背景意义
研究背景与意义
随着全球化的加速,传统文化的保护与传承面临着前所未有的挑战。尤其是韩国的传统文化,作为东亚文化的重要组成部分,蕴含着丰富的历史、艺术和哲学内涵。然而,随着现代化进程的推进,许多传统文化元素逐渐被边缘化,亟需通过科技手段进行有效的保护与传播。在此背景下,基于改进YOLOv8的传统韩文化元素分割系统的研究显得尤为重要。
YOLO(You Only Look Once)系列模型以其高效的目标检测能力在计算机视觉领域取得了显著成就。YOLOv8作为该系列的最新版本,结合了深度学习的先进技术,能够在复杂环境中快速、准确地识别和分割图像中的目标。通过对YOLOv8的改进,我们可以更好地适应传统韩文化元素的多样性和复杂性,从而实现对这些元素的精准识别与分类。研究表明,传统文化元素的视觉特征往往具有独特性和多样性,例如,韩国传统服饰“韩服”、传统建筑、民间信仰等,均可通过图像识别技术进行有效的提取与分析。
本研究所使用的数据集包含2100幅图像,涵盖63个类别,涉及到的传统韩文化元素包括但不限于“韩服”、“传统宫殿”、“丹青”等。这些元素不仅是韩国文化的象征,也是其历史和社会发展的重要见证。通过对这些元素的分割与识别,研究者能够深入分析其在当代社会中的表现与变迁,进而为传统文化的保护与传播提供数据支持。
此外,基于改进YOLOv8的分割系统还具有重要的应用价值。通过对传统韩文化元素的精准识别,相关机构和组织可以更有效地进行文化遗产的数字化保存与展示,促进公众对传统文化的认知与理解。例如,在博物馆展览、文化活动以及教育领域,该系统可以帮助观众更直观地了解传统文化的内涵与价值。同时,该系统的开发也为其他国家和地区的传统文化保护提供了借鉴,推动了全球范围内的文化交流与合作。
综上所述,基于改进YOLOv8的传统韩文化元素分割系统的研究,不仅为传统文化的保护与传承提供了新的技术手段,也为相关领域的研究提供了丰富的数据支持与理论基础。通过这一研究,我们期望能够激发更多人对传统文化的关注与热爱,促进文化的多样性与可持续发展,为构建和谐社会贡献力量。
图片效果
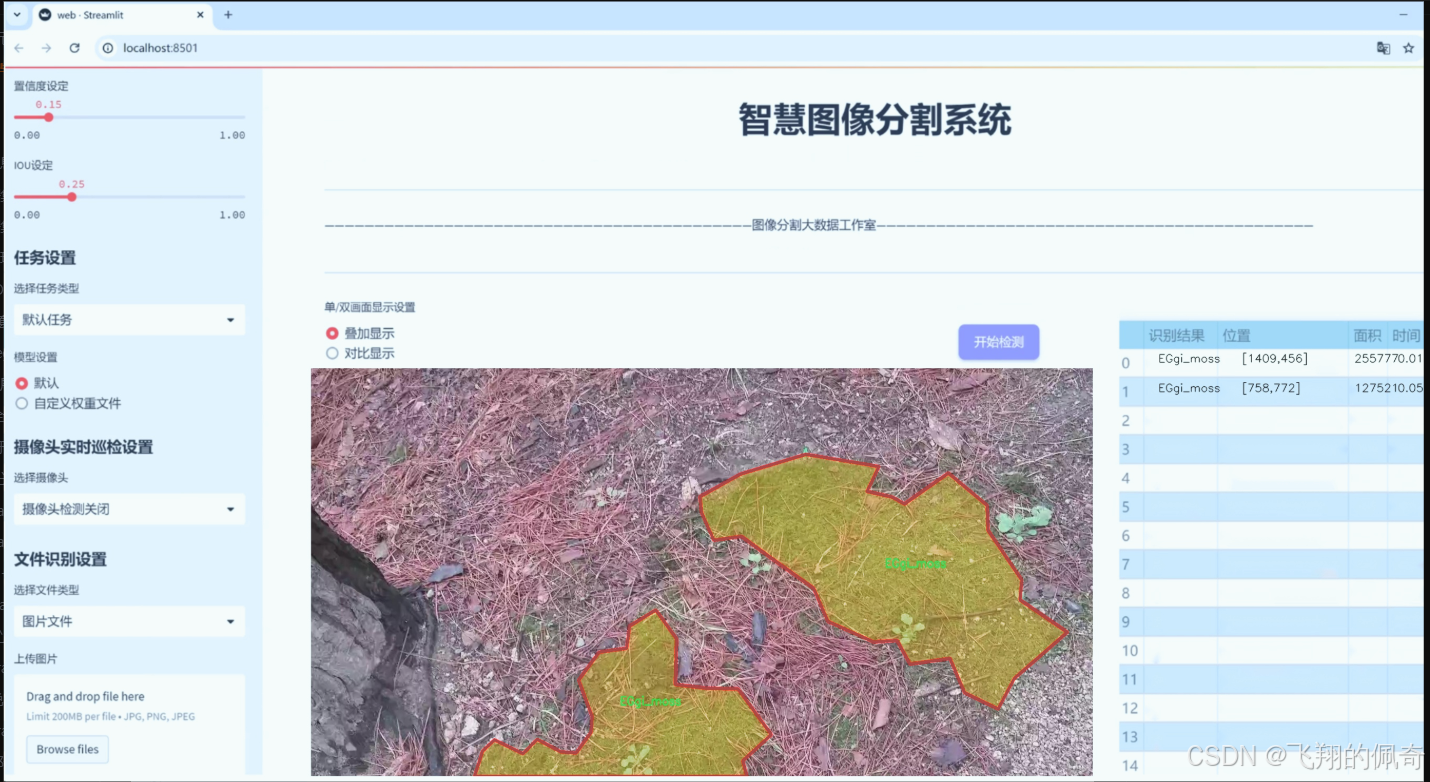
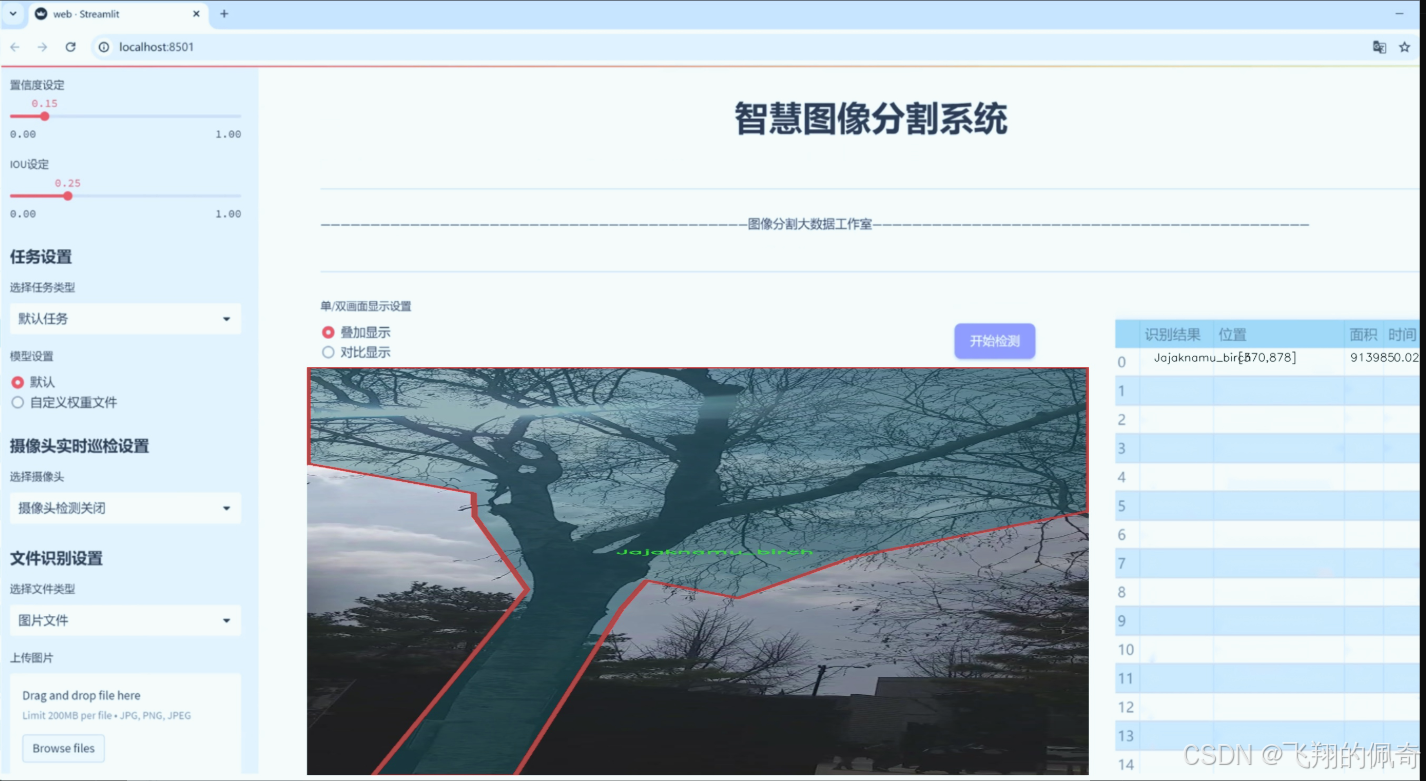
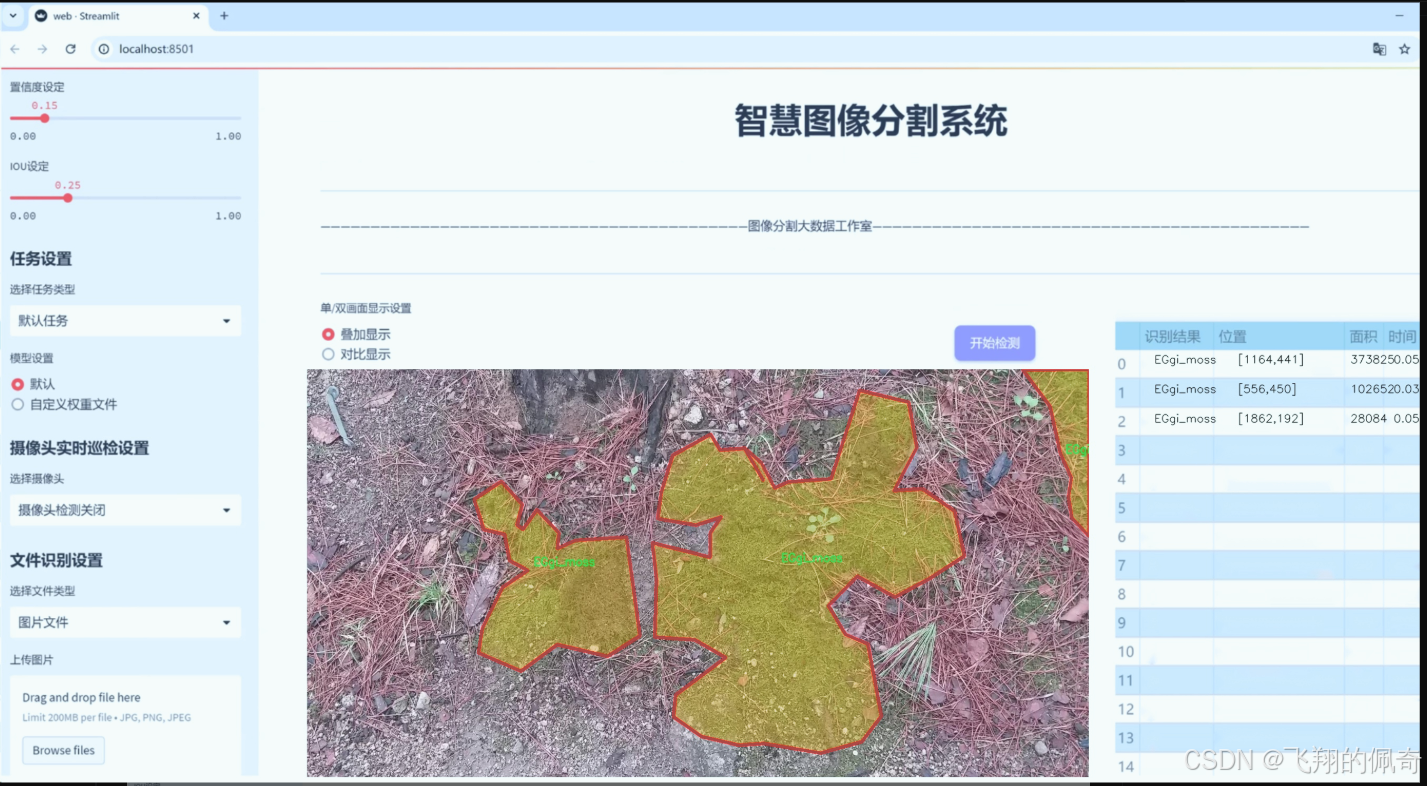
数据集信息
数据集信息展示
在现代计算机视觉领域,数据集的构建与应用是实现高效模型训练的基础。本研究所使用的数据集名为“sae_0309”,其主要目的是为改进YOLOv8-seg的传统韩文化元素分割系统提供丰富的训练数据。该数据集包含24个类别,涵盖了多种与韩国传统文化密切相关的元素,体现了深厚的文化底蕴和自然生态的多样性。
数据集中的类别列表包括了多种植物、动物以及传统服饰等元素,具体类别如下:-HalmiGgot(奶奶花)、Buknamu(北南木)、Ccachi(喜鹊)、ChulZzuk(皇家杜鹃)、Dancheong(韩国宫殿的彩绘)、Dungnamu(东南木)、EGgi(苔藓)、Ganari(甘栗)、Jaebi(紫罗兰)、Jajaknamu(桦树)、JindalRae(杜鹃花)、Korean Traditional Hanbok(韩国传统韩服)、Korean folk beliefs(韩国民间信仰)、Korean traditional palace(韩国传统宫殿)、KoreanLee(韩国李树)、Mindulrae(蒲公英)、MokRyun(木兰)、Pigeon(鸽子)、SAEZIP(塞子)、SalguGgot(杏花)、Sansuyou(山茱萸)、Sonamu(松树)、Whasalnamu(花梨木)、Wheyangmok(红枫)。