文章目录
- 一、引言:搜索引擎为啥越来越慢?
- 1.1 典型业务场景
- 性能瓶颈表现:
- 二、倒排索引压缩:让存储与检索更高效
- 🧠 2.1倒排索引结构简述
- 🔧 2.2 压缩算法三剑客
- ✅ 调优建议
- 三、分片策略:写入性能的生命线
- ⚠️3.1 分片数量黄金法则
- 🔍3.2 分片写入瓶颈
- ✅ 3.3 分片动态调整
- 四、深度分页:性能黑洞解决方案
- 🚨4.1 From/Size 的性能灾难
- 🧭 4.2 高性能替代方案
- 🔁方案一:Search After(实时分页)
- 🔁方案二:PIT(Point In Time)
- 方案对比
- 五、相关性算分:从理论到业务定制
- 🔍5.1 BM25 算法原理
- 🎯业务相关性优化
- 1. 字段加权:
- 2. 结合业务数据:
- 六、脑裂防护:集群高可用保障
- 😱6.1 脑裂成因与影响
- 🛡️6.2 防脑裂配置
- ✅6.3 节点部署最佳实践
- 七、总结与调优建议清单 ✅
- 🔧7.1 性能调优清单
- 🗂️7.2 冷热集群架构
- 🖼️7.3 紧急故障处理
- 八、技术附录
- 🧨8.1 Java 客户端配置
- 🛠8.2 索引生命周期管理
一、引言:搜索引擎为啥越来越慢?
在电商平台的商品检索系统中,随着商品数量的增长、筛选条件变多、排序逻辑变复杂,搜索响应变得越来越慢:
用户搜索「运动鞋」带上多个筛选条件(品牌、尺码、价格、评分等);
排序字段组合复杂(销量 + 综合评分 + 时间);
用户经常点击下一页,导致深度分页调用。
高并发 + 多字段组合查询 + 分页 + 相关性评分,使 Elasticsearch 性能面临瓶颈。本文将从原理与实战双维度,深入解析核心性能优化策略。
1.1 典型业务场景

性能瓶颈表现:
- 响应时间从 50ms → 3000ms+
- 分页越深越慢
- 写入速度随数据量增加而下降
- 节点负载不均(热节点 CPU 100%)
数据统计:超过深度分页请求数(from>1000)的查询,98% 最终被用户放弃!
二、倒排索引压缩:让存储与检索更高效
🧠 2.1倒排索引结构简述
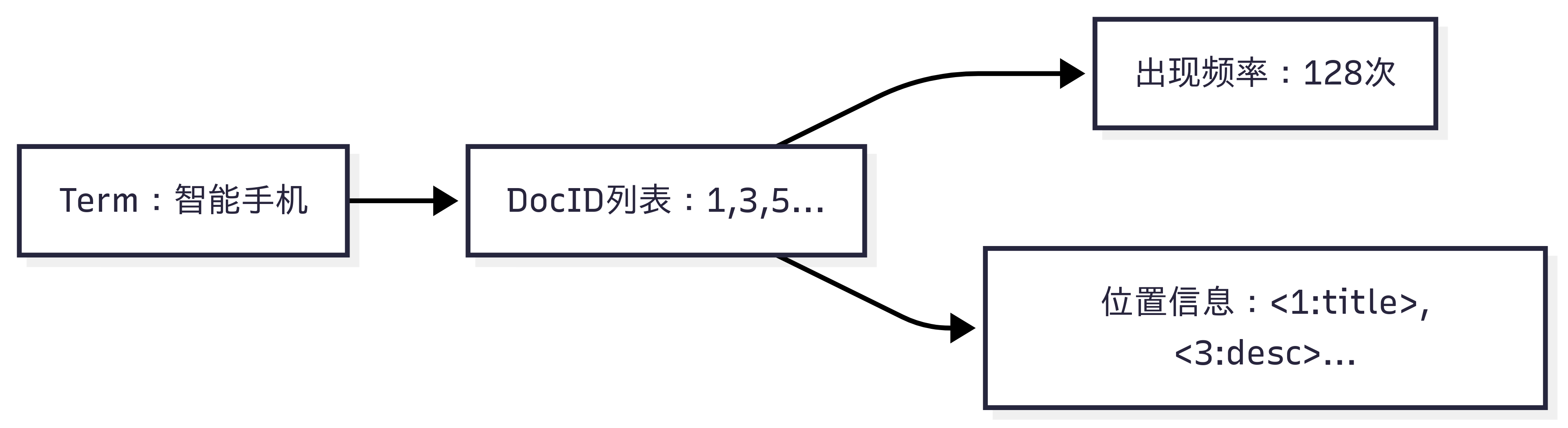
🔧 2.2 压缩算法三剑客
| 压缩方式 | 应用场景 | 说明 |
|---|---|---|
