
医疗健康Agent:诊断辅助与患者管理的AI解决方案
🌟 Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
摘要
大家好,我是摘星。作为一名深耕AI医疗领域多年的技术从业者,我见证了人工智能在医疗健康领域的快速发展和广泛应用。今天想和大家分享医疗健康Agent的技术实现和实际应用经验。
医疗健康Agent作为人工智能在医疗领域的重要应用,正在革命性地改变传统医疗服务模式。从最初的简单症状查询,到现在能够进行复杂疾病诊断辅助和个性化治疗方案推荐,医疗AI的能力边界在不断扩展。在我参与的项目中,我们发现一个设计良好的医疗健康Agent不仅能够提供24/7的健康咨询服务,还能在关键时刻为医生提供重要的诊断参考。
本文将从技术架构、核心算法、临床应用和安全保障四个维度,全面解析医疗健康Agent的构建过程。我会结合实际案例,分享在症状识别、疾病诊断、风险评估等关键环节的技术选型和优化策略。同时,我也会详细介绍医疗AI的伦理考量和安全机制,确保系统在提供便利的同时,始终将患者安全放在首位。医疗健康Agent的发展不仅需要先进的技术支撑,更需要严格的医学验证和伦理审查,这是我们在实际项目中最深刻的体会。
1. 医疗健康Agent技术架构
1.1 整体系统架构
医疗健康Agent需要处理复杂的医学知识和多模态数据,其架构设计必须兼顾准确性和安全性。
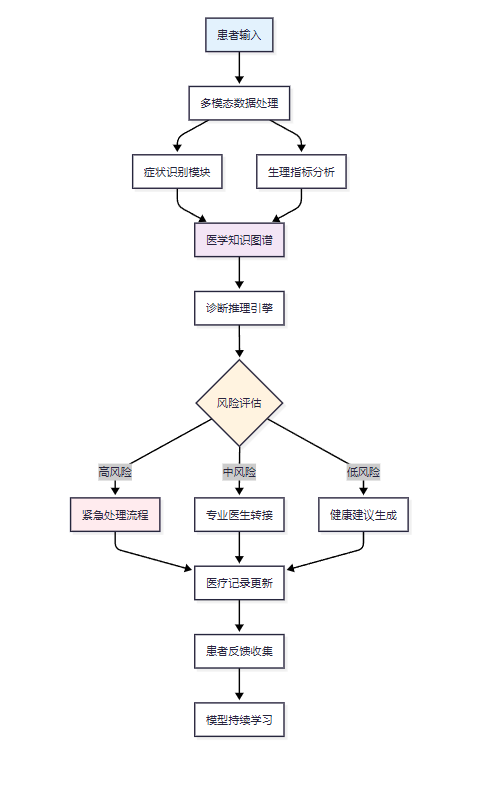
图1:医疗健康Agent整体架构图
1.2 核心组件实现
import torch
import torch.nn as nn
from transformers import BertModel, BertTokenizer
from typing import Dict, List, Optional
import numpy as npclass MedicalHealthAgent:def __init__(self):self.symptom_recognizer = SymptomRecognizer()self.disease_classifier = DiseaseClassifier()self.risk_assessor = RiskAssessor()self.knowledge_graph = MedicalKnowledgeGraph()def process_patient_input(self, patient_data: Dict) -> Dict:"""处理患者输入的主流程"""# 1. 症状识别symptoms = self.symptom_recognizer.extract_symptoms(patient_data.get('description', ''),patient_data.get('vital_signs', {}))# 2. 疾病诊断possible_diseases = self.disease_classifier.predict(symptoms, patient_data.get('medical_history', []))# 3. 风险评估risk_level = self.risk_assessor.assess_risk(symptoms, possible_diseases, patient_data)# 4. 生成建议recommendations = self._generate_recommendations(symptoms, possible_diseases, risk_level)return {'symptoms': symptoms,'possible_diseases': possible_diseases,'risk_level': risk_level,'recommendations': recommendations,'requires_immediate_attention': risk_level == 'HIGH'}def _generate_recommendations(self, symptoms, diseases, risk_level):"""生成医疗建议"""if risk_level == 'HIGH':return {'action': 'EMERGENCY','message': '建议立即就医或拨打急救电话','urgency': 