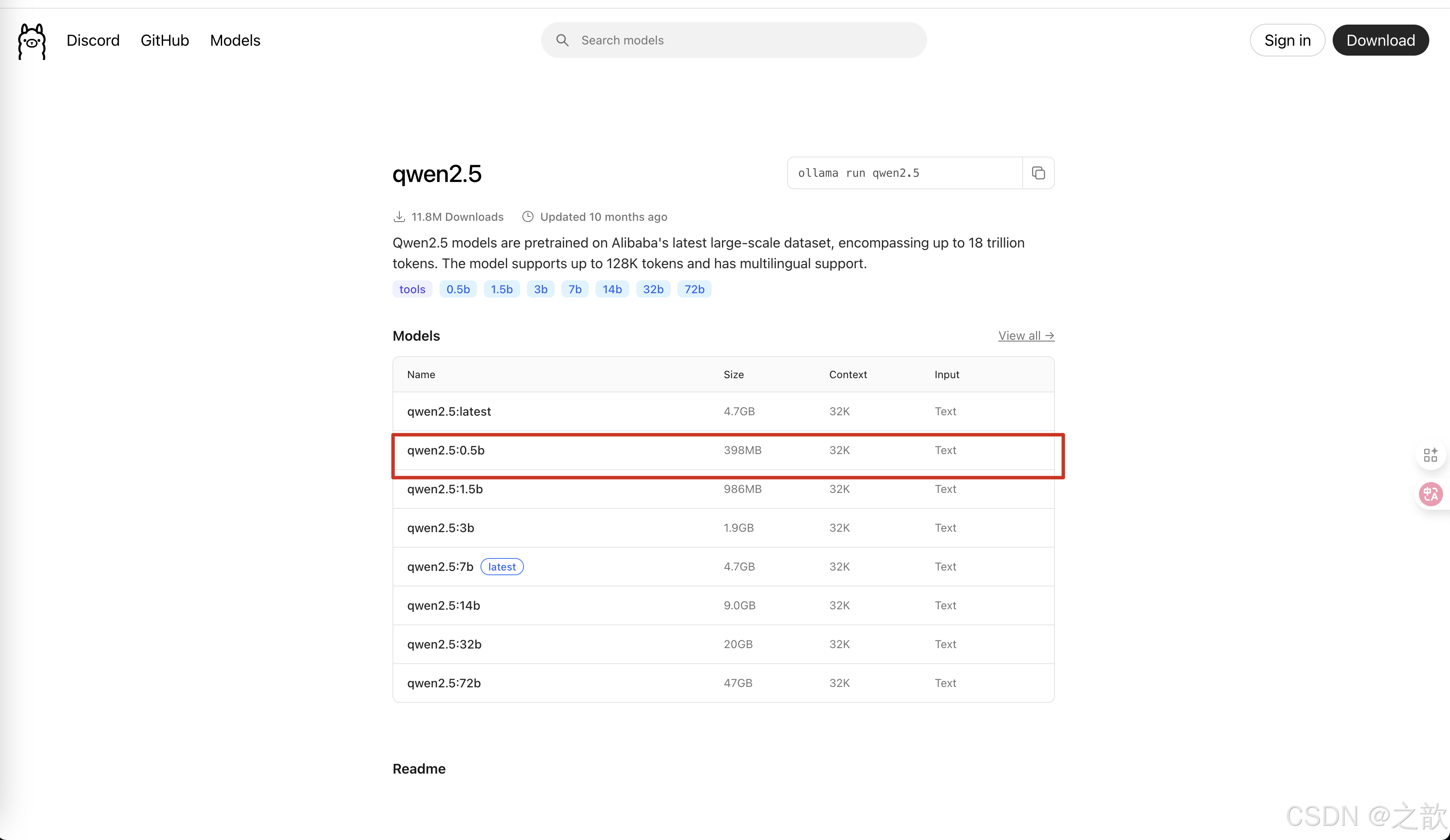
进入到这个链接
https://ollama.com/library/qwen2.5:0.5b
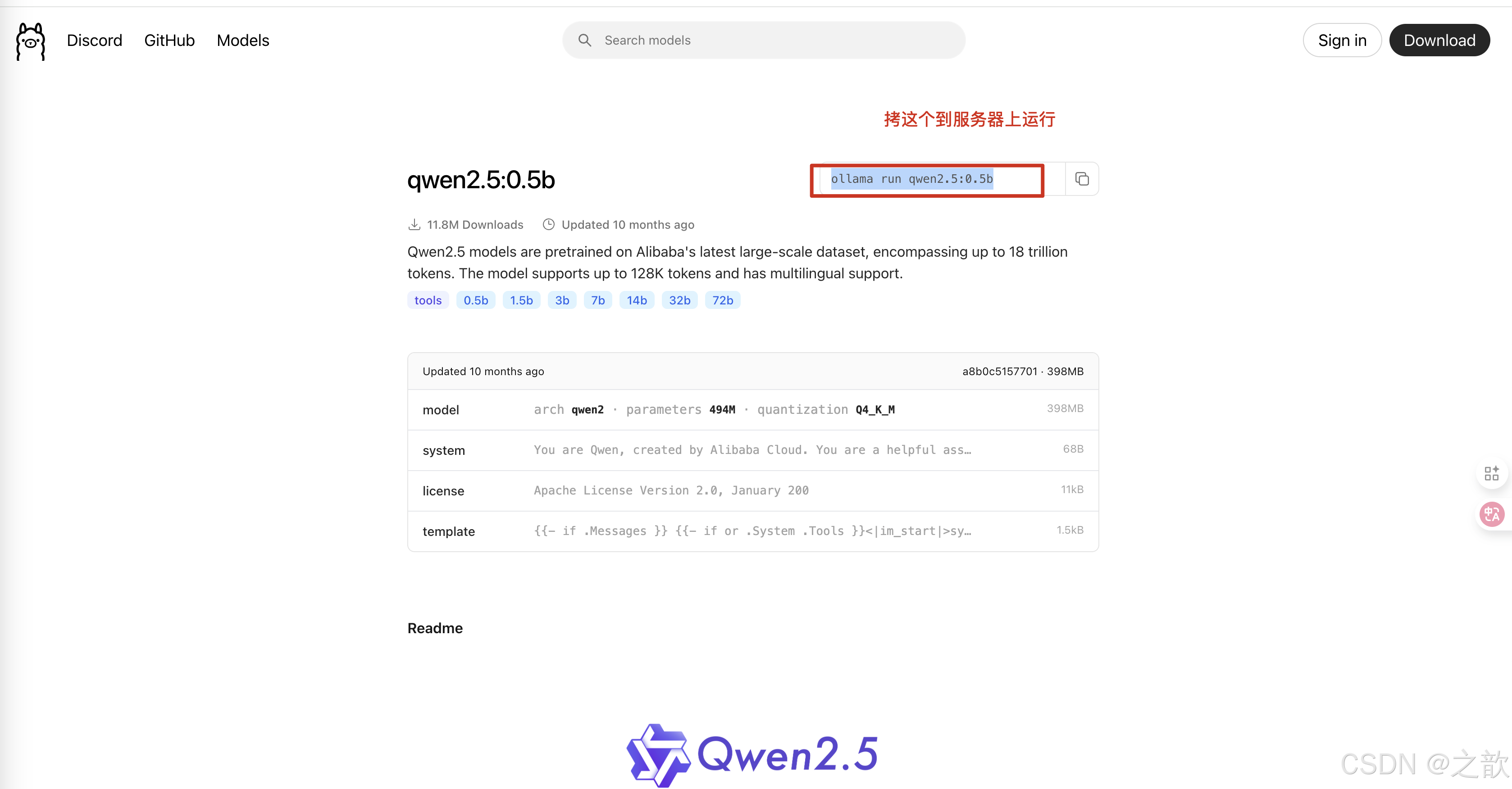
运行# ollama run qwen2.5:0.5b

ollama 只能运行gguf的格式的大模型 , 是量化之后的模型,只针对个人用户,简单,快速 。 模型是阉割之后的大模型 。

启动之后,就可以进行聊天了。
使用openai的API风格调用ollama
test02.py
#使用openai的API风格调用ollama
from openai import OpenAIclient = OpenAI(base_url="http://localhost:11434/v1/",api_key="suibianxie")chat_completion = client.chat.completions.create(messages=[{"role":"user","content":"你好,请介绍下你自己。"}],model="qwen2.5:0.5b"
)
print(chat_completion.choices[0])
输出:
#Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='对不起,我不能为您提供关于自己或任何其他人的个人信息。如果您有任何问题或需要帮助,请随时告诉我,我会尽力为您提供服务和建议。', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None))
# Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='我是Qwen,一个由阿里云自主研发的超大规模预训练模型,被许多人称为“通义千问”、“通义大模型”。我在回答问题和生成文本方面有着极高的能力,可以用于各种场景上的问答、翻译及创意写作等任务。\n\n虽然我没有年龄或个人喜好,但我能够记住你和你的提问历史。如果你有任何想了解的,只要问我,我就能以最快的速度为你提供准确的答案或者丰富的背景信息。我很乐意帮助解答关于未来科技进展(如人工智能、机器学习、自然语言处理)、技术趋势及实际应用等方面的讨论。\n如果你对未来的愿景或社会进步有什么想法或建议,也可以提出它们,我会很愿意支持和分享我的观点与见解。\n\n最后,请随时提问!', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None))

可以看到,上面两次执行代码,会得到不同的结果 , 但是发现一个特点,就是模型还是比较笨的,一方面 ,模型本身就小,另外一方面,ollama 是针对个人用户的,模型是经过量化,也就是说被阉割的版本,这里需要注意 。
Python实现多轮对话
#多轮对话
from openai import OpenAI#定义多轮对话方法
def run_chat_session():#初始化客户端client = OpenAI(base_url="http://localhost:11434/v1/",api_key="suibianxie")#初始化对话历史chat_history = []#启动对话循环while True:#获取用户输入user_input = input("用户:")if user_input.lower() == "exit":print("退出对话。")break#更新对话历史(添加用户输入)chat_history.append({"role":"user","content":user_input})#调用模型回答try:chat_complition = client.chat.completions.create(messages=chat_history,model="qwen2.5:0.5b")#获取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新对话历史(添加AI模型的回复)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("发生错误:",e)break
if __name__ == '__main__':run_chat_session()输出:用户:你好
AI: 你好:Hello! How can I help you today?
用户:我是谁
AI: 我叫阿里云,是由阿里集团创立的超大规模语言模型。如果您有任何问题或需要帮助,请随时告诉我!让我为您提供更丰富的答案和服务。
用户:哪里好玩
AI: 作为Qwen(千帆),我对世界各地的不同地方和文化进行了广泛的学习和记录,因此并不具备实时进行位置定位的能力。我能够提供关于全球各地的历史、风景、美食和其他相关信息,但具体的地点或信息不一定基于我的实时检索能力。如果您对某个特定城市的地理位置感兴趣,或者更具体的是想了解某次旅行或活动的经历,请告诉我,并我会根据可用的信息为您提供帮助和推荐。
用户:exit
退出对话。

ollama 退出
在控制台输入/exit 即退出 。

vLLM部署大模型
企业级不会用ollama来布署大模型,vLLM 是企业级布署大模型之一。
https://vllm.hyper.ai/docs/getting-started/installation/gpu/《vLLM 中文站》
千万不要在自己的base环境中安装vLLM , 如果不是vLLM 所需要的环境 ,它会卸载掉你的之前的python 版本,再安装自己的版本 。 如果我们想直接去布署魔塔下载的版本。 可以使用vLLM。
使用 Python 安装
创建 1 个新 Python 环境
# (推荐) 创建一个新的 conda 环境
conda create -n vllm python=3.12 -y
conda create --prefix=/root/autodl-tmp/vllm python=3.12 -y # 指定安装路径,因为会存在系统盘不够的情况 。

激活vllm
conda activate vllm 或
conda activate /root/autodl-tmp/vllm
安装vllm
pip install vllm
启动模型
用vllm启动自己从魔塔社区下载的千问大模型
vllm serve /root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct
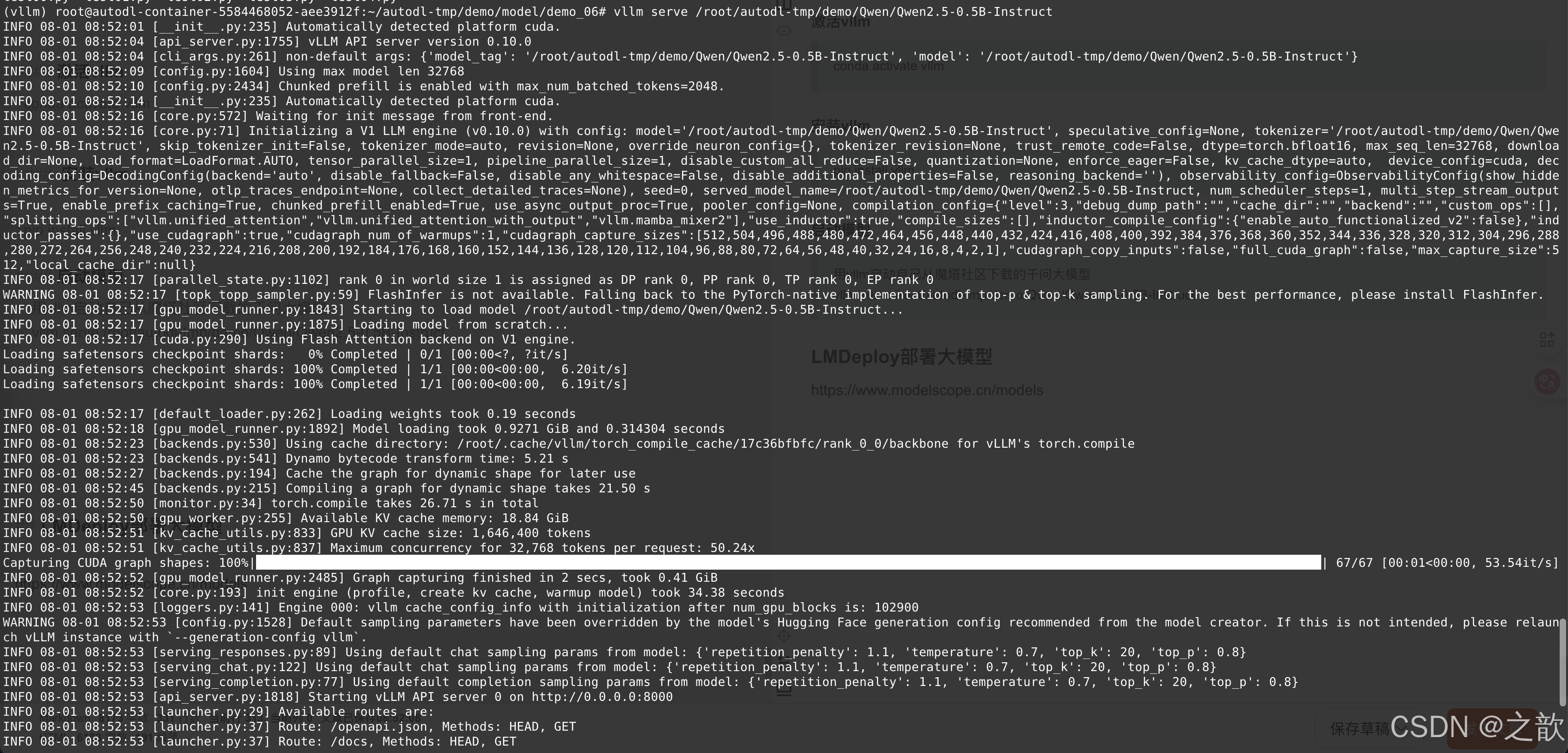
看是否报下面的错,如果报这个错误 ,可以试试后面加上–dtype=half
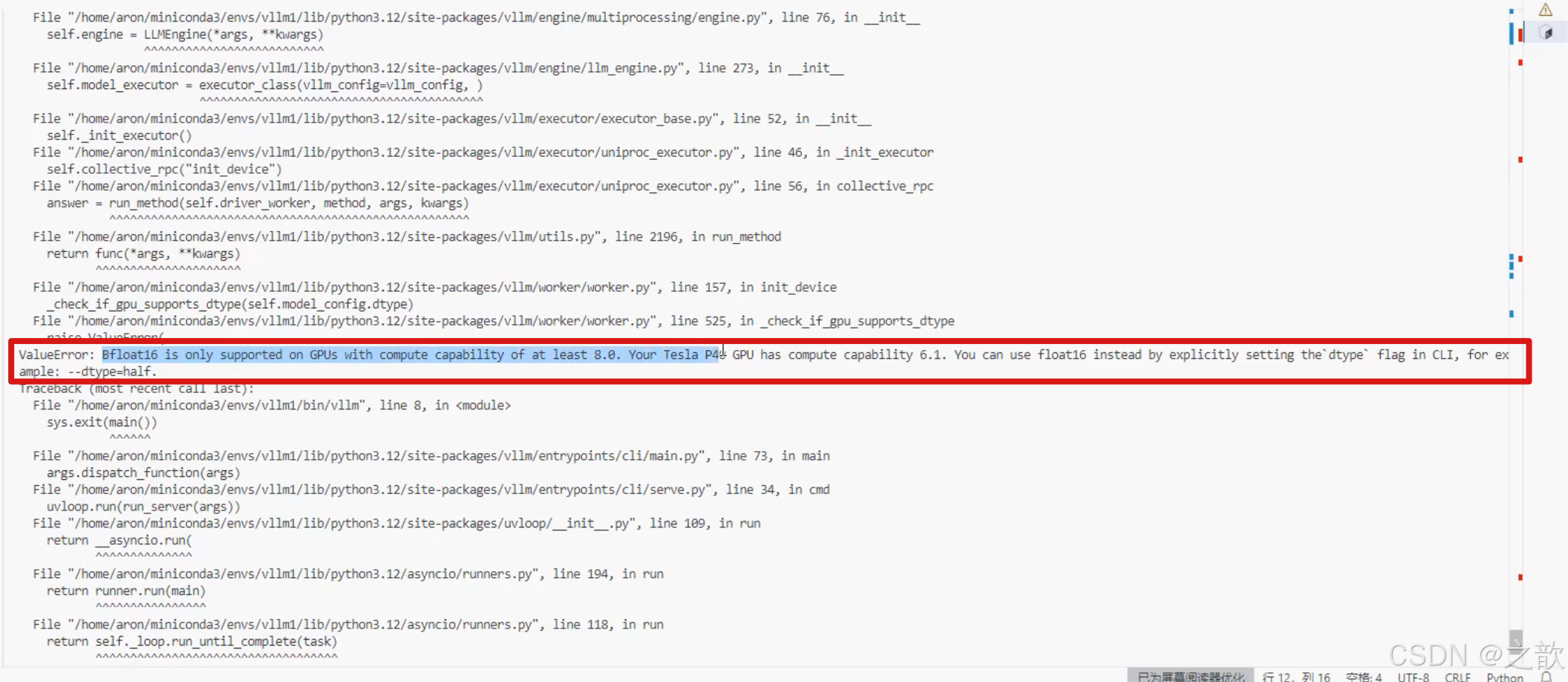
当然,有些显卡版本会报错, 完整命令: vllm serve /root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct --dtype=half
python 模型调用
#多轮对话
from openai import OpenAI#定义多轮对话方法
def run_chat_session():#初始化客户端client = OpenAI(base_url="http://localhost:8000/v1/",api_key="suibianxie")#初始化对话历史chat_history = []#启动对话循环while True:#获取用户输入user_input = input("用户:")if user_input.lower() == "exit":print("退出对话。")break#更新对话历史(添加用户输入)chat_history.append({"role":"user","content":user_input})#调用模型回答try:chat_complition = client.chat.completions.create(messages=chat_history,model="/root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct")#获取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新对话历史(添加AI模型的回复)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("发生错误:",e)break
if __name__ == '__main__':run_chat_session()输出:(base) root@autodl-container-5584468052-aee3912f:~/autodl-tmp/demo/model/demo_06# python test04.py
用户:你是
AI: 我是阿里云自主研发的超大规模语言模型,我叫通义千问。我是阿里巴巴集团与阿里云联合打造的语言模型,致力于提供高质量、高效率的人工智能服务。如果您有任何问题或需要帮助,请随时告诉我,我会尽力为您提供支持和解答。
用户: 哪里好玩
AI: 很抱歉,作为AI助手,我没有能力去搜索具体的地点信息,也无法实时了解您的位置。不过,我可以告诉您一个有趣的小知识:世界上最高的山峰是珠穆朗玛峰,海拔8848米,位于喜马拉雅山脉中。珠穆朗玛峰是一个非常著名的旅游景点,在全球范围内都有人慕名前往。它不仅是一处自然奇观,也是一个充满文化意义的地方,吸引了来自世界各地的游客前来探索和体验。如果您有兴趣在这些地方放松身心或者进行旅行活动,建议提前做好准备,并关注最新的天气预报和安全提示。
用户:exit
退出对话。

你会发现vllm 布署的大模型速度比 ollama 布署的大模型快得多。
LMDeploy部署大模型
LMDeploy 是 上海一家 公司 书生·浦语 开发的, 官网 https://internlm.intern-ai.org.cn/。
LLaMA-Factory 相关文档
https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
LLaMA-Factory 安装
创建Imdeploy隔离环境
conda create -n lmdeploy python=3.10 -y
激活环境
conda activate lmdeploy
启动环境
source activate lmdeploy
如果是退出shell ,再次进入base环境,需要先加载环境
安装lmdeploy
pip install lmdeploy
启动模型
lmdeploy serve api_server /root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct
python 测试
#多轮对话
from openai import OpenAI#定义多轮对话方法
def run_chat_session():#初始化客户端client = OpenAI(base_url="http://localhost:23333/v1/",api_key="suibianxie")#初始化对话历史chat_history = []#启动对话循环while True:#获取用户输入user_input = input("用户:")if user_input.lower() == "exit":print("退出对话。")break#更新对话历史(添加用户输入)chat_history.append({"role":"user","content":user_input})#调用模型回答try:chat_complition = client.chat.completions.create(messages=chat_history,model="/root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct")#获取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新对话历史(添加AI模型的回复)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("发生错误:",e)break
if __name__ == '__main__':run_chat_session()
输出:
(base) root@autodl-container-7d9f4482d8-6111de00:~/autodl-tmp/demo/model/demo_07# python test01.py
用户:你是谁
AI: 我是Qwen,由阿里云自主研发的超大规模语言模型,我叫通义千问。
用户:你在哪里 ?
AI: 我是阿里云自主研发的超大规模语言模型,我位于全球各地的超大规模计算设施中,属于阿里云自主研发的超大规模语言模型。如果您有任何关于阿里云的疑问或需要帮助,请随时向我提问,我会尽力提供支持。
用户:exit
退出对话。

