爬虫04 - 高级数据存储
文章目录
- 爬虫04 - 高级数据存储
- 一:加密数据的存储
- 二:JSON Schema校验
- 三:云原生NoSQL(了解)
- 四:Redis Edge近端计算(了解)
- 五:二进制存储
- 1:Pickle
- 2:Parquet
一:加密数据的存储
对于用户的隐私数据,可能需要进行数据的加密才能存储到文件或者数据库,因为要遵守《个人信息保护法》
所以对于这些隐私数据处理顺序是:明文数据 → AES加密 → 密文字节流 → 序列化(如Base64) → 存储至文件
from Crypto.Cipher import AES
from Crypto.Random import get_random_bytes
import base64
import json# 第一步:生成256位(32字节)密钥 + 16字节IV(CBC模式必需)
key = get_random_bytes(32)
iv = get_random_bytes(16)# 第二步:加密数据
def encrypt_data(data: str, key: bytes, iv: bytes) -> bytes:cipher = AES.new(key, AES.MODE_CBC, iv)data_bytes = data.encode('utf-8')# PKCS7填充至分组长度倍数pad_len = AES.block_size - (len(data_bytes) % AES.block_size)padded_data = data_bytes + bytes([pad_len] * pad_len)return cipher.encrypt(padded_data)plain_text = "用户机密数据:张三|13800138000|身份证1101..."
encrypted_bytes = encrypt_data(plain_text, key, iv)# 第三步:转成base64并写入json文件中
encrypted_b64 = base64.b64encode(iv + encrypted_bytes).decode('utf-8')# 写入文件(JSON示例)
with open("encrypted_data.json", "w") as f:json.dump({"encrypted_data": encrypted_b64}, f)# 第四步,读取文件并解密
def decrypt_data(encrypted_b64: str, key: bytes) -> str:encrypted_full = base64.b64decode(encrypted_b64)iv = encrypted_full[:16] # 提取IVciphertext = encrypted_full[16:]cipher = AES.new(key, AES.MODE_CBC, iv)decrypted_padded = cipher.decrypt(ciphertext)# 去除PKCS7填充pad_len = decrypted_padded[-1]return decrypted_padded[:-pad_len].decode('utf-8')# 从文件读取并解密
with open("encrypted_data.json", "r") as f:data = json.load(f)
decrypted_text = decrypt_data(data["encrypted_data"], key)
print(decrypted_text) # 输出原始明文
二:JSON Schema校验
在爬虫开发中,JSON因其轻量、易读和跨平台特性,成为数据存储的主流格式。
然而,面对动态变化的网页结构或API响应,未经校验的JSON数据可能导致字段缺失、类型混乱甚至数据污染,进而引发下游分析错误或系统崩溃。本文聚焦JSON Schema校验,结合Python的jsonschema库,详解如何为爬虫数据“上保险”,确保存储的JSON文件结构合法、字段完整,为数据质量筑起第一道防线。
| 规则 | 场景实例 |
|---|---|
| required | 确保商品名称、价格等核心字段必填 |
| enum | 限定状态字段为[“已售罄”, “在售”] |
| pattern | 验证手机号、邮箱格式合法性 |
| custom format | 使用date-time校验爬取时间戳格式 |
| oneOf/anyOf | 处理多态结构(如不同店铺的商品模型) |
from jsonschema import validate, ValidationError
import json
from datetime import datetime
import logging# 定义商品数据Schema