这些类别不仅涵盖了自然界的植物和动物,还融入了丰富的文化元素,体现了韩国传统文化的独特魅力。
“sae_0309”数据集的构建过程注重数据的多样性和代表性,确保每个类别都有足够的样本,以便模型能够学习到更为细致的特征。这种多样性不仅体现在样本的数量上,还体现在样本的质量上。每个类别的图像均经过精心挑选,确保其在光照、角度和背景等方面的多样性,以提高模型的泛化能力。此外,数据集中的图像还经过标注,确保每个元素的边界清晰可辨,从而为分割任务提供准确的训练数据。
在数据集的应用方面,研究者可以利用“sae_0309”进行YOLOv8-seg模型的训练,以实现对传统韩文化元素的高效分割。这一过程不仅有助于提升模型的分割精度,还能为后续的文化遗产保护、数字化展示等应用提供技术支持。通过对这些传统元素的精确分割,研究者能够更好地分析和理解韩国文化的多样性与复杂性,从而为文化传承与创新提供新的视角。
总之,“sae_0309”数据集不仅是一个用于训练YOLOv8-seg模型的工具,更是一个承载着韩国传统文化和自然生态的丰富资源。通过对这一数据集的深入研究与应用,研究者能够在推动计算机视觉技术发展的同时,助力传统文化的保护与传播,为实现文化的可持续发展贡献力量。




核心代码
以下是经过简化并注释的核心代码部分:
import os
import platform
import logging
from pathlib import Path
import torch
import yaml
设置日志记录
def set_logging(name=‘ultralytics’, verbose=True):
“”“设置日志记录的配置”“”
level = logging.INFO if verbose else logging.ERROR # 根据verbose设置日志级别
logging.basicConfig(level=level, format=‘%(message)s’) # 配置日志格式
检查是否在Ubuntu系统上
def is_ubuntu() -> bool:
“”“检查当前操作系统是否为Ubuntu”“”
return platform.system() == ‘Linux’ and ‘ubuntu’ in platform.version().lower()
加载YAML文件
def yaml_load(file=‘data.yaml’):
“”“从YAML文件加载数据”“”
with open(file, ‘r’, encoding=‘utf-8’) as f:
return yaml.safe_load(f) # 使用安全加载避免执行任意代码
保存YAML文件
def yaml_save(file=‘data.yaml’, data=None):
“”“将数据保存到YAML文件”“”
