1.磁盘结构
Linux中的文件加载到内存上之前是放到哪的?
放在磁盘上的文件——>访问文件,打开它——>找到这个文件——>路径
但文件是怎样存储在磁盘上的
1.1物理结构

磁盘可以理解为上百亿个小磁铁(如N为1,S为0)
清除磁盘数据:消磁——软件、物理、化学
1.1.1磁盘的存储结构
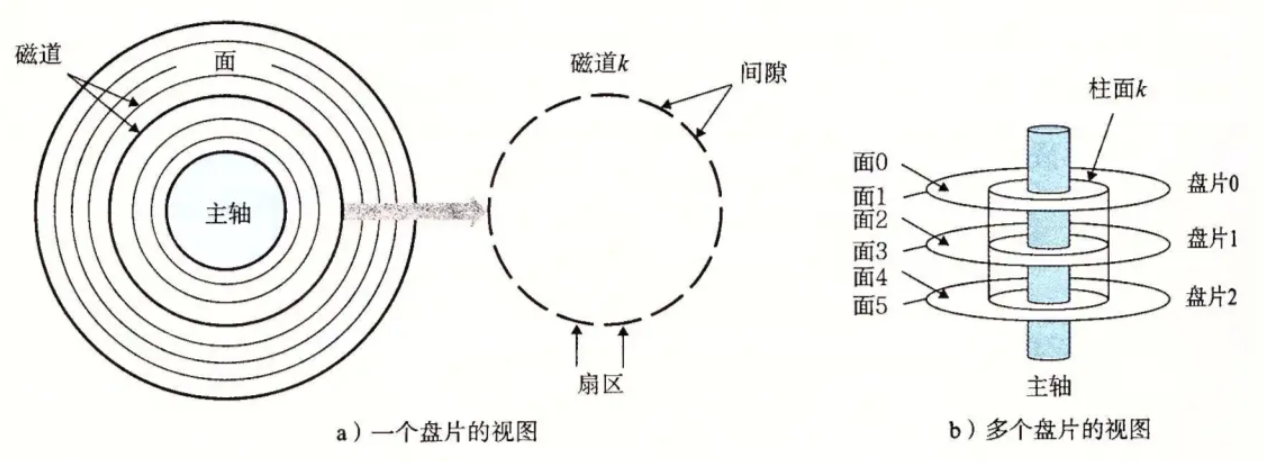
扇区:是磁盘存储的基本单位,512字节,块设备
磁头在摆动的本质:定位磁道(柱面)
磁盘盘片旋转的本质:定位扇区
磁盘容量 = 磁头数* 磁道数 * 扇区数 * 每扇区字节数
如何定位一个扇区?
1.先定位磁头(Header)
2.确定磁头要访问哪一个柱面(磁道)(Cylinder)
3.定位一个扇区(Sector)
4.这就是CHS地址定位法
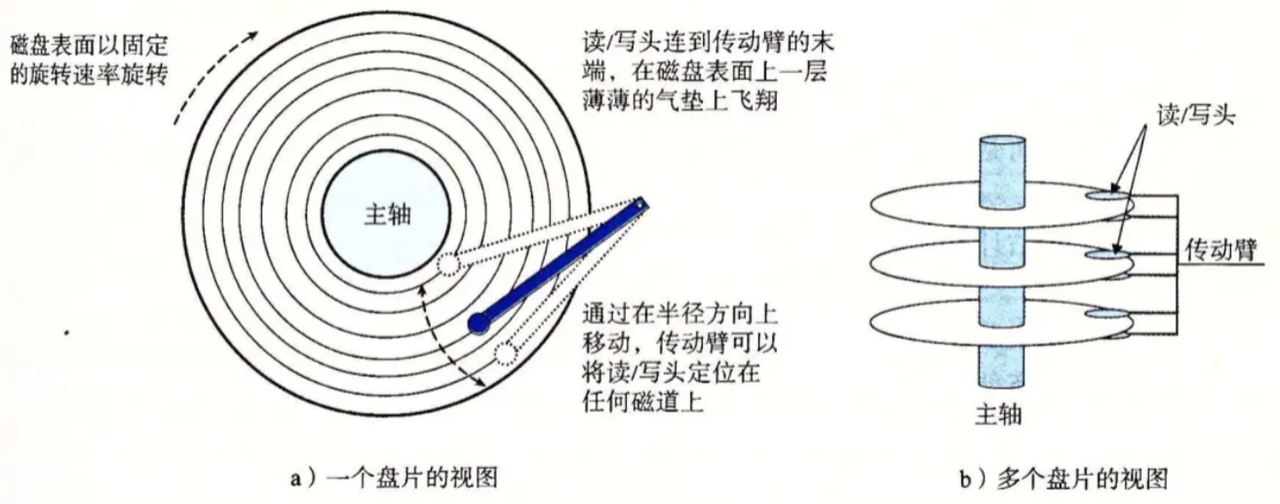
1.2逻辑结构
1.2.1逻辑抽象
⼀个细节:传动臂上的磁头是共进退的
柱⾯是⼀个逻辑上的概念,其实就是每⼀⾯上,相同半径的磁道逻辑上构成柱⾯。
所以,磁盘物理上分了很多⾯,但是在我们看来,逻辑上,磁盘整体是由“柱⾯”卷起来的。
磁道:
某⼀盘⾯的某⼀个磁道展开

柱⾯:
整个磁盘所有盘⾯的同⼀个磁道,即柱⾯展开:即二维数组
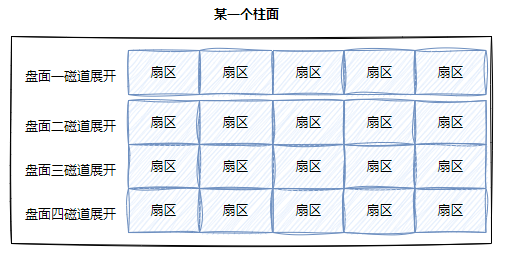
整盘:
整个磁盘不就是多张⼆维的扇区数组表(三维数组?)

