Hadoop HDFS高可用性(HA)概述
在分布式存储领域,Hadoop分布式文件系统(HDFS)作为Hadoop生态系统的核心存储组件,其高可用性(HA)设计一直是架构师们关注的焦点。传统HDFS架构中,NameNode作为单一主节点管理整个文件系统的元数据,这种设计虽然简单高效,却存在明显的单点故障风险——一旦NameNode宕机,整个集群将陷入瘫痪状态。
HDFS HA的基本架构
为解决这一关键问题,Hadoop 2.0引入了高可用性架构,通过部署双NameNode(Active-Standby模式)来消除单点故障。Active NameNode负责处理所有客户端请求,而Standby NameNode则实时同步元数据变更,随时准备接管工作。这种设计使得系统在Active节点故障时能够实现秒级切换,将服务中断时间控制在最小范围内。
腾讯云技术社区的研究表明,HDFS HA的实现依赖于三个关键技术组件:ZooKeeper用于协调和故障检测,JournalNode集群负责元数据同步,以及ZKFC(ZooKeeper Failover Controller)实现自动故障转移。这种架构不仅解决了单点故障问题,还通过共享存储设计避免了传统SecondaryNameNode方案中可能出现的元数据丢失风险。
在Hadoop生态系统中的关键作用
作为大数据处理的基石,HDFS的高可用性直接影响着整个Hadoop生态系统的稳定性。51CTO的技术分析指出,HDFS HA确保了MapReduce、YARN、Hive等上层计算框架能够持续访问存储数据,避免了因存储层故障导致的计算任务中断。特别是在金融交易、电信计费等对服务连续性要求极高的场景中,HA机制成为业务连续性的重要保障。
百度开发者社区的案例研究显示,某大型电商平台在部署HDFS HA后,系统年可用率从99.5%提升至99.99%,相当于每年减少约4小时的计划外停机时间。这种提升对于处理日均PB级交易数据的平台而言,意味着数百万潜在订单损失的避免。
解决的核心问题与业务价值
HDFS HA主要应对三类典型问题:首先是硬件故障,包括服务器宕机、网络分区等意外情况;其次是软件升级和维护期间的业务连续性保障;最后是应对突发流量峰值时的快速扩容需求。通过主备节点无缝切换,系统可以在这些场景下保持持续服务。
从技术实现角度看,HA机制带来了多重优势:
- 1. 故障自动恢复:通过ZKFC监控和自动切换,平均故障恢复时间(MTTR)从人工干预的分钟级缩短至秒级
- 2. 数据一致性保障:基于QJM(Quorum Journal Manager)的元数据同步机制,确保切换过程中不会丢失已提交的写操作
- 3. 运维透明化:管理员可以安全地进行计划内维护,而不必担心影响生产服务
CSDN技术专家在分析中指出,现代HDFS HA方案已能容忍N/2的JournalNode节点故障(N为集群规模),这种设计既保证了数据安全性,又避免了传统共享存储方案(如NAS)带来的性能瓶颈和额外成本。随着容器化部署的普及,HDFS HA架构还展现出良好的云原生适配性,支持在Kubernetes等平台上实现弹性伸缩。
HDFS HA实现原理详解
