✅步骤一:安装 PyTorch(M1 专用)
# 推荐使用官方 MPS 后端(Apple Metal 加速)
pip install torch torchvision torchaudio确认是否使用了 Apple MPS:

import torch
print(torch.backends.mps.is_available())# True 表示支持
✅ 步骤二:安装 OpenCV(预编译版)
pip install opencv-python==4.8.0.76
如仍失败,可以降级到更稳定的版本:

pip install opencv-python==4.6.0.66
✅ 步骤三:安装 Ultralytics(YOLOv8)
这个会去依赖opencv
pip install ultralytics --no-binary opencv-python或者,使用无依赖模式(跳过 OpenCV 的再次依赖):
pip install ultralytics --no-deps 
✅ 步骤四:验证安装

yolo version
如果输出了版本号(如 Ultralytics YOLOv8.1.26 等)说明一切正常。
✅ 测试 YOLOv8 是否能跑起来
你可以运行一个简单的预测命令测试模型:
yolo task=detect mode=predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'

这会下载一个图片并进行目标检测,自动弹出预测窗口(或保存预测图像)。

🔧 1、识别人物-整体流程总览
准备数据集(图像 + 标注)
数据集格式转换(转为 YOLO 格式)
安装 YOLOv8(ultralytics)
配置训练参数(模型、类别、路径)
开始训练
验证和测试
部署使用
🧩 2、每一步分模块详解
📁 1. 数据采集与标注(图像和标注文件)
需要采集图像并对目标进行手动标注。
✅ 推荐免费标注工具(支持导出为 YOLO 格式):
| 工具名 | 平台 | 特点说明 |
|---|---|---|