每⼀个扇区都有⼀个下标,我们叫做LBA(Logical Block Address)地址,其实就是线性地址。
1.2.2CHS转LBA
LBA,1000,CHS 必须要! LBA地址转成CHS地址,CHS如何转换成为LBA地址?
由硬盘自己来做!固件(硬件电路,伺服系统)
CHS转成LBA:
• 磁头数每磁道扇区数 = 单个柱⾯的扇区总数
• LBA = 柱面号C * 单个柱面的扇区总数 + 磁头号H * 每磁道扇区数 + 扇区号S - 1
LBA转成CHS:
• 柱⾯号C = LBA // (磁头数每磁道扇区数)【就是单个柱面的扇区总数】
• 磁头号H = (LBA % (磁头数*每磁道扇区数)) // 每磁道扇区数
• 扇区号S = (LBA % 每磁道扇区数) + 1
• “//”: 表示除取整
2.抽象理解分区,格式化
OS和磁盘进行IO的时候,以扇区为基本单位,512字节作为单次数据量,有些少。
以1KB、2KB、4KB、8KB为单位,一般以4KB数据块——8个扇区
即一个数据库——8个LBA地址,这样就将磁盘转化成了 以块为单位的一维数组
通过将磁盘分区、分组,使用分治实现管理整个磁盘
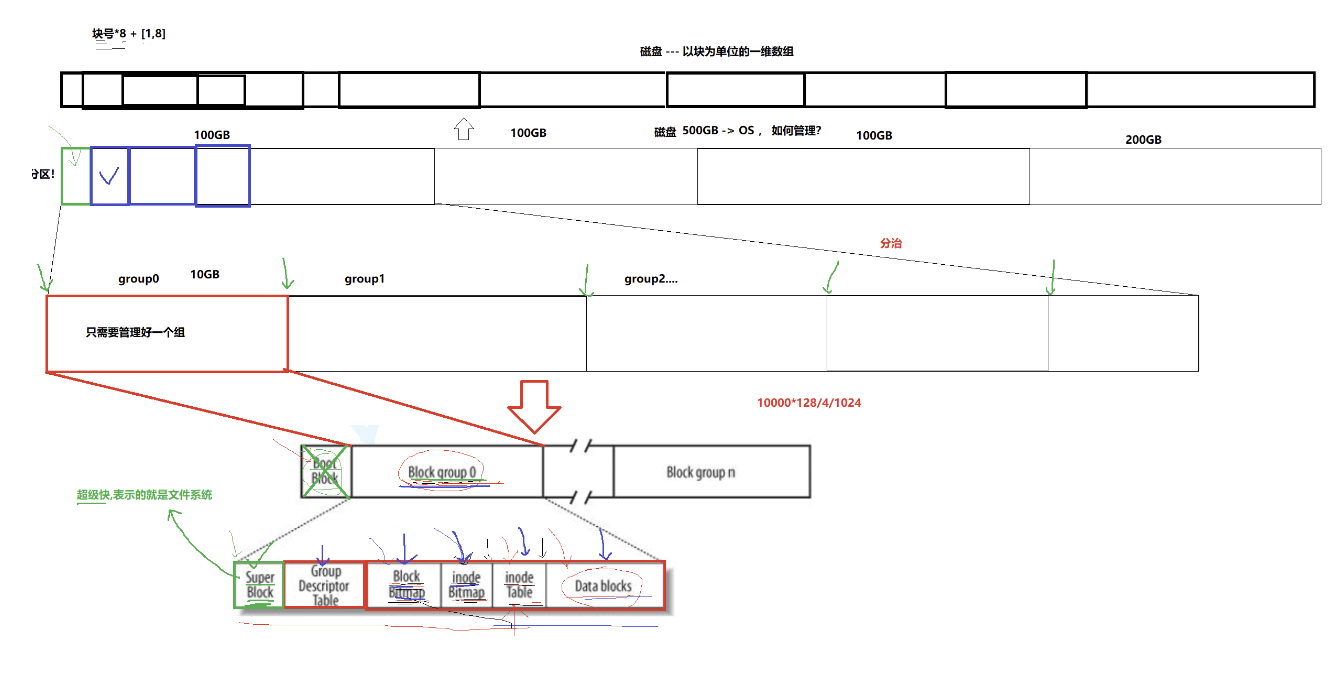
3.Ext系列的文件系统,inode号和inode
知识点:
1.文件 = 内容+属性
2.属性也是数据,以结构体方式构建出来的inode
3.一个文件一个inode,inode是属性数据的集合
在Linux中可以使用ls -l -i命令来查看文件inode编号,找到inode就能映射到对应储存位置Data

- Block Group:ext2 文件系统会根据分区的大小划分为数个 Block Group。而每个 Block Group都有着相同的结构组成。
- 超级块(Super Block):存放文件系统本身的结构信息,管理整个分区,不是每个组的super bloc都起作用。记录的信息主要有:bolck 和inode 的总量,未使用的 block 和 inode 的数量,一个 block 和 inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。
