中国优秀开源软件及企业调研报告
引言
当前中国开源生态呈现蓬勃发展态势,技术创新领域尤为活跃,其中人工智能大模型成为开源动作的核心聚焦方向。2025年上半年,国内AI领域开源生态迎来密集爆发,头部科技企业相继推出重要开源举措:6月30日,华为正式开源部分盘古大模型体系,百度同步推出文心大模型4.5系列模型的开源方案;阿里巴巴通过发布多版本开源大模型及运营魔搭社区构建起完善的开源生态体系;腾讯混元亦已开源其混合推理MoE模型Hunyuan-A13B及3D生成模型等。这些动态集中体现了中国企业在AI大模型领域的开源进展,构成国内开源生态技术创新热点的重要组成部分。
主要开源企业及明星项目分析
华为
OpenHarmony(开源鸿蒙)
OpenHarmony作为全场景分布式操作系统,其核心技术优势在于“弹性部署”“软总线”及“一次开发、多端部署”的架构设计,能够打破不同设备间的硬件壁垒,实现异构终端的跨端互联、数据统一调度与服务协同。该系统以统一操作系统为底座,支持从嵌入式设备到智能终端的全场景适配,通过硬件互助与资源共享机制,构建安全可靠的端网云协同环境,有效解决传统行业中“信息孤岛”“设备协同难”等痛点,为行业数字化转型提供技术支撑[1][2][3]。
在推动行业数字化转型方面,OpenHarmony已在建筑、工业、电力、交通等多领域实现规模化落地。建筑领域,福州建总大厦作为全国首个基于OpenHarmony的智慧楼宇,通过“开鸿安全数字底座”与KaihongOS构建“智慧大脑”,实现空调灯光自动调节(预计节能率10%-15%,年减碳排放近百吨)、智慧安防(人脸识别入楼、轨迹追踪)及应急保障(数字孪生逃生路线推送)等功能,设备寿命延长10%~15%,成为国产化技术在建筑领域的典范[4][5][6]。同时,《建筑开源鸿蒙技术框架白皮书》提出统一开放架构,涵盖终端底座、端端互联、端云协同及管理平台,采用CoAP协议保障通信安全,定义标准化数据模型,推动建筑智能化全链路国产化,已规划工程、产品、子系统等多维度标准体系[2][7][8]。
工业领域,OpenHarmony的分布式特性与高安全性被广泛应用于工业控制场景。华龙讯达基于OpenHarmony开发的华龙工业操作系统(HualongOS),实现PLC、HMI、SCADA等设备互联互通,支持“一次开发、多端部署”,其具身智能生产线可通过人机界面快速定制生产,验证了对国外工业软件的替代能力[9][10]。天罡智能研发的iiRobotOS则是国内首个基于OpenHarmony的工业机器人操作系统,已在珞石、埃夫特等企业完成验证,提升机器人协作编程效率[11]。此外,电力行业的中国南方电网“电鸿”系统实现设备即插即用,超300家伙伴加入生态;交通领域的杭山东隧道落地智慧隧道解决方案,树立全域数字化示范样板[1][9]。
生态扩展方面,OpenHarmony 5.0 Release版本的发布标志着生态逐步成熟。软通动力旗下鸿湖万联累计贡献代码超100万行,投入超800人月参与社区建设,发布SwanlinkOS SDK推动架构模块化,并推出搭载该系统的AI PC及智能交互平板,2025年进一步优化AI PC体验,集成大模型应用与教育软件移植[1][12]。行业合作方面,与南方科技大学等共建教学中心,与微展世联合发布工业操作系统,在居民服务领域部署1.2万台社保自助终端,生态覆盖芯片、模组、终端、应用等全产业链[1]。
商业化潜力方面,OpenHarmony已从技术验证迈向规模商用。建筑领域,万安智能与华为云合作推出基于OpenHarmony V5.0的空间单元智控器,实现IoT设备全域协同[13];油气行业的智慧油站方案搭载LightBeeOS,支持消费者全程无接触操作;养老领域的“幸福开鸿”方案通过弹性部署满足多场景需求[9]。对比Android等系统,OpenHarmony以全场景分布式架构为核心差异,聚焦垂直行业数字化,强调设备互联与数据安全,而Android更侧重消费端移动应用生态,两者在应用场景与技术定位上形成互补。随着标准体系完善与示范应用推广,OpenHarmony有望在工业互联网、智慧城市等领域构建差异化竞争优势。
盘古大模型
2025年6月30日,华为正式开源部分盘古大模型体系,这是其首次开源大模型,具体包括70亿参数的盘古稠密模型、720亿参数的盘古Pro MoE混合专家模型,以及配套的昇腾模型推理技术体系[14][15]。此前,在6月20日举办的华为开发者大会2025上,华为云已发布全面升级的盘古大模型5.5版本,其技术版图覆盖自然语言处理、计算机视觉、多模态理解等五大基础模型领域[14]。
华为此举的核心战略意图在于践行昇腾生态战略,通过开源推动大模型技术的研究与创新发展,加速人工智能在千行百业的应用与价值创造[15]。在技术路线上,盘古大模型展现出显著特色,特别是720亿参数的盘古Pro MoE混合专家模型,采用动态激活专家网络的创新设计。该模型在参数量仅为720亿、激活160亿参数量的情况下,即可达到千亿级模型的性能表现,体现了其在高效计算与性能优化方面的优势[15]。
| 模型名称 | 参数量(亿) | 关键特性 | 适用场景 |
|---|---|---|---|
| 盘古稠密模型 | 70 | 部署门槛较低 | 智能客服、知识库等轻量化场景 |
| 盘古Pro MoE混合专家模型 | 720 | 动态激活专家网络设计,激活参数量160亿,性能达千亿级模型水平 | 高性能计算需求场景 |
| 数据来源:[15] |
为降低行业应用门槛,华为针对性地开源了70亿参数的稠密模型,该模型部署门槛较低,适用于智能客服、知识库等多样化场景,能够满足不同行业的轻量化应用需求[15]。同时,配套开源的昇腾模型推理技术体系,进一步强化了盘古大模型与昇腾算力平台的协同,有助于推动昇腾算力生态的建设与完善,为开发者和企业提供从模型到算力的全栈支持。
百度
文心大模型4.5系列
百度在文心大模型的发展中展现了从闭源向开源的战略转变。2025年6月30日,百度正式开源文心大模型4.5系列,涵盖10款不同参数规模的模型,包括47B、3B激活参数的混合专家(MoE)模型及0.3B参数的稠密型模型,实现了预训练权重与推理代码的完全开源[14][15]。该系列在技术上实现了多模态理解与轻量化部署的突破,针对MoE架构提出创新性的多模态异构模型结构,适用于从大语言模型向多模态模型的持续预训练范式,其关键技术包括多模态混合专家模型预训练、训练推理框架及针对模态的后训练等,在保持或提升文本任务性能的基础上显著增强了多模态理解能力[15]。
性能表现上,文心多模态后训练模型在视觉常识、多模态推理、视觉感知等主流多模态大模型评测中表现优于闭源的OpenAI o1;轻量模型文心4.5-21B-A3B-Base的文本模型效果与同量级的Qwen3相当[15]。此外,文心大模型4.5系列的独立自研技术比例、模型类型多样性及参数规模丰富度均处于行业领先水平[14]。
Apache HugeGraph