在Hadoop 2.0之前,HDFS架构存在明显的单点故障风险——整个集群仅依赖单个NameNode管理元数据。一旦NameNode发生故障,整个HDFS集群将不可用,必须重启NameNode才能恢复服务。这种设计缺陷严重影响了系统的可用性,使得7×24小时持续服务成为不可能完成的任务。HDFS高可用(HA)架构的引入彻底改变了这一局面,其核心思想是通过主备NameNode机制配合共享存储系统,实现快速故障转移和无缝服务接管。

主备NameNode架构设计
HA架构的核心在于构建Active-Standby双节点体系。Active NameNode负责处理所有客户端请求,而Standby NameNode则实时同步元数据变化,随时准备接管服务。这种设计需要解决三个关键问题:
- 1. 元数据实时同步:确保Standby节点能及时获取Active节点的所有状态变更
- 2. 故障自动检测:快速识别Active节点失效并触发切换
- 3. 服务无缝转移:客户端能够自动重定向到新的Active节点
为解决这些问题,HDFS HA引入了三个核心组件:ZKFC负责监控和故障转移决策,JournalNode集群提供共享存储服务,而ZooKeeper则提供分布式协调能力。这种架构下,即使Active NameNode发生硬件故障,整个切换过程可在30秒内完成,远快于传统手动恢复所需的数十分钟。
QJM共享存储系统原理
Quorum Journal Manager(QJM)是HDFS HA采用的共享存储方案,其设计灵感源自Paxos分布式一致性协议。JournalNode集群通常由2N+1个节点组成,可容忍最多N个节点故障。这种设计实现了CAP理论中的CP平衡(一致性与分区容错性),确保元数据变更能够安全持久化。
当Active NameNode接收到写请求时,会先将编辑日志(EditLog)写入JournalNode集群。根据QJM的仲裁原则,只有当大多数(N+1)JournalNode确认写入成功后,本次操作才会被视为完成。这种机制保证了即使部分JournalNode不可用,系统仍能继续运作。例如,由3个JournalNode组成的集群(N=1)需要至少2个节点确认写入,即使1个节点宕机也不影响服务。
JournalNode内部采用分段存储机制管理EditLog。每个日志段(segment)对应一个连续的事务ID(txid)范围,包含两种状态:
- • Inprogress段:当前正在写入的活跃段文件(如edits_inprogress_000000003)
- • Finalized段:已完成写入的封闭段文件(如edits_000000001-000000002)
这种设计不仅提高了日志管理的效率,还便于Standby NameNode按需拉取特定范围的元数据变更。
元数据一致性保障机制
保证主备NameNode元数据一致性是HA架构的核心挑战。HDFS通过多层次的同步机制实现这一目标:
- 1. Epoch编号系统:每个Active NameNode实例拥有唯一的递增epoch编号。JournalNode会拒绝epoch值小于本地记录的写入请求,防止"脑裂"情况下出现双主节点同时写入。当发生主备切换时,新Active节点会生成更大的epoch值,确保其写入权限的合法性。