- GDT,Group Descriptor Table:块组描述符,描述块组属性信息
- 块位图(Block Bitmap):Block Bitmap 中记录着 Data Block中哪个数据块已经被占用,哪个数据块没有被占用
- inode 位图(inode Bitmap):每个 bit 表示一个 inode 是否空闲可用
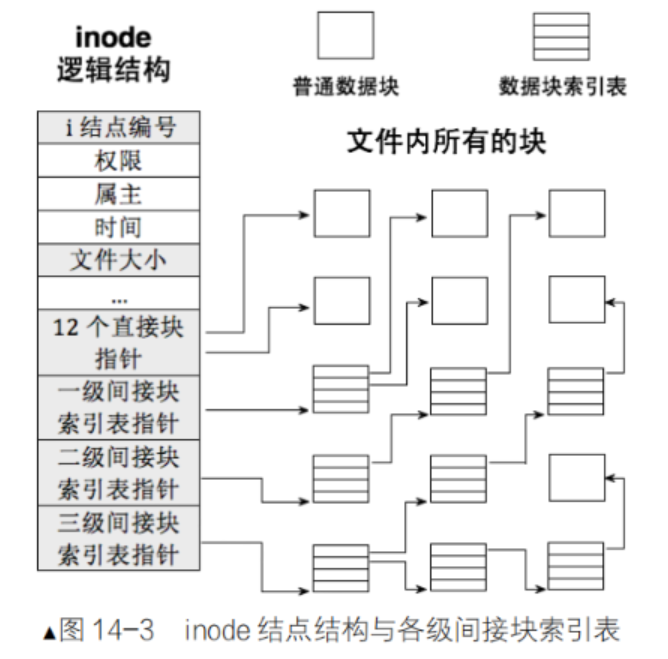
- 节点表(inode table):存放文件属性 如文件大小,所有者,最近修改时间等 ,如下图inode逻辑结构
- 数据区(data blocks):存放文件内容
删除的本质是设置inode bitmap、block bitmap,设置对应inode 、block无效
格式化:对inod bitmap、block bitmap 、GDT 、super block操作
4.理解什么叫文件,什么叫目录,准确理解文件系统
格式化即写入空的文件系统
GDT中存有start_inode、start_block他们是这个组包含的inode、block的起始编号。
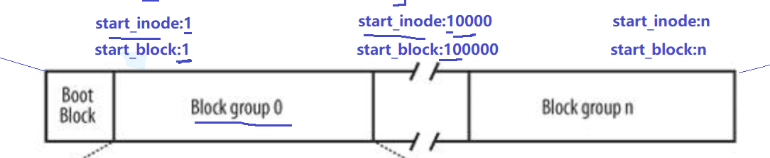
inode号的个数、block的个数都是固定的!(先分配inode、再分配block,故不存在inode没用完、data block用完的情况)
关于inode
1.inode以分区为单位,一套inode
2.inode分配时,只需确定起始inode即可
关于block
1.块号也是以分区为单位统一编号的
那么如何分配一个inode、block?
inode、block都是全局的(整个分区通用的),先根据GDT中的起始编号确定组,再根据bitmap确定是否有效,再通过inode table找到inode属性集
4.1文件的增删查改流程
已知inode号
1.如何查找一个文件?