| LabelImg | Windows / Mac / Linux | 本地运行,轻量,支持 Pascal VOC 和 YOLO 格式 |
| Roboflow | 在线工具 | 免费计划支持上传图像、标注、自动转换格式 |
| Labelme | Python 工具 | 支持多边形标注,也可导出为 COCO 格式 |
| CVAT | 在线部署或本地部署 | 适合大规模标注,功能强大,支持团队协作 |
👉 建议初学者使用 LabelImg 或 Roboflow,操作直观,输出格式直接支持 YOLO。
🔄 2. 转换数据集为 YOLO 格式
YOLO 格式标注样例如下(txt 文件):0 0.5 0.5 0.2 0.3
格式说明:
[class_id] [x_center] [y_center] [width] [height]
都是相对坐标(比例,相对于图片大小)。
如果你标注格式不是 YOLO,需要转换,比如从 VOC / COCO → YOLO,可以使用:
Roboflow 自动转换
labelme2yolo工具roboflowpython 工具包
📁 3、 roboflow标注(图像和标注文件)
可以搜索教程怎么标记要训练的数据
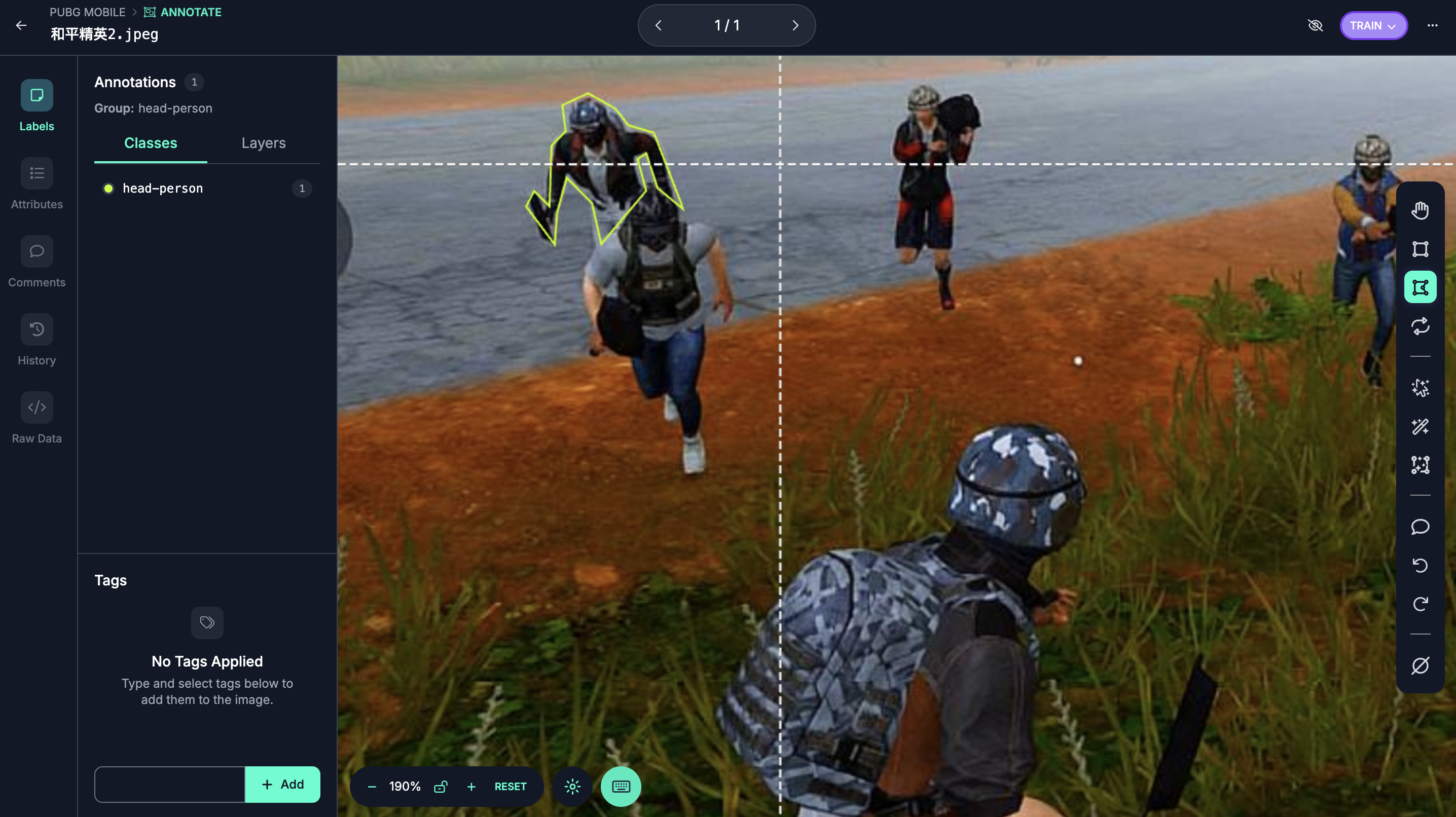
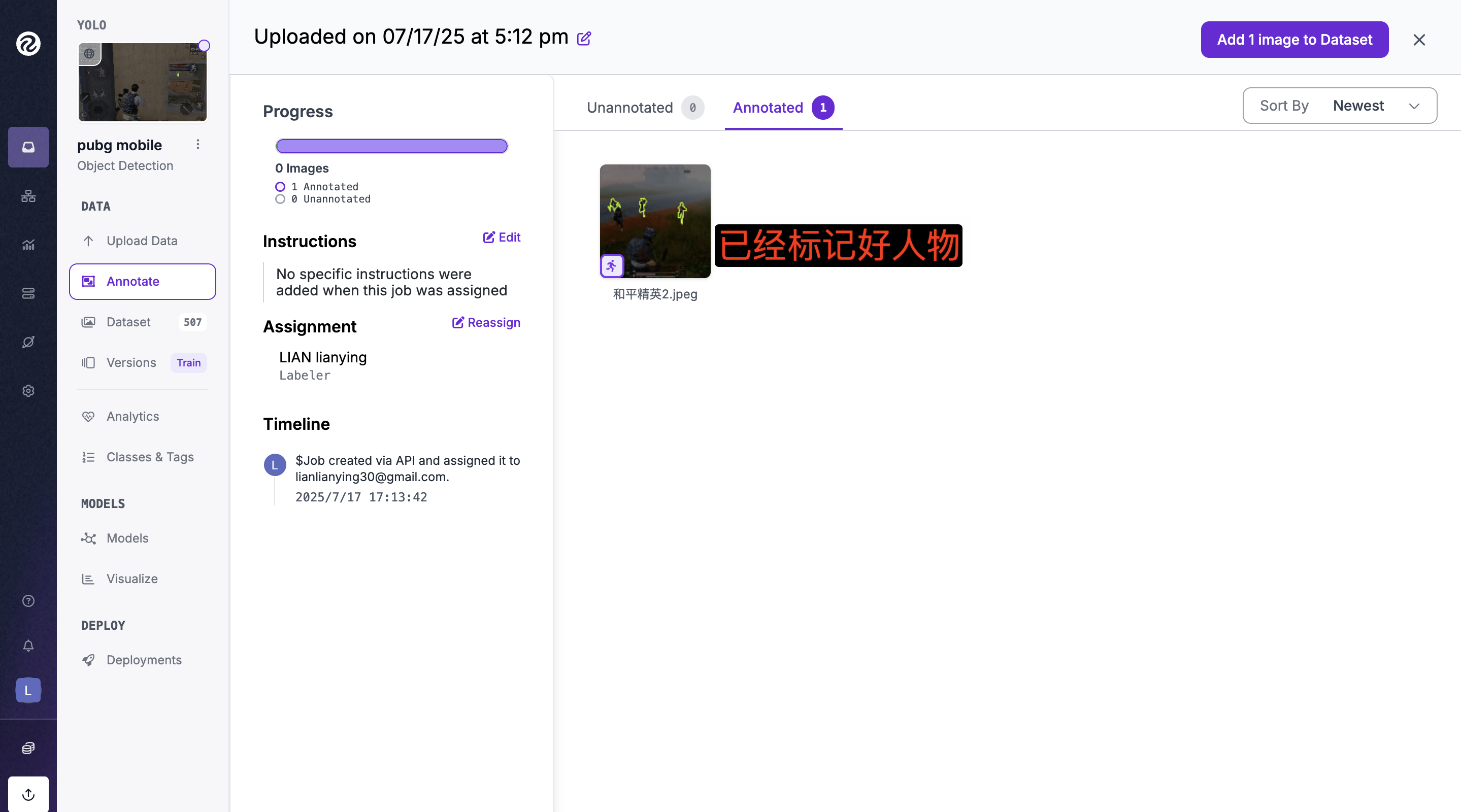
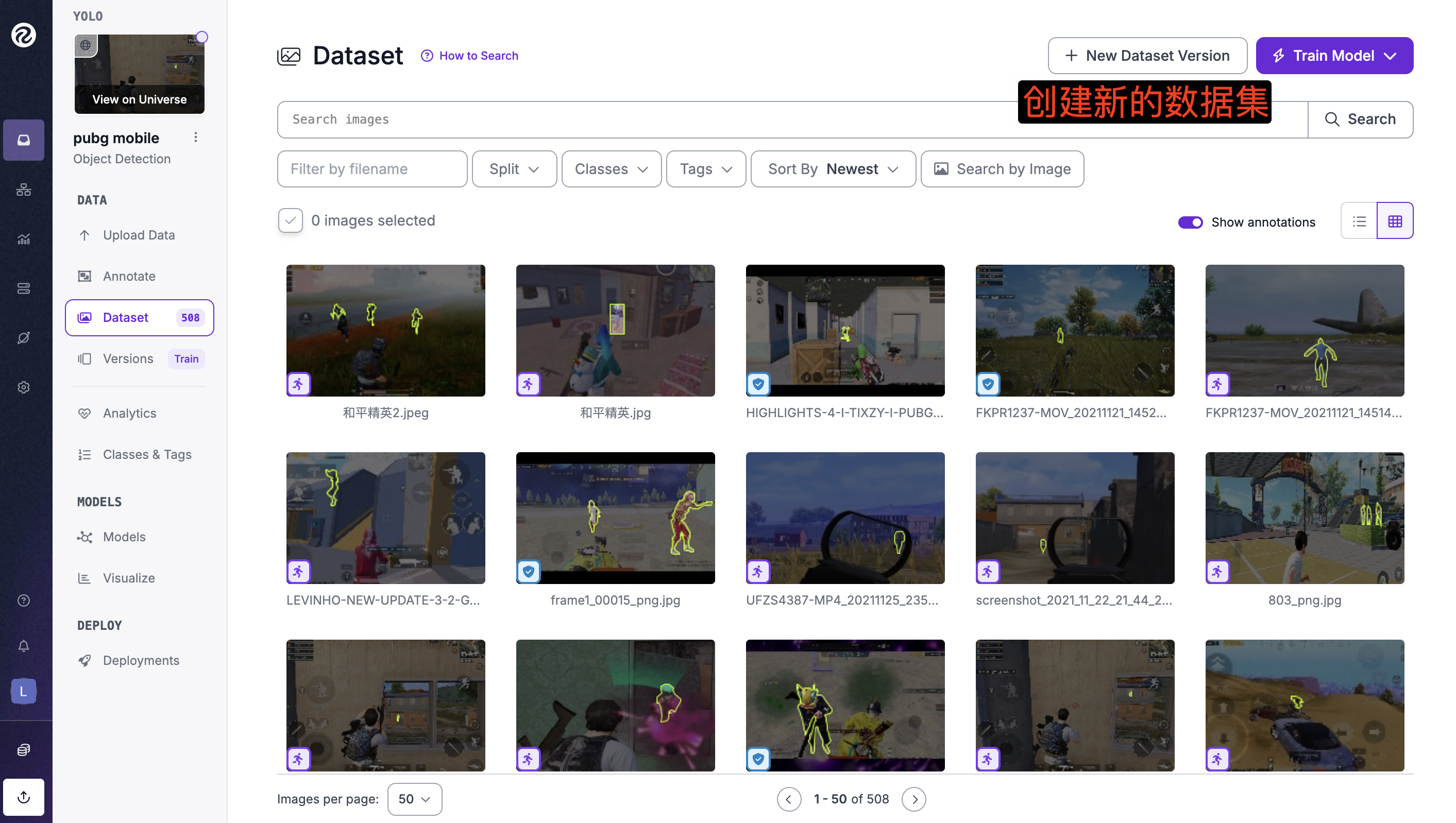
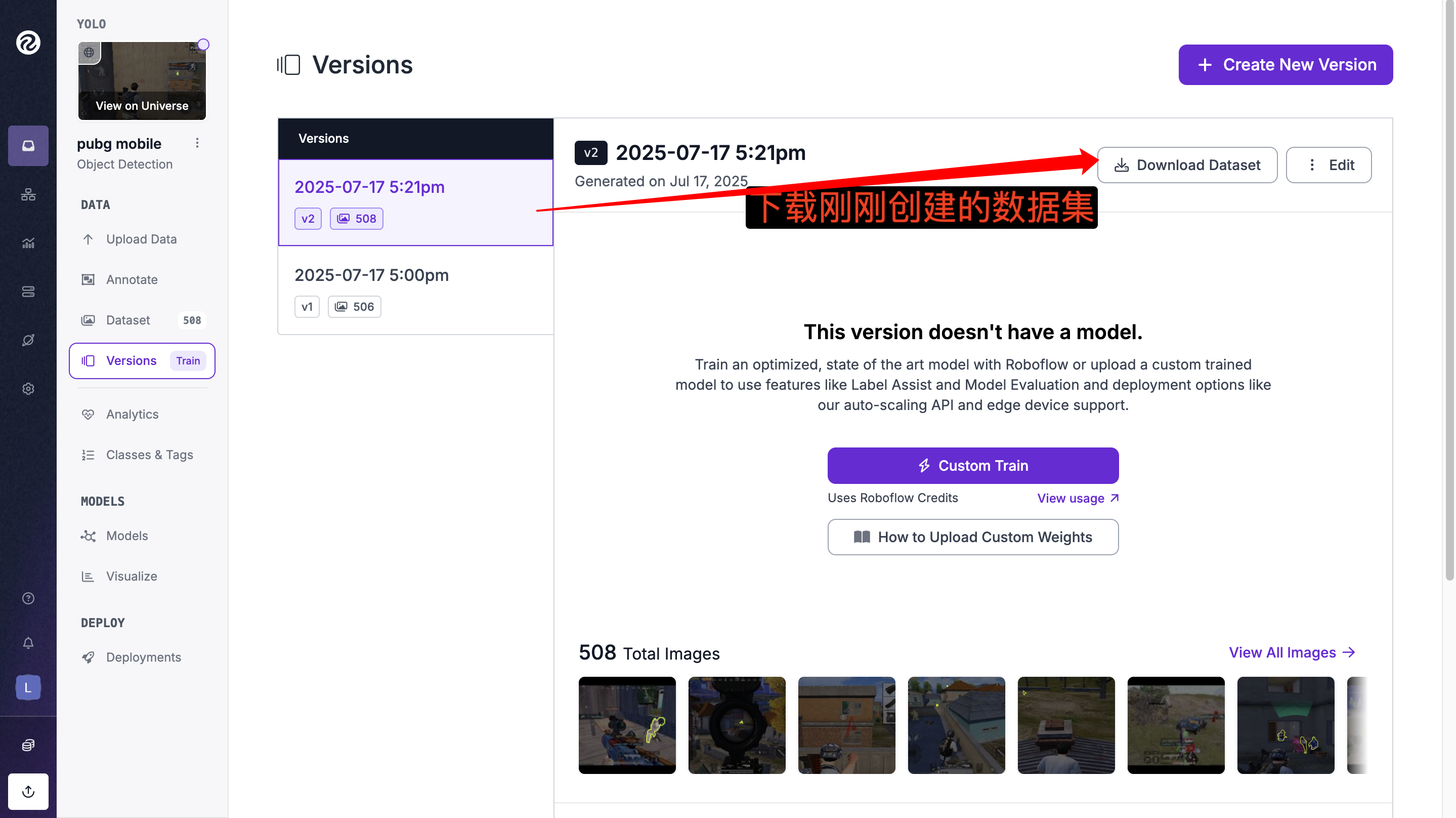
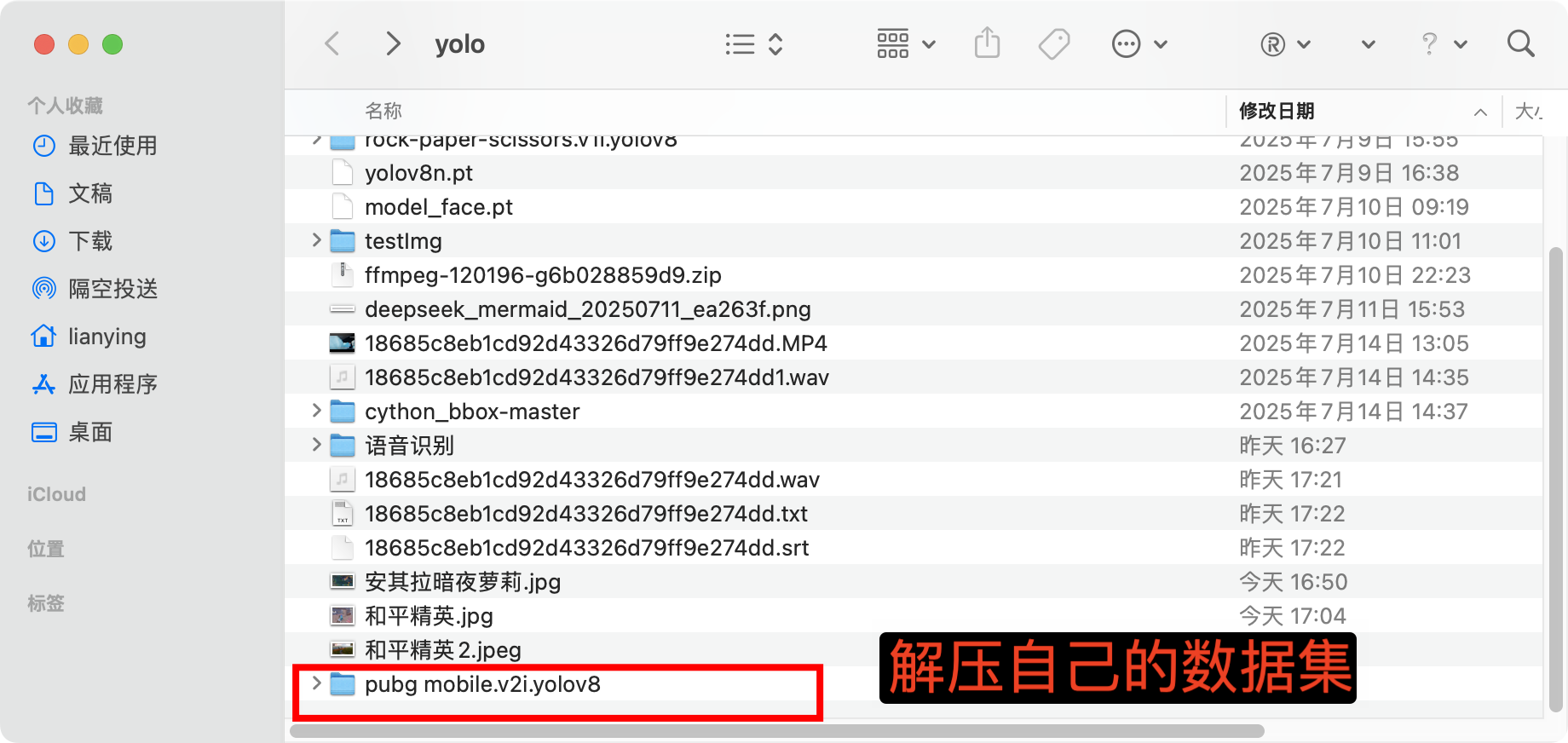
✅ 3、开始训练识别和平精英人物识别
🔧 model.train() 常用参数解析
| 参数 | 类型 | 说明 |
|---|---|---|
data | str | 数据集配置文件路径(例如 data.yaml) |
epochs | int | 训练轮数(epoch 数) |
