1. 指针的“温柔陷阱”:空指针与野指针的致命一击
Go语言的指针虽然比C/C++简单,但照样能让你“痛不欲生”。新手常觉得Go的指针“安全”,但真相是:Go并不会帮你完全规避指针相关的Bug。空指针(nil pointer)和野指针(未初始化或错误引用的指针)是开发中最常见的陷阱之一。
1.1 空指针的“隐形炸弹”
在Go中,指针默认值是nil,但如果你不小心对nil指针解引用(*p),程序会毫不留情地抛出panic: runtime error: invalid memory address or nil pointer dereference。听起来很耳熟,对吧?来看个经典的例子:
type User struct {Name stringAge int
}func GetUserName(user *User) string {return user.Name // 危险!如果user是nil,这里会panic
}func main() {var user *User // 默认nilfmt.Println(GetUserName(user)) // boom!panic
}为什么会炸? 因为user是nil,你试图访问user.Name,相当于在空地上挖金子——啥也没有,只会崩。现实中,这种问题常出现在函数参数未检查、API返回空指针、或者结构体嵌套复杂时。
解决办法:防御性编程! 在访问指针之前,总是先检查是否为nil:
func GetUserName(user *User) string {if user == nil {return "Anonymous"}return user.Name
}或者用更现代的写法,结合errors包返回错误:
func GetUserName(user *User) (string, error) {if user == nil {return "", errors.New("user is nil")}return user.Name, nil
}1.2 野指针的“幽灵”
野指针问题在Go中相对少见,但依然可能发生。比如,你可能不小心使用了未初始化的指针,或者指针指向的内存被意外释放。来看个例子:
func CreateUser() *User {user := &User{Name: "Alice"} // 局部变量return user
}func main() {u := CreateUser()fmt.Println(u.Name) // 没问题// 但如果CreateUser返回的是栈上分配的地址(假设Go没逃逸分析)// 可能会导致未定义行为
}好消息是,Go的逃逸分析通常会把user分配到堆上,避免野指针问题。但如果你在复杂的场景中(比如Cgo或unsafe包)手动操作内存,野指针的幽灵可能悄悄找上门。
应对策略:
始终初始化指针:用new()或&显式分配内存。
避免unsafe操作:除非万不得已,别用unsafe.Pointer,它会绕过Go的安全检查。
善用工具:用go vet或静态分析工具检查潜在的指针问题。
1.3 真实案例:JSON反序列化的空指针噩梦
我在一个项目中见过这样的代码:
type Config struct {Database *DBConfig
}type DBConfig struct {Host stringPort int
}func ParseConfig(jsonStr string) (*Config, error) {var cfg Configif err := json.Unmarshal([]byte(jsonStr), &cfg); err != nil {return nil, err}return &cfg, nil
}func main() {cfg, _ := ParseConfig(`{}`)fmt.Println(cfg.Database.Host) // panic!Database是nil
}问题出在JSON反序列化时,如果JSON数据没有Database字段,cfg.Database会保持nil。调用cfg.Database.Host直接崩。
修复方案:
在访问嵌套字段前检查nil。
或者在Config结构体中初始化Database:
func ParseConfig(jsonStr string) (*Config, error) {var cfg Configcfg.Database = &DBConfig{} // 初始化if err := json.Unmarshal([]byte(jsonStr), &cfg); err != nil {return nil, err}return &cfg, nil
}小提示: 在处理API返回的JSON时,永远不要假设字段一定存在。防御性检查是你的救命稻草!
2. 切片的“膨胀危机”:容量与长度的微妙区别
Go的切片(slice)是开发中最常用的数据结构之一,但它的“动态”特性背后藏着不少陷阱。尤其是长度(len)和容量(cap)的区别,稍不注意就会导致性能问题或逻辑错误。
2.1 切片的基本原理
切片是一个轻量级的数据结构,底层依赖数组。它的结构包含:
指向底层数组的指针
长度(len):当前切片包含的元素数
容量(cap):底层数组的总长度
来看个例子:
func main() {s := make([]int, 3, 5) // 长度3,容量5fmt.Println(len(s), cap(s)) // 输出:3 5s = append(s, 1, 2) // 添加两个元素fmt.Println(len(s), cap(s)) // 输出:5 5s = append(s, 3) // 超出容量,触发重新分配fmt.Println(len(s), cap(s)) // 输出:6 10(容量可能翻倍)
}关键点: 当append操作超出容量时,Go会分配一个更大的底层数组(通常翻倍),并将数据拷贝过去。这会导致性能开销,尤其在循环中频繁append时。
2.2 陷阱:无脑append导致性能爆炸
来看个常见的错误:
func GenerateNumbers(n int) []int {var result []int // 长度和容量都是0for i := 0; i < n; i++ {result = append(result, i)}return result
}这段代码看似无害,但如果n很大(比如100万),每次append可能触发多次数组重新分配和拷贝,性能极差。解决办法是预分配容量:
func GenerateNumbers(n int) []int {result := make([]int, 0, n) // 预分配容量for i := 0; i < n; i++ {result = append(result, i)}return result
}通过make指定容量,append操作无需频繁重新分配,性能提升显著。经验之谈: 只要能预估切片大小,尽量用make指定容量!
