一、ORCA
1.1 ORCA 概览
看下Continuous Batching 技术的开山之作ORCA,这个其实是融合的思路。
ORCA:把调度粒度从请求级别调整为迭代级别,并结合选择性批处理(selective batching)来进行优化。
Sarathi[2] :利用Chunked Prefill策略通过将不同长度的prompts拆分成长度一致的chunks来进行prefill,同时利用这些chunks间隙进行decode 操作。
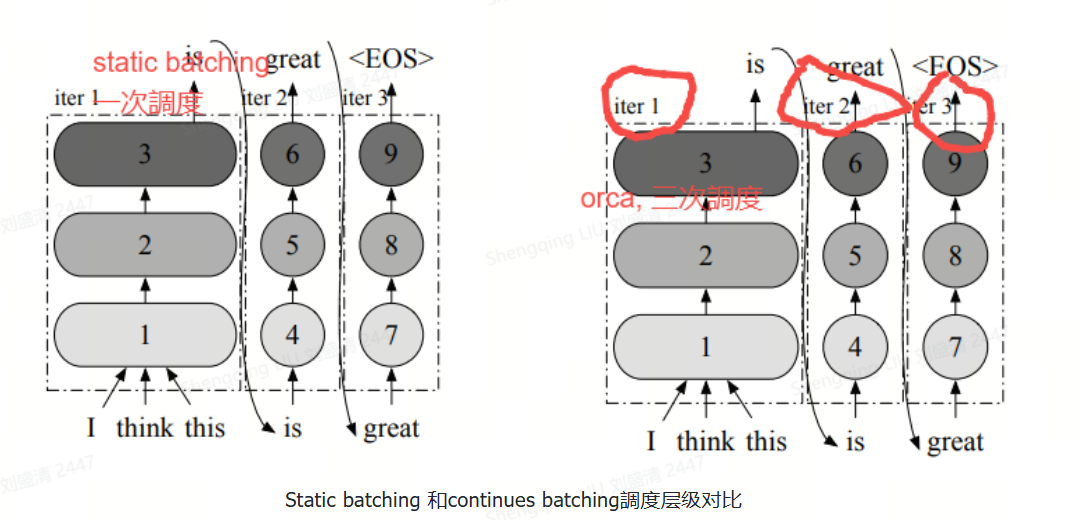
目前业界把依据ORCA思想实现的方案叫做Continuous Batching(连续批处理)。连续批处理是一种优化技术,它允许在生成过程中动态地调整批处理的大小。具体来说,一旦一个序列在批处理中完成生成,就可以立即用新的序列替代它,从而提高了GPU的利用率。这种方法的关键在于实时地适应当前的生成状态,而不是等待整个批次的序列都完成。
与静态批处理不同,连续批处理采用了迭代级别的调度。它并不等待每个序列在批次中完成生成后再进行下一个序列的处理。相反,调度程序在每个迭代中根据需要确定批次的大小。这意味着在每次迭代之前,调度程序检查所有请求的状态。一旦某个序列在批次中完成生成,就可以立即将一个新的序列插入到相同位置,同时删除已完成的请求。
1.2 ORCA 具体实现说明
针对如何处理“提前完成和延迟加入的请求”这个挑战,ORCA给出的解决方案是用迭代级调度减少空闲时间,即以迭代为粒度(iteration-level)控制执行,而不是请求级粒度(request-level),并结合选择性批处理(selective batching)来进行优化。
迭代级调度的目标是:及时检测出推理完毕的请求,将其从batch中移出,以便新请求可以填补到旧请求的位置上,这样新请求和旧请求能接连不断组成新的batch。
整体调度策略:
Orca是第一篇提到迭代级别调度(Iteration-Level Schedule)的论文。具体来说就是:一个batch中的所有请求每做完1次iteration(prefill或者decode),scheduler就和engine交互一次,去检查batch中是否有做完推理的请求,以此决定是否要更新batch。这样就可以在每次GPU推理的空隙,可以插入调度操作,实现Batch样本的增删和显存的动态分配释放。
下图给出了请求粒度的调度和迭代粒度调度的区别。前者需在整批请求全部完成前对调度批次进行多次迭代,而对于ORCA,服务系统在调度任务时,每次只向 Execution Engine 提交一次迭代的计算,而非等到完成整个 Request才能处理。这样 ORCA 就可以在每个迭代都动态更改要处理的请求,新请求只需等待单次迭代即可被处理,从而避免early-finish的请求等待其他请求的结束。通过迭代级调度,调度器能够完全控制每个迭代中处理哪些请求以及处理数量。
ORCA的系统框架图
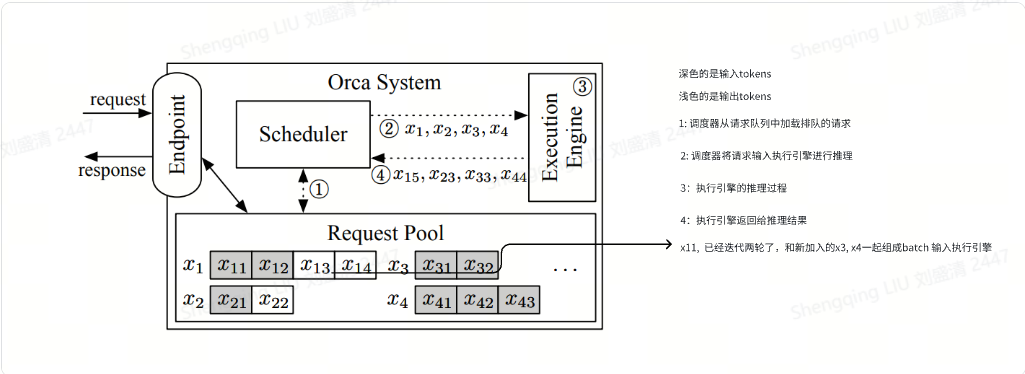
上图展示了采用迭代级调度的ORCA系统架构和整体工作流程。ORCA系统包括如下模块:
Endpoint(端点)。用于接收推理请求并发送响应。
Request Pool(请求池)。新到达的请求被放入请求池中,该组件负责管理系统中所有请求的生命周期。
Scheduler(调度器)。调度器监控请求池,负责以下任务:从池中选择一组请求,调度执行引擎对这些请求执行模型迭代;接收执行引擎返回的执行结果(即输出token),并将每个输出token追加到对应请求中来更新请求池。
Execution Engine(执行引擎)。执行引擎是执行实际张量操作的抽象层,可在跨多个机器分布的多个GPU上并行化。