Apache HugeGraph 作为 Apache 基金会下首个融合图数据库、图计算与图 AI 能力的开源系统,在技术架构上展现出显著领先性。其核心优势在于实现了 OLTP(在线事务处理)与 OLAP(在线分析处理)的一体化支持,能够同时满足实时图数据查询与大规模图计算需求,这一特性使其在图计算与 AI 融合领域具备独特竞争力[16]。技术兼容性方面,HugeGraph 全面支持 Apache TinkerPop 3 框架,并兼容 Gremlin 和 Cypher 两种主流图查询语言,可无缝对接多种大数据组件,为企业级复杂场景下的多源数据整合与分析提供了灵活支撑[16]。
与国际同类产品(如 Neo4j)相比,HugeGraph 的差异化优势体现在“数据库+计算+AI”的深度融合能力。传统图数据库多聚焦于单一事务处理或分析场景,而 HugeGraph 通过一体化架构设计,可直接支撑 AI 模型对图数据的实时访问与计算下推,减少数据流转开销。例如,在 2025 年 GLCC 编程夏令营中,百度安全围绕 HugeGraph 发布的课题涵盖 AI 仓库智能化改造、存储引擎升级(如 RocksDB Plus 应用)及图计算下推实现等方向,进一步验证了其在 AI 融合与高性能存储领域的技术深耕[16]。
开源社区活跃度方面,HugeGraph 通过持续输出技术课题与激励机制(如单个课题最高奖励 12000 元)吸引开发者参与核心功能迭代,显示出项目在技术演进上的社区驱动力[16]。商业化潜力层面,其多语言支持、大数据生态兼容性及一体化处理能力,使其具备成为企业级图数据库解决方案的基础条件,尤其适用于需要实时图分析与 AI 建模结合的复杂业务场景(如金融风控、社交网络分析等)。
阿里巴巴
通义千问Qwen系列
在开源大模型竞赛中,阿里巴巴通义团队通过快速迭代与生态共建相结合的策略巩固市场地位。截至2025年6月,该团队已开源200多款大模型,通义千问Qwen系列的衍生模型数量突破13万,超越美国Llama模型,全球下载量超过3亿次,在HuggingFace社区2024年全球模型下载量中占比超30%,显示出其在生态构建上的显著成效[15]。性能方面,Qwen系列通过丰富的衍生模型数量形成差异化竞争力,其开源策略中“所有模型均免费使用”的条款进一步降低了开发者使用门槛,推动了模型的广泛应用与生态扩展[15]。
Dubbo
Dubbo作为阿里巴巴开源的微服务框架,其技术演进历程反映了从传统分布式服务治理到云原生架构的适配过程。该框架起源于2008年阿里巴巴内部的SOA解决方案,2011年正式开源(2.0.7版本),2017年重启开源维护,并于2020年启动Dubbo 3.0版本研发,标志着向云原生服务治理平台的转型[17]。在版本迭代方面,2.x系列为经典稳定版本,其中2.6.x侧重稳定性优化与兼容性改进,2.7.x引入元数据中心、配置中心支持(如Apollo、Nacos)及异步化改进;3.x系列则聚焦云原生能力建设,3.0版本(2021年发布)推出应用级服务发现、统一路由规则、Triple协议(兼容gRPC,支持HTTP/2和流式通信)及Kubernetes、Service Mesh等云原生支持,3.1版本(2022年)强化服务网格集成(如Istio)与可观测性,3.2版本(2023年)进一步优化云原生支持、增强流量治理(流量控制、熔断、降级)并扩展多语言支持(Go、Rust等)[18]。
在云原生时代,Dubbo与Spring Cloud的竞争力对比体现在多维度。远程调用方式上,Dubbo基于RPC协议,采用自定义数据格式与原生TCP通信,具有速度快、效率高的优势,但需进行序列化和反序列化;Spring Cloud则基于HTTP协议,消息封装虽较臃肿,但具备跨语言、跨平台特性[18]。核心组件方面,两者差异显著:
| 核心组件 | Dubbo | Spring Cloud |
|---|---|---|
| 服务注册中心 | zookeeper | Spring Cloud Netflix Eureka |
| 服务调用方式 | RPC | REST API |
| 服务网关 | 无 | Spring Cloud Netflix Zuul |
| 断路器 | 不完善 | Spring Cloud Netflix Hysrix |
| 分布式配置 | 无 | Spring Cloud Config |
| 分布式追踪系统 | 无 | Spring Cloud Sleuth |
| 消息总线 | 无 | Spring Cloud Bus |
| 数据流 | 无 | Spring Cloud Stream(基于Redis,Rabbit,Kafka实现的消息微服务) |
| 批量任务 | 无 | Spring Cloud Task |
生态与社区活跃度方面,Spring Cloud凭借更完善的组件生态(如服务网关、分布式配置中心)和更高的更新频率,社区活跃度相对更高,问题解决效率与资料丰富度占优;Dubbo生态虽涵盖注册中心(Nacos、Zookeeper等)、配置中心(Apollo、Nacos等)及监控工具(Prometheus、Grafana等),但整体生态完整性与社区更新频率略逊[18][19]。
Dubbo社区呈现活跃与挑战并存的特点。截至相关统计,其GitHub星标数达40290,拥有超过600位contributor、57位committer,近一年日均提交约60个commits,外部代码贡献量已超过阿里内部,全球微服务框架排名第五[17][20]。为保障代码质量,社区采用单测、集成测试(dubbo-samples)、性能测试(dubbo-benchmark)及code review机制,但单测存在耗时过长(如Ubuntu和Windows环境下JDK8/11测试常超时)、多注册中心混合场景覆盖不足等问题,其中与Zookeeper相关的测试用例耗时显著,例如:
| Testcase | Time elapsed(s) |
|---|---|
| org.apache.dubbo.rpc.protocol.dubbo.ArgumentCallbackTest | 76.013 |
| org.apache.dubbo.config.spring.ConfigTest | 61.33 |
| org.apache.dubbo.config.spring.schema.DubboNamespaceHandlerTest | 50.437 |
| org.apache.dubbo.config.spring.beans.factory.annotation.ReferenceAnnotationBeanPostProcessorTest | 44.678 |
| org.apache.dubbo.rpc.cluster.support.AbstractClusterInvokerTest | 29.954 |
| org.apache.dubbo.remoting.zookeeper.curator.CuratorZookeeperClientTest | 25.847 |
| org.apache.dubbo.config.spring.beans.factory.annotation.MethodConfigCallbackTest | 25.635 |
| org.apache.dubbo.registry.client.event.listener.ServiceInstancesChangedListenerTest | 24.866 |
