【服务器与部署 14】消息队列部署:RabbitMQ、Kafka生产环境搭建指南
关键词:消息队列、RabbitMQ集群、Kafka集群、消息中间件、异步通信、微服务架构、高可用部署、消息持久化、生产环境配置、分布式系统
摘要:本文从实际业务场景出发,深入解析RabbitMQ和Kafka消息队列的生产环境部署方案。通过生动的比喻和实战案例,帮助读者理解消息队列的核心原理,掌握高可用消息队列架构的设计与部署,解决分布式系统中的异步通信难题。
为什么需要消息队列?
想象一下,你经营着一家繁忙的餐厅。顾客点餐、厨师做菜、服务员上菜,如果每个环节都要等待前一个环节完成,整个餐厅的效率会非常低。聪明的做法是什么?
引入"传菜单"系统:顾客点餐后,服务员把订单放到厨房的订单架上,厨师按顺序处理,做好的菜放到出菜口,服务员再取走上菜。这样,每个环节都能并行工作,大大提高了效率。
这就是消息队列的基本思想——通过异步消息传递,解耦系统各个组件,提高整体性能和可靠性。
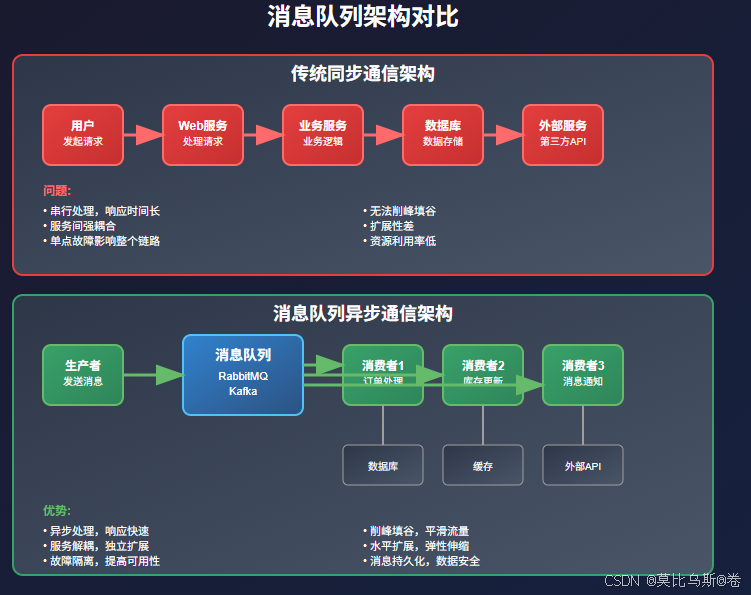
消息队列的核心概念
生产者与消费者模式
消息队列就像是一个智能的邮局系统:
- 生产者(Producer):寄信人,负责发送消息
- 消息队列(Queue):邮箱,暂存消息
- 消费者(Consumer):收信人,接收和处理消息
- 代理(Broker):邮局,管理消息的存储和转发
消息队列的优势
- 解耦:系统组件之间不需要直接通信
- 异步:发送方不需要等待接收方处理完成
- 削峰填谷:应对流量突发,保护下游系统
- 可靠性:消息持久化,保证不丢失
- 扩展性:可以灵活增加生产者和消费者
RabbitMQ:可靠的消息传递专家
RabbitMQ的特点
RabbitMQ就像一个经验丰富的邮局局长,擅长处理各种复杂的消息路由需求。它基于AMQP协议,提供了丰富的消息路由功能。
RabbitMQ单机部署
1. 安装RabbitMQ
# Ubuntu/Debian
sudo apt-get update
sudo apt-get install rabbitmq-server# CentOS/RHEL
sudo yum install epel-release
sudo yum install rabbitmq-server# 启动服务
sudo systemctl start rabbitmq-server
sudo systemctl enable rabbitmq-server
2. 基础配置
# 启用管理插件
sudo rabbitmq-plugins enable rabbitmq_management# 创建管理员用户
sudo rabbitmqctl add_user admin admin123
sudo rabbitmqctl set_user_tags admin administrator
sudo rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"# 删除默认用户
sudo rabbitmqctl delete_user guest
3. 配置文件优化
# 创建配置文件 /etc/rabbitmq/rabbitmq.conf
cat > /etc/rabbitmq/rabbitmq.conf << EOF
# 网络配置
listeners.tcp.default = 5672
management.tcp.port = 15672# 内存配置
vm_memory_high_watermark.relative = 0.6
vm_memory_high_watermark_paging_ratio = 0.5# 磁盘配置
disk_free_limit.relative = 2.0# 日志配置
log.console = true
log.console.level = info
log.file = /var/log/rabbitmq/rabbitmq.log
log.file.level = info# 集群配置
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config
EOF
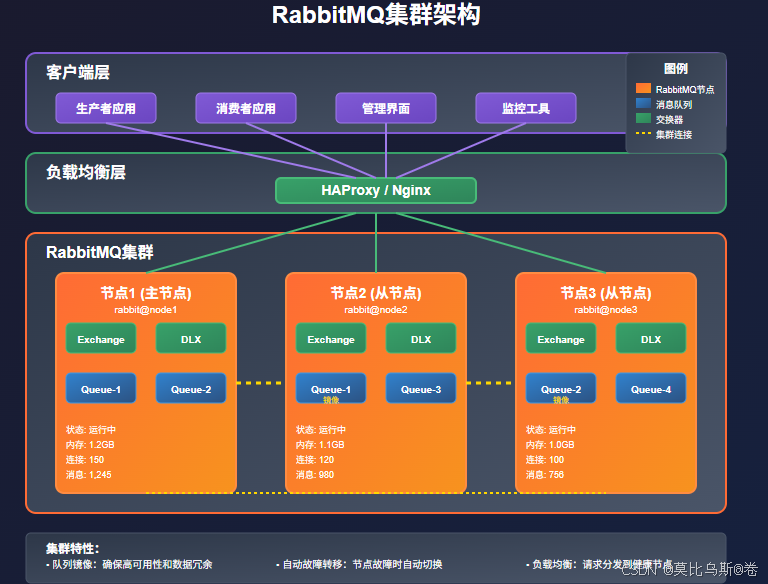
RabbitMQ集群部署
1. 集群规划
# 节点规划
# rabbit-node1: 192.168.1.10 (主节点)
# rabbit-node2: 192.168.1.11 (从节点)
# rabbit-node3: 192.168.1.12 (从节点)# 配置hosts文件
echo "192.168.1.10 rabbit-node1" >> /etc/hosts
echo "192.168.1.11 rabbit-node2" >> /etc/hosts
echo "192.168.1.12 rabbit-node3" >> /etc/hosts
2. 集群配置
# 在所有节点上设置相同的Erlang Cookie
sudo systemctl stop rabbitmq-server
echo "RABBITMQ_CLUSTER_COOKIE" | sudo tee /var/lib/rabbitmq/.erlang.cookie
sudo chmod 600 /var/lib/rabbitmq/.erlang.cookie
sudo chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie# 启动所有节点
sudo systemctl start rabbitmq-server# 在node2和node3上加入集群
sudo rabbitmqctl stop_app
sudo rabbitmqctl join_cluster rabbit@rabbit-node1
sudo rabbitmqctl start_app# 验证集群状态
