目录
一、三级缓存和内存布局
二、CPU架构
(1)SMP对称对处理器架构
(2)NUMA非统一内存架构
三、RCU机制在内核中的体现
四、内存优化屏障
(1)编译器、CPU优化
(2)优化的问题和解决办法
(3)volatile关键字
在学习Linux或者c++的时候,经常会看到缓存、内存、寄存器这样的字眼。只知道他们都是用于存储数据、指令的,且有效率之分,但是具体的框图并不了解。本篇文章以此为基础,延伸到CPU的架构等问题。
一、三级缓存和内存布局
我们知道当前主流的计算机是符合冯诺依曼体系架构的。内存位于所有结构的中心,任何外设想要进行数据交换都必须先把数据、指令交给内存,然后分别从内存中读取。
如下图所示: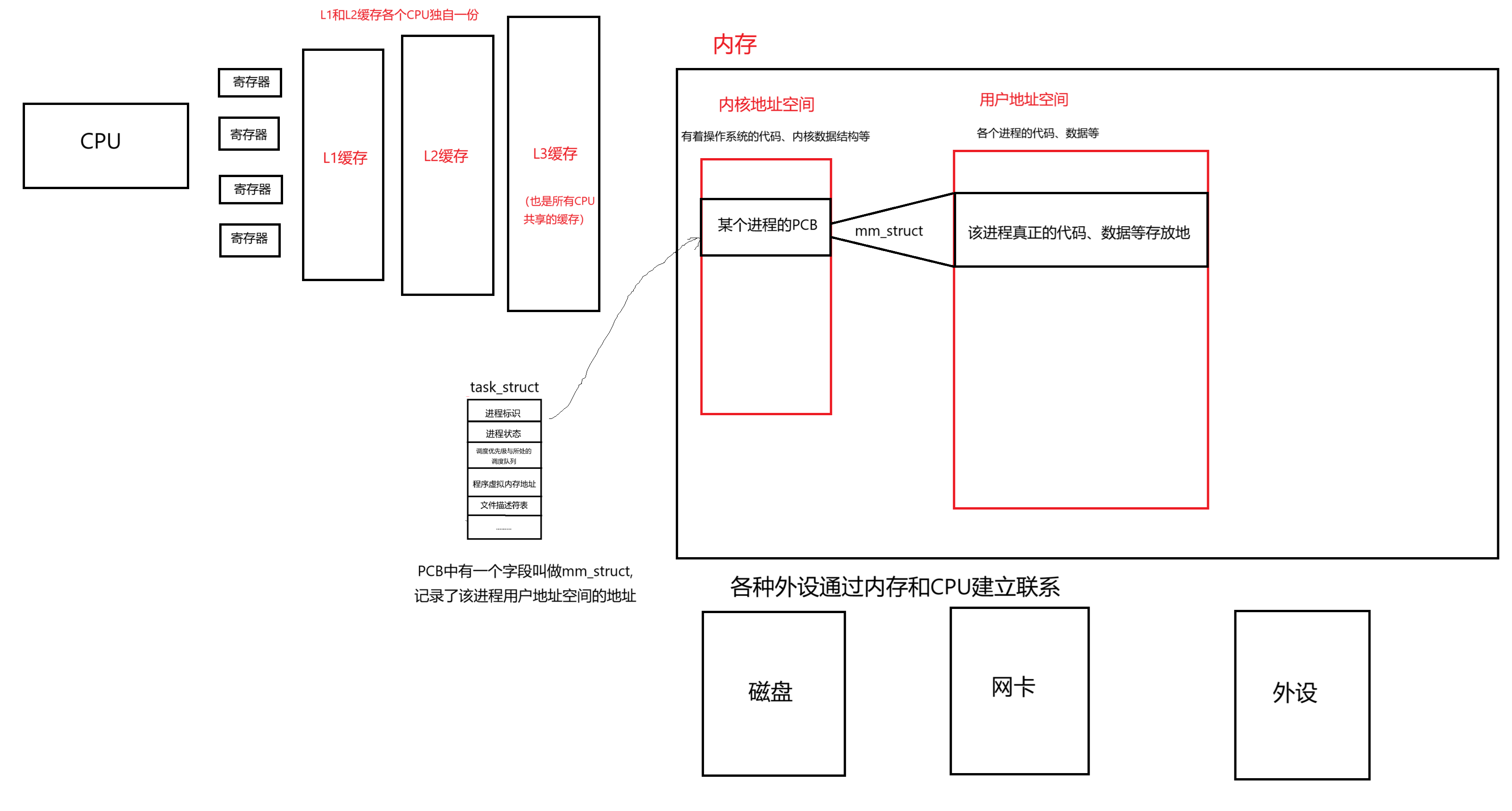
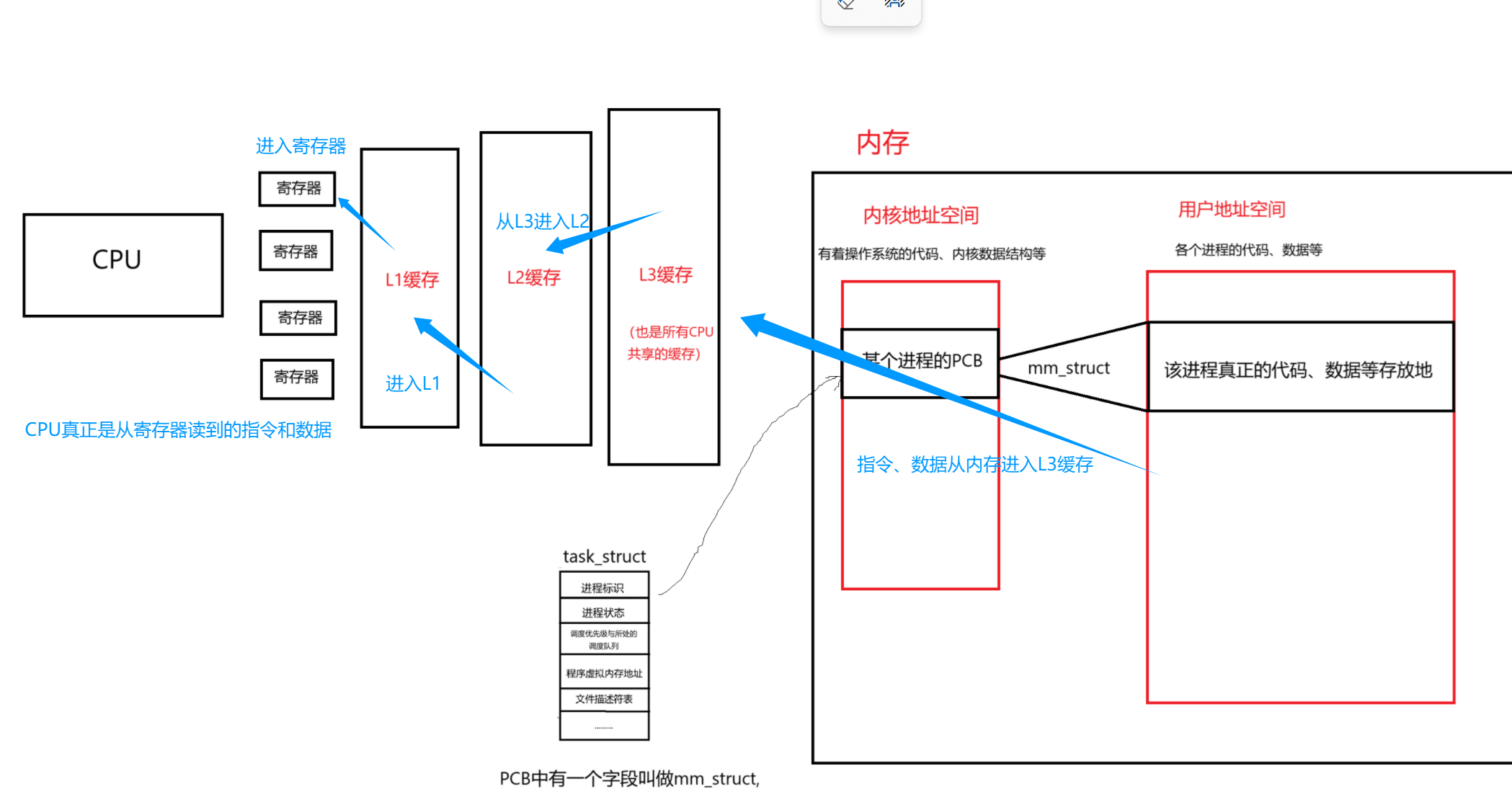
有了这样一份基础架构,我们就能更好的理解CPU运行的时候,是如何从内存得到指令和数据的。
即调度器把某个进程的PCB给到CPU,然后CPU根据PCB里面的地址找到物理内存要数据、指令,通过三级缓存和寄存器逐级交付,最终传递给CPU的过程。
二、CPU架构
(1)SMP对称对处理器架构
SMP(Symmetric Multi - Processing)架构中,多个 CPU 核心共享统一的内存空间、I/O 设备等系统资源,并且所有 CPU 核心的地位平等,它们可以无差别地访问内存、外设等,操作系统可以将任务动态分配到任意一个 CPU 核心上执行。