- 2. 双重确认机制:Active NameNode执行元数据变更时,必须完成两个关键步骤:
- • 将EditLog同步到大多数JournalNode
- • 更新内存中的文件系统镜像(FsImage)
只有这两个操作都成功,才会向客户端返回成功响应
- 3. 定期检查点机制:Standby NameNode会定期执行检查点操作,将EditLog合并到FsImage中。这不仅减少了故障恢复时需要重放的日志量,还通过以下流程确保数据完整性:
- • 从JournalNode下载最新的EditLog
- • 与本地FsImage合并生成新镜像
- • 将新镜像上传回Active NameNode
这个过程使得Standby节点始终保持与Active节点近实时的状态同步
主备状态转换流程
当需要进行主备切换时(无论是计划内维护还是故障转移),系统遵循严格的协议确保状态转换安全:
- 1. Active节点降级:当前Active节点首先停止接受新的客户端请求,完成所有进行中的操作,并将最后的EditLog强制刷写到JournalNode。这一步骤确保不会有未持久化的元数据变更丢失。
- 2. Standby节点准备:待切换的Standby节点确保已同步所有JournalNode中的EditLog,完成最后一次检查点操作,并验证其FsImage与最新EditLog的一致性。
- 3. 服务接管:新Active节点加载完整的元数据后,通知所有DataNode更新其块报告,并开始接受客户端请求。此时ZooKeeper会更新其存储的Active节点信息,使客户端能够发现新的服务端点。
值得注意的是,整个切换过程中JournalNode集群始终保持可用,这为快速故障恢复提供了基础。即使在极端情况下同时丢失Active和Standby NameNode,管理员仍可通过从JournalNode恢复元数据重建NameNode服务。
ZKFC故障切换流程解析
在HDFS高可用架构中,ZKFC(ZooKeeper Failover Controller)扮演着至关重要的角色。这个轻量级进程运行在每个NameNode节点上,通过与ZooKeeper集群的协同工作,实现了对NameNode状态的实时监控和自动故障转移功能。理解ZKFC的工作机制,是掌握HDFS高可用实现原理的关键环节。
ZKFC的核心组件与架构
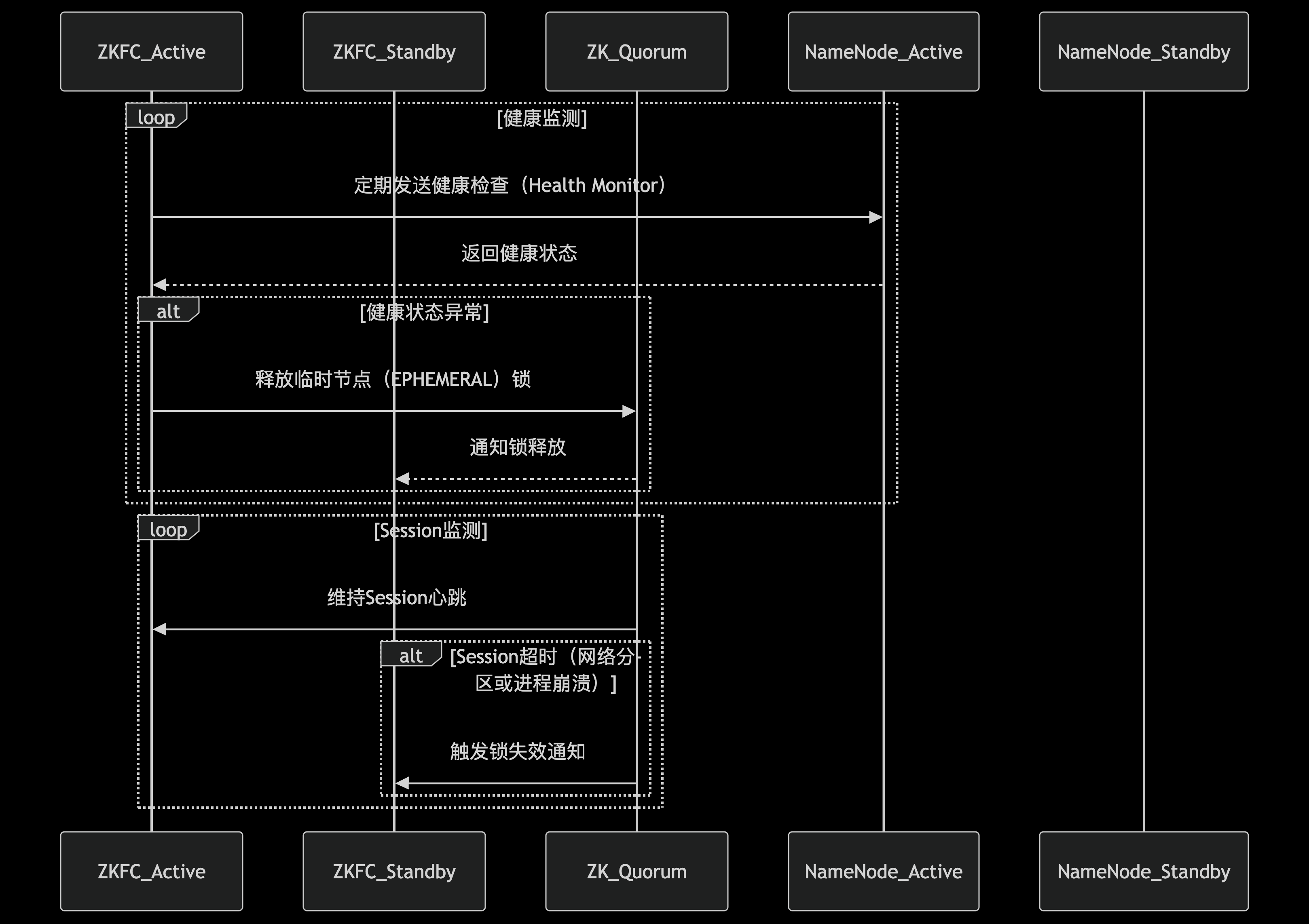
ZKFC内部由三个核心模块构成一个精密的监控-决策-执行体系。首先是HealthMonitor模块,它通过定期向本地NameNode发送健康检查请求(默认每5秒一次),持续评估NameNode的运行状态。检查内容包括RPC响应能力、文件系统健康状况等关键指标。根据检测结果,NameNode可能被标记为四种状态之一:初始化中(INITIALIZING)、服务正常(SERVICE_HEALTHY)、服务异常(SERVICE_UNHEALTHY)、或者连接失败(SERVICE_NOT_RESPONDING)。
