第十五天
集合框架
1.什么是集合 Collections
集合Collection,也是一个数据容器,类似于数组,但是和数组是不一样的。集合是一个可变的容器,可以随时向集合中添加元素,也可以随时从集合中删除元素。另外,集合还提供了若干个用来操作集合中数据的方法。
集合里的数据,我们称之为元素(elements);集合只能用来存储引用类型的数据,不能存储八大基本**数据类型的数据**。
Java SE 5.0以前,集合的元素只要是Object类型就行,那个时候任何对象都可以存放在集合内,但是从集合中获取对象后,需要进行正确的强制类型转换。但是,Java SE 5.0 以后,可以使用新特性”泛型”,用来指定要存放在集合中的对象类型。避免了强制转换的麻烦。
2.集合与数组
数组是定长的容器,一旦实例化完成,长度不能改变。集合是变长的,可以随时的进行增删操作。
数组中可以存储基本数据类型和引用数据类型的元素,集合中只能存储引用数据类型的元素。
数组的操作比较单一,只能通过下标进行访问。集合中提供了若干个方便对元素进行操作的方法。
3.集合框架体系图
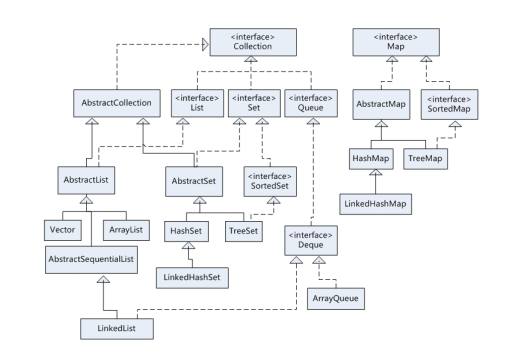
父接口Collection
Collection 接口是 List、Set 和 Queue 接口的父接口,该接口里定义了他们三个子接口的共同方法。既可用于操作 Set 集合,也可用于操作 List 和 Queue 集合。作为父接口,其子类集合的对象,存储元素的特点,可能是无序的,也可能是有序的,因此在父接口中并没有定义通过下标获取元素的方法功能。
// 1、实例化一个 ArrayList 对象,并向上转型为 Collection 类型。
// 向上转型后的对象,只能访问父类或者接口中的成员
// 在这里,collection 将只能够访问 Collection 接口中的成员。
Collection<String> collection = new ArrayList<>();
// 2、向集合中添加元素
collection.add("lily");
collection.add("lucy");
collection.add("Uncle wang");
collection.add("Polly");
// 3、向集合中批量的添加元素(将一个集合中的元素依次添加到这个集合中)
collection.addAll(collection);
// 4、删除从前往后第一个匹配的元素
collection.remove("lily");
// 5、准备另外一个集合
Collection<String> list = new ArrayList<>();
list.add("Han Meimei");
list.add("Li Lei");
list.add("Uncle wang");
list.add("Polly");
// 6、删除所有的在另外一个集合中存在的元素
// 删除逻辑:遍历集合,将每一个元素带入到参数集合中判断是否存在,如果存在,就删除这个元素。
//删除的是list中的集合元素
collection.removeAll(list);
// 7、删除所有的满足条件的元素
// 删除逻辑:遍历集合,将每一个元素带入到参数方法中,如果返回值是true,需要删除这个元素。
collection.removeIf(ele -> ele.startsWith("lu"));
// 8、清空所有
collection.clear();
// 9、保留在另外一个集合中存在的元素
// 逻辑:遍历集合,将每一个元素带入到参数集合中,判断是否存在,如果存在则保留这个元素,如果 不存在,删除
collection.retainAll(list);
// 10、判断集合中是否包含指定的元素
boolean ret = collection.contains("Uncle wang");
System.out.println(ret);
// 11、判断参数集合中的每一个元素是否都在当前集合中包含
boolean ret1 = collection.containsAll(list);
System.out.println(ret1);
// 12、判断两个集合是否相同(依次比较两个集合中的每一个元素,判断是否完全相同)
// 只有当两个集合中的元素数量、元素一一对应