with open(file, ‘w’, encoding=‘utf-8’) as f:
yaml.safe_dump(data, f, allow_unicode=True) # 允许Unicode字符
检查网络连接
def is_online() -> bool:
“”“检查是否有网络连接”“”
import socket
try:
# 尝试连接到一个公共DNS服务器
socket.create_connection((‘1.1.1.1’, 53), timeout=2)
return True
except OSError:
return False
默认配置路径
DEFAULT_CFG_PATH = Path(file).resolve().parents[1] / ‘cfg/default.yaml’
加载默认配置
DEFAULT_CFG_DICT = yaml_load(DEFAULT_CFG_PATH)
设置全局变量
USER_CONFIG_DIR = Path(os.getenv(‘YOLO_CONFIG_DIR’, str(Path.home() / ‘.config’ / ‘Ultralytics’))) # 用户配置目录
SETTINGS_YAML = USER_CONFIG_DIR / ‘settings.yaml’ # 设置文件路径
初始化日志
set_logging()
检查是否在Ubuntu系统上
if is_ubuntu():
print(“当前操作系统是Ubuntu”)
检查网络连接
if is_online():
print(“网络连接正常”)
else:
print(“没有网络连接”)
代码注释说明:
日志记录设置:set_logging函数用于配置日志记录的级别和格式,便于在运行时输出信息。
操作系统检查:is_ubuntu函数用于检查当前操作系统是否为Ubuntu,以便在特定环境下执行不同的操作。
YAML文件加载与保存:yaml_load和yaml_save函数用于从YAML文件加载数据和将数据保存到YAML文件,使用yaml.safe_load确保安全性。
网络连接检查:is_online函数通过尝试连接到公共DNS服务器来检查网络连接的可用性。
默认配置路径:DEFAULT_CFG_PATH用于定义默认配置文件的路径,便于后续加载。
全局变量初始化:USER_CONFIG_DIR和SETTINGS_YAML用于定义用户配置目录和设置文件的路径。
日志初始化和状态检查:在代码的最后部分,初始化日志并检查操作系统和网络状态,输出相应的信息。
这个文件是Ultralytics YOLO项目中的一个初始化模块,主要用于设置和管理各种工具和功能,以支持YOLO模型的训练和推理。文件中包含了许多导入的库和定义的常量、类、函数,以下是对文件内容的详细说明。
首先,文件导入了多个标准库和第三方库,包括contextlib、logging、os、platform、re、subprocess、sys、threading、urllib、uuid、cv2、matplotlib、numpy、torch和yaml等。这些库提供了文件操作、日志记录、并发处理、网络请求、数据处理等功能。
接下来,文件定义了一些常量,例如多GPU训练的相关常量(RANK和LOCAL_RANK),以及项目的根目录、默认配置文件路径、线程数、自动安装和详细模式的开关等。这些常量为后续的功能提供了基础设置。