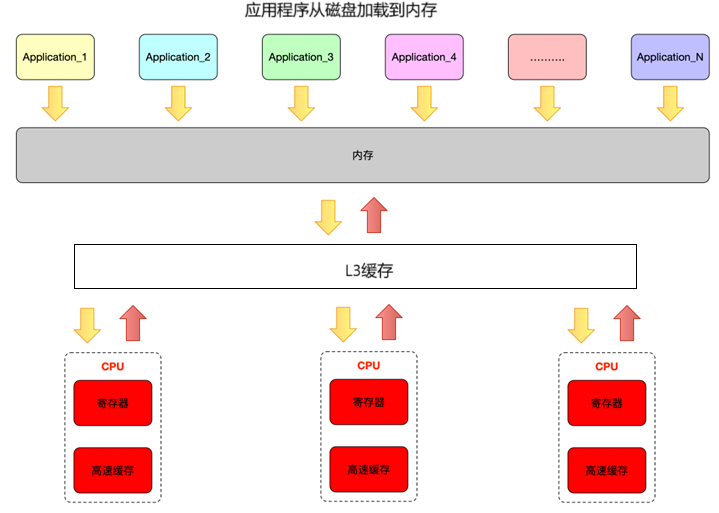
优点:
- 易于编程:对于开发者来说,SMP 架构下的编程模型相对简单,因为所有 CPU 核心对系统资源的访问方式基本相同,不需要考虑太多复杂的资源分配和访问差异问题。
- 负载均衡:操作系统能够方便地在各个 CPU 核心之间进行任务调度,实现负载均衡,充分利用各个核心的计算能力。
缺点:
- 内存访问瓶颈:随着 CPU 核心数量的增加,所有核心都访问同一个内存空间,会导致内存总线的竞争加剧,从而形成性能瓶颈。
- 可扩展性受限:由于共享内存等资源的限制,当核心数量增加到一定程度时,性能提升不明显甚至会下降。
(2)NUMA非统一内存架构
NUMA(Non - Uniform Memory Access)架构中,多个 CPU 核心被划分成不同的节点,每个节点都有自己的本地内存,同时也可以访问其他节点的内存,但访问本地内存的速度要比访问远程(其他节点)内存的速度快。操作系统需要考虑内存分配与 CPU 核心的位置关系,以提高性能。
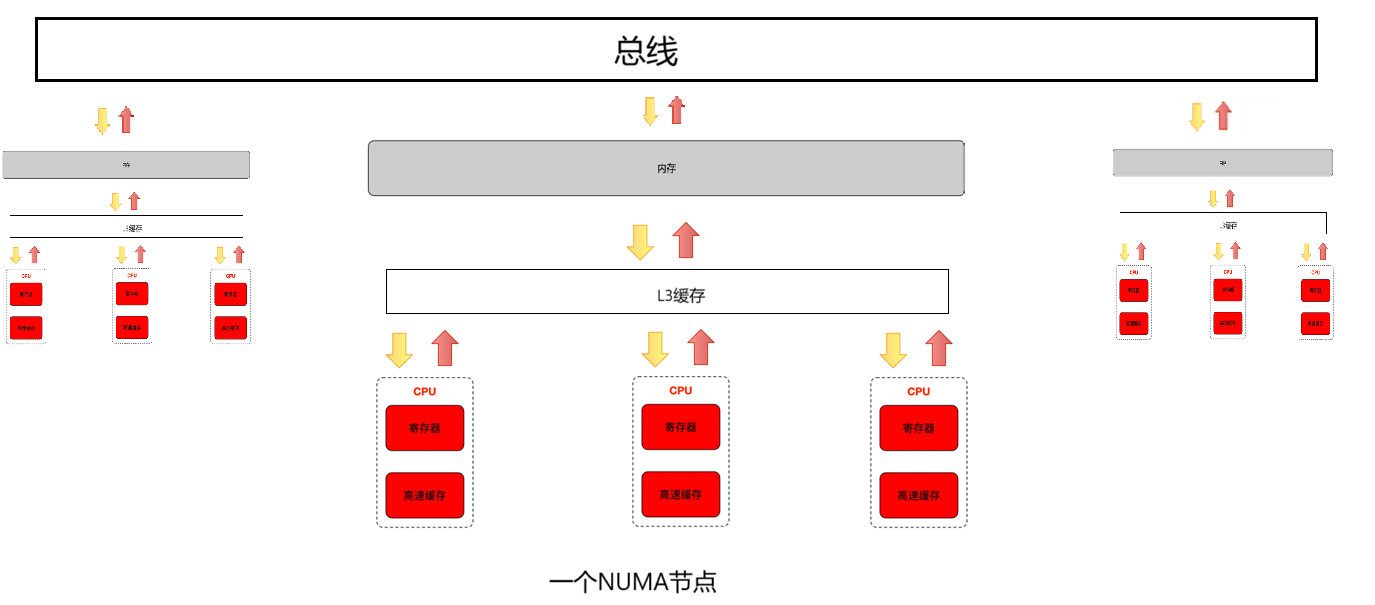
优点:
- 高可扩展性:通过将内存分配到不同节点,减少了内存访问冲突,使得系统在增加 CPU 核心数量时,依然能够保持较好的性能扩展性。