imgsz | int 或 tuple | 输入图片尺寸,默认 640(可为整数或 (h,w) 元组) |
batch | int | 每批训练的图像数量,默认 16 |
device | int 或 str | 使用的设备,例如 '0'(GPU0)、'cpu' 或 '0,1' |
save | bool | 是否保存模型(默认 True) |
exist_ok | bool | 是否允许覆盖已有运行目录 |
resume | bool | 是否从上次训练中断处恢复 |
patience | int | 如果验证指标在这么多 epoch 内不再提升,则提前停止训练(默认 50) |
optimizer | str | 选择优化器:SGD、Adam、AdamW(默认 SGD) |
lr0 | float | 初始学习率(默认 0.01) |
lrf | float | 最终学习率与初始学习率的比值(默认 0.01) |
momentum | float | 动量参数(仅用于 SGD) |
weight_decay | float | 权重衰减(默认 0.0005) |
workers | int | 数据加载线程数(建议 0 或 2~8) |
pretrained | bool 或 str | 使用预训练模型(True 或权重路径) |
project | str | 日志文件保存路径 |
name | str | 本次运行的名称,结果将保存在 runs/train/name/ 下 |
verbose | bool | 显示更多训练信息 |
seed | int | 设置随机种子以保证复现性 |
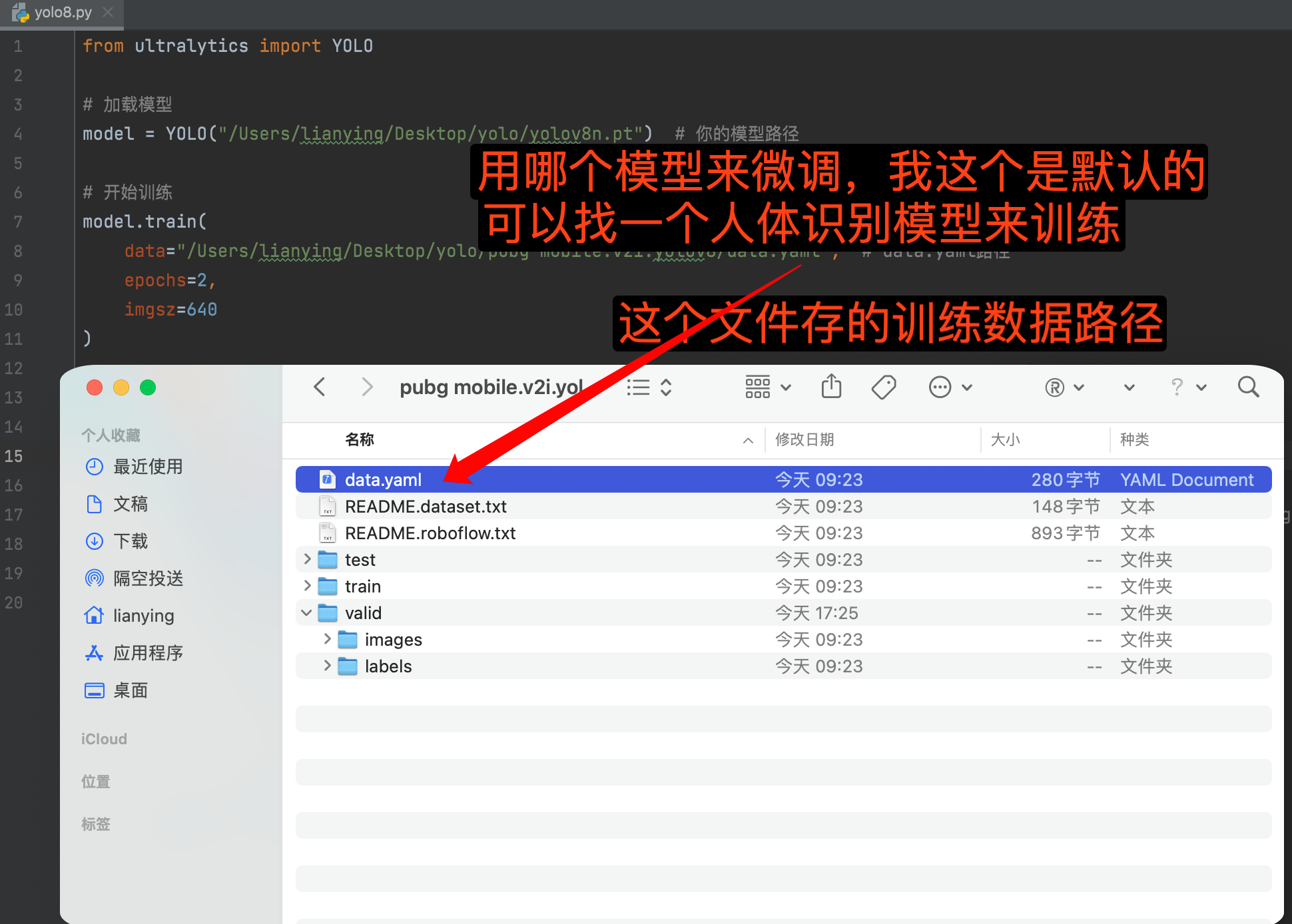
📌 数据集配置文件(data.yaml)结构:

from ultralytics import YOLO# 加载模型
model = YOLO("/Users/lianying/Desktop/yolo/yolov8n.pt") # 你的模型路径# 开始训练
