目录
前言
一、天地图POI分类简介
1、数据表格
2、分类结构
二、从CSV导入到PG数据库
1、CSV解析流程
2、数据转换及入库
3、入库成果及检索
三、总结
前言
在之前的博客中,曾经对高德地图和百度地图的POI分类以及使用PostGIS数据库来进行管理的模式进行了详细的介绍。之前的博文列表:
| 序号 | 博客地址 |
| 1 | 基于ApachePOI实现百度POI分类快速导入PostgreSQL数据库实战 |
| 2 | 基于ApachePOI实现高德POI分类快速导入PostgreSQL数据库实战 |
相信大家在平时的日常生活中,用的比较多的肯定是百度地图和高德地图。虽然天地图在移动端的使用市场没有前两者的份额多。但是作为官方的标准,天地图还是拥有自己得天独厚的优势,除了本身最具权威的地理数据,同时还有承载着官方标准的执行。因此天地图的POI数据也是非常重要的,因此可以作为我们日常数据分析和处理的一个可靠的信息来源。不同的平台对POI的分级分类都有所不同,相信看过上面两篇博文的朋友一定知道,不同的厂商,对于POI分类时,它的大类和小类的定义一定是不一样的。但是天地图POI的分类存在非常大的差异,层次结构也是不一样的。如下图:
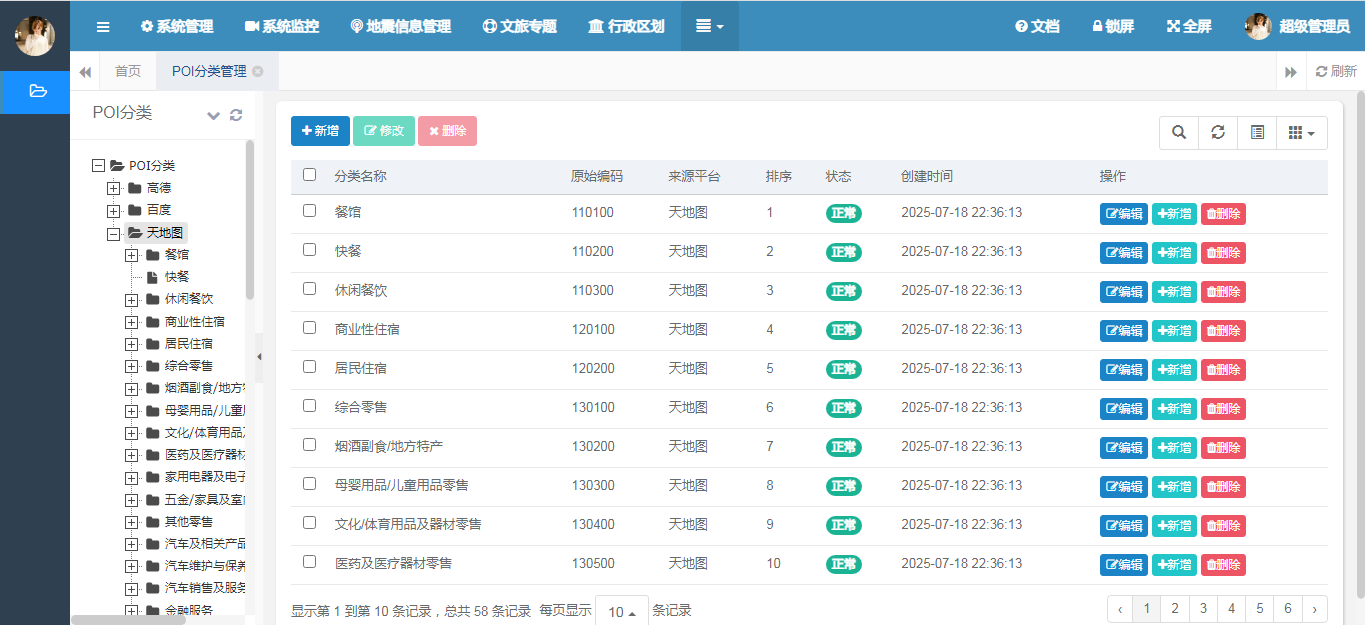
天地图的POI分类从大类来说就跟高德和百度不一样。单从一级大类的数量来说,百度拥有 32个,而高德只区分了25个,天地图居然有58个,在数量上天地图是比较多的(是否可以再精简和合并呢,需要讨论),比前两个加起来都多。另外从层级上来说,高德通常只区分了3级分类,而百度竟然有5级分类,然而天地图在层级上非常简单,只有2级展示,从扁平的角度来说,天地图的扁平化做的不错。
那么本文即来重点讲讲天地图POI分类与高德POI分类以及百度POI分类存在什么不一样的地方,同时结合代码深入讲解使用Java标准库来读取天地图的POI 分类兵如何进行数据导入到PostGIS空间数据库中,也为各类基于 POI 分类数据的地理信息系统开发、商业智能分析以及城市规划应用等,铺设一条从数据获取到存储利用的高效路径,助力行业在空间数据赋能下实现精准决策与创新发展。
一、天地图POI分类简介
本节将首先重点介绍天地图地图的POI分类信息,在之前的博客中我们设计了用于POI管理的物理表,这里可以继续用来存储天地图对应的POI分类信息。然后使用数据库脚本的方法对POI分类信息进行录入管理。对于天地图而言,其POI的分类较多,但是层级简单,因此这一节我们来详细的解读一下天地图的POI分类,让大家对分类信息有进一步的了解,为下一步对数据层级组装和批量解析入库打下牢固的基础。
1、数据表格
与之前介绍的内容一样,大家可以从天地图的地图开放平台中获取其最新的POI分类的CSV表格(是的,你没有看错,官方提供的确实是CSV而不是Excel,如果需要使用Excel也可以将CSV转一下格式),这里我将从官网下载的类型截取一部分给大家参考。下载链接传送门:分类编码表。下面来看下官方在数据检索的相关介绍:
1.1.1输入参数说明
| 参数值 | 参数说明 | 参数类型 | 是否必备 | 备注(值域) |
| keyWord | 搜索的关键字 | String | 必填 | 无 |
| specify | 指定行政区的国标码(行政区划编码表)严格按照行政区划编码表中的(名称,gb码) | String | 必填 | 下载行政区划编码表。9位国标码,如:北京:156110000或北京。 |
| queryType | 服务查询类型参数 | String | 必填 | 12:行政区划区域搜索服务。 |
| start | 返回结果起始位(用于分页和缓存)默认0 | String | 必填 | 0-300,表示返回结果的起始位置。 |