| FST(Finite State Transducer) | keyword 字段的 term dictionary | 前缀压缩,相同前缀只存一份,提高内存命中率 |
| Roaring Bitmap | 布尔条件组合,如标签筛选 | 加速 AND/OR 操作,比 bitset 更紧凑 |
| Block-Packed Encoding | docID + 位置信息压缩 | Lucene 默认优化机制 |
✅ 调优建议
- 合理选择字段类型:keyword 用于聚合和排序,text 用于全文搜索;
- 对非查询字段设置 “index”: false,避免不必要的倒排索引;
- 可关闭不需要的 _source 字段,节省存储空间。
// 创建优化映射
PUT /products
{"settings": {"index": {"number_of_shards": 12,"number_of_replicas": 1}},"mappings": {"_source": {"enabled": false // 对不需要原始数据的场景},"properties": {"product_name": {"type": "text", "index_options": "docs" // 仅存储文档ID},"brand_id": {"type": "keyword","index": false // 不建索引,仅作为存储字段},"specs": {"type": "text","norms": false // 禁用长度归一化,节省空间}}}
}
三、分片策略:写入性能的生命线
⚠️3.1 分片数量黄金法则

🔍3.2 分片写入瓶颈
// 分片写入伪代码
class IndexShard {void indexDocument(Document doc) {// 1. 写入事务日志(translog)writeToTranslog(doc); // 2. 刷新到内存缓冲区addToMemoryBuffer(doc);// 3. 周期性刷新到Lucene段if (shouldRefresh()) {refresh(); // 成本高昂的操作}}
}
写入优化配置:
# elasticsearch.yml
index.translog.durability: async # 异步写translog