| org.apache.dubbo.remoting.zookeeper.curator5.Curator5ZookeeperClientTest | 19.664 |
此外,社区还面临入门门槛高、官网资料不全、网上源码级分享少、框架部署复杂等挑战[20][21]。
在行业渗透率方面,Dubbo已广泛应用于电商、金融等关键领域。阿里巴巴内部各业务线(淘宝、考拉、饿了么、钉钉、达摩院等)已全量或分批上线Dubbo 3.0版本;外部企业中,金融领域的工商银行、平安健康,电商领域的网易考拉,以及VIVO、当当、瓜子二手车、去哪儿、芒果TV、TCL、海尔等均大量采用该框架,登记企业用户超200个,生态合作伙伴达30多个[17][20][22]。
PingCAP
TiDB
TiDB是由PingCAP开发的开源分布式关系型数据库,自2015年在GitHub创建以来,已发展至v8版本,持续保持在国产数据库市场前列,以HTAP(混合事务/分析处理)能力著称,适用于对实时分析和事务处理要求较高的业务场景[23][24]。作为国内活跃开源项目,其技术优势主要体现在兼容性、弹性扩展、架构先进性及多模态处理能力等方面[25]。
技术层面,TiDB兼容MySQL协议和SQL语法,可直接复用MySQL生态工具与应用,降低迁移成本[24][26]。弹性扩展能力突出,支持通过添加节点实现存储与处理能力的线性扩展,结合智能分片、负载均衡及故障自动迁移机制,可动态应对业务增长[24]。HTAP架构是其核心特性,通过TiFlash列式存储组件与向量化执行引擎,实现同一系统内OLTP与OLAP workload的一体化处理,满足实时数据分析需求[24][26]。此外,TiDB采用云原生架构,支持公有云、私有云及混合云部署,通过TiDB Operator实现自动化运维,并具备高可用性(多副本机制与节点故障自动切换)[24]。在AI时代,TiDB积极拓展向量搜索能力,自v6.0 TiFlash开源后,逐步支持向量存储(最高16383维)、HNSW索引算法(特定场景准确率达98%)及性能优化,最新LTS版本(v8.5.0)进一步提升向量距离计算效率与数据更新场景下的查询性能,新增CPU使用率监控指标,强化AI就绪能力[26][27]。
国产替代方面,TiDB在金融、医疗等核心系统领域成效显著。针对金融行业核心交易场景,v8.5 LTS版本通过优化I/O抖动(影响降至十分之一)、动态扩缩容机制及更新性能(提升500%),并支持多租户资源组划分,满足金融业务高并发、高可用需求[24]。在医疗领域,TiDB被集成至临床一体化信息系统,作为核心数据库平台承接基础业务与数据中台的数据流通,通过“多库合一、资源统一调度”实现业务资源弹性分配与隔离,支撑门诊、电子病历等系统高并发访问,解决传统数据库资源孤岛与扩展瓶颈问题,实现医疗核心系统国产化替代[28]。其“自主开源、架构先进、PB级扩展、全场景、异构迁移友好”的优势,成为国产化替代的重要选择[28]。
国际化布局上,TiDB全球影响力持续提升。DB-Engines排名从2019年的150–160区间跃升至全球数据库总榜前100名,在关系型数据库中排名第38位,仅次于Singlestore,超越Google Spanner[27]。2024年全球业务翻倍增长,服务超4000家企业,覆盖25个国家和地区,典型客户包括北美的Pinterest、日本的Rakuten、亚太的NinjaVan与Flipkart、EMEA地区的Bolt等[27]。其全球化战略以“本地化(Local for local)”为核心,通过开源模式触达用户,并构建本地化服务支撑体系,如2025年印度TiDB User Day India大会上,Flipkart等客户分享实践经验[27]。此外,TiDB连续三年入选Gartner Peer Insights“Voice of the Customer”云数据库报告,并在日本市场连续三年被选为工程师最想使用的数据库之一,彰显国际市场认可度[27]。
蚂蚁集团
隐语SecretFlow
隐语SecretFlow是由蚂蚁集团旗下蚂蚁密算于2022年7月开源的可信隐私计算框架,在隐私计算领域展现出显著的技术包容性与实用性。该框架支持多方安全计算(MPC)、联邦学习(FL)、可信执行环境(TEE)等当前主流隐私计算技术,能够满足不同场景下的数据安全协作需求,体现了其在技术整合与兼容性方面的领先性[16]。
在数据要素市场化进程中,隐语SecretFlow已在银行、医疗、保险、政务、互联网营销等多个关键行业实现应用,有效推动了数据在“可用不可见”前提下的流通与价值释放,为打破数据孤岛、促进跨主体数据协作提供了技术支撑,成为数据要素市场化配置的重要基础设施[16]。
蚂蚁集团通过开源隐语SecretFlow,积极构建了由高校、企业及开源社区共同参与的协作生态。例如,在GLCC 2025编程夏令营中,隐语项目设置了Kuscia基于带宽调度实现、SCQL多余RunSQL语句优化等技术课题,吸引开发者参与框架的迭代优化,这一举措不仅有助于提升项目的技术成熟度,更体现了其通过开源模式凝聚行业共识、推动隐私计算技术标准化的战略意图[16]。
Ant Design
Ant Design是蚂蚁集团开源的企业级UI设计语言与React组件库,自2015年发布以来持续迭代,截至2025年已更新至v5.25.2版本,GitHub星标数达89.5k,每月NPM下载量超4000万次,是GitHub中文排行榜中的热门UI框架,其生态影响力在国内外前端领域均表现突出[29][30]。
在设计体系标准化方面,Ant Design基于统一设计体系构建,支持全场景组件覆盖与灵活定制。核心特性包括80+基础组件(如按钮、输入框、导航等)、数据组件(表格、树状图、图表等)、高级组件(动态表单生成与验证、复杂日期选择器等)及实验性组件(Web3、低代码场景探索),并通过Less实现主题配置,支持自定义色彩、字体、间距等设计tokens,内置暗黑模式一键切换,全程提供TypeScript接口定义与智能提示,确保开发过程中的设计一致性与规范性[30]。
多端适配与跨框架支持是Ant Design的重要优势。针对移动端与跨框架需求,其衍生项目Ant Design Blazor持续优化,2025年发布的1.1.0版本新增Table组件条纹样式、树形结构延迟加载、列索引设置等功能,修复行分组响应异常,并支持SVG字符串自定义与Typography组件标题级别扩展;1.4.2版本进一步聚焦组件稳定性与性能,优化Tabs、Table、Form等核心组件在wasm渲染模式下的加载速度,修复固定头/列样式错位等问题,同时新增eu_ES巴斯克语支持,完善国际化能力[31][32][33]。此外,Ant Design Pro作为企业级Web应用开发框架,基于React技术栈集成umi、dva状态管理,支持响应式布局设计,覆盖金融、电商、内部OA系统等多场景,提供开箱即用的UI解决方案[34]。
Ant Design显著提升了国内前端开发效率。其组件库通过按需加载(Tree Shaking)与虚拟滚动(Virtual Scrolling)优化性能,减少打包体积并提升大数据列表渲染效率;Ant Design Pro内置Mock服务、完整国际化解决方案及UI测试流程,支持模块化设计与动态配置,例如2025年发布的Ant Design Pro v6正式版提供动态菜单与权限控制教程,涵盖项目搭建、路由配置、权限校验等核心功能,助力开发者快速构建企业级后台管理系统[30][35]。