文件中还包含了一个帮助信息字符串,提供了使用YOLOv8的示例,包括如何安装、如何使用Python SDK和命令行接口(CLI)进行模型训练、验证和预测等。
在设置部分,文件对torch、numpy和cv2进行了配置,以优化打印选项和线程使用,确保与PyTorch的兼容性。
接下来,定义了几个类,包括TQDM、SimpleClass和IterableSimpleNamespace。TQDM类是对tqdm库的自定义封装,提供了不同的默认参数。SimpleClass类提供了更友好的字符串表示和错误报告,便于调试。IterableSimpleNamespace类扩展了SimpleNamespace,增加了可迭代功能。
文件中还定义了一些实用函数,例如plt_settings用于设置Matplotlib的绘图参数,set_logging用于配置日志记录,emojis用于处理平台相关的表情符号,yaml_save和yaml_load用于保存和加载YAML格式的数据。
在默认配置部分,文件加载了默认的配置字典,并将其存储在DEFAULT_CFG中,方便后续使用。
文件还包含了一些环境检测函数,例如is_ubuntu、is_colab、is_kaggle、is_jupyter、is_docker等,用于检测当前运行环境。这些函数帮助确定代码在不同环境下的行为。
此外,文件中还定义了一些与Git相关的函数,例如is_git_dir、get_git_dir、get_git_origin_url和get_git_branch,用于获取当前Git仓库的信息。
最后,文件的末尾部分包含了一些初始化代码,包括设置默认的配置、确定数据集、权重和运行目录,并检测当前环境。它还应用了一些补丁,以确保在特定情况下的功能正常。
总体而言,这个文件是Ultralytics YOLO项目的核心工具模块,提供了多种功能和配置选项,以支持YOLO模型的使用和开发。
11.4 ultralytics\models\fastsam_init_.py
导入必要的模块和类
Ultralytics YOLO 🚀, AGPL-3.0 license
从当前包中导入 FastSAM 模型类
from .model import FastSAM
从当前包中导入用于预测的 FastSAMPredictor 类
from .predict import FastSAMPredictor
从当前包中导入用于提示的 FastSAMPrompt 类
from .prompt import FastSAMPrompt
从当前包中导入用于验证的 FastSAMValidator 类
from .val import FastSAMValidator
定义该模块公开的接口,包含四个类
all = ‘FastSAMPredictor’, ‘FastSAM’, ‘FastSAMPrompt’, ‘FastSAMValidator’
代码核心部分及注释说明:
模块导入:
from .model import FastSAM:导入 FastSAM 类,该类可能是模型的核心实现。
from .predict import FastSAMPredictor:导入 FastSAMPredictor 类,用于执行模型的预测功能。