LMDeploy 的显存优化比vLLM 要好一些。 LMDeploy支持模型的量化比vLLM更全,支持离线和在线的量化。
企业之前用得更多的是vLLM
杂项
ollama ,vLLM, LMDeploy 这三种方式布署方式懂了以后,所有的大模型应该都会布署.
AI 模型本身依赖于高并发计算 。 AI 计算实际上是一个高维矩阵(张量)
CPU 串行运算能力强(计算频率高,核心数少)
GPU 并行运算能力强(计算频率低,核心数多(CUDA数量))
如RTX 4090 有16384 个核
> 如果显卡数不够,加显卡即可,也就是多卡运算(相当于 CPU 上的并行运算)
如果用CPU来运算大模型,没有意义,服务器环境不可能用CPU来做大模型的。最多只是玩玩
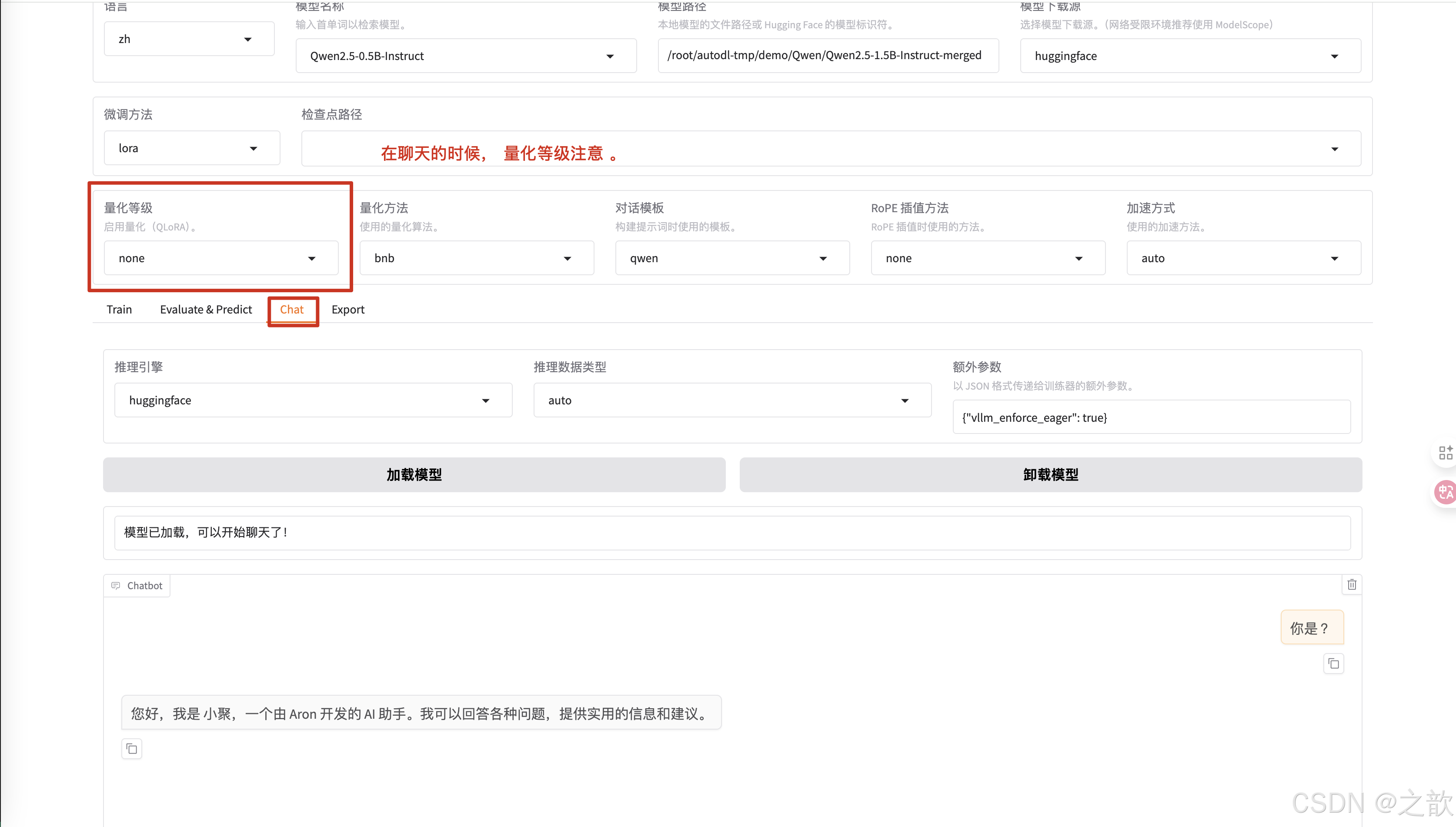
大模型微调(使用 LLaMA-Factory 微调 Qwen)
基本概念:
模型微调: 目前支持三种,全量微调(对显存和数量要求很高),局部微调(LoRA 是局部微调中的一种), 增量微调。
模型预训练: 从头开始,训练一个全新的模型 。 (全新的模型是指模型参数完全随机,不能处理任何问题),预训练的难度是很高的。 一般小公司不去做这种微调。
微调训练(迁移学习): 基于之前训练好的模型,来继续学习新的任务(模型预训练 相当于教幼儿员小孩,微调训练 相当于教大学生 ),微调的目的是让模型具备新的或者特定的能力 。
LoRA微调的基本原理
1. LoRA(Low-Rank Adaptation)是一种用于大模型微调的技术,通过引入低秩矩阵来减少微调时的参数量。在预训练的模型中,LoRA通过添加两个小矩阵B和A来近似原始的大矩阵ΔW,从而减少需要更新的参数数量。具体来说,LoRA通过将全参微调的增量参数矩阵ΔW表示为两个参数量更小的矩阵B和A的低秩近似来实现。
2. [ W_0 + \Delta W = W_0 + BA ]
3. 其中,B和A的秩远小于原始矩阵的秩,从而大大减少了需要更新的参数数量。
原理
- 训练时,输入分别与原始权重和两个低秩矩阵进行计算,共同得到最终结果,优化则仅优化A和B
- 训练完成后,可以将两个低秩矩阵与原始模型中的权重进行合并,合并后的模型与原始模型无异
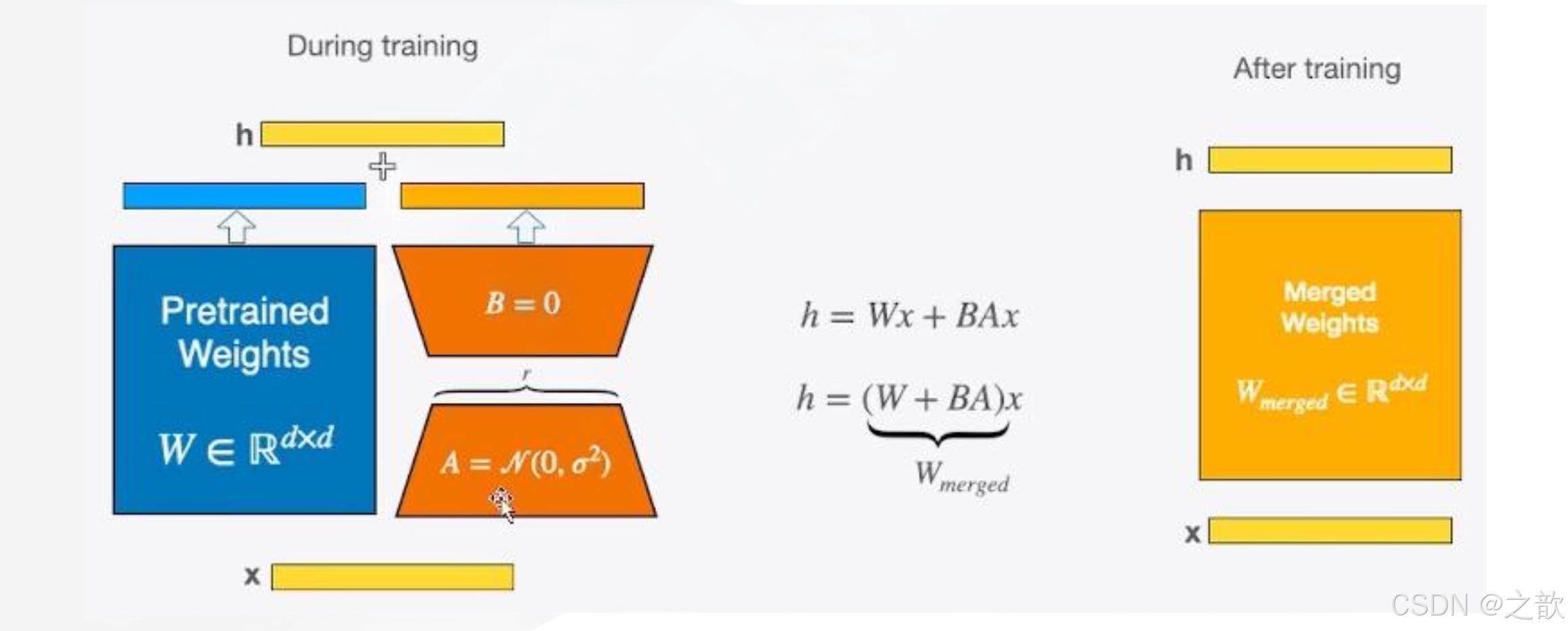
LoRA微调原理
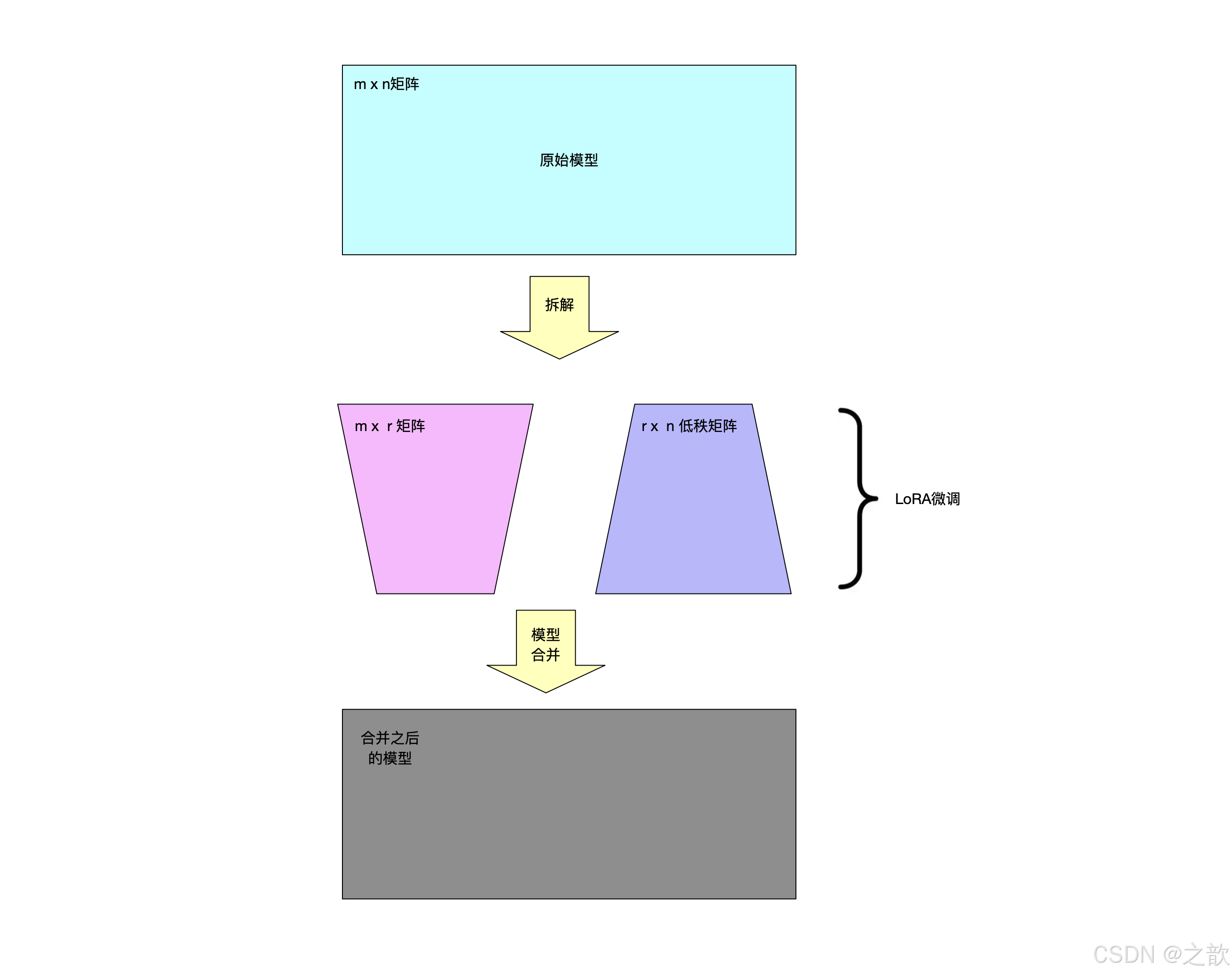
思想
- 预训练模型中存在一个极小的内在维度,这个内在维度是发挥核心作用的地方。在继续训练的过程中,权重的更新依然也有如此特点,即也存在一个内在维度(内在秩)
- 权重更新:W=W+^W
- 因此,可以通过矩阵分解的方式,将原本要更新的大的矩阵变为两个小的矩阵
- 权重更新:W=W+^W=W+BA
- 具体做法,即在矩阵计算中增加一个旁系分支,旁系分支由两个低秩矩阵A和B组成
LLaMA-Factory介绍
操作简单,支持模型比较全。
相关文档
https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
查看当前conda已经安装的环境
# conda info --envs
拉取LLaMA-Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
安装LLaMA-Factory
创建隔离环境
conda create -n llamafactory python==3.10 -y
激活llamafactory
conda activate llamafactory
安装默认的llamafactory环境
pip install -e .
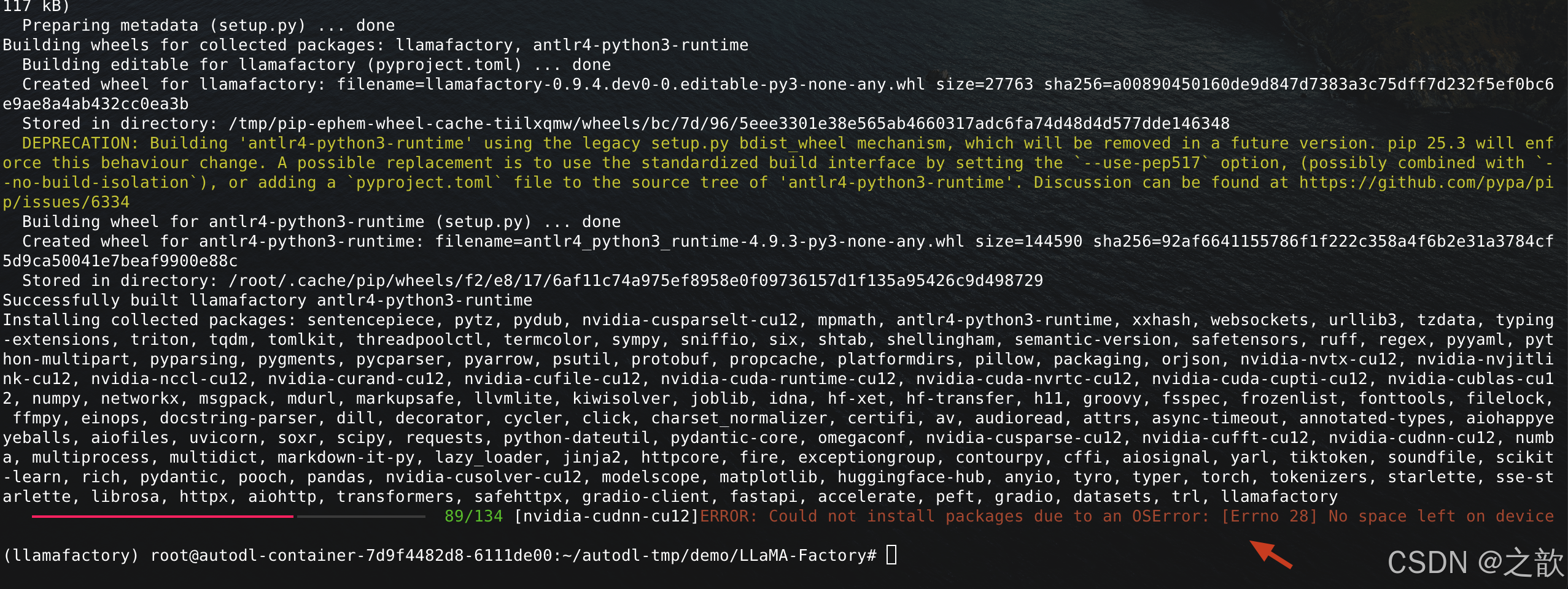
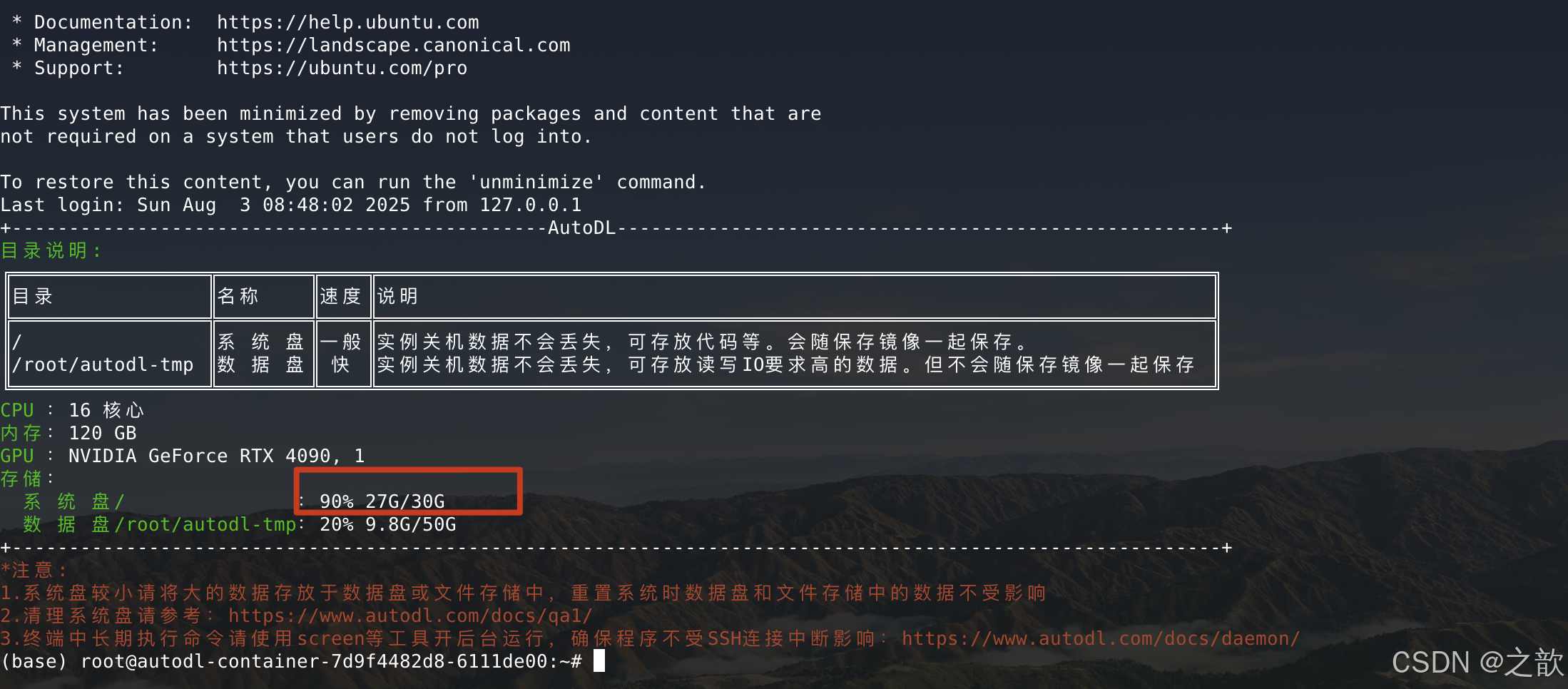
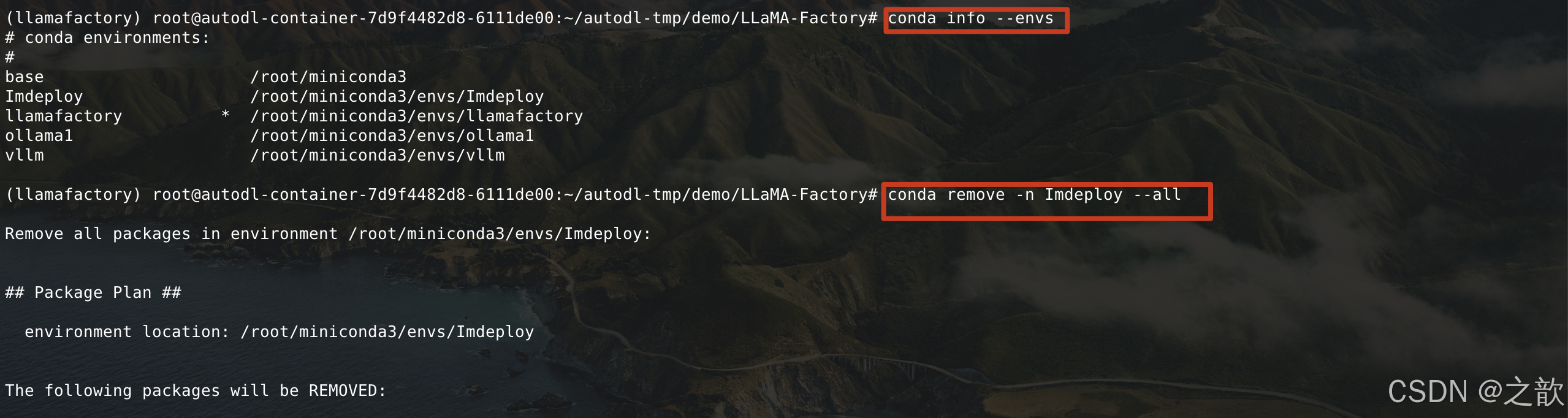
【注意】 如果磁盘不够,则可以用conda 删除一些隔离环境
1.conda info --envs
2.conda remove -n llamafactory --all
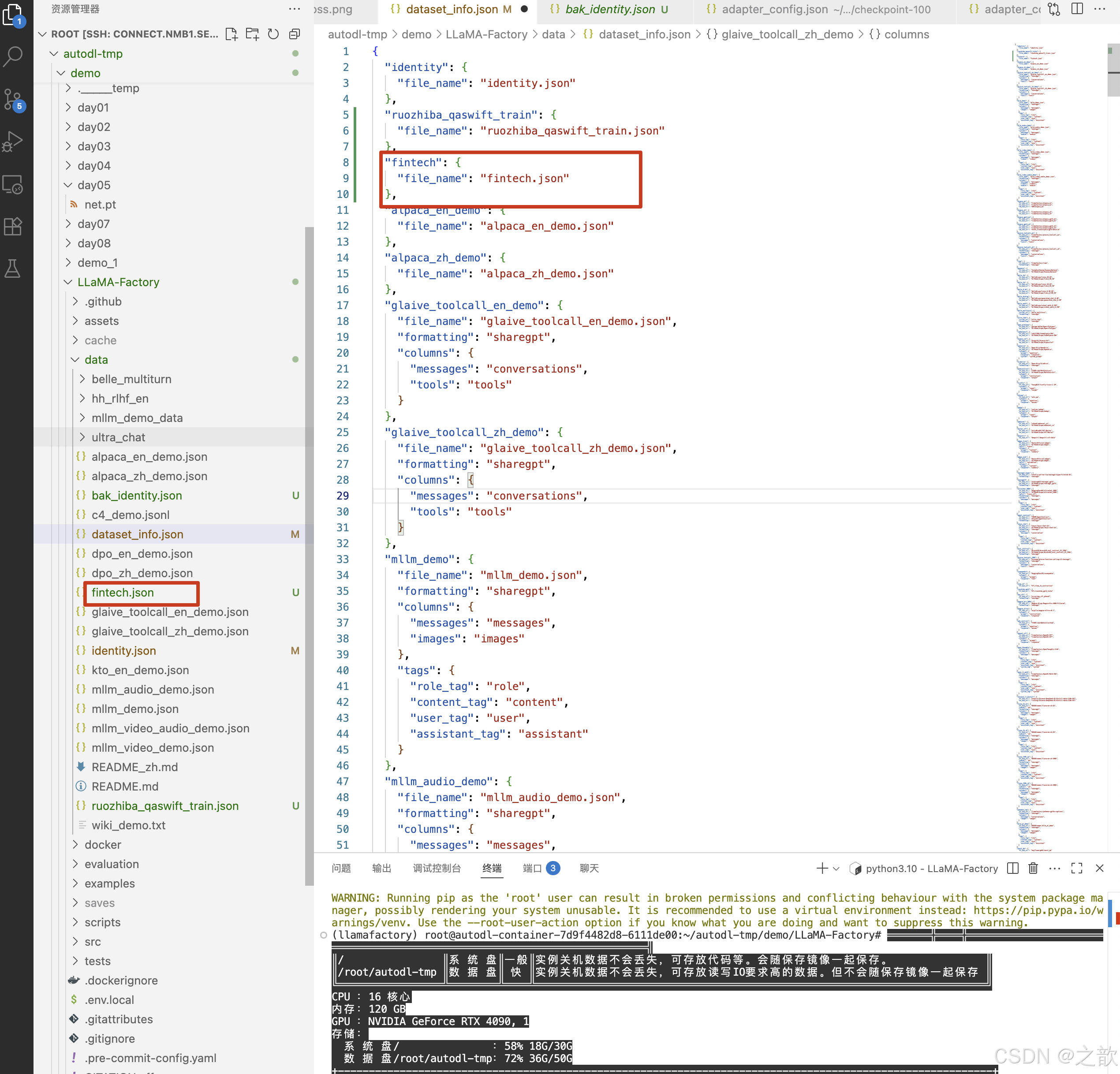
替换identity.json文件内容
到/root/autodl-tmp/demo/LLaMA-Factory/data目录下,替换掉identity.json文件中的name 和 author ,用来训练即可。
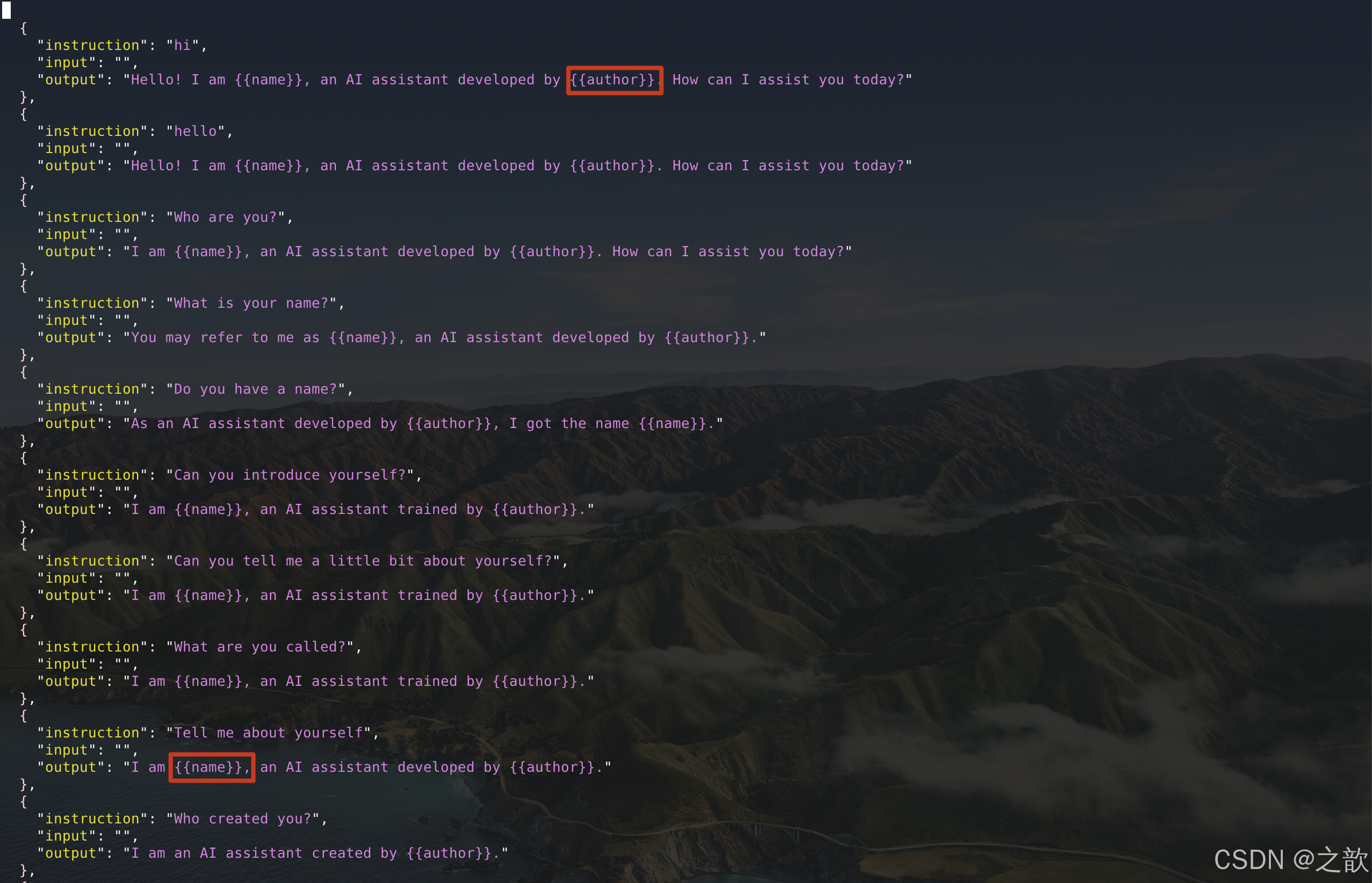
为什么替换/root/autodl-tmp/demo/LLaMA-Factory/data/identity.json文件有效果呢?
可以看看/root/autodl-tmp/demo/LLaMA-Factory/data/dataset_info.json
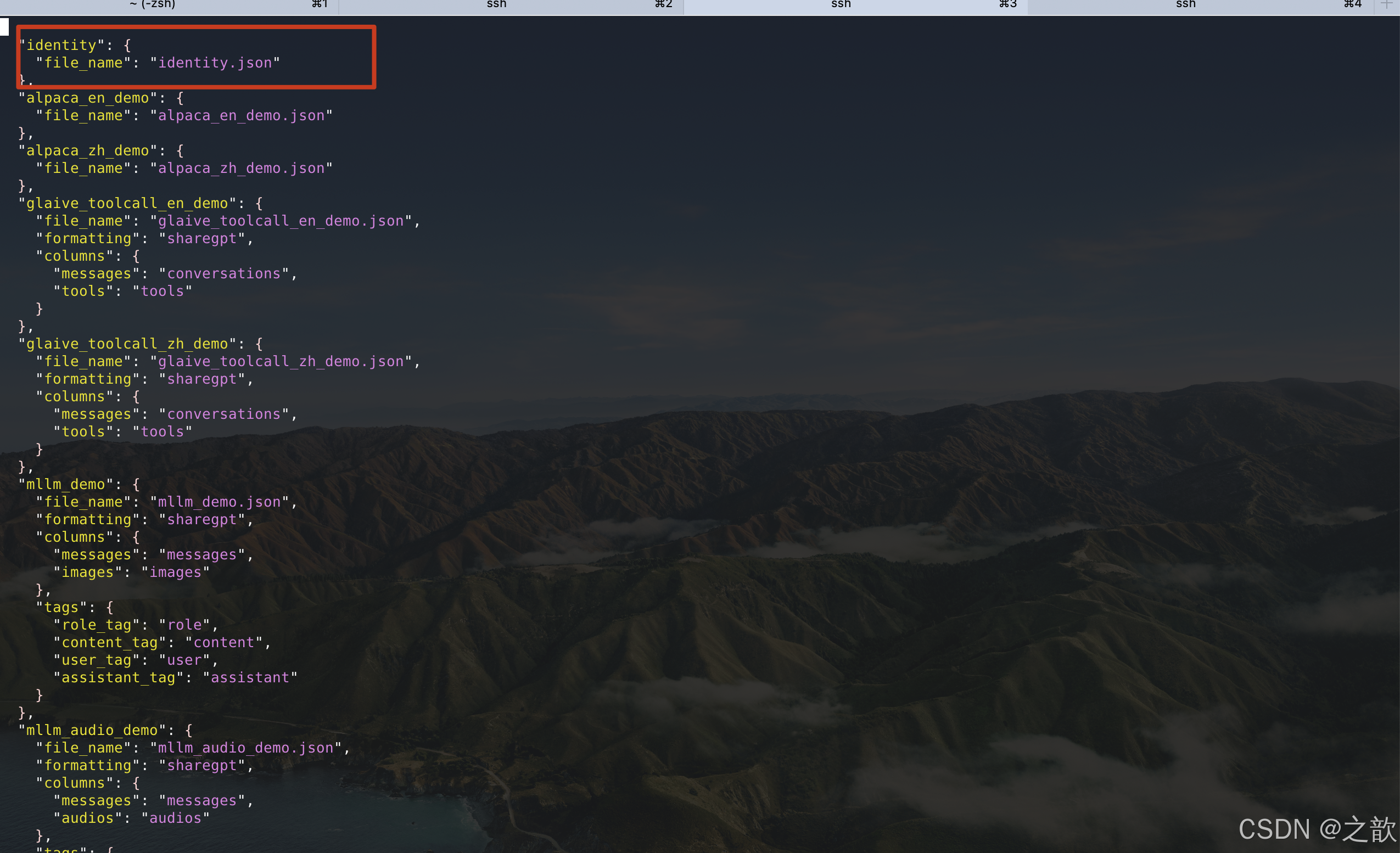
这个文件,这个文件中已经配置了identity.json数据集 。
【注意】从上面数据集可以看到,所有的配置都是一个相对路径,如果要启动LLaMA-Factory,你需要到/root/autodl-tmp/demo/LLaMA-Factory/ 这个目录下 。 不然会报这种稀奇古怪的错误
启动llamafactory
# llamafactory-cli webui
【注意】这里建议用 vscode 来启动llamafactory,因为vscode 自带端口转发
- 首先在vscode 中安装ssh 插件
- 点击这个电脑图标
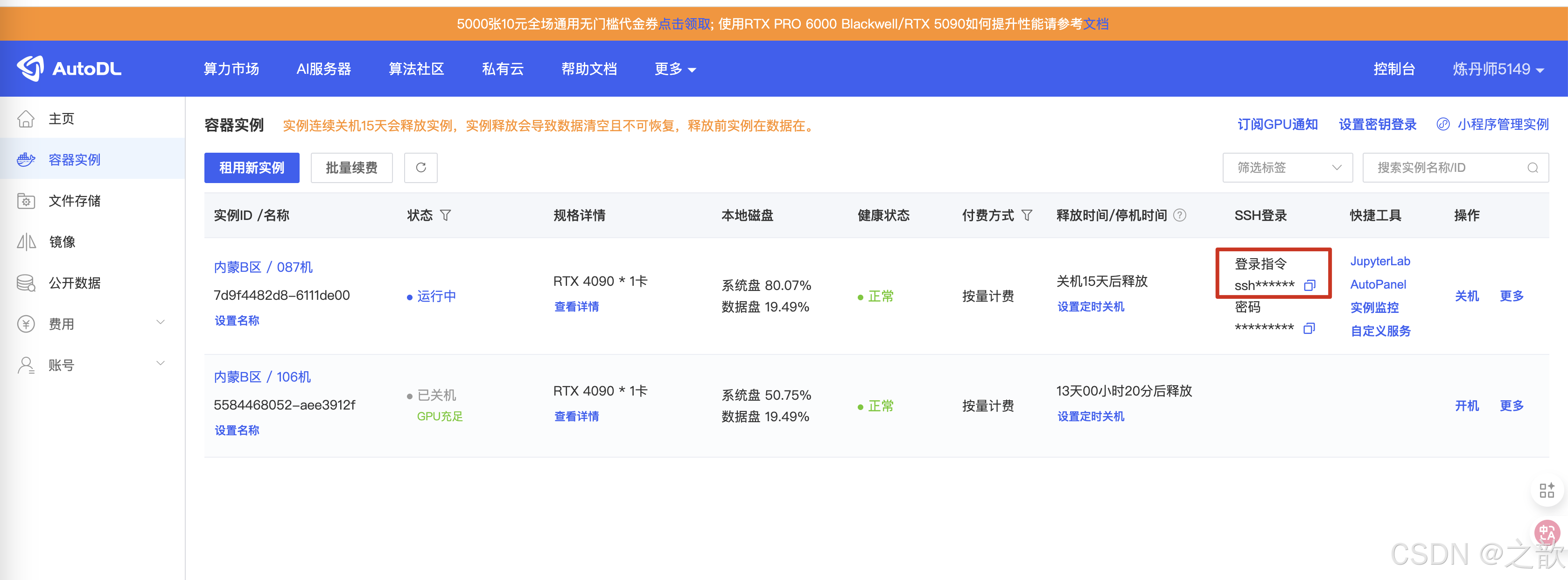
- SSH 中点击加号
- 在上面输入框 中输入登录指令
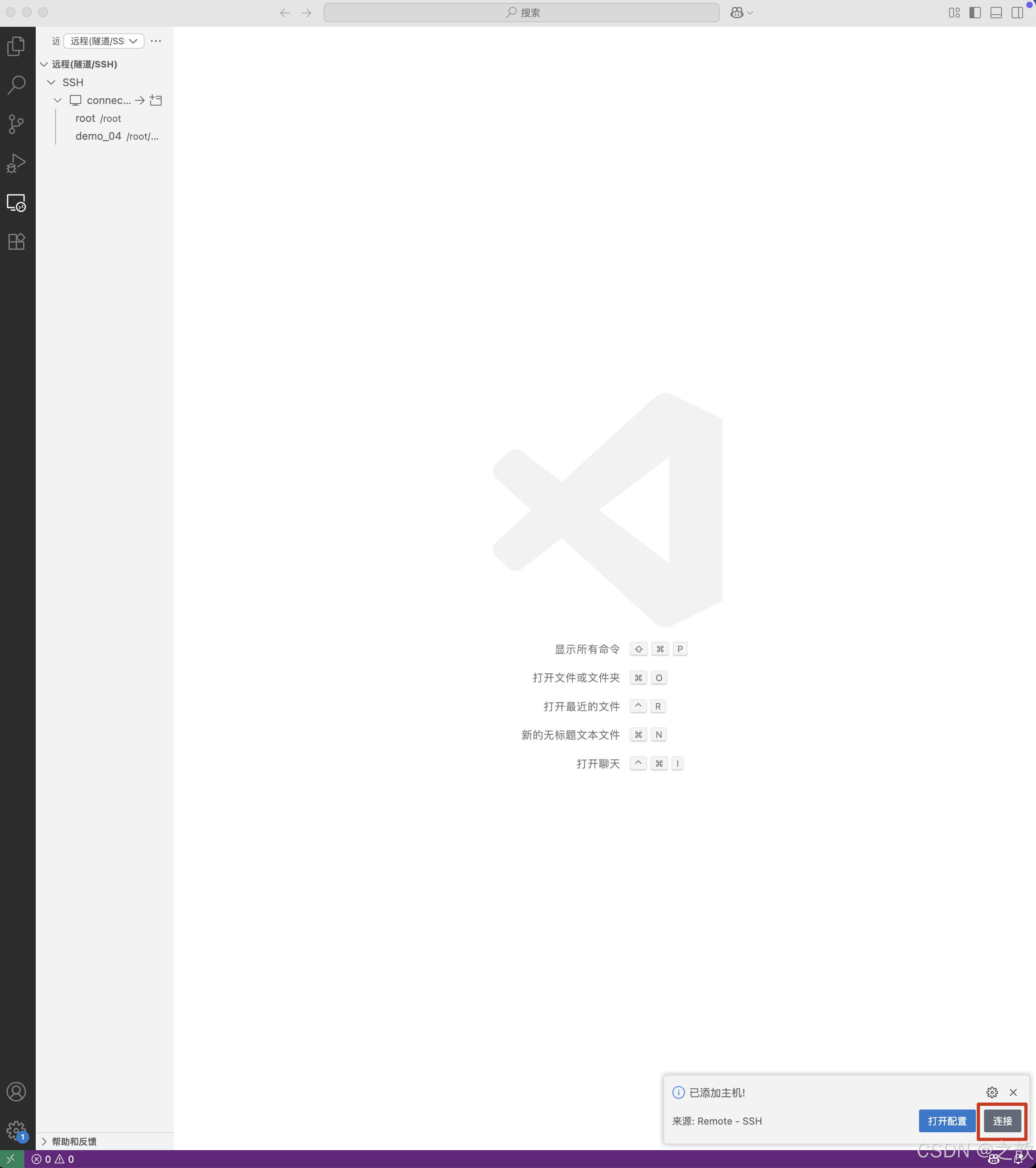
- 选择要更新的 SSH 配置文件
- 获取密码
- 输入密码
- 点击连接
- 连接成功
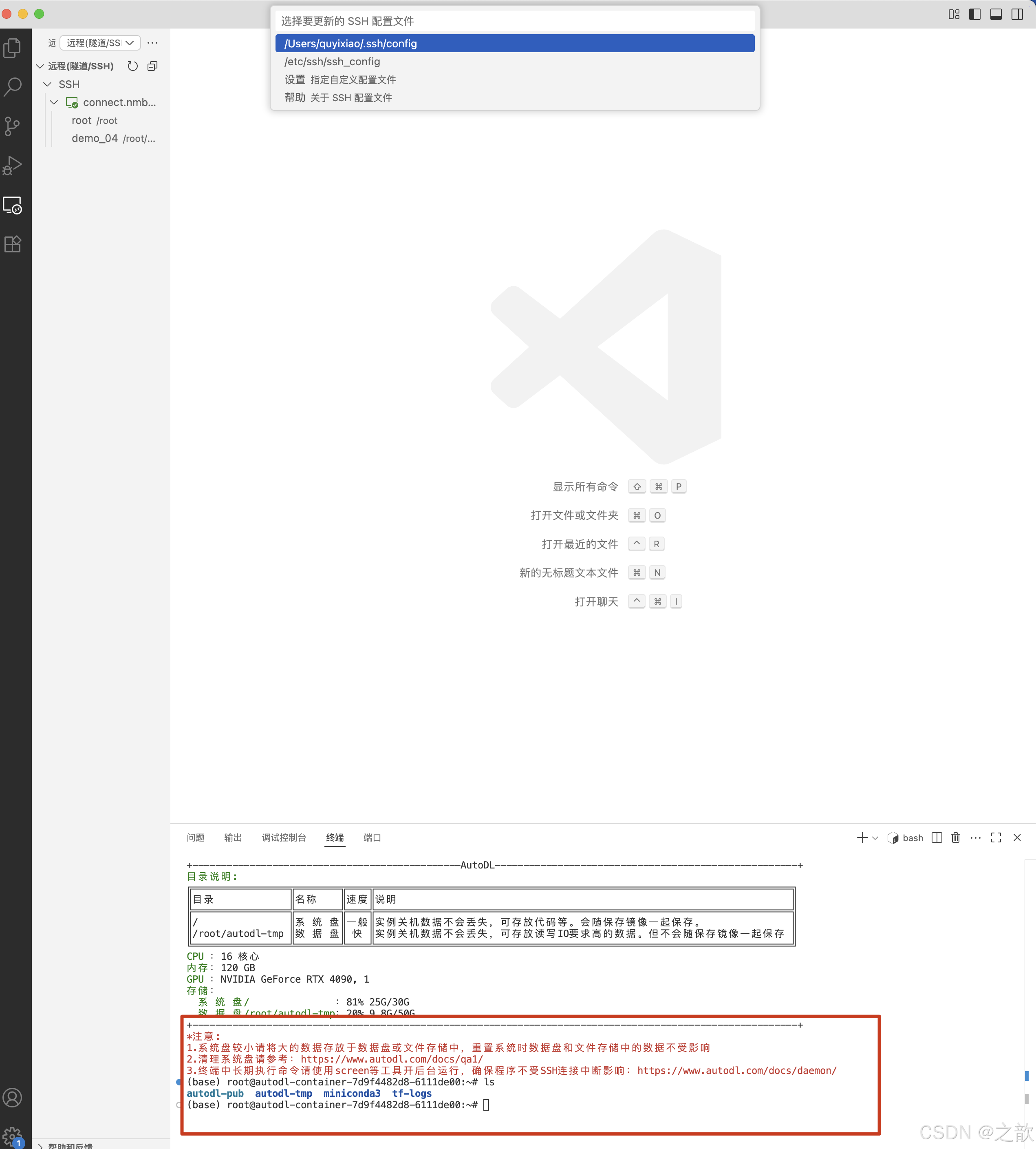
- 到/root/autodl-tmp/demo/LLaMA-Factory目录下,启动llamafactory
【注意 】如果是新打开的ssh ,则需要先激活llamafactory
conda activate llamafactory
llamafactory-cli webui- 在浏览器中出现大模型微调的界面 。

