Redis 作为一款高性能的开源内存数据库,凭借其丰富多样的数据结构和出色的性能,在缓存、会话存储、实时分析等众多场景中得到了广泛应用。下面将详细介绍 Redis 主要的数据结构,包括它们的类型、具体用法和适用场景。
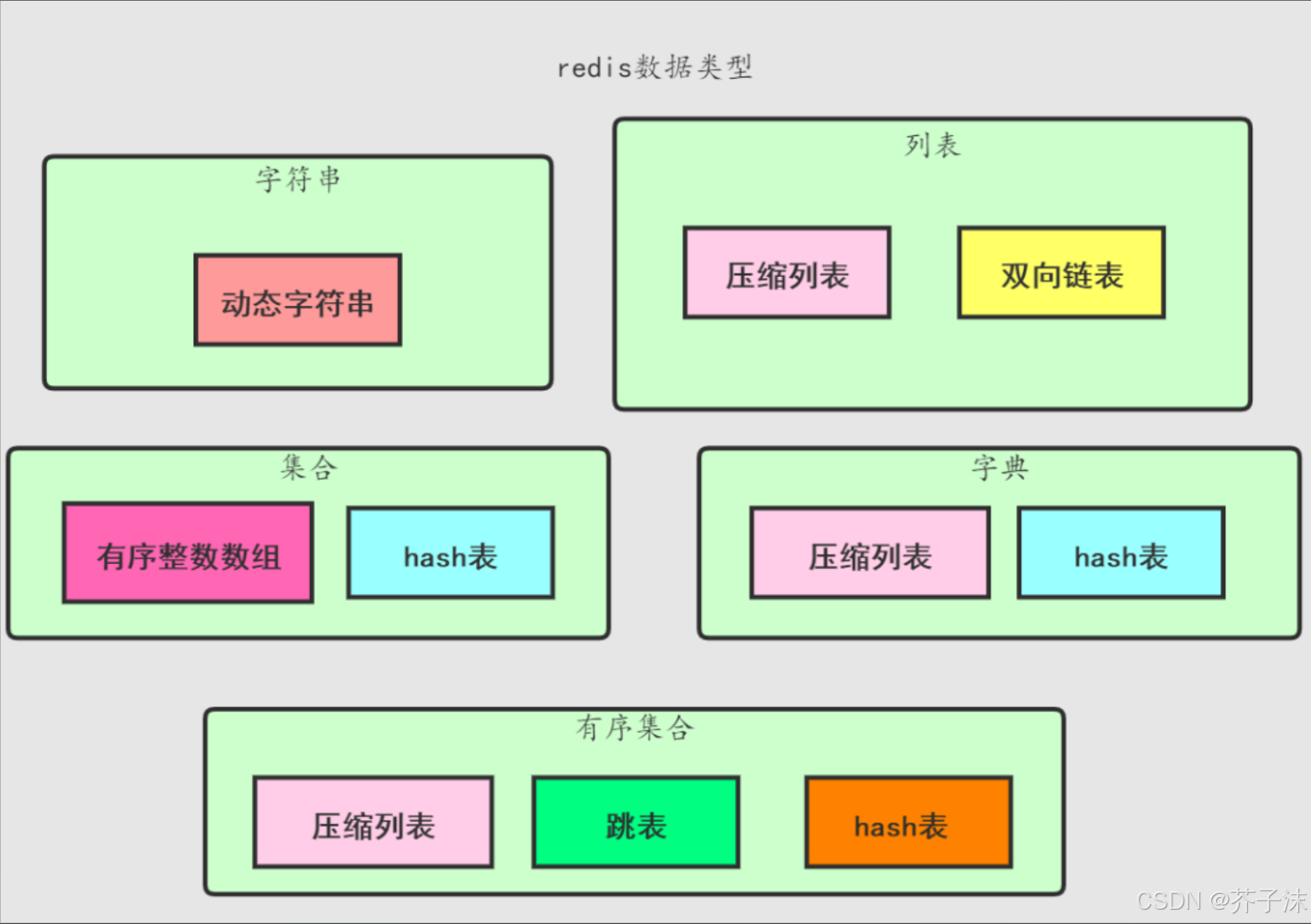
1、字符串(String)
字符串是 Redis 中最基础也最常用的数据结构,它可以存储字符串、整数和浮点数等多种类型的数据,最大能存储 512MB 的数据。
具体用法
字符串的常用命令丰富多样。SET key value命令用于设置指定键的值,例如SET username "zhangsan",就将键 “username” 的值设置为 “zhangsan”。GET key则用于获取指定键的值,执行GET username会返回 “zhangsan”。INCR key可对存储整数的键进行自增操作,若键 “count” 的值为 5,执行INCR count后,其值变为 6。DECR key用于自减操作,INCRBY key increment能按指定增量增加,DECRBY key decrement可按指定减量减少。APPEND key value可以向字符串末尾追加内容,比如对键 “message” 的值 “Hello” 执行APPEND message " World",其值就变为 “Hello World”。
使用场景
在缓存场景中,字符串可用于存储用户信息、商品详情等,减轻数据库压力。例如将商品的基本信息缓存起来,当用户查询时直接从 Redis 获取,提高响应速度。在计数器方面,像网站的访问量统计、视频的播放次数统计等,都可以通过INCR等命令轻松实现。此外,还可用于存储会话信息,如用户登录后的会话 ID 对应的用户数据。
2、哈希(Hash)
哈希数据结构类似于 Java 中的 HashMap,适合存储对象类型的数据,它由字段和对应的字段值组成,每个哈希可以存储多达 2^32 - 1 个键值对。
具体用法
HSET key field value用于为哈希表中的字段设置值,例如HSET user:1 name "zhangsan" age 25,就为键 “user:1” 的哈希表设置了 “name” 字段值为 “zhangsan”,“age” 字段值为 25。HGET key field获取指定哈希表中字段的值,HGET user:1 name会返回 “zhangsan”。HGETALL key能获取哈希表中所有的字段和值,执行后会返回 “name”“zhangsan”“age”“25” 等内容。HDEL key field用于删除哈希表中的指定字段,HEXISTS key field可判断字段是否存在,HKEYS key返回哈希表中所有字段,HVALS key返回所有字段值。
使用场景
哈希非常适合存储对象数据,如用户信息包含姓名、年龄、地址等多个属性,商品信息包含名称、价格、库存等,使用哈希存储可以方便地对单个属性进行操作,而无需修改整个对象。例如更新用户的年龄,只需使用HSET user:1 age 26即可,操作高效且灵活。
3、列表(List)
Redis 的列表是一种有序的字符串集合,它允许在头部和尾部进行元素的插入和删除操作,列表中的元素可以重复,最多能存储 2^32 - 1 个元素。
具体用法
LPUSH key value1 value2 ...用于向列表头部添加一个或多个元素,LPUSH fruits "apple" "banana"会在列表 “fruits” 头部依次添加 “apple” 和 “banana”,此时列表为 ["banana", "apple"]。RPUSH key value1 value2 ...则向列表尾部添加元素。LPOP key移除并返回列表头部的元素,RPOP key移除并返回列表尾部的元素。LRANGE key start stop用于获取列表中指定范围的元素,LRANGE fruits 0 1会返回列表 “fruits” 中从索引 0 到 1 的元素。LLEN key获取列表的长度,LREM key count value删除列表中指定数量的指定值元素。