model.train(data="/Users/lianying/Desktop/yolo/pubg mobile.v2i.yolov8/data.yaml", # data.yaml路径epochs=2,imgsz=640
)
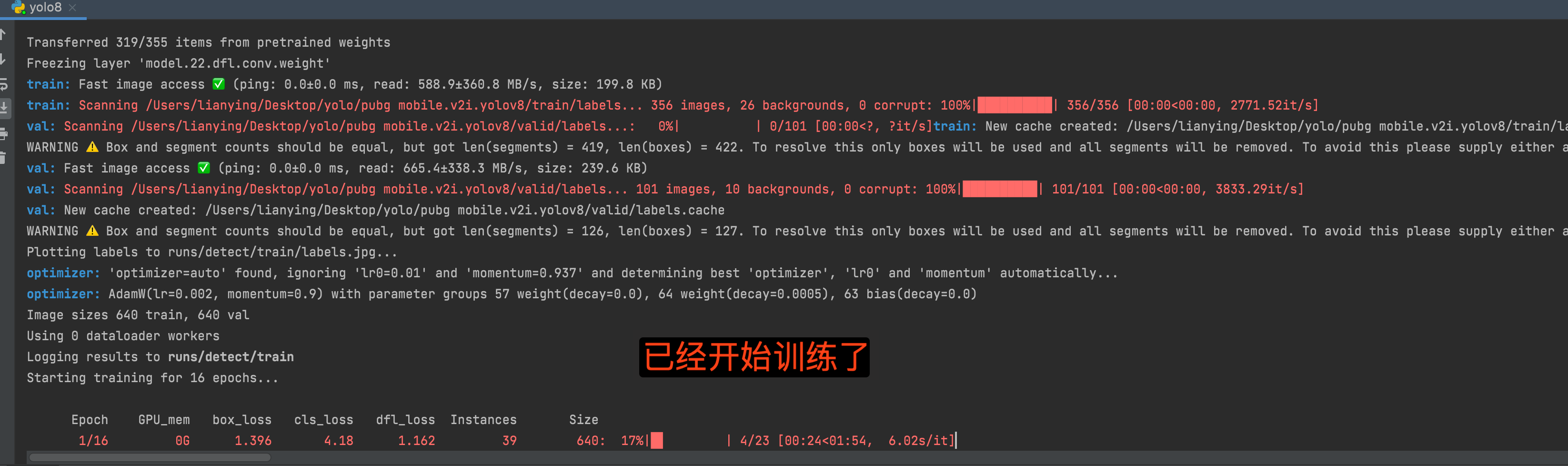
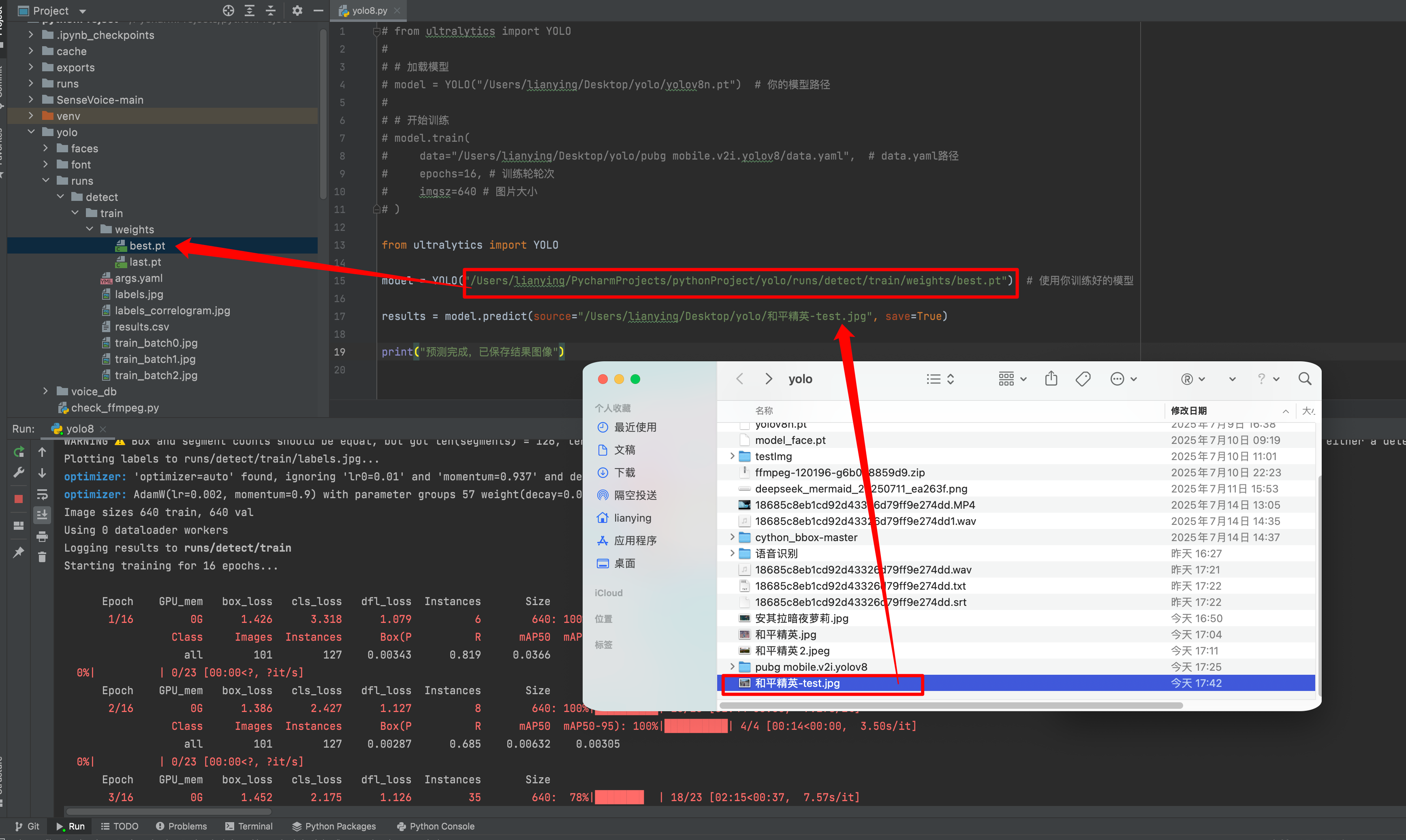
在使用 YOLOv8(如 Ultralytics YOLOv8)训练模型后,输出目录(通常是 runs/detect/train)中会生成两个主要的模型文件:
✅ best.pt
含义:在训练过程中,在验证集上表现最好的模型(通常指 mAP 值最高)。
用途:用于部署或实际推理时的首选模型。
保存时机:每轮训练后都会验证一次性能,若当前 mAP 更优于之前所有轮次,就保存为
best.pt。
✅ last.pt
含义:训练最后一轮保存的模型。
用途:
若训练中断,可以从
last.pt恢复继续训练;如果对
best.pt不满意,也可以尝试last.pt。
🛠 选择哪个用于推理?