2.3 切片共享的“阴谋”
切片的另一个陷阱是底层数组共享。多个切片可能指向同一个底层数组,修改一个切片可能影响其他切片。看例子:
func main() {s1 := []int{1, 2, 3, 4}s2 := s1[1:3] // s2是{2, 3},但共享底层数组s2[0] = 999fmt.Println(s1) // 输出:[1 999 3 4]
}为什么会这样? 因为s2和s1共享同一个底层数组,修改s2会直接影响s1。这在并发编程或复杂切片操作中尤其危险。
解决办法:
如果需要独立副本,使用copy函数:
s2 := make([]int, 2)
copy(s2, s1[1:3])
s2[0] = 999 // 不会影响s1或者用append创建新切片(确保触发重新分配):
s2 := append([]int{}, s1[1:3]...)实战建议: 在函数返回切片时,考虑是否需要拷贝,避免意外共享底层数组。
3. Goroutine的“失控狂奔”:并发编程的陷阱
Go的并发模型(goroutine + channel)是它的杀手锏,但也带来了不少“惊吓”。新手常以为go关键字一加就万事大吉,殊不知goroutine可能悄无声息地泄漏,或者死锁让你抓狂。
3.1 Goroutine泄漏的“隐形杀手”
Goroutine非常轻量,但如果不正确管理,可能导致内存泄漏。看个例子:
func processItems(items []string) {for _, item := range items {go func() {time.Sleep(time.Second) // 模拟耗时操作fmt.Println(item)}()}
}问题在于,processItems函数结束后,goroutine可能还在运行。如果items很多,或者goroutine中有无限循环,程序的内存会逐渐被耗尽。
修复方案: 使用sync.WaitGroup确保goroutine完成:
func processItems(items []string) {var wg sync.WaitGroupfor _, item := range items {wg.Add(1)go func(item string) {defer wg.Done()time.Sleep(time.Second)fmt.Println(item)}(item) // 注意传递item}wg.Wait()
}注意: 这里还修复了另一个陷阱——循环变量捕获问题。原始代码中,go func()捕获的是item的引用,可能导致所有goroutine打印相同的最后一个item。通过显式传递item参数解决。
3.2 死锁的“无底深渊”
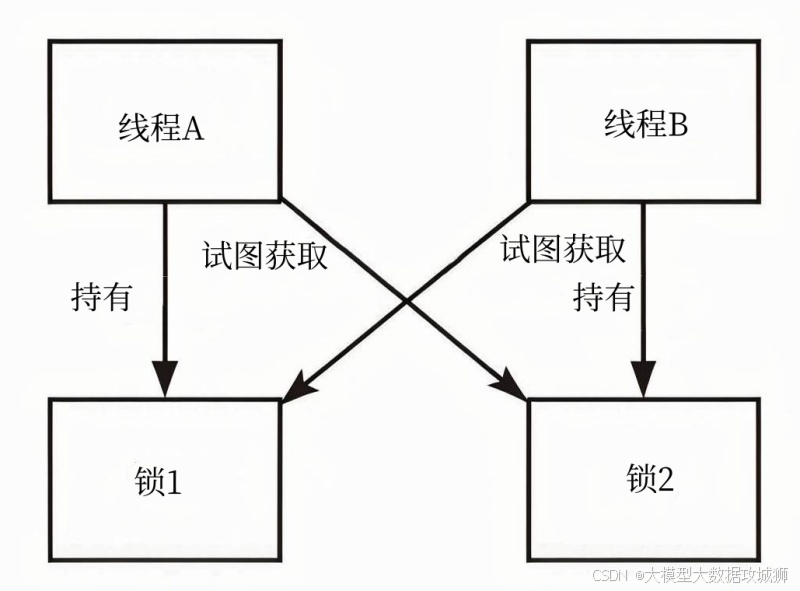
另一个常见问题是channel导致的死锁。比如:
func main() {ch := make(chan int)ch <- 42 // 死锁!无人接收fmt.Println(<-ch)
}为什么死锁? 因为ch是无缓冲channel,发送操作会阻塞直到有人接收,但main函数里没人接收,程序直接卡死。
解决办法:
使用缓冲channel(make(chan int, 1))减少阻塞。
确保发送和接收配对,或者用select处理复杂逻辑:
func main() {ch := make(chan int, 1)ch <- 42fmt.Println(<-ch) // 正常运行
}实战经验: 用context包控制goroutine生命周期,遇到超时或取消时优雅退出,避免泄漏或死锁。
4. 接口的“隐藏成本”:nil接口与类型断言的陷阱
Go的接口(interface)是静态类型语言中的一朵奇葩,强大但也容易让人摔跟头。尤其是nil接口和类型断言,稍不留神就出问题。
4.1 nil接口的“假象”
很多人以为nil接口是安全的,实则不然。接口在Go中包含两部分:类型和值。即使值是nil,接口本身可能不是nil。看例子:
func process(err error) {if err == nil {fmt.Println("No error")return}fmt.Println("Error:", err)
}func main() {var e *errors.Error // 自定义错误类型var err error = e // err是接口,值是nil但类型是*errors.Errorprocess(err) // 输出:Error: <nil>
}为什么不是“No error”? 因为err接口的类型非空,即使值是nil,接口整体不为nil。
解决办法: 谨慎处理接口的nil检查,或者显式返回nil接口:
func main() {var e *errors.Errorvar err errorif e != nil {err = e}process(err) // 输出:No error
}4.2 类型断言的“暗礁”