- 局部性原理利用:可以将数据和任务分配到对应的节点,充分利用本地内存访问速度快的优势,提高整体性能。
缺点:
- 编程复杂度增加:开发者需要考虑内存的本地性问题,在编程时需要手动管理内存分配,以确保数据在合适的节点上,否则可能导致性能下降。
- 管理复杂:操作系统需要更复杂的资源管理和调度策略,来平衡各个节点的负载和优化内存访问。
三、RCU机制在内核中的体现
RCU本质只是一种提高读写效率的锁。但是在Linux中广泛的用到。比如在task_struct中,我们曾说到有进程的ID、调度策略、用户地址空间指针等等各种成员。内核中存在着大量的链表结构,无论是调度器就绪队列,还是全局进程链表、子进程链表。这些链表操作往往涉及到大量的读,而对写性能要求不高。此时RCU机制就能发挥到极致。
下面我们来看看内核中的RCU机制引申出的链表rcu操作。
// 安全的节点插入(使用内存屏障)
void safe_add_node(struct my_node *new) {// 1. 完成所有数据初始化new->data = 100;// 2. 使用写内存屏障(确保之前的写操作对其他CPU可见)smp_wmb();// 3. 原子更新链表指针(使新节点对读操作可见)list_add_tail_rcu(&new->list, &my_list);
}// 安全的节点删除(使用内存屏障)
