文档
基础使用
- 前提:开发机器已安装mongo配置环境,已启动服务。
macOS启动服务:brew services start mongodb-community@8.0
macOS停止服务:brew services stop mongodb-community@8.0 - 安装:
python3 -m pip install pymongo - 导入:
import pymongo - 与MongoClient建立连接:
client = MongoClient()from pymongo import MongoClient# 创建连接的三种方式:(任选一种即可) ## 第一种:使用默认的主机 localhost 和端口号 27017 创建连接 client = MongoClient() ## 第二种:指定主机和端口创建连接 client_1 = MongoClient("localhost", 27017) ## 第三种:使用url格式创建连接 client_2 = MongoClient("mongodb://localhost:27017/")# 有账号密码时的连接 client3 = MongoClient(f"mongodb://{username}:{password}@localhost:27017/mydatabase?authSource=admin") ## 或者使用独立参数 client4 = MongoClient(host='localhost',port=27017,username='your_username',password='your_password@123',authSource='admin', # 认证数据库 ) ## 若密码包含特殊字符,则需要额外处理 from urllib.parse import quote_plus safe_password = quote_plus("p@ssw:rd/$") - 获取数据库:
db = client.test_database# 获取数据库的两种方式: ## 第一种:通过 .数据库名 获取 db = client.test_database ## 第二种:如果数据库名含特殊字符,不能使用属性样式访问时,可通过 字典式 访问 db1 = client['test-database'] - 收集(数据库表):
collection = db.test_collection# 获取数据库表的两种方式: ## 第一种:通过 .表名 获取 collection = db.test_collection ## 第二种:如果表名含特殊字符,不能使用属性样式访问时,可通过 字典式 访问 collection1 = db['test-collection'] - 文件(表数据):可以包含原生Python类型(如
datetime.datetime实例),它们将自动转换为相应的BSON类型。(二进制json格式)# 构造表数据 import datetime post = {"author": "Mike","text": "My first blog post!","tags": ["mongodb", "python", "pymongo"],"date": datetime.datetime.now(tz=datetime.timezone.utc), } - 插入文档(将数据插入到数据库表中):
collection.insert_one(post)
⚠️注意:由于延迟创建,此时(在向集合和数据库中插入第一个文档时)才会创建这些集合和数据库。# 将文档插入到集合中(即将数据插入到数据库表) post_id = collection.insert_one(post).inserted_id print(post_id) # 插入数据对应的id # 查看集合(数据库表) db.list_collection_names() # ['collection'] - 获取单个文档(获取表中某个数据):
result = collection.find_one({'key':'value'})
⚠️注意:返回的文档包含 “_id” ,在插入时自动添加。(也可以按{'_id': ObjectId(post_id)}来查找)# 默认获取第一个数据 collection.find_one() # 根据条件查找匹配的数据 collection.find_one({'key':'value'}) - 大容量插入(批量插入多条数据):
result = collection.insert_many(collection_data_list)new_posts = [{"author": "Mike","text": "Another post!","tags": ["bulk", "insert"],"date": datetime.datetime(2009, 11, 12, 11, 14),},{"author": "Eliot","title": "MongoDB is fun","text": "and pretty easy too!","date": datetime.datetime(2009, 11, 10, 10, 45),}, ] result = collection.insert_many(new_posts) # 参数为列表 result.inserted_ids # 可以获取插入后的id列表 - 查询多个文档:
result = collection.find({'key':'value'}),result是在collection表内搜索key=value的结果列表。 - 计数:
- 获取所有数据条数:
collection.count_documents({}) - 获取特定条件的数据条数:
collection.count_documents({"author": "Mike"})
- 获取所有数据条数:
- 范围查询:
collection.find({"date": {"$lt": date_value}}).sort("author"),查询date_value日期之前的帖子,按作者对结果进行排序。d = datetime.datetime(2009, 11, 12, 12) result = collection.find({"date": {"$lt": d}}).sort("author") # result是一个字典列表 - 索引:添加索引有助于加速某些查询,还可以为查询和存储文档添加附加功能。
result = collection.create_index([("user_id", pymongo.ASCENDING)], unique=True) # 将user_id设置为唯一索引 indexs = sorted(list(collection.index_information())) # 获取collection表中已创建的索引列表
PyMongo 常用方法汇总
| 方法 | 使用场景 | 示例代码 | 关键特性 |
|---|---|---|---|
find() | 条件查询、数据检索 | db.users.find({"status": "active"}, {"name": 1, "email": 1}) | 支持投影、排序、分页链式操作 |
insert_one() | 插入单个文档 | result = db.products.insert_one({"name": "Mouse", "price": 29.99})print(result.inserted_id) | 返回插入文档的_id |
insert_many() | 批量插入文档 | users = [{"name": "Alice"}, {"name": "Bob"}]result = db.users.insert_many(users, ordered=False) | 支持有序/无序插入,返回插入ID列表 |
update_one() | 更新单个文档 | db.users.update_one( {"_id": 123}, {"$set": {"status": "active"}}) | 使用$set避免覆盖整个文档 |
update_many() | 批量更新文档 | result = db.orders.update_many( {"status": "pending"}, {"$inc": {"retries": 1}}) | 返回匹配和修改的文档计数 |
delete_one() | 删除单个文档 | db.sessions.delete_one({"expire_at": {"$lt": datetime.now()}}) | 删除第一个匹配文档 |
delete_many() | 批量删除文档 | result = db.logs.delete_many({"created": {"$lt": datetime(2023,1,1)}})print(result.deleted_count) | 返回删除的文档数量 |
count_documents() | 统计符合条件的文档数量 | active_users = db.users.count_documents( {"status": "active", "last_login": {"$gt": last_month}}) | 替代已废弃的count()方法 |
distinct() | 获取字段的唯一值列表 | categories = db.products.distinct("category") | 比聚合$group更高效 |
aggregate() ⚠️ | 复杂数据分析、多阶段处理 | pipeline = [ {"$match": {"status": "active"}}, {"$group": {"_id": "$dept", "count": {"$sum": 1}}}]results = db.users.aggregate(pipeline) | 支持 $match, $group, $lookup等聚合阶段,先 $match过滤比较高效 |
find_one() | 查找单个文档 | user = db.users.find_one({"email": "user@example.com"}) | 直接返回文档对象或None |
find_one_and_update() | 原子查找并更新文档 | task = db.tasks.find_one_and_update( {"status": "pending"}, {"$set": {"status": "processing"}}, return_document=ReturnDocument.AFTER) | 保证操作的原子性 |