类型断言是接口的常用操作,但用错会导致panic:
func main() {var i interface{} = "hello"s := i.(int) // panic!类型不匹配
}修复方案: 使用带返回值的类型断言,检查是否成功:
func main() {var i interface{} = "hello"if s, ok := i.(string); ok {fmt.Println("String:", s)} else {fmt.Println("Not a string")}
}实战建议: 在处理动态类型时,优先使用switch类型断言,清晰且安全:
func processValue(i interface{}) {switch v := i.(type) {case string:fmt.Println("String:", v)case int:fmt.Println("Int:", v)default:fmt.Println("Unknown type")}
}5. 并发中的“数据争夺战”:数据竞争的隐形杀手
Go语言的并发模型以“goroutine+channel”为核心,号称简单高效,但并发编程从来不是省心的事。数据竞争(data race)是Go开发者最容易踩的雷之一,尤其在多goroutine共享数据时,一个不小心,程序行为就变得不可预测。
5.1 数据竞争的“罪魁祸首”
数据竞争发生在多个goroutine同时访问同一块内存,且至少有一个是写操作,而没有同步机制保护。来看个经典的错误:
func main() {counter := 0for i := 0; i < 1000; i++ {go func() {counter++ // 多个goroutine同时写counter}()}time.Sleep(time.Second) // 等待goroutine执行fmt.Println(counter) // 期望1000,但可能远小于1000
}为什么结果不对? 因为counter++不是原子操作,它包含读、加、写三个步骤。多个goroutine同时操作counter,会导致值被覆盖,最终结果随机且不可靠。
检测神器: Go提供了一个强大的工具go run -race来检测数据竞争。运行上面的代码加上-race标志,你会看到类似以下的警告:
WARNING: DATA RACE
Read at 0x00c0000a4000 by goroutine 7:main.main.func1()main.go:6 +0x44
Write at 0x00c0000a4000 by goroutine 8:main.main.func1()main.go:6 +0x445.2 解决数据竞争的“三板斧”
要消灭数据竞争,有三种常用方法:
互斥锁(sync.Mutex)
使用sync.Mutex保护共享资源,确保同一时间只有一个goroutine能访问:
func main() {var mu sync.Mutexcounter := 0var wg sync.WaitGroupfor i := 0; i < 1000; i++ {wg.Add(1)go func() {defer wg.Done()mu.Lock()counter++mu.Unlock()}()}wg.Wait()fmt.Println(counter) // 输出:1000
}注意: 别忘了mu.Unlock(),否则会导致死锁!另外,defer mu.Unlock()是个好习惯,确保锁一定被释放。
原子操作(sync/atomic)
对于简单的计数器操作,sync/atomic包更高效:
func main() {var counter int32var wg sync.WaitGroupfor i := 0; i < 1000; i++ {wg.Add(1)go func() {defer wg.Done()atomic.AddInt32(&counter, 1)}()}wg.Wait()fmt.Println(atomic.LoadInt32(&counter)) // 输出:1000
}Channel通信
Go提倡“通过通信共享内存,而不是通过共享内存通信”。可以用channel重构:
func main() {ch := make(chan int, 1000)var wg sync.WaitGroupfor i := 0; i < 1000; i++ {wg.Add(1)go func() {defer wg.Done()ch <- 1}()}go func() {wg.Wait()close(ch)}()counter := 0for n := range ch {counter += n}fmt.Println(counter) // 输出:1000
}实战建议: 小规模计数用atomic,复杂逻辑用Mutex,而channel适合任务分发或事件通知。根据场景选择合适的工具!