void safe_delete_node(struct my_node *node) {// 1. 原子更新链表指针(从链表移除节点)list_del_rcu(&node->list);// 2. 使用读内存屏障(确保后续同步操作的顺序)smp_rmb();// 3. 等待宽限期结束(确保没有读操作引用旧节点)synchronize_rcu();// 4. 安全释放内存kfree(node);
}// 安全的链表遍历(无锁读)
void safe_traverse(void) {struct my_node *node;rcu_read_lock(); // 标记读临界区开始// 使用 RCU 安全遍历宏(确保指针解引用安全)list_for_each_entry_rcu(node, &my_list, list) {// 读操作期间,数据可能被修改,但保证可见性顺序printk("Data: %d\n", node->data);}rcu_read_unlock(); // 标记读临界区结束
}可以看到这个rcu插入链表节点的函数,不仅仅是更新了链表的节点,还调用了内存屏障函数,保证了编译器和CPU的优化不会乱序,让别的进程要么看到数据最新的新节点,要么看不到该节点,不存在已经插入到链表中而数据后更新的问题。
四、内存优化屏障
(1)编译器、CPU优化
我们写好了一个程序交给编译器编译、或者交给CPU运行的时候,可能与我们想象中一条条地执行不同,无论是编译器还是CPU都会采取一定的优化策略,让性能进一步提高。
