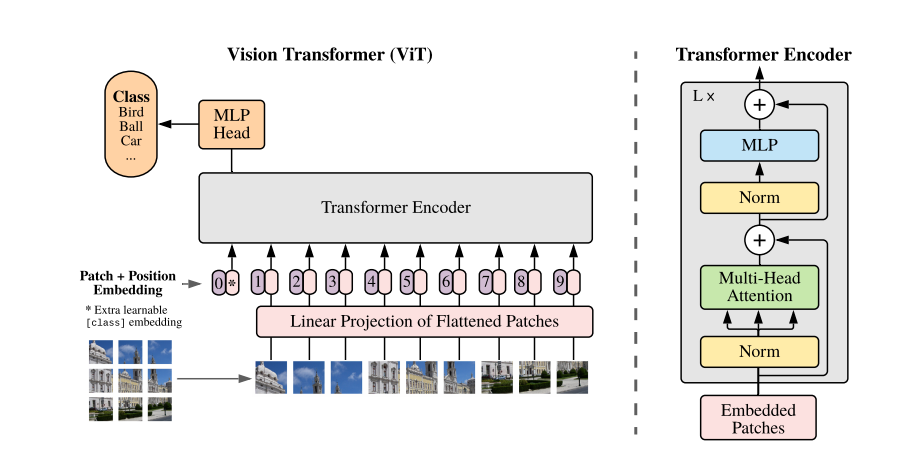
当我们取到一张图片,我们会把它划分为一个个patch,如上图把一张图片划分为了9个patch,然后通过一个embedding把他们转换成一个个token,每个patch对应一个token,然后在输入到transformer encoder之前还要经过一个class token,带有分类信息,然后加上位置信息如图123456789。
Transformer Encoder由右图所示的部分组成,一共L个,然后再输出到MLP Head,然后做一个分类。
当我们取到一张图片,我们会把它划分为一个个patch,如上图把一张图片划分为了9个patch,然后通过一个embedding把他们转换成一个个token,每个patch对应一个token,然后在输入到transformer encoder之前还要经过一个class token,带有分类信息,然后加上位置信息如图123456789。
Transformer Encoder由右图所示的部分组成,一共L个,然后再输出到MLP Head,然后做一个分类。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若转载,请注明出处:http://www.pswp.cn/diannao/91831.shtml 繁体地址,请注明出处:http://hk.pswp.cn/diannao/91831.shtml 英文地址,请注明出处:http://en.pswp.cn/diannao/91831.shtml
如若内容造成侵权/违法违规/事实不符,请联系英文站点网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!



)
)









)