5.3 真实案例:并发Map的崩溃
标准库的map不是并发安全的,如果多个goroutine同时读写map,会直接抛出fatal error: concurrent map read and mapbud write。看例子:
func main() {m := make(map[string]int)for i := 0; i < 100; i++ {go func() {m["key"] = 1 // 并发写map}()}time.Sleep(time.Second)
}运行这段代码(加-race),你会看到数据竞争的警告,甚至可能直接崩溃。
解决办法:
使用sync.RWMutex保护map:
func main() {m := make(map[string]int)var mu sync.RWMutexvar wg sync.WaitGroupfor i := 0; i < 100; i++ {wg.Add(1)go func() {defer wg.Done()mu.Lock()m["key"] = 1mu.Unlock()}()}wg.Wait()
}或者使用sync.Map,专为并发设计的线程安全map:
func main() {var m sync.Mapvar wg sync.WaitGroupfor i := 0; i < 100; i++ {wg.Add(1)go func() {defer wg.Done()m.Store("key", 1)}()}wg.Wait()
}sync.Map适合高并发、读多写少的场景,但它的API不如普通map灵活,性能开销也略高。
6. 包管理的“版本噩梦”:Go Modules的正确打开方式
Go 1.11引入了Go Modules,解决了依赖管理的老大难问题,但新手在使用时仍会遇到不少坑,比如版本冲突、依赖丢失,甚至“404 not found”的噩梦。
6.1 陷阱:版本冲突与伪版本
假设你的项目依赖了两个包A和B,而A依赖github.com/some/lib@v1.2.0,B依赖github.com/some/lib@v1.3.0。运行go build时,Go会选择最高版本(v1.3.0),但如果v1.3.0有破坏性变更,A可能会崩溃。
解决办法:
在go.mod中显式指定版本:
require github.com/some/lib v1.2.0使用go mod tidy清理无用依赖,确保go.mod和go.sum一致。
如果需要临时测试某个版本,用replace指令:
replace github.com/some/lib => github.com/some/lib v1.2.06.2 陷阱:私有仓库的认证问题
如果你的项目依赖私有Git仓库,go get可能会报错404或permission denied。这是因为Go默认使用HTTPS协议,而你的仓库可能需要SSH认证。
解决办法:
配置Git使用SSH:
git config --global url."git@github.com:".insteadOf "https://github.com/"或者在go.mod中指定SSH地址:
require github.com/yourorg/private v1.0.0
replace github.com/yourorg/private => git@github.com:yourorg/private.git v1.0.0确保你的环境有正确的SSH密钥,或者设置GOPRIVATE环境变量:
export GOPRIVATE="github.com/yourorg/*"6.3 真实案例:依赖丢失的“神秘失踪”
我曾在一个项目中遇到go build失败,提示某个依赖“not found”。原因是go.mod中指定的版本被上游删除,或者仓库被迁移。解决办法是找到可用的提交哈希(commit hash),用伪版本:
require github.com/some/lib v0.0.0-20230101000000-abcdef123456实战建议:
定期运行go mod tidy和go mod verify检查依赖完整性。
使用工具如golangci-lint或dependabot监控依赖更新。
在CI/CD中缓存go.sum和模块缓存,加速构建。
7. 错误处理的“艺术”:优雅而非抓狂
Go的错误处理以显式返回error为核心,简单却容易让人写出“丑陋”的代码。如何在简洁和健壮之间找到平衡,是一门技术活。
7.1 陷阱:忽略错误
新手最常见的错误是忽略error:
func main() {data, _ := ioutil.ReadFile("config.txt") // 忽略错误fmt.Println(string(data))
}如果config.txt不存在,程序会继续运行,但data是空的,后续逻辑可能彻底崩盘。
解决办法: 始终检查error:
func main() {data, err := ioutil.ReadFile("config.txt")if err != nil {log.Fatalf("Failed to read file: %v", err)}fmt.Println(string(data))
}小技巧: 使用log.Fatal或os.Exit在main函数中快速退出,或者返回错误给上层处理。
7.2 陷阱:重复的错误处理代码
错误处理容易导致代码冗长,比如:
func processFile() error {f, err := os.Open("input.txt")if err != nil {return err}defer f.Close()data, err := ioutil.ReadAll(f)if err != nil {return err}// 更多类似检查...
