深度学习是加深了层的深度神经网络。只需通过叠加层,就可以创建深度网络。
1、 加深网络
将深度学习中的重要技术(构成神经网络的各种层、学习时的有效技巧、对图像特别有效的CNN、参数的最优化方法等)汇总起来,创建一个深度网络,对MNIST数据集的手写数字识别。
1.1、构建网络

上图网络有如下特点:
1、基于3×3的小型滤波器的卷积层。特点是随着层的加深,通道数变大(卷积层的通道数从前面的层开始按顺序以16、16、32、32、64、64的方式增加)
2、插入了池化层,以逐渐减小中间数据的空间大小
3、激活函数是ReLU。
4、全连接层的后面使用Dropout层。
5、基于Adam的最优化。
6、使用He初始值作为权重初始值。
实现代码:
# 构建深层网络
import sys, os
sys.path.append(os.pardir)
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *class DeepConvNet:"""识别率为99%以上的高精度的ConvNet网络结构如下所示conv - relu - conv- relu - pool -conv - relu - conv- relu - pool -conv - relu - conv- relu - pool -affine - relu - dropout - affine - dropout - softmax"""def __init__(self, input_dim=(1, 28, 28),conv_param_1 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},conv_param_2 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},conv_param_3 = {'filter_num':32, 'filter_size':3, 'pad':1, 'stride':1},conv_param_4 = {'filter_num':32, 'filter_size':3, 'pad':2, 'stride':1},conv_param_5 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},conv_param_6 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},hidden_size=50, output_size=10):# 初始化权重===========# 各层的神经元平均与前一层的几个神经元有连接(TODO:自动计算)pre_node_nums = np.array([1*3*3, 16*3*3, 16*3*3, 32*3*3, 32*3*3, 64*3*3, 64*4*4, hidden_size])wight_init_scales = np.sqrt(2.0 / pre_node_nums) # 使用ReLU的情况下推荐的初始值self.params = {}pre_channel_num = input_dim[0]for idx, conv_param in enumerate([conv_param_1, conv_param_2, conv_param_3, conv_param_4, conv_param_5, conv_param_6]):self.params['W' + str(idx+1)] = wight_init_scales[idx] * np.random.randn(conv_param['filter_num'], pre_channel_num, conv_param['filter_size'], conv_param['filter_size'])self.params['b' + str(idx+1)] = np.zeros(conv_param['filter_num'])pre_channel_num = conv_param['filter_num']self.params['W7'] = wight_init_scales[6] * np.random.randn(64*4*4, hidden_size)self.params['b7'] = np.zeros(hidden_size)self.params['W8'] = wight_init_scales[7] * np.random.randn(hidden_size, output_size)self.params['b8'] = np.zeros(output_size)# 生成层===========self.layers = []self.layers.append(Convolution(self.params['W1'], self.params['b1'], conv_param_1['stride'], conv_param_1['pad']))self.layers.append(Relu())self.layers.append(Convolution(self.params['W2'], self.params['b2'], conv_param_2['stride'], conv_param_2['pad']))self.layers.append(Relu())self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))self.layers.append(Convolution(self.params['W3'], self.params['b3'], conv_param_3['stride'], conv_param_3['pad']))self.layers.append(Relu())self.layers.append(Convolution(self.params['W4'], self.params['b4'],conv_param_4['stride'], conv_param_4['pad']))self.layers.append(Relu())self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))self.layers.append(Convolution(self.params['W5'], self.params['b5'],conv_param_5['stride'], conv_param_5['pad']))self.layers.append(Relu())self.layers.append(Convolution(self.params['W6'], self.params['b6'],conv_param_6['stride'], conv_param_6['pad']))self.layers.append(Relu())self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))self.layers.append(Affine(self.params['W7'], self.params['b7']))self.layers.append(Relu())self.layers.append(Dropout(0.5))self.layers.append(Affine(self.params['W8'], self.params['b8']))self.layers.append(Dropout(0.5))self.last_layer = SoftmaxWithLoss()def predict(self, x, train_flg=False):for layer in self.layers:if isinstance(layer, Dropout):x = layer.forward(x, train_flg)else:x = layer.forward(x)return xdef loss(self, x, t):y = self.predict(x, train_flg=True)return self.last_layer.forward(y, t)def accuracy(self, x, t, batch_size=100):if t.ndim != 1 : t = np.argmax(t, axis=1)acc = 0.0for i in range(int(x.shape[0] / batch_size)):tx = x[i*batch_size:(i+1)*batch_size]tt = t[i*batch_size:(i+1)*batch_size]y = self.predict(tx, train_flg=False)y = np.argmax(y, axis=1)acc += np.sum(y == tt)return acc / x.shape[0]def gradient(self, x, t):# forwardself.loss(x, t)# backwarddout = 1dout = self.last_layer.backward(dout)tmp_layers = self.layers.copy()tmp_layers.reverse()for layer in tmp_layers:dout = layer.backward(dout)# 设定grads = {}for i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):grads['W' + str(i+1)] = self.layers[layer_idx].dWgrads['b' + str(i+1)] = self.layers[layer_idx].dbreturn gradsdef save_params(self, file_name="params.pkl"):params = {}for key, val in self.params.items():params[key] = valwith open(file_name, 'wb') as f:pickle.dump(params, f)def load_params(self, file_name="params.pkl"):with open(file_name, 'rb') as f:params = pickle.load(f)for key, val in params.items():self.params[key] = valfor i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):self.layers[layer_idx].W = self.params['W' + str(i+1)]self.layers[layer_idx].b = self.params['b' + str(i+1)]
# 训练deep_convent
import sys, os
sys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from ch08.deep_convnet import DeepConvNet
from common.trainer import Trainer(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)network = DeepConvNet()
trainer = Trainer(network, x_train, t_train, x_test, t_test,epochs=20, mini_batch_size=100,optimizer='Adam', optimizer_param={'lr':0.001},evaluate_sample_num_per_epoch=1000)
trainer.train()# 保存参数
network.save_params("deep_convnet_params.pkl")
print("Saved Network Parameters!")运行结果:

如上结果,这个网络的识别精度约为99.4%,错误识别率为0.6%。
识别错误的例子:

所以,这次的深度CNN尽管识别精度很高,但是对于某些图像,也犯了和人类同样的“识别错误”。
1.2、进一步提高识别精度-Data Augmentation(数据扩充)
Data Augmentation基于算法“人为地”扩充输入图像(训练图像)。具体地说,如下图,对于输入图像,通过施加旋转、垂直或水平方向上的移动等微小变化,增加图像的数量。这在数据集的图像数量有限时尤其有效。
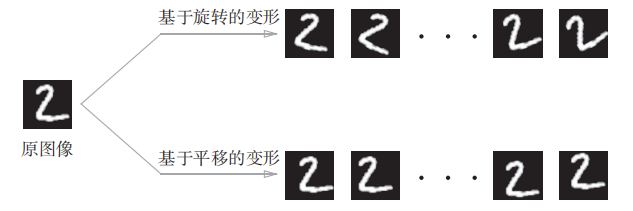
除了上图的变形之外,Data Augmentation还可以通过其他各种方法扩充图像,比如裁剪图像的“crop处理”、将图像左右翻转的“flip处理”等。对于一般的图像,施加亮度等外观上的变化、放大缩小等尺度上的变化也是有效的。综上,通过Data Augmentation巧妙地增加训练图像,可以提高深度学习的识别精度。虽然这个看上去只是一个简单的技巧,不过经常会有很好的效果。
1.3、加深层的动机
1、与没有加深层的网络相比,加深了层的网络可以用更少的参数达到同等水平(或者更强)的表现力。
叠加小型滤波器来加深网络的好处是可以减少参数的数量,扩大感受(receptive field,给神经元施加变化的某个局部空间区域)。并且,通过叠加层,将 ReLU等激活函数夹在卷积层的中间,进一步提高了网络的表现力。
这是因为向网络添加了基于激活函数的“非线性”表现力,通过非线性函数的叠加,可以表现更加复杂的东西。
例子:
5×5的卷积运算:

重复两次3×3的卷积层运算
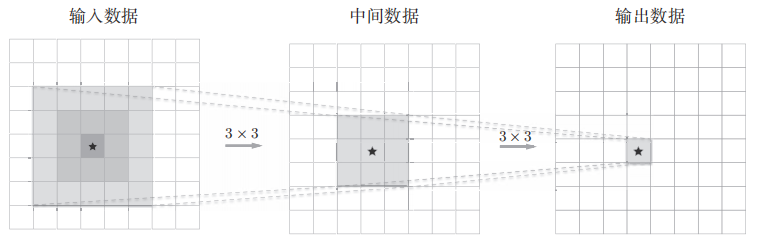
如上,一次5 × 5的卷积运算的区域可以由两次3 × 3的卷积运算抵充。并且,相对于前者的参数数量25(5 × 5),后者一共是18(2 × 3 × 3),通过叠加卷积层,参数数量减少了。而且,这个参数数量之差会随着层的加深而变大。比如,重复三次3 × 3的卷积运算时,参数的数量总共是27。而为了用一次卷积运算“观察”与之相同的区域,需要一个7 × 7的滤波器,此时的参数数量是49。
2、与没有加深层的网络相比,加深了层的网络可以可以减少学习数据,从而高效地进行学习。
在CNN的卷积层中,神经元会对边缘等简单的形状有响应,随着层的加深,开始对纹理、物体部件等更加复杂的东西有响应。
例子:
要用浅层网络解决这个问题的话,卷积层需要一下子理解很多“狗”的特征。“狗”有各种各样的种类,根据拍摄环境的不同,外观变化也很大。因此,要理解“狗”的特征,需要大量富有差异性的学习数据,而这会导致学习需要花费很多时间。
通过加深网络,就可以分层次地分解需要学习的问题。因为和印有“狗”的照片相比,包含边缘的图像数量众多,并且边缘的模式比“狗”的模式结构更简单。所以,各层需要学习的问题就变成了更简单的问题。比如,最开始的层只要专注于学习边缘就好,这样一来,只需用较少的学习数据就可以高效地进行学习。
2、 代表性网络
2.1、VGG
VGG是由卷积层和池化层构成的基础的CNN。

如上图,VGG的特点:
1、将有权重的层(卷积层或者全连接层)叠加至16层或者19层,具备了深度(称为“VGG16”或“VGG19”)。
2、基于3×3的小型滤波器的卷积层的运算是连续进行的。如图,重复进行“卷积层重叠2次到4次,再通过池化层将大小减半”的处理,最后经由全连接层输出结果。
2.2、GoogLeNet
GoogLeNet的网络结构如下图。图中的矩形表示卷积层、池化层等:

如上图,GoogLeNet的特点:
1、网络不仅在纵向上有深度,在横向上也有深度(广度)。
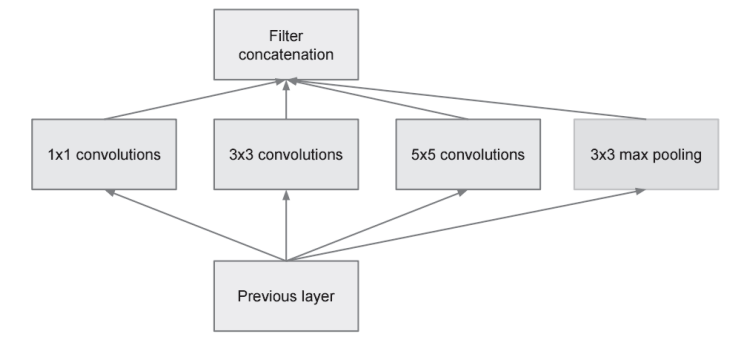
2、将Inception结构用作一个构件(构成元素)(横向上的“广度”,称为“Inception结构”。如下图,Inception结构使用了多个大小不同的滤波器和池化,最后再合并它们的结果)。
2.3、ResNet
ResNet以VGG网络为基础,引入快捷结构以加深层,结果如下图:

ResNet的特点
1、导入“快捷结构”导致即便加深到150层以上,识别精度也会持续提高。
2、通过以2个卷积层为间隔跳跃式地连接来加深层,使其具有比以前的网络更深的结构。
原理:
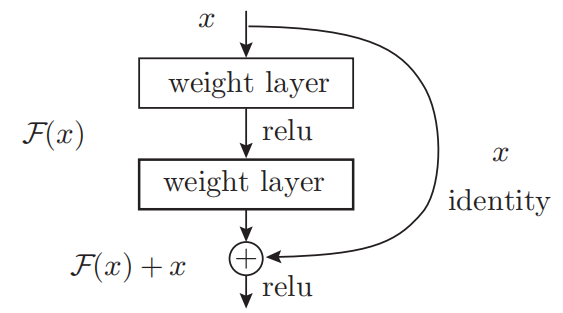
在深度学习中,过度加深层的话,很多情况下学习将不能顺利进行,导致最终性能不佳。而在ResNet中,为了解决这类问题,导入了“快捷结构”。导入快捷结构后,就可以随着层的加深而不断提高性能了(层的加深是有限度的)。
如上图,这是因为在连续2层的卷积层中,将输入x跳着连接至2层后的输出。这里的重点是,通过快捷结构,原来的2层卷积层的输出F(x)变成了F(x) + x。又因为,通过快捷结构,反向传播时信号可以无衰减地传递。所以通过引入这种快捷结构,即使加深层,也能高效地学习。
3、 深度学习的高速化-卷积层运算高速化
3.1、GPU
由于GPU不仅可以高速地进行图像处理,也可以高速地进行并行数值计算,因此 ,GPU计算(基于GPU进行通用的数值计算的操作)的目标就是将这种压倒性的计算能力用于各种用途。
CPU vs GPU:
CPU比较擅长连续的、复杂的计算。
GPU比较擅长大量的乘积累加运算,或者大型矩阵的乘积运算。
综上,与使用单个CPU相比,使用GPU进行深度学习的运算可以达到惊人的高速化。
3.2、分布式学习
分布式学习:将深度学习的学习过程扩展开来。
为了进一步提高深度学习所需的计算的速度,可以考虑在多个GPU或者多台机器上进行分布式计算。至于“如何进行分布式计算”是一个非常难的课题。它包含了机器间的通信、数据的同步等多个无法轻易解决的问题。可以将这些难题都交给TensorFlow等优秀的框架。
3.3、运算精度的位数缩减
为了避免流经GPU(或者CPU)总线的数据超过某个限制,要尽可能减少流经网络的数据的位数。又因为神经网络的健壮性,深度学习并不那么需要数值精度的位数。所以,在深度学习中,即便是16位的半精度浮点数(half float),也可以顺利地进行学习且识别精度不会下降。
代码证明:
# 证明在深度学习中,即便是16位的半精度浮点数(half float),也可以顺利地进行学习
import sys, os
sys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from ch08.deep_convnet import DeepConvNet
from dataset.mnist import load_mnist(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)network = DeepConvNet()
network.load_params("deep_convnet_params.pkl")sampled = 10000 # 为了实现高速化
x_test = x_test[:sampled]
t_test = t_test[:sampled]print("caluculate accuracy (float64) ... ")
print(network.accuracy(x_test, t_test))# 转换为float16型
x_test = x_test.astype(np.float16)
for param in network.params.values():param[...] = param.astype(np.float16)print("caluculate accuracy (float16) ... ")
print(network.accuracy(x_test, t_test))4、 深度学习的应用
深度学习并不局限于物体识别,在图像、语音、自然语言等各个不同的领域,深度学习都展现了优异的性能。
4.1、物体检测(R-CNN)
物体检测是从图像中确定物体的位置,并进行分类的问题。