第二个关键组件是ActiveStandbyElector,它负责管理NameNode在ZooKeeper中的会话状态。当本地NameNode健康时,ZKFC会在ZooKeeper中维持一个活跃会话(session)。如果该NameNode处于活动状态,还会在ZooKeeper的指定路径(如/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock)创建一个临时节点(ephemeral node),这个节点实际上就是一把分布式锁。ZooKeeper的特性保证了同一时刻只有一个客户端能成功创建该节点,从而确保集群中只有一个Active NameNode。
第三个组件ZKFailoverController作为总协调者,负责处理来自HealthMonitor和ActiveStandbyElector的事件通知,并根据预设策略决定是否触发故障转移。这种模块化设计使得系统各部分的职责清晰明确,便于维护和扩展。
故障检查流程图
故障检测与状态转换机制
ZKFC的故障检测机制采用多层次的健康评估策略。除了基本的进程存活检查外,还包括对NameNode关键服务的深度探测。当HealthMonitor检测到本地NameNode连续多次(可配置)未能通过健康检查时,会向ZKFailoverController发送状态变更通知。值得注意的是,此时系统并不会立即触发切换,而是进入一个"观察期",避免因网络抖动等瞬时问题导致的误判。
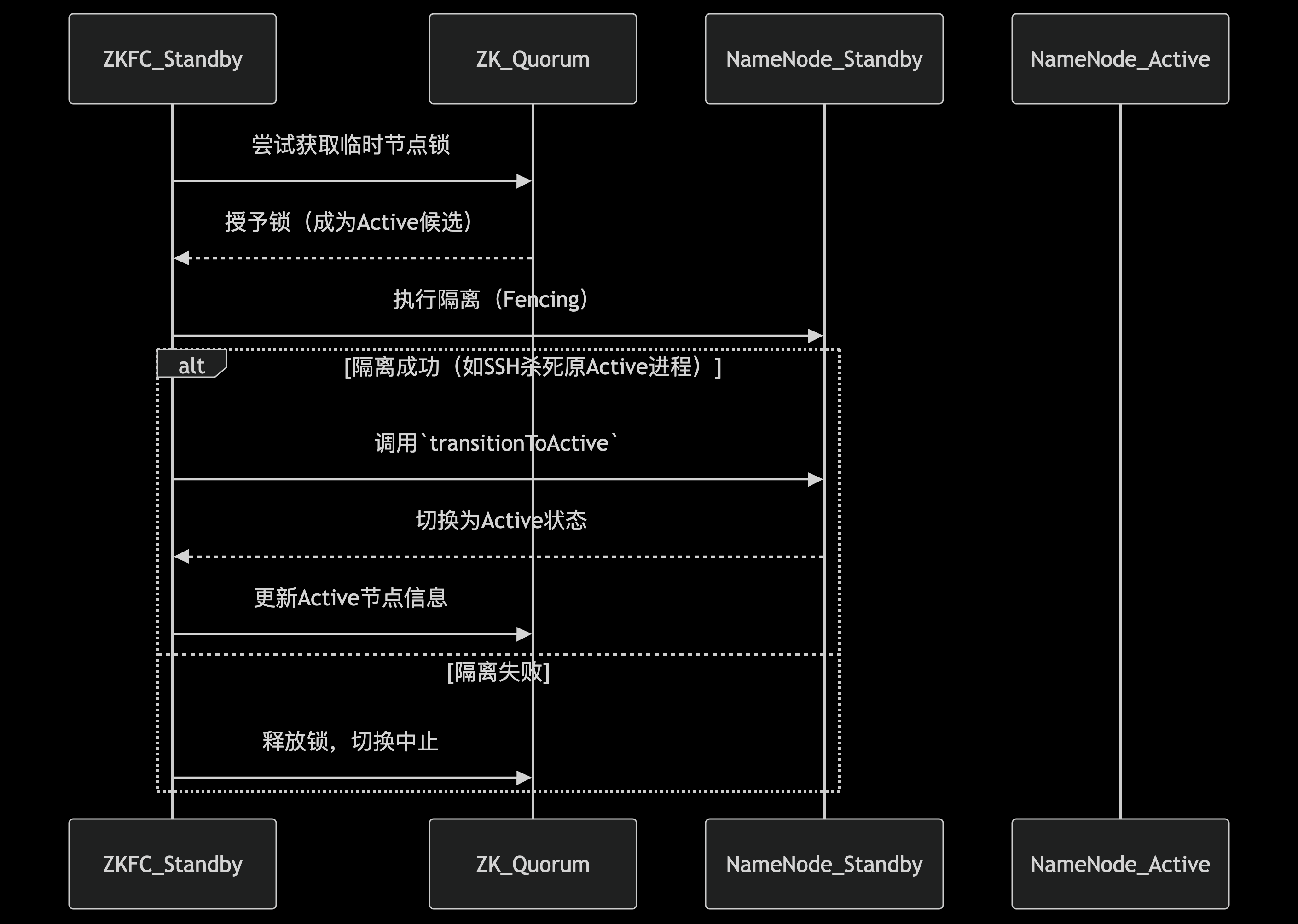
在状态转换过程中,ZKFC会综合考虑多方因素做出决策。如果检测到当前Active NameNode失效,ZKFC首先会尝试通过"防护隔离"(fencing)机制确保原Active节点不能再进行任何写操作。常见的隔离手段包括:通过SSH远程终止NameNode进程、撤销其访问共享存储的权限,或者调用预配置的防护脚本。这一步骤至关重要,可以防止"脑裂"(split-brain)情况的发生,即两个NameNode同时认为自己是Active节点。
基于ZooKeeper的选举流程
当需要进行主备切换时,ZKFC通过ZooKeeper实现了一个高效的选举算法。所有健康的Standby NameNode都会尝试在ZooKeeper上创建同一个临时节点,由于ZooKeeper的强一致性保证,最终只有一个客户端能够创建成功。这个成功的ZKFC随即将其监控的NameNode提升为Active状态。
选举过程中有几个关键细节值得注意:首先,每个参与选举的NameNode都会携带一个单调递增的epoch编号,这个编号在每次主备切换时都会增加,确保系统能够识别最新的选举请求。其次,ZooKeeper的watcher机制使得所有参与者能够实时感知到锁节点的变化,一旦当前Active节点释放锁(通常是因为会话过期),其他节点会立即收到通知并触发新一轮选举。
故障切换的完整流程
一个完整的自动故障切换流程通常包含以下步骤:
- 1. HealthMonitor检测到Active NameNode失效,通知ZKFailoverController。
- 2. ZKFC验证问题确实存在(避免误报),然后通过ActiveStandbyElector释放ZooKeeper上的锁节点。
