一.网络爬虫库
网络爬虫通俗来讲就是使用代码将HTML网页的内容下载到本地的过程。爬取网页主要是为了获取网之间需要中的关键信息,例如网页中的数据、图片、视频等。
urllib库:是Python自带的标准库,无须下载、安装即可直接使用。urllib库中包含大量的爬虫功能,但其代码编写略微复杂。
requests库:是Python的第三方库,需要下载、安装之后才能使用。由于requests库是在urllib军的基础上建立的,它包含urllib库的功能,这使得requests库中的函数和方法的使用更加友好,因此requests库使起来更加简洁、方便。
scrapy库:是Python的第三方库,需要下载、安装之后才能使用。scrapy库是一个适用于专业应用程序允许用户开发的网络爬虫库。scrapy库集合了爬虫的框架,通过框架可创建一个专业爬虫系统。
selenium库:是Python的第三方库,需要下载、安装后才能使用。selenium库可用于驱动计算机中的消览器执行相关命令,而无须用户手动操作。常用于自动驱动浏览器实现办公自动化和Web应用程序测试。
二.requests库和网页源码
1.requests库的安装
在命令提示符下执行以下命令:
pip install requests安装完后可以使用命令查看库信息:
pip show requests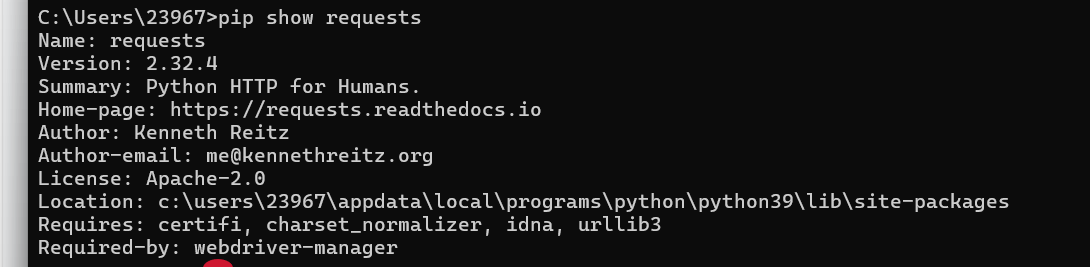
2.网页源码
用户在使用浏览器访间网页时,往往会忽视网页的源代码,而获取网页中的信息需要从源代码出发。例如使用浏览器打开首页,在网页空白处单击鼠标右键,选择快捷菜单中的‘查看源码’。