- 通过GDT找到分组,使用inode号 - start_inode,找到组内的位置,通过bitmap判断该位置是否有效,再通过inode table找到inode属性集。
2.如何删除
- 找到文件后设置bitmap
3.如何新增
4.如何修改
- 找到文件后对inode、data block进行修改
4.2子问题1:inode和block怎么映射的
将组的设计和文件内容的设计解耦了,文件的内容可以是其他组的块
4.3子问题2:
4.3.1.我们使用中使用的都是文件名,OS怎么拿到inode的
文件名不再inode中保存。存在哪?——文件名分为:普通文件、目录文件——存在自己所处目录的数据块中
4.3.2.如何理解目录文件
目录 = inode + data block = 属性 + 内容
内容:对应数据块存储了 文件名:inode的映射关系。因为同一个目录中不能有同名文件,所以inode和文件名互为映射。
为什么要这样设计?
因为文件名可长可短,inode是数字定长,OS管理时效率高。
命令
ls -ln-ln可以将能显示成数字的内容显示为数字
查找文件的逻辑:
找到文件名——>打开当前目录——>当前目录也是文件,找到inode编号——>逆向路径解析——>从根目录找回去
为什么任何一个文件,都要有路径?? 进程提供的路径
每个进程都要有一个CWD,故 任何目标文件都有路径
那每次打开文件都要对路径进行逆向解析吗?
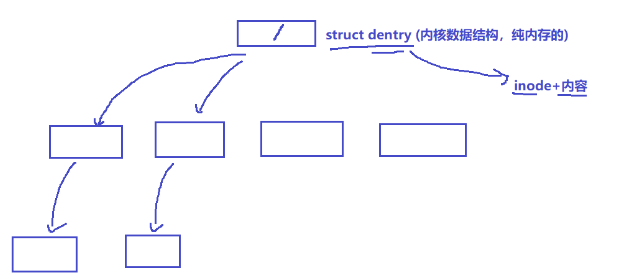
Linux可以对路径结构进行缓存
Linux以多叉树的结构对操作路径进行缓存
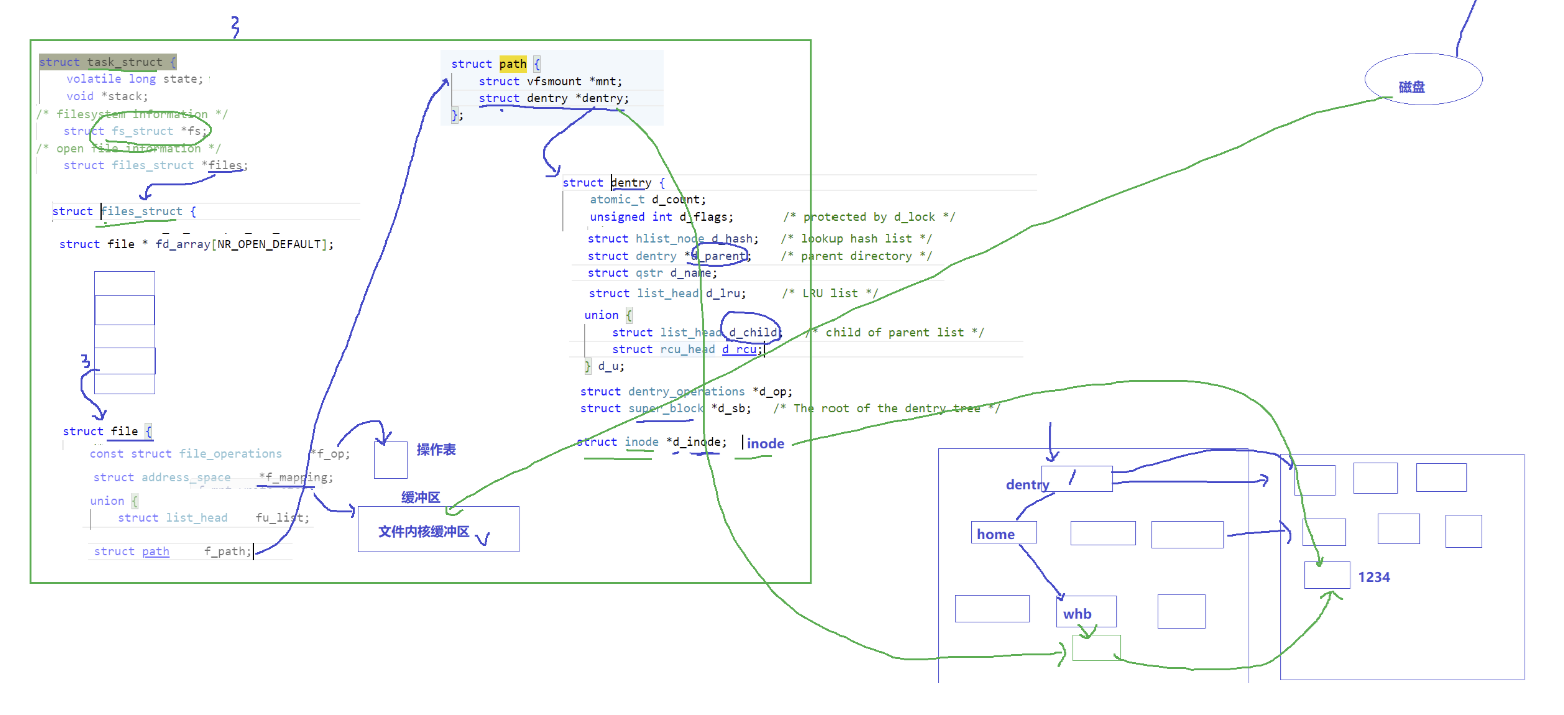
4.3.3.文件描述符和进程的关系
通过struct file 可以找到:
1.操作表
2.缓冲区
3.