boolean ret2 = collection.equals(list);
System.out.println(ret2);
// 13、判断一个集合是否为空
boolean ret3 = collection.isEmpty();
System.out.println(ret3);
// 14、获取一个集合中元素的数量,类似于数组长度
int size = collection.size();
System.out.println(size);
// 15、转成 Object 数组
Object[] array = collection.toArray();
System.out.println(Arrays.toString(array));
// 16、转成指定类型的数组
String[] arr = collection.toArray(new String[0]);
System.out.println(Arrays.toString(arr));
System.out.println(collection);
1.集合的迭代
在进行集合的遍历的时候,方式其实很多。但是,基本上所有的遍历,都与 Iterable 接口有关。这个接 口提供了对集合进行迭代的方法。只有实现了这个接口,才可以使用增强for循环进行遍历。
1)增强for循环
for (String ele : collection) {System.out.println(ele);
}
注意事项:
增强for循环中不允许对集合中的元素进行修改,修改是无效的
增强for循环中不允许对集合的长度进行修改,否则会出现 ConcurrentModificationException
2)迭代器
迭代器Iterator,是一个接口, Collection集合中有一个方法 iterator() 可以获取这个接口的实现类 对象。在这个迭代器中,维护了一个引用,指向集合中的某一个元素。默认指向一个集合前不存在的元 素,可以认为是下标为-1的元素。
迭代器的工作原理:循环调用 next() 方法进行向后的元素指向,并返回新的指向的元素。同时,在向 后进行遍历的过程中,使用 hasNext() 判断是否还有下一个元素可以迭代。
在迭代器使用的过程中,需要注意:
不应该对集合中的元素进行修改
不应该对集合的长度进行修改
如果非要修改,需要使用迭代器的方法,不能使用的集合的方法。
// 1、获取迭代器对象,这里的 iterator 是一个 Iterator 接口的实现类对象
Iterator<String> iterator = collection.iterator();
// 2、使用迭代器进行集合的遍历
while (iterator.hasNext()) {// 让迭代器向后指向一位,并返回这一位的元素String element = iterator.next();System.out.println(element);
}
子接口List
List 是一个元素有序、且可重复的集合,集合中的每个元素都有其对应的顺序索引,从0开始
List 允许使用重复元素,可以通过索引来访问指定位置的集合元素。
List 默认按元素的添加顺序设置元素的索引。
List 集合里添加了一些根据索引来操作集合元素的方法
1.ArrayList和LinkedList的区别
ArrayList是一个可变大小组,初始容量为10,当数组满时,容量扩大1.5倍。新建一个更大的数组,将老数组复制到新数组上。他在查找元素更高效,因为数组是由一块连续区域的内存实现,可以通过地址索引计算出值的位置。而当删除或新增一个元素时,其他元素都要移动。
LinkedList是一个双向链表,不考虑内存大小,原则上是可以无限大的,链表由不连续内存实现,链表中的每个节点都包含了前一个和后一个节点的引用,所以他在新增上是高效的。当查找时,它需要通过一个以知元素向下遍历才能找到要找到的值,
2.ArrayList线程安全吗?想要线程安全怎么办?
非线程安全的
使用Collections.synchronizedList方法可以得到一个线程安全的List,但在ArrayList的所有公共方法上加锁
使用CopyOnWriteArrayList或手动加锁
3.CopyOnWriteArrayList怎么保证线程安全?它的优点和缺点呢?