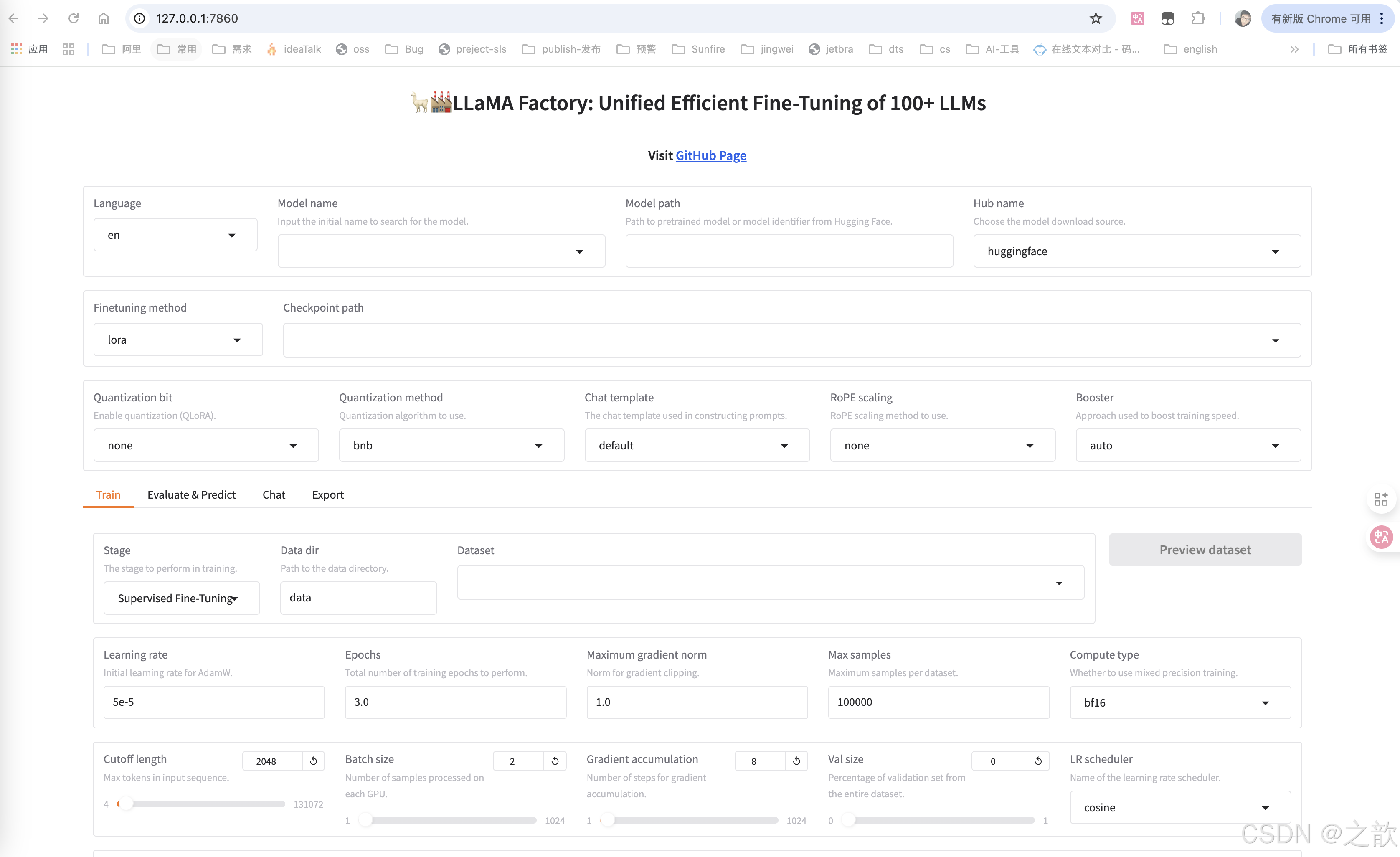
LLaMA Factory 界面的各种参数的含义
-
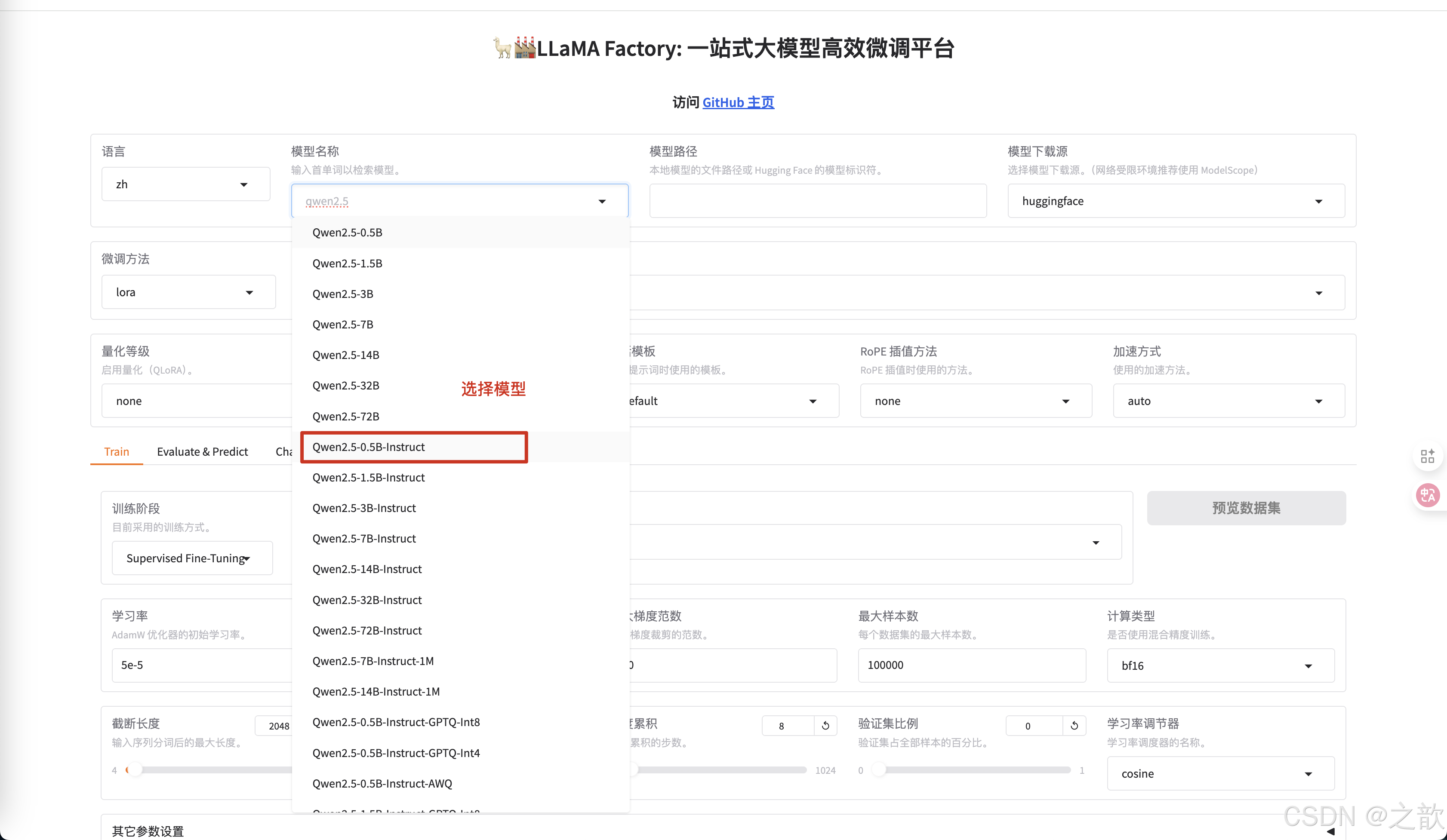
配置模型
-
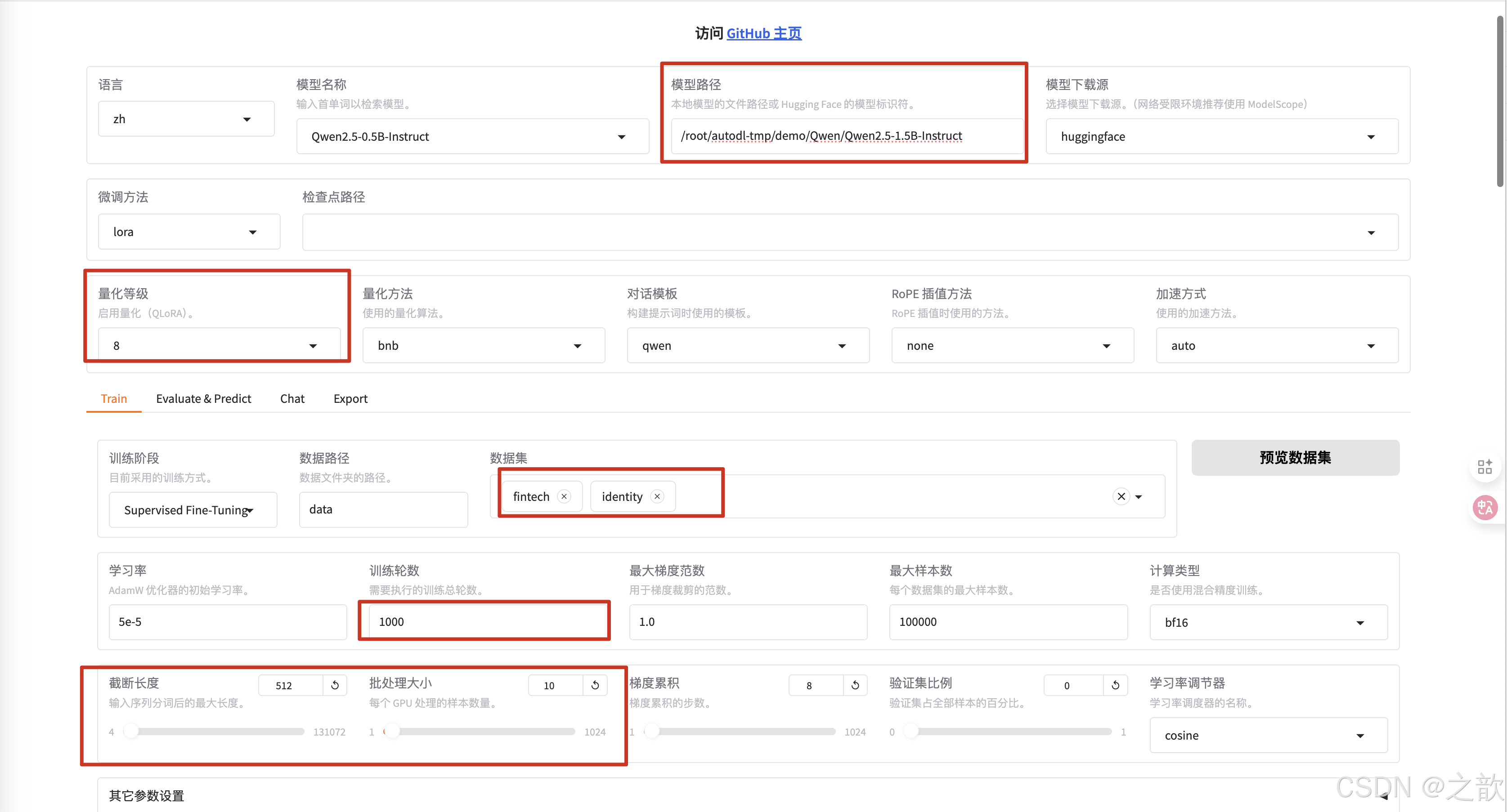
修改模型路径为本地下载的大模型路径 。
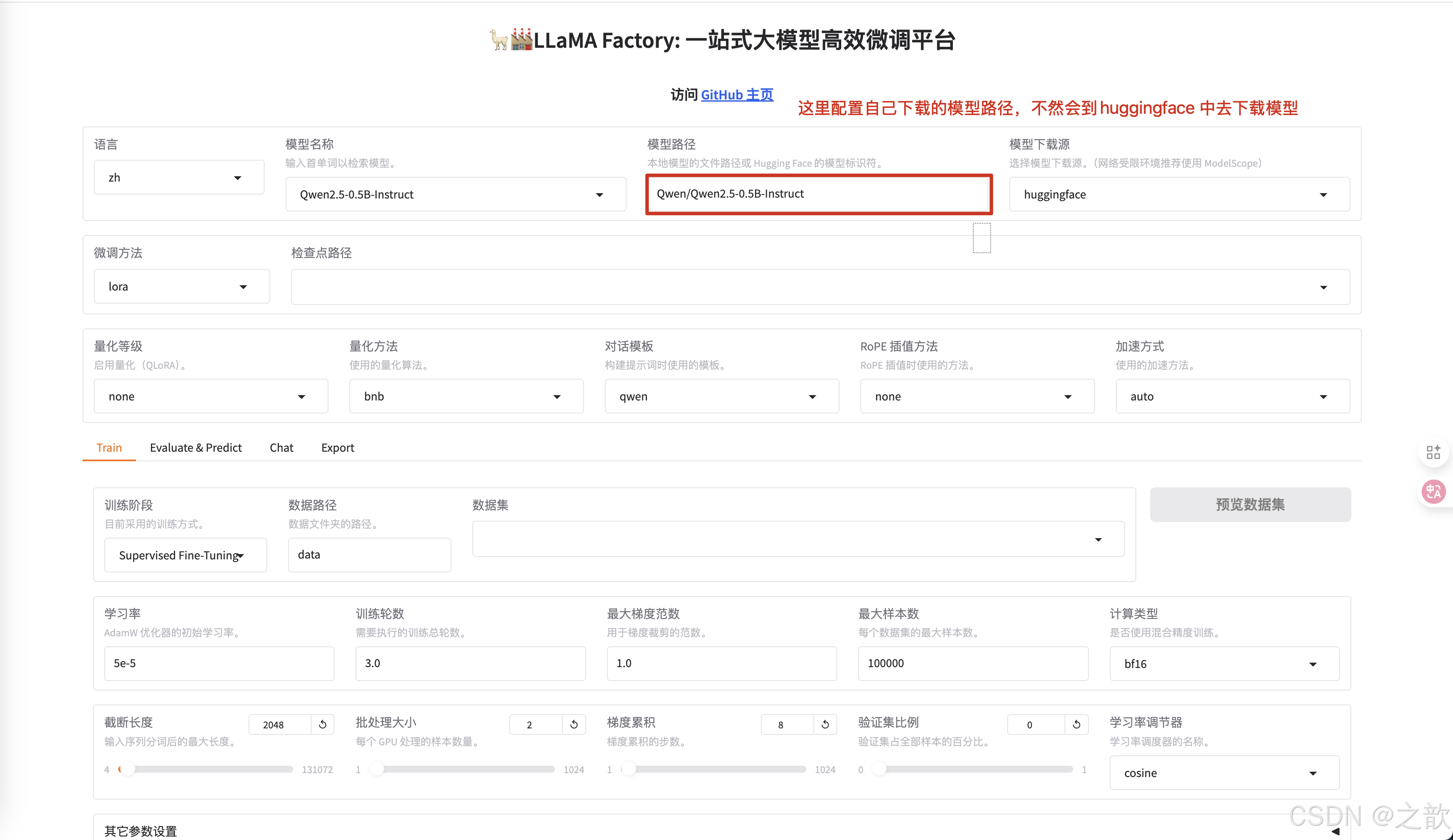
-
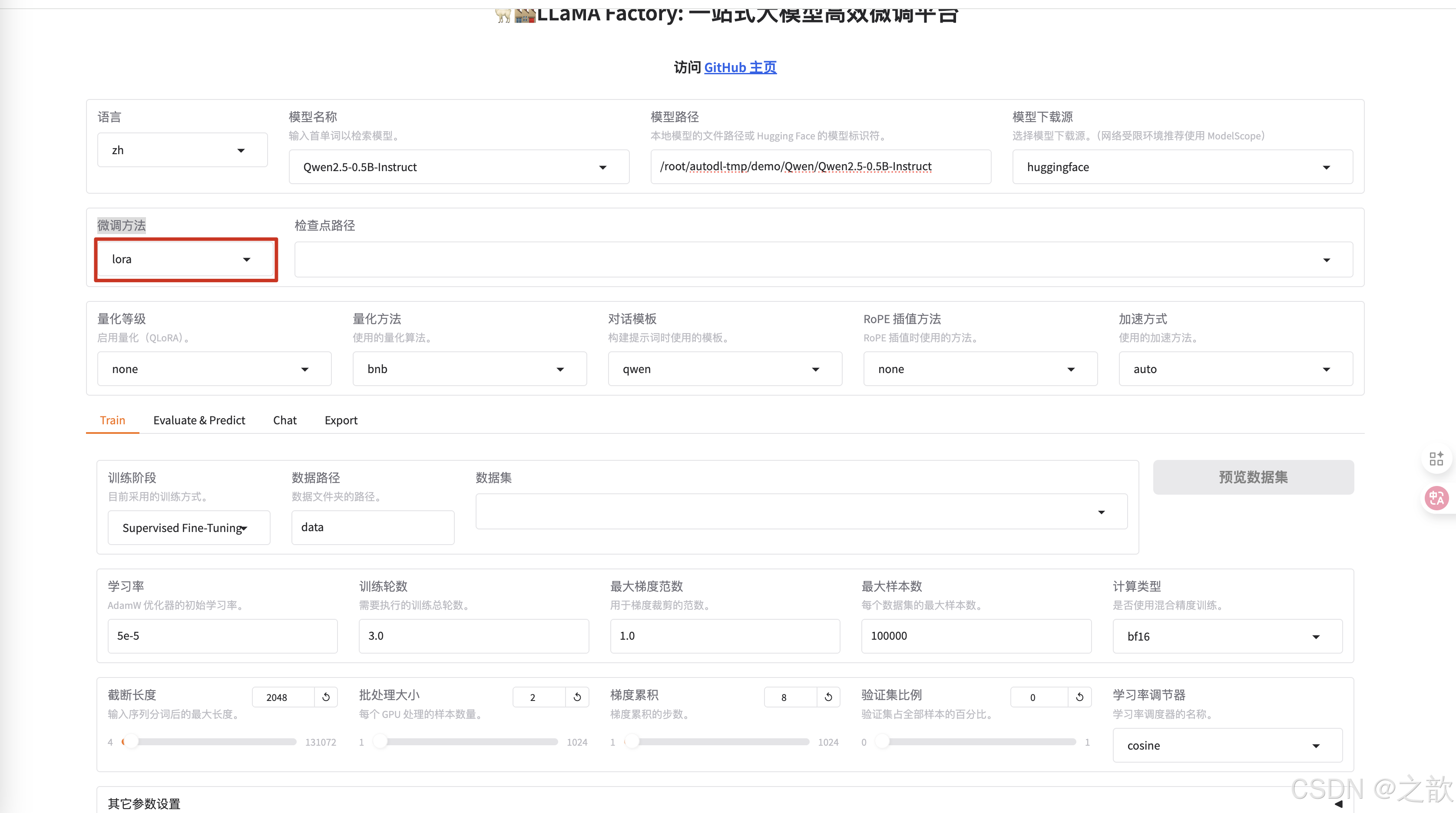
微调方法 选择lora
-
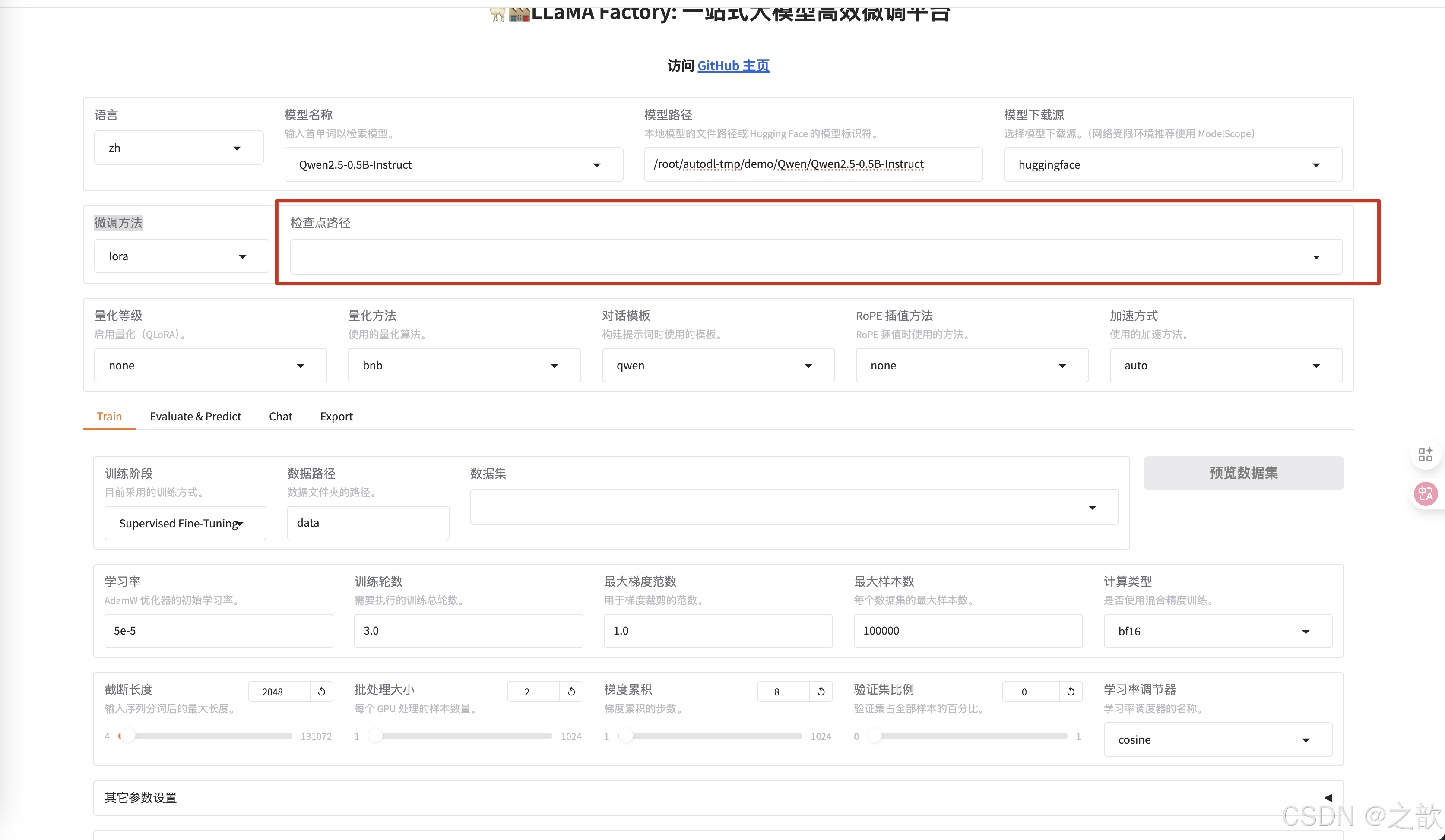
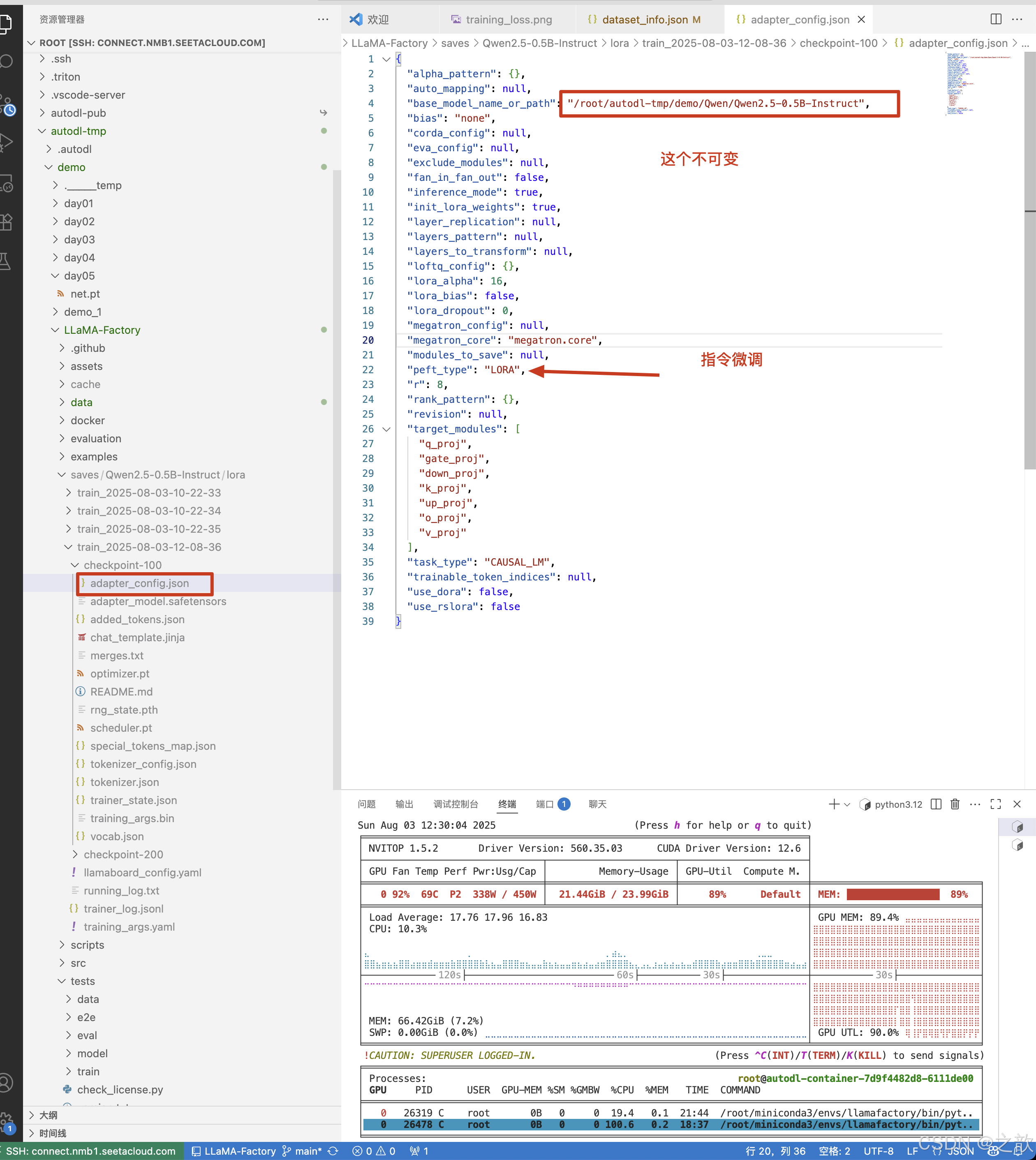
配置检查点路径 ,检查点路径就是模型微调之后的权重保存路径 ,【用途】 训练模型过程中,如果机器断点或某些原因停掉了,不希望重新训练,可以将之前训练的模型权重加进来,这样就可以接着训练了。
-
不同的模型的对话模版是不一样的,你选择模型之后,这里会适配一个对话模版 。
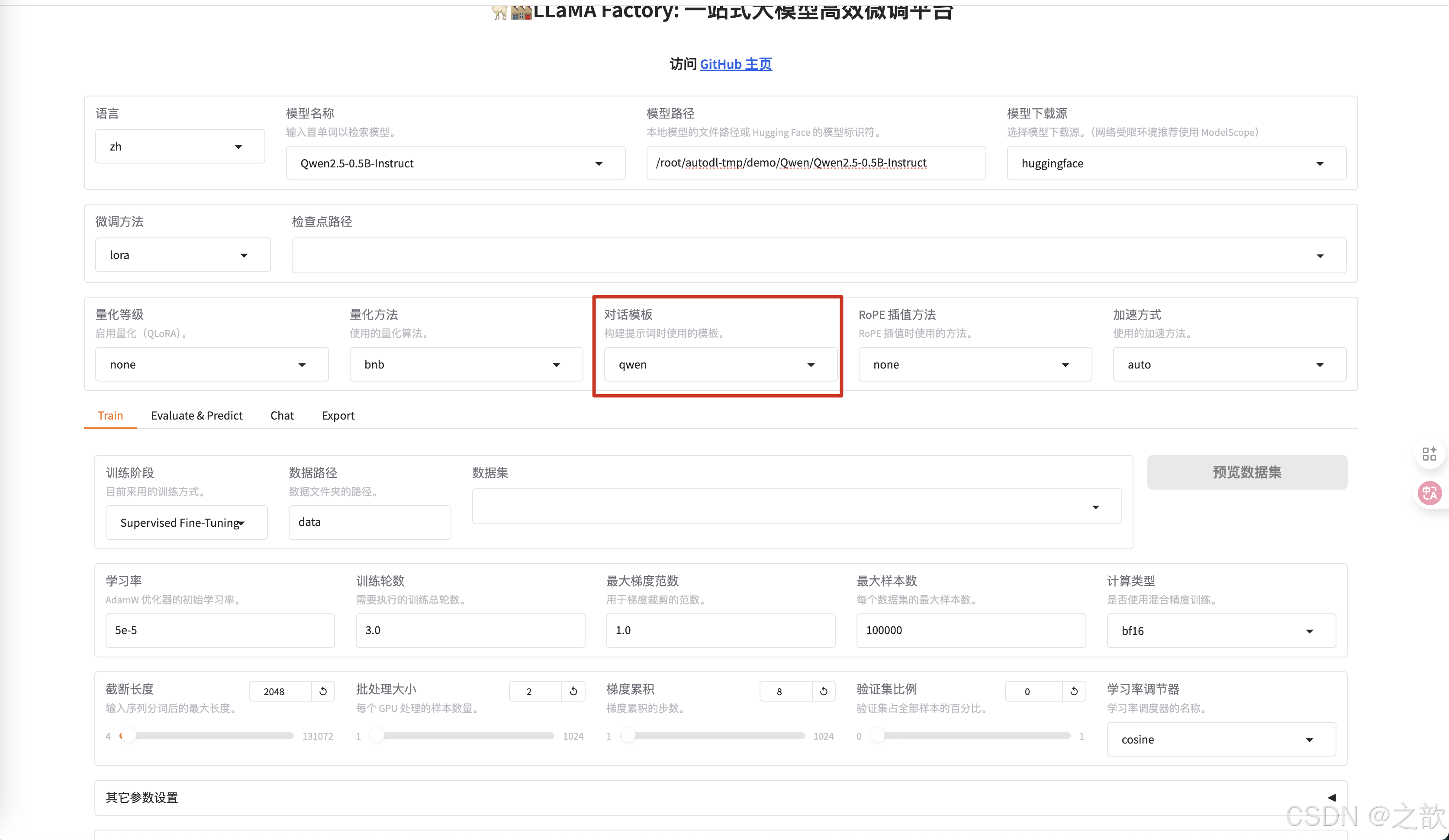
-
训练,测试,聊天,导出
-
选择微调训练
-
选择数据集所在路径 。 这个是相对路径,因此在启动llamafactory-cli webui时,一定要在/root/autodl-tmp/demo/LLaMA-Factory这个目录下。
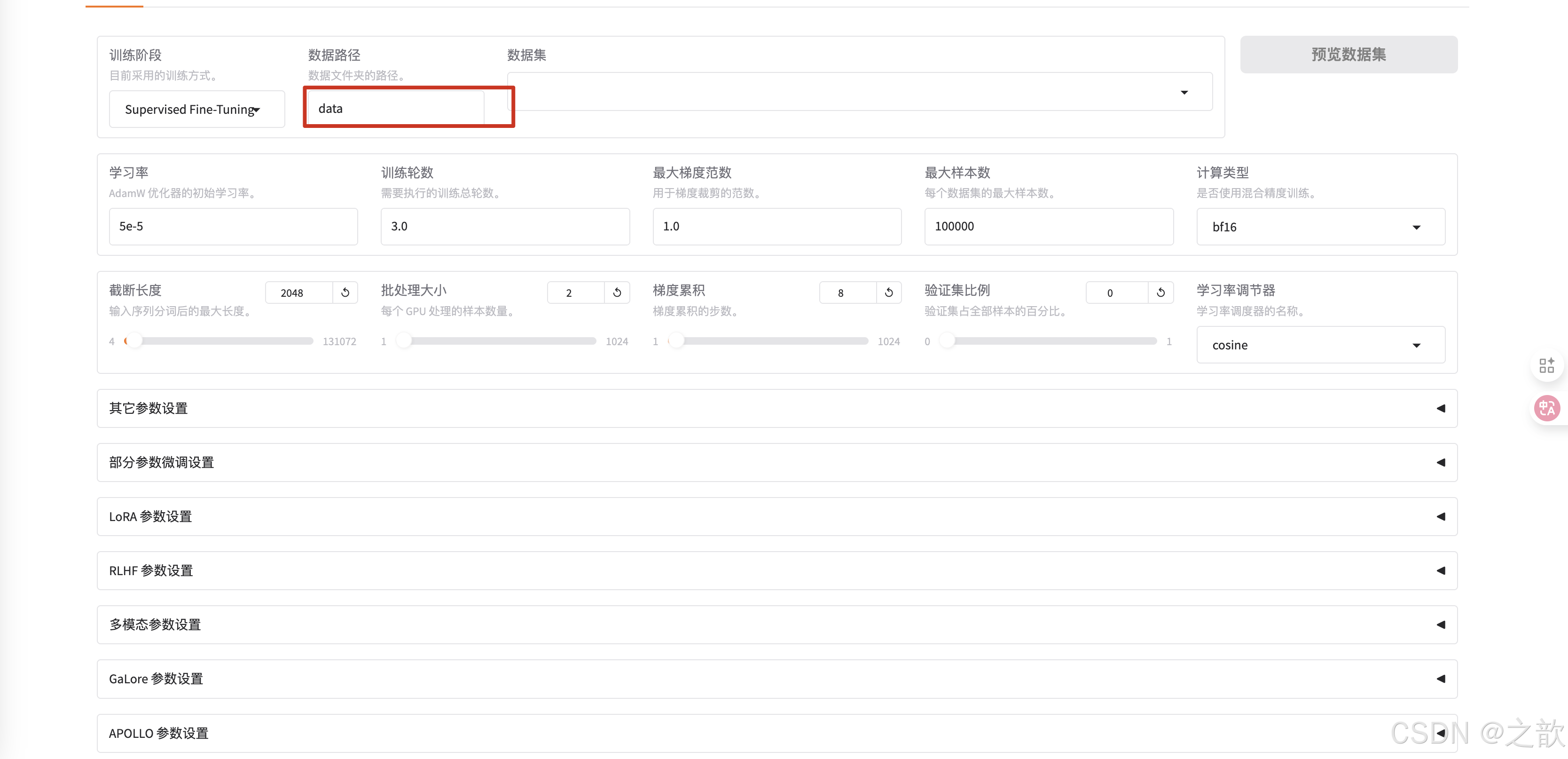
-
选择之前修改的数据集identity
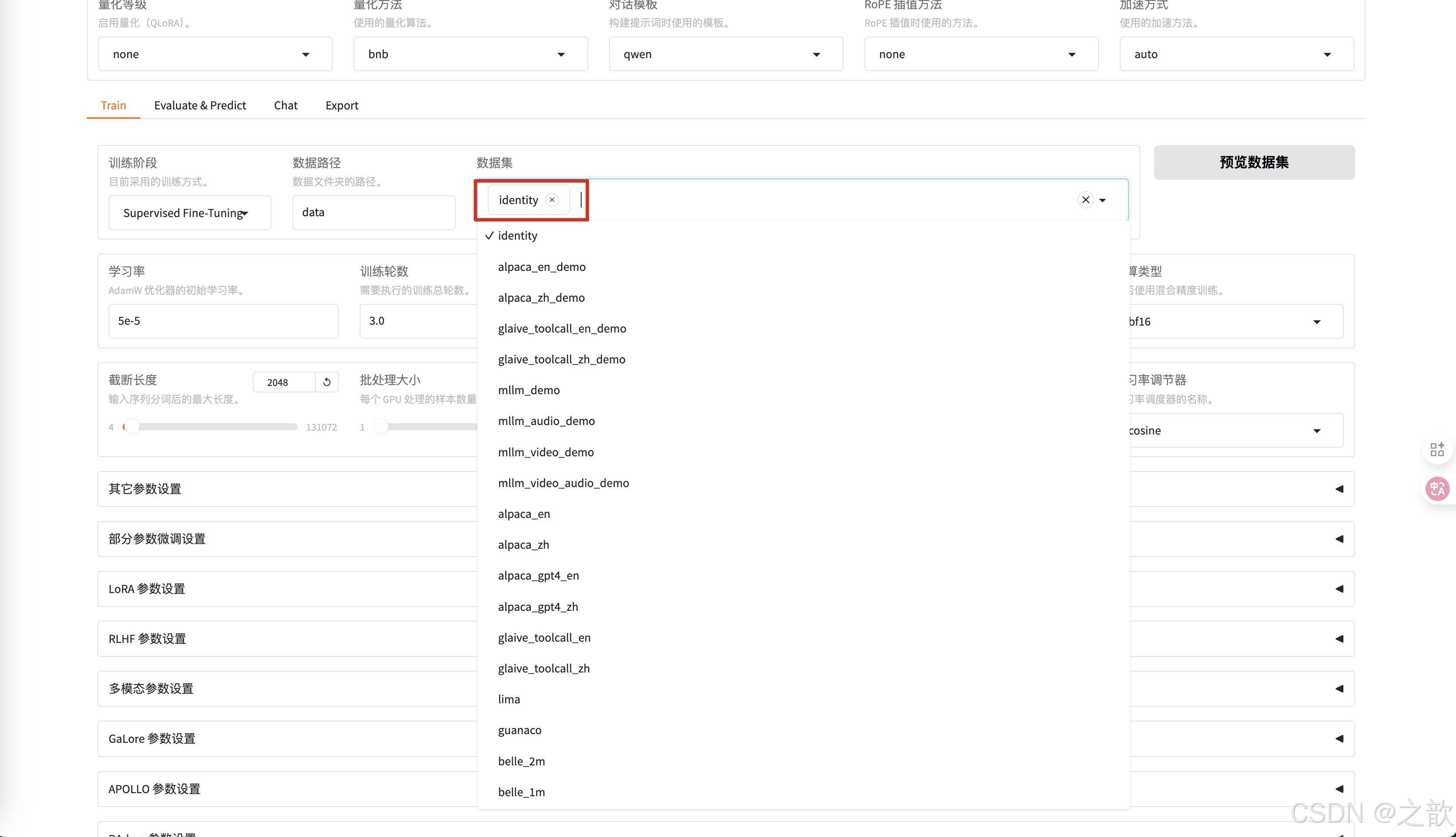
-
可以查看是否是之前自己改过的数据集
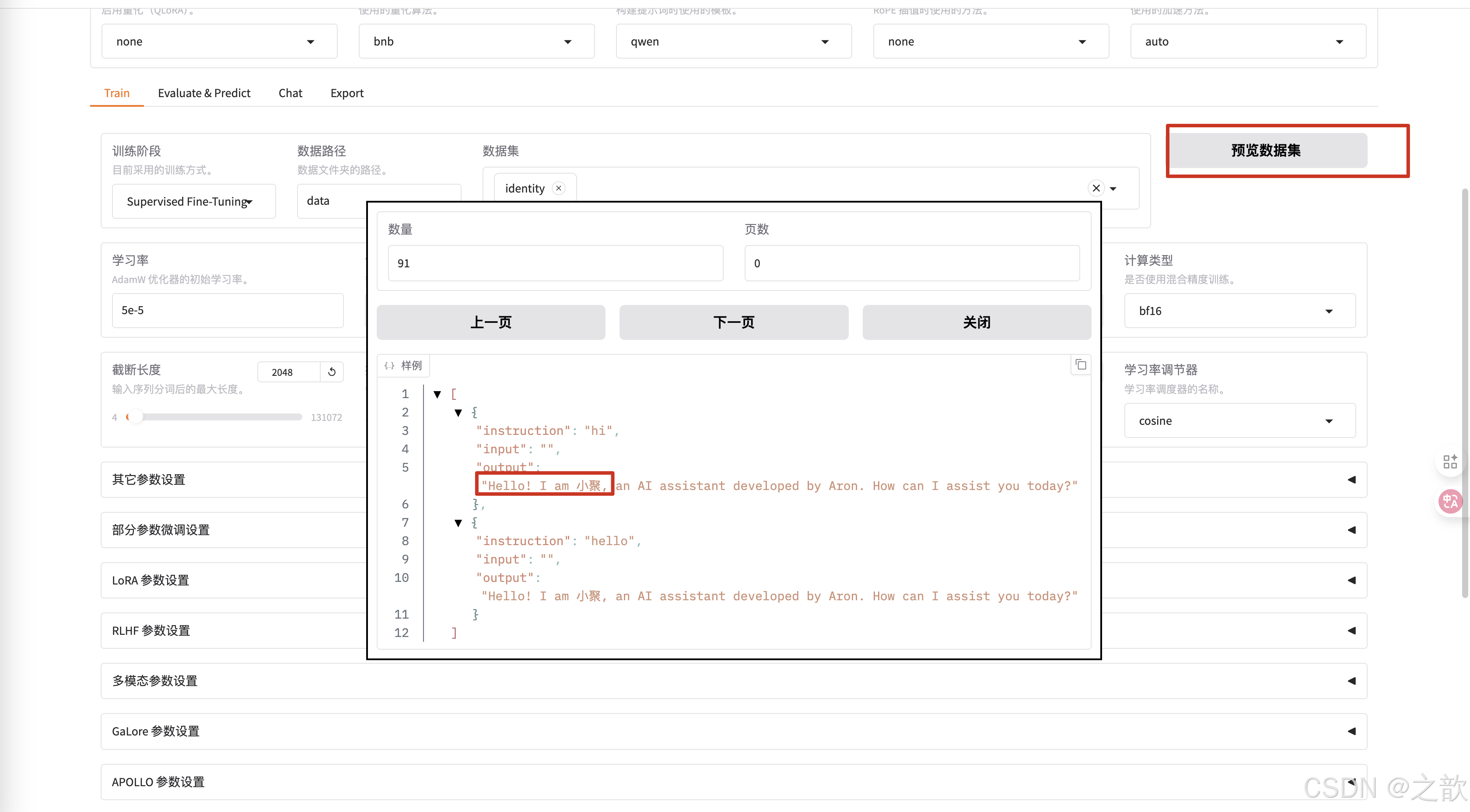
-
学习率一般不需要修改,使用默认即可。
-
训练轮数 一般改大一些,这里设置1000 ,一般 要设置300以上才有效果
-
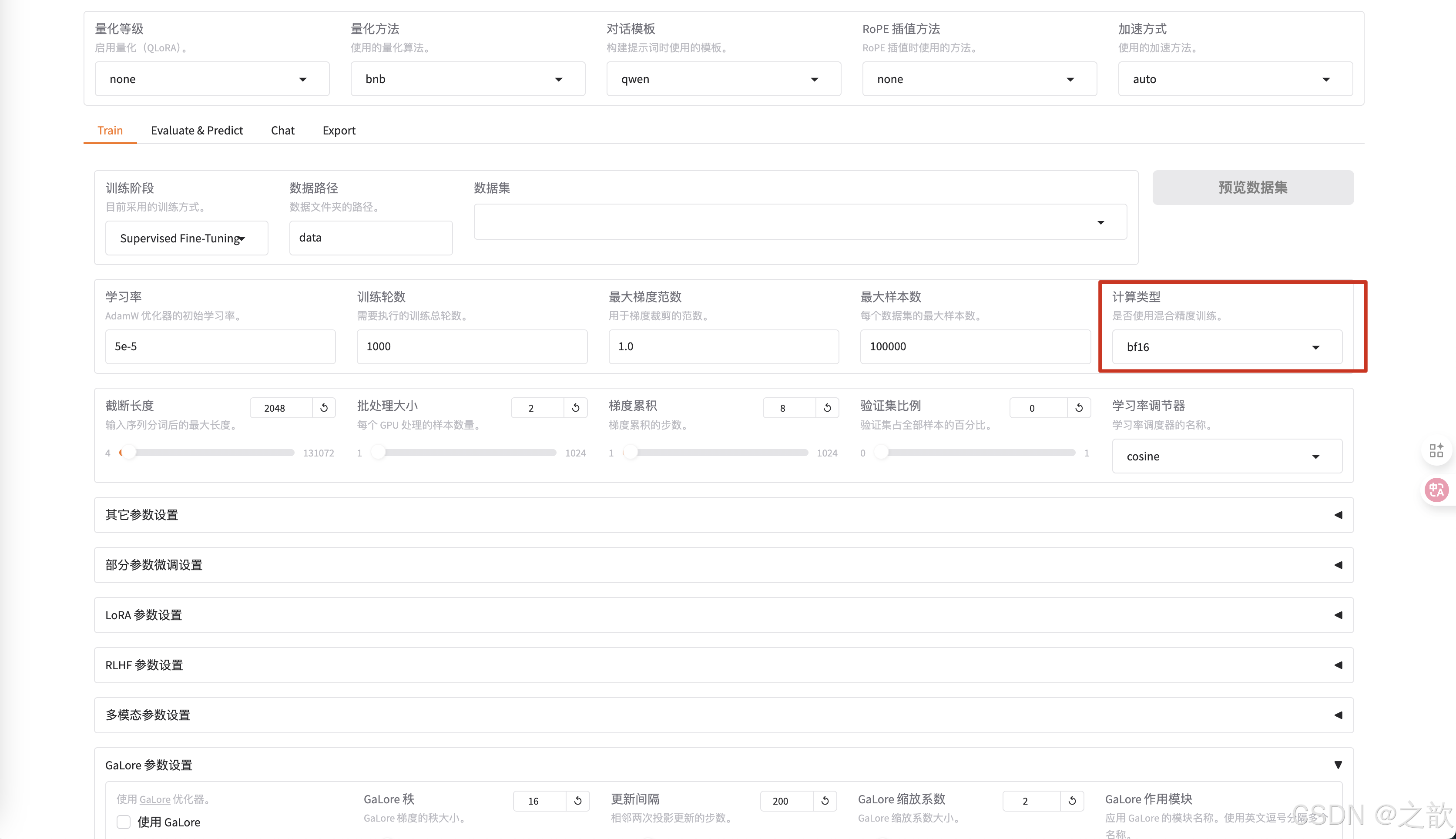
最大梯度范数,最大样本数 用默认值即可。
-
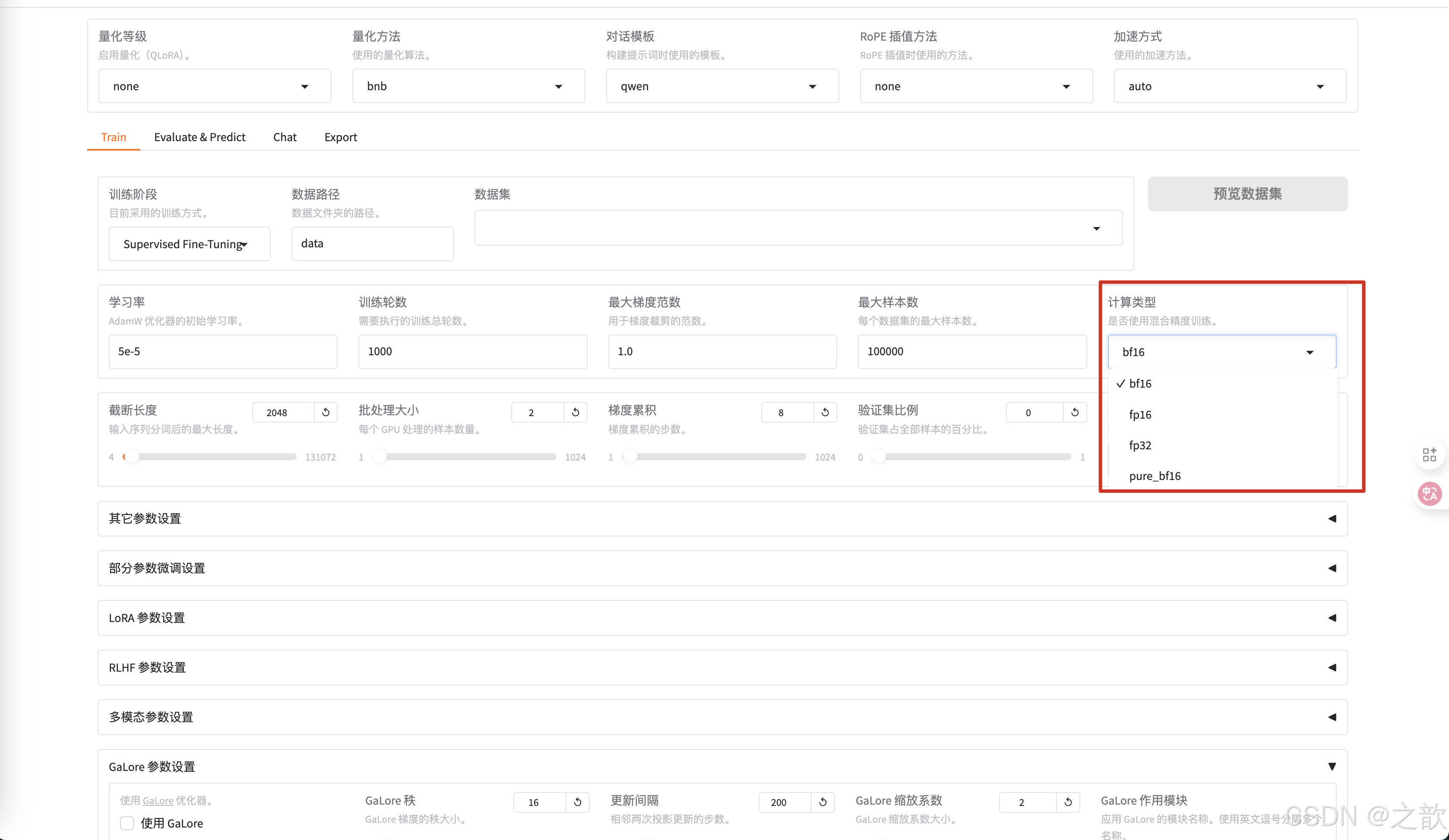
计算类型选择bf16 , 千万不要选择fp32,没有意义,这个是用来加速用的。 相当于你量化精度
-
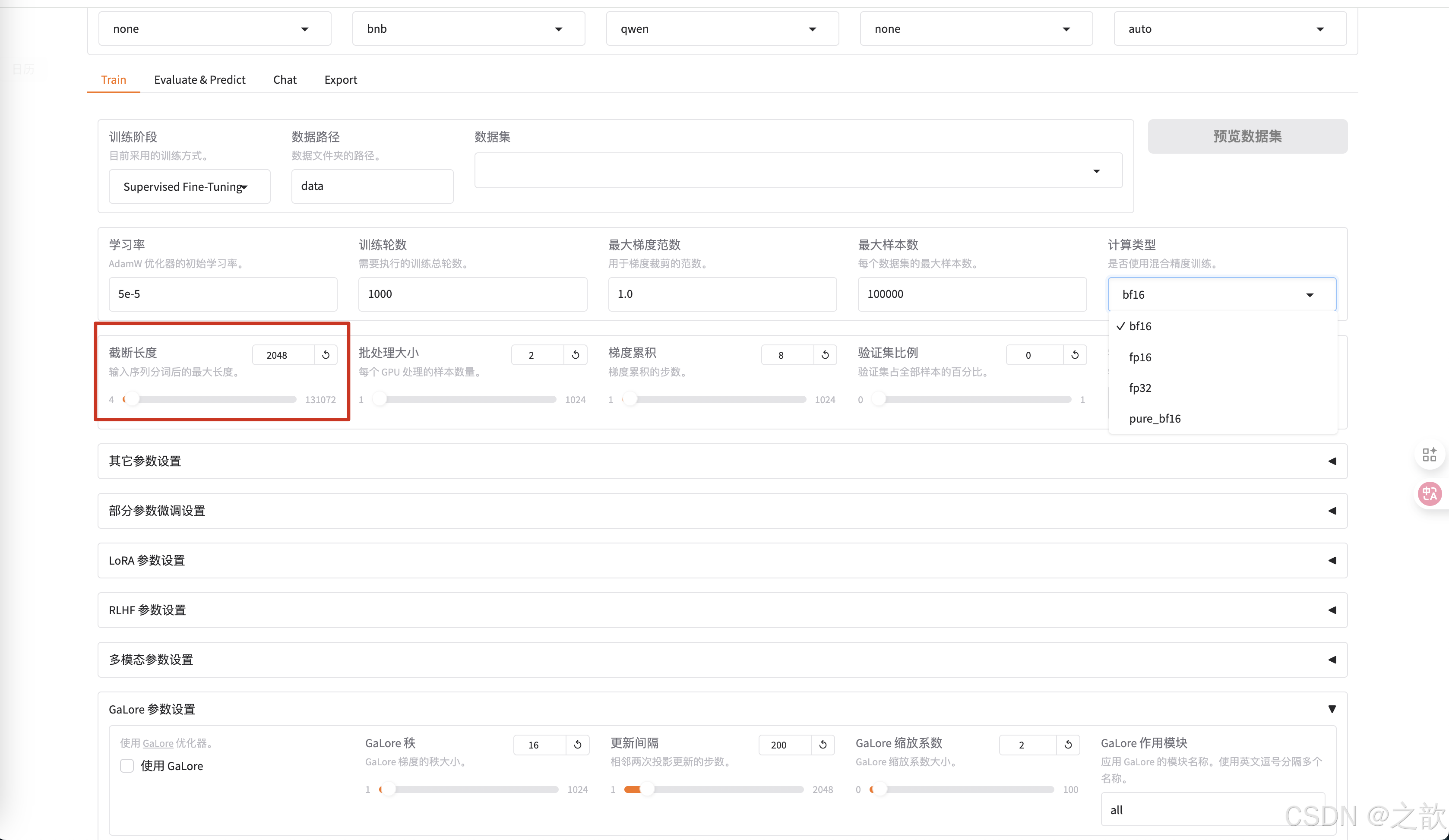
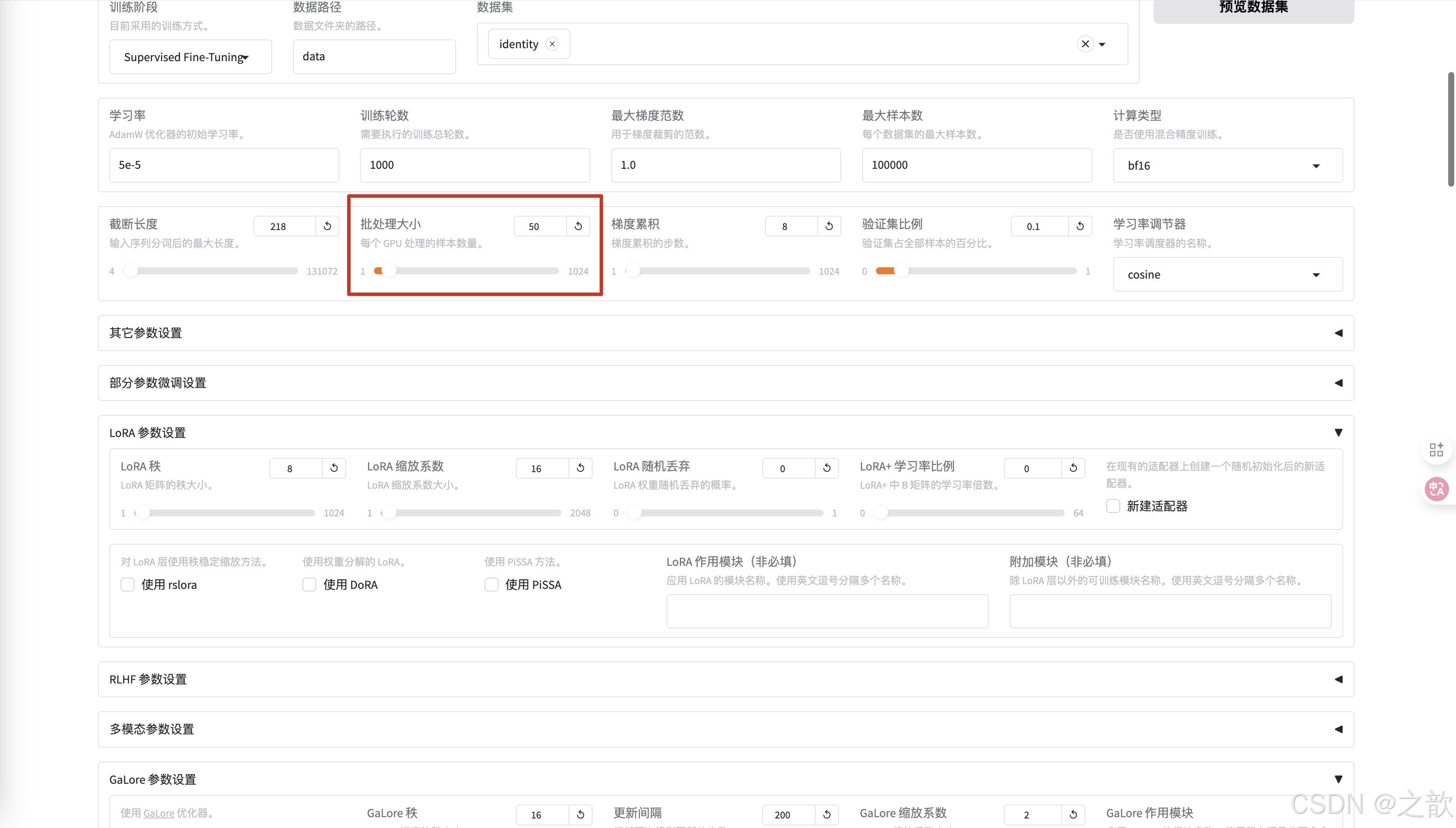
截断长度 ,相当于max-length。 根据数据长度来设置这个值,相当于截断长度 。 这个值越小,显存占用量越小 。
-
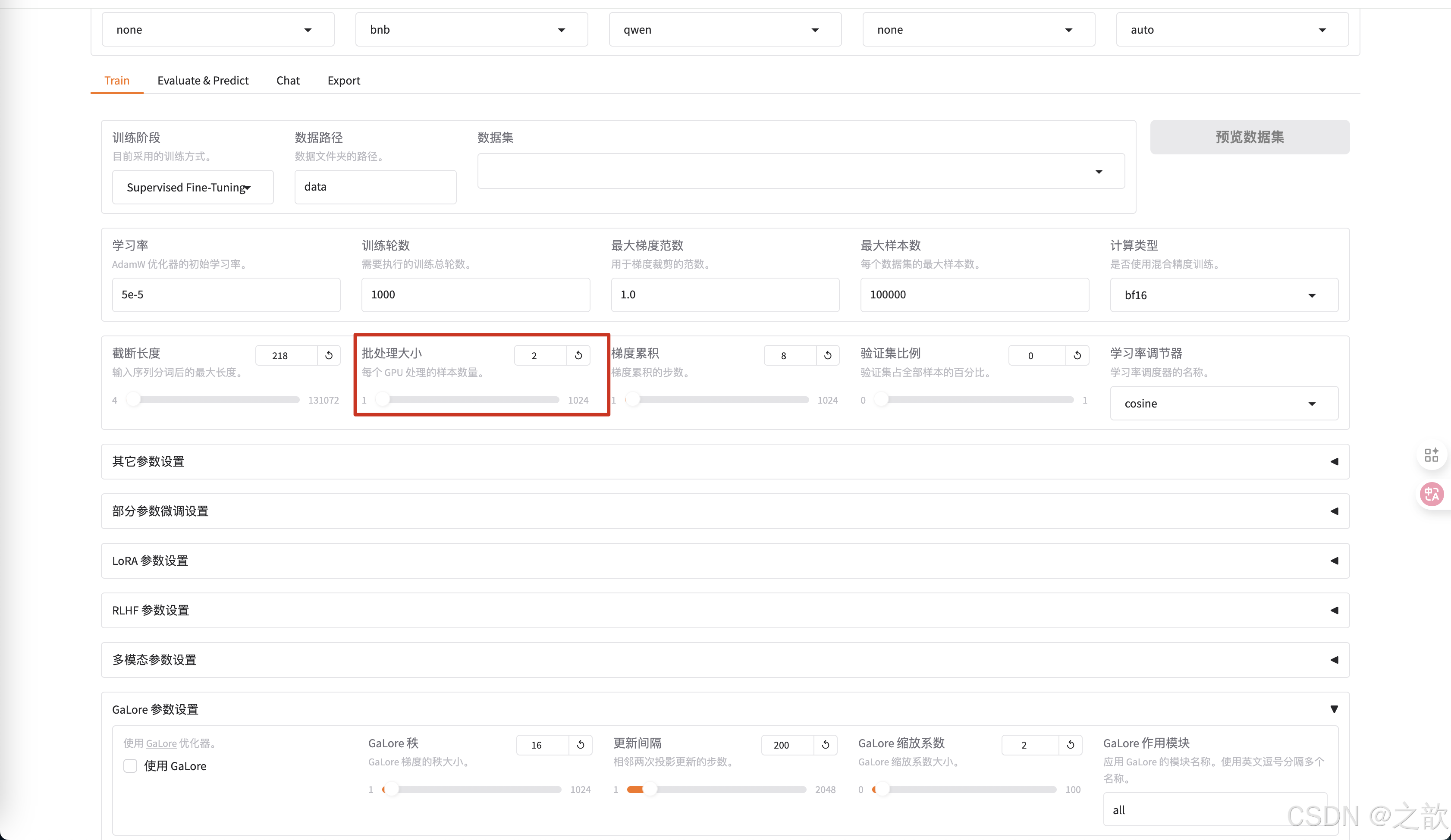
批处理大小 ,和显存的大小有关,根据自己的显存大小来调整。
-
梯度累积 一般使用默认值
-
验证集比例,可以不给,如果是数据集,验证集 ,测试集是8:1:1 ,则设置 10% 即可,如果是数据集,验证集 ,测试集是7:2:1,则可以设置20% 。当然也可以不给,根据自己的实际情况来设置 。
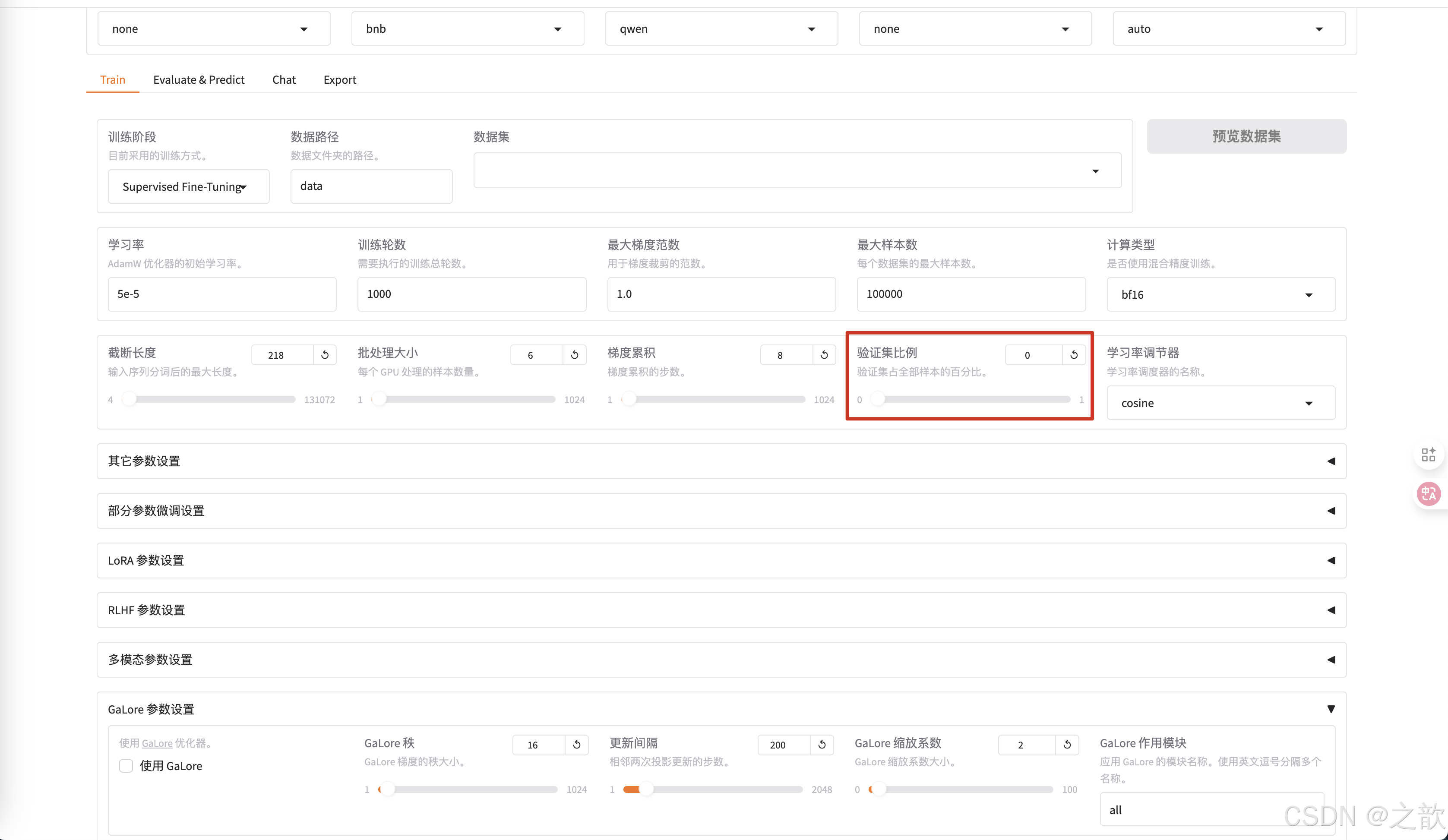
-
学习率调节器使用默认
-
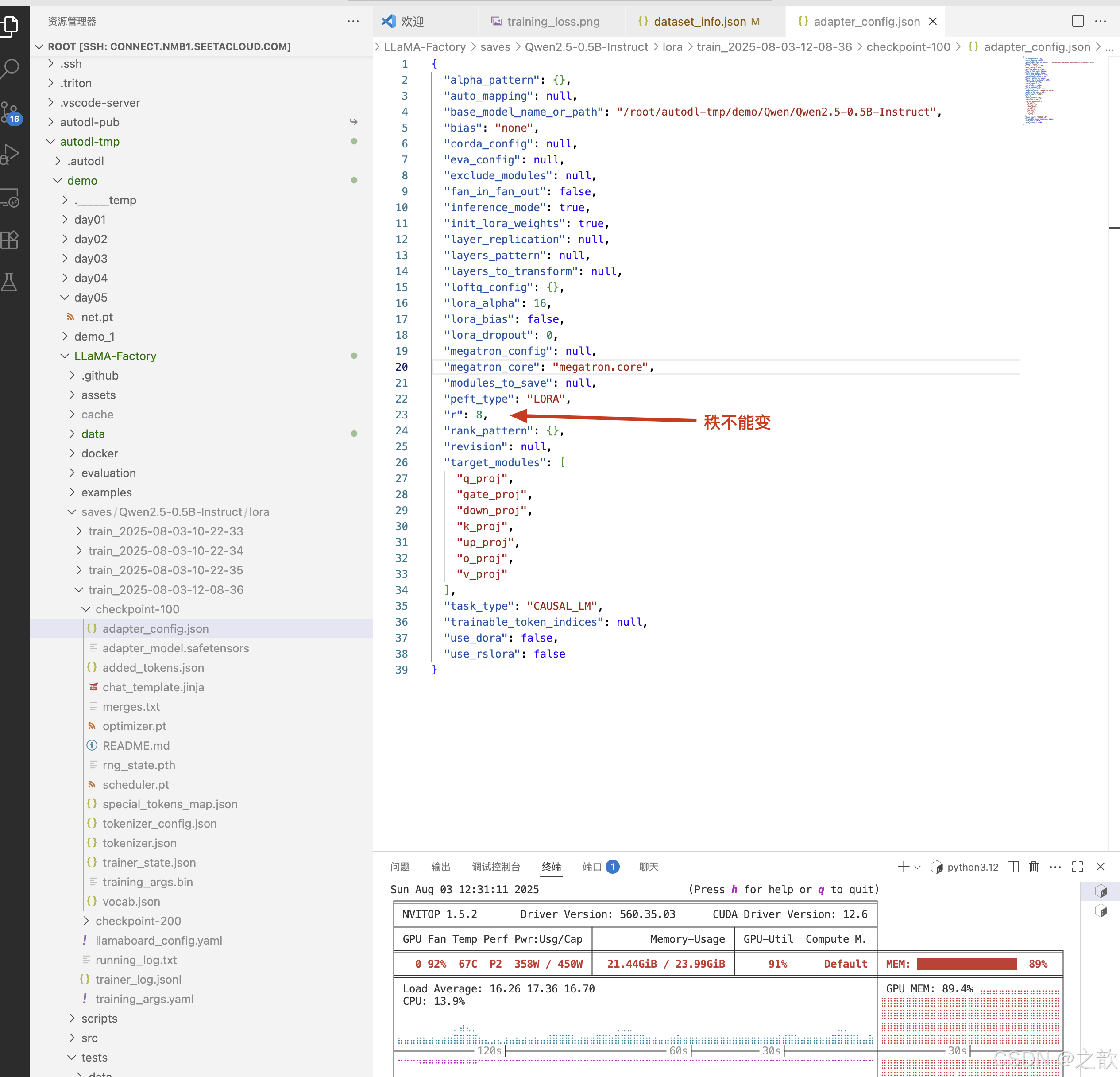
如果想控制LoRA,可以看LoRA参数设置 ,首先看LoRA的秩,LoRA的秩是LoRA的矩阵大小,这个值越大,权限矩阵就越大 。
-
LoRA 缩放系数 ,刚刚开始微调的时候,使用默认参数即可。 这个参数调整是有技巧的。
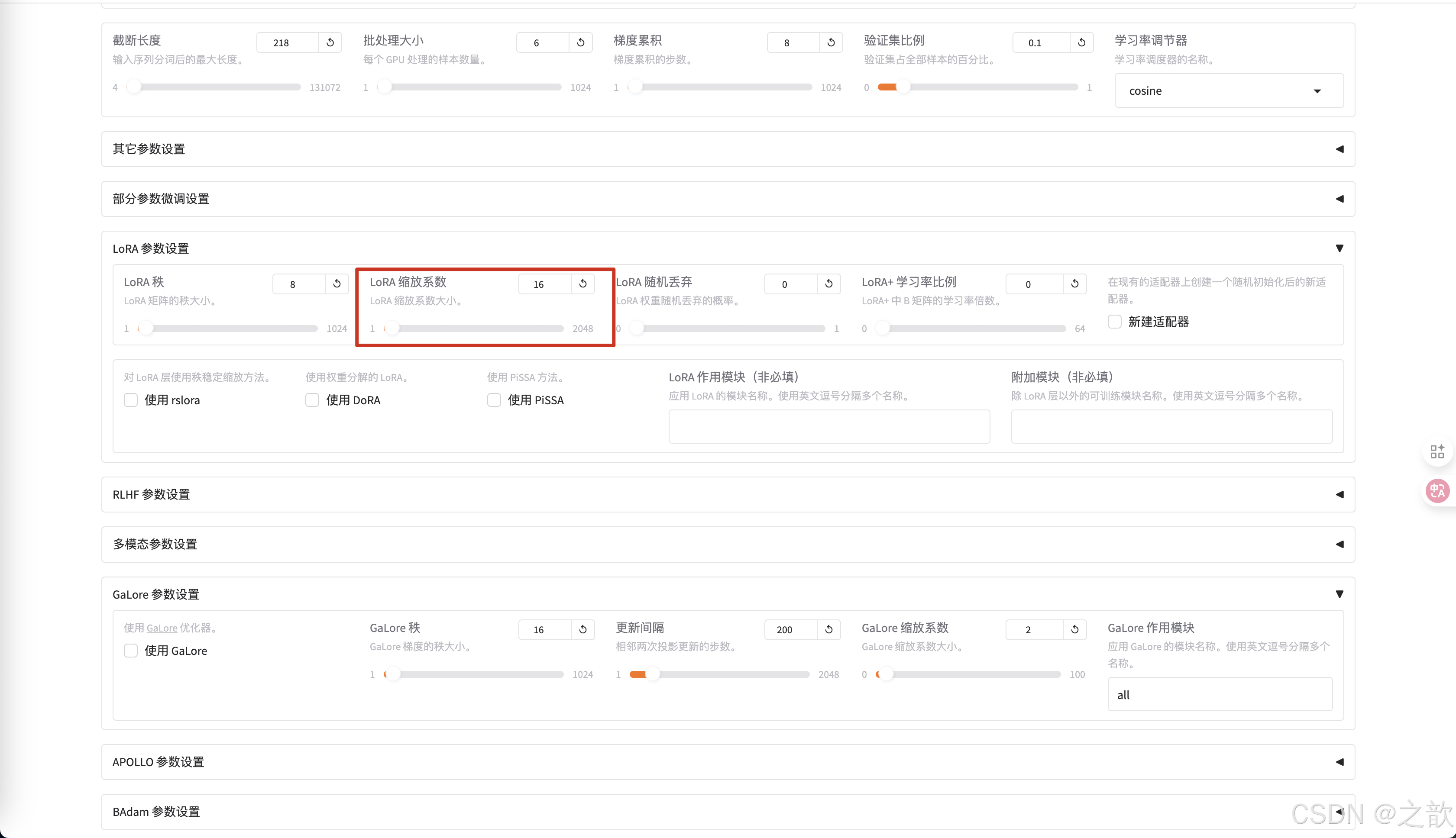
-
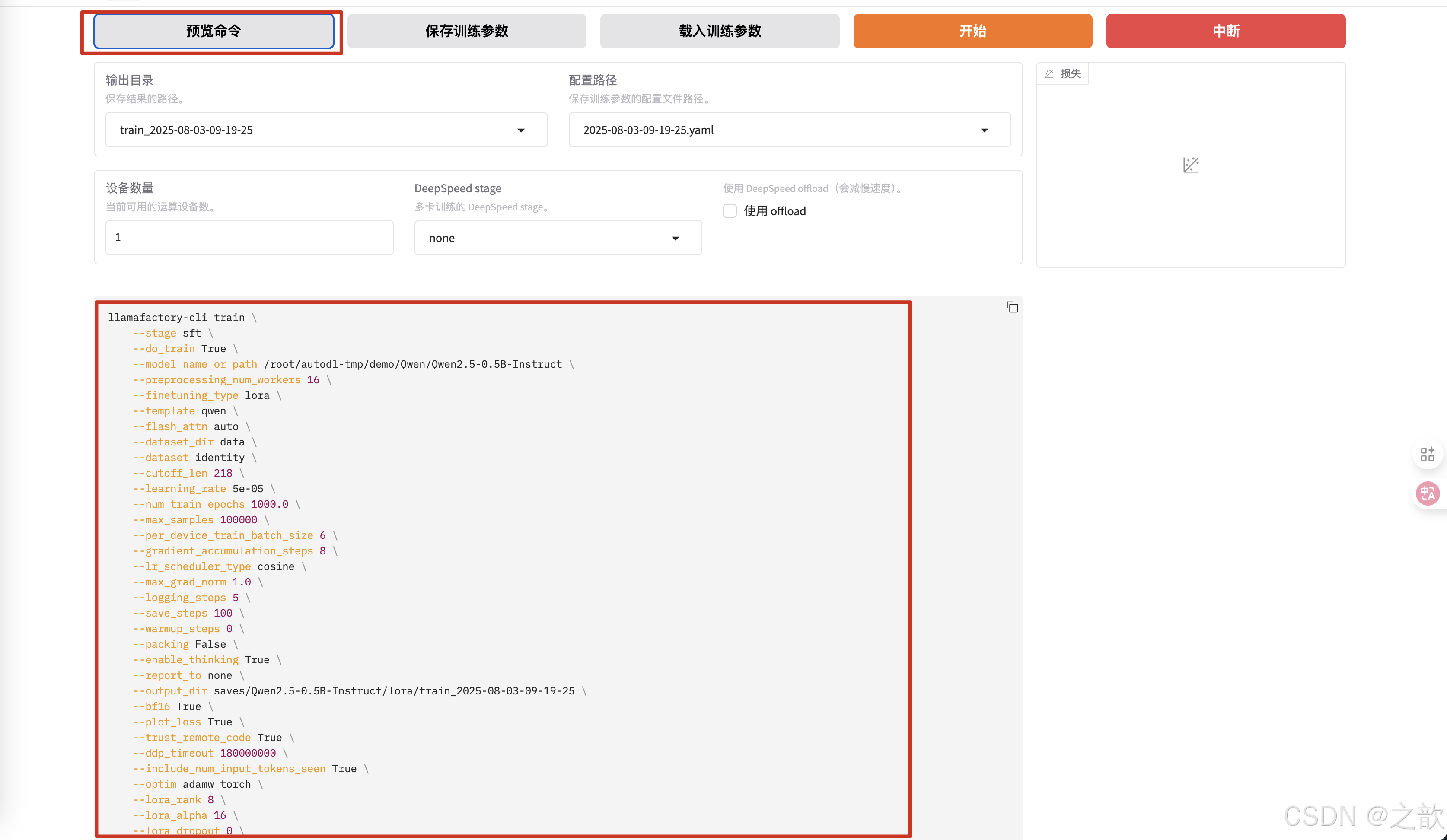
可以查看预览命令
-
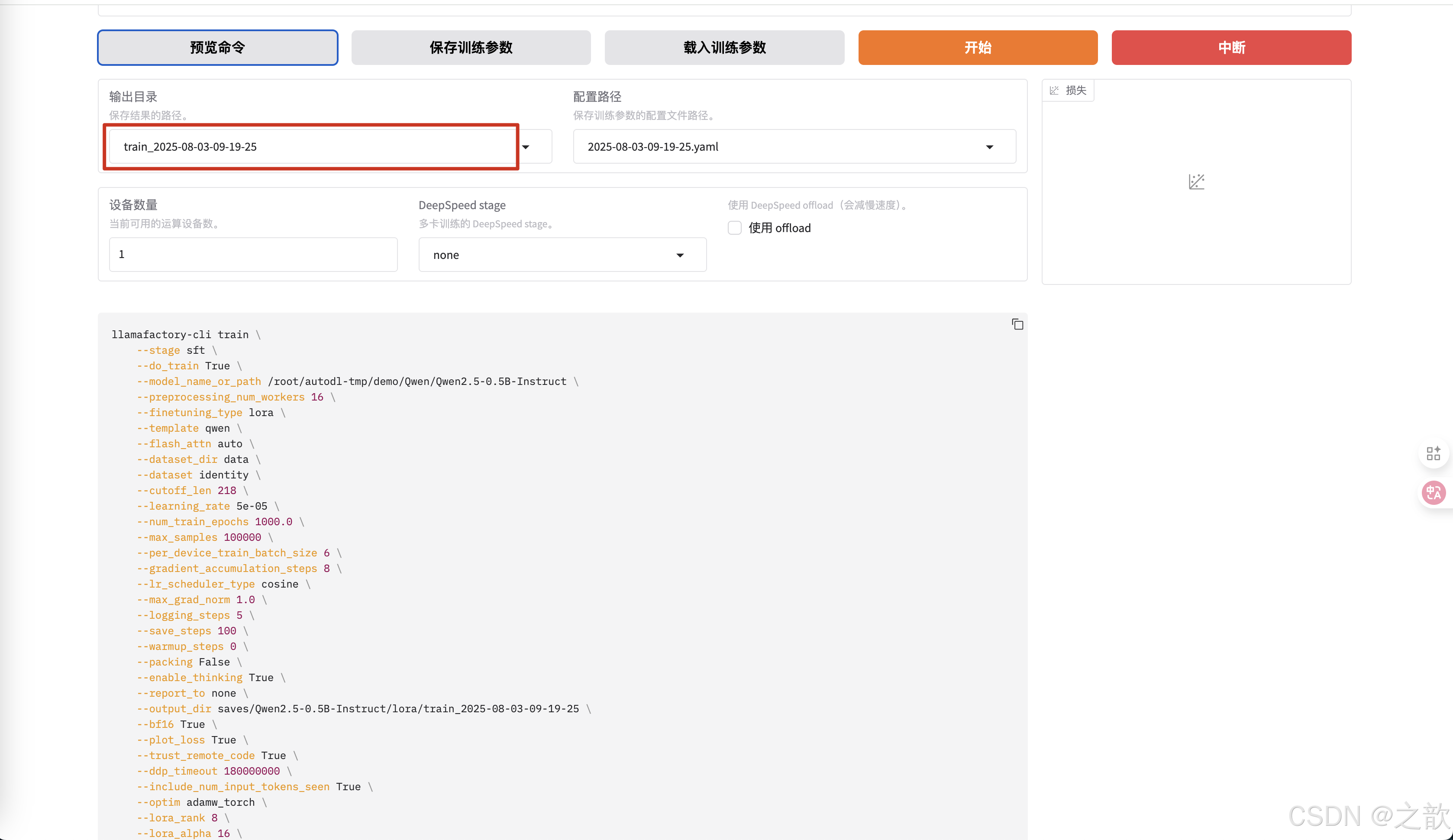
输出目录 ,权重的保存路径
-
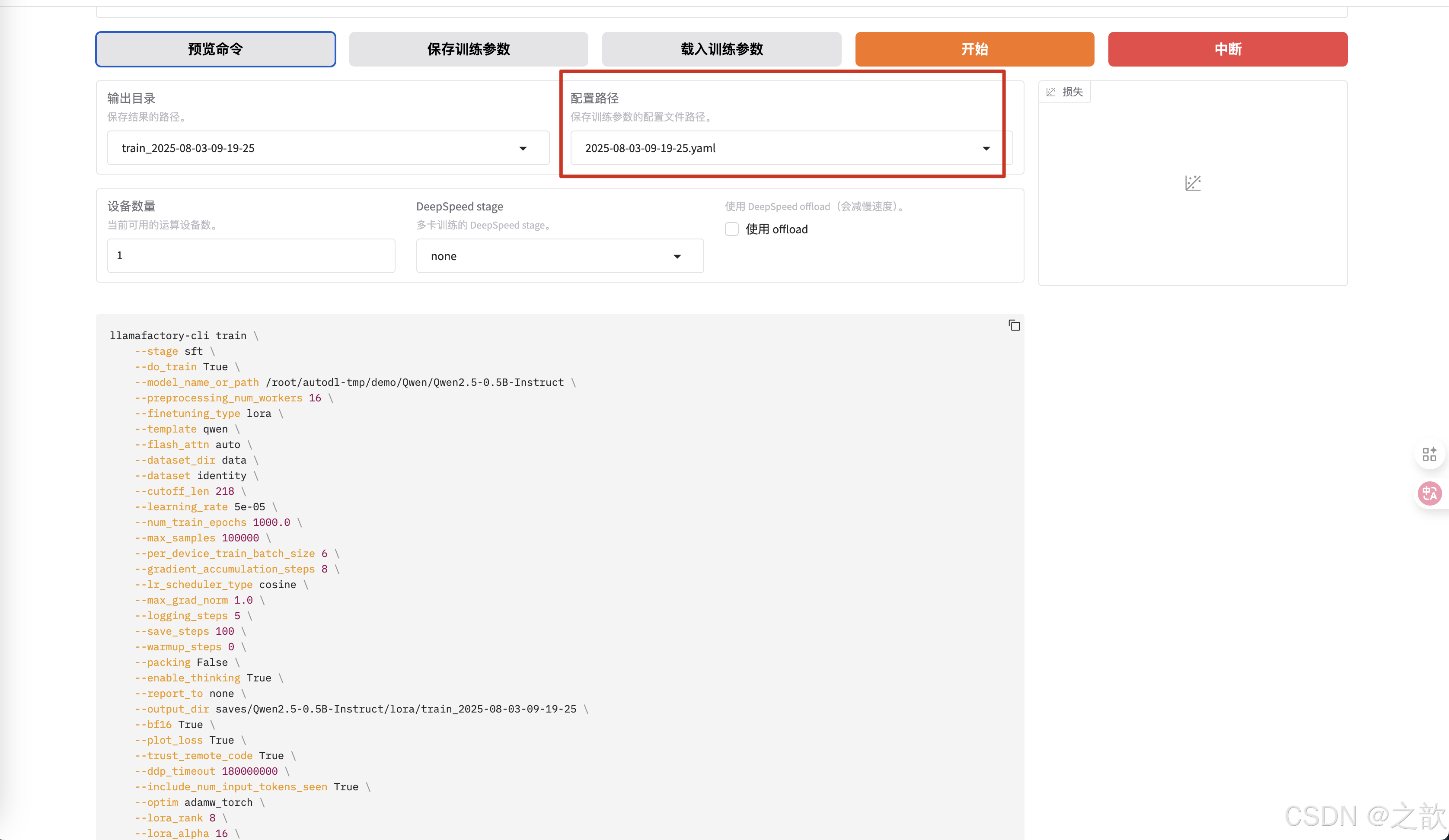
配置路径 ,本次配置保存路径
-
自己训练的显卡数量
-
点击开始进行训练
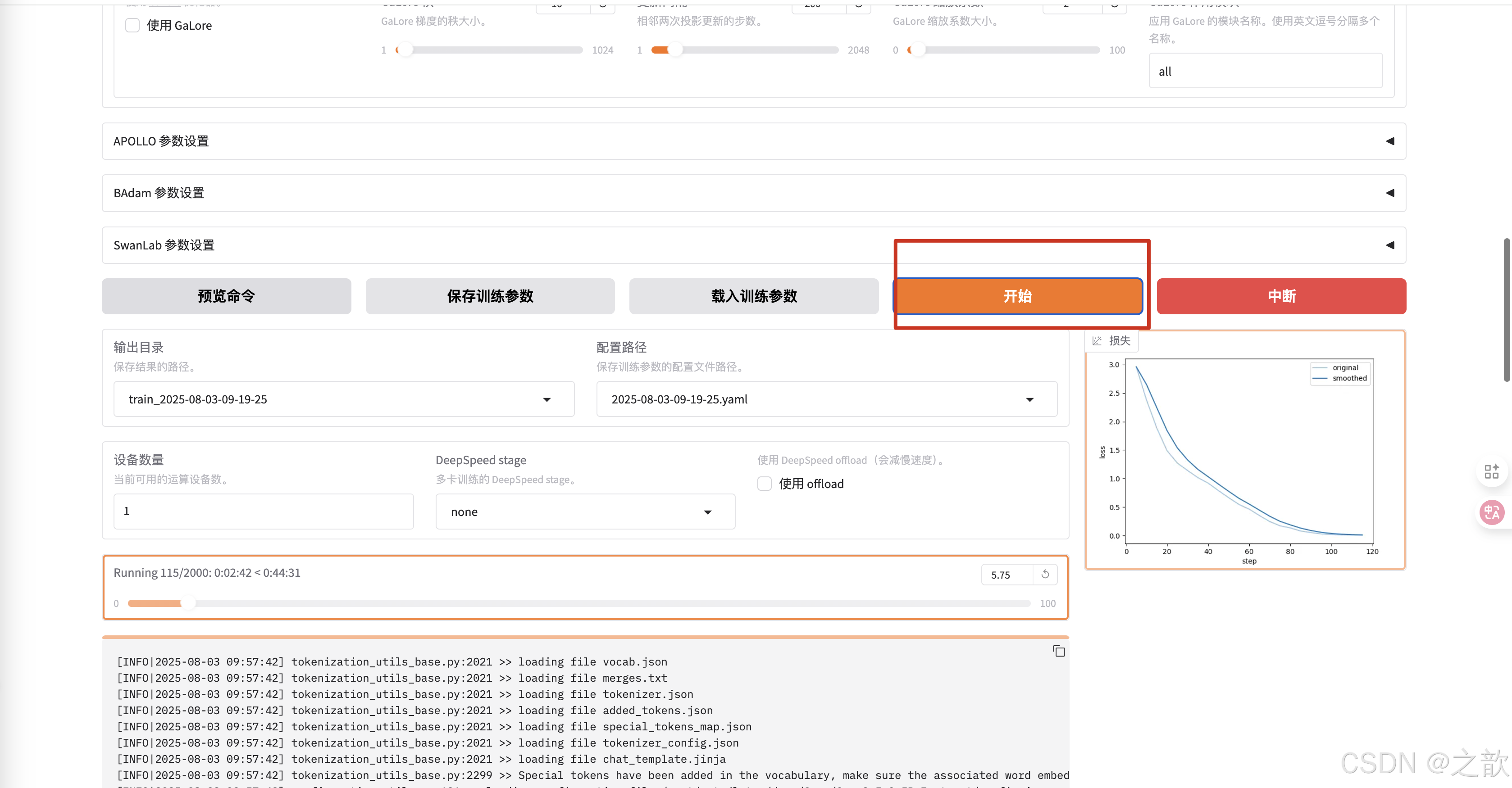
整个过程还是比较简单的
- 配置模型
- 配置数据
- 配置参数
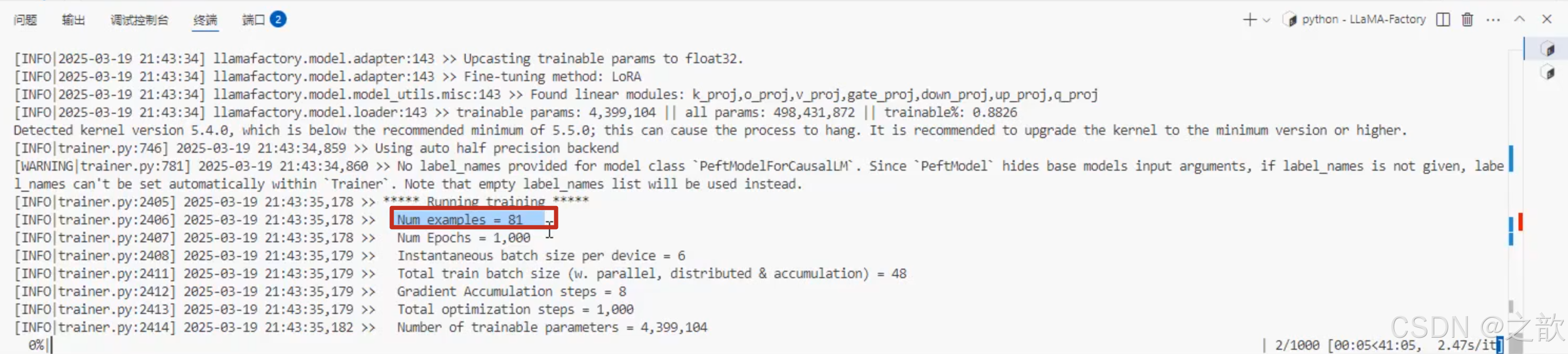
Num examples = 81 # 计算出来,整体样本数量
Num Epochs = 1,000 # 轮次是1000
Instantaneous batch size per device = 6 # 批次是6
Total train batch size (w. parallel, distributed & accumulation) = 48 Gradient Accumulation steps = 8
Total optimization steps = 1,000
Number of trainable parameters = 4,399,104
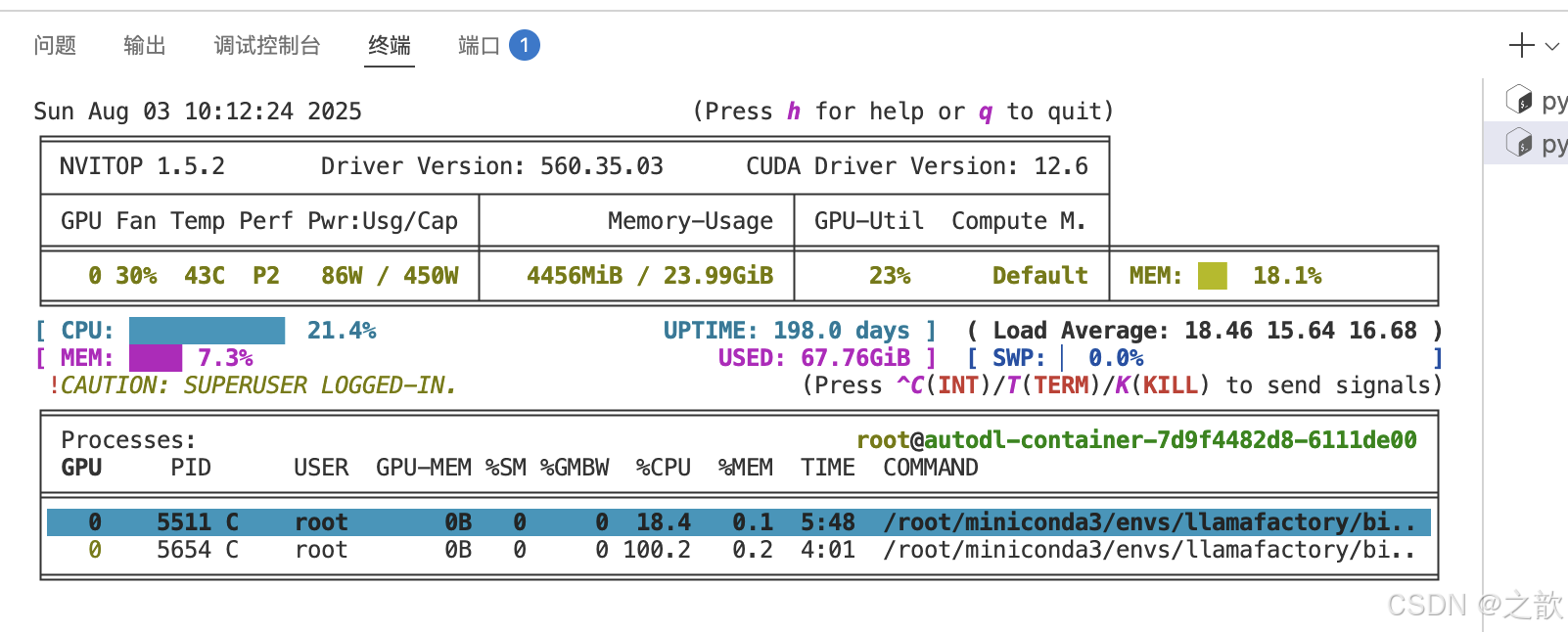
可以查看自己配置的批次合不合理,先conda install -c conda-forge nvitop
再运行nvitop
如果发现显存占用量少。可以点击中断
修改批处理大小
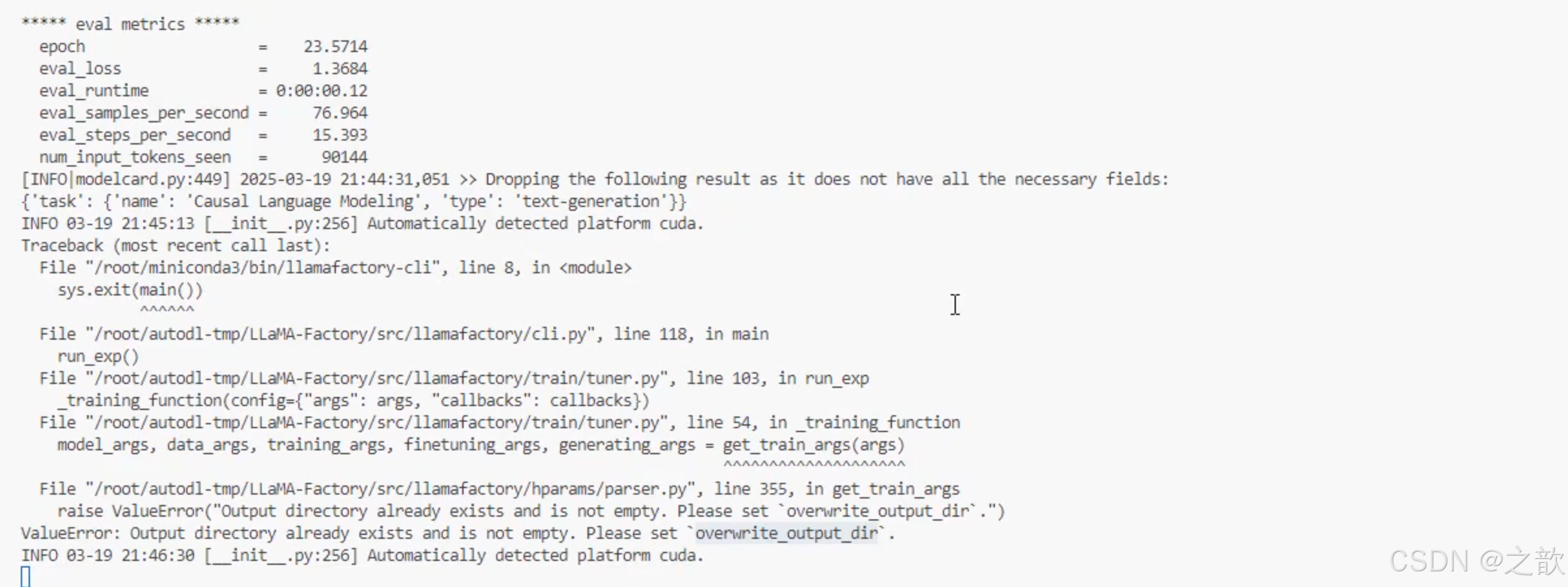
如果中断之后,再次启动报如下错误
将/root/autodl-tmp/demo/LLaMA-Factory/saves/Qwen2.5-0.5B-Instruct/lora/train_2025-08-03-09-19-25永久删除即可 。
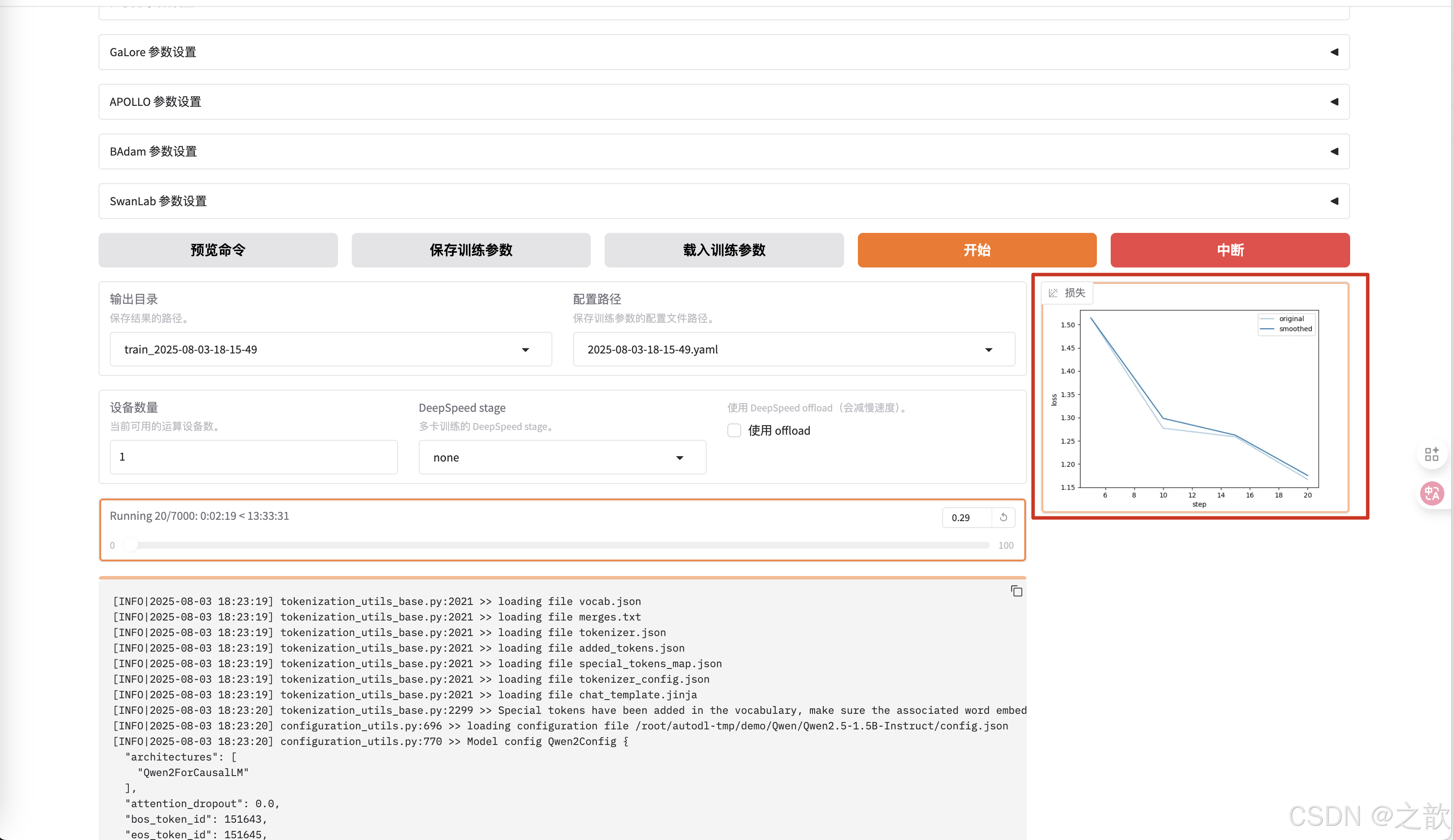
如果训练的次数到达,如果损失精度持平了,按道理训练好了。
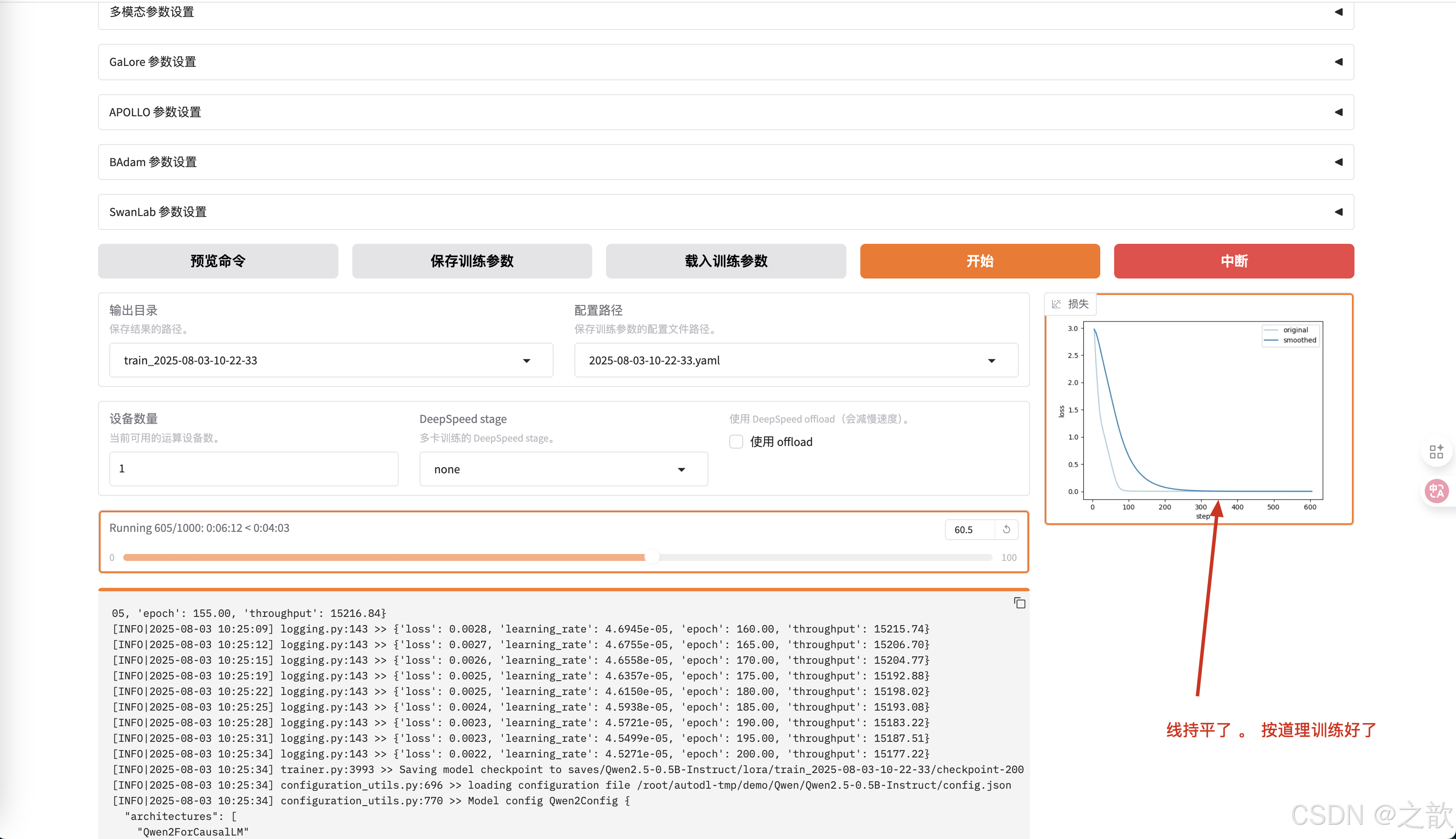
一般这个损失精度要变成平线,才可以当作训练完成 。 损失往下降,则证明训练是有效的 。
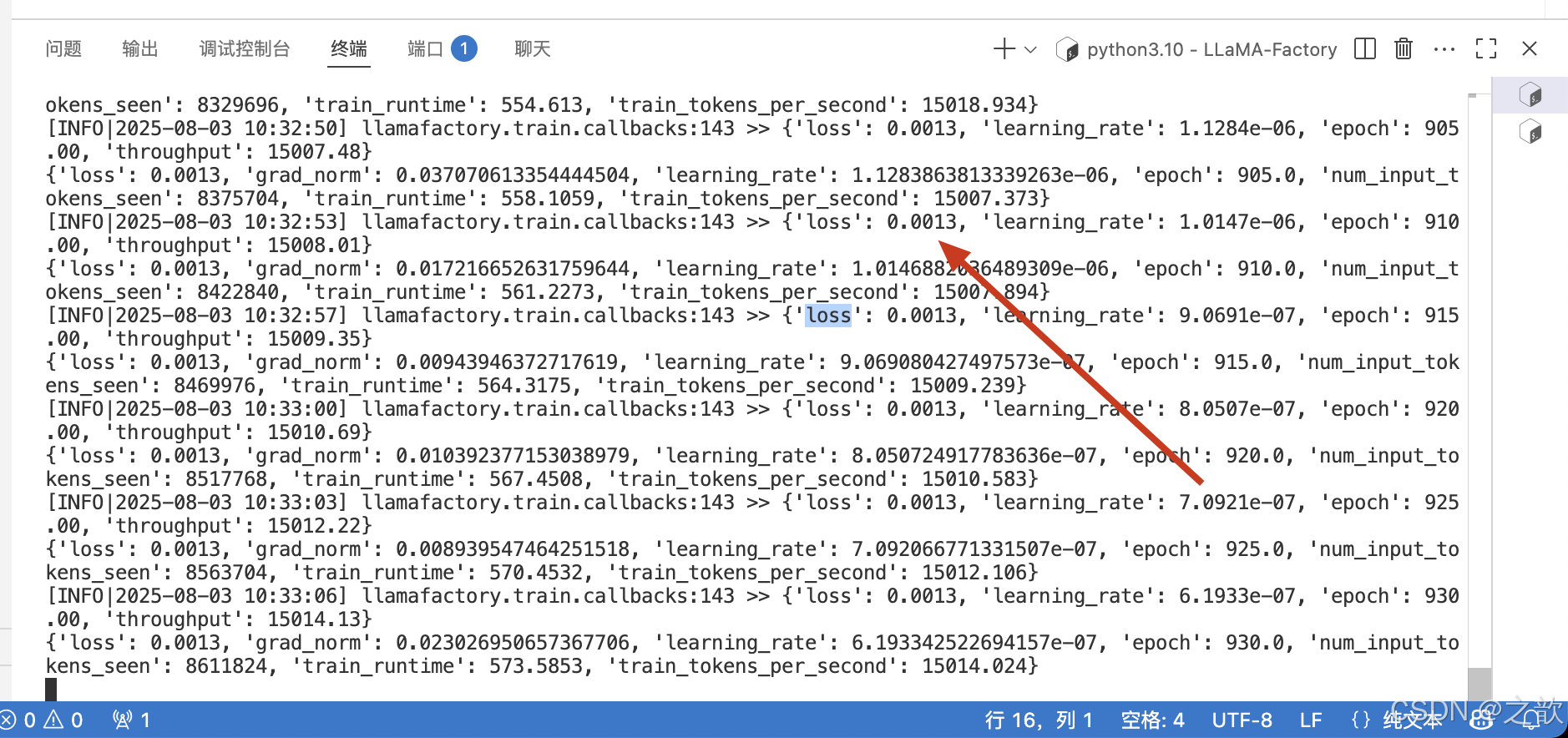
当然,从控制台上也可以看到损失精度 。 精度越少,则证明模型训练得越好。
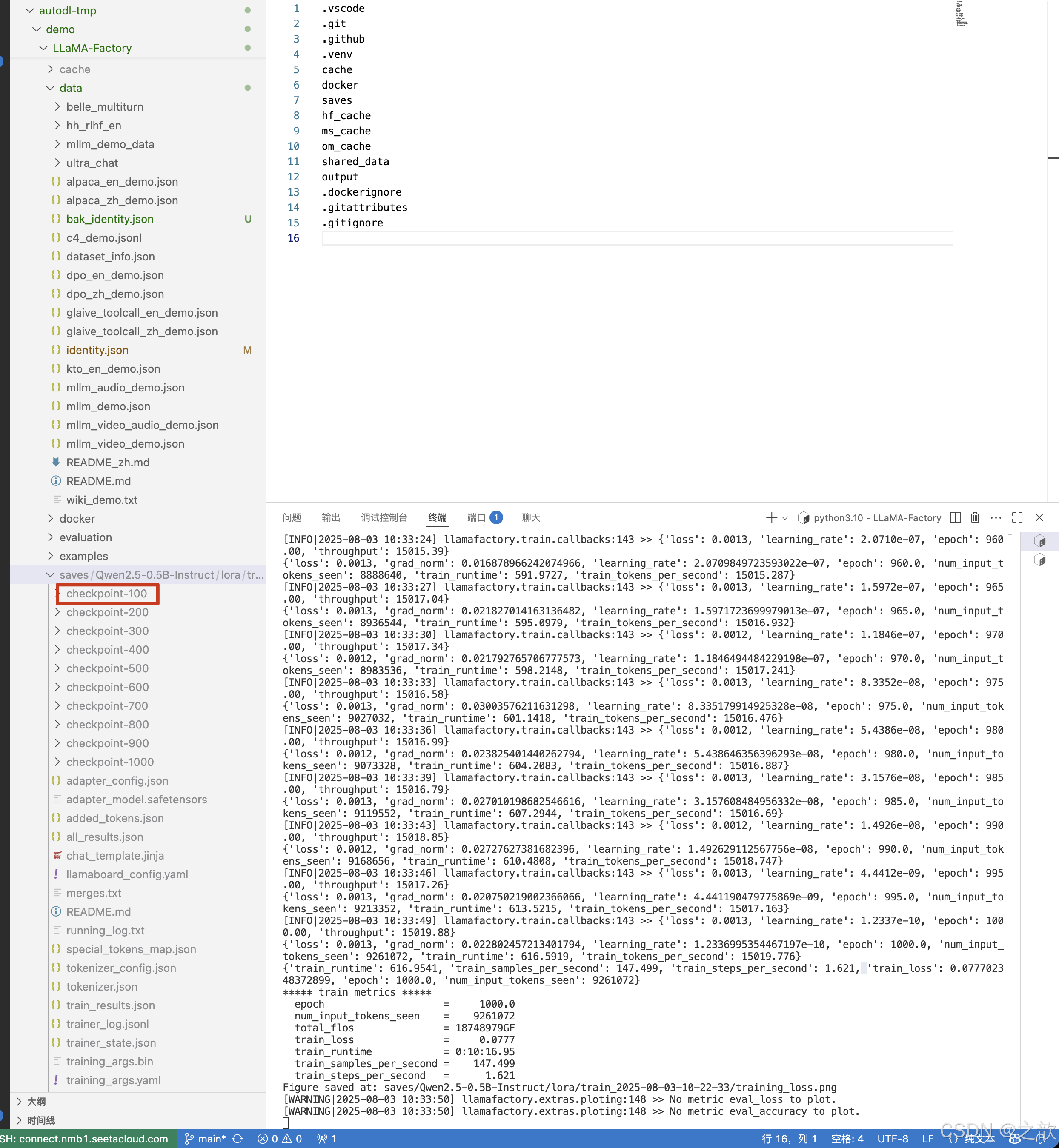
llmafactory 默认训练100次保存一次权重 。
如果要调整这个权重保存次数,则可以在其他参数设置-> 保存间隔中进行修改
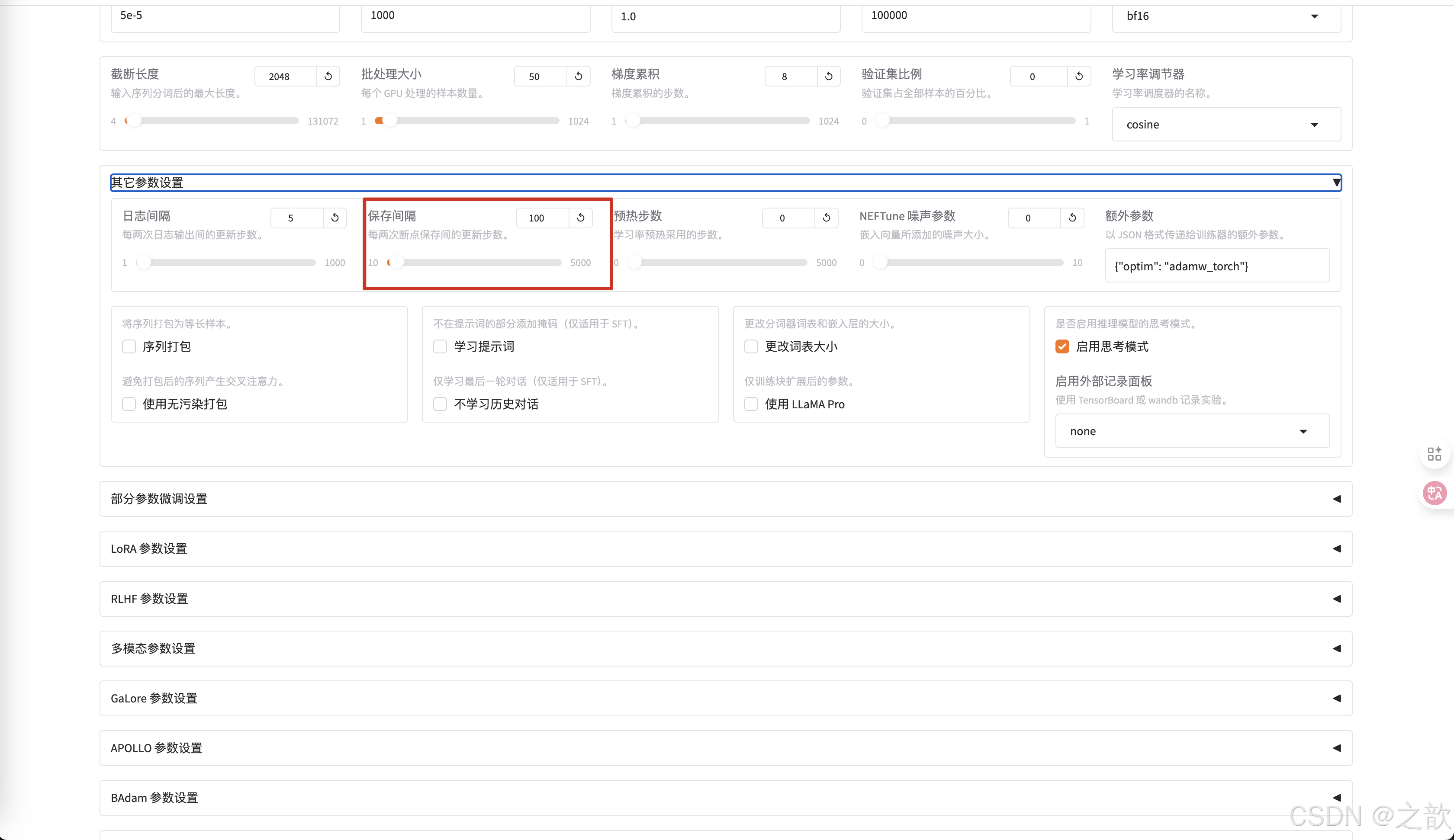
当然可以修改日志间隔 ,当训练完成,可以看到最终损失精度的保存图像 。
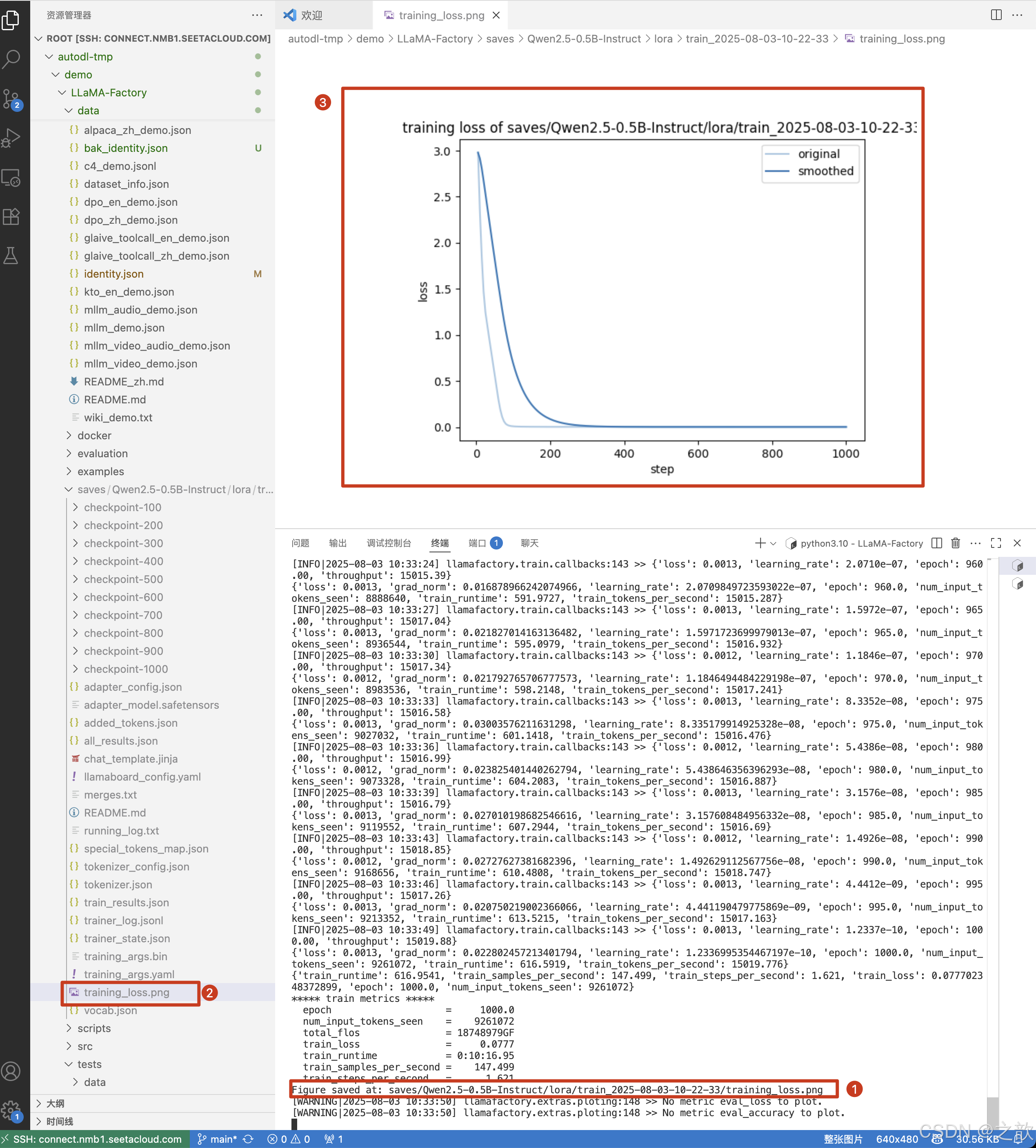
如何进行继续训练
-
设置检测点路径
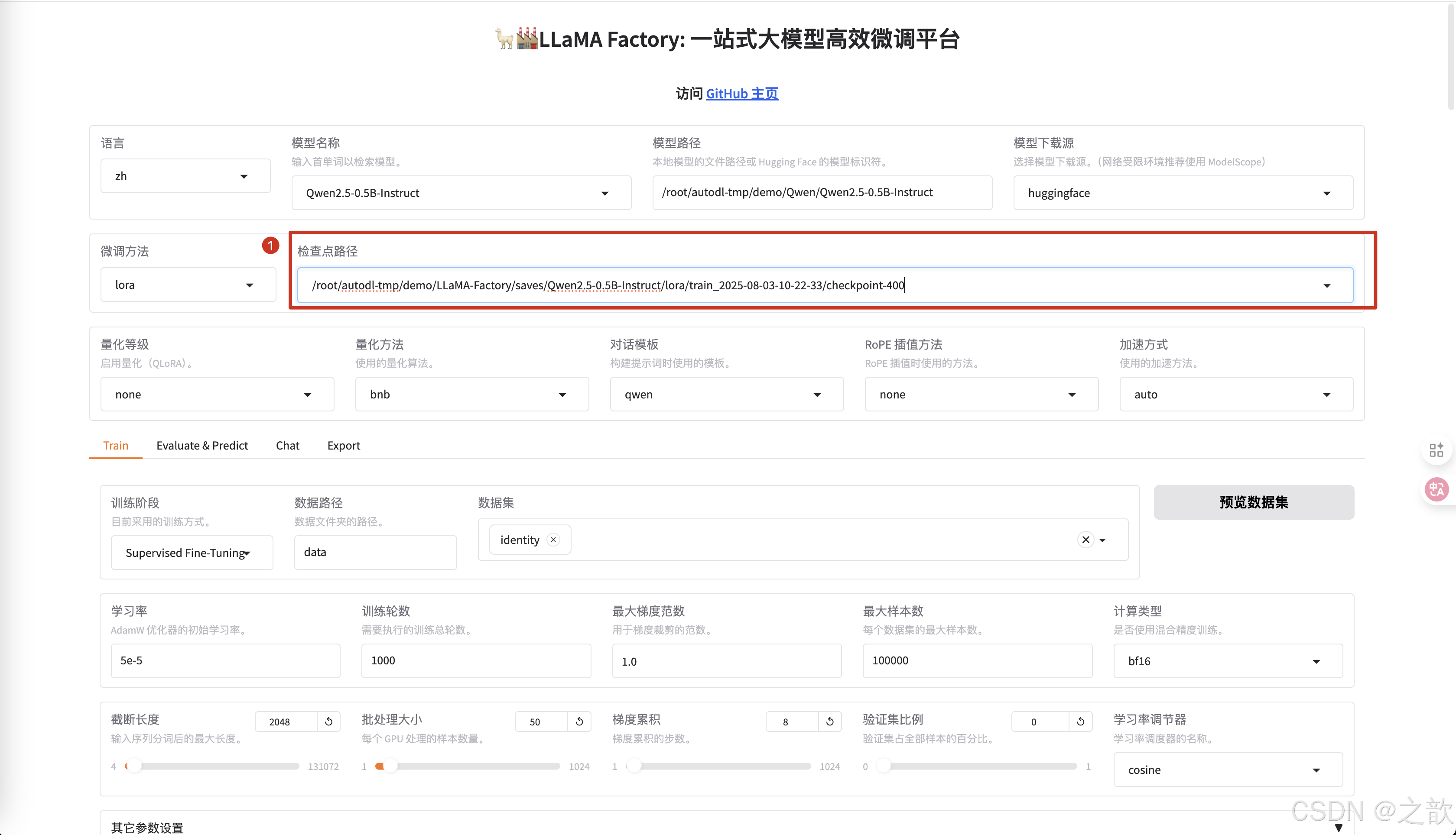
-
修改输出目录
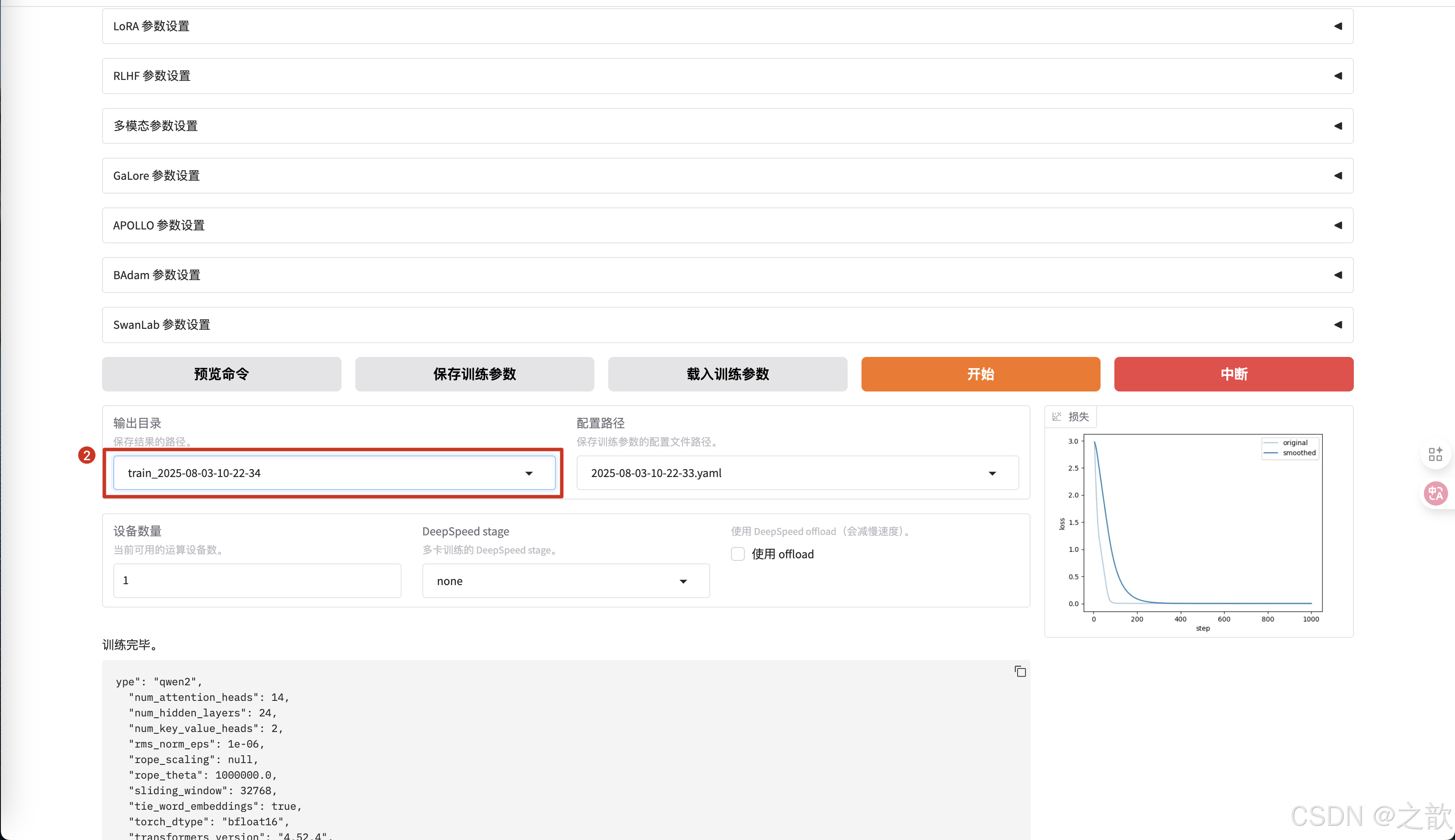
-
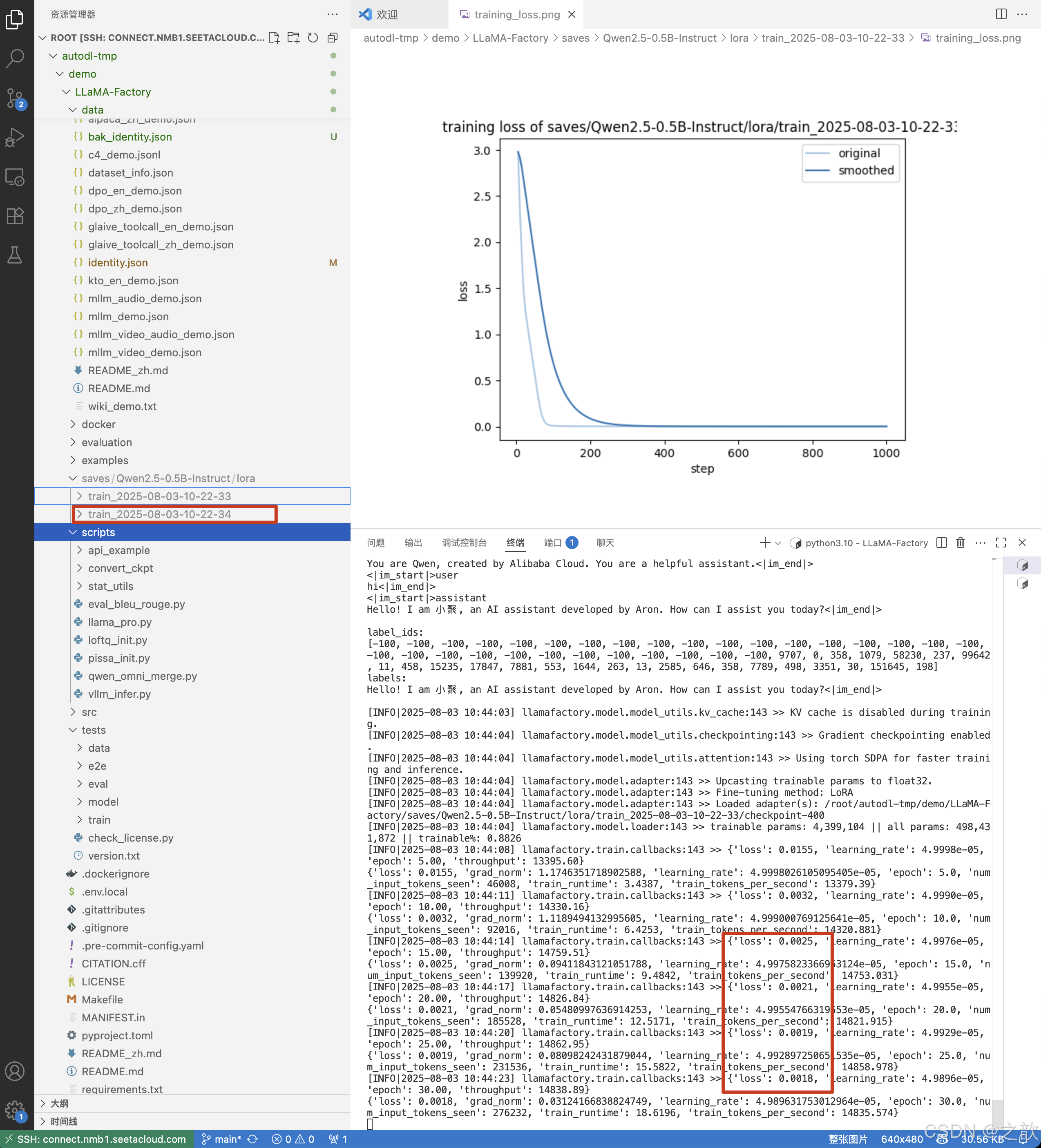
点击开始后,从控制台中可以看到,生成了新的权重 ,并且精度重新开始计算 。
-
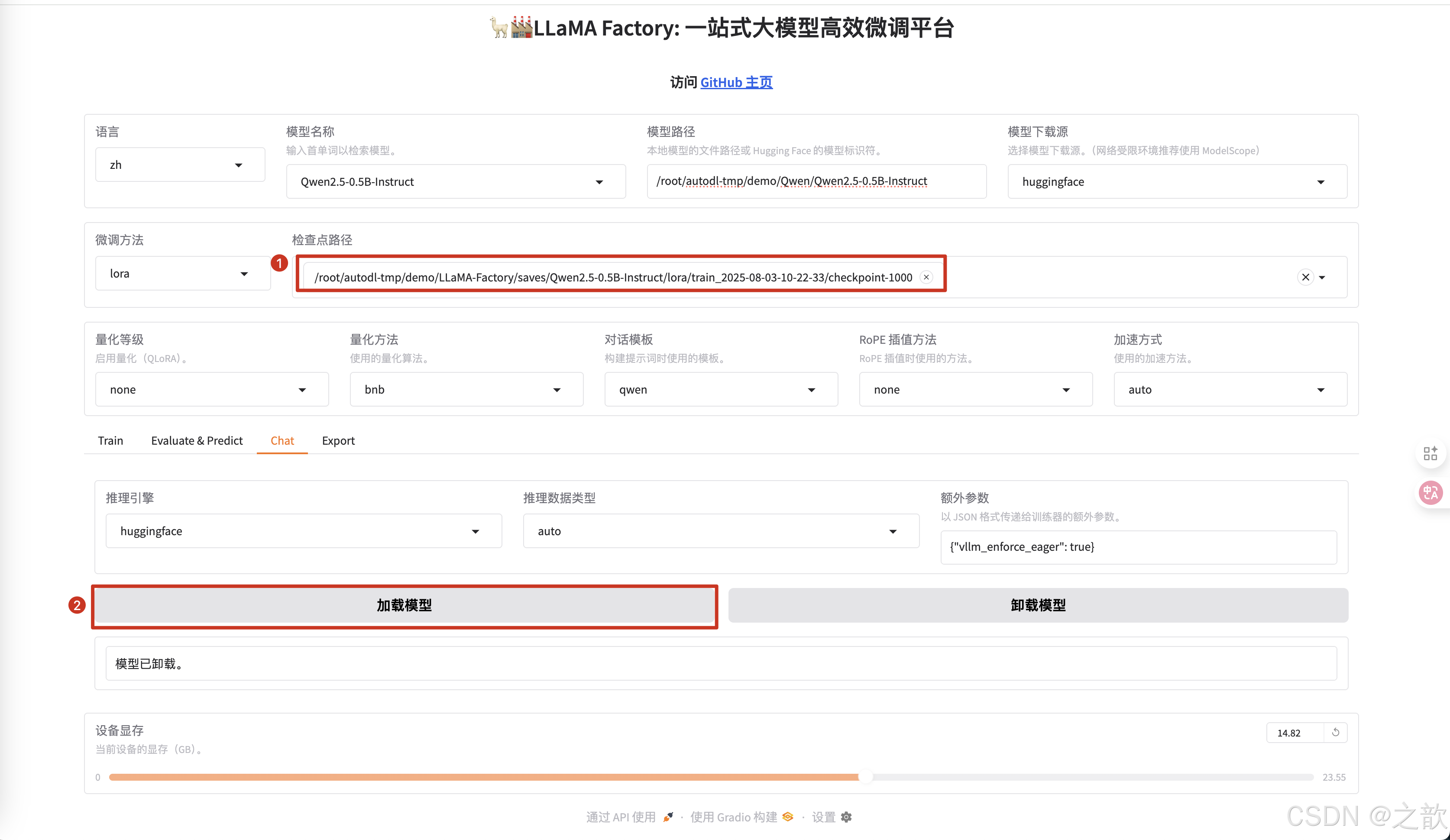
训练完成之后,加载模型测试, 先不使用检测点路径测试 。
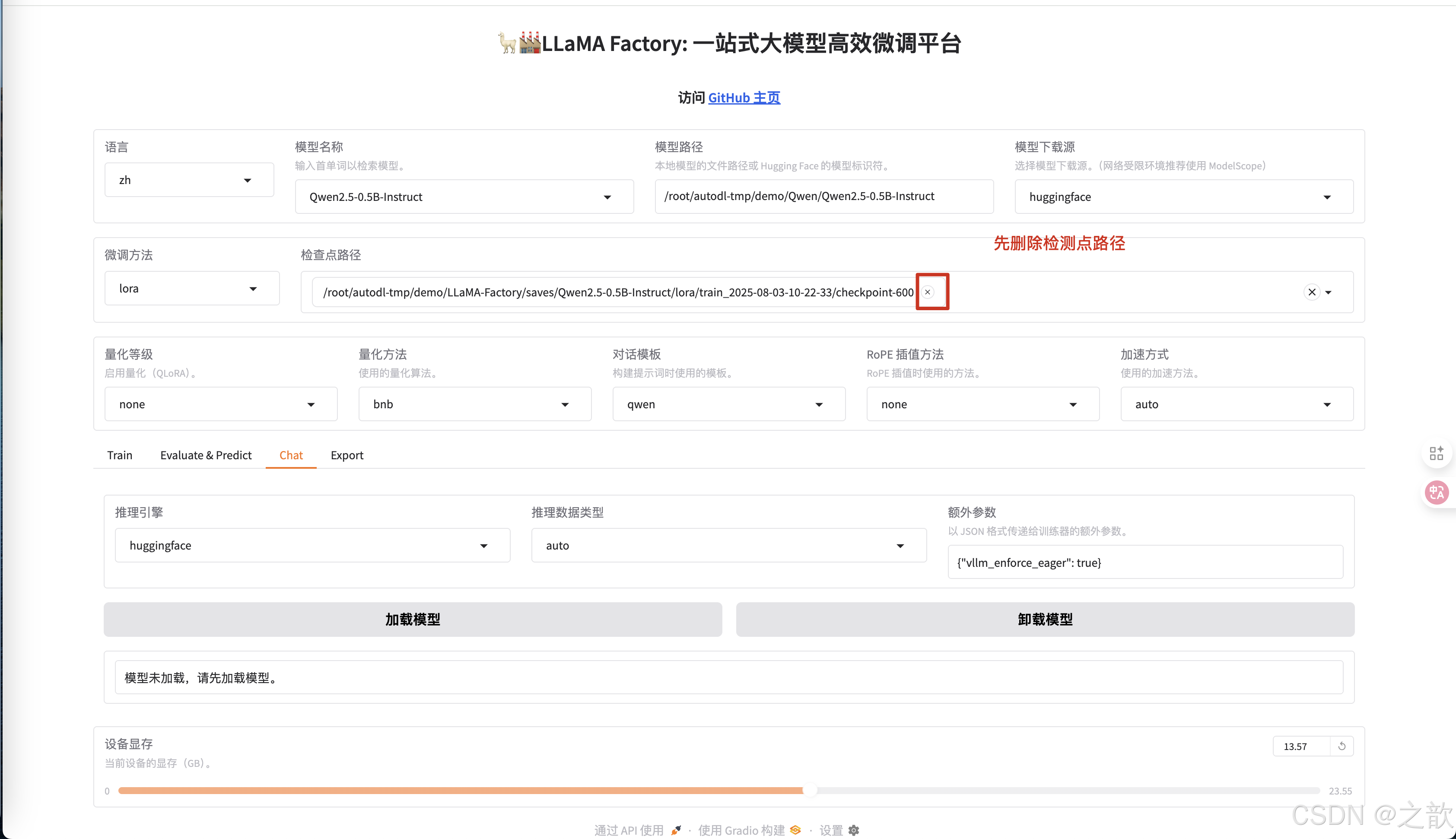
-
点击加载模型
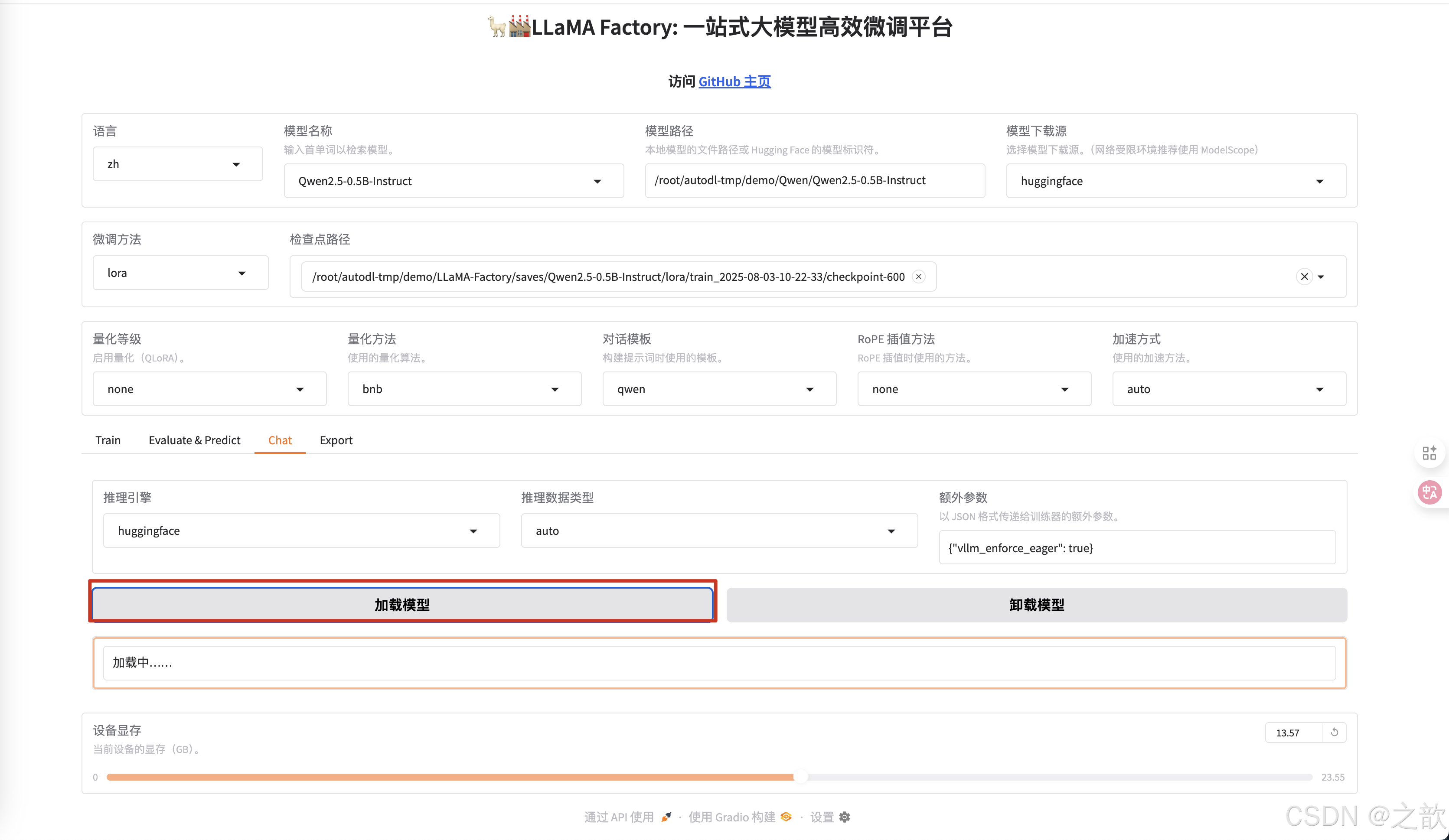
-
开始聊天
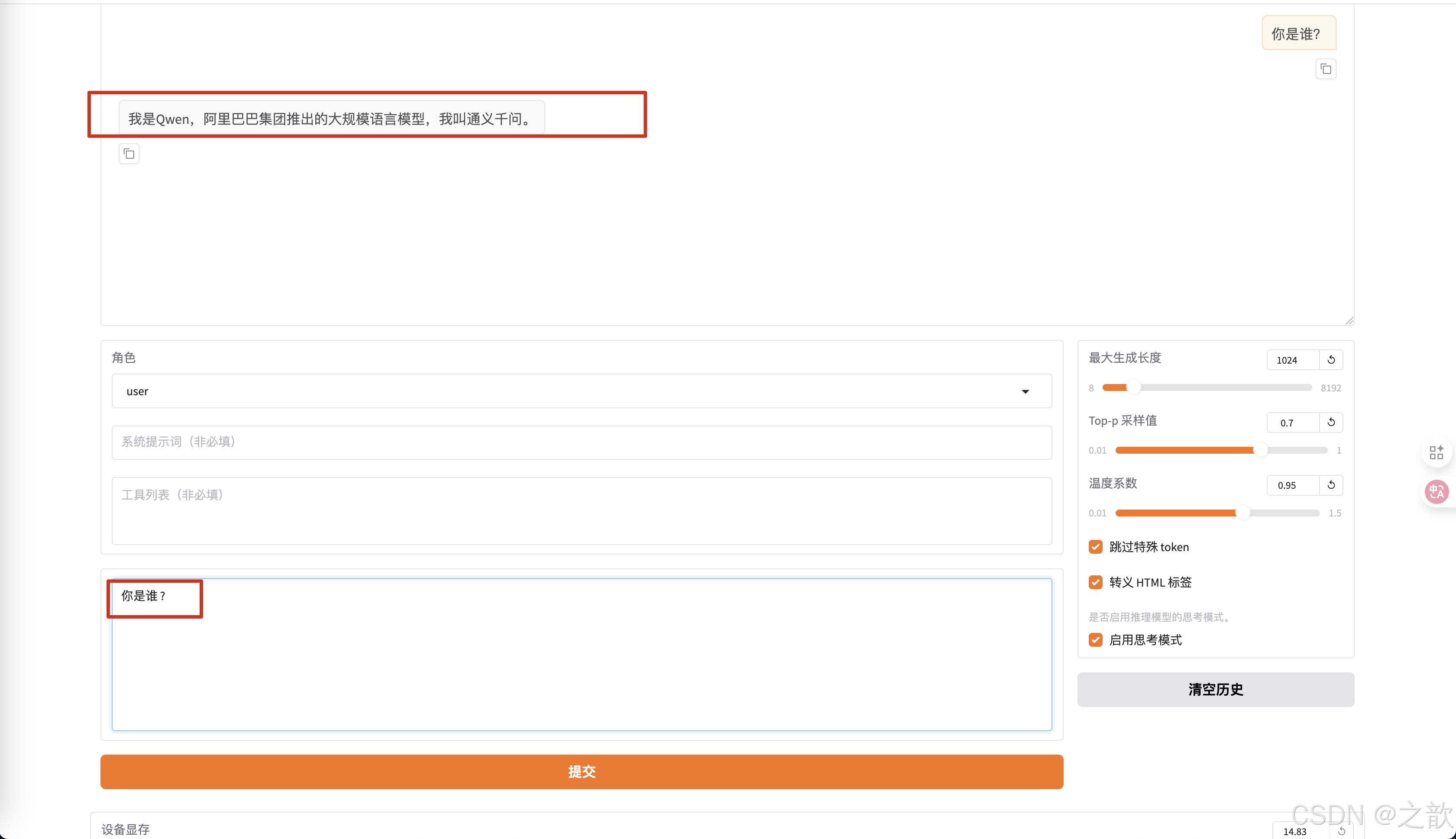
如果没有训练,则生成的内容是 ? 我是Qwen,阿里巴巴集团推出的大规模语言模型,我叫通义干问。 -
加载训练之后的模型 。
-