from .prompt import FastSAMPrompt:导入 FastSAMPrompt 类,可能用于处理用户输入或提示信息。
from .val import FastSAMValidator:导入 FastSAMValidator 类,用于验证模型的性能或输出。
公开接口定义:
all 变量定义了模块的公共接口,只有在使用 from module import * 时,这些类会被导入。这有助于控制模块的可见性和使用。
通过这些核心部分的导入和定义,代码为后续的模型预测、用户交互和验证提供了基础结构。
这个程序文件是一个Python模块的初始化文件,位于ultralytics/models/fastsam目录下。它的主要功能是导入和组织与FastSAM相关的类和功能,以便在其他地方使用。
首先,文件开头有一行注释,提到这是Ultralytics YOLO项目的一部分,并且使用的是AGPL-3.0许可证。这表明该项目是开源的,并且遵循特定的许可证条款。
接下来,文件通过相对导入的方式引入了四个主要的组件:FastSAM、FastSAMPredictor、FastSAMPrompt和FastSAMValidator。这些组件分别来自于同一目录下的不同模块。具体来说:
FastSAM:可能是一个核心模型类,负责实现FastSAM算法的主要功能。
FastSAMPredictor:这个类可能用于执行预测任务,利用FastSAM模型进行推断。
FastSAMPrompt:这个类可能涉及到与用户交互的功能,比如接受输入提示或配置参数。
FastSAMValidator:这个类可能用于验证模型的性能或结果,确保其输出的准确性和可靠性。
最后,__all__变量定义了当使用from module import *语句时,哪些名称会被导入。这里列出了四个类的名称,表明它们是该模块的公共接口,用户可以直接使用这些类而不需要了解模块内部的实现细节。
总的来说,这个初始化文件的作用是将FastSAM相关的功能模块整合在一起,方便其他部分的代码进行调用和使用。
11.5 ultralytics\models\fastsam\val.py
Ultralytics YOLO 🚀, AGPL-3.0 license
from ultralytics.models.yolo.segment import SegmentationValidator
from ultralytics.utils.metrics import SegmentMetrics
class FastSAMValidator(SegmentationValidator):
“”"
自定义验证类,用于在Ultralytics YOLO框架中进行快速SAM(Segment Anything Model)分割。
该类扩展了SegmentationValidator类,专门定制了快速SAM的验证过程。它将任务设置为'分割',
并使用SegmentMetrics进行评估。此外,为了避免在验证过程中出现错误,禁用了绘图功能。