path---dentry---inode| |
通过文件名访问磁盘上文件的流程:
通过task_struct找到打开的文件,通过file中的path找到dentry解析文件路径,通过自己所在目录的data block找到此文件的inode,再通过inode将磁盘中的内容映射到文件内核缓冲区
5.分区模拟挂载
怎么确认自己在哪一个分区中?(通过路径前缀)
多个分区——>一个分区包含若干个普通目录
|
只有分区该分区无法直接使用
分区必须经过“挂载”到目录上,分区才可以通过路径的方式进行访问
df -h可以查看磁盘信息
#复制数据
dd if=/dev/zero of=./disk.iso bs=1M count=5
#创建虚拟磁盘分区
mkfs.ext4 disk.iso
#挂载分区
mount -t ext4 ./disk.iso /mnt/myvda# #卸载分区
#umount
任何一个分区,天然有基本路径(经过挂载,路径+挂载点+新建目录)
6.软硬链接
ln -s file.txt file-soft.link #软链接
ln file.txt file-hard.ling #硬链接
6.1如何理解软硬链接
软链接本质是一个独立的文件,硬链接本质不是一个独立的文件
a.软链接没有独立的inode,软链接内容上,保存的是文件的路径,类似Windows的快捷方式
b.硬链接本质就是一组文件名和已经存在的文件的映射
6.2为什么要用软硬链接?各种应用场景
软链接:快捷方式(帮助快速找到指令和库)
硬链接:
- 1.可以使用硬链接对文件进行备份
- 2.硬链接文件后,因为inode相同,OS会存储inode的引用计数,目录也有引用计数,可通过硬链接分析一个目录内含几个目录(结合3.)

- 3.Linux不允许对目录进行新建硬链接(… 和 . 被特殊处理了)(因为会形成环状路径,软链接也会形成环状路径,但软链接的文件类型标识为l)
7.动态库和静态库
7.1静态库
制作静态库
# lib为固定前缀,.a为固定后缀 -rc:r意为replace,c意为create
ar -rc libmylib.a file1.o file2.o file3.o
使用静态库
方法一:安装到系统中 一般为目录 /lib64
# 使用-l选项:指定名称的外部库,库名称去前缀、后缀
gcc main.c -lmystdio
方法二:和源文件在同一目录下
# -L选项告诉编译器,编译的时候查找库时,除了系统路径,也要在指明路径下找
gcc main.c -L. -lmystdio
gcc在查找静态(动态)库时,不会在当前路径下找
方法三:使用带路径的库
# -I指定路径头文件 -L指定链接的目录 -l指定链接哪个库的目录
gcc main.c -Istdc/include -Lstdc/lib -lmystdio