使用场景
消息队列是列表的典型应用场景之一,通过LPUSH向队列中添加消息,RPOP从队列中取出消息,实现简单的消息传递。在排行榜方面,可以存储用户的积分等数据,结合LRANGE命令获取排名靠前的用户。此外,还可用于存储用户的最近浏览记录,通过LPUSH不断添加新记录,并用LTRIM命令限制列表长度,只保留最近的几条记录。
4、集合(Set)
集合是一个无序的字符串集合,集合中的元素具有唯一性,不能重复,最多可存储 2^32 - 1 个元素。
具体用法
SADD key member1 member2 ...用于向集合中添加一个或多个元素,SADD tags "java" "python" "redis"就向集合 “tags” 中添加了 “java”“python”“redis” 三个元素。SMEMBERS key返回集合中的所有元素。SISMEMBER key member判断元素是否在集合中,SISMEMBER tags "java"会返回 1,表示存在。SREM key member1 member2 ...删除集合中的指定元素,SCARD key获取集合的元素个数。集合还支持交集、并集、差集操作,SINTER key1 key2返回两个集合的交集,SUNION key1 key2返回并集,SDIFF key1 key2返回差集。
使用场景
集合适合用于存储需要去重的数据,如用户的兴趣标签,确保每个标签只出现一次。在社交场景中,可用于存储用户的好友列表,通过交集操作可以轻松找到两个用户的共同好友,例如SINTER user:1:friends user:2:friends就能得到用户 1 和用户 2 的共同好友。此外,还可用于实现抽奖功能,通过SRANDMEMBER key count随机获取集合中的元素作为中奖用户。
5、有序集合(Sorted Set)
有序集合与集合类似,元素具有唯一性,但它为每个元素关联了一个分数(score),并通过分数对元素进行排序,最多可存储 2^32 - 1 个元素。
具体用法
ZADD key score1 member1 score2 member2 ...用于向有序集合中添加一个或多个元素及其分数,ZADD ranking 90 "zhangsan" 85 "lisi"向有序集合 “ranking” 中添加了 “zhangsan”(分数 90)和 “lisi”(分数 85)。ZRANGE key start stop [WITHSCORES]按照分数从小到大的顺序返回指定范围的元素,加上WITHSCORES会同时返回分数,ZRANGE ranking 0 1 WITHSCORES会返回 “lisi” 85、“zhangsan” 90。ZREVRANGE key start stop [WITHSCORES]则按照分数从大到小的顺序返回元素。ZSCORE key member获取指定元素的分数,ZINCRBY key increment member为元素的分数增加指定值,ZREM key member1 member2 ...删除有序集合中的指定元素。
使用场景
有序集合在排行榜场景中应用广泛,如游戏中的玩家积分排行榜、电商平台的商品销量排行榜等,通过ZRANGE或ZREVRANGE可以快速获取排名靠前或靠后的用户或商品。在延迟任务方面,可将任务的执行时间作为分数,通过ZRANGEBYSCORE命令获取到了执行时间的任务进行处理。此外,还可用于实现范围查询,例如查询分数在某个区间内的元素。
6、Bitmap(位图)
Bitmap 是一种特殊的字符串,它通过位来存储数据,每个位只能是 0 或 1,适合进行位级别的操作,能高效地利用存储空间。
具体用法