sudo rabbitmqctl cluster_status
3. 高可用队列配置
# 设置队列镜像策略
sudo rabbitmqctl set_policy ha-all "^ha\." '{"ha-mode":"all","ha-sync-mode":"automatic"}'# 设置高可用交换器
sudo rabbitmqctl set_policy ha-federation "^federation\." '{"federation-upstream-set":"all"}'
RabbitMQ监控与管理
Python监控脚本
import pika
import json
import requests
import time
from datetime import datetimeclass RabbitMQMonitor:def __init__(self, host='localhost', port=15672, username='admin', password='admin123'):self.host = hostself.port = portself.username = usernameself.password = passwordself.base_url = f"http://{host}:{port}/api"def get_cluster_status(self):"""获取集群状态"""try:response = requests.get(f"{self.base_url}/nodes",auth=(self.username, self.password))if response.status_code == 200:nodes = response.json()cluster_info = {'total_nodes': len(nodes),'running_nodes': len([n for n in nodes if n['running']]),'nodes': []}for node in nodes:cluster_info['nodes'].append({'name': node['name'],'running': node['running'],'memory_used': node.get('mem_used', 0),'disk_free': node.get('disk_free', 0),'uptime': node.get('uptime', 0)})return cluster_infoelse:return Noneexcept Exception as e:print(f"获取集群状态失败: {e}")return Nonedef get_queue_metrics(self):"""获取队列指标"""try:response = requests.get(f"{self.base_url}/queues",auth=(self.username, self.password))if response.status_code == 200:queues = response.json()metrics = {'total_queues': len(queues),'total_messages': sum(q.get('messages', 0) for q in queues),'total_consumers': sum(q.get('consumers', 0) for q in queues),'queues': []}for queue in queues:metrics['queues'].append({'name': queue['name'],'messages': queue.get('messages', 0),'consumers': queue.get('consumers', 0),'memory': queue.get('memory', 0),'message_stats': queue.get('message_stats', {})})return metricselse:return Noneexcept Exception as e:print(f"获取队列指标失败: {e}")return Nonedef health_check(self):"""健康检查"""try:# 检查API连接response = requests.get(f"{self.base_url}/overview",auth=(self.username, self.password),timeout=5)if response.status_code == 200:overview = response.json()return {'status': 'healthy','version': overview.get('rabbitmq_version', 'unknown'),'erlang_version': overview.get('erlang_version', 'unknown'),'total_messages': overview.get('queue_totals', {}).get('messages', 0)}else:return {'status': 'unhealthy', 'reason': 'API不可访问'}except Exception as e:return {'status': 'unhealthy', 'reason': str(e)}def generate_report(self):"""生成监控报告"""print("RabbitMQ集群监控报告")print("=" * 50)print(f"时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")# 健康检查health = self.health_check()print(f"集群状态: {health['status']}")if health['status'] == 'healthy':print(f"RabbitMQ版本: {health['version']}")print(f"Erlang版本: {health['erlang_version']}")# 集群信息cluster = self.get_cluster_status()if cluster:print(f"节点数量: {cluster['running_nodes']}/{cluster['total_nodes']}")# 队列信息queues = self.get_queue_metrics()if queues:print(f"队列数量: {queues['total_queues']}")print(f"消息总数: {queues['total_messages']}")print(f"消费者总数: {queues['total_consumers']}")else:print(f"错误原因: {health['reason']}")# 使用示例
monitor = RabbitMQMonitor()
monitor.generate_report()
Kafka:高吞吐量的流处理平台
Kafka的特点
Kafka就像一个高速公路系统,专门设计用来处理大量的数据流。它不仅是消息队列,更是一个分布式流处理平台。
Kafka单机部署
1. 安装Java环境
# 安装OpenJDK 11
sudo apt-get update
sudo apt-get install openjdk-11-jdk# 设置JAVA_HOME
echo 'export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64' >> ~/.bashrc
source ~/.bashrc
2. 安装Kafka
# 下载Kafka
wget https://downloads.apache.org/kafka/2.8.0/kafka_2.13-2.8.0.tgz
tar -xzf kafka_2.13-2.8.0.tgz
sudo mv kafka_2.13-2.8.0 /opt/kafka# 创建用户和目录
sudo useradd -r -s /bin/false kafka
sudo mkdir -p /var/log/kafka
sudo chown -R kafka:kafka /opt/kafka /var/log/kafka
3. 配置Zookeeper
# 配置Zookeeper
cat > /opt/kafka/config/zookeeper.properties << EOF
dataDir=/var/lib/zookeeper
clientPort=2181
maxClientCnxns=0
admin.enableServer=false
server.1=localhost:2888:3888
EOF# 启动Zookeeper
sudo -u kafka /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties
4. 配置Kafka
# 配置Kafka服务器
cat > /opt/kafka/config/server.properties << EOF
# 服务器ID
broker.id=0# 监听地址
listeners=PLAINTEXT://localhost:9092
advertised.listeners=PLAINTEXT://localhost:9092# 日志目录
log.dirs=/var/log/kafka# 分区数量
num.partitions=3
default.replication.factor=1# 日志保留时间
log.retention.hours=168
log.retention.bytes=1073741824# Zookeeper连接
zookeeper.connect=localhost:2181# 其他配置
group.initial.rebalance.delay.ms=0
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
EOF# 启动Kafka
sudo -u kafka /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
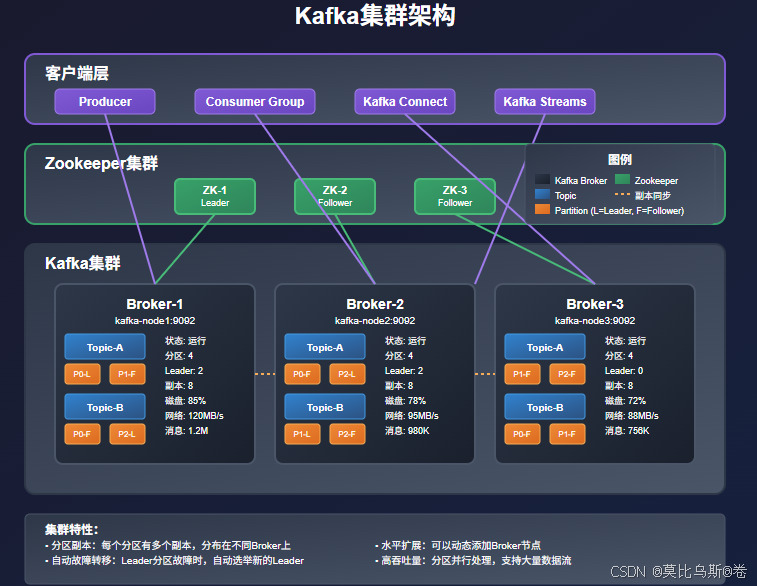
Kafka集群部署
1. 集群规划
# 节点规划
# kafka-node1: 192.168.1.20 (broker.id=1)
# kafka-node2: 192.168.1.21 (broker.id=2)
# kafka-node3: 192.168.1.22 (broker.id=3)# Zookeeper集群
# zk-node1: 192.168.1.20:2181
# zk-node2: 192.168.1.21:2181
# zk-node3: 192.168.1.22:2181
2. Zookeeper集群配置
# 在每个节点上配置Zookeeper
cat > /opt/kafka/config/zookeeper.properties << EOF
dataDir=/var/lib/zookeeper
clientPort=2181
maxClientCnxns=0
admin.enableServer=false# 集群配置
server.1=192.168.1.20:2888:3888
server.2=192.168.1.21:2888:3888
server.3=192.168.1.22:2888:3888# 选举配置