读不加锁,写加锁
优点:
- 读高效
- 线程安全
- 高并发性
缺点:
- 写性能低
- 内存占用高
- 不适合实时性要求高的场景
4.数组和链表的区别
数组每个元素都是连续的,通过下标进行访问
链表中的元素不连续的,必须获得某个元素后,才能访问后续元素
数组可以由一块连续区域的内存实现,数组从申请之后就会固定
链表可以由不连续内存实现,内存足够时可以任意申请空间
数组:查询O(1),插入/删除O(n)
链表:查询O(n),插入/删除O(1)
5.常用方法
1)添加元素
boolean add(E e)
作用:向列表末尾添加指定的元素
void add(int index, E element)
作用:在列表的指定位置添加元素
boolean addAll(Collection c)
作用:将集合c中的所有元素添加到列表的结尾
boolean addAll(int index, Collection c)
作用::将集合c中的所有元素添加到列表的指定位置
2)获取元素
E get(int index)
作用:返回列表指定位置的元素
3)查找元素
int indexOf(Object obj)
作用:返回列表中指定元素第一次出现的位置,如果没有该元素,返回-1
int lastIndexOf(Object obj)
作用:返回列表中指定元素最后一次出现的位置,如果没有该元素,返回-1
4)移除元素
E remove(int index)
作用:移除集合中指定位置的元素,返回被移除掉的元素对象
5)修改元素
E set(int index, E element)
作用:用指定元素替换指定位置上的元素,返回被替换出来的元素对象
6)截取子集
List subList(int fromIndex, int toIndex)
作用:截取子集,返回集合中指定的fromIndex 到 toIndex之间部分视图,包前不包后
7)案例演示
// 1、实例化一个 List 接口的实现类对象,并向上转型为接口类型 List<Integer> list = new ArrayList<>(); // 2、增 list.add(10); list.add(20); // 3、在指定的位置插入元素 list.add(1, 15); // 4、删除元素 list.remove(Integer.valueOf(15)); // 5、按照下标删除元素 list.remove(0); // 6、通过下标设置元素 list.set(0, 200); // 7、通过下标获取元素 Integer element = list.get(0); // 8、获取某一个元素出现的下标 int index = list.indexOf(200); // 9、获取某一个元素最后一次出现的下标 int index = list.lastIndexOf(200); System.out.println(element);
6.ListIterator
ListIterator是Iterator接口的子接口,继承到了Iterator中所有的方法,同时自己也添加了若干个方法。 允许使用ListIterator在进行元素迭代的时候,对集合中的数据进行修改,或者对集合的长度进行修改。 同时,使用ListIterator还可以进行倒序的迭代。
// 3、在迭代的过程中,修改集合
while (iterator.hasNext()) {// 向后指向一位,并返回当前指向的元素String ele = iterator.next();if (ele.equals("Vertu")) {// 在迭代的过程中,删除这个元素iterator.remove();// 在迭代的过程中,添加一个元素(加在当前迭代的这个元素的后面)iterator.add("HTC");// 在迭代的过程中,对当前迭代的元素进行修改iterator.set("Nokia");}
}
//倒叙
ArrayList<String> objects2 = new ArrayList<>();objects2.add("lily");objects2.add("lucy");objects2.add("Uncle wang");objects2.add("Polly");ListIterator<String> iterator = objects2.listIterator();
// ListIterator<String> iterator = objects2.listIterator(4); //不写值,不正序就不会找到while (iterator.hasNext()){Object next = iterator.next();System.out.println(next+" ");}while (iterator.hasPrevious()){Object previous = iterator.previous();System.out.println(previous+" ");System.out.println(1);}
子接口Set
Set集合中的元素是无序的(取出或者打印的顺序与存入的顺序无关)
Set集合中的元素不能重复
底层实现是hashmap
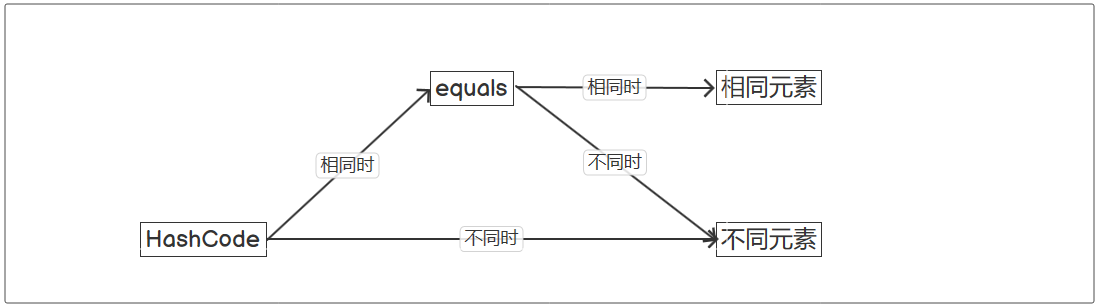
1.HashSet
HashSet 具有以下特点:
不能保证元素的排列顺序
HashSet 不是线程安全的
集合元素可以是 null
2.LinkedHashSet