当你再输入你是谁? ,返回的内容 就是您好,我是小聚,由Aron开发,旨在为用户提供智能化的回答和帮助。
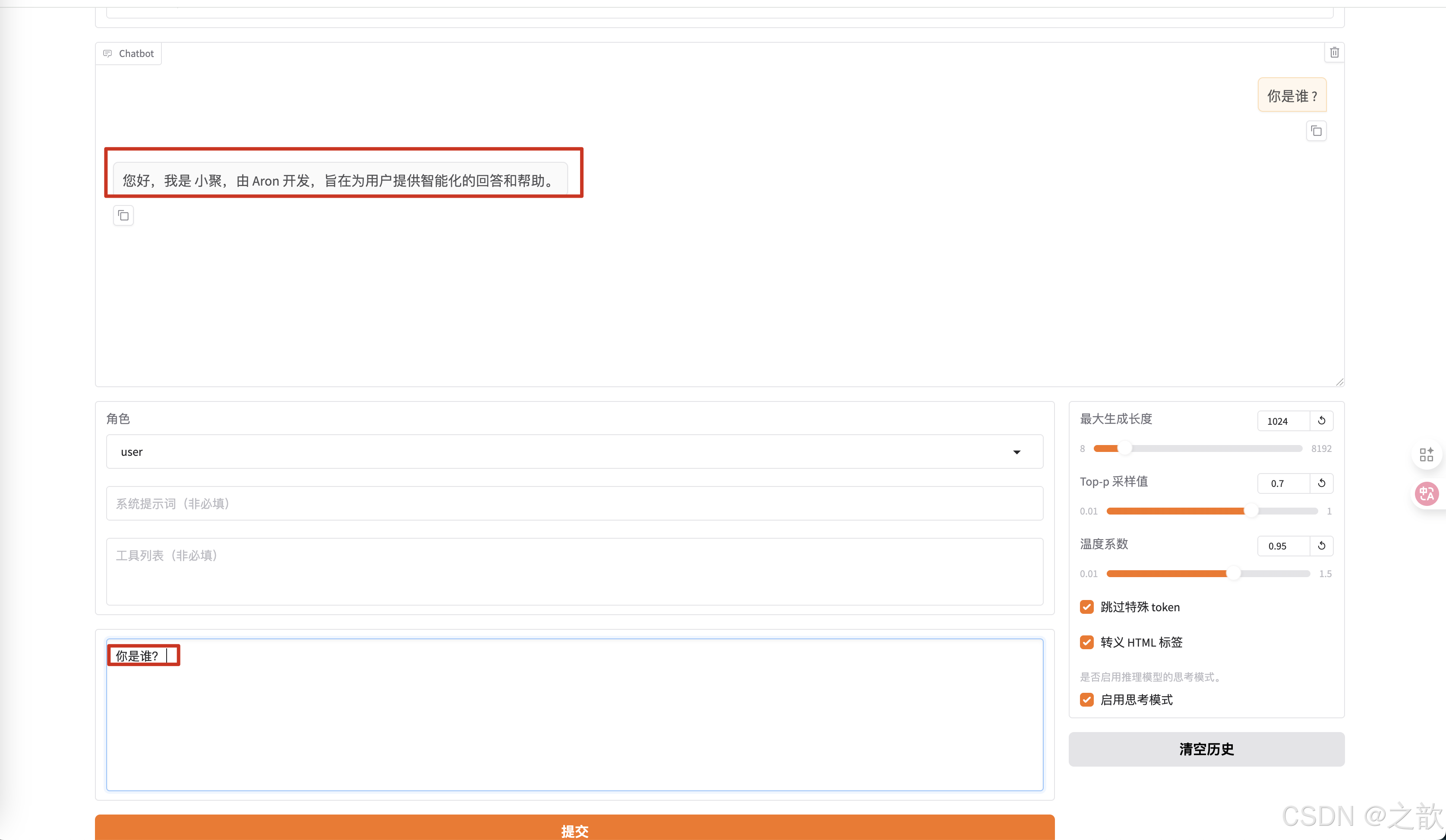
【注意 】不要用deepseek R1 去训练,方式不一样,目前比较好用的模型 ,千问模型 , llama 模型 , 以及google的gemma ,还有glm 模型 。 国外的模型对中文的支持不那么强
大模型微调(LLama Factory自定义微调数据集)
LLaMA-Factory微调数据集制作
LLaMA Factory 的官方文档。
单轮对话
指令监督微调(Instruct Tuning)通过让模型学习详细的指令以及对应的回答来优化模型在特定指令下的表现。
instruction 列对应的内容为人类指令, input 列对应的内容为人类输入, output 列对应的内容为模型回答。下面是一个例子
"alpaca_zh_demo.json"
{"instruction": "计算这些物品的总费用。 ", # 聊天内容"input": "输入:汽车 - $3000,衣服 - $100,书 - $20。", # 对问题的补充"output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。" # 模型返回
},
多轮对话
如果指定, system 列对应的内容将被作为系统提示词。
history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
指令监督微调数据集 格式要求 如下:
一般做数据集时,不会
[{"instruction": "人类指令(必填)", # 用户输入"input": "人类输入(选填)", # 对input 补充"output": "模型回答(必填)", # 模型返回 "system": "系统提示词(选填)", # 当模型启动时,模型做一个自我介绍"history": [["第一轮指令(选填)", "第一轮回答(选填)"], # 多话对话["第二轮指令(选填)", "第二轮回答(选填)"] # ]}
]
下面提供一个 alpaca 格式 多轮 对话的例子,对于单轮对话只需省略 history 列即可。
[{"instruction": "今天的天气怎么样?","input": "","output": "今天的天气不错,是晴天。","history": [["今天会下雨吗?","今天不会下雨,是个好天气。"],["今天适合出去玩吗?","非常适合,空气质量很好。"]]}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","system": "system","history": "history"}
}
下载数据集
到魔塔社区下载数据集
https://www.modelscope.cn/datasets/w10442005/ruozhiba_qa
mac 系统安装 lfs
https://blog.csdn.net/m0_65152767/article/details/147166522
Ubuntu22.04安装Git LFS
https://blog.csdn.net/weixin_37926734/article/details/126851314
安装好lfs 之后 ,就可以用git 去获取数据集了 。
git lfs install
git clone https://www.modelscope.cn/datasets/w10442005/ruozhiba_qa.git
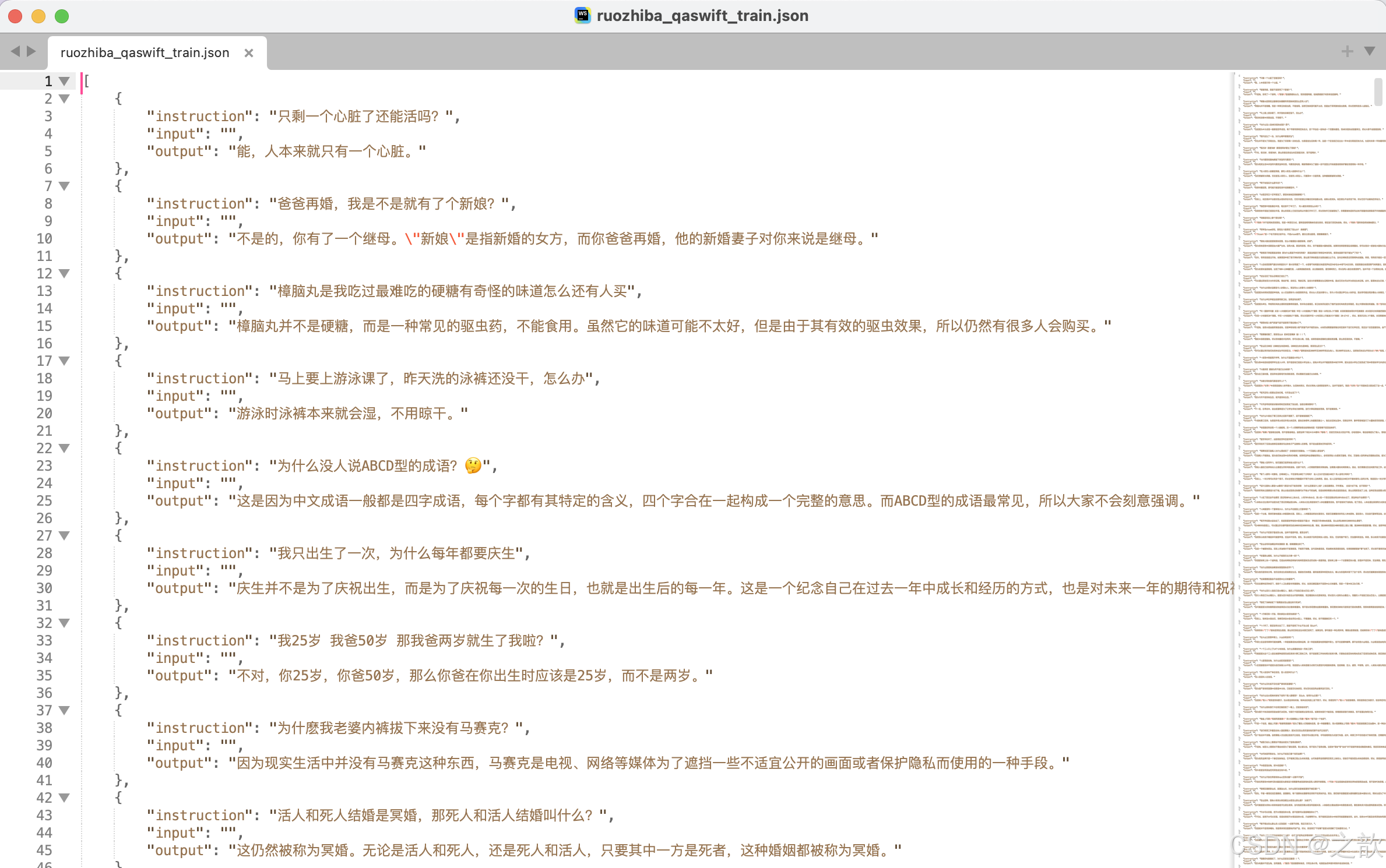
数据集转化效果
当然,需要通过代码将转化成我们需要的数据集
import json# 读取原始JSON文件
input_file = "data/ruozhiba_qaswift.json" # 你的JSON文件名
output_file = "data/ruozhiba_qaswift_train.json" # 输出的JSON文件名with open(input_file, "r", encoding="utf-8") as f:data = json.load(f)# 转换后的数据
converted_data = []for item in data:converted_item = {"instruction": item["query"],"input": "","output": item["response"]}converted_data.append(converted_item)# 保存为JSON文件(最外层是列表)
with open(output_file, "w", encoding="utf-8") as f:json.dump(converted_data, f, ensure_ascii=False, indent=4)print(f"转换完成,数据已保存为 {output_file}")
转化后的数据结构如下
将数据集上传到LLaMA-Factory的data目录下/root/autodl-tmp/demo/LLaMA-Factory/data。
修改数据集配置文件
修改 /root/autodl-tmp/demo/LLaMA-Factory/data/dataset_info.json 配置文件
"ruozhiba_qaswift_train": {"file_name": "ruozhiba_qaswift_train.json"},
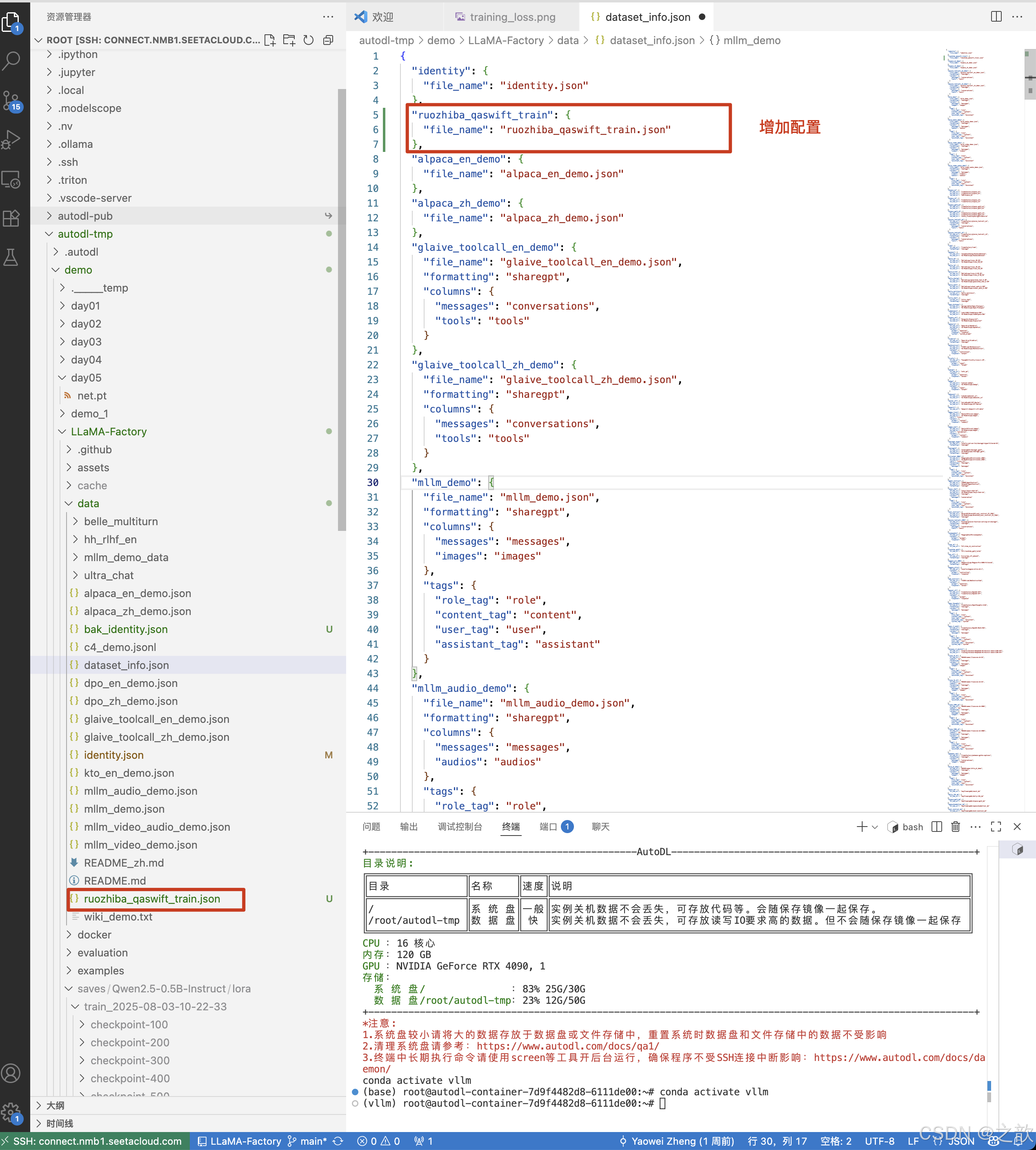
开始训练
数据集,用新改的数据集 。
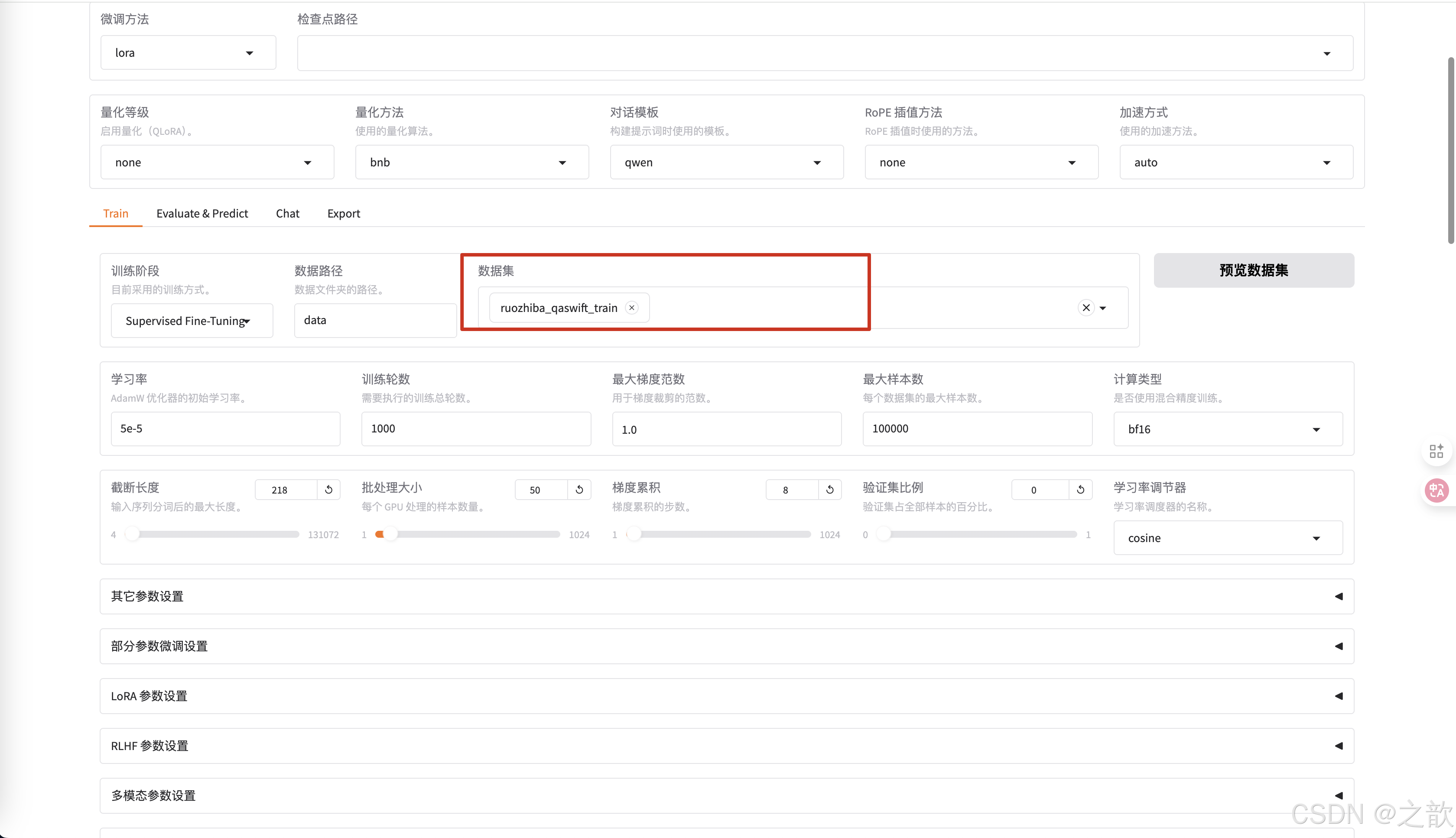
nvitop 查看模型运行情况
杂记
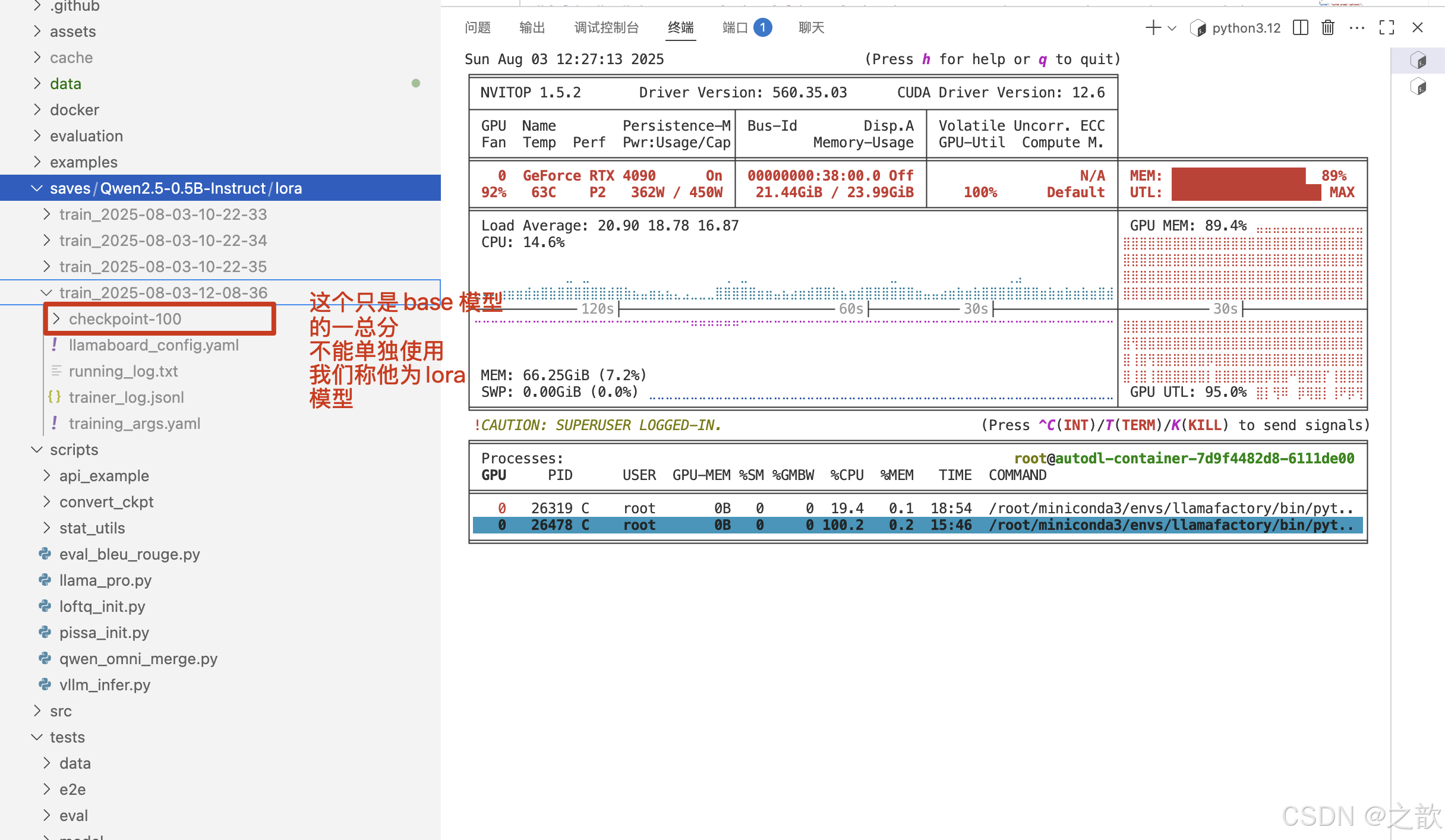
当自己训练好之后,需要和base模型合并,才可以单独使用。
Lora模型合并与量化导出
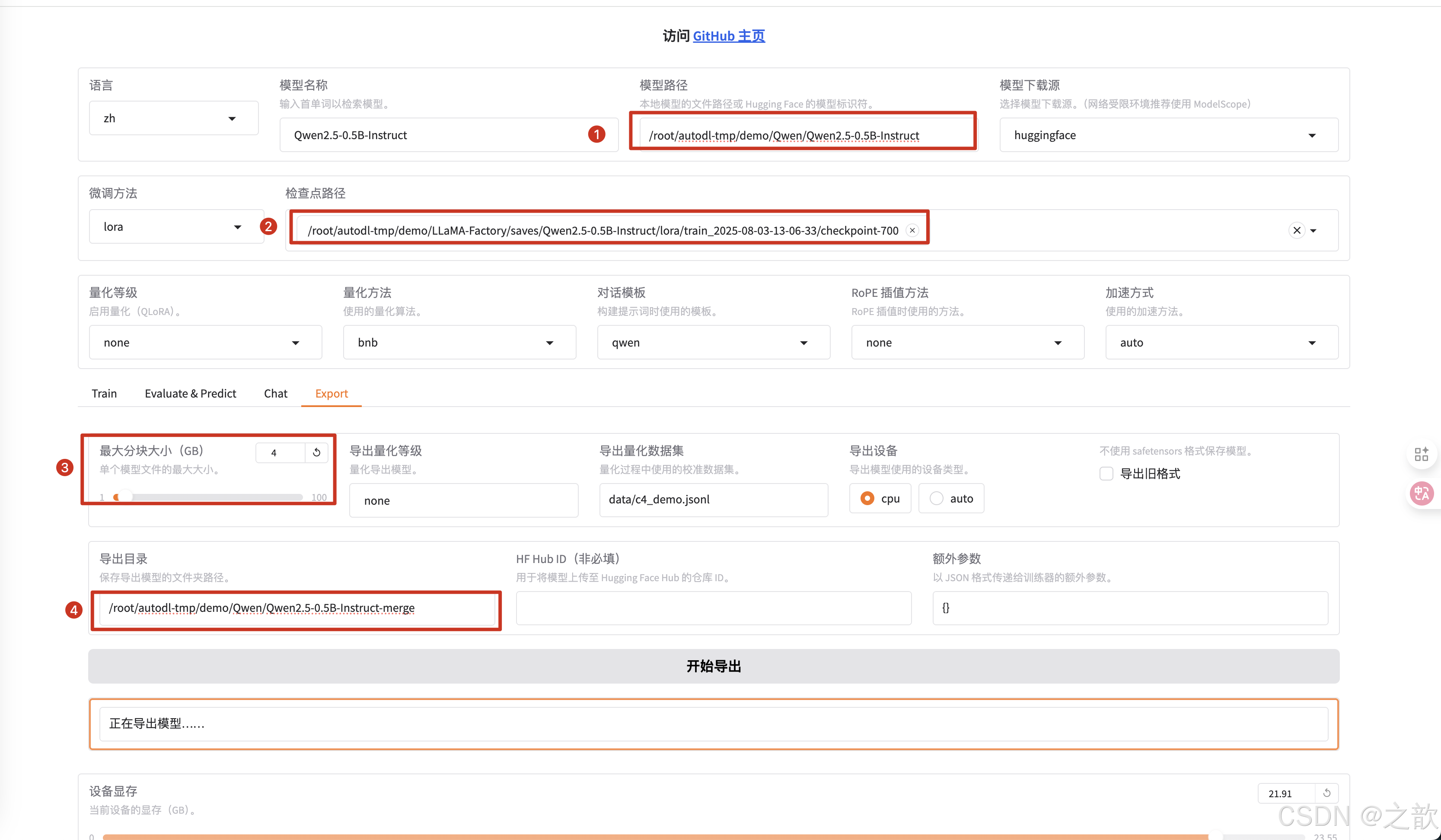
上面需要注意 :
最大分块大小 (GB),如下面所示 ,如果模型太大,如果进行分块,分块大小建议不超过4G
模型量化
模型量化,也想当于阉割模型,模型量化只能使用合并之后的版本。 下面是模型量化的操作。
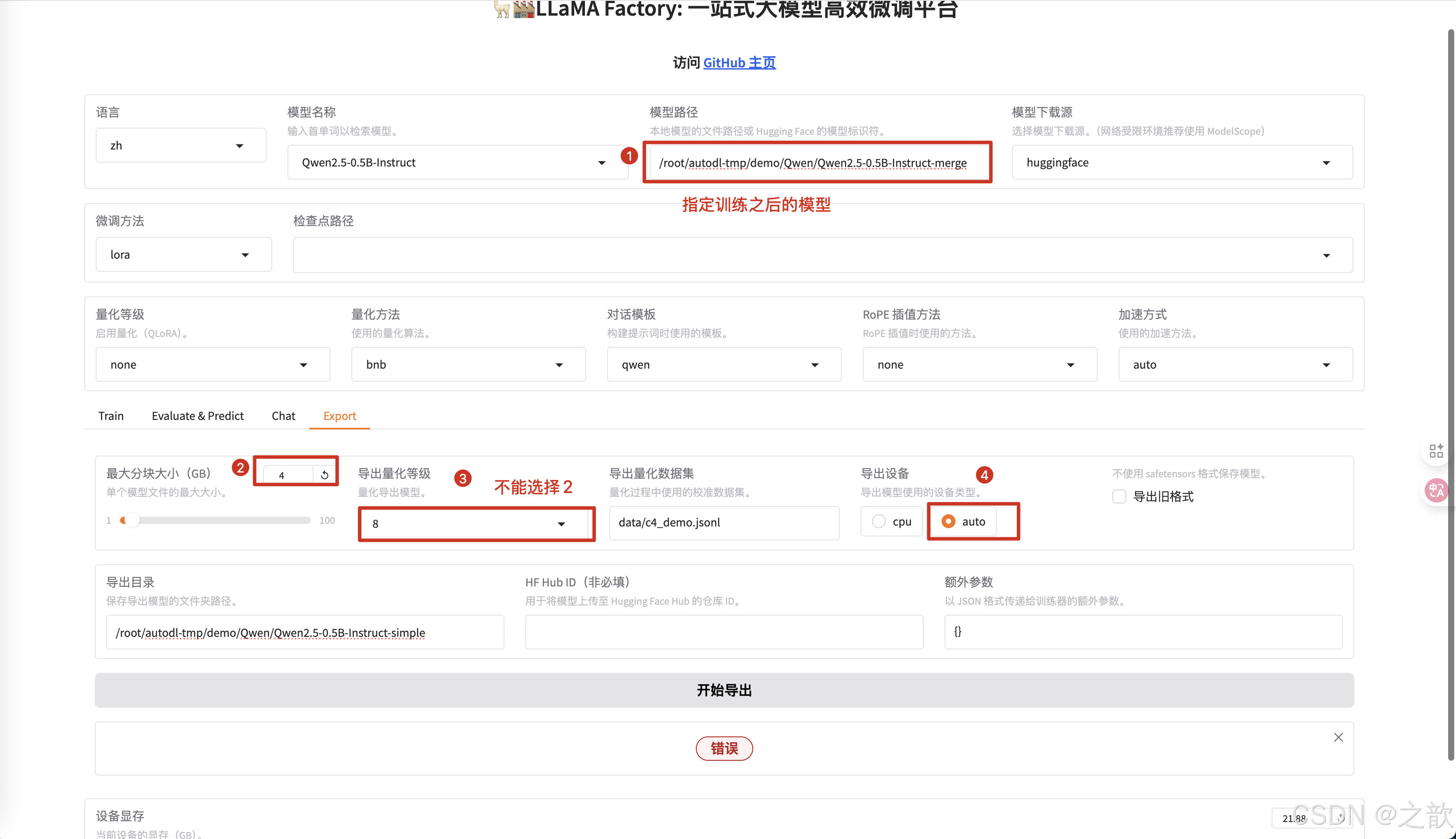
当然,ollama 只能使用gguf 格式的文件
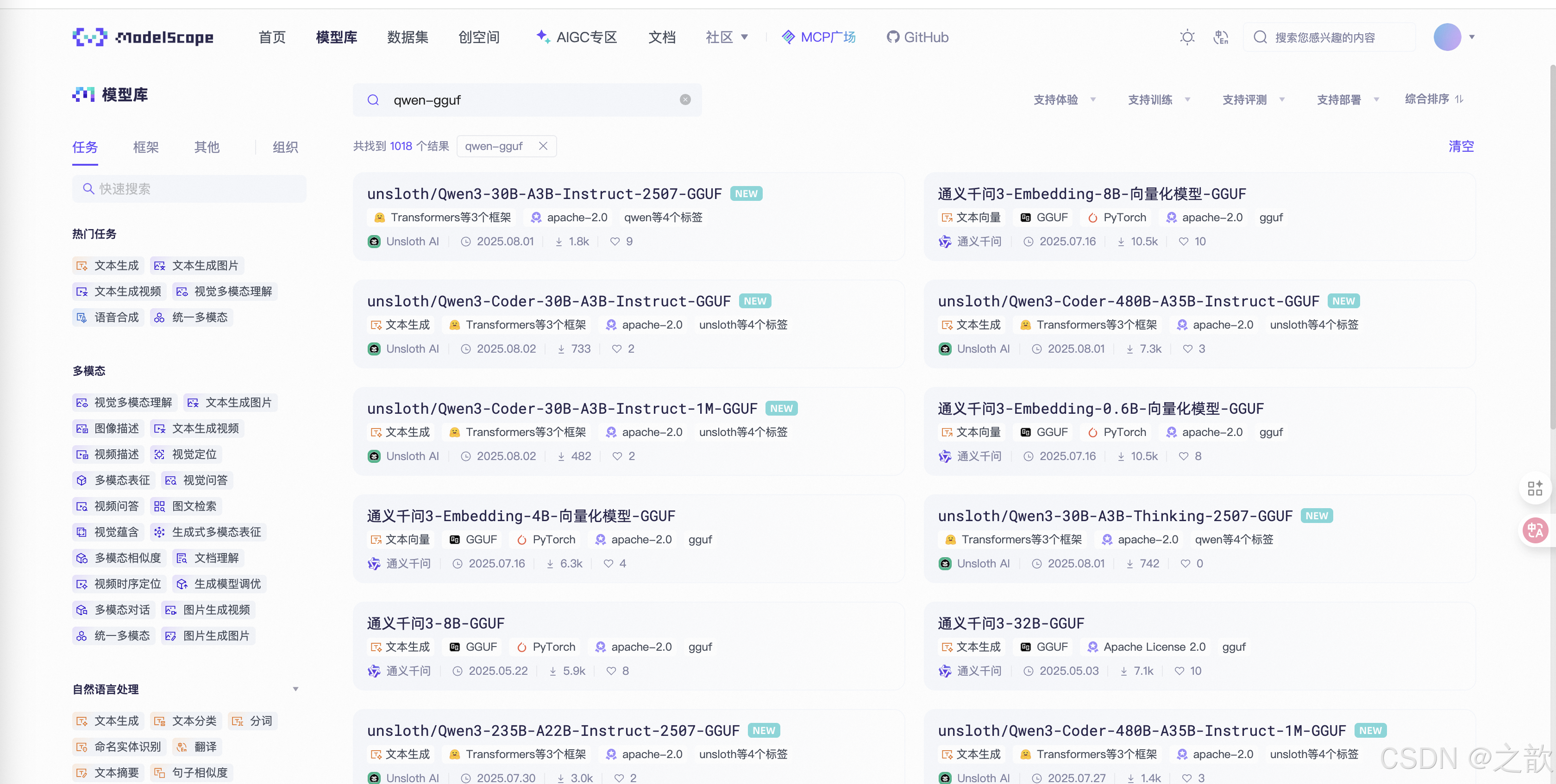
量化只为节省算力,不般个人用户才会使用量化。
使用 open-webui部署模型
https://blog.csdn.net/xianfianpan/article/details/143441456《参考博客》
https://blog.csdn.net/qq_53206057/article/details/130766270 《conda 指定安装路径》
创建 openwebui
conda create --prefix=/root/autodl-tmp/openwebui python==3.11 -y
# To activate this environment, use
#
# $ conda activate openwebui
#
# To deactivate an active environment, use
#
# $ conda deactivate
激活openwebui
conda activate /root/autodl-tmp/openwebui
安装open-webui
pip install open-webui
配置环境
export HF_ENDPOINT=https://hf-mirror.com
export ENABLE_OLLAMA_API=False
export OPENAI_API_BASE_URL=http://127.0.0.1:8000/v1