| count | 返回的结果数量(用于分页和缓存) | String | 必填 | 1-300,返回结果的条数。 |
| dataTypes | 数据分类(分类编码表) | String | 可选 | 下载分类编码表,参数可以分类名称或分类编码。多个分类用","隔开(英文逗号)。 |
| show | 返回poi结果信息类别 | String | 可选 | 取值为1,则返回基本poi信息; 取值为2,则返回详细poi信息 |
这里不进行赘述,需要原始CSV表格的,可以去网站上下载。打开下载后的表格数据如下:
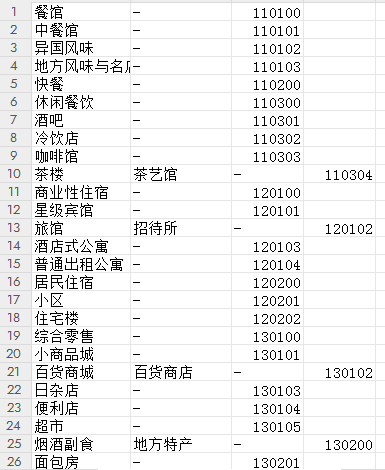
从上面这张图可以看出天地图的POI分类确实分的比较简单。 同时也能看到一个比较明显的区别,与百度的POI分类不一样的是,天地图有编码的概念。同样的,基于天地图地图的POI检索可以从返回接口中看到其对应的POI分类值为:
{"eaddress": "","address": "荣滨南路东段11号附28附近","city": "","provinceCode": "156500000","cityCode": "","county": "荣昌区","typeName": "副食专卖店","source": "0","typeCode": "130207","lonlat": "105.590250,29.416870","countyCode": "156500153","ename": "","province": "重庆市","phone": "18716232760","poiType": "101","name": "李氏卤鹅","hotPointID": "50166082CE55CFF5"
}其中typeCode对应poi分类的类别编码,而typeName则表示具体的类别名称。
2、分类结构
在了解了天地图的POI分类之后,下面我们基于之前设计的数据库物理表和分类信息构建树形的信息。因此需要对其分类采取细致的分类管理。在进行树形层次构建时,我们根据分类名称来进行统一管理:
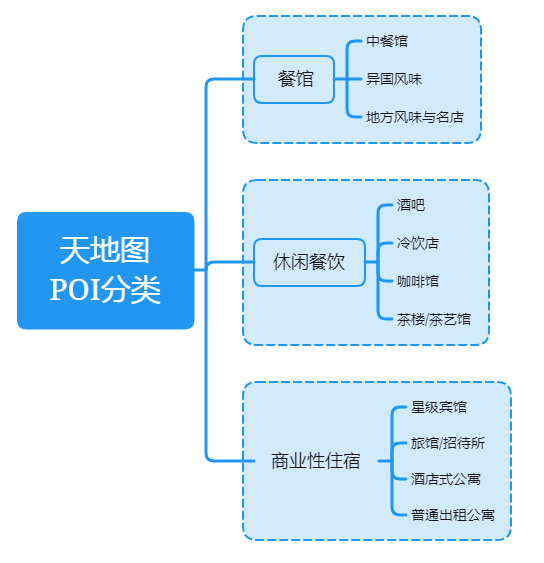
这个结构是天地图POI分类管理的基础,也是后面的数据程序解析的基础。我们将使用编码来进行数据的解析及入库。 在CSV中,很大的大类和种类都是重复的,因此需要在入库时将类别进行去重分类,最终构建一棵完整的POI分类树。
二、从CSV导入到PG数据库
本节将详细介绍在Java中使用标准库实现从CSV中解析到存储至PostgreGIS中,主要包含两个方面,第一个是如何使用Java标准库来进行CSV解析。第二个方面是如何基于Mybatis实现程序的批量入库。关于数据处理流程与高德和百度POI入库的流程一致,基本分为三个步骤:第一步是批量读取数据源,第二步是将数据源解析出POI分类数据,最后将分类好的数据导入到PG数据库中。
1、CSV解析流程
首先还是对天地图下载的CSV格式的POI分类进行解析,在进行POI的分类进行构建时尤其重要,为了防止各层级在构建时出现重复的情况,这里采用LinkedHashMap集合来进行重复判断,在存储集合对象时,将分类编码作为map的key,而具体分类对象作为value。在天地图的POI分类编码中,可以发现将编码的前四位和后两位可以拆开,后两位如果是00的一般都是父类节点,通过我们的观察可以看到在后续的对象去重判断时,key就是重复的标记。为了实现从CSV格式的文件中读取数据,这里首先介绍一下CSV的解析流程。在正式讲解数据导入时,需要明确一个信息,就是在CSV数据的每一行中,只要遇到-这个字符就基本表示再往后读一个单元格,当前行的数据读取任务结束。
第一步:一些不要的辅助信息,比如需要定义需要处理的文件本地路径地址。代码如下:
@Autowired
private IPoiCategoryService poiCateGoryService;