LinkedHashSet 是 HashSet 的子类
LinkedHashSet 集合根据元素的 hashCode 值来决定元素的存储位置,但它同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的。
LinkedHashSet 性能插入性能略低于 HashSet,但在迭代访问 Set 里的全部元素时有很好的性能。
LinkedHashSet 不允许集合元素重复。
3.TreeSet
TreeSet 是 SortedSet 接口的实现类, TreeSet集合是用来对元素进行排序的,同样他也可以保证元素的唯一。TreeSet 可以确保集合元素处于排序状态。
TreeSet 支持两种排序方法:自然排序和定制排序。默认情况下,TreeSet 采用自然排序。
必须实现Comparable,否则会报Exception in thread "main" java.lang.ClassCastException: com.youcai.day10._01.teacher cannot be cast to java.lang.Comparable
4.set去重
子接口Queue
队列Queue也是Collection的一个子接口,它也是常用的数据结构,可以将队列看成特殊的线性表,队列限制对线性表的访问方式:只能从一端添加(offer)元素,从另一端取出(poll)元素。
队列遵循先进先出(FIFO first Input First Output)的原则
实现类LinkedList也实现了该接口,选择此类实现Queue的原因在于Queue经常要进行添加和删除操作,而LinkedList在这方面效率比较高。
其主要方法如下:
方法 解析 boolean offer(E e) 作用:将一个对象添加到队尾,如果添加成功返回true E poll() 作用:从队首删除并返回这个元素 E peek() 作用:查看队首的元素
public void testQueue(){Queue<String> queue = new LinkedList<>();queue.offer("a");queue.offer("b");queue.offer("c");System.out.println(queue); // [a,b,c]String str = queue.peek();System.out.println(str); // awhile(queue.size() > 0){str = queue.poll();System.out.println(str+" "); // a b c}
}
子接口Deque
Deque是Queue的子接口,定义了所谓的”双端队列”,即从队列的两端分别可以入队(offer)和出队(poll)。同样,LinkedList实现了该接口
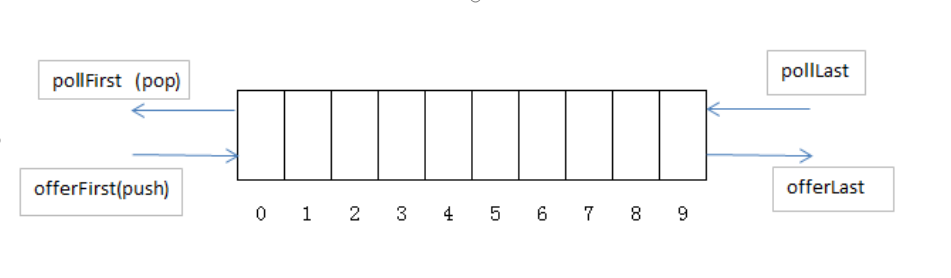
如果将Deque限制为只能一端入队和出队,则可以实现“栈”(Stack)的数据结构,对于栈而言,入栈被称为push,出栈被称为pop。遵循先进后(FILO)出原则
public void testDeque(){Deque<String> stack = new LinkedList<>();stack.push("a");stack.push("b");stack.push("c");System.out.println(push); // [c,b,a]String str = queue.peek();System.out.println(str); // cwhile(stack.size() > 0){str = stack.pop();System.out.println(str+" "); // c b a}
}
父接口Map
Map是集合框架中的另一个父接口,它用来保存具有映射(一对一)关系的数据,这样的数据称之为键值对(Key-Value-Pair)。key可以看成是value的索引。特点如下:
key和value必须是引用类型的数据
作为key,在Map集合中不允许重复,Value可以重复
key可以为null
key和value之间存在单向一对一关系,通过指定的key总能找到唯一,确定的value
1.常用方法
/ 1、实例化一个 Map 接口的实现类的对象,并向上转型为 Map 接口类型
Map<String, String> map = new HashMap<>();
// 2、增,向集合中添加一个键值对
map.put("name", "xiaoming");
map.put("age", "12");
map.put("gender", "male");
// 3、增,如果增的这个键在Map中已经存在,此时会用新的值覆盖原来的值
map.put("age", "20");
// 4、增,当这个键不存在的时候,才会增 ; 如果存在,这个方法没有任何效果
map.putIfAbsent("age", "30");
// 5、增,从一个Map集合中添加键值对,如果两个Map中存在相同的键,则会用新值覆盖原来的值
Map<String, String> tmp = new HashMap<>();
tmp.put("name", "xiaobai");
tmp.put("java", "89");
tmp.put("mysql", "78");
map.putAll(tmp);
System.out.println(map);