initLimit=10
syncLimit=5
EOF# 创建myid文件
sudo mkdir -p /var/lib/zookeeper
echo "1" | sudo tee /var/lib/zookeeper/myid # 节点1
echo "2" | sudo tee /var/lib/zookeeper/myid # 节点2
echo "3" | sudo tee /var/lib/zookeeper/myid # 节点3
3. Kafka集群配置
# 节点1配置
cat > /opt/kafka/config/server.properties << EOF
broker.id=1
listeners=PLAINTEXT://0.0.0.0:9092
advertised.listeners=PLAINTEXT://192.168.1.20:9092
log.dirs=/var/log/kafka
num.partitions=3
default.replication.factor=3
min.insync.replicas=2
zookeeper.connect=192.168.1.20:2181,192.168.1.21:2181,192.168.1.22:2181
EOF# 节点2配置 (broker.id=2, IP改为192.168.1.21)
# 节点3配置 (broker.id=3, IP改为192.168.1.22)
4. 启动集群
# 启动顺序:先启动Zookeeper,再启动Kafka
# 在所有节点上启动Zookeeper
sudo -u kafka /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties# 等待Zookeeper集群稳定后启动Kafka
sudo -u kafka /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
Kafka监控与管理
Python监控脚本
from kafka import KafkaProducer, KafkaConsumer, KafkaAdminClient
from kafka.admin import ConfigResource, ConfigResourceType
import json
import time
from datetime import datetimeclass KafkaMonitor:def __init__(self, bootstrap_servers=['localhost:9092']):self.bootstrap_servers = bootstrap_serversself.admin_client = KafkaAdminClient(bootstrap_servers=bootstrap_servers,client_id='kafka_monitor')def get_cluster_metadata(self):"""获取集群元数据"""try:metadata = self.admin_client._client.clustercluster_info = {'cluster_id': metadata.cluster_id,'controller': metadata.controller,'brokers': [],'topics': list(metadata.topics())}for broker in metadata.brokers():cluster_info['brokers'].append({'id': broker.nodeId,'host': broker.host,'port': broker.port,'rack': broker.rack})return cluster_infoexcept Exception as e:print(f"获取集群元数据失败: {e}")return Nonedef get_topic_info(self, topic_name):"""获取主题信息"""try:metadata = self.admin_client._client.clustertopic_metadata = metadata.topics_to_brokers().get(topic_name)if topic_metadata:partitions = []for partition in topic_metadata.partitions.values():partitions.append({'partition': partition.partition,'leader': partition.leader,'replicas': partition.replicas,'isr': partition.isr})return {'topic': topic_name,'partitions': partitions,'partition_count': len(partitions)}else:return Noneexcept Exception as e:print(f"获取主题信息失败: {e}")return Nonedef create_topic(self, topic_name, num_partitions=3, replication_factor=3):"""创建主题"""try:from kafka.admin import NewTopictopic = NewTopic(name=topic_name,num_partitions=num_partitions,replication_factor=replication_factor)result = self.admin_client.create_topics([topic])# 等待创建完成for topic, future