}优化方案: 使用errors.Wrap(来自github.com/pkg/errors)添加上下文:
func processFile() error {f, err := os.Open("input.txt")if err != nil {return errors.Wrap(err, "failed to open input file")}defer f.Close()data, err := ioutil.ReadAll(f)if err != nil {return errors.Wrap(err, "failed to read file")}return nil
}errors.Wrap不仅保留原始错误,还添加了调用栈信息,便于调试。
7.3 真实案例:错误丢失上下文
我曾遇到一个API服务,日志只记录了“invalid input”,但完全不知道是哪个字段出了问题。改进后:
func validateInput(input string) error {if input == "" {return errors.New("input cannot be empty")}if len(input) > 100 {return fmt.Errorf("input too long: %d characters", len(input))}return nil
}实战建议:
使用fmt.Errorf或errors.Wrap为错误添加上下文。
定义自定义错误类型,携带更多信息:
type ValidationError struct {Field stringMsg string
}func (e *ValidationError) Error() string {return fmt.Sprintf("validation failed for %s: %s", e.Field, e.Msg)
}8. 循环变量的“鬼影”:Goroutine中的捕获陷阱
我们已经在第3章提到过goroutine中的循环变量问题,但它值得单独拎出来说,因为这坑害了无数开发者。
8.1 陷阱:循环变量被覆盖
看这个代码:
func main() {items := []string{"a", "b", "c"}for _, item := range items {go func() {fmt.Println(item) // 可能全打印"c"}()}time.Sleep(time.Second)
}为什么? 因为item是循环变量,所有goroutine共享同一个变量地址,goroutine执行时,循环可能已经结束,item变成了最后一个值。
解决办法:
将变量显式传递给goroutine:
for _, item := range items {go func(s string) {fmt.Println(s) // 正确打印a, b, c}(item)
}或者在循环体内定义新变量:
for _, item := range items {s := itemgo func() {fmt.Println(s)}()
}实战建议: 养成习惯,在goroutine中使用循环变量时,总是显式传递或复制,避免“鬼影”作祟。
9. 内存管理的“隐秘角落”:垃圾回收与内存泄漏的博弈
Go语言的垃圾回收(GC)让开发者从手动内存管理的噩梦中解脱出来,但别以为有了GC就万事大吉。内存泄漏和性能瓶颈依然可能悄悄找上门,尤其在高并发或长时间运行的程序中。
9.1 陷阱:Goroutine导致的内存泄漏
Goroutine是Go的杀手锏,但如果管理不当,它会像“吃内存的小怪兽”。来看一个经典案例:
func leakyServer() {ch := make(chan int)go func() {for {<-ch // 阻塞等待,但没人发送数据}}()
}问题在哪? 如果ch永远没人发送数据,这个goroutine会一直阻塞,占用内存,无法被GC回收。如果这种goroutine成千上万,内存就“雪崩”了。
解决办法: 使用context包控制goroutine生命周期:
func safeServer(ctx context.Context) {ch := make(chan int)go func() {for {select {case <-ctx.Done():return // 上下文取消,goroutine退出case <-ch:// 处理数据}}}()
}func main() {ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)defer cancel()safeServer(ctx)
}小贴士: 总是为goroutine设置退出机制,比如context或关闭channel,避免“僵尸goroutine”。
9.2 陷阱:字符串与切片的内存陷阱
字符串和切片在Go中看似简单,但它们与底层数组的交互可能导致内存浪费。看这个例子:
func processLargeData(data string) string {return data[:100] // 取前100个字符
}func main() {largeData := strings.Repeat("x", 1000000) // 1MB字符串smallData := processLargeData(largeData)fmt.Println(len(smallData)) // 输出:100// 但largeData的整个1MB内存依然被引用!
}为什么内存没释放? 因为smallData是largeData的子字符串,共享同一个底层字节数组。GC无法回收largeData,即使你只需要100字节。
解决办法: 强制复制数据,断开引用:
func processLargeData(data string) string {return string([]byte(data[:100])) // 复制到新数组
}这样,largeData的原始内存可以被GC回收。类似的问题也出现在切片操作中,记得用copy创建独立副本。
9.3 真实案例:对象池的内存陷阱
我在一个高并发服务中见过这样的代码,用sync.Pool缓存对象以提高性能:
var pool = sync.Pool{New: func() interface{} {return &Buffer{Data: make([]byte, 1024)}},
}type Buffer struct {Data []byte
}func process() {buf := pool.Get().(*Buffer)// 使用buf.Datapool.Put(buf) // 放回池中
}看似没问题,但如果buf.Data被外部引用(比如传递给另一个goroutine),放回sync.Pool后可能导致未定义行为。
修复方案: 重置对象状态:
func process() {buf := pool.Get().(*Buffer)defer func() {buf.Data = buf.Data[:0] // 重置切片pool.Put(buf)}()// 使用buf.Data
}实战建议:
用runtime.GC()和runtime.MemStats调试内存问题。
定期监控服务的内存使用情况,推荐工具如pprof。