比如编译器优化:把显而易见的代码直接求出结果,编译成二进制。这样能减少CPU运行的时间。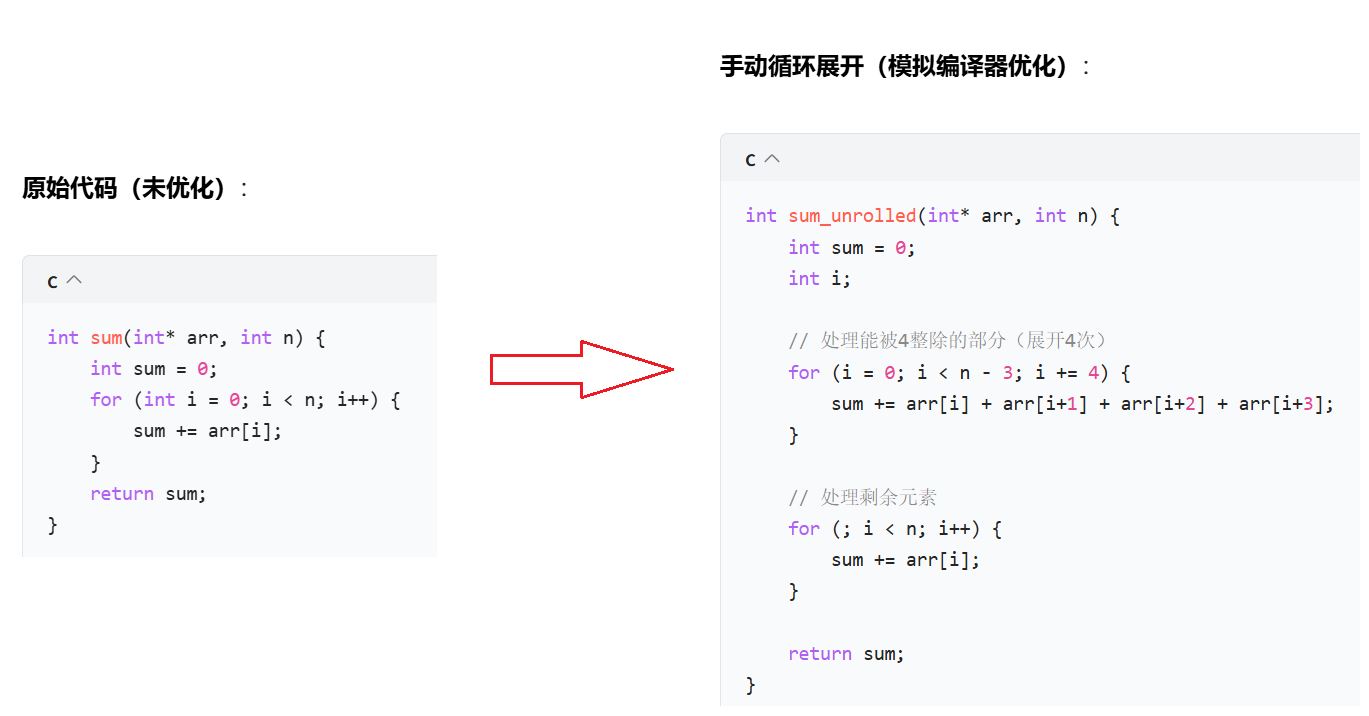
优化原理:
把显而易见的步骤直接在编译环节得到结果,减少CPU运行次数。
- 减少循环次数(原循环执行 n 次,展开后执行 n/4 次),降低分支预测失败和循环开销(如计数器更新、条件判断)。
- 增加指令级并行(ILP):多条加法指令可同时在 CPU 流水线中执行。
再比如CPU运行优化:
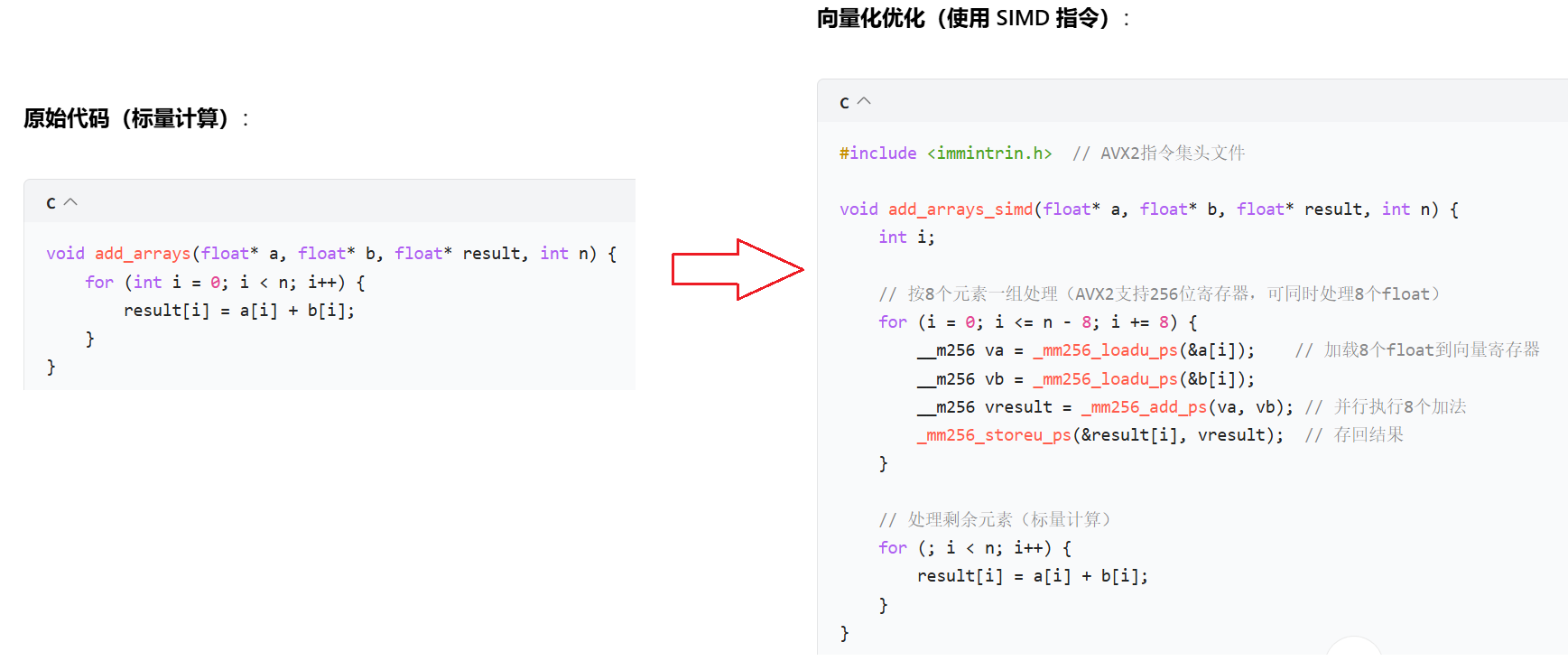
优化原理:
CPU从内存读取一个数据需要时间,这个时间如果傻等就白白浪费了,所以选择同时读取一堆,重叠掉这个等待时间。
- SIMD(单指令多数据):利用 CPU 的向量寄存器(如 AVX2 的 256 位寄存器)同时处理多个数据。
- 数据并行:一条指令完成 8 个浮点数加法,吞吐量提升 8 倍(理论值)。
(2)优化的问题和解决办法
CPU和编译器的乱序优化,本质上是为了提高运行效率。但是也导致了一个结果:可能导致不同线程错误的读到类似空指针的错误。
举个例子:
// 期望的链表插入函数