// 6、删,按照键删除键值对
map.remove("age");
System.out.println(map);
// 7、删,删除指定的键值对,只有当键和值都能够匹配上的时候,才会删除
map.remove("name", "xiaobai");
// 8、删,清空所有的键值对
map.clear();
// 9、改,通过键,修改值
map.replace("gender", "female");
System.out.println(map);
// 10、改,只有当键和值都能够匹配上,才会修改值
map.replace("gender", "female", "Unknown");
System.out.println(map);
// 11、 /*
V apply(K key, V oldValue):
将Map集合中的每一个键值对都带入到这个方法中,用返回值替换原来的值 */
// 需求 : 将现在所有的成绩后面添加上"分 "
map.replaceAll((k, v) -> {
if (k.matches("java|scala|linux|mysql|hadoop")) { return v + "分 ";
}
return v;
});
System.out.println(map);
// 12、查询(通过键,查询值)(如果不存在这个键,则结果是 null)
String value = map.get("java1");
System.out.println(value);
// 13、查询(通过键查询值,如果不存在这个键,会返回默认的值)
String value2 = map.getOrDefault("java1", "0");
System.out.println(value2);
// 1、判断集合中是否包含指定的键
map.containsKey("java");
// 2、判断集合中是否包含指定的值
map.containsValue(98);
// 3、获取集合中元素的数量(键值对的数量)
map.size();
// 4、判断集合是否是一个空集合
map.isEmpty();
// 5、获取所有的值
Collection<Integer> values = map.values();
2.Map遍历
Map提供了三种遍历方式
1)遍历所有的key
Set<K> keySet();
该方法会将当前Map中的所有key存入一个Set集合后返回
2)遍历所有的key-value
Set<Entry<K,V>> entrySet()Map<Object, Object> objectObjectMap = new HashMap<>();
objectObjectMap.put("1", "1");
objectObjectMap.put("2", "2");
objectObjectMap.put("3", "3");
Set<Map.Entry<Object, Object>> entries = objectObjectMap.entrySet();
for (Map.Entry<Object, Object> s: entries){System.out.println(s.getKey()+"--"+s.getValue());
}该方法会将当前Map中的每一组key-value封装成Entry对象存入Set集合后返回
3)遍历所有的value(不常用)
Collection<V> values
3.hashMap实现原理
在1.8之前是用链表加数组实现的,并使用头插法插入元素,在1.8之后使用数组链表红黑树实现的,当数组大于64,链表大于8,链表会转成红黑树,为了解决头插法产生的死循环,改为尾插法。hashMap是通过hash方法找到对应的存储位置。如果hash值相同,key值相同覆盖,不同会将数组插入链表或红黑树,Hashmap的初始值是17加载因子是0.75,所以当已将使用12个空间时,会扩大2倍,并且已有的数据会根据新的长度计算出对应的位置。HashMap是线程不安全的,会发生数据覆盖,size不准确,数据不一致问题。线程安全替代类:ConcurrentHashMap。
4.红黑树介绍
一种自平衡的二叉搜索树:
- 节点红或黑
- 根节点黑色
- 每个叶子节点黑色
- 如果一个节点是红色,则它的子节点必须是黑色
- 从任一节点到其每个子节点的所有路径会有相同数目的黑色节点
- 通过变色和旋转保持平衡
5.HashMap与HashTable、ConcurrentHashMap
Hashtable线程安全通过方法使用synchronized关键字进行同步,保证了多线程的并发安全性。由于方法的同步锁机制,性能低于HashMap。不允许null键和null值,插入null键值会抛出NullPointerException
HashMap:非线程安全的,没有线程同步机制。单线程性能高于Hashtable,允许一个null键和多个null值
ConcurrentHashMap底层由数组+链表+红黑树组成,是线程安全的,使用了分段锁技术,将哈希表分成很多段,每个段有独立的锁。多个线程同时访问,只需锁住操作的那个段而不是整个表,提高并发性能。在JDK1.8后采用CAS+synchronized保证线程安全,锁粒度更细,从段锁到桶锁,添加元素时判断某个桶是否为空,空使用CAS添加,不空使用synchronized。key和value都不允许null。
6.HashMap的hash方法是如何实现的?