在高并发场景下,谨慎使用sync.Pool,确保对象状态可控。
10. 性能优化的“锦囊妙计”:从微优化到架构调整
Go以性能著称,但写出高性能代码并不简单。很多开发者在追求“快”时,掉进了“过度优化”或“忽视瓶颈”的陷阱。
10.1 陷阱:字符串拼接的性能黑洞
字符串在Go中是不可变的,频繁拼接会导致大量内存分配和拷贝。看这个低效代码:
func buildString(n int) string {result := ""for i := 0; i < n; i++ {result += fmt.Sprintf("%d", i) // 每次拼接都分配新字符串}return result
}问题: 每次+=都会创建一个新字符串,性能随n增大而急剧下降。
优化方案: 使用strings.Builder:
func buildString(n int) string {var builder strings.Builderfor i := 0; i < n; i++ {builder.WriteString(fmt.Sprintf("%d", i))}return builder.String()
}strings.Builder通过预分配缓冲区,减少内存分配,性能提升可达数倍。
小技巧: 如果涉及复杂格式化,考虑bytes.Buffer或预分配切片:
func buildString(n int) string {buf := make([]byte, 0, n*2) // 预估容量for i := 0; i < n; i++ {buf = append(buf, []byte(fmt.Sprintf("%d", i))...)}return string(buf)
}10.2 陷阱:不必要的接口装箱
接口(interface)虽然强大,但每次赋值都会触发“装箱”(boxing),带来性能开销。看例子:
func sum(values []interface{}) int {total := 0for _, v := range values {total += v.(int) // 类型断言,性能开销}return total
}如果明确知道类型,直接用具体类型:
func sum(values []int) int {total := 0for _, v := range values {total += v}return total
}性能对比: 使用具体类型可以减少装箱和类型断言的开销,尤其在高频调用场景下。
10.3 真实案例:JSON序列化的性能瓶颈
我曾优化一个API服务,发现JSON序列化占用了大量CPU。原始代码:
type User struct {Name stringAge int
}func toJSON(users []User) string {data, _ := json.Marshal(users)return string(data)
}问题: json.Marshal每次都动态反射结构体字段,性能较差。对于固定结构,推荐使用encoding/json的Encoder或第三方库如github.com/json-iterator/go:
func toJSON(users []User) string {var buf bytes.Bufferenc := json.NewEncoder(&buf)enc.Encode(users)return buf.String()
}进阶优化: 如果性能要求极高,尝试json-iterator:
import jsoniter "github.com/json-iterator/go"func toJSON(users []User) string {data, _ := jsoniter.Marshal(users)return string(data)
}实战建议:
使用pprof定位性能瓶颈,聚焦热点代码。
优先优化高频路径,避免“过早优化”。
在性能敏感场景下,考虑代码生成工具(如ffjson)加速JSON处理。
11. 测试中的“隐藏雷区”:写出健壮的单元测试
Go的测试框架简单易用,但写出高质量的测试并不容易。很多开发者在测试中忽略了边界情况,或者让测试代码变得脆弱。
11.1 陷阱:忽略错误场景
很多测试只关注“成功路径”,忽略错误处理。看这个例子:
func Divide(a, b int) (int, error) {if b == 0 {return 0, errors.New("division by zero")}return a / b, nil
}func TestDivide(t *testing.T) {result, err := Divide(10, 2)if err != nil || result != 5 {t.Errorf("Expected 5, got %d", result)}
}问题: 没有测试b==0的错误场景。如果代码逻辑改变,错误分支可能失效。
修复方案: 使用表驱动测试覆盖多种场景:
func TestDivide(t *testing.T) {tests := []struct {a, b intexpected interr error}{{10, 2, 5, nil},{10, 0, 0, errors.New("division by zero")},{-10, 2, -5, nil},}for _, tt := range tests {t.Run(fmt.Sprintf("%d/%d", tt.a, tt.b), func(t *testing.T) {result, err := Divide(tt.a, tt.b)if !errors.Is(err, tt.err) {t.Errorf("Expected error %v, got %v", tt.err, err)}if result != tt.expected {t.Errorf("Expected %d, got %d", tt.expected, result)}})}
}小技巧: 使用errors.Is或errors.As检查错误类型,兼容errors.Wrap等场景。
11.2 陷阱:测试依赖外部资源
依赖数据库或网络的测试不稳定且慢。看这个例子:
func TestFetchUser(t *testing.T) {user, err := FetchUserFromDB("alice")if err != nil || user.Name != "Alice" {t.Errorf("Expected Alice, got %v", user)}
}问题: 如果数据库挂了,测试就失败,维护成本高。
解决办法: 使用接口和Mock:
type UserStore interface {GetUser(id string) (*User, error)
}type MockUserStore struct{}func (m *MockUserStore) GetUser(id string) (*User, error) {return &User{Name: "Alice"}, nil
}func TestFetchUser(t *testing.T) {store := &MockUserStore{}user, err := FetchUser(store, "alice")if err != nil || user.Name != "Alice" {t.Errorf("Expected Alice, got %v", user)}