网页中的源代码形式与HTML代码形式基本相同,我们可尝试阅读网页中的源代码通过源代码可以轻松地获取网页中的文字、图片、视频等信息,还可以获取图片或视频文件的url并将文件下载到本地。而一个网页除了HTML代码还包含JawaScript脚本语言代码,JavaScript脚本语言使得浏览器可以解析和渲染网页源代码,使得用户可以阅览到图形界面,而不是阅读纯文本代码。网页中有大量数据是包含会在JavaScript脚本语言代码中的,而通过查看源代码的方式是无法获取这些数据的。网页源代码中是无法找到的,但可以通过检查(在网页空白处单击鼠标右键,选择快捷菜单中的检查选项)找到相应的信息
三.获取网页资源
requests库具有获取网页内容和向网页中提交信息的功能。
1.get()函数
在requests库中获取HTML网页内容的方法是使用get()函数。其使用形式如下:
get(url,params=None,**kwargs)参数url:表示需要获取的HTML网址(也称为url)。
参数params:表示可选参数,以字典的形式发送信息,当需要向网页中提交查询信息时使用。
参数**kwargs:表示请求采用的可选参数。
返回值:返回一个由类Response创建的对象。类Response位于requests库的models.py文件中。
import requests
r = requests.get('https://www.ptpress.com.cn/')
print(r.text)
2.get()搜索信息
当在网页中搜索人民邮电出版社的某些指定信息时,输入关键词“Excel”时,从搜索结果网页中可以看到当前页面的网址为https://www.ptpress.com.cn/search?keyword=excel.其中https://www.ptpress.com.cn/为官网主页,search表示搜索,keyword表示搜索的关键网(这里为 excel,表示需要搜索的关键词为“excel”),“?”用于分隔search和keyword.在其他网页中搜索也有与以上类似的效果,search或keyword可能会用其他字符表示,但基本形式是相同的。
import requests
r = requests.get('https://www.ptpress.com.cn/search?keyword=excel')
print(r.text)3.get()添加信息
get()函数中第2个参数params会以字典的形式在url后自动添加信息,需要提前将params定义为字典。示例代码:
import requests
info ={'keyword':'excel' }
r = requests.get('https://www.ptpress.com.cn/search',params=info)
print(r.url)
print(r.text)第2行代码建立字典info,包含一个键值对。
第3行代码使用get()函数获取网页,由于get()中包含参数params,因此系统会自动在url后添加字典信息,形式为https://www.ptpress.com.cn/search?keyword=excel,该使用形式便于灵活设定需要搜索的信息,即可以添加或删除字典信息。
第4行代码输出返回的Response对象中的url,即获取网页的url
4.返回Response对象
通过get()函数获取HTML网页内容后,由于网页的多样性,通常还需要对网页返回的Response对象进行设置。Response属性:
Response包含的属性有status_code、headers、url、encoding、cookies等。
status_code(状态码):当获取一个HTML网页时,网页所在的服务器会返回一个状态码,表明本次获取网页的状态。例如访问人民邮电出版社官网,当使用get()函数发出请求时,人民邮电出版社官网的服务器接收到请求信息后,会先判断请求信息是否合理,如果请求合理则返回状态码200和网页信息;如果请求不合理则返回一个异常状态码。
import requests
r = requests.get('https://www.ptpress.com.cn')
print(r.status_code)
if r.status_code==200:print(r.text)
else:print('本次访问失败')第3行代码输出Response对象返回的状态码。
第4行代码用于判断状态码是否为200,如果为200,则输出获取的网页内容,否则表明访问存在异常。
headers(响应头):服务器返回的附加信息,主要包括服务器传递的数据类型、使用的压缩方法、语言、服务器的信息、响应该请求的时间等。
url: 响应的最终url位置。
encoding:访问r.text时使用的编码。
cookies:服务器返回的文件。这是服务器为辨别用户身份,对用户操作进行会话跟踪而存储在用户本地终端数据上的数据。
5.设置编码
当访问一个网页时,如果获取的内容是乱码,这是由网页读取编码错误导致的,可以通过设置requests.get(url)返回的Response对象的encoding='utf'-8来修改Response对象.text'文本内容的编码方式。同时Response对象中提供了apparent_encoding()方法来自动识别网页的编码方式,不过由于此方法是由机器自动识别,因此可能会存在识别错误的情况。
如果要设置自动识别网页的编码方式,可以使用以下形式:
Response对象.encoding=Response对象.apparent_encoding
import requests
r = requests.get('https://www.baidu.com')
r.encoding = r.apparent_encoding
print(r.text)
6.返回网页内容
Response对象中返回网页内容有两种方法,分别是text()方法和content()方法,其中text方法在前面的内容中有介绍,它是以字符串的形式返回网页内容。而content()方法是以二进制的形式返回网页内容常用于直接保存网页中的媒体文件。
import requests
r = requests.get('https://cdn.ptpress.cn/uploadimg/Material/978-7-115-41359-8/72jpg/41359.jpg')
f2 = open('b.jpg','wb')
f2.write(r.content)
f2.close()第2行代码使用get()方法访问了图片的url
第3行代码使用open()函数创建了一个'b.jpg'文件,并且设置以二进制写入的模式。
第4行代码将获取的url内容以二进制形式写入文件。
执行代码后将在相应文件夹中存储一张图片,

6.小项目案例:实现处理获取的网页信息
项目描述:使用get()函数获取HTML网页源代码的目的在于让获取的信息为用户所用。
项目任务 :新书快递-人邮教育社区”网页中上架了新书现,需要使用requests库爬取当前网页中所有新书的书名。
项目实现步骤:
步骤1,通过使用requests库获取“新书快递-人邮教育社区”网页的全部内容。
步骤2,从网页中寻找到图书名,为了确保获取正确的图书名,需要提前在网页源代码中寻找到图书名并观察它们的特点。其步骤为:首先进入网页的源代码页面,其次观察到所有新上架图书的书名都在标签<h4>中,且位于<h4>标签的<a>标签中,标签中还存在属性title。这些特点在整个HTML网页源代码中是独一无二的。最后设计正则表达式,过滤开头为title且结尾为</ a></h4>的字符串内容。
项目实现代码:
import requests
import re
r = requests.get('https://www.ryjiaoyu.com/tag/details/7')
result = re.findall(r'title=(.+?)">(.+?)</a></h4>',r.text)
for i in range(len(result)):print('第',i+1,'本书: ',result[i][1])第3行代码使用get()函数爬取“新书快递-人邮教育社区”网页。
第4行代码使用正则表达式对r.text(网页中的内容)进行查找,最终找出满足正则表达式条件的语句


)








)




![[每日随题10] DP - 重链剖分 - 状压DP](http://pic.xiahunao.cn/[每日随题10] DP - 重链剖分 - 状压DP)