| 文件名 | 适用场景 | 建议 |
|---|---|---|
best.pt | 精度优先的推理部署 | ✅ 推荐使用 |
last.pt | 继续训练、对比测试 | 可选(不推荐部署) |
🛠 加载方式
使用 YOLO 类加载模型:
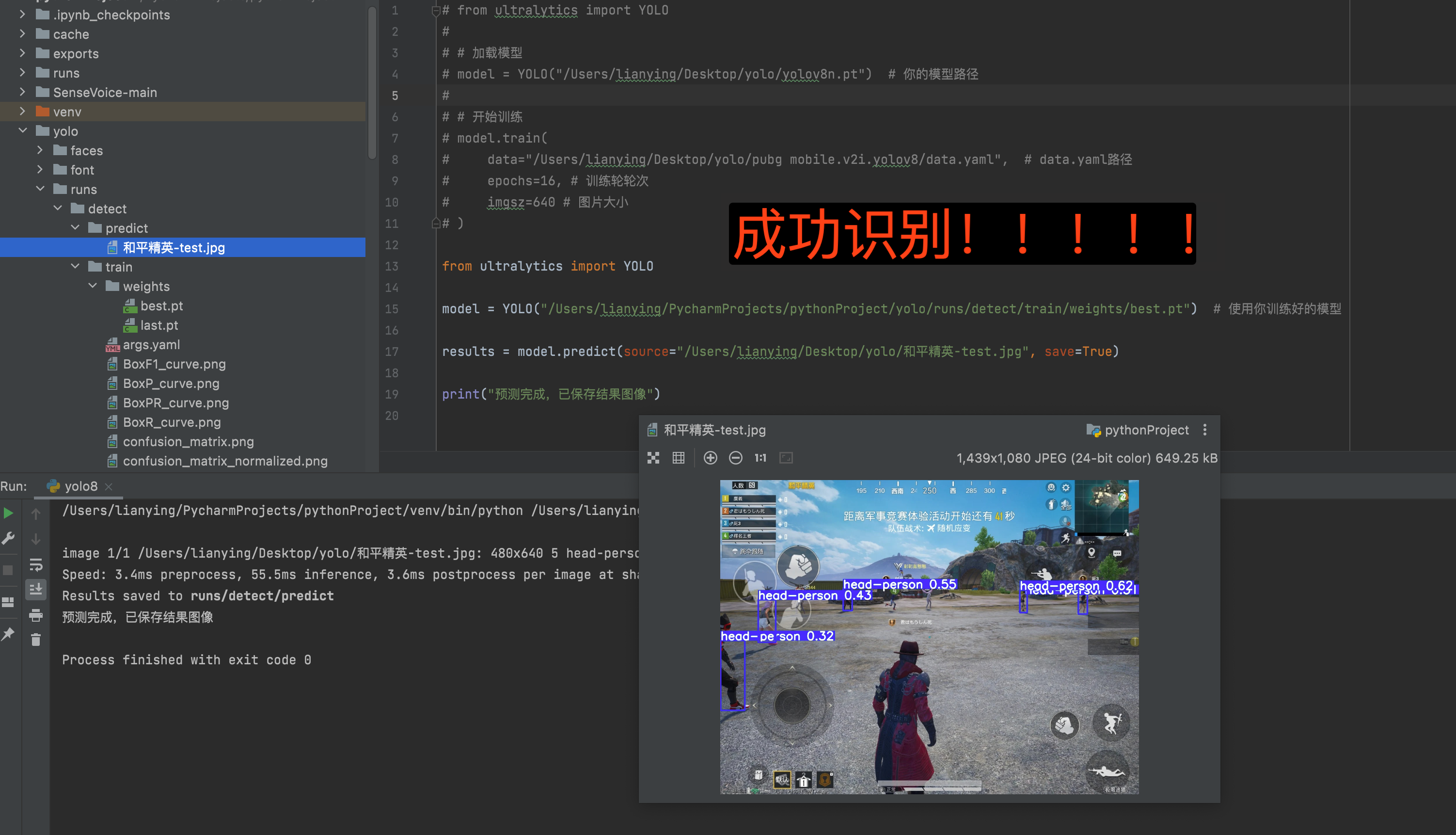
from ultralytics import YOLOmodel = YOLO("runs/detect/train/weights/best.pt") # 加载最优模型








完整指南)



![[实战]巴特沃斯滤波器全流程解析:从数学原理到硬件实现](http://pic.xiahunao.cn/[实战]巴特沃斯滤波器全流程解析:从数学原理到硬件实现)

详解 + Python实现)

安装包免费免激活版下载 附图文详细安装教程)
(补题))

![[Linux]git_gdb](http://pic.xiahunao.cn/[Linux]git_gdb)