7.2动态库
动态库制作:
# -shared :不要形成可执行程序,形成.so库
gcc -shared# -fPIC:意为 flag position ignore code
# 此指令为在.c文件编译为.o文件时形成与位置无关码
gcc -fPIC
动态库的使用
方法一:安装到系统 /lib64库中,链接方式与静态库相同
# 此命令可以查看依赖库
ldd a.out
方法二:和源文件在同一目录下(与静态库相同,gcc查找动态库时不会在当前路径下查)
方法三:使用带路径的库(与静态库相同)
7.3知识点
链接动态库的程序执行程序时会显示找不到.so库

编译时找动态库是告诉编译器库在哪
运行时呢?OS要加载程序,系统找不到库——静态库需要找吗?不需要
如何给系统指定路径,查找自己的动态库
1*.拷贝到系统默认路径下,如/lib64
2.在系统路径,建立软链接 ln
3*.Linux系统中,OS查找动态库,修改环境变量:LD_LIBRARY_PATH(将库路径加入环境变量)
4.idconfig(更改系统配置文件)配置如 /etc/ld.so.confd/
若同时提供动 、静态库,gcc、g++默认使用动态库,-static指明静态链接
如果强制静态链接,必须提供对应静态库
如果只提供静态库,但链接方式是动态链接的,gcc、g++没得选只能针对你的.a局部性采用静态链接
7.4动态库的理解,动态库的加载,进程地址空间
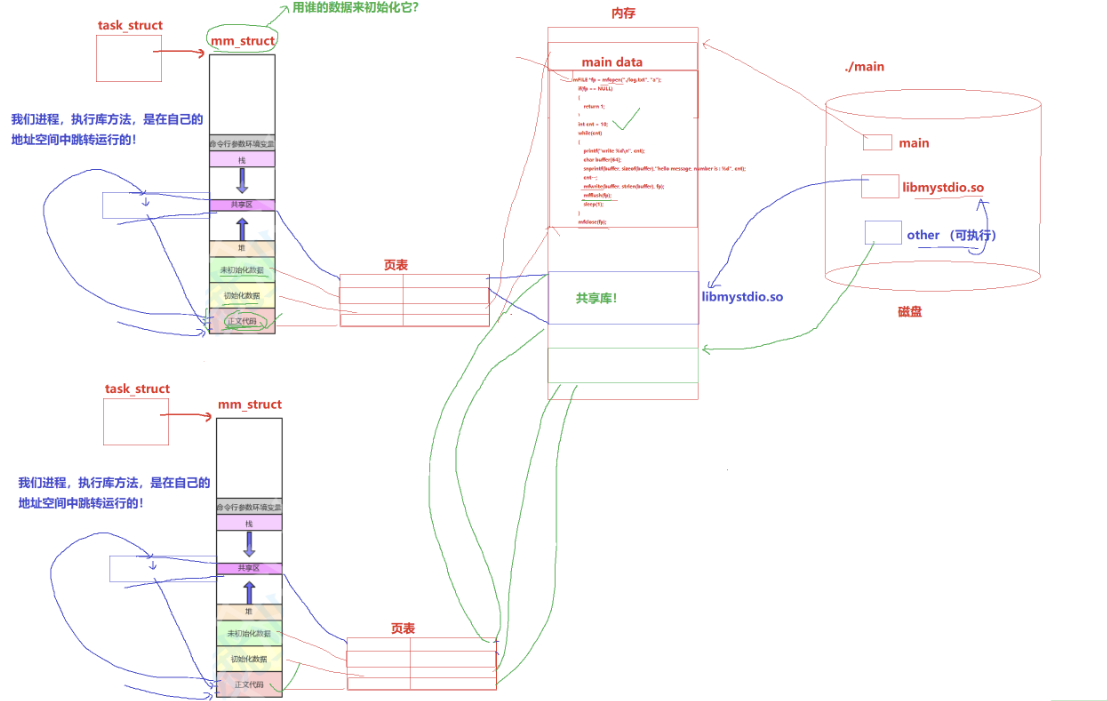
a.原理上理解动态库(共享库)
将动态库映射到进程的虚拟地址空间(共享区)
进程执行库方法时,是在自己的地址空间中跳转执行的
8.EIF文件
8.1可执行程序格式
-可重定位⽂件(Relocatable File) :.o ⽂件。
-可执行文件(Executable File) :即可执行程序。
-共享目标文件(Shared Object File) :即 xxx.so文件
上面三种文件都属于EIF文件,EIF文件的结构如下:
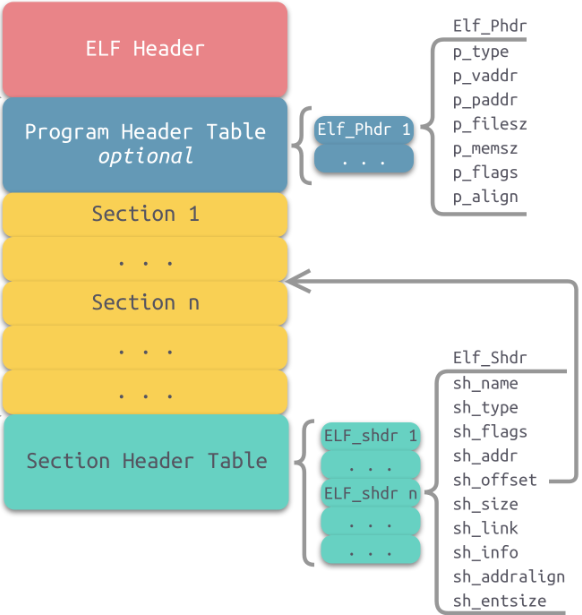
section中就是一段一段文件的内容,如:代码区(.text)、数据区(.data)
链接:就是将EIF文件一段一段相同属性的section进行合并。
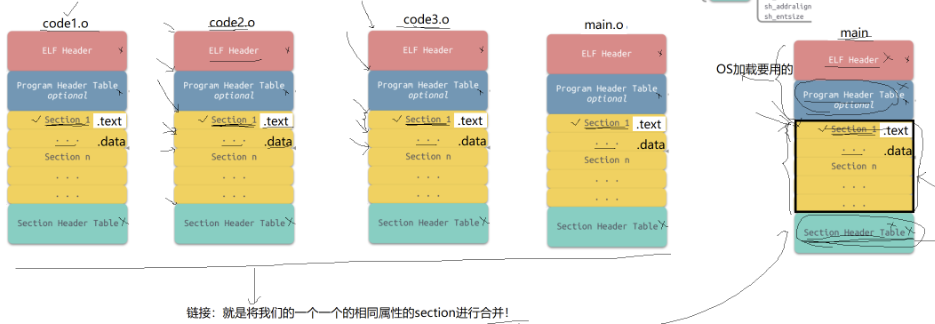
对于任何文件,文件的内容就是一个巨大的一维数组
标识文件任何一个区域,可以使用 偏移量+大小的方式
readelf指令可以查看某个EIF文件结构
8.2地址空间——可执行程序的加载
操作系统是要认识可执行程序的,那操作系统如何管理可执行程序的的代码的。
提出以下两个问题
1.mm_struct中的属性由谁初始化的?