index.refresh_interval: 30s # 降低刷新频率
indices.memory.index_buffer_size: 20% # 增加内存缓冲区
✅ 3.3 分片动态调整
# 扩容后重新分配分片
POST _reindex
{"source": {"index": "products-v1"},"dest": {"index": "products-v2"}
}# 限制节点分片数
PUT _cluster/settings
{"persistent": {"cluster.routing.allocation.total_shards_per_node": 100}
}
经验值:SSD 节点建议单分片不超过 50GB,HDD 不超过 30GB
四、深度分页:性能黑洞解决方案
🚨4.1 From/Size 的性能灾难
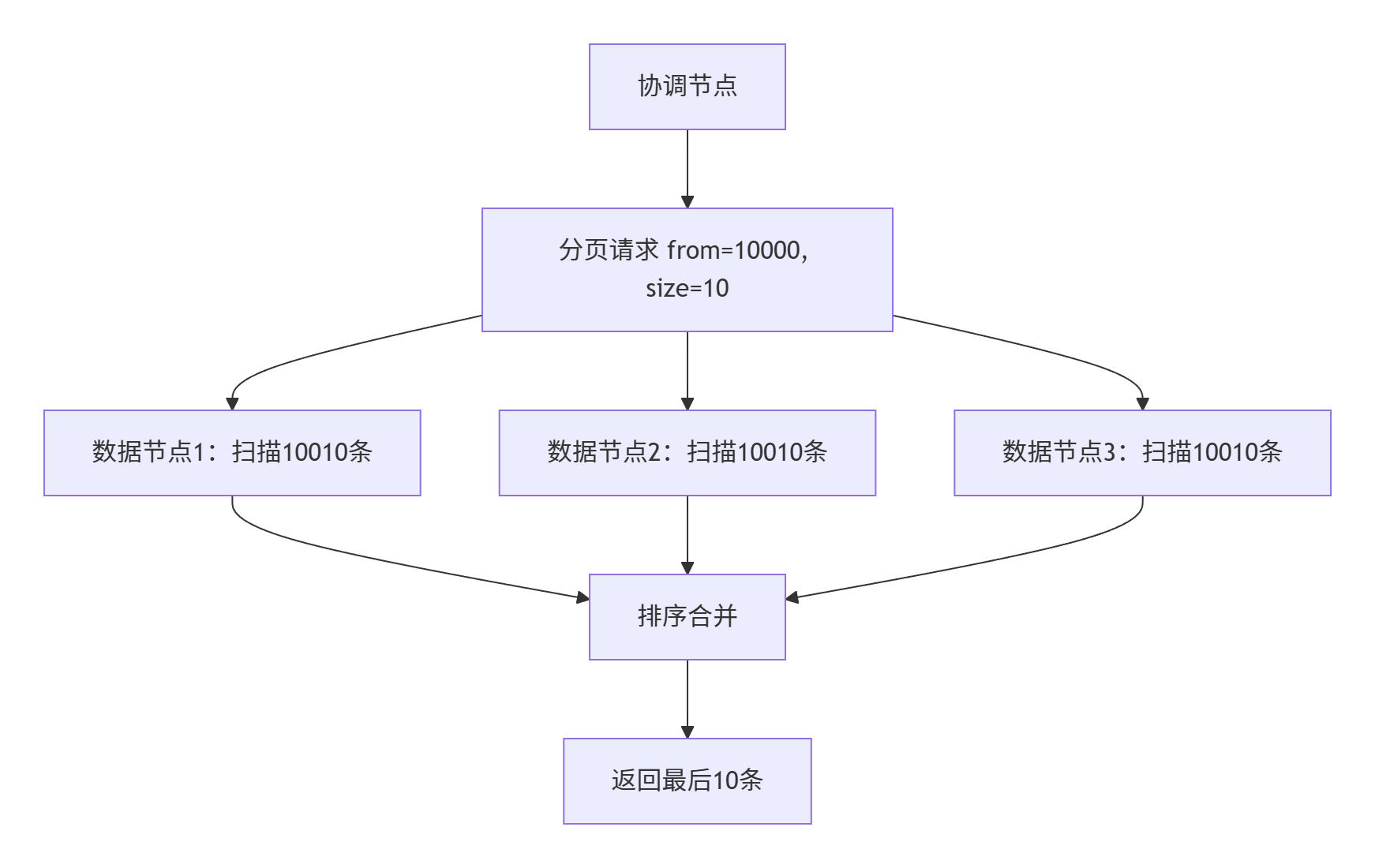
🧭 4.2 高性能替代方案
🔁方案一:Search After(实时分页)
GET /products/_search
{"size": 10,"query": {"match": {"category": "手机"} },"sort": [{"price": "desc"},{"_id": "asc"} // 确保排序唯一性],"search_after": [2999, "prod_123456"]
}
🔁方案二:PIT(Point In Time)
// Java客户端操作
OpenPointInTimeRequest pitRequest = new OpenPointInTimeRequest("products").keepAlive(TimeValue.timeValueMinutes(5));
OpenPointInTimeResponse pitResponse = client.openPointInTime(pitRequest, RequestOptions.DEFAULT);SearchRequest searchRequest = new SearchRequest().source(new SearchSourceBuilder().pointInTimeBuilder(new PointInTimeBuilder(pitResponse.getPointInTimeId())).sort(SortBuilders.fieldSort("price").order(SortOrder.DESC)).size(100));