SETBIT key offset value用于设置指定偏移量的位的值,SETBIT user:login:20231001 5 1表示用户 ID 为 5 的用户在 2023 年 10 月 1 日登录过(将偏移量 5 的位设置为 1)。GETBIT key offset获取指定偏移量的位的值,GETBIT user:login:20231001 5会返回 1。BITCOUNT key [start end]统计指定范围内值为 1 的位的数量,BITCOUNT user:login:20231001可统计该日的登录用户数。BITOP operation destkey key1 key2 ...对多个 Bitmap 执行位运算(AND、OR、XOR 等),例如BITOP AND user:login:both user:login:20231001 user:login:20231002可得到两天都登录的用户。
使用场景
Bitmap 非常适合用于存储布尔型数据,如用户的登录状态(每天一个 Bitmap,位的偏移量代表用户 ID,值为 1 表示登录),通过BITCOUNT可以快速统计每天的登录人数,通过位运算可以统计连续多天登录的用户等。此外,还可用于实现用户标签的存储,每个标签对应一个 Bitmap,通过位运算可以快速筛选出具有特定组合标签的用户。
7、HyperLogLog
HyperLogLog 是一种用于基数统计的数据结构,它能够以极小的空间代价估算出一个集合中不同元素的数量(基数),误差率较低,通常在 1% 左右。
具体用法
PFADD key element1 element2 ...向 HyperLogLog 中添加元素,PFADD unique:visitors "user1" "user2" "user3"向 “unique:visitors” 中添加了三个用户。PFCOUNT key用于获取 HyperLogLog 估算的基数,PFCOUNT unique:visitors会返回 3(估算值)。PFMERGE destkey sourcekey1 sourcekey2 ...将多个 HyperLogLog 合并到一个新的 HyperLogLog 中,PFMERGE unique:visitors:week unique:visitors:day1 unique:visitors:day2 ...可得到一周的独立访客估算数。
使用场景
HyperLogLog 主要用于独立用户数统计、页面 UV(独立访客)统计等场景。例如统计一个网站每天的独立访客数,无需存储每个访客的信息,只需通过PFADD添加访客标识,PFCOUNT获取估算的独立访客数,大大节省了存储空间,尤其适合数据量大的场景。
8、Geospatial(地理空间)
Geospatial 是 Redis 用于存储和操作地理空间数据的数据结构,它可以存储经纬度信息,并支持距离计算、范围查询等操作。
具体用法
GEOADD key longitude latitude member ...用于向地理空间集合中添加地理位置,GEOADD cities 116.403874 39.914885 "beijing" 121.473701 31.230416 "shanghai"向 “cities” 中添加了北京和上海的经纬度信息。GEODIST key member1 member2 [unit]计算两个地理位置之间的距离,GEODIST cities beijing shanghai km会返回北京到上海的大致距离(单位为千米)。GEORADIUS key longitude latitude radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count]根据指定的经纬度和半径,查询该范围内的地理位置,例如GEORADIUS cities 116.403874 39.914885 100 km可查询北京周边 100 千米内的城市。
使用场景
Geospatial 在 LBS(基于位置的服务)场景中发挥着重要作用,如外卖平台的附近商家查询、打车软件的附近司机查找等。通过GEORADIUS命令可以快速筛选出指定范围内的地理位置,结合距离信息为用户提供相关服务。
综上所述,Redis 的每种数据结构都有其独特的特点和适用场景,在实际开发中,应根据具体的业务需求选择合适的数据结构,以充分发挥 Redis 的高性能优势。




)






)



)



留存用户数)