void incorrect_add_node(struct my_node *new) {// 初始化新节点new->data = 42;// 设置数据字段(可能被重排序到指针更新之后)new->data = 100; // 危险:可能在节点可见后才被更新// 将新节点连接到链表中list_add_tail_rcu(&new->list, &my_list);}
被优化后的:
// 错误的链表插入函数(无内存屏障)
void incorrect_add_node(struct my_node *new) {// 初始化新节点new->data = 42;// 先将新节点连接到链表中list_add_tail_rcu(&new->list, &my_list);// 然后设置数据字段(可能被重排序到指针更新之后)new->data = 100; // 危险:可能在节点可见后才被更新
}即使关闭了所有的优化,还是有可能出现问题:
正确的做法是在中间部分添加内存屏障:这里保证了先初始化数据,再更新链表指针。让其他线程要么看不到更新的链表节点,要么看到就是数据已经更新的完全体。
// 正确的链表插入函数(使用内存屏障)
void correct_add_node(struct my_node *new)
{// 1. 先完成所有数据初始化new->data = 100;// 2. 使用写内存屏障确保数据初始化对其他CPU可见smp_wmb(); // 写内存屏障,确保之前的写操作都完成// 3. 最后更新链表指针,使新节点对读操作可见list_add_tail_rcu(&new->list, &my_list);