- 3. 所有Standby NameNode的ZKFC检测到锁节点消失,开始新一轮选举。
- 4. 选举获胜的ZKFC执行防护隔离操作,确保原Active节点不再工作。
- 5. 新的Active NameNode加载最新的元数据(通过JournalNode同步),并开始对外服务。
- 6. 所有DataNode根据心跳机制自动重新注册到新的Active NameNode。
整个切换过程通常在几十秒内完成(具体时间取决于配置参数如会话超时时间等),对上层应用的影响可以降到最低。Hadoop管理员可以通过调整参数如dfs.ha.fencing.methods(防护方法)、ha.zookeeper.session-timeout.ms(ZooKeeper会话超时)等来优化切换速度和可靠性。
异常处理与恢复机制
在实际生产环境中,网络分区、ZooKeeper集群不稳定等情况时有发生。ZKFC设计了多种机制来应对这些异常场景。例如,当ZKFC与ZooKeeper集群失去连接时,它会进入一个"中立"状态,既不会尝试获取Active锁,也不会放弃现有锁(如果是Active节点),直到连接恢复。这种保守策略避免了在网络不稳定的情况下频繁触发无意义的切换。
另一个重要特性是graceful failover(优雅故障转移),管理员可以通过命令行工具手动触发主备切换,而不需要实际发生故障。这在计划维护时非常有用。执行过程中,ZKFC会协调两个NameNode完成状态转换,确保元数据完全同步后再进行角色切换,实现零数据丢失。
性能优化与监控建议
为了确保ZKFC的高效运行,有几个关键配置参数需要注意:
- • dfs.ha.heartbeat.interval:控制健康检查的频率,需要平衡及时性和系统开销
- • ha.zookeeper.acl:设置适当的ZooKeeper访问权限,保障安全性
- • dfs.ha.automatic-failover.enabled:明确是否启用自动故障转移功能
监控方面,除了常规的进程存活检查外,还应特别关注:
- • ZKFC与ZooKeeper的连接延迟
- • 健康检查的成功率与时延
- • 主备切换的历史记录和耗时统计
- • ZooKeeper锁节点的状态变化
主备切换流程图
这些指标可以帮助管理员提前发现潜在问题,如网络延迟增大可能导致误判,或者JournalNode同步延迟可能延长切换时间等。
JournalNode的元数据同步机制
在HDFS高可用架构中,JournalNode集群承担着元数据同步中枢的关键角色。这套基于Paxos算法的分布式系统设计,解决了传统NFS共享存储方案的单点故障问题,为双NameNode提供了高可靠的元数据同步通道。
JournalNode的核心架构设计
JournalNode集群通常由奇数个节点组成(最少3个),采用Quorum机制确保数据一致性。每个JournalNode独立运行轻量级服务进程,维护着完整的edit log序列。这种去中心化设计使得系统在部分节点故障时仍能保持可用——只要超过半数的JournalNode节点存活,集群就能继续提供服务。与传统的NFS共享存储相比,JournalNode方案具有更好的水平扩展能力和容错性。