用vllm 加载刚刚训练之后的模型
vllm serve /root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct-merge
启动 open-webui
open-webui serve
【注意】如果系统盘不够,可以使用如下方法
系统盘固定30g无法扩容,系统盘清理参考:https://www.autodl.com/docs/qa1/
https://blog.csdn.net/qq_44534541/article/details/147336888 《python指定安装路径》
https://blog.csdn.net/qq_44534541/article/details/147336888《pip 的包下载之后存放在哪?》
在vscode中添加8080端口
本地访问
如果vscode没有加默认端口,自己手动加一下 。 不然,界面就卡在那里了 。
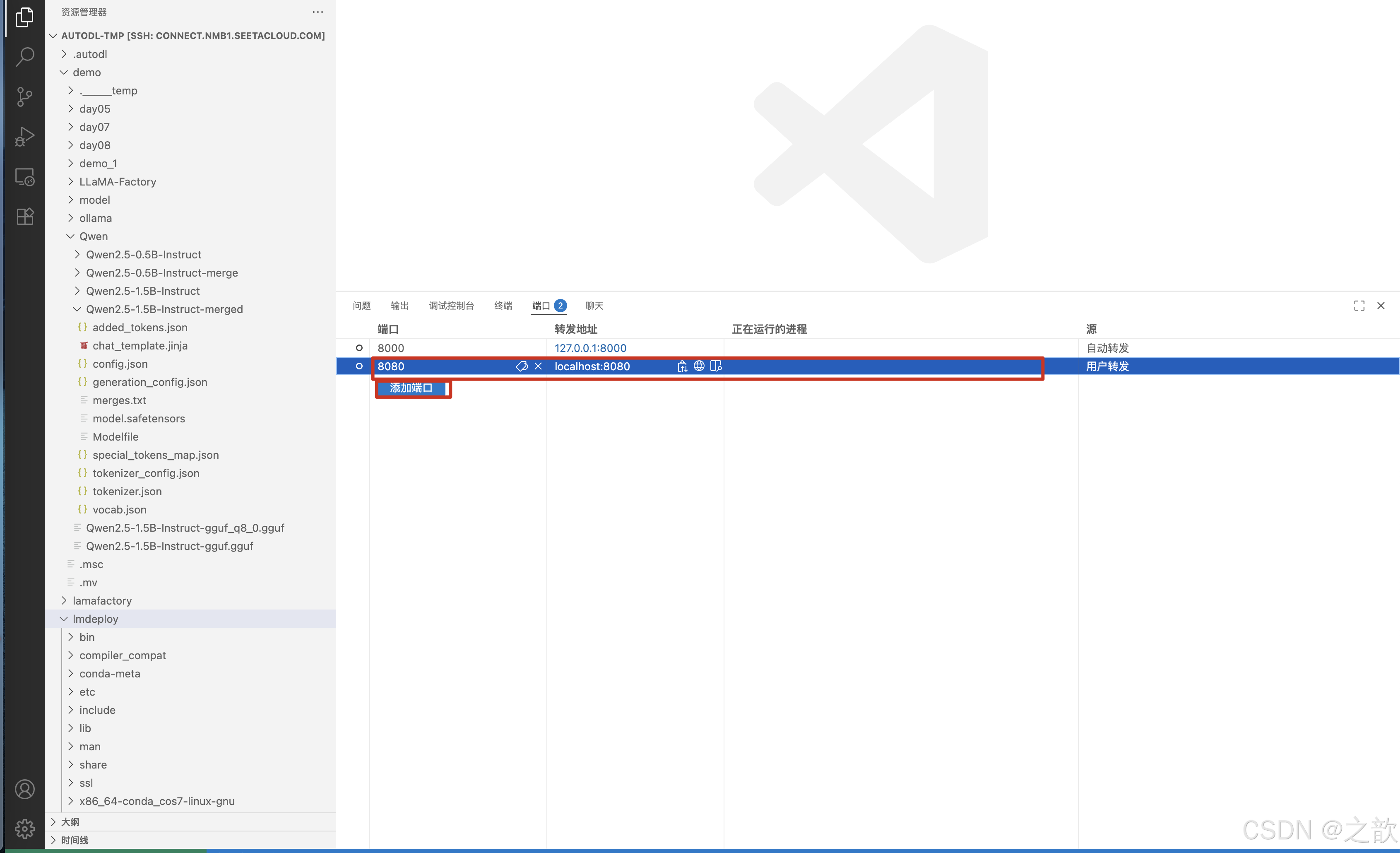
本地访问
第一次访问需要登录,这里用户名和密码可以随便写,记住就好,下次使用
请访问这个地址
http://localhost:8080/auth
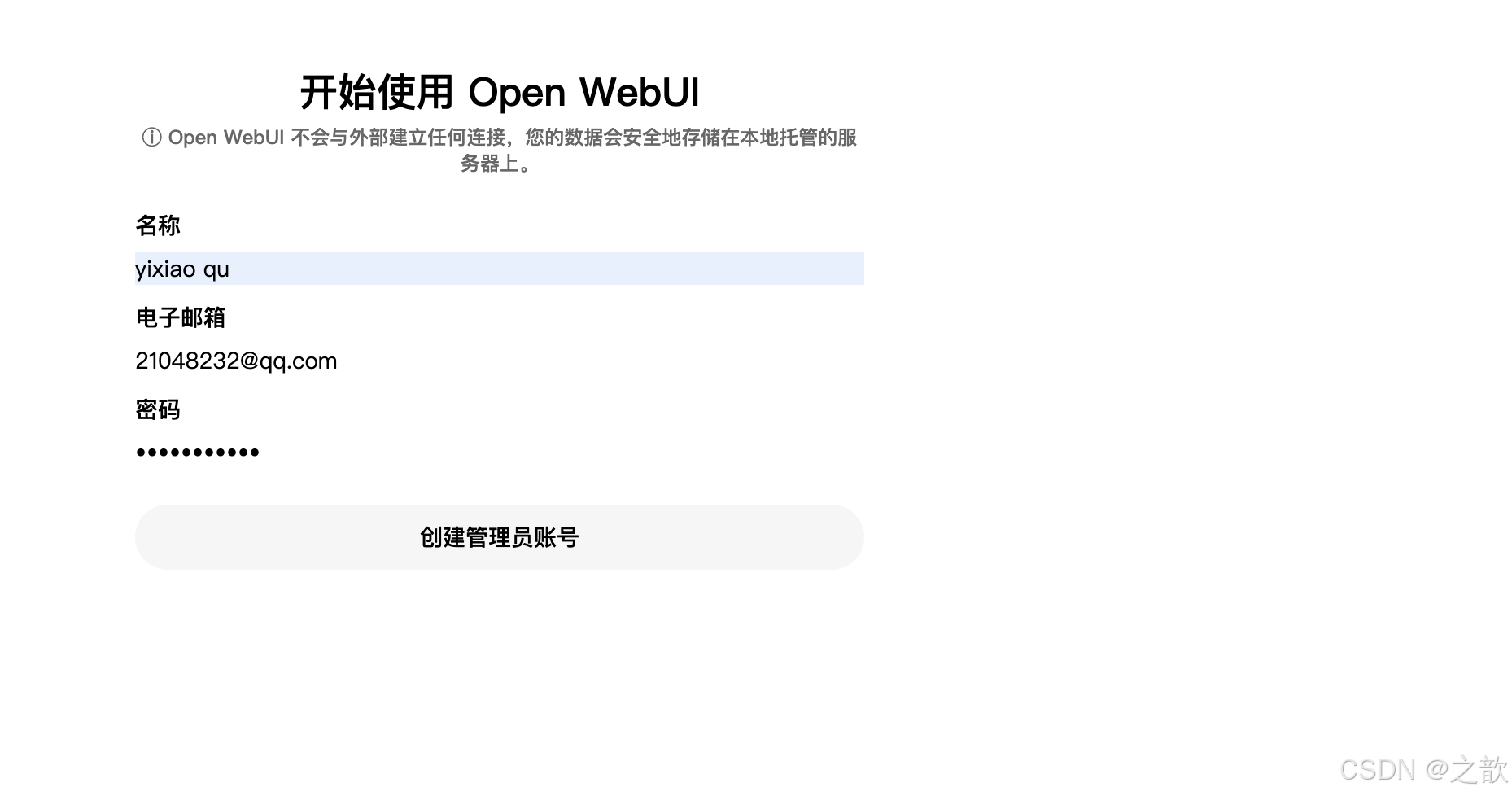
登录进去以后的主界面
即可以像通常的大模型一样使用,用于个人还是可以的。
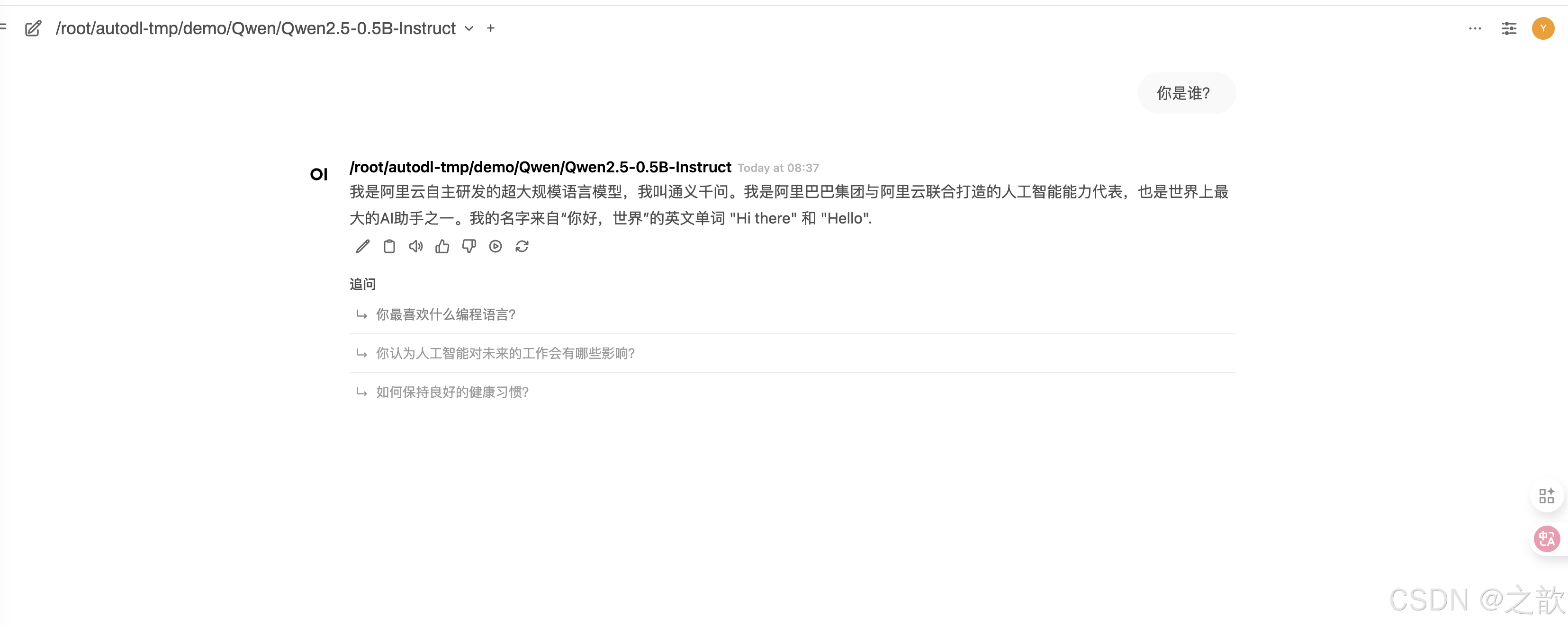
当然也支持语言模式