方案对比
| 方案 | 特点 | 场景适配 |
|---|---|---|
| Scroll API | 游标式分页,保持快照一致 | 报表导出、数据迭代 |
| search_after | 基于上页 sort 值定位下一页 | 无状态分页推荐 |
| PIT(Point In Time) | 7.10+ 引入,轻量快照 | 精准分页、支持重试 |
五、相关性算分:从理论到业务定制
🔍5.1 BM25 算法原理
score(q,d) = IDF(q) * [ TF(q,d) * (k1 + 1) ] / [ TF(q,d) + k1 * (1 - b + b * |d|/avgdl) ]
参数调优:
PUT /products
{"settings": {"index": {"similarity": {"custom_bm25": {"type": "BM25","b": 0.75, // 长度归一化因子"k1": 1.2 // 词频饱和度}}}}
}
🎯业务相关性优化
1. 字段加权:
GET /products/_search
{"query": {"multi_match": {"query": "防水相机","fields": ["title^3", // 标题权重3倍"features^2","description"],"type": "best_fields"}}
}2. 结合业务数据:
GET /products/_search
{"query": {"function_score": {"query": {"match": {"name": "耳机"}},"functions": [{"filter": {"range": {"sales": {"gte": 1000}}},"weight": 2},{"script_score": {"script": {"source": "Math.log(2 + doc['click_count'].value)"}}}],"score_mode": "sum"}}
}六、脑裂防护:集群高可用保障
😱6.1 脑裂成因与影响
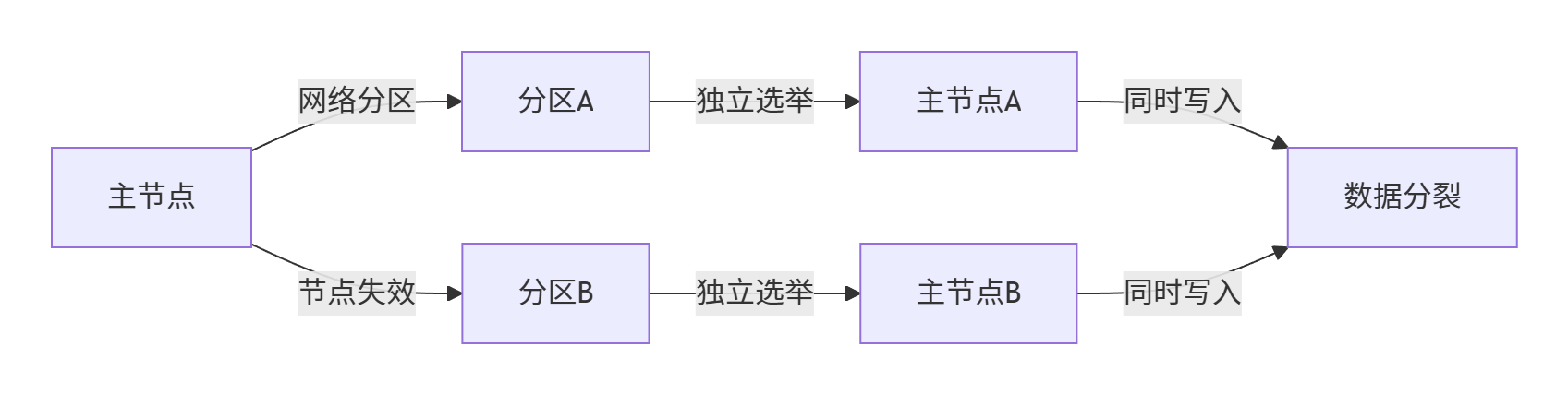