}实战建议:
使用testing.TB接口支持Test和Benchmark复用代码。
借助testify或gomock简化Mock生成。
定期运行go test -cover检查测试覆盖率。
12. 上下文的“双刃剑”:Context的正确使用与常见误区
Go的context包是并发编程的利器,常用于控制goroutine的生命周期、传递请求范围的值。但它的灵活性也带来了不少误用场景,稍不留神就可能让代码变得混乱或不可靠。
12.1 陷阱:Context泄漏
context的一个常见问题是未正确取消,导致goroutine或资源泄漏。看这个例子:
func fetchData(ctx context.Context, url string) (string, error) {go func() {// 模拟耗时操作time.Sleep(10 * time.Second)fmt.Println("Data fetched from", url)}()return "mock data", nil
}问题在哪? fetchData启动了一个goroutine,但完全忽略了ctx。如果调用者取消了上下文,这个goroutine依然会运行10秒,浪费资源。
解决办法: 在goroutine中监听ctx.Done():
func fetchData(ctx context.Context, url string) (string, error) {ch := make(chan string)go func() {select {case <-ctx.Done():return // 上下文取消,立即退出case <-time.After(10 * time.Second):ch <- "mock data"}}()select {case <-ctx.Done():return "", ctx.Err()case result := <-ch:return result, nil}
}小贴士: 总是确保goroutine能响应ctx.Done(),避免“僵尸goroutine”。
12.2 陷阱:滥用Context传值
context可以携带请求范围的值,但滥用会导致代码难以维护。看这个例子:
func handleRequest(ctx context.Context) {userID := ctx.Value("userID").(string) // 类型断言,危险!fmt.Println("User:", userID)
}问题: 用ctx.Value传递关键业务逻辑(如用户ID)会导致:
类型不安全,可能引发panic。
代码耦合,调用者必须知道键名"userID"。
调试困难,值来源不明确。
解决办法: 优先使用显式参数传递:
func handleRequest(ctx context.Context, userID string) {fmt.Println("User:", userID)
}如果确实需要用context传值,定义明确的键类型:
type contextKey stringconst UserIDKey contextKey = "userID"func handleRequest(ctx context.Context) {if userID, ok := ctx.Value(UserIDKey).(string); ok {fmt.Println("User:", userID)} else {fmt.Println("No user ID")}
}实战建议: 限制ctx.Value的使用场景,仅用于请求范围的元数据(如追踪ID),避免将其变成“全局变量”。
12.3 真实案例:超时控制的“失灵”
我曾见过一个API服务,设置了1秒超时,但实际请求耗时远超预期:
func callAPI(ctx context.Context, url string) error {client := &http.Client{}req, _ := http.NewRequest("GET", url, nil)resp, err := client.Do(req) // 忽略ctxif err != nil {return err}defer resp.Body.Close()return nil
}问题: http.Client的默认行为不响应ctx的超时。正确做法是用ctx创建请求:
func callAPI(ctx context.Context, url string) error {client := &http.Client{}req, _ := http.NewRequestWithContext(ctx, "GET", url, nil)resp, err := client.Do(req)if err != nil {return err}defer resp.Body.Close()return nil
}小技巧: 为http.Client设置全局超时,防止意外的长耗时:
var client = &http.Client{Timeout: 5 * time.Second,
}13. 标准库的“隐藏宝藏”:被忽视的实用功能
Go的标准库强大而简洁,但很多开发者只用到了它的“冰山一角”。下面介绍几个容易被忽视但超级实用的功能,帮你写出更优雅的代码。
13.1 陷阱:重复造轮子
很多开发者习惯自己实现一些常见功能,比如深拷贝或时间格式化,其实标准库已经提供了现成方案。看这个低效的深拷贝:
func copySlice(src []int) []int {dst := make([]int, len(src))for i, v := range src {dst[i] = v}return dst
}优化方案: 使用copy函数:
func copySlice(src []int) []int {dst := make([]int, len(src))copy(dst, src)return dst
}copy不仅更简洁,还经过高度优化,性能更佳。
13.2 隐藏宝藏:time包的高级用法
time包不仅能获取当前时间,还有很多实用功能。比如,定时任务:
func scheduleTask() {ticker := time.NewTicker(1 * time.Second)defer ticker.Stop()for {select {case t := <-ticker.C:fmt.Println("Task executed at", t)case <-time.After(5 * time.Second):fmt.Println("Task stopped")return}}
}小技巧: 使用time.Tick进行简单定时任务,但注意它不会自动回收,建议用time.NewTicker并显式Stop。
13.3 真实案例:高效的日志记录
很多开发者用fmt.Println打日志,但标准库的log包更强大,支持时间戳和文件输出:
func main() {log.SetFlags(log.Ldate | log.Ltime | log.Lshortfile)log.Println("Starting server...")
