十一、集合
1. 为什么要使用集合
(1) 数组存在的弊端
1) 数组在初始化之后,长度就不能改变,不方便扩展。
2) 数组中提供的属性和方法比较少,不便于进行添加、删除、修改等操作,并且效率不高,同时无法直接存储元素的个数。
3) 数组中存储的元素是可以重复的。
(2) Java 集合类可以用于存储数量不等的多个对象,还可以保存具有映射关键的键值对。
(3) Java 中的集合可分为 Collection 和 Map 两种体系
1) Collection 接口:单列数据,定义了存取一组对象的方法的集合,包含两个子接口:
a. List 接口:元素有序,元素可重复的集合
b. Set 接口:元素无序,元素不可重复的集合
2) Map 接口:双列数据,保存具有映射关系“key-value”对的集合
(4) Collection 接口常用的方法:
① 添加
add(Object obj)
addAll(Collection obj)
② 获取有效元素的个数
int size()
③清空集合
void clear()
④ 判断是否是空集合
boolean isEmpty()
⑤ 是否包含某个元素
boolean contains(Object obj):是通过元素的equals方法来判断是否是同一个对象
boolean containsAll(Collection c)
⑥ 删除
boolean remove(Object obj):也是通过equals方法来判断
boolean removeAll(Collection c)
⑦ 求两个集合的交集
boolean retainAll(Collection c)
⑧ 判断两个集合是否相等
boolean equals(Object obj)
⑨ 转换成对象数组
Object[] toArray()
⑩ 获取哈希码
hashCode()
⑪ 遍历
iterator():返回迭代对象
从上面的方法可以看出:集合只能接收引用数据类型(对象)
示例:Collection 接口的子接口 List 有一个实现类 ArrayList,表示数组类型的集合
package com.edu.coll;
import java.util.ArrayList;
import java.util.Collection;
public class CollectionDemo1 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Collection c = new ArrayList();//向上转型,多态
for (int i = 1; i <= 10; i++) {
c.add(new Person("姓名" + i, 20 + i));//多态性,实际上调用的是 ArrayList 的 add() 方法
}
System.out.println("集合的大小为:" + c.size());
Object[] array = c.toArray();//转换为对象数组
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
}
}
class Person {
private String name;
private int age;
public Person() {
// TODO Auto-generated constructor stub
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
}
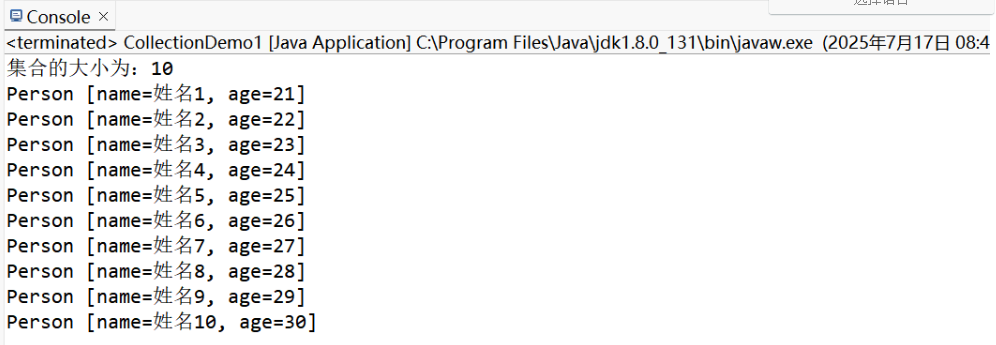
课堂练习:创建一个集合,往里面放10个 Person 对象,然后删除一个元素,再查看所有元素
package com.edu.coll;
package com.edu.coll;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Objects;
public class CollectionDemo1 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Collection c = new ArrayList();//向上转型,多态
for (int i = 1; i <= 10; i++) {
c.add(new Person("姓名" + i, 20 + i));//多态性,实际上调用的是 ArrayList 的 add() 方法
}
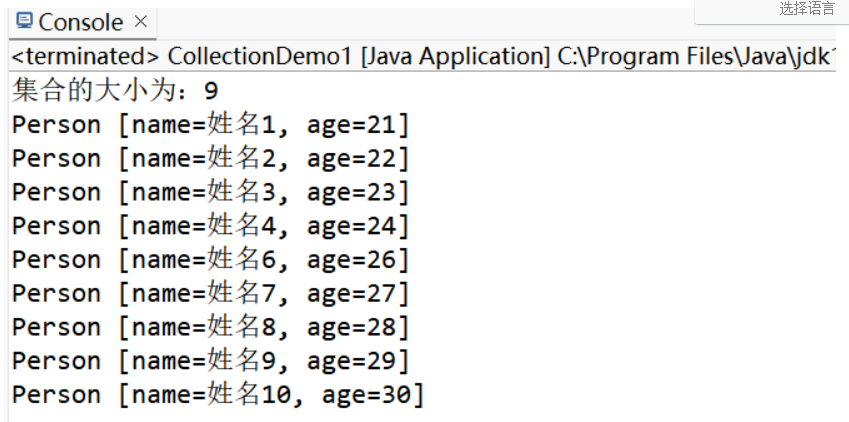
c.remove(new Person("姓名5", 25));//要这样删除就必须重写 equals 方法,然后比较内容是否相等
System.out.println("集合的大小为:" + c.size());
Object[] array = c.toArray();//转换为对象数组
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
}
}
class Person {
private String name;
private int age;
public Person() {
// TODO Auto-generated constructor stub
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
/**
* 为什么重写 equals 方法的同时一定要重写 hashCode()?
* 原因就是相等的对象必须具有相同的哈希值(hash 值)
* equals() 没有重写的时候比较的是两个对象地址值是否相等,这个时候如果两个对象相等,那么它们没有重写的 hashCode
* 也是相等的,然后 equals 方法重写之后是比较对象的属性内容是否相等,要保证这两个对象的 hashCode 相等,那么也必须
* 要重写 hashCode() 方法,从而使用对象的属性来生成 hashCode。
*/
@Override
public int hashCode() {
return Objects.hash(age, name);
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
return age == other.age && Objects.equals(name, other.name);
}
}
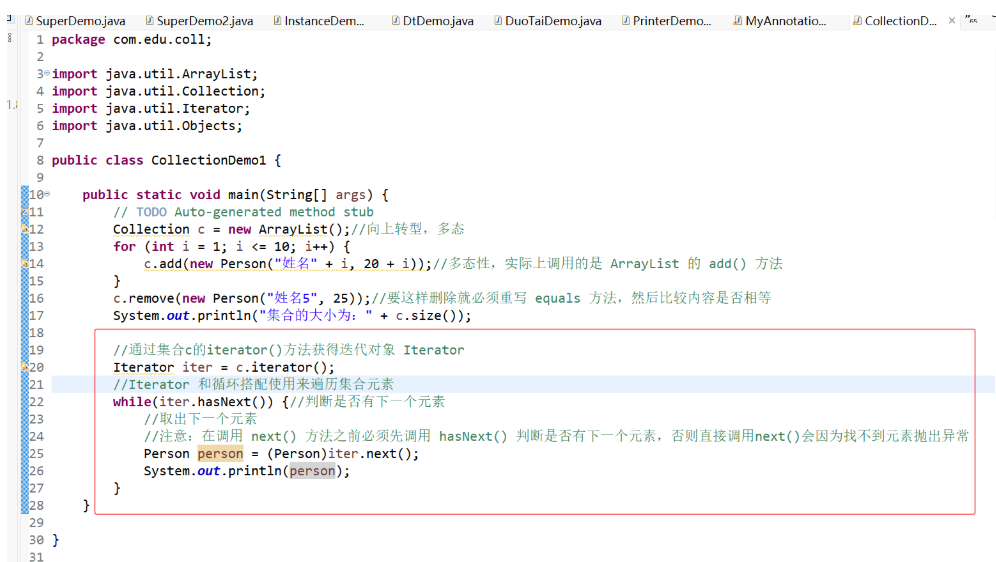
(5) Iterator 迭代器:用于循环遍历集合元素
1) Collection 接口继承了 java.lang.Iterator 接口,该接口中有一个方法 iterator() 方法,所有实现 Collection 接口的集合类都有一个 iterator() 方法,可以返回 Iterator 对象
2) Iterator 对象包含三个方法,用于遍历集合,但是需要注意:Iterator 本身并不提供承载对象的能力,如果需要创建 Iterator 对象,则必须有一个被迭代的集合,它包含的三个方法:
a. boolean hasNext():判断是否有下一个元素
b. Object next():返回下一个元素
c. void remove():删除指定的元素
示例:

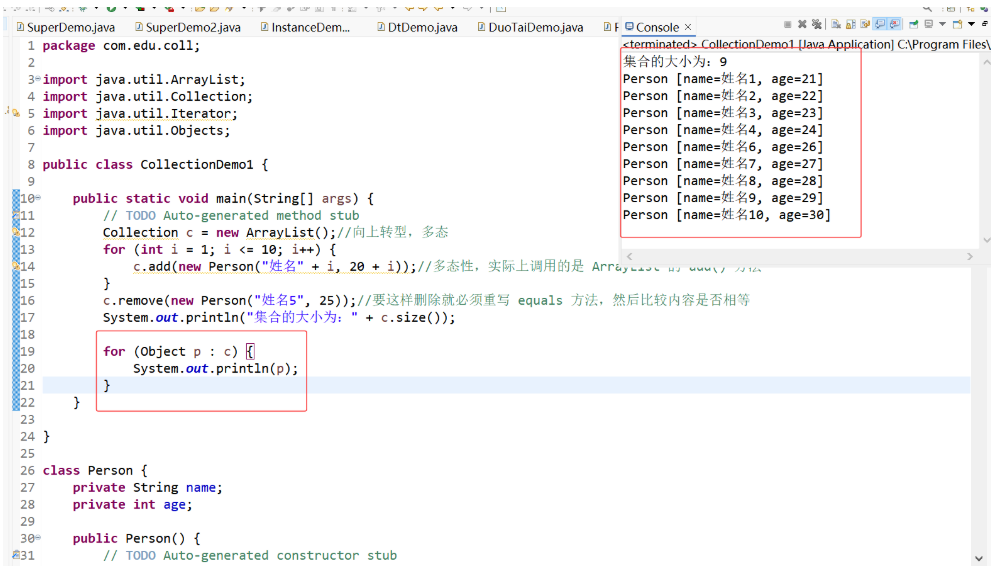
(6) foreach 循环(增强 for 循环):
foreach 循环可用于遍历集合和数组,它的底层也是通过 Iterator 完成
语法:

其中:
类型:待遍历的元素的类型
变量:遍历后自定义元素的名称
集合/数组:待遍历的集合或数组
(7) Collection 接口的子接口 --- List 接口
1) List 集合中元素有序,且元素可以重复,集合中的每个元素都有对应的索引。
2) List 接口常用的实现类:ArrayList、Vector、LinkedList
3) List 集合除了继承了 Collection 接口的常用方法之外,还添加了一些根据索引来操作集合的方法,这些额外的方法有:

示例:
package com.edu.coll;
import java.util.ArrayList;
import java.util.List;
public class ListDemo1 {
public static void main(String[] args) {
// TODO Auto-generated method stub
List list = new ArrayList();//向上转型,多态
for (int i = 0; i < 10; i++) {
list.add("集合元素" + i);//添加元素,多态性
}
//获取第二个元素
String s2 = (String)list.get(1);//向下转型,强转
System.out.println(s2);
/**
* 找到"集合元素2"的索引位置:ArrayList 的 indexOf() 方法是通过 equals() 方法来比较元素的
* 因为 String 已经重写 equals() 方法,是比较内容是否相等
*/
int i = list.indexOf(new String("集合元素2"));
System.out.println(i);
//设置索引位置3的元素值:
list.set(3, "修改后的元素值");
//取出区间[2,5)的子集合
List subList = list.subList(2, 5);
System.out.println(subList);
System.out.println();
//打印所有元素
for (Object s : list) {
System.out.println(s);
}
}
}