我们接下来看看下图中的工作流程,其中,虚线表示组件之间的交互,交互发生在执行引擎的每次迭代中。xij是第i个请求的第j个token。阴影token表示从客户端接收到的输入token,而非阴影token由ORCA生成。例如,请求x1最初带有两个输入标记(x11,x12),到目前为止已经运行了两次迭代,其中第一次和第二次迭代分别生成了x13和x14。另一方面,请求x3只包含输入标记x31,x32,请求x4包括x41,x42,x43,因为它们还没有运行任何迭代。
工作流程分为如下几步:
调度器与请求池交互,以决定下一步运行哪些请求。对应下图标号➀。
调度器调用引擎为所选定的四个请求(x1,x2,x3,x4)执行一次迭代。此时,因为x3和x4还没有运行任何迭代,因此调度器为x3移交x31,x32给执行引擎,为x4移交x41,x42,x43给执行引擎。对应下图标号➁。
引擎对四个请求运行模型迭代,对应下图标号➂。
引擎把生成的输出token(x15, x23, x33, x44)返回给调度器,对应下图标号➃。调度器在每次引擎返回,接收该迭代的执行结果之后会检查请求是否完成。如果请求完成,请求池就会删除已完成的请求,并通知端点发送响应,返回给客户端。
对于新到达的请求,在当前迭代执行完毕后,它有机会开始处理(即调度器可能选择新请求作为下一个执行对象)。因为新到达的请求只需等待一次迭代,从而显著减少了排队延迟。
ORCA对于中止请求(Canceled Requests)并没有进行处理,实际上应该把这些请求会被及时从Batch中剔除并释放相应显存
ORCA的请求调度算法
下图详细描述如何在每次迭代中选择请求的算法。
n_scheduled: micro-batch(微批)
micro-batch(微批) 是将一个完整的 batch 拆分成多个更小的子批次,用于提升硬件资源利用率,尤其在流水线并行(Pipeline Parallelism) 中非常常见。
当大模型被划分为多个阶段并分布在不同 GPU 上时,如果直接处理整个 batch,会导致部分 GPU 处于空闲等待状态。为了解决这个问题,我们将 batch 拆分成多个 micro-batch,并让它们像“流水线”一样在各阶段依次推进。这样,每个阶段的 GPU 都可以同时处理不同的 micro-batch,大幅提高并行度和吞吐量,减少资源浪费。
举个例子,如果一个 batch 有 64 个样本,可以被拆成 8 个 micro-batch,每个包含 8 个样本,在模型各阶段中交错处理,从而避免 GPU 空转,提高执行效率。每个阶段表示模型中一部分连续的层,由一个 GPU 负责计算。例如,在一个 12 层的 Transformer 模型中,若使用 4 个 GPU,则每个阶段可能包含 3 层。

核心功能实现:
实现了动态的选择新的序列构成batch,实现了continuous batching
实现了将已经推理结束的序列删除和资源释放。
此算法中对KV Cache释放时机控制得不是很理想。在请求生成结束时就立即释放其K/V Cache。在多轮对话场景中,这个机制会导致冗余计算,即“上一轮对话生成K/V Cache → 释放K/V Cache显存 → 通过本轮对话的Prompt生成 之前的K/V Cache”。这样会恶化后续几轮对话的First Token Time(产生第一个Token的时延)指标。
1.3 selective batching
核心作用
Selective Batching将注意力计算从 Batching 中解耦。即为了提高计算效率,需要想办法让引擎能够以批处理方式处理任何选定的请求集。
问题分析
在前面分析中,我们其实做了一个简化的假设,即所有请求序列具有相同的长度。这是因为GPU的特殊性,如果想批量执行多个请求,每个请求的执行应该包含相同的操作,且消耗形状相同的输入张量。然而,在现实中,请求序列的长度是不同的。诚然Padding+Masking的方法可以解决,但严重浪费算力和显存,对于算力和显存均有限的推理GPU是不利的。
