目录
1.在BAM文件中根据指定的变异等位基因分数的指定位置或区域随机选择read。
2.筛选变异等位基因分数的reads:
3.装BWA和samtools软件包(samtools在linux系统中下载过,前文有讲过)
4.写py脚本
5.下载pysam库模块
6.下载参考基因组hg38
7.解压gz
8.建立samtools索引
9.建立BWA索引
10.下载picard工具包
11.对hg38.fa建立索引
12.使用BWA的index命令为参考基因组文件创建索引
13.BWA进行比对
14.对bam文件进行标记重复并移除重复的读取
15.使用变体检测工具:运行GATK、FreeBayes、Samtools等变体检测工具,在比对后的数据中检测SNV和Indel,并生成VCF文件。
16.下载transverse colon的wgs的vcf文件
编辑
17.尖峰点突变(SNV 和 InDel)进入 bam 文件。(Illumina平台)
18、变异检测验证(FreeBayes / GATK / samtools)
19、Tips 与建议
浅浅介绍一下VarBen是什么东东吧。
VarBen是用于向bam文件添加变异模拟的工具,包括单核苷酸变异、短的插入和缺失以及结构变异。
VarBen主要在linux系统下使用,无需编译即可运行。但是需要预先配置运行环境。
采用的是比对到参考基因组特定位点的测序reads进行编辑的方式来进行模拟。这种方法可保留测序过程中产生的错误类型分布模式,使生成的模拟数据更接近实际数据。那么我们应该怎么做呢?请听我一本正经的胡说八道吧~
1.在BAM文件中根据指定的变异等位基因分数的指定位置或区域随机选择read。
【概念:等位基因分数是一个用于描述在某个基因座中,某个特定等位基因出现的频率或比例的指标。】
首先,确保你的BAM文件已经被索引。你可以使用samtools index命令为BAM文件创建索引。这个索引文件(.bai)将允许你快速查询BAM文件中的特定区域。
(具体操作在前文有讲过哦~)

利用samtools view命令,你可以提取指定区域或位置的reads(提取染色体chr1上位置10000到20000之间的reads)。
samtools view sorted_ENCFF845HFA.bam chr1:10000-20000 >extracted_reads.bam
查看文件:
less -n extracted_reads.bam
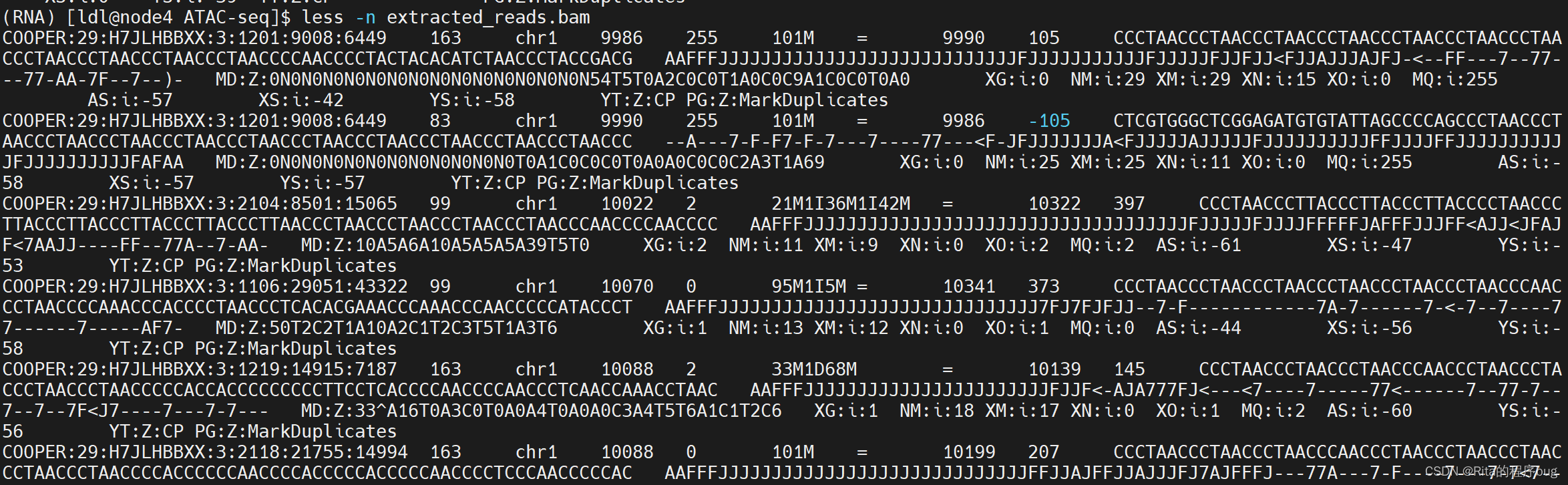
2.筛选变异等位基因分数的reads:
这一步通常需要使用一些自定义的脚本或工具,因为标准的SAMtools并不直接支持根据等位基因分数筛选reads。你可以使用Python的pysam库或者其他编程语言的相关库来读取BAM文件,并筛选出具有特定等位基因分数的reads。
大家放心,在Linux中使用Python是非常简单的,因为大多数Linux发行版都预装了Python。
#检查python版本
python --version