元数据写入的原子性保证
当Active NameNode执行元数据变更时,会通过两阶段提交协议确保数据一致性:
- 1. 准备阶段:Active NN将edit log条目并行发送给所有JournalNode,但并不立即提交。此时JournalNode将数据暂存于内存缓冲区,同时持久化到本地磁盘的临时区域。
- 2. 提交阶段:当收到多数JournalNode(N/2+1)的ACK响应后,Active NN广播提交指令。JournalNode收到指令后,将临时数据原子性地移动到正式存储位置,并更新最后提交的事务ID(Transaction ID)。
这种设计确保了即使在网络分区或节点故障的情况下,系统也能维持强一致性——要么所有可用JournalNode都成功提交事务,要么全部回滚。
实时同步与追赶机制
Standby NameNode通过以下机制保持与Active节点的元数据同步:
- 1. 长轮询监听:Standby NN持续向JournalNode集群发送携带最后已知事务ID的GET请求。JournalNode会保持连接开放,直到有新数据到达或超时,大幅减少轮询开销。
- 2. 分段批量拉取:当检测到落后较多时(如故障恢复场景),Standby NN会自动切换为批量拉取模式,每次获取多个事务块,通过流水线传输优化同步效率。
- 3. 校验与重试机制:每条edit log都包含CRC32校验码,Standby NN在应用变更前会验证数据完整性。当发现数据损坏时,会自动从其他JournalNode节点重新拉取。
数据持久化与恢复策略
JournalNode采用多级持久化策略保障数据安全:
- 1. 内存缓冲:最新接收的edit log首先存入环形缓冲区,支持快速读写。
- 2. 本地磁盘存储:数据同步写入本地文件系统,采用滚动文件机制管理(默认每100万条记录或1小时生成新文件)。
- 3. 定期检查点:与NameNode的checkpoint机制协同工作,定期将edit log合并到fsimage,减少恢复时的重放负载。
在节点崩溃恢复场景中,JournalNode启动时会执行以下操作:
- • 检查最后提交的事务ID与磁盘文件的一致性
- • 通过与其他JournalNode比对事务日志来修复潜在的不一致
- • 重建内存中的事务索引表
性能优化关键技术
- 1. 批量写入:Active NN将多个元数据操作打包成单个RPC请求发送,显著减少网络往返开销。测试数据显示,批量大小设置为100-200条时吞吐量可提升3-5倍。
- 2. 异步化处理:JournalNode采用事件驱动架构,网络I/O、磁盘写入和副本同步操作都在独立线程池中执行,避免阻塞关键路径。
- 3. 内存映射文件:对历史edit log文件使用mmap技术,加速Standby NN的随机读取操作。
异常处理机制
当出现网络分区或节点故障时,系统通过以下策略维持可用性:
- • 写入超时处理:Active NN在500ms(默认)未收到JournalNode响应时,会标记该节点为临时不可用,转而将数据发送给其他健康节点。