当使用迭代级别调度时,上述挑战会愈发加剧。因为:
请求池中的请求可能具有不同的特征。
prefill和decode的计算方式不同。
prefill过程是长序列并行计算的,decode过程是token by token的。
prefill过程不需要读取KV cache,decode过程需要读取KV cache。
对于prefill,各个请求的prompt长度是不一致的。
对于decode,不同请求的decode token的index不一样,意味着它们计算attention的mask矩阵也不一样。
迭代级调度方法可能导致同一个批处理中的不同请求的处理进度不一样,即输入张量的形状会因为已处理的token数量不同而不一致。
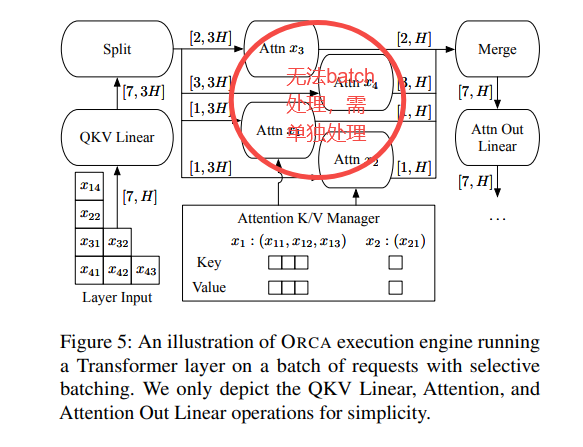
我们用上面架构图作为例子来进行分析,来看看即使对于一对请求(xi,xj),也不能保证它们的下一次迭代可以合并、替换为批处理版本。有三种情况导致请求对不能合并批处理:
两个请求都处于初始化阶段,但输入token数量不同(如下图中的x3和x4)或者说输入张量的“长度”维度不相等,因此无法将两个请求进行批处理。
两个请求都处于增量阶段,但各自处理的token索引不同(如x1和x2)。由于每个请求处理的token索引不同,导致注意力键和值的张量形状不同,因此也不能合并批处理。
请求处于不同阶段:有的处于初始化阶段,有的处于增量阶段(如x1和x3)。由于不同阶段的迭代输入token数量不同(初始化阶段迭代并行处理所有输入token以提高效率,而增量阶段每次迭代仅处理一个token),因此无法合并批处理。
上述关于批处理的主要问题在于,前述三种情况对应于形状不规则的输入(或状态)张量,这些张量无法合并成一个大的张量并输入到批处理操作中。因此,并非所有的请求都能在任意Iteration被Batching到一起。仅当两个选定请求处于同一阶段,且(在初始化阶段)具有相同数量的输入token或(在增量阶段)具有相同的token索引时,批处理才适用。这一限制大大降低了在实际工作负载中执行批处理的可能性,因为调度器需要同时找到两个符合批处理条件的请求。
问题解决
解决这些问题的一个好思路是:尽量找到这些请求计算时的共同之处,使得计算能最大化合并。对于有差异的部分再单独处理。我们先以一个transformer decode block为例,回顾一下序列要经过哪些计算。下图是decoder block的各种计算类型。可以看到,Transformer decoder block 在计算上可以看做六个操作的总和:pre-proj,attn,post-proj,ffn_ln1,ffn_ln2,others(比如 layer normalization,activation functions,residual connection)。Transformer 输出一个形状为 [B, L, H] 的张量。其中 B 是 batch size,L 是 input tokens length,H 是模型的 embedding size。每个 token 的 KV Cache 大小均为 [1, H]。
论文SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills对transform 模块进行了分析。
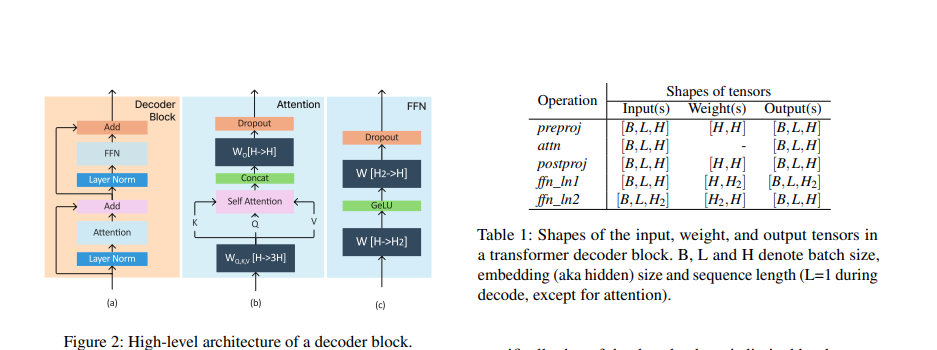
我们把上面的介绍稍作提炼,得到如下重要信息:Transformer 层中的操作可以分为两种类型: Attention 和 non-Attention,这两种模块的算子特点不同。
preproj/postproj/FFN1/FFN2:这几个模块中主要是Add、Linear、GeLU等算子,这些算子的特点是:不需要区分 token 来自于哪个请求。因此,虽然它们是