在国际竞争力方面,Ant Design凭借庞大的社区支持、高频迭代能力与多语言适配(如完善da_DK Form文案),成为全球前端开发者广泛使用的组件库之一。其持续的功能升级(如v5.13.0版本为Form、Cascader等组件新增variant属性,优化Table隐藏列与Select最大可选配置)与问题修复(如修复Segmented、Checkbox等组件样式问题),进一步巩固了其在国际市场的技术竞争力[30][36]。
飞致云
MaxKB
MaxKB(Max Knowledge Brain)是飞致云推出的基于大语言模型(LLM)和检索增强生成(RAG)技术的开源企业级智能体平台,遵循GPLv3开源协议,GitHub Star总数超12万,截至2025年5月全网累计下载量已突破50万次,日均安装下载量超过1000次,在企业知识管理、智能服务等领域展现出显著价值[37][38][39]。
在企业知识管理中,MaxKB通过多项核心功能构建价值体系。其RAG检索增强能力支持文档上传(如Markdown、PDF、DOCX等格式及ZIP打包上传)、在线爬取、智能文本拆分(按标题层级拆分,单段最长4096字符)与向量化处理,可有效减少大模型幻觉,提升知识问答准确性[39][40]。内置工作流引擎与函数库支持复杂业务流程编排,例如通过MCP工具调用节点和AI对话节点的Streamable HTTP协议支持,满足智能客服、项目管理等场景的灵活需求[37][41]。同时,其零编码嵌入能力可快速集成至网站、钉钉、企业微信、CRM等第三方系统,赋予外部系统智能问答能力,显著提升企业内部知识获取效率与客户服务响应速度[38][41]。目前,MaxKB已在多领域落地应用,如高校领域的中国农业大学“小鹉哥”、东北财经大学“小银杏”,医疗领域的解放军总医院智能问答系统,企业领域的中铁水务知识库助手、中核西仪研究院“西仪睿答”等[38]。
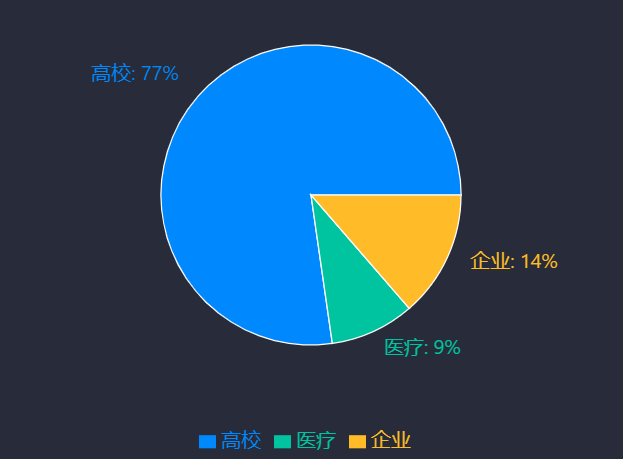
在大模型集成方面,MaxKB秉持“模型中立”原则,支持多类型大模型灵活对接与混合使用,包括本地私有大模型(如Llama 3、Qwen 2)、国内公共大模型(如DeepSeek、通义千问、智谱AI、百度千帆、Kimi)及国外公共大模型(如OpenAI、Azure OpenAI、Gemini),并支持动态切换模型供应商以适配不同场景需求[38][39][41]。其中,“DeepSeek+MaxKB”组合已在教育领域形成典型应用模式,例如天津外国语大学、北京建筑大学等17所高校及福建省厦门第六中学等中小学,将其应用于教学辅助、学术研究、校园服务、行政办公、财务管理、招生等场景,通过DeepSeek的模型能力与MaxKB的知识管理能力协同,提升教育服务智能化水平[37]。
在2025年7月,MaxKB 还推出了v2(详见 https://maxkb.cn/docs/v2/ )版本,支持了完整的 RBAC + 访问控制,同时持续加大了开发的力度,企业数字化的业务范围在不断地扩大。
从飞致云开源生态构建策略来看,MaxKB与JumpServer(运维审计)、1Panel(服务器管理面板)等开源工具形成互补,共同完善DevOps生态布局。MaxKB聚焦企业知识管理与智能交互层,通过轻量化部署(支持Docker一键启动及Ubuntu/CentOS离线部署,最低配置2C/4GB)、开放API及LDAP单点登录等特性,降低与其他DevOps工具的集成门槛[39][40]。其系统架构采用Vue.js/Logicflow前端、Python/Django后端,集成Langchain与PostgreSQL/pgvector向量数据库,技术栈与飞致云现有开源工具保持兼容性,为用户提供从基础设施管理到知识智能化应用的全链路开源解决方案支持[39]。
VAST AI
TripoSG/TripoSF
VAST在3D生成领域实现了多项技术突破,其核心项目TripoSG与TripoSF构建了高保真、高效率的3D内容生成基础能力。TripoSG作为高保真3D形状生成基础模型,具备高保真生成(清晰几何特征、精细表面细节及复杂结构网格)、语义一致性(准确反映输入图像语义与外观)、强泛化性(支持真实图像、卡通、草图等多风格输入)及鲁棒性能(复杂拓扑输入生成连贯形状)等关键特性[42]。技术架构上,TripoSG率先将基于校正流(Rectified Flow, RF)的Transformer架构应用于3D形状生成,融合跳跃连接增强设计,并通过独立交叉注意力机制注入全局(CLIP)和局部(DINOv2)图像特征;其先进变分自编码器(VAE)采用符号距离函数(SDFs)进行几何表示,引入SDF损失、表面法线引导及程函方程损失的混合监督训练策略,基于200万精心策划的图像-SDF对数据集训练,实现小模型规模下的高性能[42][43]。TripoSF则作为新一代三维基础模型,聚焦高分辨率三维重建和生成任务,提供SOTA级基础组件,其VAE预训练模型及推理代码已同步开源[43]。此外,VAST的技术进展还体现在Tripo 2.0模型中,该模型采用融合DiT和U-Net的复合架构,实现10秒生成形状几何、10秒生成纹理及PBR,验证了3D大模型的Scaling Law,在匿名测试中效果领先[44][45]。
在开源策略方面,VAST以“模型权重+推理代码”的全链路开源模式显著降低了3D创作行业门槛。2025年3月,VAST正式开源TripoSG与TripoSF,其中TripoSG的15亿参数模型(非MoE版本,2048 token潜空间运行)权重、推理代码及交互式演示通过GitHub和Hugging Face向AI社区开放,TripoSF的VAE预训练模型及推理代码亦同步发布[43]。此前,VAST已与Stability AI合作开源3D基础模型TripoSR(0.5秒单图生3D),并开源单张图像生成3D场景模型MIDI、多视角图像生成模型MV-Adapter,后续还计划开源三维部件补全、通用三维模型绑定生成等模型,形成覆盖3D生成全流程的开源体系[43][45]。这一策略使开发者与创作者可直接获取高性能工具,减少技术壁垒,推动3D内容创作从专业领域向大众普及。
| 项目名称 | 发布时间 | 技术特性 | 开源平台 |
|---|---|---|---|
| TripoSR | 2024年3月 | 0.5秒完成单图生3D模型 | GitHub, Hugging Face |
| MIDI | 2024年 | 单张图像生成3D场景模型 | GitHub |
| MV-Adapter | 2024年 | 多视角图像生成模型 | GitHub |
| TripoSG | 2025年3月 | 15亿参数3D生成模型,图像到3D生成任务领先 | GitHub, Hugging Face |
| TripoSF | 2025年3月 | 高分辨率三维重建基础组件 | GitHub, Hugging Face |
| 三维部件补全模型 | 2025年4月 | 三维部件补全技术 | 计划开源 |
| 模型绑定生成模型 | 2025年4月 | 通用三维模型绑定生成 | 计划开源 |