2.可执行程序有没有地址的存在?
8.2.1可执行程序的地址
readelf -S 或 --section -headers #显示EIF文家节头信息
查看EIF文件节头信息,发现每一段汇编代码、函数头都有一个地址。
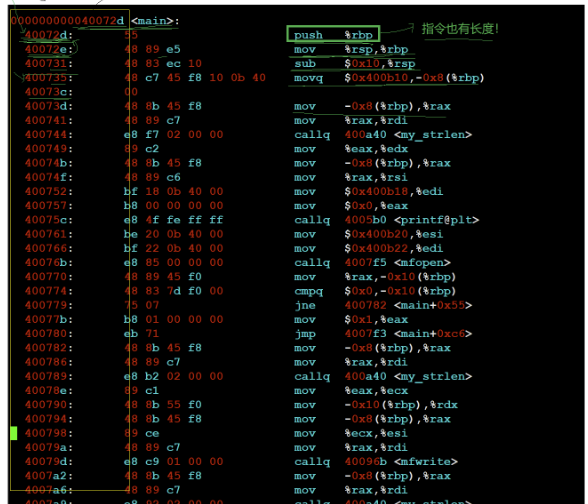
当代OS的可执行程序编址模式:
平坦模式:
逻辑地址 = 起始地址 + 偏移量[000···,FFF···]
故可以看出,EIF在没有加载到内存时,已经按照[000···,FFF···]进行编址了(虚拟地址)
故编译器编译时,就已经形成虚拟地址了。
逻辑地址(磁盘EIF) == 虚拟地址(加载到内存中时) //故逻辑地址和虚拟地址只是两种不同情景下的表达
执行程序时使用的是虚拟地址,执行时将Entry Point address放入PC指针,由MMU硬件(Memory Management Unit,查表逻辑在硬件电路中实现)查页表将虚拟地址转换为物理地址
- 故CPU出来的都是物理地址
- CR3寄存器,指向页表的起始地址
所以,虚拟地址是操作系统、CPU、编译器共同协作下的产物!!!
为什么要有虚拟地址和虚拟地址空间?
将编译器与OS解耦,编译器编址就可以以平坦模式编址了
8.2.2mm_struct中的属性填充
mm_struct存在一条属性mmap为分区链表