create_index() | 创建查询索引 | db.orders.create_index([("user_id", 1), ("create_time", -1)]) | 显著提升查询性能 |
bulk_write() | 高性能批量操作 | ops = [ UpdateOne({"id": 1}, {"$inc": {"views": 1}}), DeleteMany({"expired": True})]result = db.collection.bulk_write(ops, ordered=False) | 减少网络往返,提升吞吐量,ordered=False无序操作更快 |
drop() | 删除整个集合 | db.temp_data.drop() | 谨慎使用,不可逆操作 |
根据使用场景选择对应的方法:
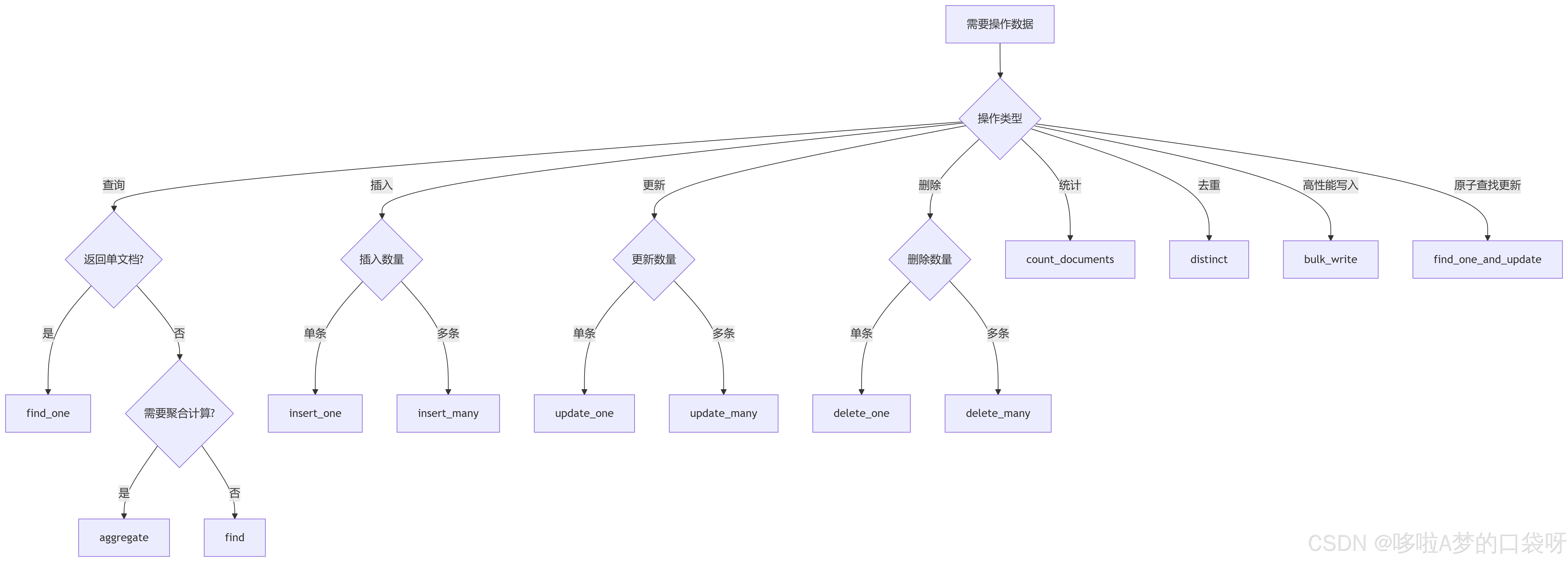
aggregate中pipeline的核心聚合操作符速查表
| 操作符 | 类别 | 功能描述 | 语法示例 |
|---|---|---|---|
$match | 筛选阶段 | 过滤文档 (类似SQL的WHERE) | {"$match": {"status": "active"}} |
$project | 重塑阶段 | 选择/重命名字段 (类似SELECT) | {"$project": {"name": 1, "year": {"$year": "$date"}}} |
$group | 分组阶段 | 按字段分组并计算聚合值 | {"$group": {"_id": "$dept", "total": {"$sum": "$salary"}}} |
$sort | 排序阶段 | 结果排序 (1升序, -1降序) | {"$sort": {"age": -1, "name": 1}} |
$limit | 限制阶段 | 限制输出文档数量 | {"$limit": 10} |
$skip | 跳过阶段 | 跳过指定数量文档 | {"$skip": 5} |
$unwind | 数组处理 | 展开数组为多条文档 | {"$unwind": "$tags"} |
$lookup | 关联查询 | 跨集合关联查询 (类似SQL JOIN) | {"$lookup": {"from": "products", # 关联集合"localField": "product_id", # 本地字段 "foreignField": "_id", # 关联集合字段"as": "product_info" # 输出字段名}} |
$addFields | 字段操作 | 添加新字段 (不改变原字段) | {"$addFields": {"discount": {"$multiply": ["$price", 0.9]}}} |
$count | 统计阶段 | 返回文档总数 | {"$count": "total_users"} |
$facet | 多管道处理 | 同一输入执行多个聚合管道 | pipeline = [ # 单次查询获取多种统计结果{"$facet": {"department_stats": [ # 部门统计管道{"$group": {... }}],"age_distribution": [ # 年龄分布管道 {"$bucket": {... }} ], "total_count": [ # 总计数管道{"$count": "value"} ]}}] |
在聚合管道中使用的核心表达式操作符:
| 类型 | 操作符 |
|---|---|
| 算术运算 | $add, $subtract, $multiply, $divide, $mod |
| 比较运算 | $eq, $ne, $gt, $gte, $lt, $lte, $cmp |
| 逻辑运算 | $and, $or, $not, $cond (三元表达式) |
| 日期处理 | $year, $month, $dayOfMonth, $hour, $minute, $dateToString |
| 字符串处理 | $concat, $substr, $toLower, $toUpper, $trim, $split |
| 数组处理 | $size, $slice, $map, $filter, $in, $arrayElemAt |
| 数据类型 | $type, $convert, $toInt, $toString, $toDate |
| 条件处理 | $ifNull, $switch (多分支条件) |
聚合管道优化策略
-
管道顺序优化原则
-
性能优化技巧
- 将
$match和$project放在管道最前端减少数据处理量 - 在
$lookup前使用$match过滤关联集合数据 - 避免在
$group中使用$push操作大数组 - 对
$sort和$match使用的字段创建索引 - 使用
allowDiskUse=True处理大数据集result = collection.aggregate(pipeline, allowDiskUse=True)
- 将







|SVM-拉格朗日乘数法理解)




)




与赛题)