🛡️6.2 防脑裂配置
配置关键参数:
# elasticsearch.yml 配置# 7.x+版本
discovery.seed_hosts: ["node1:9300", "node2:9300", "node3:9300"]
cluster.initial_master_nodes: ["node1", "node2", "node3"]# 通用设置
cluster.name: prod-search-cluster # 统一集群名
node.master: true # 主节点角色
node.data: false # 专用master节点建议关闭data角色
✅6.3 节点部署最佳实践
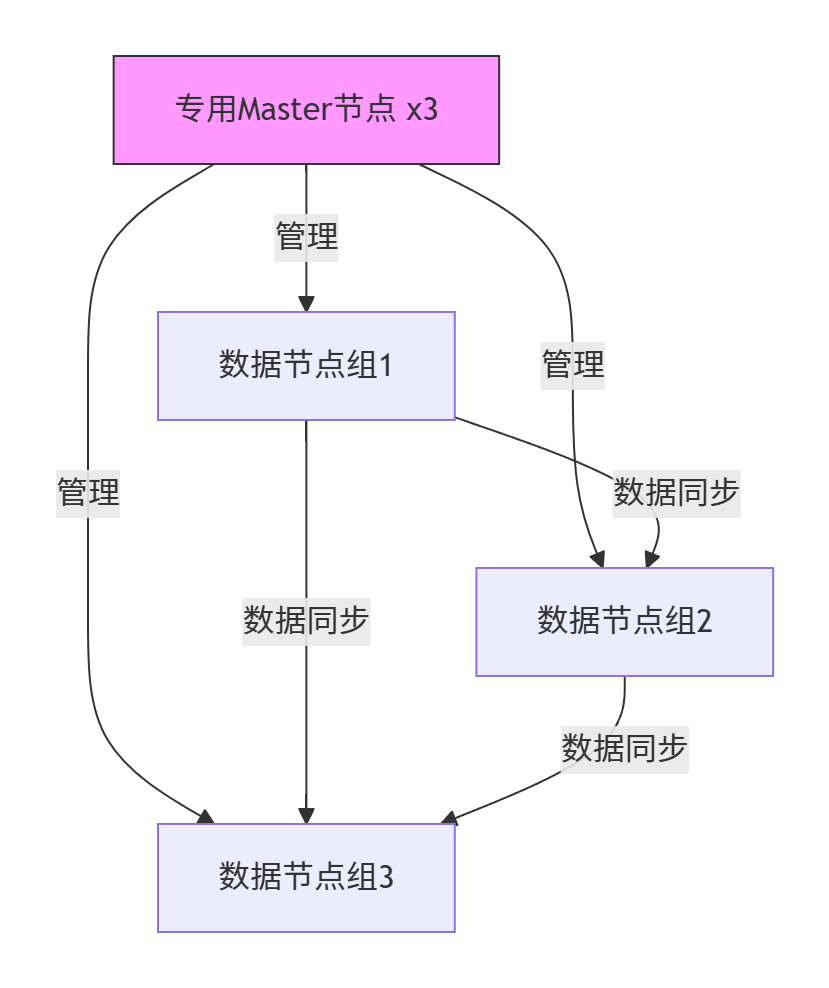
部署建议:
- Master节点数:3/5/7(奇数)
- 跨机房部署:每个机房部署独立数据节点组
- 角色隔离:
- 专用Master:3-5节点
- 数据节点:承担data角色
- 协调节点:client节点分离
七、总结与调优建议清单 ✅
🔧7.1 性能调优清单
| 类别 | 参数/操作 | 推荐值 |
|---|---|---|
| 索引设计 | 分片大小 | 10-50GB/分片 |
| 副本数量 | 生产环境≥1 | |
| 查询优化 | 深度分页 | 使用search_after/PIT |
| 聚合精度 | 设置shard_size | |
| 写入性能 | refresh_interval | 30s-120s |
| translog模式 | async | |
| 集群安全 | 最小主节点 | discovery.zen.minimum_master_nodes=(N/2+1) |
| 节点角色 | 分离master/data |
🗂️7.2 冷热集群架构
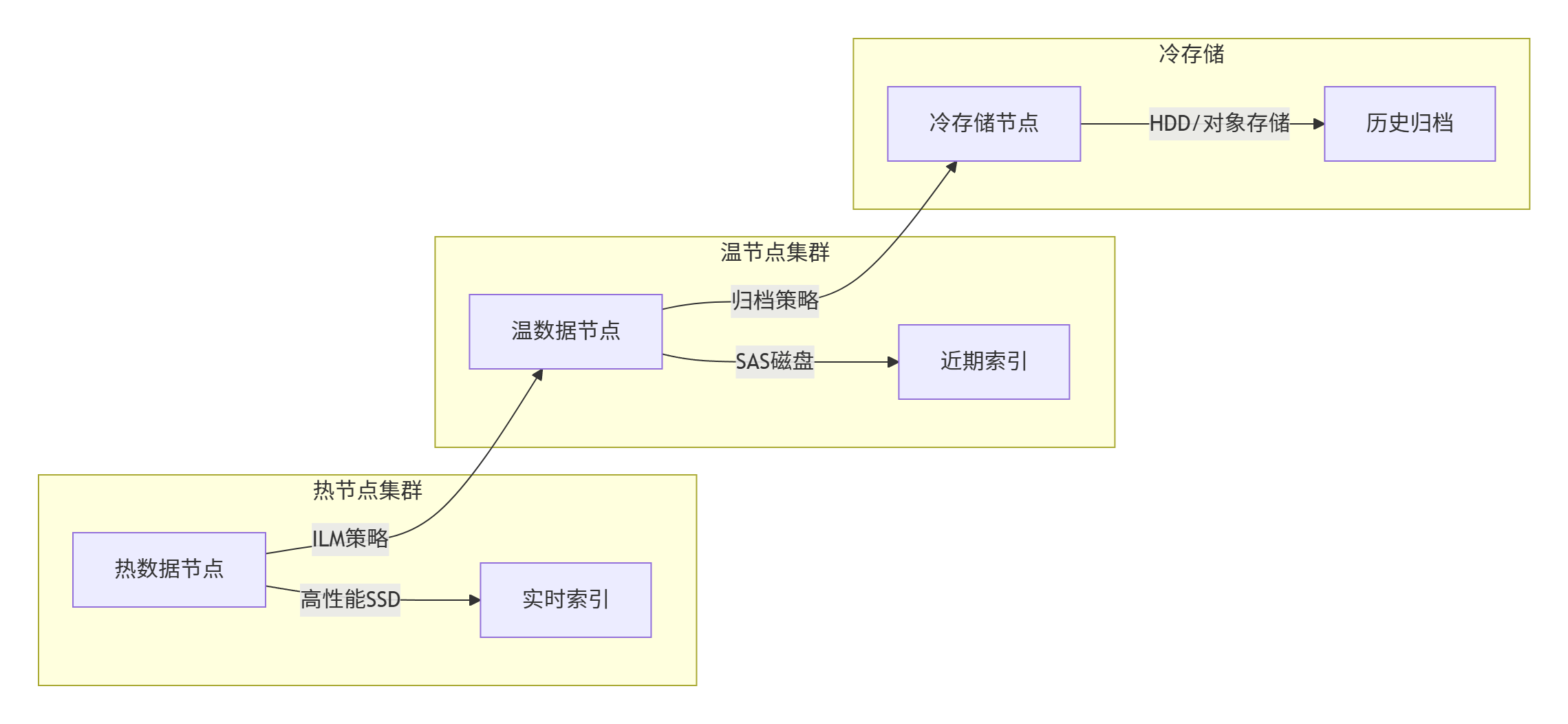
🖼️7.3 紧急故障处理
# 1. 快速定位慢查询
GET _tasks?detailed=true&actions=*search*# 2. 清除缓存(谨慎使用)
POST /products/_cache/clear# 3. 临时限制分片分配
PUT _cluster/settings