(8) List 的实现类(集合的难点就是在下面的源码分析,用集合不难,但是面试会问这些底层!)
1) List 接口的实现类之一:ArrayList,其底层就是一个变长的对象数组,ArrayList 的源码分析:
//ArrayList 实现了 List 接口
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
//默认容量/初始容量为10
private static final int DEFAULT_CAPACITY = 10;
//一个空的 Object 类型的数组,给内部的 elementData 对象数组赋值
private static final Object[] EMPTY_ELEMENTDATA = {};
//一个空的 Object 类型的数组,给内部的 elementData 对象数组赋值
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//ArrayList 存放对象的对象数组
transient Object[] elementData; // non-private to simplify nested class access
//ArrayList 目前存放了多少个元素
private int size;
//如果 initialCapacity > 0,就是用 initialCapacity 来初始化对象数组 elementData
//否则如果 initialCapacity == 0,就是用一个空的数组来初始还 elementData
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
//无参构造器中使用一个空的数组来初始化 elementData
//所以从这里我们可以看出:默认情况下,我们调用 ArrayList 的默认构造函数产生对象时,它此时的容量为 0,是一个空的数组
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
//用一个集合 c 来初始化 ArrayList 内部对象数组 elementData,使用 Arrays.copyOf() 将集合 c 转换成对象数组之后拷贝到 ArrayList 内部的对象数组 elementData 中,如果此时size为0(证明传进来的c为空),就直接给 elementData 赋予一个空的数组
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
//将新的数据(c)以及大小 size 复制到elementData中
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
......
//增加元素的方法
public boolean add(E e) {
//将当前元素的个数size+1之后传入方法,如果此时容量不够了,则需要对 elementData 进行扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
//将元素 e 添加到 elementData 对应的下标位置,同时元素个数 size 自增
elementData[size++] = e;
return true;//返回 true
}
//然后上面的扩容方法
private void ensureCapacityInternal(int minCapacity) {
//判断数据是否为空(调用 ArrayList 默认构造方法时就是空的)
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//将能允许的最小容量 minCapacity 取值为默认容量 10 和 允许的最小容量 minCapacity 取个最大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//扩容
ensureExplicitCapacity(minCapacity);
}
//继续看上面的扩容方法
private void ensureExplicitCapacity(int minCapacity) {
modCount++;//修改计数自增
// overflow-conscious code
//如果能允许的最小容量 minCapacity 减去当前数组 elementData 的长度大于 0,证明数组当前已经不能容纳更多的元素了,需要扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);//扩容
}
//然后看grow()扩容:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;//取出数组当前的长度作为老的容量
//扩充的新的容量为老的容量的 1.5 倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
//如果算出来的新容量比能允许的最小容量 minCapacity 都还要小,那么直接将新的容量赋值为能允许的最小容量 minCapacity
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//如果算出来的新容量比 MAX_ARRAY_SIZE 还要大,那么就调用 hugeCapacity() 来扩容
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
//然后调用 Arrays.copyOf() 将数组当前内容以及新的容量拷贝到 elementData 中
elementData = Arrays.copyOf(elementData, newCapacity);
}
//然后就是 hugeCapacity():
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
从上面代码分析可知:我们通过 ArrayList 的默认构造器创建对象的时候,它此时内部的对象数组的大小为 0,是一个空的数组,然后第一次调用 add() 方法添加元素的时候,才去进行扩容,此时扩容的大小是默认的容量 10。
然后继续分析源码:
//返回数组的大小:数组中包含的元素的个数
public int size() {
return size;
}
//判断 ArrayList 是否为空
public boolean isEmpty() {
return size == 0;
}
//判断是否存在某个元素
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
//遍历数组,找到参数 o 的下标返回,找不到返回 -1
//注意,这里使用的是 equals() 方法来比较对象的,要注意此时的 equals() 方法有没有重写,是比较地址还是比较内容,同时也看出 ArrayList 中可以放置 null 元素
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
//从后面往前面找,找到对应元素返回下标,注意也是用 equals() 来比较
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
//获取指定索引位置的数组元素
public E get(int index) {
rangeCheck(index);//检查索引的范围
return elementData(index);
}
//通过数组下标 index 返回 elementData 对应的元素
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
//设置对应索引位置的元素值
public E set(int index, E element) {
rangeCheck(index);//检查索引范围
//取出对应索引位置的旧值
E oldValue = elementData(index);
elementData[index] = element;//将新值赋予对应索引位置的元素
return oldValue;//返回旧值
}
然后是通过索引位置删除,索引位置后面的元素要依次往前面移动一个位置:
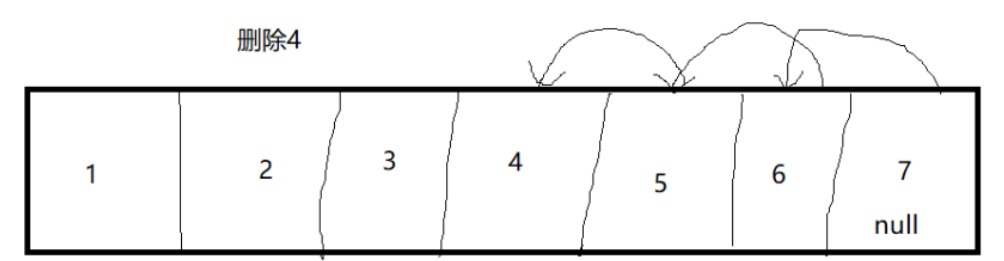
继续看源码:
//通过索引删除
public E remove(int index) {
rangeCheck(index);//索引范围检查
modCount++;//修改计数自增
E oldValue = elementData(index);//取出对应索引位置的旧值
int numMoved = size - index - 1;//总共要移动的元素的个数
if (numMoved > 0)
//通过 System.arraycopy() 方法将 index+1 到最后的元素拷贝到 index 这个位置(注意底层还是一个一个的移动的),总共移动了 numMoved 个元素
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//元素移动后,最后一个元素会空出,通过 --size 找到最后一个元素,将其置为 null,等待垃圾回收
elementData[--size] = null; // clear to let GC do its work
return oldValue;//将旧值返回
}
从上面的源码分析可知:ArrayList 的读取效率比较高,因为只需要一个索引 index 就可以定位到要读取的元素,但是删除的效率比较低,因为后面的元素要一个一个的往前移动,所以 ArrayList 读操作效率高,修改操作效率低。
继续看源码:

然后是往指定的索引位置插入元素,在插入的位置以及后面的元素要依次往后面移动一个位置:
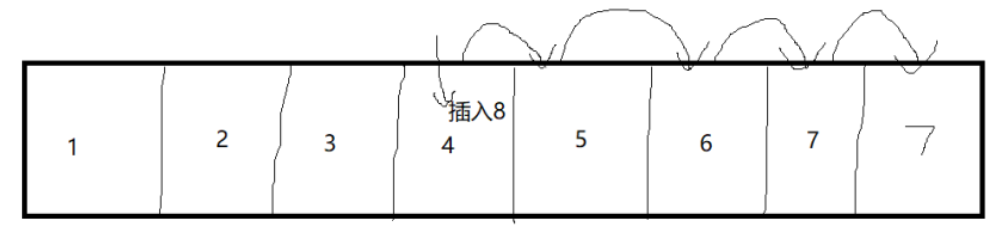
看源码:
2) List 接口的实现类之二:Vector
Vector源码分析:Vector 的底层实现和 ArrayList 类似,Vector 的很多方法和 ArrayList 一样,只是多加了一个 synchronized 锁来保证线程安全(效率没有 ArrayList 高)。我们这里只把 Vector 和 ArrayList 不一样的地方提一下:
Vector 比 ArrayList 多了一个属性:

从以上的代码分析可知,Vector 在默认情况下会创建容量为 10 的内部对象数组,这点和 ArrayList 不一样,ArrayList 默认情况下,内部的对象数组容量为 0,是一个空的数组,在第一次 add() 的时候才扩容为 10.
然后我们来看 Vector 的扩容方法:

总结:
1. ArrayList 默认创建的时候大小为 0,当加入第一个元素的时候,进行第一次扩容,扩充的容量为默认的 10。
2. ArrayList 每次扩容都是以当前数组大小的 1.5 倍去扩容。
3. Vector 创建时的默认容量为 10。
4. Vector 每次扩容默认是数组大小 2 倍去扩容,当指定了 capacityIncrement 之后,每次扩容仅在原来的基础上加上 capacityIncrement 个单位空间。
5. ArrayList 是非线程安全,Vector 是线程安全。
3) List 接口的另一个实现:LinkedList
a. 对于频繁插入或删除的元素的操作,建议使用 LinkedList,效率会比较高,原因是 LinkedList 内部是一个双向链表结构。
b. LinkedList 除了继承了 List 接口的方法之外,还新增了如下方法:

示例1:

示例2:
package com.edu.list;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
import java.util.Objects;
public class LinkedListDemo2 {
public static void main(String[] args) {
// TODO Auto-generated method stub
List list = new LinkedList();
for (int i = 1; i <= 10; i++) {
list.add(new Person("姓名" + i, 20 + i));
}
list.remove(new Person("姓名5", 25));//注意:通过对象删除时,也是通过 equals() 来比较的
Iterator iter = list.iterator();
while(iter.hasNext()) {
Person p = (Person)iter.next();
System.out.println(p);
}
}
}
class Person {
private String name;
private int age;
public Person() {
// TODO Auto-generated constructor stub
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
@Override
public int hashCode() {
return Objects.hash(age, name);
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
return age == other.age && Objects.equals(name, other.name);
}
}
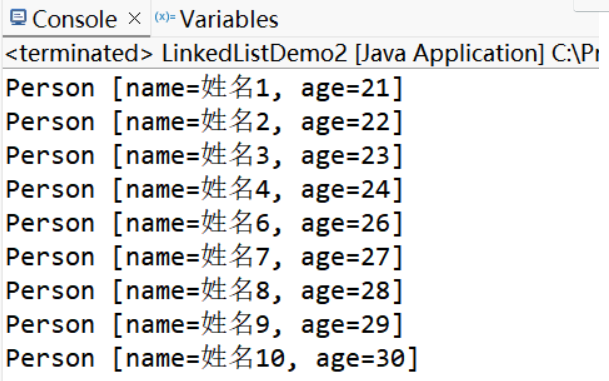
c. LinkedList 源码分析:
LinkedList 是一个双向链表:

双向链表每个节点除了数据域之外,还有一个前指针(prev)和后指针(next),分别指向前驱节点和后继节点(如果有前驱/后继的话),另外,双向链表还有一个first指针,指向头节点,和last指针,指向尾节点。
b) 我们先来看一下 LinkedList 中的属性:
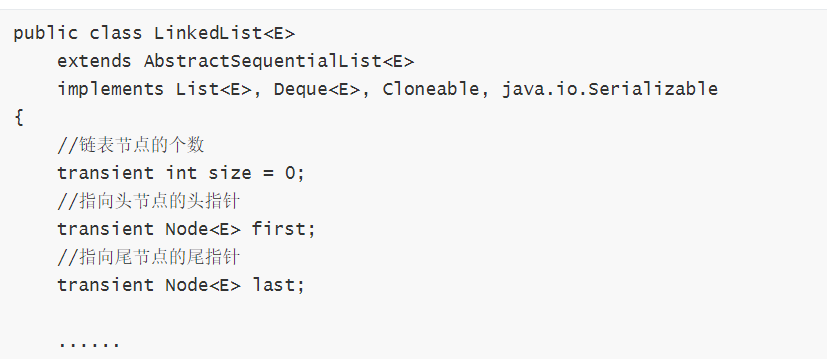
c) 然后就是 LinkedList 的每个节点,节点是 Node 的结构:
每个节点是一个 Node 类型的类,Node 是 LinkedList 内部的一个静态内部类,它表示链表的每一个节点,包含一个数据域 item,一个前指针 prev(指向前驱节点),一个后指针 next(指向后继节点):

d) 添加元素
I. 在表头添加元素的过程:
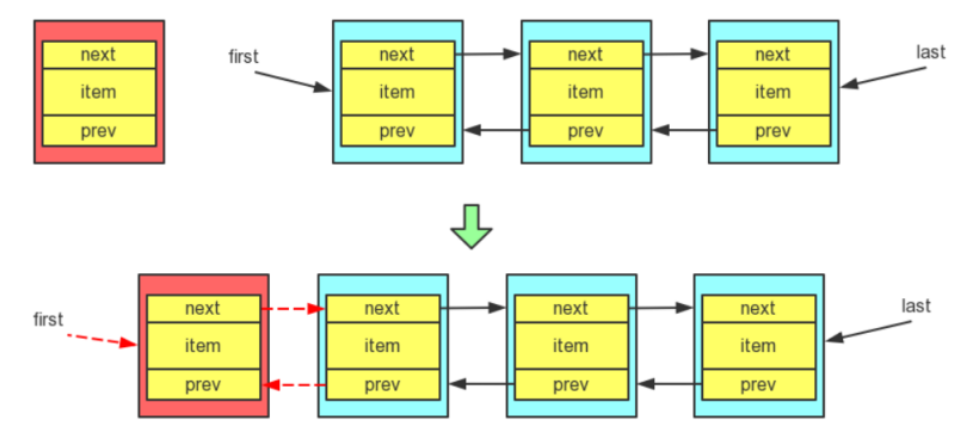
当向表头插入一个节点时,很显然当前节点的前驱(prev)一定是null,后继节点(next)是 first 指针指向的原来的这个节点,当然还要修改 first 指针指向新的头结点,除此之外,原来的头结点变成了第二个节点,所以还要修改原来的头结点的前驱指针,使它指向新的头结点。
源码实现:

III. 在指定的节点之前插入,如图:
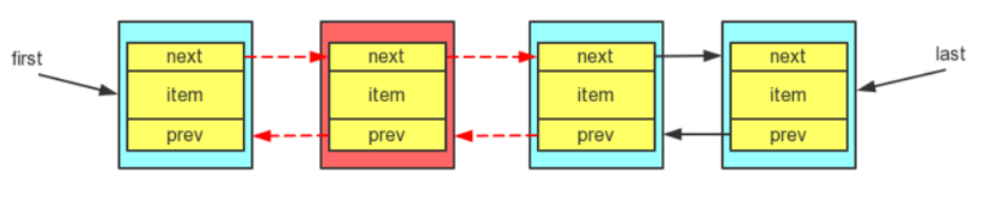
当向指定节点之前插入一个节点时,当前节点(新节点)的后继为指定节点,而前驱为指定节点的前驱节点,此外,还要修改指定节点的前驱节点的后继为新节点,以及指定节点前驱为新节点,源码如下:


e) 删除元素(删除节点)
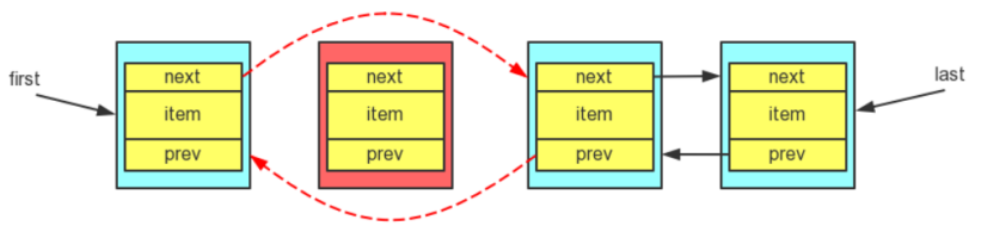
删除操作与添加操作大同小异,例如删除指定节点的过程是,需要把指定节点的前驱节点的后继修改为指定节点的后继,以及指定节点的后继节点前驱修改为指定节点的前驱,同时将指定节点的next,item,prev置null,等待垃圾回收器回收
I. 删除表头节点

II. 删除尾节点:

III. 删除指定节点:


f) 获取元素
I. 获取表头元素
public E getFirst() {
final Node<E> f = first;//获取头指针,头指针指向的就是头元素
if (f == null)
throw new NoSuchElementException();
return f.item;//返回头元素的数据域
}
II. 获取尾元素

III. 获取指定索引的元素

h) 其他常用的方法
I. 获取链表大小

II. 设置指定索引位置的值

III. 在指定索引位置前面插入节点

IV. 删除指定索引位置的节点

V. 获取表头节点的值,表头为空返回 null

VI. 获取表头节点的值,表头为空抛出异常
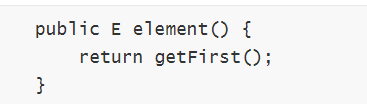
VII. 获取表头节点的值,并删除表头节点,表头为空则返回 null

VIII. 添加元素到表头:

VV. 弹出表头元素,弹出=返回+删除

从上面两个方法可以看出,LinkedList 可以作为一个栈(后进先出)来使用,也可以当成一个队列来使用。
总结:
1. LinkedList的底层是一个带头/尾指针的双向链表,可以快速对头/尾节点进行操作。
2. 相比ArrayList,LinkedList 的特点就是在指定位置插入和删除元素的效率比较高(只需改变前驱和后继指针的指向即可),但是查找效率就不如 ArrayList 那么高了(因为需要去遍历链表才能找到对应的节点)
示例:队列(Queue)是一个典型的先进先出(FIFO)的容器,LinkedList 实现了 Queue 接口,并提供了方法来支持队列的行为:



多协议标记交换 MPLS)


格式全解析:从 RP 到 Word 的选择与实践)




)





 with Kafka Connect:实时数据同步的完整指南)