token-wise的,但可以使用批处理实现。和输入序列长度无关。这意味着我们可以把一个batch中所有的tokens都展平成一行进行计算(维护好各自的位置向量就好, 便于从结果中取出对应的值),这样不同长度的输入也可以组成batch,从而进行计算。例如,上述x3和x4的输入张量可以组合成一个二维张量[ΣL,H] = [5,H],而不需要明确的批处理维度。
需要从显存读取模型权重。读取模型权重意味着我们应该尽量增大batch size,使得一次读取能就可以造福更多请求,以此减少IO次数。
attention: 该模块的特点是:
由于计算受各个序列的差异性影响(例如不同序列的mask矩阵不同、是否需要读取KV cache),因此需要将序列拆分开独立处理,即batch维度是重要的。
对于注意力操作, 无论是
token-wise还是request-wise的 batching 都无法执行。不对Attention层进行批处理对效率的影响较小,因为Attention层的操作不涉及到模型参数的重复使用,无法通过批处理来减少GPU内存读取。
方案
总结上述思路:Transformer Layer里,并非所有的算子都要求组成批次的输入具有相同的形状。基于上述思路,Orca 提出了第二点核心技术: Selective batching(选择性批处理),它不是对构成模型的所有张量操作(注意力和非注意力)都进行批处理, 而是有选择地将批处理仅应用于少数非注意力操作,即对于不同类型的请求应用于不同类型的操作来解决问题,具体如下:
单独处理每个注意力操作。即对于必须有相同Shape才能Batching的算子(例如Attention)会对不同的输入进行单独的计算。
对其他层(例如MLP层)则进行批处理。
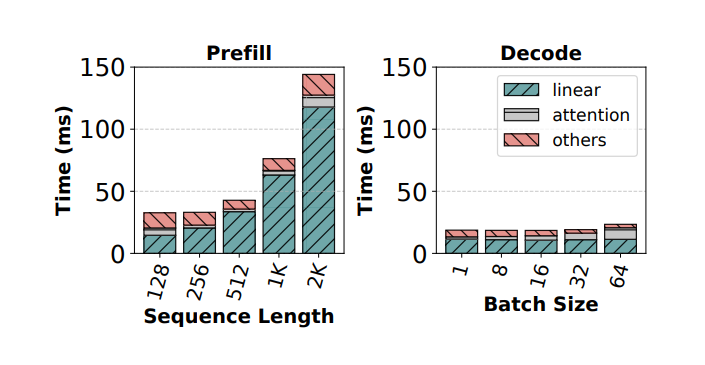
图片来源:Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
二、引用文献
[1] Orca: A distributed serving system for transformer-based generative models https://www.usenix.org/system/files/osdi22-yu.pdf
[2] SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills https://arxiv.org/pdf/2308.16369
[3] DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference https://arxiv.org/pdf/2401.08671
[4] Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
https://arxiv.org/pdf/2403.02310
[5] Splitwise: Efficient generative LLM inference using phase splitting
https://arxiv.org/abs/2311.18677
[6] DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
https://arxiv.org/abs/2401.09670
[7] https://zhuanlan.zhihu.com/p/1928005367754884226
CA1区域(dCA1)的时空联合细胞对NLP中的深层语义分析的积极影响和启示)
)
问题解决方法)


安装 docker + ollama+ deepseek-r1:7b + Open WebUI(内含一键安装脚本))

和ArrayList<>()的区别)