} 最后,Linux中的内存屏障有许多种,其中通用屏障开销最大,我们最好根据请款选择合适的内存屏障。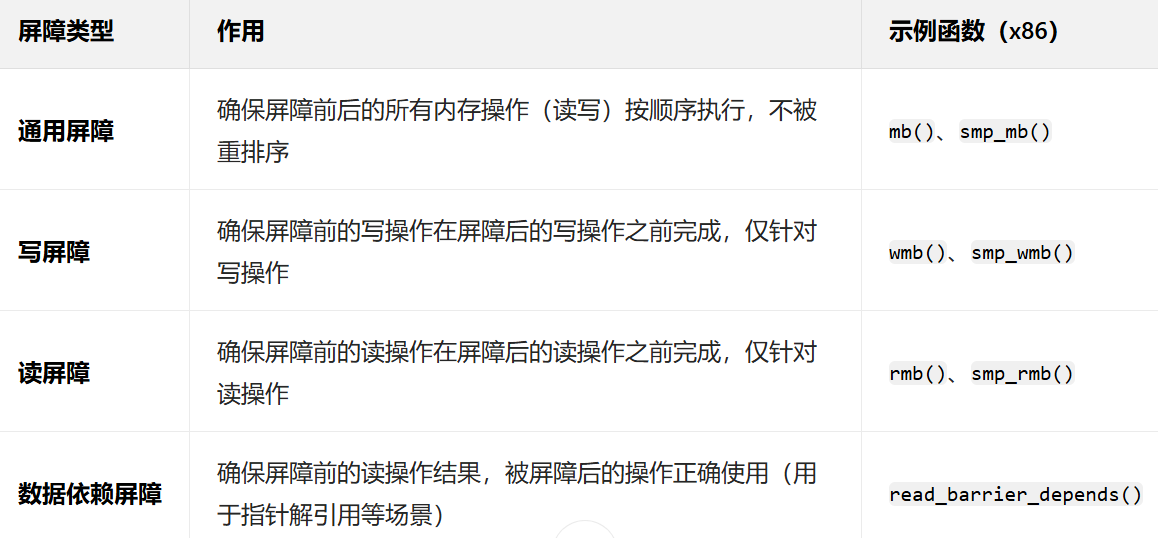
(3)volatile关键字
正如我们上面所说的优化有乱序的问题,CPU在读取某个变量的值的时候也会存在优化。当寄存器中恰好存储的就是该变量的值的时候(频繁访问某一个变量很有可能出现这种情况),cpu往往会直接从该寄存器中读取。
而寄存器更新的原则是覆盖式更新,即读新的数据,寄存器中原本没有,于是从L1、L2等缓存中覆盖写入到寄存器。如果该变量刚好就在寄存器,则可能读到旧值(缓存中的值已经发生了改变)。
volatile关键字的作用就是,禁止编译器把变量缓存到寄存器中,强制要求cpu每次必须在内存/缓存中读取该变量的值,从而保证了值的实时性。
不过他仅仅是解决 “编译器和硬件缓存导致的旧值读取” 的轻量级工具,但仅适用于简单场景。复杂的多线程 / 硬件同步,必须用更强大的原语(原子操作、内存屏障、锁)。
)
)
)



)


![[BrowserOS] Nxtscape浏览器核心 | 浏览器状态管理 | 浏览器交互层](http://pic.xiahunao.cn/[BrowserOS] Nxtscape浏览器核心 | 浏览器状态管理 | 浏览器交互层)


)





—— 多元素控件)