(我的是python3版本,你的是什么版本呢?)
3.装BWA和samtools软件包(samtools在linux系统中下载过,前文有讲过)
#如果你也是python3版本的话
pip3 install BWA
#如果不是
pip install BWA下载完成标志:
4.写py脚本
我在linux专栏中有讲到vim文本编辑器,可以用来编辑python脚本的。除此之外,你还可以使用任何文本编辑器(如nano、emacs、gedit等)来编写Python代码,并将其保存为.py文件。然后,你可以使用上述方法在终端中运行它。
vim reads.py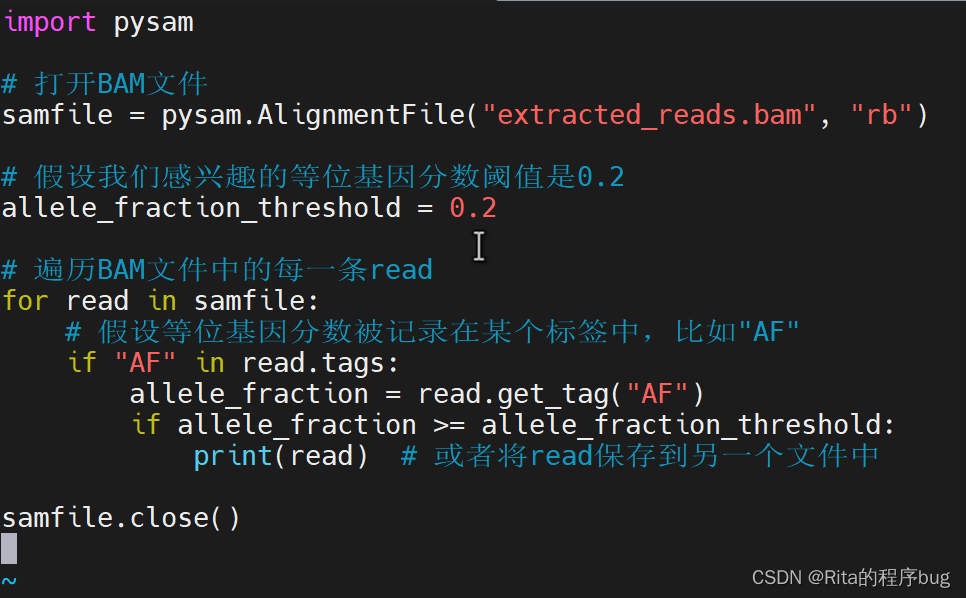
vim命令:
i进入编辑模式
Esc退出编辑
:wq保存并退出
【忘记的话可以回去看看我之前写的文章(linux专栏)哦】
5.下载pysam库模块
pip3 install pysam我一开始以为我以为python3会自带的,一运行脚本发现报错,原来是我自作多情了,所以如果你也没有安装的话,需要安装一下呢。(以下为报错信息)

 本地开发环境搭建指南)








)
)







)