注:加粗项目为2025年核心开源版本
3D内容生成在多场景展现出显著商业化潜力,VAST已通过产品矩阵实现规模化应用。在应用场景上,其技术支持游戏、动画、3D打印、工业设计等领域的二次编辑,以及骨骼绑定、动作生成、场景生成等动态内容创作[44]。产品层面,大众级创作工具Tripo累计生成超3000万个3D模型,用户超300万;针对PGC场景的一站式3D工作台Tripo Studio自2024年下半年推出后,截至2025年6月收入达60万美元/月[46]。当前VAST占据超70%的3D AI内容生成市场份额,服务300多大客户及2万多中小客户,目标构建3D UGC内容平台,推动3D创作大众化[45]。投资机构普遍看好其商业化前景,如达晨财智认为文生3D是“新文明”最后一环,看好2C方向改变生活方式;春华创投则期待其探索更多3D创作可能[47]。
竞争格局方面,3D生成领域呈现“初创企业领跑、巨头加速入局”的态势。VAST凭借技术先发优势和开源生态构建,目前处于行业领先地位,但其面临抖音、腾讯、阿里等互联网巨头发力3D大模型的竞争压力,行业整体仍需应对商业化路径验证的考验[46]。不过,VAST核心团队背景深厚(如CTO梁鼎为清华博士,50+论文、100+专利;首席科学家曹炎培为清华博士,腾讯ARC实验室前领导),且已完成数亿元融资,为其技术迭代与商业化拓展提供支撑[44][47]。
技术领域专题分析
人工智能与大模型
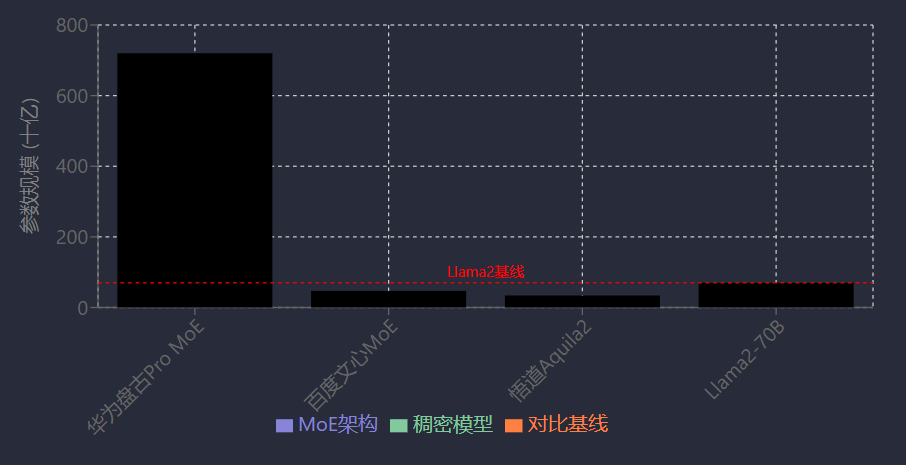
国内大模型开源生态呈现多维度竞争格局,头部科技企业与创新团队共同推动技术多样化发展。华为、百度等企业于2025年6月集中开源核心模型体系:华为首次开源盘古大模型体系,涵盖70亿参数稠密模型、720亿参数Pro MoE混合专家模型及昇腾推理技术体系;百度同步开源文心大模型4.5系列的10款模型,包含47B、3B激活参数MoE模型与0.3B参数稠密模型,并全量开放预训练权重与推理代码[14]。阿里通义团队则通过长期积累形成规模优势,已开源200多款模型,其通义千问Qwen衍生模型数量超13万,下载量突破3亿次[15]。此外,悟道·天鹰Aquila大语言模型系列升级至Aquila2,新增340亿参数成员,其开源全家桶包含基础模型、对话模型、SQL模型及语义向量模型等,在22项综合评测中超越Llama2-70B等同类模型[48];VAST AI聚焦3D大模型领域,Tripo系列(Tripo 1.0、Tripo 2.0)通过优化生成速度与质量推动行业技术收敛[44];DeepSeek于2025年初开源的R1推理模型及Janus Pro多模态模型,两周内GitHub Star新增超15万,覆盖185个国家和地区开发者[49]。
| 企业 | 开源模型 | 参数规模 | 技术特点 | 来源 |
|---|---|---|---|---|
| 华为 | 盘古大模型体系 | 70亿参数(稠密)<br>720亿参数(Pro MoE) | 首次开源大模型体系,含昇腾推理技术 | [14] |
| 百度 | 文心大模型4.5系列 | 10款模型<br>含47B/3B MoE<br>0.3B稠密 | 全量开放预训练权重与推理代码 | [14] |
| 阿里 | 通义系列 | 200+开源模型<br>13万+衍生模型 | 通义千问Qwen下载量超3亿次 | [15] |
| 悟道 | Aquila2系列 | 340亿参数(34B) | 22项评测领先Llama2-70B,支持16K上下文 | [48] |
| VAST | Tripo系列 | - | 10秒生成3D模型,累计生成3000万+模型 | [44] |
| DeepSeek | R1+Janus Pro | - | 两周新增Star超15万,覆盖185国 | [49] |
技术路线方面,国内大模型呈现MoE架构与稠密模型并行发展态势。MoE(混合专家模型)以其参数规模优势成为重要方向,如华为盘古Pro MoE模型达720亿参数,百度文心4.5系列包含47B激活参数MoE模型,通过动态激活专家网络提升性能[14][15]。稠密模型则通过算法优化实现高效性能,例如Aquila2-34B基座模型以仅1/2参数量、2/3训练数据量超越Llama2-70B,其创新的NLPE(非线性位置编码)和分段式Attention算子,将上下文长度扩展至16K(34B-16K版本在LongBench任务中接近GPT-3.5),并支持32K长度续写[48]。此外,3D大模型领域探索3D+2D融合技术路线,如VAST的Tripo系列支持10秒生成带纹理及PBR的3D模型[44]。
国际市场影响力方面,国内开源大模型通过主流平台逐步拓展全球覆盖。悟道·天鹰系列模型在HuggingFace平台(huggingface.co/BAAI)开源,其AquilaChat2-34B被称为当前最强开源中英双语对话模型[48]。DeepSeek的R1模型开源10天进入中国OpenRank Top 62位,企业榜单全球排名第86位,美国开发者占比15.7%(仅次于中国的24.4%),主要参与使用与技术观望[49]。阿里通义千问Qwen衍生模型下载量超3亿次,显示其在国际开发者社区的渗透力[15]。
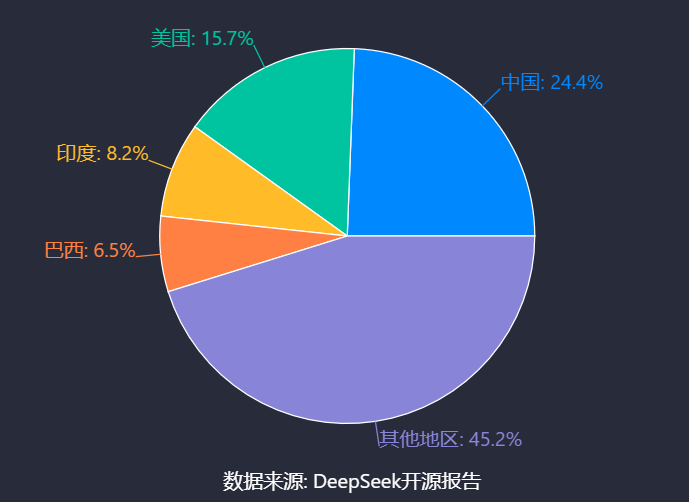
开源模式显著推动AI技术普惠与产业落地。在技术普惠层面,企业通过开放核心能力降低应用门槛:华为、百度全量开放模型权重与推理代码,VAST开源threestudio、Wonder3D等算法框架,推动3D行业技术收敛[14][44];GitHub热门项目如awesome-deepseek-integration(聚合300+工具)、dify(LLMOps平台)等覆盖AI开发全链路需求[50]。产业落地方面,开源工具与模型已在多领域实现规模化应用:MaxKB基于LLM+RAG技术,支持多模型集成与业务逻辑编排,应用于智能客服、企业知识库[38][40];腾讯Angel机器学习平台处理速度较LightLDA提速5倍以上,其联邦学习平台Angel PowerFL支持千亿级数据计算,已落地金融、医疗行业[51];VAST的Tripo2.0推动3D内容创作工具发展,预示下一代互联网3D交互场景的普及可能[47]。
数据库
近年来,中国国产分布式数据库在技术创新与行业应用中取得显著进展,形成以OceanBase、TiDB、openGauss等为代表的多元产品体系,并在金融、运营商等核心领域加速替代进程。开源模式通过社区协作与生态共建,成为推动技术迭代与市场渗透的关键力量。
技术优势与特性演进
国产分布式数据库在架构设计、多模态处理及易用性优化上展现核心竞争力。OceanBase通过持续产品迭代强化分布式能力,其OCP 4.3.5-CE社区版支持OBKV-Redis监控、180天数据恢复区间等20余项改进,并推出桌面版降低部署门槛,集成向量能力与数组函数扩展功能[52][53]。TiDB作为原生分布式关系型数据库,凭借HTAP架构与向量化计算引擎提升性能,支持16383维向量存储及HNSW索引算法,可构建RAG解决方案满足多模态数据需求,2025年v8版本进一步针对金融场景优化,将I/O抖动影响降低、更新性能提升500%[24][26][28]。openGauss 7.0.0版本引入oGRAC多写架构与DataVec向量数据库能力,通过存算分离架构实现多节点并行访问与RAG技术支持,结合轻量级锁与全局页级MVCC技术提升高并发处理能力[54];时序数据库领域如TDengine以高效物联网数据处理为特色,GitHub星标达13.9K,集群版开源后连续6天全球趋势榜第一[55];图数据库Apache HugeGraph则支持数千亿顶点边存储与Gremlin/Cypher查询,实现OLTP+OLAP融合[16]。