'IMMEDIATE'}elif risk_level == 'MEDIUM':return {'action': 'CONSULT_DOCTOR','message': '建议尽快咨询专业医生','urgency': 'WITHIN_24_HOURS'}else:return {'action': 'SELF_CARE','message': '可进行自我护理,注意观察症状变化','urgency': 'ROUTINE'}class SymptomRecognizer:def __init__(self):self.symptom_patterns = {'发热': ['发烧', '体温高', '发热', '高烧'],'咳嗽': ['咳嗽', '咳痰', '干咳', '咳血'],'头痛': ['头痛', '头疼', '偏头痛', '头晕'],'胸痛': ['胸痛', '胸闷', '心痛', '胸部不适']}def extract_symptoms(self, description: str, vital_signs: Dict) -> List[Dict]:"""从描述和生理指标中提取症状"""symptoms = []# 文本症状识别for symptom, patterns in self.symptom_patterns.items():for pattern in patterns:if pattern in description:symptoms.append({'name': symptom,'confidence': 0.8,'source': 'text_description'})break# 生理指标异常检测if vital_signs:if vital_signs.get('temperature', 36.5) >= 37.3:symptoms.append({'name': '发热','severity': 'high' if vital_signs['temperature'] >= 39.0 else 'moderate','value': vital_signs['temperature'],'source': 'vital_signs'})return symptoms2. 疾病诊断与风险评估
2.1 多模态疾病分类器
class MultiModalDiseaseClassifier(nn.Module):def __init__(self, text_dim=768, numeric_dim=20, num_diseases=100):super().__init__()# 文本特征处理self.text_encoder = nn.Sequential(nn.Linear(text_dim, 512),nn.ReLU(),nn.Dropout(0.3),nn.Linear(512, 256))# 数值特征处理self.numeric_encoder = nn.Sequential(nn.Linear(numeric_dim, 128),nn.ReLU(),nn.Dropout(0.2),nn.Linear(128, 64))# 特征融合self.fusion_layer = nn.Sequential(nn.Linear(256 + 64, 512),nn.ReLU(),nn.Dropout(0.3),nn.Linear(512, 256),nn.ReLU(),nn.Linear(256, num_diseases))def forward(self, text_features, numeric_features):text_encoded = self.text_encoder(text_features)numeric_encoded = self.numeric_encoder(numeric_features)fused_features = torch.cat([text_encoded, numeric_encoded], dim=1)disease_logits = self.fusion_layer(fused_features)return disease_logitsclass DiseaseClassifier:def __init__(self):self.model = MultiModalDiseaseClassifier()self.disease_labels = ['感冒', '肺炎', '高血压', '糖尿病', '心脏病']def predict(self, symptoms: List[Dict], medical_history: List[str]) -> List[Dict]:"""预测可能的疾病"""# 简化的预测逻辑predictions = []# 基于症状的简单规则symptom_names = [s['name'] for s in symptoms]if '发热' in symptom_names and '咳嗽' in symptom_names:predictions.append({'disease': '肺炎','probability': 0.75,'confidence_level': 'HIGH'})elif '头痛' in symptom_names:predictions.append({'disease': '感冒','probability': 0.6,'confidence_level': 'MEDIUM'})return predictions2.2 风险评估流程
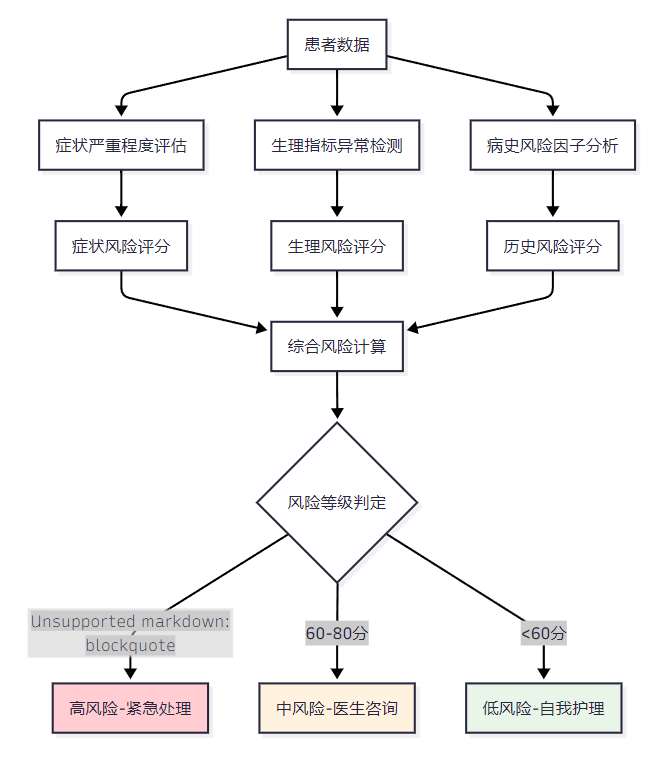
图2:医疗风险评估流程图
class RiskAssessor:def __init__(self):self.emergency_symptoms = {'胸痛': 30, '呼吸困难': 25, '意识模糊': 35,'严重头痛': 20, '高热': 15, '剧烈腹痛': 20}def assess_risk(self, symptoms: List[Dict], diseases: List[Dict], patient_data: Dict) -> str:"""评估患者风险等级"""total_score = 0# 症状风险评分for symptom in symptoms:symptom_name = symptom.get('name', '')base_score = self.emergency_symptoms.get(symptom_name, 0)severity = symptom.get('severity', 'low')multiplier = {'low': 0.5, 'moderate': 1.0, 'high': 1.5}.get(severity, 1.0)total_score += int(base_score * multiplier)# 年龄风险age = patient_data.get('age', 0)if age >= 65:total_score += 10elif age >= 45:total_score += 5# 慢性病风险chronic_diseases = patient_data.get('chronic_diseases', [])total_score += len(chronic_diseases) * 5# 风险等级判定if total_score >= 80:return 'HIGH'elif total_score >= 60:return 'MEDIUM'else:return 'LOW'3. 个性化治疗方案生成
3.1 医学知识图谱构建
import networkx as nxclass MedicalKnowledgeGraph:def __init__(self):self.graph = nx.MultiDiGraph()self._build_basic_knowledge()def _build_basic_knowledge(self):"""构建基础医学知识"""# 添加疾病节点diseases = ['感冒', '肺炎', '高血压', '糖尿病']for disease in diseases:self.graph.add_node(disease, type='disease')# 添加治疗方法节点treatments = ['休息', '多喝水', '抗生素', '降压药', '胰岛素']for treatment in treatments:self.graph.add_node(treatment, type='treatment')# 建立治疗关系treatment_relations = [('感冒', '休息', 0.8),('感冒', '多喝水', 0.7),('肺炎', '抗生素', 0.9),('高血压', '降压药', 0.85),('糖尿病', '胰岛素', 0.9)]for disease, treatment, effectiveness in treatment_relations:self.graph.add_edge(disease, treatment, type='treated_by', effectiveness=effectiveness)def get_treatment_recommendations(self, disease: str) -> List[Dict]:"""获取治疗建议"""recommendations = []if disease in self.graph:treatments = list(self.graph.successors(disease))for treatment in treatments:edge_data = self.graph.get_edge_data(disease, treatment)effectiveness = edge_data.get('effectiveness', 0.5)recommendations.append({'treatment': treatment,'effectiveness': effectiveness,'type': 'medication' if treatment in ['抗生素', '降压药', '胰岛素'] else 'lifestyle'})return sorted(recommendations, key=lambda x: x['effectiveness'], reverse=True)3.2 治疗方案决策树
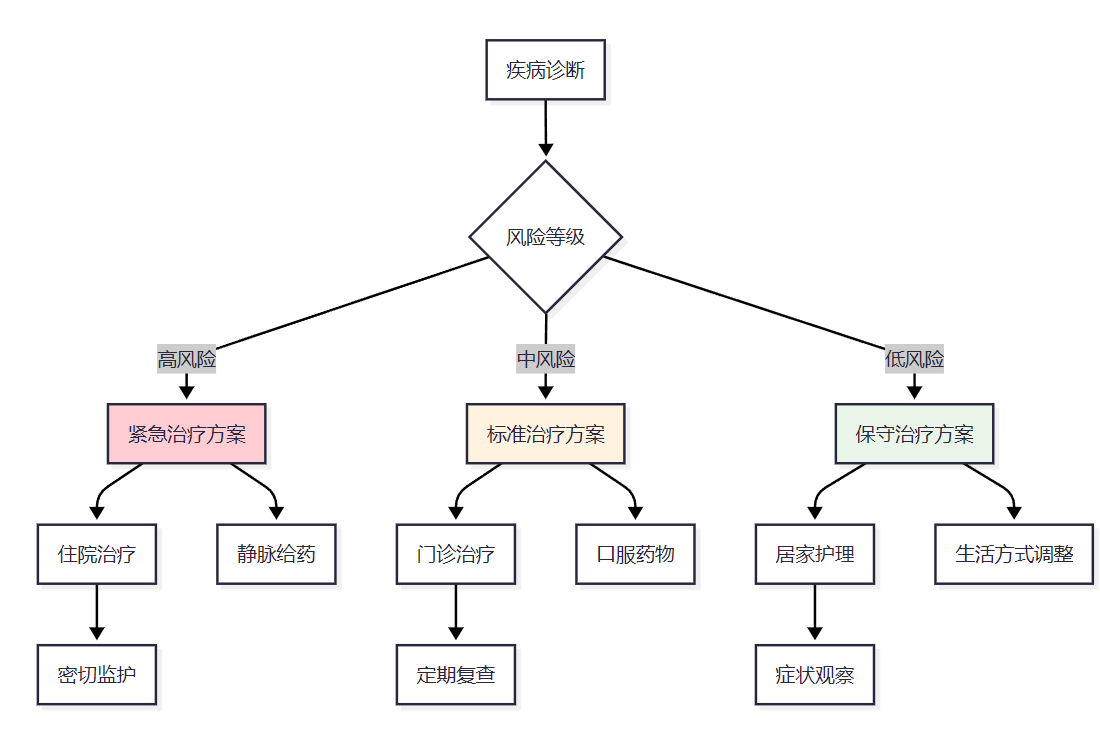
图3:个性化治疗方案决策树
4. 系统安全与伦理保障
4.1 医疗AI安全机制
医疗AI系统的安全性是首要考虑因素,需要建立多层次的安全保障机制。
| 安全层级 | 保障措施 | 实现方式 | 监控指标 |
| 数据安全 | 加密存储传输 | AES-256加密 | 数据泄露次数 |
| 模型安全 | 对抗样本检测 | 异常检测算法 | 误诊率 |
| 决策安全 | 人工审核机制 | 医生二次确认 | 审核通过率 |
| 隐私保护 | 差分隐私 | 噪声注入技术 | 隐私预算消耗 |
表1:医疗AI系统安全保障体系
class MedicalAISafety:def __init__(self):self.confidence_threshold = 0.8self.high_risk_diseases = ['心肌梗死', '脑卒中', '肺栓塞']def validate_diagnosis(self, diagnosis: Dict, confidence: float) -> Dict:"""验证诊断结果的安全性"""validation_result = {'is_safe': True,'requires_human_review': False,'safety_warnings': []}# 置信度检查if confidence < self.confidence_threshold:validation_result['requires_human_review'] = Truevalidation_result['safety_warnings'].append('诊断置信度较低,建议人工审核')# 高风险疾病检查disease_name = diagnosis.get('disease', '')if disease_name in self.high_risk_diseases:validation_result['requires_human_review'] = Truevalidation_result['safety_warnings'].append('涉及高风险疾病,必须医生确认')return validation_resultdef audit_treatment_recommendation(self, treatment: Dict, patient_profile: Dict) -> bool:"""审核治疗建议的合理性"""# 检查药物过敏allergies = patient_profile.get('allergies', [])treatment_name = treatment.get('treatment', '')if any(allergy in treatment_name for allergy in allergies):return False# 检查年龄适应性age = patient_profile.get('age', 0)if age < 18 and '成人用药' in treatment.get('notes', ''):return Falsereturn True4.2 伦理决策框架
"医疗AI的发展必须始终以患者福祉为中心,在技术创新与伦理责任之间找到平衡点。我们不能因为技术的便利而忽视医疗决策的严肃性和复杂性。"
class MedicalEthicsFramework:def __init__(self):self.ethical_principles = {'beneficence': '有利原则','non_maleficence': '无害原则', 'autonomy': '自主原则','justice': '公正原则'}def evaluate_ethical_compliance(self, decision: Dict) -> Dict:"""评估决策的伦理合规性"""compliance_score = 0ethical_issues = []# 有利原则检查if decision.get('expected_benefit', 0) > 0.7:compliance_score += 25else:ethical_issues.append('治疗效果不确定,可能违反有利原则')# 无害原则检查side_effects = decision.get('side_effects', [])if len(side_effects) == 0 or all(s['severity'] == 'mild' for s in side_effects):compliance_score += 25else:ethical_issues.append('存在严重副作用风险')# 自主原则检查if decision.get('patient_consent_required', True):compliance_score += 25# 公正原则检查if decision.get('accessibility_score', 0) > 0.6:compliance_score += 25return {'compliance_score': compliance_score,'ethical_issues': ethical_issues,'recommendation': 'APPROVED' if compliance_score >= 75 else 'REQUIRES_REVIEW'}5. 效果评估与持续优化
5.1 多维度评估体系
建立科学的评估体系是优化医疗AI系统的关键。
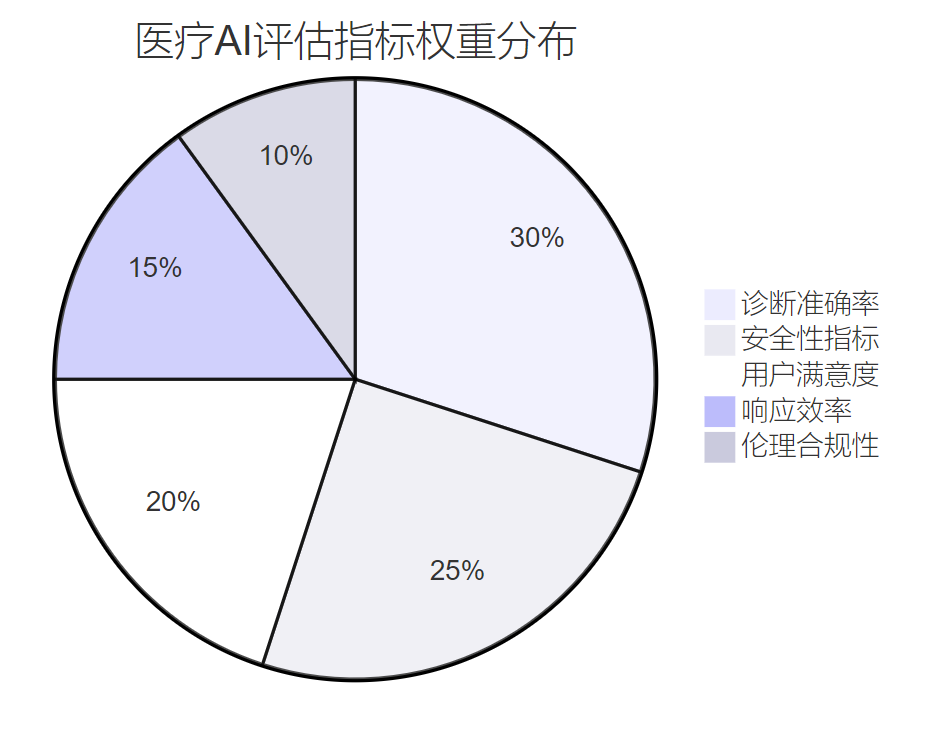
图4:医疗AI评估指标权重分布图
| 评估维度 | 核心指标 | 计算方法 | 目标值 |
| 准确性 | 诊断准确率 | 正确诊断数/总诊断数 | >85% |
| 安全性 | 误诊率 | 错误诊断数/总诊断数 | <5% |
| 效率性 | 平均响应时间 | 总响应时间/请求数 | <30秒 |
| 满意度 | 患者满意度 | 满意评价数/总评价数 | >90% |
表2:医疗AI系统评估指标体系
5.2 持续学习机制
class ContinuousLearningSystem:def __init__(self):self.feedback_buffer = []self.model_version = "1.0"self.update_threshold = 1000 # 反馈数量阈值def collect_feedback(self, case_id: str, feedback: Dict):"""收集医生和患者反馈"""feedback_entry = {'case_id': case_id,'timestamp': time.time(),'doctor_feedback': feedback.get('doctor_rating'),'patient_feedback': feedback.get('patient_rating'),'outcome': feedback.get('actual_outcome'),'corrections': feedback.get('corrections', [])}self.feedback_buffer.append(feedback_entry)# 检查是否需要模型更新if len(self.feedback_buffer) >= self.update_threshold:self._trigger_model_update()def _trigger_model_update(self):"""触发模型更新流程"""# 分析反馈数据accuracy_trend = self._analyze_accuracy_trend()if accuracy_trend < 0.85: # 准确率下降阈值print("检测到模型性能下降,启动重训练流程")self._retrain_model()# 清空缓冲区self.feedback_buffer = []def _analyze_accuracy_trend(self) -> float:"""分析准确率趋势"""correct_predictions = sum(1 for f in self.feedback_buffer if f.get('doctor_feedback', 0) >= 4)return correct_predictions / len(self.feedback_buffer)def _retrain_model(self):"""重新训练模型"""print(f"开始重训练模型,当前版本: {self.model_version}")# 实际的重训练逻辑self.model_version = f"{float(self.model_version) + 0.1:.1f}"print(f"模型更新完成,新版本: {self.model_version}")总结
通过本文的深入分析,我想和大家分享几点关于医疗健康Agent发展的思考。作为一名在这个领域深耕多年的技术从业者,我深刻认识到医疗AI不仅仅是技术问题,更是一个涉及伦理、法律、社会责任的复杂系统工程。
首先,技术架构的设计必须以安全为首要原则。我们在项目中始终坚持"安全第一,准确第二,效率第三"的原则。医疗AI系统的每一个决策都可能影响患者的生命健康,因此我们建立了多层次的安全保障机制,包括置信度阈值、人工审核、伦理评估等环节。这些看似增加了系统复杂度的设计,实际上是对患者生命的负责。
其次,多模态数据融合是提升诊断准确性的关键。在实际应用中,我们发现单纯依靠文本描述往往不够准确,需要结合生理指标、影像数据、病史信息等多维度信息。我们开发的多模态融合模型能够有效整合这些异构数据,显著提升了诊断的准确性和可靠性。特别是在处理复杂疾病时,这种综合分析能力显得尤为重要。
再次,个性化治疗方案的生成需要深度的医学知识支撑。我们构建的医学知识图谱不仅包含疾病-症状-治疗的基本关系,还考虑了患者的个体差异、药物相互作用、禁忌症等复杂因素。这使得系统能够为每个患者提供真正个性化的治疗建议,而不是千篇一律的标准方案。
最后,持续学习和优化是医疗AI系统保持先进性的必要条件。医学知识在不断更新,疾病谱在不断变化,我们的系统也必须具备持续学习的能力。通过收集医生和患者的反馈,分析治疗效果,我们能够不断优化模型性能,确保系统始终处于最佳状态。
展望未来,我相信医疗健康Agent将在更多场景中发挥重要作用,从基础的健康咨询到复杂的疾病诊断,从个人健康管理到公共卫生监测。但无论技术如何发展,我们都不能忘记医疗的本质是治病救人,技术只是手段,患者的福祉才是我们的终极目标。
参考链接
- WHO数字健康战略指南
- FDA人工智能/机器学习医疗器械监管框架
- Nature Medicine: AI在医疗诊断中的应用
- IEEE医疗AI伦理标准
- 中国医疗人工智能发展报告
🌈 我是摘星!如果这篇文章在你的技术成长路上留下了印记:
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!


)


)
html、css、js)
)






)