解决方法为R-CNN的处理流(R-CNN用一个CNN来完成所有处理,使得高速处理成为可能):
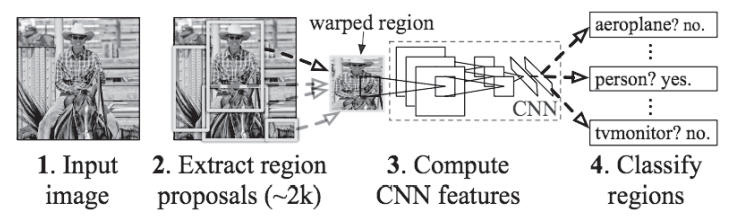
上图中的第2步和第3步“2.Extract region proposals”(候选区域的提取)和“3.Compute CNN features”(CNN特征的计算)的处理部分。这里,首先(用Selective Search、Faster R-CNN等方法)找出形似物体的区域,然后对提取出的区域应用CNN进行分类。R-CNN中会将图像变形为正方形,或者在分类时使用SVM(支持向量机),实际的处理流会稍微复杂一些,不过从宏观上看,也是由刚才的两个处理(候选区域的提取和CNN特征的计算)构成的。
4.2、图像分割(FCN)
图像分割是指在像素水平上对图像进行分类。如下图,使用以像素为单位对各个对象分别着色的监督数据进行学习。然后,在推理时,对输入图像的所有像素进行分类。

解决方法为用FCN(Fully Convolutional Network)通过一次forward处理,对所有像素进行分类:
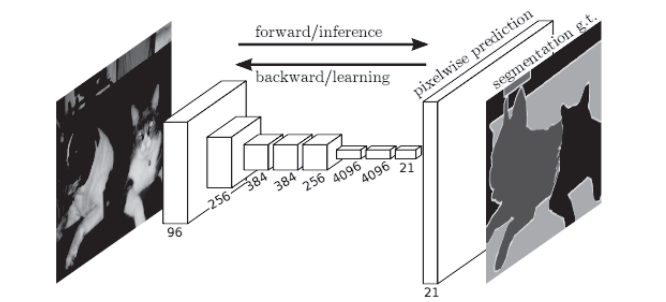
FCN即“全部由卷积层构成的网络”。相对于一般的CNN包含全连接层,FCN将全连接层替换成发挥相同作用的卷积层。在物体识别中使用的网络的全连接层中,中间数据的空间容量被作为排成一列的节点进行处理,如上图只由卷积层构成的网络中,FCN最后导入了扩大空间大小的处理。基于这个处理,变小了的中间数据可以一下子扩大到和输入图像一样的大小,空间容量可以保持原样直到最后的输出。
FCN最后进行的扩大处理是基于双线性插值法的扩大(双线性插值扩大)。FCN中,这个双线性插值扩大是通过去卷积(逆卷积运算)来实现的。
4.3、图像标题的生成(NIC)
给出一个图像后,会自动生成介绍这个图像的文字。

解决方法为NIC(Neural Image Caption)模型:
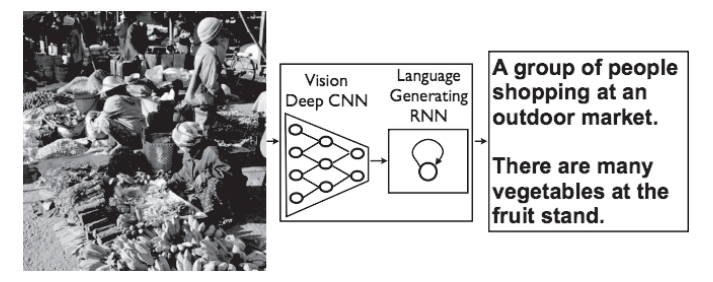
如上图,NIC由深层的CNN和处理自然语言的RNN(Recurrent Neural Network)构成。
RNN是呈递归式连接的网络,经常被用于自然语言、时间序列数据等连续性的数据上。
NIC基于CNN从图像中提取特征,并将这个特征传给RNN。
RNN以CNN提取出的特征为初始值,递归地生成文本。
多模态处理:将组合图像和自然语言等多种信息进行的处理。
4.4、其他应用
1、图像风格变换:输入两个图像后,会生成一个新的图像。

2、图像的生成:事先学习大量图像后生成新的图像

3、自动驾驶:计算机代替人类驾驶汽车

4、强化学习(reinforcement learning):像人类通过摸索试验来自主学习





)





与知识蒸馏(Knowledge Distillation, KD))