在金融与运营商等核心行业的替代进展
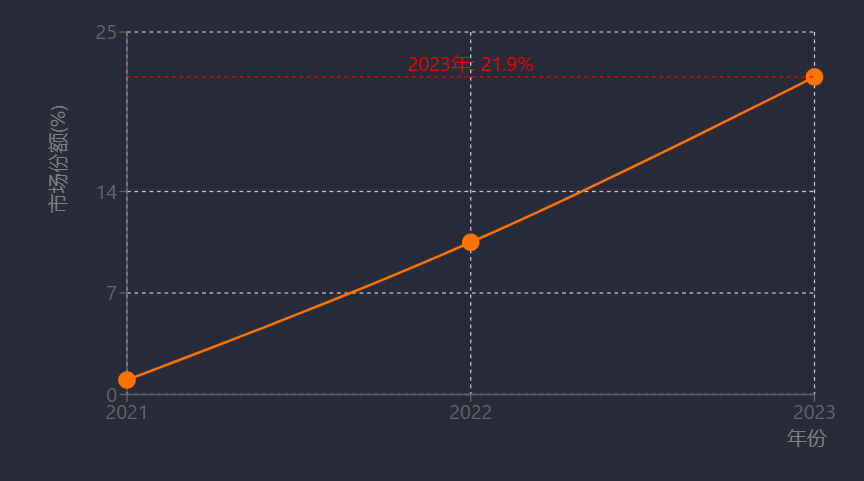
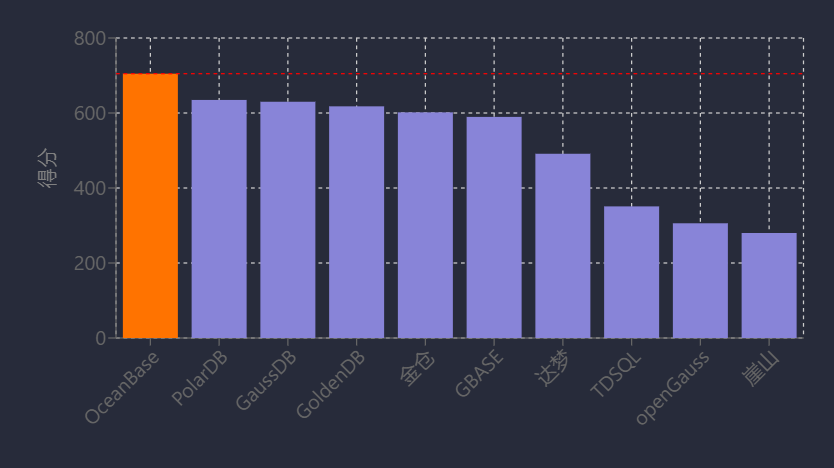
国产数据库在关键行业的替代已从试点走向规模化应用。金融领域,腾讯云TDSQL中标招商银行2025-2028年度许可采购项目,其分布式事务处理专利保障金融交易稳定性;OceanBase落地东莞银行项目招标预算1110万元,TiDB通过性能优化切入核心交易场景[56][57]。运营商领域替换成效显著:中国移动采购达梦、TiDB等五类数据库共2582套,青海公司数智云原生系统100%替换为自研磐维数据库,部署21节点集群将数据迁移时长缩短至50分钟;中移动全域核心系统规模上线openGauss,民生银行亦实现openGauss核心系统规模化部署[54][56][58]。政务与能源领域,金仓数据库中标新疆移动自主可控替换项目及宁波市司法局26套系统采购,国能集团基于openGauss开发CERDB支撑云平台与电商系统[23][54]。市场数据显示,2023年本地部署关系型数据库外资厂商市占率降至37.1%;openGauss市场份额从2021年1%跃升至2023年21.9%[54][56];2025年4月中国数据库排行榜中OceanBase以领先第二名近70分登顶,PolarDB集成大模型实现AI算力扩展,GaussDB、金篆信科GoldenDB等进入前五[23]。
开源模式对生态建设的促进作用
开源社区通过技术共享与开发者赋能加速生态扩张。OceanBase推出“DBA实战营在线体验平台”,提供零门槛集群管理(租户创建、副本扩缩容)、故障演练(节点宕机切换)等实验环境,并复现金融电商典型用例;发起“隐藏技能挖掘计划”鼓励创意应用开发,2025年社区版本下载量增长超25%[54][59][60]。openGauss采用Mulan PSL-2.0许可证,opengauss-server仓库吸引109名贡献者,通过92个子仓库构建连接器、文档等完整生态,海量数据基于其开发Vastbase G100并实现医疗核心系统落地[54][61][62]。TiDB社区活跃度位居前列,开展多地实践分享活动并入选《2025年度中国数据库优秀厂商图谱》,其云原生工具链(TiProxy、TiUP)与Apache Spark等组件集成完善[24][63]。迁移工具生态同步发展:OMS V4.2.8-CE社区版支持MySQL、TiDB等到OceanBase的全量/增量迁移,并新增Hive数据写入能力[64]。开源模式不仅降低技术门槛,更通过人才培养(如OceanBase OBCA/OBCP认证、TiDB高校特训营)与伙伴合作(OceanBase“伙伴主导战略”)推动产业协同,2024年国内活跃开源数据库项目已覆盖关系型(openGauss)、时序(TDengine)分布式(TiDB)等全品类[25][56][59]。
操作系统
开源鸿蒙(OpenHarmony)作为面向物联网场景的开源操作系统,其差异化竞争力核心在于分布式架构、弹性部署能力及统一数字底座技术。技术特性方面,其通过KaihongOS实现“弹性部署”与“软总线”技术,支持跨设备异构互联与算力共享;HiHopeOS提供可视化与自动化探测功能,LightBeeOS则扩展了操作范围能力,形成多场景适配的技术体系[1][12]。此外,原子化服务架构支持低代码开发,端到端安全防护(设备认证、数据加密、指令校验)满足行业安全标准,进一步强化了其技术优势[65]。
在打破“数据孤岛”方面,开源鸿蒙通过分布式软总线与统一数据模型实现设备跨端协同。以智慧楼宇场景为例,福州建总大厦基于KaihongOS连接3195个异构设备(涵盖空调、照明、安防等十多个子系统),形成“超级设备”管理模式,解决了硬件协同与数据割裂问题,实现能耗管理、人员跟踪等19个场景的智能调度[4][5][65]。建筑开源鸿蒙操作系统还通过标准化CoAP通信协议、设备发现注册机制及统一数据模型(定义设备关键信息、服务、事件和特征),为设备互联与数据互通提供技术支撑[8][66]。
推动产业数字化进程中,开源鸿蒙已在工业、电力、水利、智慧城市等多领域实现深度应用。工业领域,天罡智能基于开源鸿蒙开发国内首个工业机器人实时操作系统iiRobotOS,支持多机器人统一编程与复杂协作;龙芯生态伙伴推出“龙架构+开源鸿蒙”工业控制操作系统,包括华夏天信矿鸿操作系统(MineHarmony)、中电启明星星鸿EOS操作系统及华龙迅达华龙工业操作系统(HualongOS),后者实现工业控制设备互联互通与“一次开发、多端部署”[9][10][11][67]。此外,中国南方电网“电鸿”、苏州水利智慧联调联控等项目也验证了其在能源、市政等领域的数字化价值[9]。
与Android、iOS等面向消费电子的移动操作系统不同,开源鸿蒙聚焦物联网与工业场景,其渗透潜力呈现“工业领域快速拓展、消费电子场景化突破”的特点。工业领域,依托全栈自主体系与高安全性,已形成从机器人控制到工业互联网的完整解决方案,吸引诚迈科技等企业参与生态建设[11]。消费电子领域,虽暂未大规模进入手机市场,但其在智慧楼宇、智能家居等场景通过原子化服务与跨设备协同构建差异化体验,如《建筑开源鸿蒙互联参考架构》白皮书支撑智能建造、智慧工地等场景创新,未来有望通过“超级设备”模式向消费电子延伸[3][65]。生态层面,超300家伙伴加入电鸿物联产业链,鸿湖万联与海思等芯片厂商深化协作,为其跨领域渗透提供底层支撑[1]。
前端与低代码
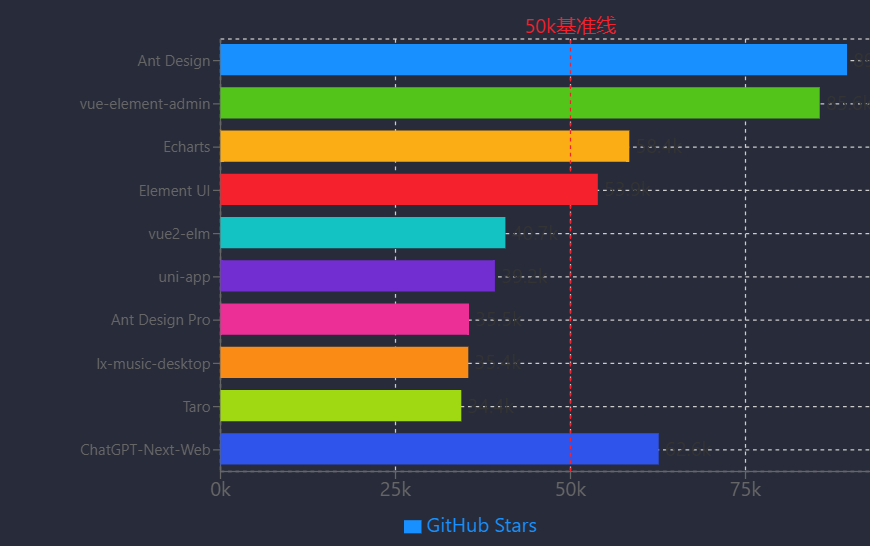
前端框架与低代码平台作为企业数字化转型的关键技术支撑,通过组件化、模块化及可视化开发模式显著提升开发效率,推动业务快速迭代。在前端框架领域,以Ant Design系列为代表的开源项目形成了完整的技术生态:Ant Design作为企业级React UI组件库,不仅提供丰富的基础组件,还通过实验性组件探索低代码等新兴场景,为界面开发提供高效解决方案[30];其衍生框架Ant Design Pro 5.0进一步整合预置模板与最佳实践,支持数据分析仪表板、复杂表单处理等核心业务场景,并具备多设备响应式显示与国际化部署能力,可快速搭建企业级Web应用[34]。2024年国产开源前端项目Top 10(按GitHub Star数排序)显示,Ant Design(89.5k)、vue-element-admin(85.6k)、Echarts(58.4k)等项目广泛覆盖React/Vue技术栈、数据可视化及跨端开发等领域,其中uni-app(39.2k)支持多端发布,Taro(34.4k)实现跨框架开发,通过技术标准化降低协作成本,提升大规模应用开发效率。