hash方法的功能是根据Key来定位这个K-V在链表数组中的位置的。也就是hash方法的输入应该是个Object类型的Key,输出应该是个int类型的数组下标。最简单的话,我们只要调用Object对象的hashCode()方法,该方法会返回一个整数,然后用这个数对HashMap或者HashTable的容量进行取模就行了。
在这里面,HashMap的hash方法为了提升效率,主要用到了以下技术手段:
使用位运算(&)来代替取模运算(%),因为位运算(&)效率要比代替取模运算(%)高很多,主要原因是位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快。
对hashcode进行扰动计算,防止不同hashCode的高位不同但低位相同导致的hash冲突。简单点说,就是为了把高位的特征和低位的特征组合起来,降低哈希冲突的概率,也就是说,尽量做到任何一位的变化都能对最终得到的结果产生影响。
7.hash冲突通常怎么解决?
1.开放定址法 开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。这种方法的缺点是可能导致“聚集”问题,降低哈希表的性能。 2.链地址法 最常用的解决哈希冲突的方法之一。每个哈希桶(bucket)指向一个链表。当发生冲突时,新的元素将被添加到这个链表的末尾。在Java中,HashMap就是通过这种方式来解决哈希冲突的。Java 8之前,HashMap使用链表来实现;从Java 8开始,当链表长度超过一定阈值时,链表会转换为红黑树,以提高搜索效率。 3.再哈希法 当哈希地址发生冲突用其他的函数计算另一个哈希函数地址,直到冲突不再产生为止。这种方法需要额外的计算,但可以有效降低冲突率。 4.建立公共溢出区 将哈希表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表中。 5.一致性hash 主要用于分布式系统中,如分布式缓存。它通过将数据均匀分布到多个节点上来减少冲突。
8.LinkedHashMap
LinkedHashMap 是 HashMap 的子类
LinkedHashMap 可以维护 Map 的迭代顺序:迭代顺序与 Key-Value 对的插入顺序一致
9.TreeMap
TreeMap 存储 Key-Value对时,需要根据 Key 对 key-value 对进行排序。TreeMap 可以保证所有的 Key-Value 对处于有序状态。
注意:TreeMap里的key,是使用comparaTo来确定是否唯一的,而不是调用HashCode和equals的
TreeMap 的 Key 的排序:
自然排序:TreeMap 的所有的 Key 必须实现 Comparable 接口,而且所有的 Key 应该是同一个类的对象,否则将会抛出 ClassCastException
定制排序:创建 TreeMap 时,传入一个 Comparator 对象,该对象负责对 TreeMap 中的所有 key 进行排序。此时不需要 Map 的 Key 实现 Comparable 接口
10.Properties
Properties 类是 Hashtable 的子类,该对象用于处理属性文件
由于属性文件里的 key、value 都是字符串类型,所以 properties 里的 Key 和 Value 都是字符串类型的
Collections
Collections 是一个操作 Set、List 和 Map 等集合的工具类,提供了大量方法对集合元素进行排序、查询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法
1)排序操作
reverse(List):反转 List 中元素的顺序
shuffle(List):对 List 集合元素进行随机排序
sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
2)查找、替换
Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
Object min(Collection)
Object min(Collection,Comparator)
int frequency(Collection,Object):返回指定集合中指定元素的出现次数
boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值


![[css]旋转流光效果](http://pic.xiahunao.cn/[css]旋转流光效果)







)