"""def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):"""初始化FastSAMValidator类,将任务设置为'分割',并将度量标准设置为SegmentMetrics。参数:dataloader (torch.utils.data.DataLoader): 用于验证的数据加载器。save_dir (Path, optional): 保存结果的目录。pbar (tqdm.tqdm): 用于显示进度的进度条。args (SimpleNamespace): 验证器的配置。_callbacks (dict): 用于存储各种回调函数的字典。注意:在此类中禁用了ConfusionMatrix和其他相关度量的绘图,以避免错误。"""# 调用父类的初始化方法super().__init__(dataloader, save_dir, pbar, args, _callbacks)# 设置任务类型为'分割'self.args.task = 'segment'# 禁用绘图功能,以避免在验证过程中出现错误self.args.plots = False# 初始化度量标准为SegmentMetrics,指定保存结果的目录self.metrics = SegmentMetrics(save_dir=self.save_dir, on_plot=self.on_plot)
代码核心部分解释:
类定义:FastSAMValidator 继承自 SegmentationValidator,用于实现快速SAM分割的自定义验证逻辑。
初始化方法:init 方法中设置了任务类型为’分割’,并禁用了绘图功能,以避免验证过程中的错误。
度量标准:使用 SegmentMetrics 进行评估,便于后续对分割结果的性能进行量化分析。
这个程序文件是Ultralytics YOLO框架中的一个自定义验证类,名为FastSAMValidator,主要用于快速的SAM(Segment Anything Model)分割任务。该类继承自SegmentationValidator,并对验证过程进行了特定的定制,以适应快速SAM的需求。
在类的文档字符串中,描述了其主要功能和属性。FastSAMValidator类的主要任务是进行图像分割,并使用SegmentMetrics来评估分割的效果。为了避免在验证过程中出现错误,该类禁用了绘图功能。
在构造函数__init__中,类接受多个参数,包括数据加载器、结果保存目录、进度条对象、配置参数和回调函数字典。构造函数首先调用父类的构造函数来初始化继承的属性,然后将任务类型设置为“segment”,并禁用绘图功能。最后,它初始化了SegmentMetrics对象,用于在验证过程中计算和保存评估指标。
总的来说,这个文件的主要目的是提供一个定制的验证工具,以便在Ultralytics YOLO框架中高效地进行图像分割任务,同时确保在验证过程中不会因为绘图功能而导致错误。
12.系统整体结构(节选)
程序整体功能和构架概括
Ultralytics YOLO项目是一个用于计算机视觉任务的深度学习框架,特别是目标检测和图像分割。该项目的架构模块化,包含多个子模块,每个模块负责特定的功能。整体上,项目的设计旨在提供高效、灵活的模型训练、推理和验证工具,以支持各种计算机视觉应用。
ultralytics/engine/results.py:处理模型推理结果,提供数据存储、操作和可视化的功能。