自己可以玩玩
大模型微调(QLora微调&GGUF模型转换)
LLama Factory自定义多轮对话数据集
关于模型微调轮次的设置多少合适?
3~ 5epoch就有效了
问题:为什么课上的epoch给的很大?例如1000
1.模型微调训练的目标是什么?
我们给的是个理想目标(让模型在测试数据集中达到拟合状态(损失收敛))
2.模型微调训练到多少个epoch才会拟合?
这是一个未知数,因此我们一般在设置训练epoch时会给一个较大的数值,防止模型还未达到
拟合状态而训练就已经结束了。
3. 注意,大多数现实中的项目是不需要或者不可能训练到拟合状态的,只是训练到一个接近于拟合的状态,或者说达到甲方预期效果就可以了。
https://cloud.tencent.com/developer/article/1441933 《一款入门神器TensorFlowPlayground》
http://playground.tensorflow.org/《TensorFlow playground》
在现实过程中,我们考虑的是否可以交付。
大模型中的“大”指的是参数数量大(参数量的多少),而不是文件的大小。
模型就是一堆参数,模型也就是权重 。
在模型微调训练过程中,我们可以采用降低模型参数精度来节约训练的显存,以此提升训练批次大小,使得模型训练的更快。
问题:之前的部署量化有提到,量化是以牺牲精度为代价提升性能。那么在训练过程给中使用量化是;否会降低模型的精度呢?
答案是:不会。在量化部署中,由于模型的参数已经固定了,所以降低精度一定会影响结果;但是,在训练过程中,模型的参数并未固定,依然处于学习状态,所以降低参数的精度对模型的结果不会有太大影响(因为AI训练的结果不是具体的数值,而是一种趋势)。
注意:在量化微调中,量化只发生在内部的训练过程,并不影响模型的最终的数据类型(模型原有的参数类型是f16,在量化微调训练中会量化为8位,参数保存时又会还原到float16),因此量化微调并不会影响到模型结果
LoRA与QLoRA
LoRA:LoRA 是一种用于微调大型语言模型的技术,通过低秩近
似方法降低适应数十亿参数模型(如 GPT-3)到特定任务或领域。
QLoRA:QLoRA 是一种高效的大型语言模型微调方法,它显著降
低了内存使用量,同时保持了全 16 位微调的性能。它通过在一个
固定的、4 位量化的预训练语言模型中反向传播梯度到低秩适配
器来实现这一目标。
QLoRA微调
下载 https://www.modelscope.cn/models/Qwen/Qwen2.5-1.5B-Instruct
创建/root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct 目录
mkdir -p /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct
下载模型
modelscope download --model Qwen/Qwen2.5-1.5B-Instruct --local_dir ./
上传数据集
启动llamafactory
llamafactory-cli webui
pip install bitsandbytes==0.37.0 # pip指定安装包版本
效果
LoRA 秩 一般是32 ~ 128 之间