in result.items():try:future.result()print(f"主题 {topic} 创建成功")except Exception as e:print(f"主题 {topic} 创建失败: {e}")except Exception as e:print(f"创建主题失败: {e}")def performance_test(self, topic_name, num_messages=1000):"""性能测试"""try:# 生产者性能测试producer = KafkaProducer(bootstrap_servers=self.bootstrap_servers,value_serializer=lambda v: json.dumps(v).encode('utf-8'))start_time = time.time()for i in range(num_messages):message = {'id': i,'timestamp': datetime.now().isoformat(),'data': f'test_message_{i}'}producer.send(topic_name, message)producer.flush()producer.close()produce_time = time.time() - start_time# 消费者性能测试consumer = KafkaConsumer(topic_name,bootstrap_servers=self.bootstrap_servers,auto_offset_reset='earliest',value_deserializer=lambda m: json.loads(m.decode('utf-8')))start_time = time.time()message_count = 0for message in consumer:message_count += 1if message_count >= num_messages:breakconsume_time = time.time() - start_timeconsumer.close()return {'messages_sent': num_messages,'produce_time': produce_time,'consume_time': consume_time,'produce_rate': num_messages / produce_time,'consume_rate': num_messages / consume_time}except Exception as e:print(f"性能测试失败: {e}")return Nonedef health_check(self):"""健康检查"""try:# 检查集群连接metadata = self.get_cluster_metadata()if metadata:active_brokers = len(metadata['brokers'])total_topics = len(metadata['topics'])return {'status': 'healthy','active_brokers': active_brokers,'total_topics': total_topics,'cluster_id': metadata['cluster_id']}else:return {'status': 'unhealthy', 'reason': '无法获取集群元数据'}except Exception as e:return {'status': 'unhealthy', 'reason': str(e)}def generate_report(self):"""生成监控报告"""print("Kafka集群监控报告")print("=" * 50)print(f"时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")# 健康检查health = self.health_check()print(f"集群状态: {health['status']}")if health['status'] == 'healthy':print(f"活跃Broker数: {health['active_brokers']}")print(f"主题总数: {health['total_topics']}")print(f"集群ID: {health['cluster_id']}")# 集群详细信息metadata = self.get_cluster_metadata()if metadata:print("\nBroker信息:")for broker in metadata['brokers']:print(f" Broker {broker['id']}: {broker['host']}:{broker['port']}")else:print(f"错误原因: {health['reason']}")# 使用示例
monitor = KafkaMonitor(['localhost:9092'])
monitor.generate_report()# 创建测试主题
monitor.create_topic('test-topic', num_partitions=6, replication_factor=3)# 性能测试
perf_result = monitor.performance_test('test-topic', 10000)
if perf_result:print(f"\n性能测试结果:")print(f"生产速率: {perf_result['produce_rate']:.2f} msg/s")print(f"消费速率: {perf_result['consume_rate']:.2f} msg/s")