低代码平台通过可视化拖拽、预构建模块与AI能力融合,进一步降低开发门槛,赋能企业数字化转型。JeecgBoot AI低代码平台整合人工智能技术,提供拖拽式操作与预构建AI模块,支持零代码快速搭建ERP、CRM、OA等复杂业务系统,核心功能涵盖自动化流程、数据集成与一键部署,显著降低开发成本并提升效率,应用场景覆盖智能客服、图像识别等领域[68]。GitHub开源低代码项目中,NocoBase(11.2k Star)基于插件架构与数据模型驱动设计,支持私有部署与数据密集型业务系统开发;APITable(12.6k Star)以API为中心,实现6000+应用集成与数据流自动化;LowCodeEngine(14.2k Star)由阿里巴巴前端团队开发,通过模块化设计与拖放开发模式,提供丰富UI组件库支持[69]。这些平台通过简化开发流程,使非专业开发者也能参与应用构建,加速企业数字化落地。
开源生态在标准化与定制化之间的平衡是技术可持续发展的关键。Ant Design系列通过持续迭代实现标准化与灵活性的统一:Ant Design Blazor 1.1.0通过参数标准化(字符串转枚举)提升代码可维护性,同时支持Icon自定义SVG与Typography组件升级,增强设计自由度[32];Ant Design 5.13.0版本优化Tabs、Table等核心组件的稳定性与性能,扩展形态变体并强化国际化支持,既保障组件行为一致性,又满足多样化业务场景需求[36]。低代码平台方面,LowCodeEngine的模块化设计与NocoBase的插件架构,均以标准化核心框架为基础,允许开发者通过插件扩展功能,实现“基础能力标准化、业务需求定制化”的协同模式,为企业提供灵活且可控的开发工具链。
社区与生态建设
社区活跃度分析
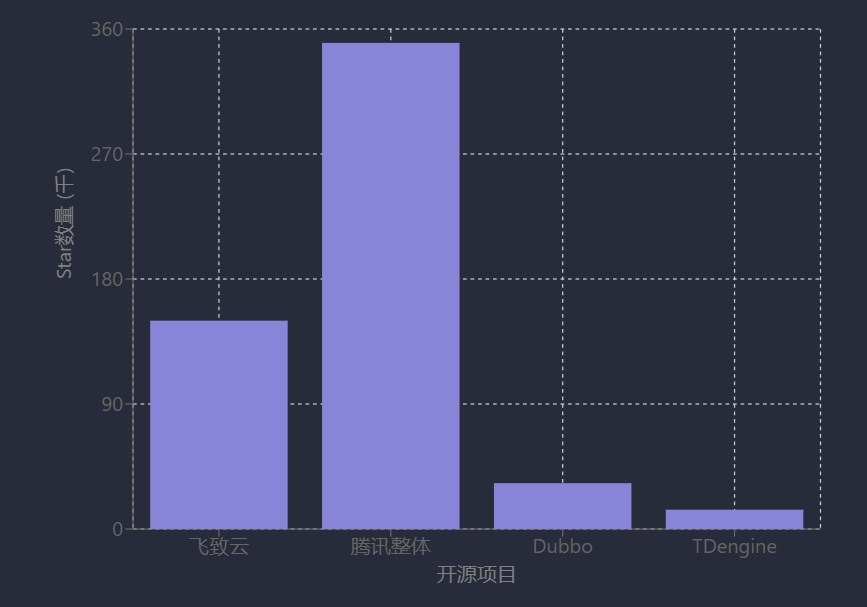
国内开源项目社区活跃度呈现多样化发展态势,核心量化指标(如GitHub Star数、开发者规模、下载量等)显示部分项目已具备较高的社区基础。例如,飞致云旗下开源项目GitHub Star总数超过150,000个,其1Panel应用商店2025年5月下载量达200,502次;RT-Thread聚集全球近30万开发者,吸引近万家企业客户[37][70]。腾讯整体开源项目超120个,Star数累计超35万,曾进入GitHub周榜前十,其中Angel项目获6200 Star,超100家公司和机构开发者参与生态建设[51]。TDengine、DeepSeek等项目亦表现活跃,TDengine在GitHub上拥有13.9K Star、3.6K Fork,日克隆代码人数超100;DeepSeek新增Star超15万(覆盖185个国家和地区),活跃开发者1679人,中国、美国、印度为主要来源[49][55]。
数据来源: [
“https://juejin.cn/post/7510077145404063807”,
“https://blog.csdn.net/tencent__open/article/details/116725184”,
“https://blog.csdn.net/u012562943/article/details/108376954”,
“https://cloud.tencent.com/developer/article/1743791?areaSource=106000.18”
]
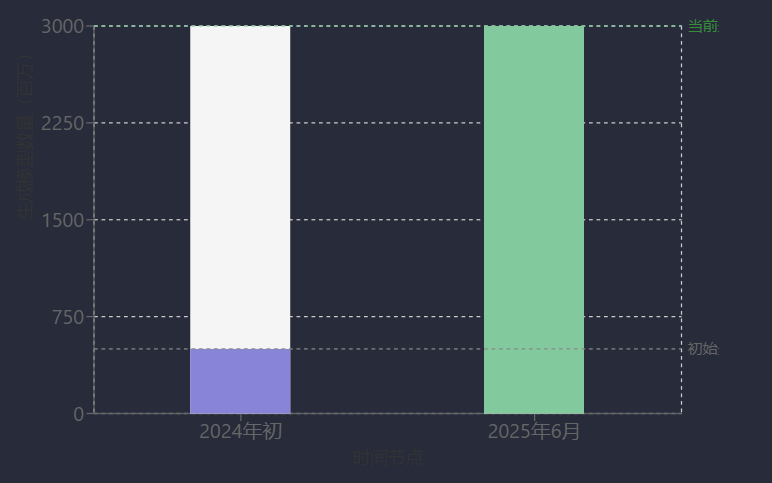
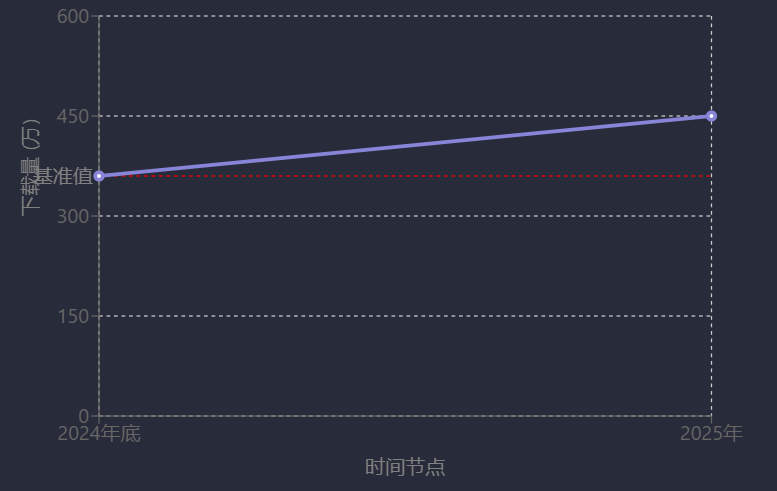
在垂直领域,AI与数据库项目社区活跃度尤为突出。通义千问Qwen在HuggingFace社区2024年全球模型下载量中占比超30%,总量超3亿,衍生模型数量超13万[15];openGauss社区版本下载量从2024年底的360万增长至2025年的450万,涨幅超25%[54];MaxKB日均下载量超1000次,广泛应用于智能客服、教育等领域[40]。
数据来源: [“https://tech.sina.cn/2025-07-14/detail-inffmtuu4812596.d.html”]
企业主导的开源项目通过多样化运营模式提升社区活力。OceanBase社区构建了“用户组+技术讨论+激励活动”的立体运营体系:通过OUG用户组(OceanBase User Group)策划线上线下聚会,SIG前沿哨(Special Interest Group)开展AI4DBA主题交流会等技术讨论,并发起“隐藏技能挖掘计划”等活动,邀请开发者分享创意应用,设置社区周边奖励[53][71]。同时,该社区持续推出学习资源,如2024年升级《DBA从入门到实践》、2025年推出“DBA实战营”,通过场景化教学和认证奖励提升用户参与度[60]。Dubbo作为阿里主导的微服务框架,社区运营以技术迭代和外部贡献为核心,拥有33k stars、21k forks,57位committer及379位contributor,外部贡献占比超阿里内部,全球微服务框架排名第五,近年3.x系列通过多个重要版本增强功能与性能[17][72]。此外,GoldenDB通过开放社区推动生态落地,DolphinDB推出技能认证高校特训营,软通动力累计向OpenHarmony社区贡献代码超100万行,均体现企业在社区建设中的主动投入[12][23]。
与国际项目相比,国内项目在社区活跃度上仍存在差距。以微服务领域为例,Spring Cloud社区活跃度显著优于Dubbo,而Dubbo又优于EJB,社区活跃度直接影响问题解决速度和框架完善度[19][73]。尽管部分国内项目通过企业资源支持实现了规模增长,但在社区自驱力、全球开发者参与广度及问题响应效率等方面,与Kubernetes等国际顶级项目相比仍有提升空间。
开源生态合作
开源生态合作是推动技术创新与产业规模化应用的核心驱动力,主要体现在产学研协同创新及全球化合作两大维度。在产学研协同方面,多方主体通过资源整合与联合实践加速技术迭代。例如,中国计算机学会主办的GLCC 2025编程夏令营联合阿里、百度等企业及高校,围绕Apache HugeGraph、隐语SecretFlow等真实开源项目开展功能改进与开发,不仅为项目注入创新活力,还通过奖金激励与实习通道构建人才培养闭环[16]。腾讯与北京大学共建“协同创新实验室”,在人工智能、大数据领域产出的Angel项目兼顾工业可用性与学术创新性,并成功捐赠至LF AI基金会成为国内首个顶级项目,彰显了产学研融合对技术成果转化的推动作用[51]。此外,鸿湖万联与高校共建实习基地,进一步打通“科研-实践-人才”链路,为开源生态持续输送专业力量[12]。
企业间的跨领域技术协同是开源生态落地的关键支撑。在操作系统领域,福州市城乡建总集团与深开鸿基于开源鸿蒙打造全国首个智慧楼宇样板点,通过“开鸿安全数字底座”实现异构设备跨端互联,沉淀19项成熟经验并形成四大模块化解决方案,为建筑行业智能化提供可复用范式[5][65]。华为云与万安智能签约推出基于OpenHarmony的智能建筑解决方案,通过空间单元智控器与场景交互终端实现IoT设备全域协同,展现龙头企业技术共享对生态集群构建的引领作用[13]。数据库领域,openGauss社区与中移动、国能集团等企业合作,推动数据库技术在运营商、能源等关键行业的应用实践;GBase与新华三联合推出全国产化基础架构解决方案,加速国产化技术替代进程[23][54]。此外,Dubbo通过集成Nacos、Prometheus、Istio等工具构建完整服务治理生态,TiDB整合Spark、Kafka等大数据组件,均体现了开源项目通过技术协同提升场景适配能力的特点[24][72]。