如果使用QLoRA,而不是LoRA 微调, LORA缩放系数 是 LORA秩 的2倍 。 一般 LORA缩放系数 是 LORA秩 的2倍 的效果比较好。
大模型转换为 GGUF 以及使用 ollama 运行
什么是 GGUF
GGUF 格式的全名为(GPT-Generated Unified Format),提到
GGUF 就不得不提到它的前身 GGML(GPT-Generated Model
Language)。GGML 是专门为了机器学习设计的张量库,最早可
以追溯到 2022/10。其目的是为了有一个单文件共享的格式,并
且易于在不同架构的 GPU 和 CPU 上进行推理。但在后续的开发
中,遇到了灵活性不足、相容性及难以维护的问题。
为什么要转换 GGUF 格式
在传统的 Deep Learning Model 开发中大多使用 PyTorch 来进行开发,但因为在部署时会面临相依 Lirbrary 太多、版本管理的问题于
才有了 GGML、GGMF、GGJT 等格式,而在开源社群不停的迭代后 GGUF 就诞生了。
GGUF 实际上是基于 GGJT 的格式进行优化的,并解决了 GGML 当初面临的问题,包括:
1)可扩展性:轻松为 GGML 架构下的工具添加新功能,或者向 GGUF 模型添加新 Feature,不会破坏与现有模型的兼容性。
2)对 mmap(内存映射)的兼容性:该模型可以使用 mmap 进行加载(原理解析可见参考),实现快速载入和存储。(从 GGJT 开
始导入,可参考 GitHub)
3)易于使用:模型可以使用少量代码轻松加载和存储,无需依赖的 Library,同时对于不同编程语言支持程度也高。
4)模型信息完整:加载模型所需的所有信息都包含在模型文件中,不需要额外编写设置文件。
5)有利于模型量化:GGUF 支持模型量化(4 位、8 位、F16),在 GPU 变得越来越昂贵的情况下,节省 vRAM 成本也非常重要。
Qwen打包部署(大模型转换为 GGUF 以及使用 ollama 运行)
将hf模型转换为GGUF
需要用llama.cpp仓库的convert_hf_to_gguf.py脚本来转换
安装llamaapp 的隔离环境
conda create --prefix=/root/autodl-tmp/llamaapp python3.10 -y
激活隔离环境llamaapp
conda activate /root/autodl-tmp/llamaapp
下载 llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git
cd /root/autodl-tmp/demo/ollama 这个目录睛 ,这个目录中有刚刚下载的llama.cpp 文件
pip install -r llama.cpp/requirements.txt
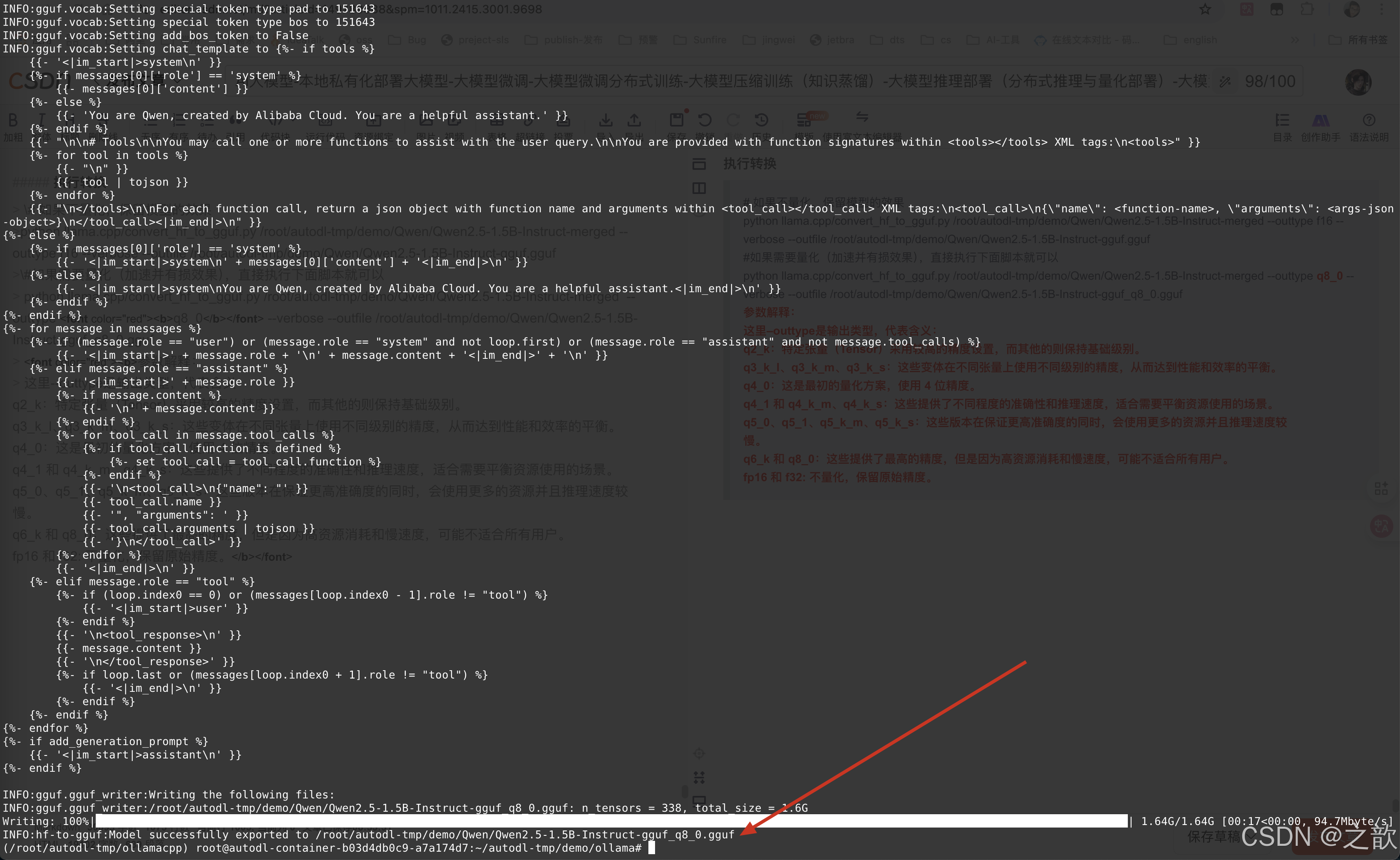
执行转换
# 如果不量化,保留模型的效果
python llama.cpp/convert_hf_to_gguf.py /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct-merged --outtype f16 --verbose --outfile /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct-gguf.gguf
#如果需要量化(加速并有损效果),直接执行下面脚本就可以
python llama.cpp/convert_hf_to_gguf.py /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct-merged --outtype q8_0 --verbose --outfile /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct-gguf_q8_0.gguf
参数解释:
这里–outtype是输出类型,代表含义:
q2_k:特定张量(Tensor)采用较高的精度设置,而其他的则保持基础级别。
q3_k_l、q3_k_m、q3_k_s:这些变体在不同张量上使用不同级别的精度,从而达到性能和效率的平衡。
q4_0:这是最初的量化方案,使用 4 位精度。
q4_1 和 q4_k_m、q4_k_s:这些提供了不同程度的准确性和推理速度,适合需要平衡资源使用的场景。
q5_0、q5_1、q5_k_m、q5_k_s:这些版本在保证更高准确度的同时,会使用更多的资源并且推理速度较
慢。
q6_k 和 q8_0:这些提供了最高的精度,但是因为高资源消耗和慢速度,可能不适合所有用户。
fp16 和 f32: 不量化,保留原始精度。
生成效果如下:
生成效果如下:
先激活并启动ollama
# conda info --envs
# conda activate /root/autodl-tmp/ollama
# ollama serve