消息队列对比与选择
RabbitMQ vs Kafka
| 特性 | RabbitMQ | Kafka |
|---|---|---|
| 消息模型 | 传统消息队列 | 分布式日志 |
| 吞吐量 | 中等 | 非常高 |
| 延迟 | 低 | 低到中等 |
| 持久化 | 可选 | 默认持久化 |
| 消息顺序 | 队列级别 | 分区级别 |
| 消息路由 | 丰富的路由功能 | 基于主题分区 |
| 消费模式 | 推送和拉取 | 拉取 |
| 运维复杂度 | 相对简单 | 较复杂 |
选择建议
选择RabbitMQ的场景:
- 需要复杂的消息路由
- 消息量不是特别大
- 需要消息确认和事务
- 团队对AMQP协议熟悉
选择Kafka的场景:
- 需要处理大量数据流
- 需要消息持久化存储
- 构建实时数据管道
- 需要流处理能力
生产环境最佳实践
性能优化
RabbitMQ优化
# 系统级别优化
# 增加文件描述符限制
echo "rabbitmq soft nofile 65536" >> /etc/security/limits.conf
echo "rabbitmq hard nofile 65536" >> /etc/security/limits.conf# 内核参数优化
echo "net.core.rmem_default = 262144" >> /etc/sysctl.conf
echo "net.core.rmem_max = 16777216" >> /etc/sysctl.conf
echo "net.core.wmem_default = 262144" >> /etc/sysctl.conf
echo "net.core.wmem_max = 16777216" >> /etc/sysctl.conf
sysctl -p
Kafka优化
# JVM参数优化
export KAFKA_HEAP_OPTS="-Xmx4G -Xms4G"
export KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35"# 操作系统优化
echo "vm.swappiness=1" >> /etc/sysctl.conf
echo "vm.dirty_background_ratio=5" >> /etc/sysctl.conf
echo "vm.dirty_ratio=60" >> /etc/sysctl.conf
echo "vm.dirty_expire_centisecs=12000" >> /etc/sysctl.conf
sysctl -p
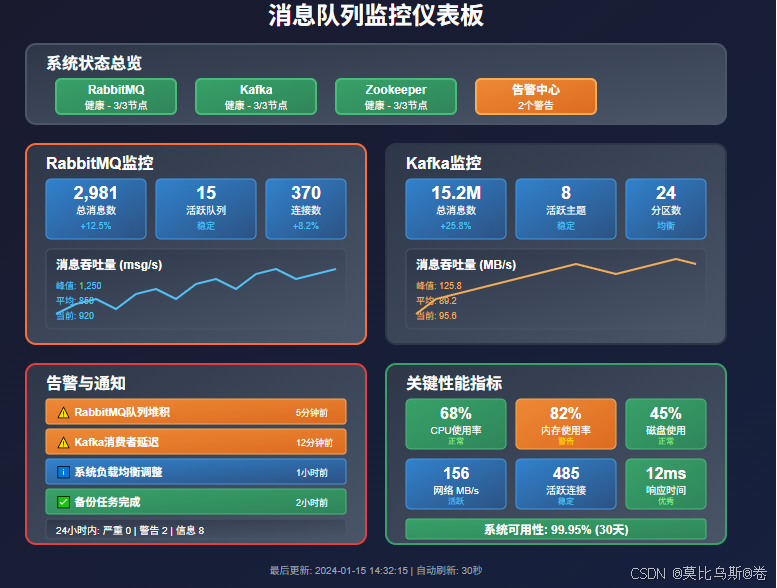
监控告警
监控指标
class MessageQueueAlerts:def __init__(self):self.thresholds = {'rabbitmq': {'queue_length': 10000,'memory_usage': 0.8,'disk_free': 0.2,'connection_count': 1000},'kafka': {'consumer_lag': 100000,'disk_usage': 0.8,'under_replicated_partitions': 0,'offline_partitions': 0}}def check_rabbitmq_alerts(self, metrics):"""检查RabbitMQ告警"""alerts = []for queue in metrics.get('queues', []):if queue['messages'] > self.thresholds['rabbitmq']['queue_length']:alerts.append({'type': 'queue_length','severity': 'warning','message': f"队列 {queue['name']} 消息堆积: {queue['messages']}"})return alertsdef check_kafka_alerts(self, metrics):"""检查Kafka告警"""alerts = []# 检查消费者延迟if metrics.get('consumer_lag', 0) > self.thresholds['kafka']['consumer_lag']:alerts.append({'type': 'consumer_lag','severity': 'critical','message': f"消费者延迟过高: {metrics['consumer_lag']}"})return alerts
安全配置
RabbitMQ安全
# SSL/TLS配置
cat > /etc/rabbitmq/rabbitmq.conf << EOF
listeners.ssl.default = 5671
ssl_options.cacertfile = /etc/ssl/certs/ca-cert.pem
ssl_options.certfile = /etc/ssl/certs/server-cert.pem
ssl_options.keyfile = /etc/ssl/private/server-key.pem
ssl_options.verify = verify_peer
ssl_options.fail_if_no_peer_cert = false
EOF# 用户权限管理
rabbitmqctl add_user producer producer_pass
rabbitmqctl add_user consumer consumer_pass
rabbitmqctl set_permissions -p / producer ".*" ".*" ""