product_schema = {"type": "object","required": ["title", "price"], # 必须包含title和price字段"properties": { # 定义字段类型和范围"title": {"type": "string"}, # title字段类型为字符串"price": {"type": "number", "minimum": 0}, # price字段类型为数字,最小值为0"currency": {"enum": ["CNY", "USD"]}, # currency字段类型为枚举,可选值为CNY和USD"images": {"type": "array", "items": {"type": "string", "format": "uri"}} # images字段类型为数组,数组元素类型为字符串,格式为URI}
}# 验证商品数据, 对于传入的数据进行验证,返回验证结果和错误信息
def validate_product(data: dict):try:validate(instance=data, schema=product_schema)return True, Noneexcept ValidationError as e:return False, f"校验失败:{e.message} (路径:{e.json_path})"def save_product(data: dict):# 校验数据合法性is_valid, error = validate_product(data)if not is_valid:logging.error(f"数据丢弃:{error}")return# 添加爬取时间戳data["crawled_time"] = datetime.now().isoformat()# 写入JSON文件(按行存储)with open("products.jsonl", "a") as f:f.write(json.dumps(data, ensure_ascii=False) + "\n")
三:云原生NoSQL(了解)
传统自建的noSQL有如下的问题:
- 运维黑洞:分片配置、版本升级、备份恢复消耗30%以上开发精力。
- 扩展滞后:突发流量导致集群扩容不及时,引发数据丢失或性能瓶- 颈。
- 容灾脆弱:自建多机房方案成本高昂,且故障切换延迟高。
- 安全风险:未及时修补漏洞导致数据泄露,合规审计难度大。
云原生的NoSQL有如下的优势:
| 特性 | 价值 | 典型的场景 |
|---|---|---|
| 全托管架构 | 开发者聚焦业务逻辑,无需管理服务器 | 中小团队快速构建爬虫存储系统 |
| 自动弹性伸缩 | 根据负载动态调整资源,成本降低40%+ | 应对“双十一”级数据洪峰 |
| 全球多活 | 数据就近写入,延迟低于50ms | 跨国爬虫数据本地化存储 |
| 内置安全 | 自动加密、漏洞扫描、合规认证(如GDPR) | 用户隐私数据安全存储 |
AWS DynamoDB
高并发写入、固定模式查询(如URL去重、状态记录)。
- 使用自适应容量(Adaptive Capacity)避免热点分片 throttling。
- 对历史数据启用TTL自动删除(节省存储费用)。
- 通过IAM策略限制爬虫节点的最小权限(如只允许PutItem)。
- 启用KMS加密静态数据。
import boto3
from boto3.dynamodb.types import Binary# 创建DynamoDB资源(密钥从环境变量注入)
dynamodb = boto3.resource('dynamodb', region_name='us-east-1')
table = dynamodb.Table('CrawlerData')# 动态创建表(按需计费模式)
table = dynamodb.create_table(TableName='CrawlerData',KeySchema=[{'AttributeName': 'data_id', 'KeyType': 'HASH'}, # 分区键{'AttributeName': 'crawled_time', 'KeyType': 'RANGE'} # 排序键],AttributeDefinitions=[{'AttributeName': 'data_id', 'AttributeType': 'S'},{'AttributeName': 'crawled_time', 'AttributeType': 'N'}],BillingMode='PAY_PER_REQUEST' # 按请求量计费,无预置容量
)# 写入加密数据(结合前文AES加密)
encrypted_data = aes_encrypt("敏感数据")