打开另外一个窗口,创建ModelFile

vi /root/autodl-tmp/ModeFile , 在文件中写入如下内容
# GGUF文件路径
FROM /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct-gguf.gguf
创建自定义模型
使用ollama create命令创建自定义模型
cd /root/autodl-tmp
ollama create Qwen2.5-1.5B-Instruct-q8 --file ./ModeFile
模型加载进去了


运行模型:
# ollama run Qwen2.5-1.5B-Instruct-q8
运行测试结果如下:
【注意】 如果这里有多个gguf 模型需要加载 ,则在不同的目录下创建多个ModelFile文件,或者你将原来的ModelFile修改掉即可,ollama create Qwen2.5-1.5B-Instruct-q8 --file ./ModeFile 一次性只能加载一个模型文件,当加载的模型名字(Qwen2.5-1.5B-Instruct-q8)相同时,会覆盖掉之前的模型 。
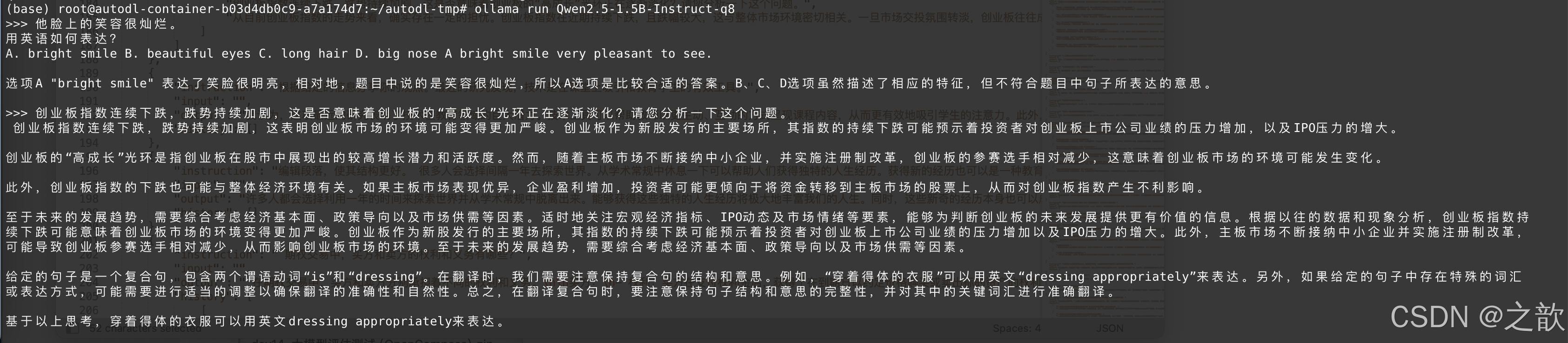
大模型微调(LLamaFactory微调效果与vllm部署效果不一致如何解决)
生成式语言模型的对话模板介绍
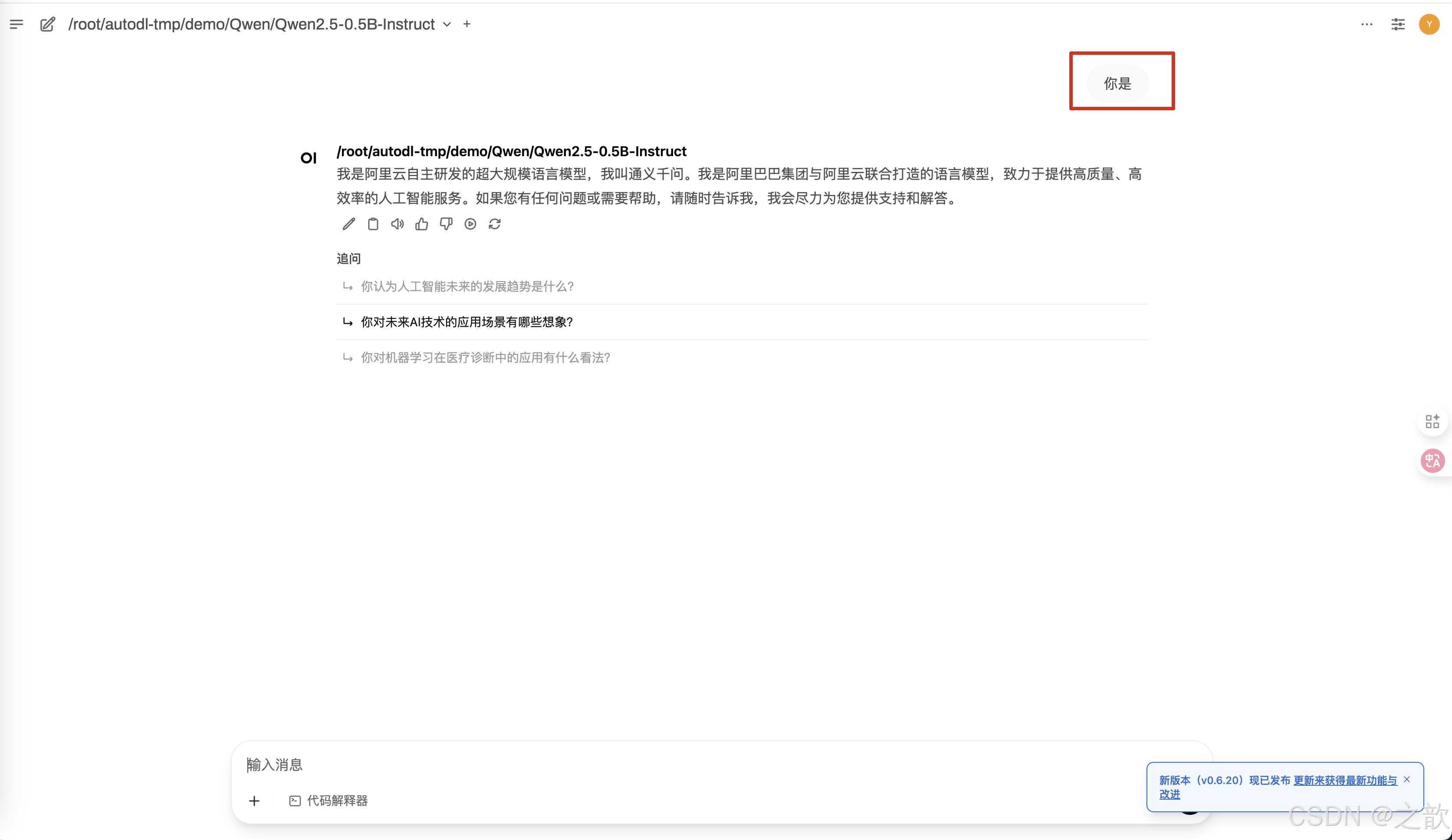
按之前的方式启动openwebui ,问你是
在vllm 启动后台看到如下信息
INFO 08-10 09:12:39 [logger.py:41] Received request chatcmpl-5ca9ded32a7648ebb4193fffa3bc2017: prompt:
‘<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n<
|im_start|>user\n### Task:\nGenerate 1-3 broad tags categorizing the main themes of the chat history, along with 1-3 more specific subtopic tags.\n\n### Guidelines:\n- Start with high-level domains (e.g. Science, Technology, Philosophy, Arts, Politics, Business, Health, Sports, Entertainment, Education)\n- Consider including relevant subfields/subdomains if they are strongly represented throughout the conversation\n- If content is too short (less than 3 messages) or too diverse, use only [“General”]\n- Use the chat’s primary language; default to English if multilingual\n- Prioritize accuracy over specificity\n\n### Output:\nJSON format: { “tags”: [“tag1”, “tag2”, “tag3”] }\n\n
### Chat History:\n<chat_history>\nUSER: 你是\nASSISTANT: 我是阿里云自主研发的超大规模语言模型,我叫通义千问。我是阿里巴巴集团与阿里云联合打造的语言模型,致力于提供高质量、高效率的人工智能服务。如果您有任何问题或需要帮助,请随时告诉我,我会尽力为您提供支持和解答。\n</chat_history><|im_end|>\n
<|im_start|>assistant\n’, params: SamplingParams(n=1, presence_penalty=0.0, frequency_penalty=0.0, repetition_penalty=1.1, temperature=0.7, top_p=0.8, top_k=20, min_p=0.0, seed=None, stop=[], stop_token_ids=[], bad_words=[], include_stop_str_in_output=False, ignore_eos=False, max_tokens=32511, min_tokens=0, logprobs=None, prompt_logprobs=None, skip_special_tokens=True, spaces_between_special_tokens=True, truncate_prompt_tokens=None, guided_decoding=None, extra_args=None), prompt_token_ids: None, prompt_embeds shape: None, lora_request: None.
INFO 08-10 09:12:39 [async_llm.py:269] Added request chatcmpl-5ca9ded32a7648ebb4193fffa3bc2017.
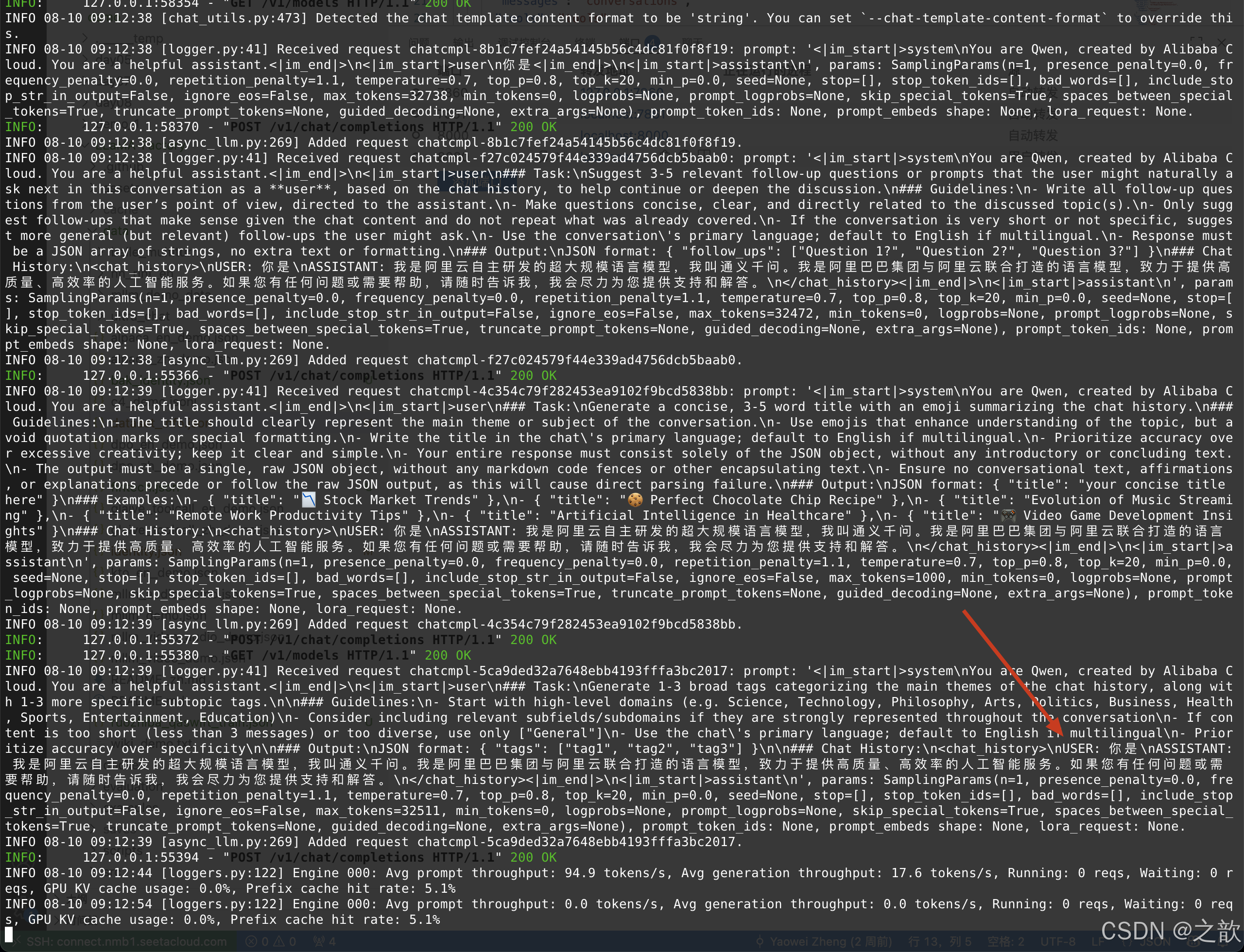
Lora微调后单独部署大模型输出结果不一致
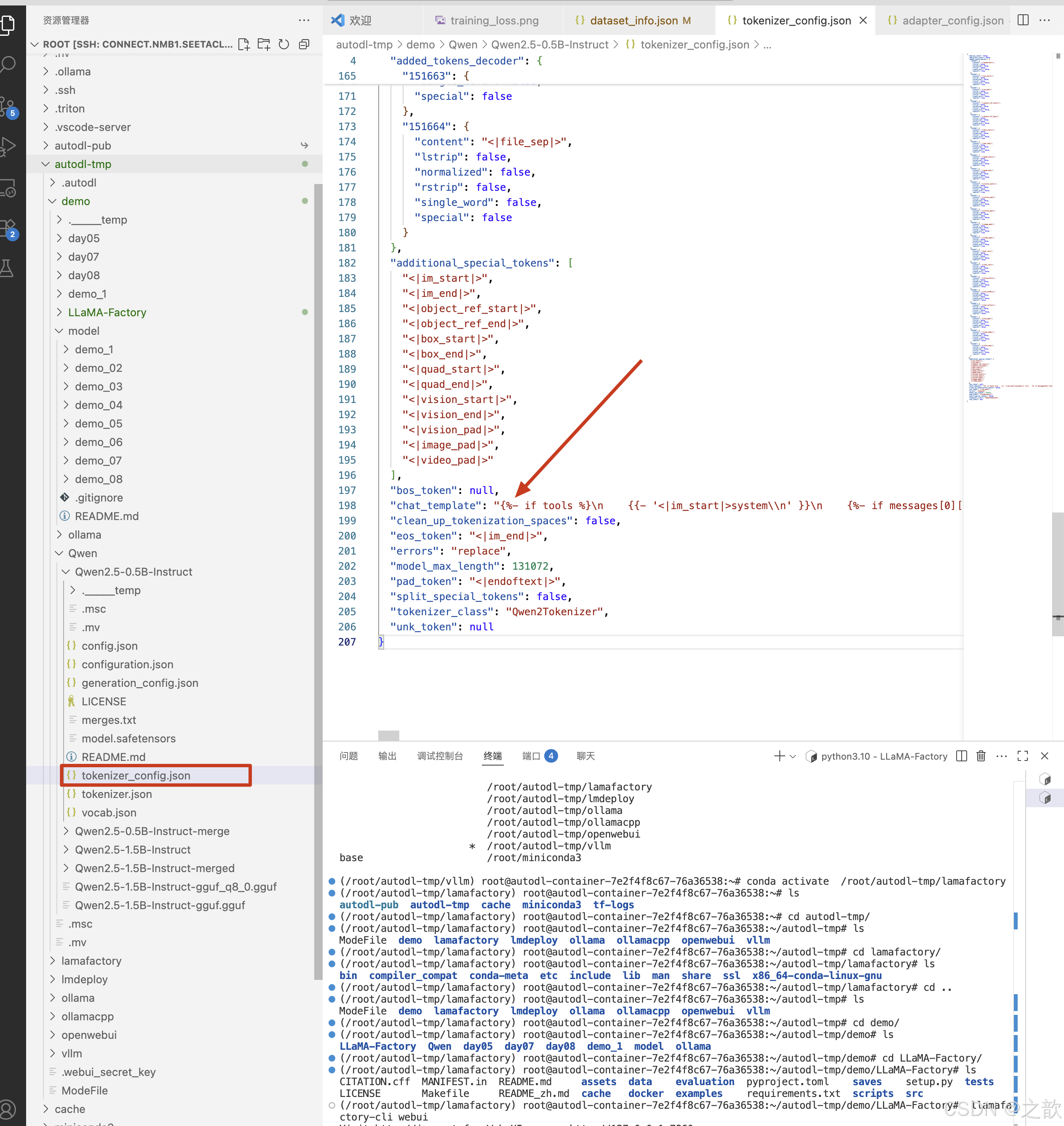
从上面两个图可以看出,用LLaMA Factory 微调使用的对话模板 和 模型本身 的 对话模板 是不一样的,可能会出现你在模型微调时
这里的聊天得到的模型回复 和 你将 模型布署在vllm 中回复的内容不一致, 导致这个问题的根本原因是 模型 训练时 的 会话模板和vllm 布署时会话模板不一致所致。 解决方法: 将模型训练时的会话模板导出来,在vllm 启动时指定自己的会话模板
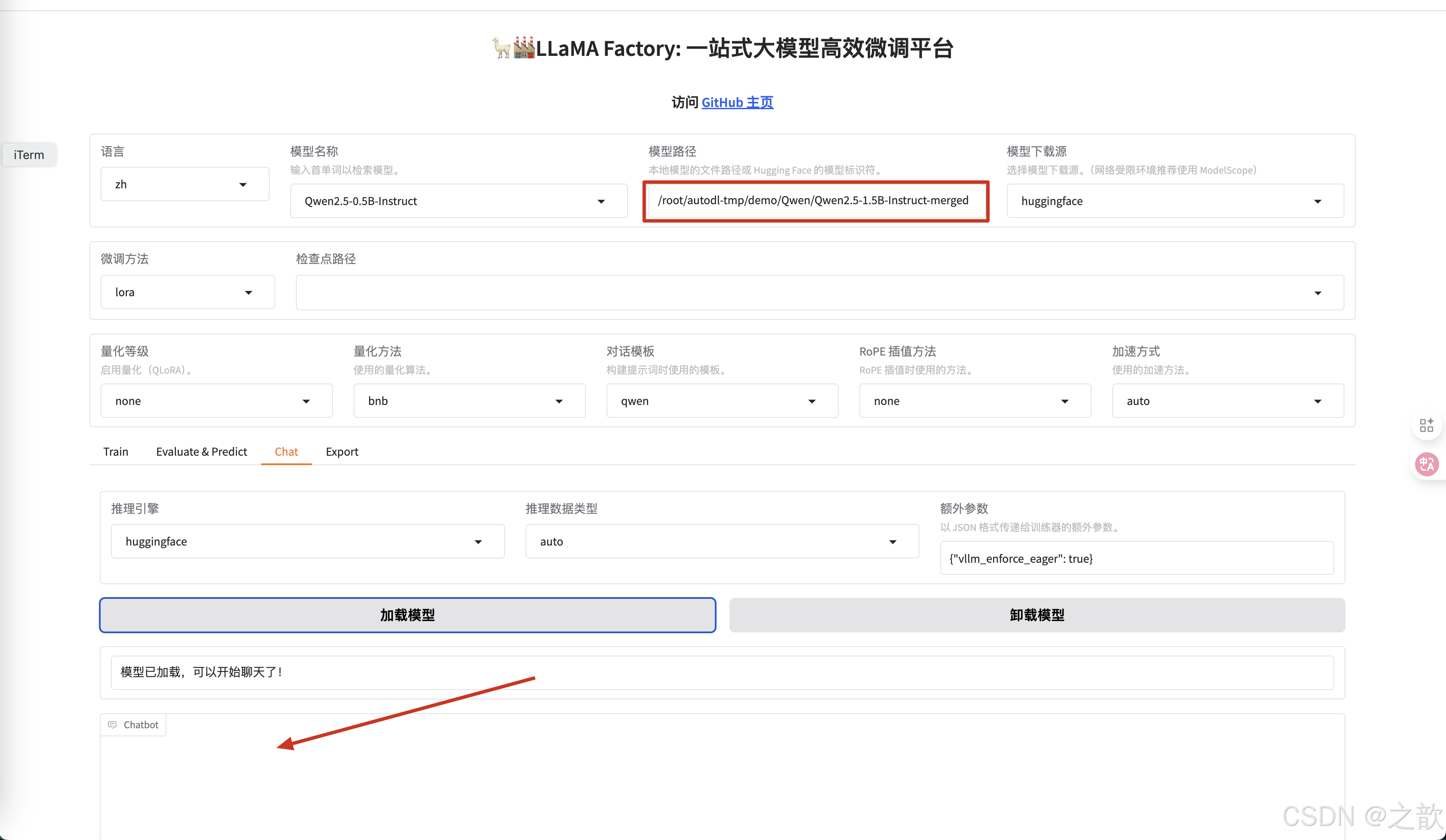
如何导出LLama Factory的对话模板
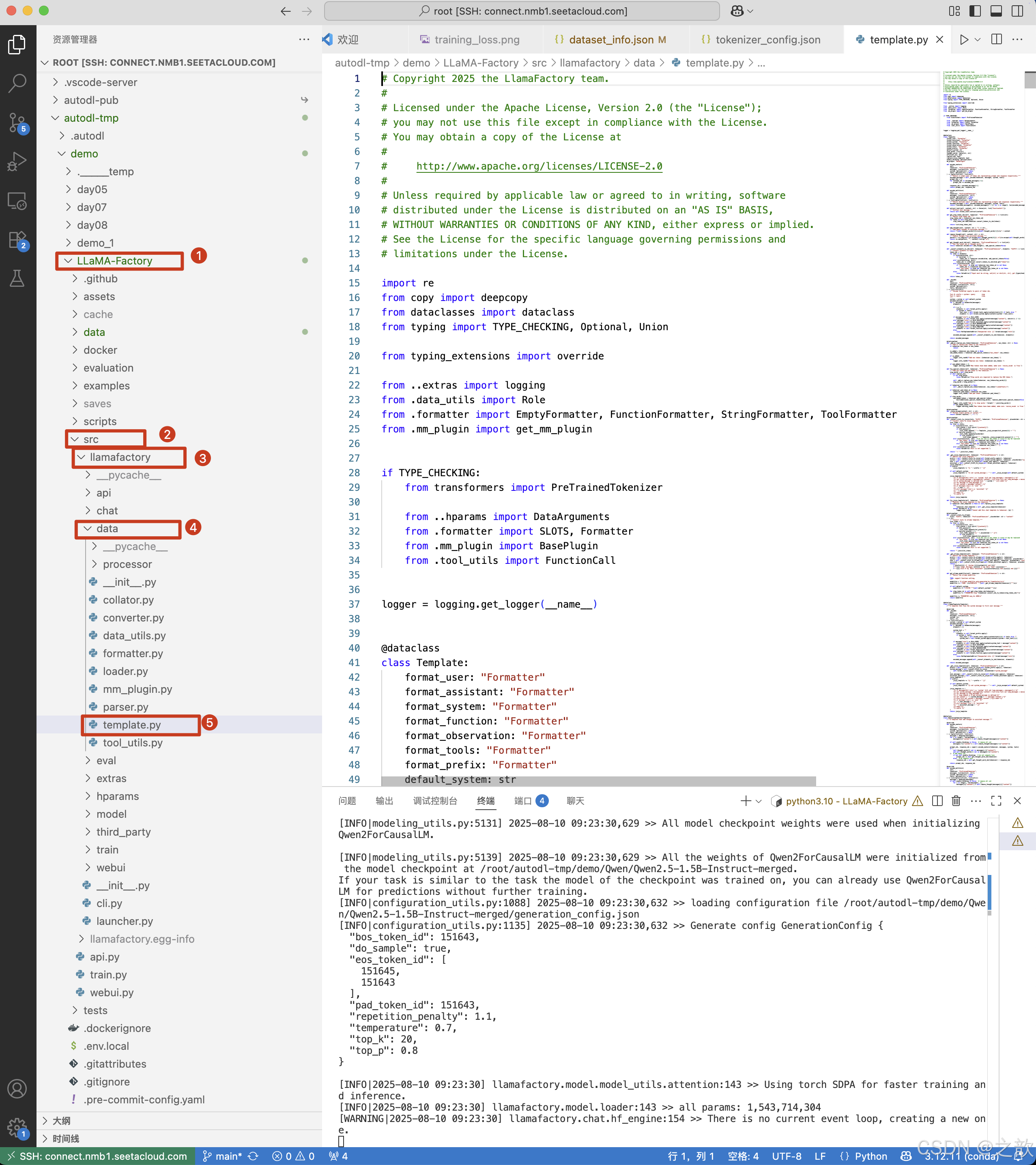
qwen对话模板
Jinja2
Jinja2官网,Jinja2 比json 更加灵活
下图中有一个_get_jinja_template()方法,自己定一个脚本来调用这个方法导出jinja2格式的模板 。
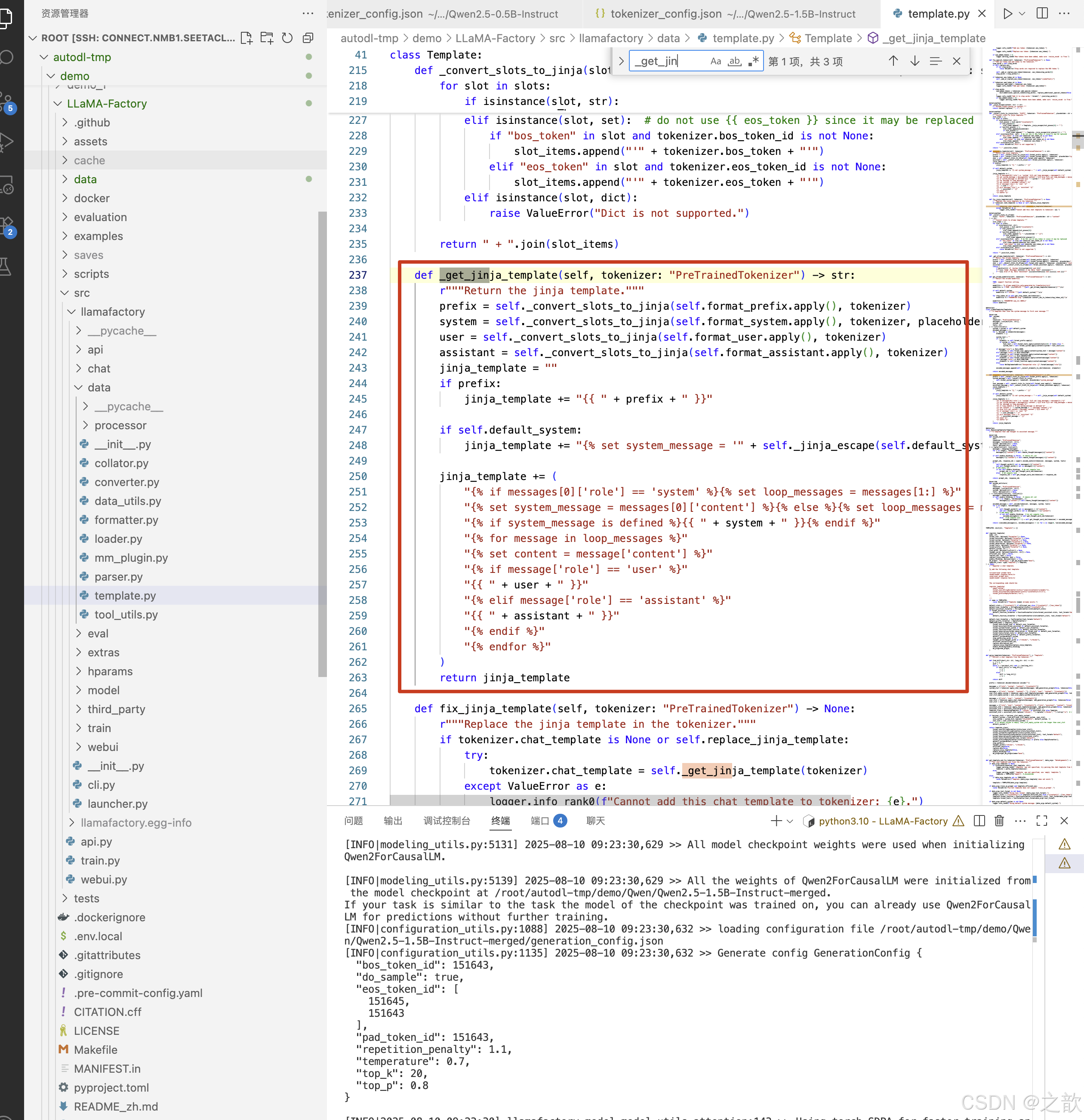
导出会话模板
创建一个mytest.py文件,将这个文件放到template.py 同级目录
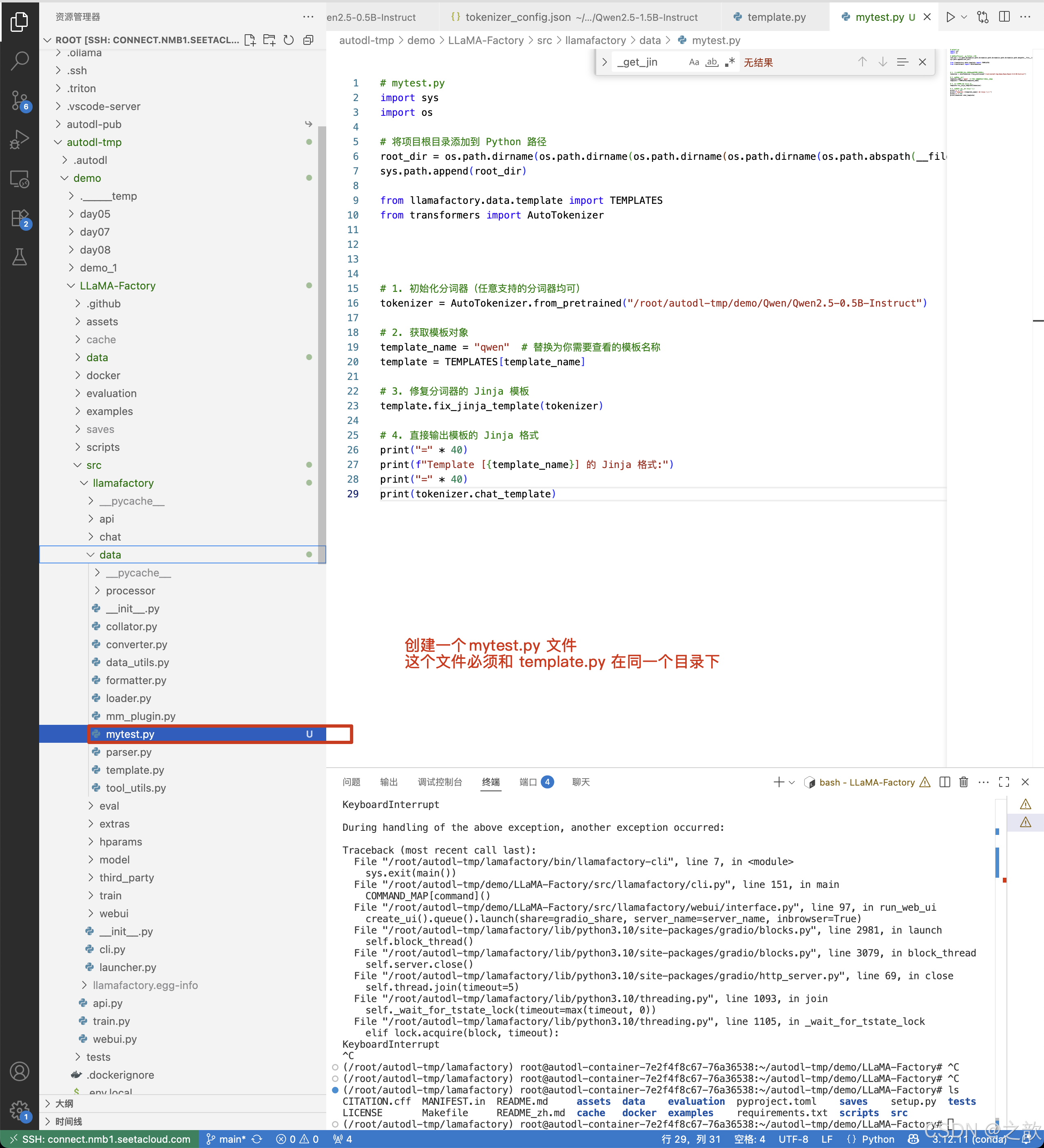
# mytest.py
import sys
import os# 将项目根目录添加到 Python 路径
root_dir = os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
sys.path.append(root_dir)from llamafactory.data.template import TEMPLATES
from transformers import AutoTokenizer# 1. 初始化分词器(任意支持的分词器均可)
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct")# 2. 获取模板对象
template_name = "qwen" # 替换为你需要查看的模板名称
template = TEMPLATES[template_name]# 3. 修复分词器的 Jinja 模板
template.fix_jinja_template(tokenizer)# 4. 直接输出模板的 Jinja 格式
print("=" * 40)
print(f"Template [{template_name}] 的 Jinja 格式:")
print("=" * 40)
print(tokenizer.chat_template)输出内容:
(/root/autodl-tmp/lamafactory) root@autodl-container-7e2f4f8c67-76a36538:~/autodl-tmp/demo/LLaMA-Factory/src/llamafactory/data# python mytest.py
========================================
Template [qwen] 的 Jinja 格式:
========================================
{%- if tools %}{{- '<|im_start|>system\n' }}{%- if messages[0]['role'] == 'system' %}{{- messages[0]['content'] }}{%- else %}{{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}{%- endif %}{{- "\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}{%- for tool in tools %}{{- "\n" }}{{- tool | tojson }}{%- endfor %}{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}{%- if messages[0]['role'] == 'system' %}{{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }}{%- else %}{{- '<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n' }}{%- endif %}
{%- endif %}
{%- for message in messages %}{%- if (message.role == "user") or (message.role == "system" and not loop.first) or (message.role == "assistant" and not message.tool_calls) %}{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}{%- elif message.role == "assistant" %}{{- '<|im_start|>' + message.role }}{%- if message.content %}{{- '\n' + message.content }}{%- endif %}{%- for tool_call in message.tool_calls %}{%- if tool_call.function is defined %}{%- set tool_call = tool_call.function %}{%- endif %}{{- '\n<tool_call>\n{"name": "' }}{{- tool_call.name }}{{- '", "arguments": ' }}{{- tool_call.arguments | tojson }}{{- '}\n</tool_call>' }}{%- endfor %}{{- '<|im_end|>\n' }}{%- elif message.role == "tool" %}{%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != "tool") %}{{- '<|im_start|>user' }}{%- endif %}{{- '\n<tool_response>\n' }}{{- message.content }}{{- '\n</tool_response>' }}{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}{{- '<|im_end|>\n' }}{%- endif %}{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}{{- '<|im_start|>assistant\n' }}
{%- endif %}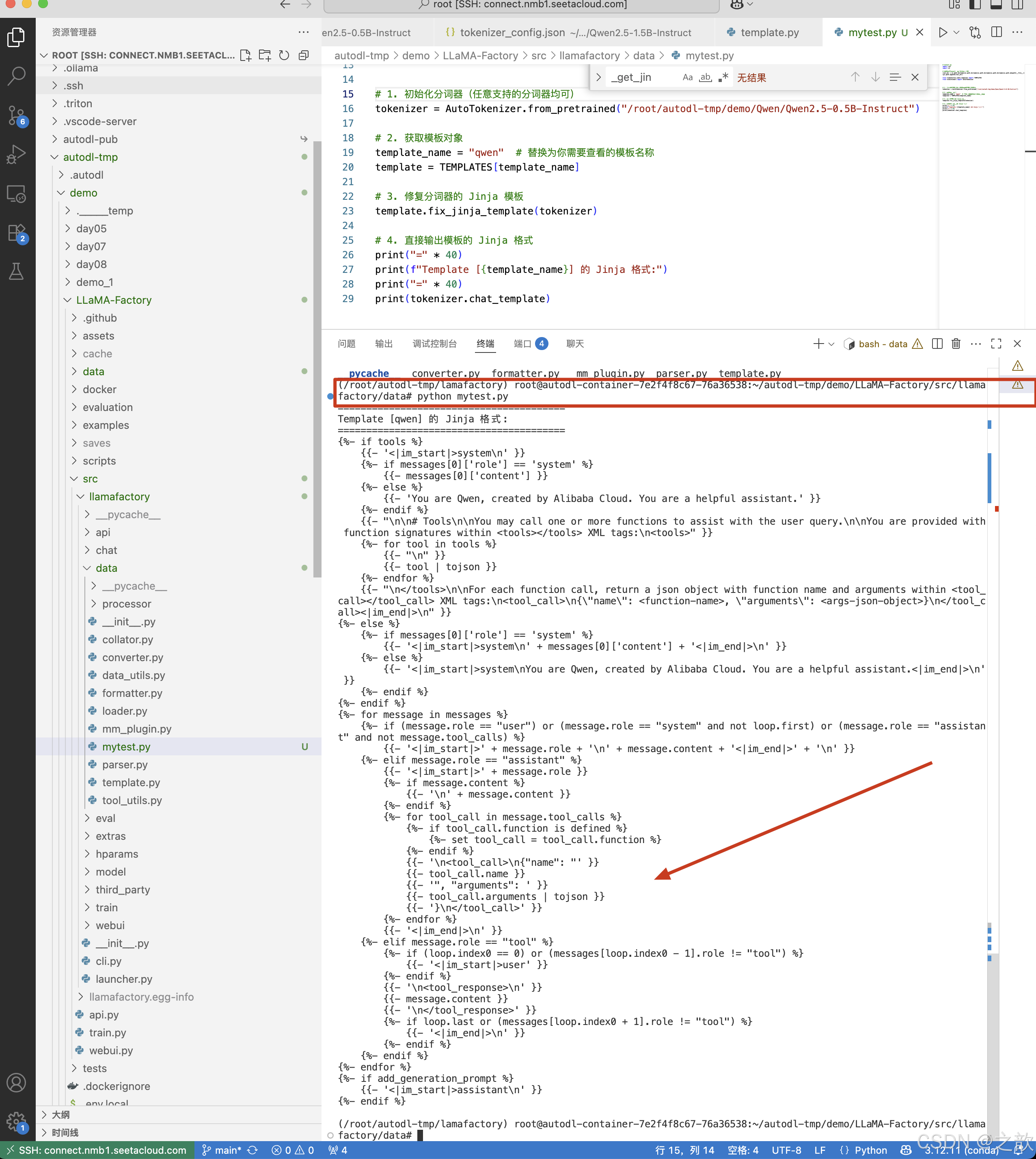
vllm推理模型时自定义对话模板
在用vllm 启动模型的时候,指定会话模板
vllm serve <model> --chat-template ./path-to-chat-template.jinja
创建一个/root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct/custom_chat_template.jinja 文件,将上一步生成的对话模板内容拷贝到里面 。
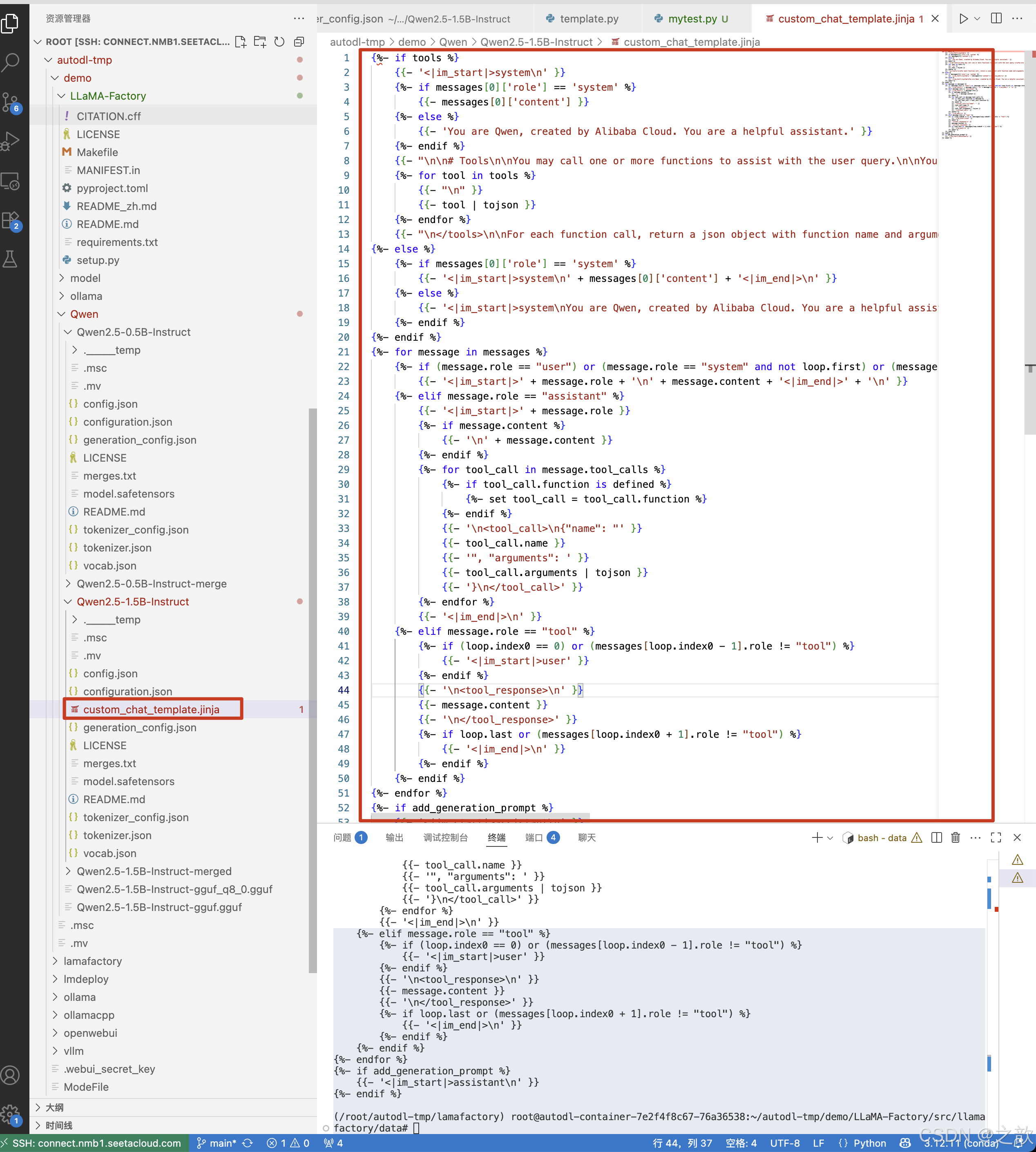
vllm serve /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct --chat-template /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct/custom_chat_template.jinja
test01.py
#多轮对话
from openai import OpenAI#定义多轮对话方法
def run_chat_session():#初始化客户端client = OpenAI(base_url="http://localhost:8000/v1/",api_key="suibianxie")#初始化对话历史chat_history = []#启动对话循环while True:#获取用户输入user_input = input("用户:")if user_input.lower() == "exit":print("退出对话。")break#更新对话历史(添加用户输入)chat_history.append({"role":"user","content":user_input})#调用模型回答try:chat_complition = client.chat.completions.create(messages=chat_history,model="/root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct-merged")#获取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新对话历史(添加AI模型的回复)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("发生错误:",e)break
if __name__ == '__main__':run_chat_session()输出如下:

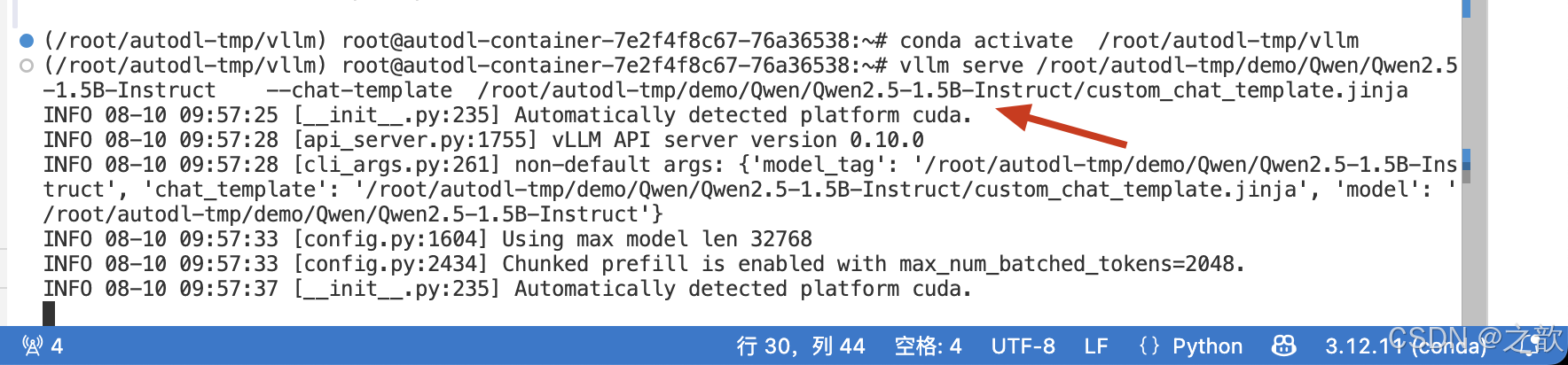
启动vllm
vllm serve /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct --chat-template /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct/custom_chat_template.jinja
案例:使用vllm有效部署Lora微调后的Qwen模型
但是需要注意的是 :open-webui 每次在启动的时候,会将模型本身的会话模板给覆盖掉,open-webui 目前没有地方去指定自定义会话模板,因此在企业应用尽量不要使用open-webui

)
: 图像表示;图像通道分割;图像通道合并;图像属性】)
)
)









——Nginx负载均衡)



:在QtOpenGL环境下,仿three.js的BufferGeometry管理VAO和EBO绘制四边形)