rabbitmqctl set_permissions -p / consumer "" ".*" ".*"
Kafka安全
# SASL配置
cat > /opt/kafka/config/kafka_server_jaas.conf << EOF
KafkaServer {org.apache.kafka.common.security.plain.PlainLoginModule requiredusername="admin"password="admin-secret"user_admin="admin-secret"user_producer="producer-secret"user_consumer="consumer-secret";
};
EOF# 服务器配置
cat >> /opt/kafka/config/server.properties << EOF
listeners=SASL_PLAINTEXT://localhost:9092
security.inter.broker.protocol=SASL_PLAINTEXT
sasl.mechanism.inter.broker.protocol=PLAIN
sasl.enabled.mechanisms=PLAIN
EOF
常见问题与解决方案
问题1:消息丢失
RabbitMQ解决方案:
# 生产者确认
def publish_with_confirm(channel, exchange, routing_key, message):channel.confirm_delivery()try:channel.basic_publish(exchange=exchange,routing_key=routing_key,body=message,properties=pika.BasicProperties(delivery_mode=2) # 持久化)return Trueexcept pika.exceptions.UnroutableError:return False
Kafka解决方案:
# 生产者配置
producer = KafkaProducer(bootstrap_servers=['localhost:9092'],acks='all', # 等待所有副本确认retries=3,batch_size=16384,linger_ms=1,buffer_memory=33554432
)
问题2:消息重复
解决方案:
# 幂等性处理
def process_message_idempotent(message_id, message_data):# 检查消息是否已处理if redis_client.exists(f"processed:{message_id}"):return "already_processed"try:# 处理消息result = process_business_logic(message_data)# 标记为已处理redis_client.setex(f"processed:{message_id}", 3600, "true")return resultexcept Exception as e:# 处理失败,不标记为已处理raise e
问题3:消息堆积
解决方案:
# 动态扩容消费者
class AutoScaleConsumer:def __init__(self, topic, min_consumers=1, max_consumers=10):self.topic = topicself.min_consumers = min_consumersself.max_consumers = max_consumersself.consumers = []def scale_consumers(self, queue_size):target_consumers = min(self.max_consumers,max(self.min_consumers, queue_size // 1000))current_consumers = len(self.consumers)if target_consumers > current_consumers:# 扩容for _ in range(target_consumers - current_consumers):self.start_consumer()elif target_consumers < current_consumers:# 缩容for _ in range(current_consumers - target_consumers):self.stop_consumer()def start_consumer(self):# 启动新的消费者实例passdef stop_consumer(self):# 停止消费者实例pass
总结
消息队列就像是现代分布式系统的"神经系统",负责各个组件之间的信息传递。通过本文的学习,我们掌握了:
- 消息队列的核心概念:理解生产者-消费者模式和异步通信的优势
- RabbitMQ部署与管理:从单机到集群的完整部署方案
- Kafka部署与管理:高吞吐量流处理平台的配置与优化
- 技术选型指导:根据业务需求选择合适的消息队列
- 生产环境最佳实践:性能优化、监控告警、安全配置
- 常见问题解决:消息丢失、重复、堆积等问题的处理方案
在实际应用中,消息队列的选择和部署需要考虑多个因素:业务规模、性能要求、团队技术栈、运维能力等。没有最好的技术,只有最适合的方案。
记住,好的消息队列架构不是一次性设计完成的,而是在实践中不断演进和优化的。从简单开始,逐步完善,在实战中积累经验,才能真正掌握消息队列的精髓。
参考资料
- RabbitMQ官方文档
- Apache Kafka官方文档
- 消息队列设计模式
- 分布式系统消息传递
- 高可用消息队列架构



)
)









)