}输出示例:2025/07/12 01:50:00 main.go:10: Starting server...
进阶玩法: 用log.New自定义日志输出到文件:
func main() {file, _ := os.OpenFile("app.log", os.O_CREATE|os.O_APPEND|os.O_WRONLY, 0644)logger := log.New(file, "APP: ", log.LstdFlags|log.Lshortfile)logger.Println("Server started")
}实战建议:
探索sync.Once实现单例初始化。
用io.MultiWriter将日志同时输出到多个目标。
善用net/http/httptest进行HTTP测试,模拟请求和响应。
14. 生产环境调试的“救命稻草”:定位问题不抓狂
生产环境的Bug往往比开发环境更难定位,日志不全、复现困难、性能瓶颈……这些都可能让你抓狂。以下是几个实用调试技巧。
14.1 陷阱:日志信息不足
生产环境中,日志是定位问题的第一线索,但很多开发者只记录错误信息,缺少上下文。看这个例子:
func processOrder(orderID string) error {log.Println("Error processing order")return errors.New("failed")
}问题: 日志没说明哪个订单、失败原因,排查起来像大海捞针。
解决办法: 添加上下文:
func processOrder(orderID string) error {log.Printf("Processing order %s", orderID)if err := validateOrder(orderID); err != nil {log.Printf("Failed to process order %s: %v", orderID, err)return fmt.Errorf("process order %s: %w", orderID, err)}return nil
}小技巧: 使用%w包装错误,保留原始错误信息,便于上层处理。
14.2 陷阱:性能问题难定位
生产环境中,性能瓶颈可能来自CPU、内存或I/O。Go的pprof工具是救星。看如何使用:
func main() {go func() {log.Println(http.ListenAndServe("localhost:6060", nil)) // 开启pprof}()// 业务逻辑
}运行后,访问http://localhost:6060/debug/pprof获取性能数据,或用命令行:
go tool pprof http://localhost:6060/debug/pprof/profile?seconds=30实战案例: 我曾用pprof发现一个服务的高CPU占用来自频繁的字符串拼接(类似第10章的例子)。通过切换到strings.Builder,CPU占用降低了50%。
14.3 真实案例:死锁的“无形杀手”
生产环境中,死锁可能导致服务挂起。看这个例子:
func worker(ch chan int, mu *sync.Mutex) {mu.Lock()ch <- 1 // 阻塞,等待接收mu.Unlock()
}如果ch无人接收,mu永远不释放,导致死锁。
解决办法: 用select避免阻塞:
func worker(ch chan int, mu *sync.Mutex) {mu.Lock()defer mu.Unlock()select {case ch <- 1:// 成功发送default:log.Println("Channel blocked, skipping")}
}实战建议:
在生产环境中启用runtime.SetMutexProfileFraction(1)收集锁竞争数据。
使用dlv调试器单步执行复杂逻辑。
定期分析日志,借助工具如ELK或Grafana可视化问题。
15. Go开发的“潜规则”:写出优雅代码的秘诀
Go语言推崇简洁和一致性,但有些“潜规则”不写在文档里,却能让你的代码更专业。
15.1 潜规则:命名要“自解释”
Go强调清晰的命名,避免缩写或模糊名称。看这个例子:
func calc(a, b int) int { // 差return a + b
}改进:
func CalculateSum(first, second int) int { // 清晰return first + second
}小贴士: 方法名用动词开头,结构体字段用名词,包名用单数(如http而非https)。
15.2 潜规则:错误处理优先于成功路径
Go开发者习惯先处理错误,确保代码健壮:
func processData(data []byte) ([]byte, error) {if len(data) == 0 {return nil, errors.New("empty data")}// 成功路径return process(data), nil
}15.3 真实案例:代码审查的“雷区”
我曾参与一个项目的代码审查,发现大量“隐式假设”。比如:
func getUser(id string) *User {return db.QueryUser(id) // 假设db.QueryUser永远返回非nil
}改进: 显式检查返回值:
func getUser(id string) (*User, error) {user := db.QueryUser(id)if user == nil {return nil, errors.New("user not found")}return user, nil
}实战建议:
遵循Go的惯例,使用gofmt和golint保持代码风格一致。
优先使用标准库,减少外部依赖。
在团队中推广“代码即文档”的理念,减少注释,依靠清晰的代码表达意图。
 在PyInstaller打包前后的区别)

基础支持模块(游戏窗口、游戏对象、物理系统、动画系统、射线检测))










--流密码)





)