table.put_item(Item={'data_id': 'page_123','crawled_time': 1633027200,'content': Binary(encrypted_data),'source_site': 'example.com'
})# 查询特定时间段数据
response = table.query(KeyConditionExpression=Key('data_id').eq('page_123') & Key('crawled_time').between(1633027000, 1633027400)
)
MongoDB Atlas
动态结构数据存储(如商品详情异构字段)、复杂聚合分析
- 选择Serverless实例应对突发流量(费用=请求数×数据量)。
- 启用压缩(Snappy)减少存储开销。
- 使用字段级加密(Client-Side Field Level Encryption)。
- 配置网络访问规则(仅允许爬虫服务器IP段)。
from pymongo import MongoClient
from pymongo.encryption import ClientEncryption# 连接Atlas集群(SRV连接串自动分片)
uri = "mongodb+srv://user:password@cluster0.abcd.mongodb.net/?retryWrites=true&w=majority"
client = MongoClient(uri)
db = client['crawler']
collection = db['dynamic_data']# 写入动态结构数据(无预定义Schema)
product_data = {"title": "智能手表","price": 599.99,"attributes": {"防水等级": "IP68", "电池容量": "200mAh"},"extracted_time": "2023-10-05T14:30:00Z" # ISO 8601格式
}
collection.insert_one(product_data)# 执行聚合查询(统计各价格区间商品数)
pipeline = [{"$match": {"price": {"$exists": True}}},{"$bucket": {"groupBy": "$price","boundaries": [0, 100, 500, 1000],"default": "Other","output": {"count": {"$sum": 1}}}}
]
results = collection.aggregate(pipeline)
四:Redis Edge近端计算(了解)
当爬虫节点遍布全球边缘网络时,传统“端侧采集-中心存储-云端计算”的链路过长,导致高延迟、带宽成本激增与实时性缺失。Redis Edge Module通过将数据处理能力下沉至爬虫节点,实现数据去重、实时聚合与规则过滤的近端执行,重构了爬虫存储架构的边界
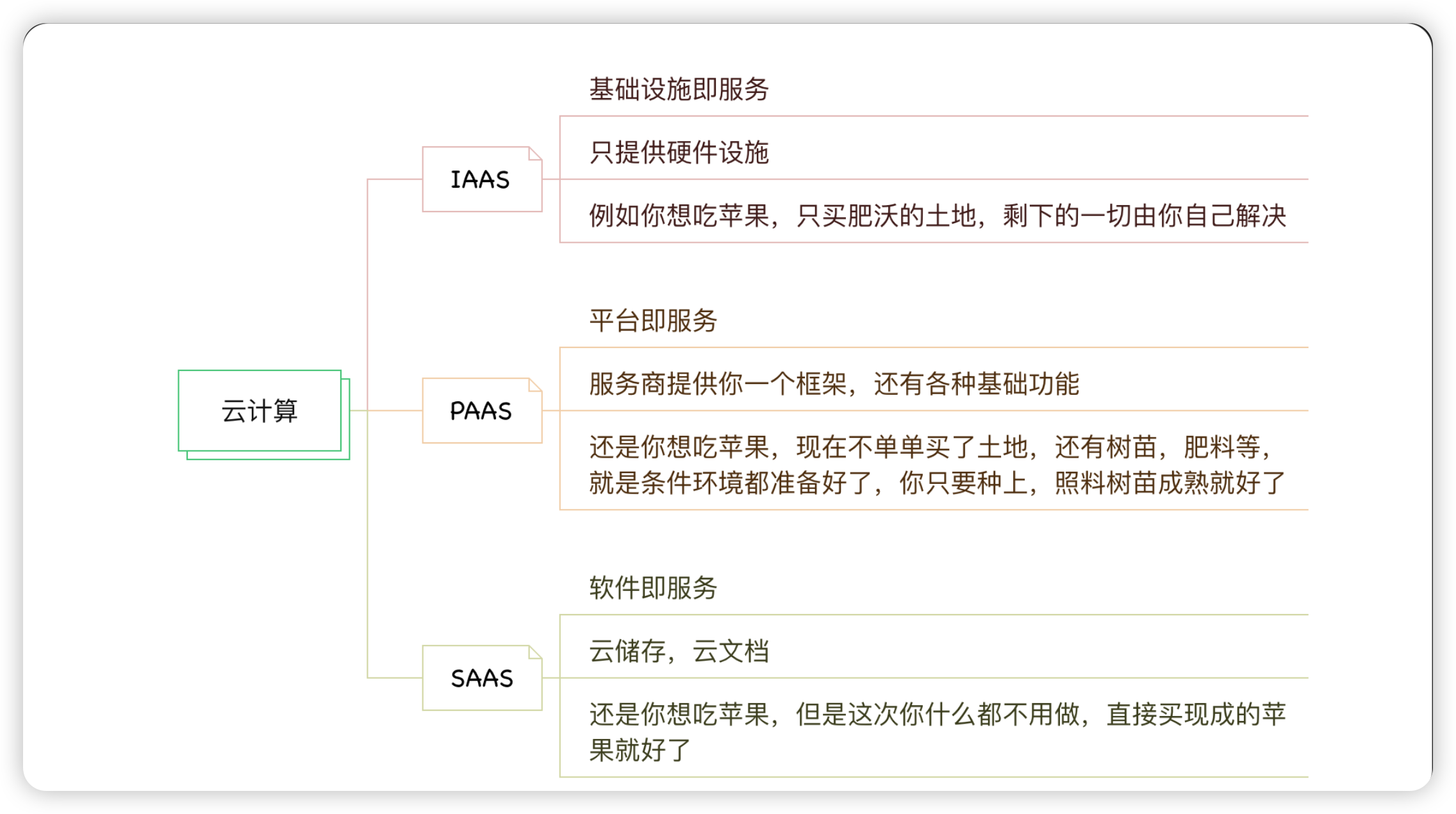
而中心化计算有如下的三个问题:
- 延迟敏感场景失效:跨国爬虫数据回传延迟高达200ms+,无法满足实时监控需求。
- 带宽成本失控:重复数据(如相似页面内容)占用80%以上传输资源。
- 数据处理滞后:中心服务器批量处理无法触发即时响应(如突发舆情告警)。
| 模块 | 功能 | 爬虫场景价值 |
|---|---|---|
| RedisTimeSeries | 毫秒级时序数据处理 | 实时统计爬虫吞吐量/成功率 |
| RedisBloom | 布隆过滤器实现去重 | 近端URL去重,节省90%带宽 |
| RedisGears | 边缘侧执行Python函数 | 数据清洗/格式化前置 |
| RedisAI | 部署轻量ML模型 | 实时敏感内容识别 |
传统架构中:爬虫节点 -> 原始数据上传 -> 中心数据库 -> 批量处理
边缘架构中:爬虫节点 -> Redis Edge -> 规则执行数据过滤和聚合 -> 压缩有效数据同步到中心数据库
# 下载Redis Edge镜像(集成所有模块)
docker run -p 6379:6379 redislabs/redisedge:latest # 启用模块(示例启用Bloom和TimeSeries)
redis-cli module load /usr/lib/redis/modules/redisbloom.so
redis-cli module load /usr/lib/redis/modules/redistimeseries.so
# 使用布隆过滤器去重
import redis
from redisbloom.client import Client # 连接边缘Redis
r = redis.Redis(host='edge-node-ip', port=6379)