{"transient": {"cluster.routing.allocation.enable": "none"}
}
八、技术附录
🧨8.1 Java 客户端配置
public class HighLevelClientExample {public static void main(String[] args) {RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")).setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder.setDefaultIOReactorConfig(IOReactorConfig.custom().setIoThreadCount(4) // 优化IO线程.build())).setRequestConfigCallback(requestConfigBuilder -> requestConfigBuilder.setConnectTimeout(5000) .setSocketTimeout(60000)));}
}
🛠8.2 索引生命周期管理
PUT _ilm/policy/hot-warm-cold-policy
{"policy": {"phases": {"hot": {"min_age": "0ms","actions": {"rollover": {"max_size": "50gb","max_age": "7d"}}},"warm": {"min_age": "7d","actions": {"shrink": {"number_of_shards": 2},"forcemerge": {"max_num_segments": 1}}},"cold": {"min_age": "30d","actions": {"allocate": {"require": {"data": "cold"}}}},"delete": {"min_age": "365d","actions": {"delete": {}}}}}
}
最后建议:生产环境部署至少3节点集群,定期进行性能压测(使用 Rally 工具)
讨论话题:你在 Elasticsearch 优化中最有成效的一项配置是什么?
👇 欢迎在评论区分享你的实战经验!















)


)
)