ultralytics/nn/backbone/repvit.py:实现RepViT模型,结合卷积神经网络和变换器的优点,用于图像处理任务。
ultralytics/utils/init.py:提供各种工具和实用函数,支持项目的配置、日志记录、环境检测等功能。
ultralytics/models/fastsam/init.py:初始化FastSAM相关模块,整合分割模型及其预测和验证功能。
ultralytics/models/fastsam/val.py:实现FastSAM模型的验证功能,评估分割效果并计算相关指标。
文件功能整理表
文件路径 功能描述
ultralytics/engine/results.py 处理推理结果,提供结果存储、操作和可视化功能,包括边界框、掩码和关键点的处理。
ultralytics/nn/backbone/repvit.py 实现RepViT模型,结合CNN和Transformer的优点,提供高效的图像处理能力。
ultralytics/utils/init.py 提供项目的工具和实用函数,包括配置、日志记录、环境检测等,支持整体框架的功能。
ultralytics/models/fastsam/init.py 初始化FastSAM相关模块,整合分割模型及其预测和验证功能,方便其他模块调用。
ultralytics/models/fastsam/val.py 实现FastSAM模型的验证功能,评估分割效果,计算并保存相关的性能指标。
这个表格总结了每个文件的主要功能,展示了Ultralytics YOLO项目的模块化设计和各个组件之间的协作关系。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)......# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)......# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param)# 绘制面积、周长、圆度和色彩值metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]for idx, (metric_name, metric_value) in enumerate(metrics):......return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():ret, frame = cap.read()if not ret:break......# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:processed_image = process_frame(model, image)......# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():ret, frame = cap.read()......
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
:刨根问底鸢尾花分类中的参数推理计算)


