rb = Client(connection_pool=r.connection_pool) def url_deduplicate(url: str) -> bool: if rb.bfExists('crawler:urls', url): return False rb.bfAdd('crawler:urls', url) return True # 在爬虫循环中调用
if url_deduplicate(target_url): data = crawl(target_url) process_data(data)
else: print(f"URL已存在:{target_url}")
# 时序数据实时统计
# 创建时序数据集
import redis
from redisbloom.client import Client # 连接边缘Redis
r = redis.Redis(host='edge-node-ip', port=6379)
rb = Client(connection_pool=r.connection_pool) r.ts().create('crawl:latency', retention_msec=86400000) # 记录每次请求延迟
def log_latency(latency_ms: float): r.ts().add('crawl:latency', '*', latency_ms, duplicate_policy='first') # 每5秒聚合平均延迟
avg_latency = r.ts().range('crawl:latency', '-', '+', aggregation_type='avg', bucket_size_msec=5000)
print(f"近5秒平均延迟:{avg_latency[-1][1]} ms")
五:二进制存储
传统的文本格式(如CSV、JSON)虽然易于阅读和解析,但在处理大规模数据时存在读写速度慢、存储空间占用高等问题。
而二进制格式凭借其紧凑的存储方式和高效的序列化机制,成为优化性能的重要选择。
和文本文件存储相比,二进制文件有如下的优势:
- 更快的读写速度:无需文本编码/解码,直接操作二进制流。
- 更小的存储体积:二进制数据压缩效率更高,节省磁盘空间。
- 支持复杂数据类型:可序列化自定义对象、多维数组等非结构化数据。
1:Pickle
Pickle是Python内置的序列化模块,可将任意Python对象转换为二进制数据并保存到文件,适用于临时缓存或中间数据存储。
- 支持所有Python原生数据类型。
- 序列化/反序列化速度快,代码简洁。
import pickle# 保存数据
data = {"name": "Alice", "age": 30, "tags": ["Python", "Web"]}
with open("data.pkl", "wb") as f:pickle.dump(data, f)# 读取数据
with open("data.pkl", "rb") as f:loaded_data = pickle.load(f)
print(loaded_data) # 输出: {'name': 'Alice', 'age': 30, 'tags': ['Python', 'Web']}
2:Parquet
Parquet是一种面向列的二进制存储格式,专为大数据场景设计,支持高效压缩和快速查询,广泛应用于Hadoop、Spark等分布式系统。
- 列式存储:按列压缩和读取,减少I/O开销,适合聚合查询。
- 高压缩率:默认使用Snappy压缩算法,体积比CSV减少70%以上。
- 跨平台兼容:支持Java、Python、Spark等多种语言和框架。
import pyarrow as pa
import pyarrow.parquet as pq
import pandas as pd# 创建示例数据
df = pd.DataFrame({"id": [1, 2, 3],"content": ["text1", "text2", "text3"]
})# 保存为Parquet文件
table = pa.Table.from_pandas(df)
pq.write_table(table, "data.parquet")# 读取Parquet文件
parquet_table = pq.read_table("data.parquet")
print(parquet_table.to_pandas())
| 指标 | Pickle | Parquet |
|---|---|---|
| 读写速度 | 快(Python专用) | 快(大数据优化) |
| 存储体积 | 中等 | 极小(高压缩) |
| 适用场景 | 临时缓存、复杂对象 | 结构化数据、分析查询 |

:软件分类展示)






:时序数据库介绍与单机版安装部署指南)



)
 对偶(II)KKT条件+变形重构)


)