在全球化合作中,国内开源项目正积极融入国际生态,但仍面临影响力提升的挑战。技术输出层面,VAST AI与Stability AI合作推出开源3D模型TripoSR,推动行业技术收敛;TiDB通过开源模式触达全球用户,加速产品打磨与市场拓展[27][44][45]。社区建设层面,TDengine吸引超50名外部贡献者,openGauss明确提出与全球开源组织深度合作的愿景,体现开放协作姿态[55][57]。然而,当前合作多集中于技术应用层面,在核心标准制定与国际社区主导权方面仍需突破。未来,随着开放原子开源基金会等组织推动超300家伙伴共建电鸿物联产业链,国内开源生态需进一步平衡本土化创新与全球化协同,加速形成“供给-需求”商业闭环,推动技术成果产业化落地[1][9]。
挑战与展望
当前挑战
国内开源软件在快速发展的同时,面临技术攻坚、生态构建及商业模式三大维度的核心挑战,需系统性应对以实现可持续发展。
在技术攻坚层面,具体项目的技术瓶颈与共性技术难题并存。部分开源项目存在场景化能力不足问题,例如MaxKB在复杂专业领域知识的准确性和深度有待提升,且存在系统集成兼容性问题;Dify的性能表现高度依赖底层模型,复杂任务需结合微调优化,同时面临API调用成本高的压力[41]。分布式系统运维复杂度突出,TiDB在大规模集群管理中面临较高运维难度[24]。基础软件领域,3D生成模型受限于3D数据匮乏(需通过长期积累获取)及市场需求未完全验证(如Meta VR部门亏损、Vision Pro出货量不及预期、腾讯字节裁撤XR部门)[74]。此外,安全合规与版本维护构成普遍挑战,《2025 State of Open Source》报告显示,保持软件更新、满足安全性和合规性要求、维护停产(EOL)版本是使用开源软件的三大核心难题,以CentOS 7为例,其于2024年6月EOL后,40%的大型企业仍在使用,而28%的受访者无针对其漏洞的修复计划[46]。行业应用中,国内银行核心系统替换传统集中式数据库时,需应对技术成熟度、稳定性保障及监管合规的多重考验[23]。
生态构建方面,社区活力与协作机制存在明显短板。部分项目社区活跃度不足,如Dubbo面临入门门槛高、官网资料不全、源码级分享少、部署复杂等问题,制约开发者参与度[21]。用户体验与文档体系不完善,OceanBase社区反馈桌面版安装崩溃、OCP功能缺陷、文档内容不一致等问题,反映开源生态在用户支持环节的薄弱[46]。工具链协同与DevOps落地困难,45%的企业因使用超5种工具导致工具链碎片化,形成信息孤岛;32%的企业因开发与运维团队目标分歧引发文化冲突,仅18%的企业建立核心指标持续监控体系,自动化工具链“伪集成”(如权限冲突导致30%构建任务失败)和持续反馈机制缺失(仅25%企业建立用户反馈通道)进一步加剧生态割裂[75]。跨场景协同障碍显著,城市治理领域因万物互联场景下硬件协议各异、数据孤岛林立,导致运营维护成本高企、响应效率低[5][65]。
商业模式层面,市场竞争与商业化路径面临双重压力。垂直领域竞争加剧,如VAST在3D大模型领域需应对抖音、腾讯、阿里等互联网巨头的挤压,行业整体面临商业化验证考验[46]。开源模式下的竞争风险凸显,开源大模型可能导致其他企业或开发者基于其进行二次开发,形成与内部业务竞争的产品,需通过持续技术优化维持优势[15]。ToB市场对综合能力要求严苛,项目成败不仅取决于产品能力,还依赖交付能力及客户需求理解深度[15]。资本市场环境趋紧,尽管优质AI企业仍能获得匹配价值的资金,但整体投资标准更趋严格,对开源项目的商业化可持续性提出更高要求[45]。
针对上述挑战,建议从三方面推进优化:政策层面加强对开源安全合规、版本维护及人才培养的扶持,例如设立专项基金支持EOL版本补丁开发与企业迁移;社区层面建立多元化激励机制,提升开发者参与度,完善文档与用户反馈闭环,增强社区活力;产业层面推动跨行业合作,打破数据孤岛与硬件协同壁垒,通过联盟共建降低API调用成本,探索开源项目与垂直行业需求的深度融合路径。
未来展望
在AI时代与数字经济深度融合的背景下,中国开源软件产业正迎来历史性发展机遇。AI技术的渗透推动开源生态向智能化、高效化演进,例如AI与数据库的深度融合将使数据底座更高效、智能和开放,基于数据库的行业解决方案及人才培养成为产业发力重点[54];AI驱动的DevOps自动化(如智能测试用例生成)与低代码工具则进一步降低技术落地门槛[75]。同时,数字经济的扩张催生新需求,3D创作市场规模预计达2-3万亿元,VAST等项目通过降低创作成本推动3D内容大众化[45],而中国开源开发者数量已居全球第二且增长最快,为GitHub贡献550万个项目,为产业创新注入持续动力[51]。
重点领域突破方向清晰显现。工业软件领域,华龙讯达依托开源鸿蒙核心优势,推动工业操作系统创新,助力工业自主创新[10];龙芯则布局打印机自研芯片,覆盖激光、喷墨等系列化产品,完成多操作系统适配[67]。物联网与智慧城市领域,开源鸿蒙的分布式能力将实现楼宇、道路及城市基础设施互联互通,形成"超级手机"级网络,衍生交通调度、能源共享等场景,数字孪生与AI交互技术的融合更推动智慧楼宇模式复制推广[5][6];机器人领域将大量采用鸿蒙系统,统一互联标准以加速研发、降低成本[23]。数据库领域,openGauss计划五年内联合伙伴在核技术、AI及"四高"特性上突破[54],OceanBase力争提升合作伙伴业务占比至70%,PolarDB转型AI计算核心平台[23],TiDB则深耕医疗、金融场景以强化性能与稳定性[24][28]。操作系统领域,理想星环OS向"空间智能操作系统"进化,软通动力深化AI与操作系统融合以推进全球化[12][70]。此外,3D与空间智能领域因Vision Pro等设备普及需求增长,AI生产力提升与李飞飞World Labs的空间智能模型将加速技术落地[74];云原生方向,Dubbo将加强Kubernetes支持、多语言SDK开发及性能优化[72];AI生态中,DeepSeek重构全球开源AI竞争格局,MaxKB、Dify等LLM框架深化企业知识管理应用[41][49]。
生态共建与全球化布局是产业发展的关键战略。生态层面,需构建开放协同的技术标准体系与完善认证体系,如华为在建筑开源鸿蒙中倡议的技术共建、标准共研和生态共享[2][8];开放原子开源基金会持续推动开源项目落地与技术成果产业化,加速产业转型升级[1][9]。全球化层面,中国基础软件需突破全球市场占比不足10%的现状,力争进入细分领域前三以增强国际影响力[55],同时依托开源社区力量,推动openGauss等项目生态繁荣,让中国科技公司及开发者为全球开源贡献更多力量[51][54]。



一文解决】var let const)










——链接预测)