srtuct vm_area_struct即为虚拟地址的分区属性,其中包含vm_start和vm_end记录了开始和结束的地址。
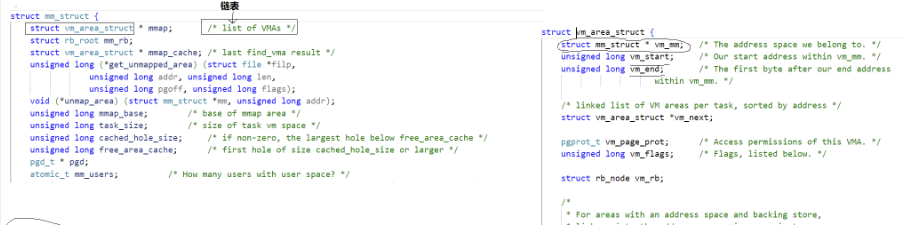
链接动态库到共享区,即新建vm_area_struct结构体链入链表
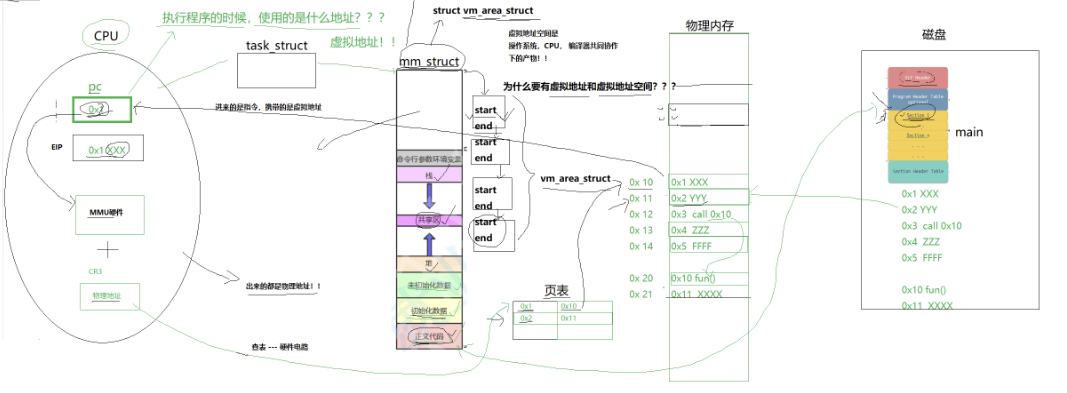
8.3动态库加载的理解
我们的程序运行之前,先把所有库加载并映射,所有库的起始虚拟地址都应该提前知道
然后对我们加载到内存中的程序的库函数调用进行地址修改,在内存中二次完成地址设置
(加载地址重定位)
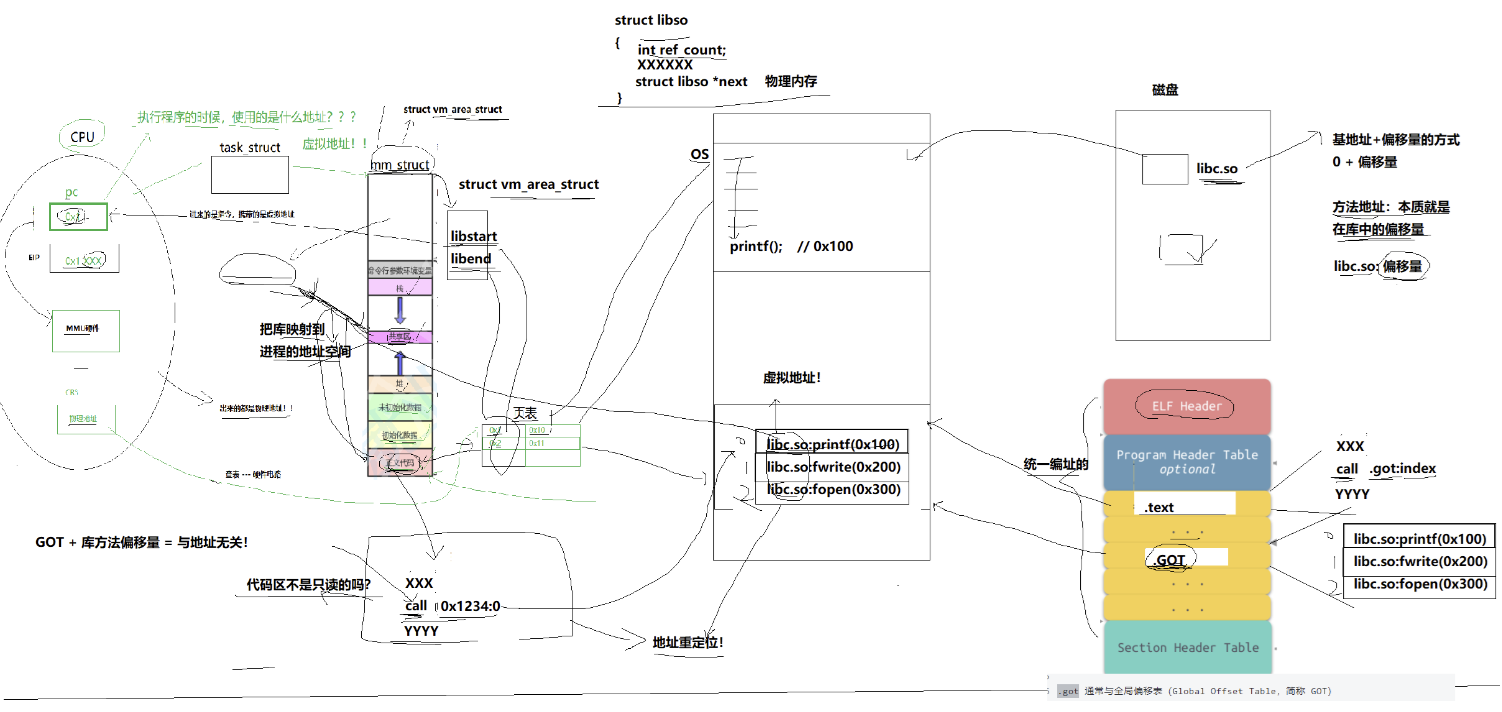
然而,代码区(.text)不是编译完成后就不能修改了吗,每次执行时动态库的虚拟地址 = 基地址 + 偏移量,不是要修改吗?
所以:动态链接采用的做法是在.data(可执行程序或者库自己)中专门预留一片区域用来存放函数
的跳转地址,它也被叫做全局偏移表.GOT(Global Offset Table),表中每一项都是本运行模块要引用的一个全局变量或函数的地址。代码区调用的动态库函数会指向此表。
所以:GOT + 库方法偏移量,这两种解决方案实现了与地址无关






)

)



:配置文件和devtool配置指南)



)