private static final String TDT_POI_CSV_FILE = "C:/Users/Administrator/Desktop/天地图及相关信息/天地图Type-数据分类(分类编码表).csv";
private static final String TRIGGER_CHAR = "-";第二步:CSV解析实现
为了能够正确的解析CSV数据,这里需要额外定外定义两个参数,以此保证数据的准确解析。关于CSV的解析实现代码如下:
// 自定义CSV行解析(处理带逗号的字段)
private static String[] parseCsvLine(String line) {java.util.List<String> fields = new java.util.ArrayList<>();StringBuilder field = new StringBuilder();boolean inQuotes = false;for (char c : line.toCharArray()) {if (c == '"') {inQuotes = !inQuotes; // 切换引号状态} else if (c == ',' && !inQuotes) {fields.add(field.toString());field.setLength(0); // 重置} else {field.append(c);}}fields.add(field.toString()); // 添加最后一个字段return fields.toArray(new String[0]);
}// 清理单元格值
private static String cleanCellValue(String value) {// 去除首尾空格和引号value = value.trim();if (value.startsWith("\"") && value.endsWith("\"")) {value = value.substring(1, value.length() - 1);}// 处理转义的双引号return value.replace("\"\"", "\"");
}第三步:CSV数据解析,实现最基本的数据解析读取和基础配置之后,下面就可以来实现对CSV数据的具体读取,这里采取的是直接的Java标准库解析的方法。实例代码如下:
private static LinkedHashMap<String,PoiCategory> csv2Map(){// UTF-8, GBK, GB2312, ISO-8859-1, Windows-1252Charset charset = Charset.forName("GBK"); // 根据实际文件编码设置LinkedHashMap<String,PoiCategory> amapPoiTypeMap = new LinkedHashMap<String, PoiCategory>(); try (BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(TDT_POI_CSV_FILE), charset))) {String line = "";int rowNum = 0;while ((line = br.readLine()) != null) {rowNum++;String[] cells = parseCsvLine(line); // 使用自定义解析方法处理带逗号的字段boolean foundTrigger = false;List<String> poiCategories = new ArrayList<String>();String poiCategoryCode = "";//获取每一行的的每个格子的数据for (int i = 0; i < cells.length; i++) {String cellValue = cleanCellValue(cells[i]);//System.out.println(cellValue);if (cellValue.contains(TRIGGER_CHAR)) {foundTrigger = true;//System.out.println("[行 " + rowNum + "] 触发单元格: " + cellValue);if (i + 1 < cells.length) {String nextValue = cleanCellValue(cells[i + 1]);poiCategoryCode = nextValue;//System.out.println("→ 终止单元格: " + nextValue);} else {System.out.println("→ 终止单元格: (空)");}break;}else {poiCategories.add(cellValue);}}if (!foundTrigger) {System.out.println("行 " + rowNum + ": 未找到触发字符");}//执行分类预处理if(foundTrigger) {String prefix_head = poiCategoryCode.substring(0,4);String prefix_tail = poiCategoryCode.substring(4);if(prefix_tail.equalsIgnoreCase("00")) {//00表示大类String levelFirst = poiCategoryCode;//处理一级,添加到集合中if(!amapPoiTypeMap.containsKey(levelFirst)) {PoiCategory category = new PoiCategory(IdWorker.getId(),1944421516292726785L,"0,100,1944421516292726785",String.join("/", poiCategories),StringUtils.EMPTY,levelFirst);amapPoiTypeMap.put(levelFirst, category);}}else {//剩下表示小类if(!amapPoiTypeMap.containsKey(poiCategoryCode)) {String _parentKey = prefix_head + "00";PoiCategory parentCategory = amapPoiTypeMap.get(_parentKey);String ancestors = parentCategory.getAncestors() + "," + parentCategory.getPkId();PoiCategory category = new PoiCategory(IdWorker.getId(),parentCategory.getPkId(),ancestors,String.join("/", poiCategories),StringUtils.EMPTY,poiCategoryCode);amapPoiTypeMap.put(poiCategoryCode, category);}}}}} catch (IOException e) {e.printStackTrace();}return amapPoiTypeMap;
}2、数据转换及入库
将CSV数据成功的解析转换成LinkedHashMap之后,事情还远远没结束,接下来需要将获取的LinkedHashMap转换成ArrayList。为了在查询数据的时候方便,在正式入库之前还需要增加一家额外的辅助信息,信息如下:
/**
* - 将map集合转换成list集合
* @param amapPoiTypeMap
* @return
*/
private static List<PoiCategory> convertMap2DataList(LinkedHashMap<String,PoiCategory> amapPoiTypeMap) {List<PoiCategory> categoryData = new ArrayList<PoiCategory>();Date now = DateUtils.getNowDate();for (PoiCategory value : amapPoiTypeMap.values()) {value.setPlatform("tianditu");value.setDelFlag(0);value.setStatus(0);value.setOrderNum(1);value.setCreateTime(now);categoryData.add(value);}return categoryData;
}到这里,我们就已经实现了如何使用Java标准库来解析CSV文件,并且将数据都读到了LinkedHashMap对象中,接下来就调用上述的方法来组装成一个完整的数据导入实例,核心代码如下:
@Test
public void writer2DB() {//step1、读取CSV到Map集合中LinkedHashMap<String,PoiCategory> map = csv2Map();//step2、将map转成list集合List<PoiCategory> categoryData = convertMap2DataList(map);//step3、插入到数据库中for (PoiCategory poiCategory : categoryData) {System.out.println(poiCategory);}//step4、数据入库 poiCateGoryService.batchInsertPoiCategory(categoryData);System.out.println("finished...");
}3、入库成果及检索
完成以上的程序编写,并运行操作后就完成了天地图POI分类数据的PostGIS数据库导入操作,程序执行完成后,可以在控制台看到以下输出:
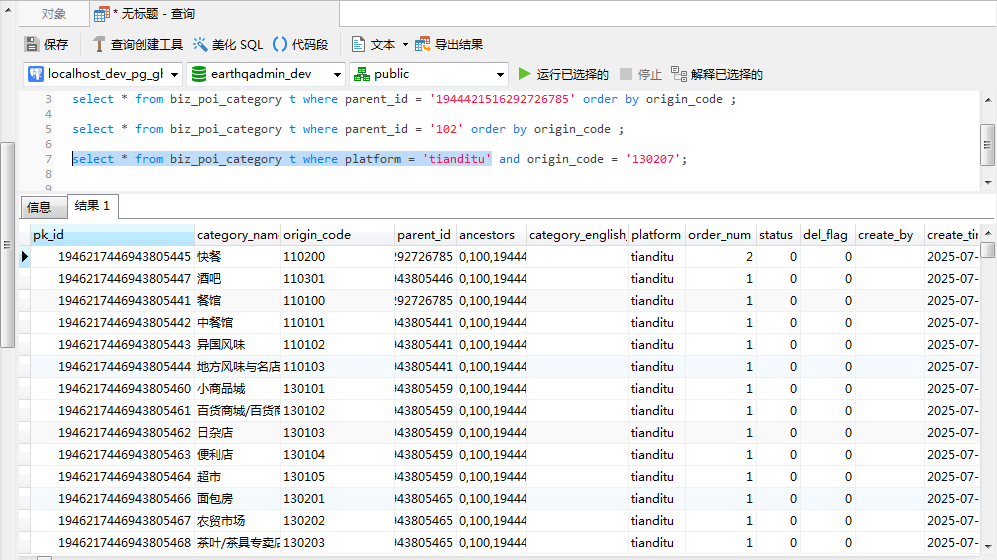
为了验证是否在数据库中是否也保存了这些数据,可以使用以下SQL语句进行查询:
select * from biz_poi_category t where platform = 'tianditu';在客户端软件中执行以上SQL后可以看到以下结果:
三、总结
以上就是本文的主要内容,支持对天地图的POI分类的CSV入库及检索就基本完成,后续我们将深入使用POI信息以及如何进行相应数据的采集。那么本文即来重点讲讲天地图POI分类与高德和百度POI分类存在什么不一样的地方,需要注意的是,本文读取的文件不是Excel而是CSV格式,因此也深入讲解了如何使用Java标准库来解析天地图的POI分类文件,同时深入讲解天地图 POI 分类如何进行数据导入,如何将CSV数据转为LinkedHashMap,再到ArrayList,最后批量入库。也为各类基于 POI 分类数据的地理信息系统开发、商业智能分析以及城市规划应用等,铺设一条从数据获取到存储利用的高效路径,助力行业在空间数据赋能下实现精准决策与创新发展。行文仓促,难免有许多不足之处,如有不足,在此恳请各位专家博主在评论区不吝留言指出,不胜感激。



与共识客户端(CL))

处理鸢尾花(iris)数据集)


)



)





)
)