- • 多数派原则:只要收到多数JournalNode的成功响应,就认为写入成功,少数落后节点会通过后台同步线程逐步追赶。
- • 脑裂防护:结合ZKFC的fencing机制,确保故障时只有一个NameNode能向JournalNode写入数据。
实际部署中,JournalNode集群通常与ZKFC、NameNode分开部署,避免资源竞争。对于超大规模集群(PB级以上),建议采用专用高性能SSD存储JournalNode数据,并将RPC超时参数(dfs.journalnode.rpc-timeout.ms)根据网络延迟情况适当调大。
HDFS HA的最佳实践与挑战
部署HDFS HA的最佳实践
在Hadoop生产环境中部署HDFS高可用集群时,遵循特定配置原则和操作流程至关重要。根据Hadoop社区推荐和实际运维经验,以下关键实践已被证明能显著提升系统稳定性:
网络与硬件配置
建议采用专用网络隔离JournalNode集群与常规数据传输通道,避免元数据同步流量与数据块传输产生竞争。JournalNode节点应部署在独立的物理服务器上,至少配置3个节点(满足2N+1原则),每个节点配备高性能SSD存储以降低编辑日志写入延迟。NameNode节点建议采用相同硬件规格,确保备用节点具备同等处理能力。
关键参数调优
在hdfs-site.xml中,dfs.journalnode.edits.dir应指向高性能存储设备,并定期清理历史编辑日志。ZKFC的健康检查间隔(ha.zookeeper.session-timeout.ms)需要根据网络延迟调整,典型值为5-15秒。对于大规模集群,应增大dfs.namenode.shared.edits.dir的写入缓冲区(dfs.journalnode.output-buffer-size),默认4MB可提升至8-16MB。
安全配置要点
启用Kerberos认证时,必须为每个JournalNode配置独立keytab文件,并确保ZKFC进程具备访问ZooKeeper的权限。建议设置dfs.ha.fencing.methods包含SSH和shell两种隔离方法,防止脑裂场景下出现双主节点。例如:
<property><name>dfs.ha.fencing.methods</name><value>sshfence(hdfs@nn1),shell(/path/to/fence_script.sh)</value>
</property>监控体系构建
除了基础的健康状态监控外,需要特别关注JournalNode的QJM(Quorum Journal Manager)指标,包括:
- •
JournalTransactionLag:反映Standby NN同步延迟 - •
LastWriterEpoch:检测编辑日志写入连续性 - •
RpcRequestQueueSize:评估JournalNode处理能力
推荐使用Prometheus+Grafana组合实现指标可视化,设置dfs.journalnode.metrics.*相关参数暴露关键指标。
运维过程中的典型挑战与解决方案
脑裂场景处理
当ZKFC因网络分区无法与ZooKeeper通信时,可能出现两个NameNode同时处于Active状态。此时依赖预配置的隔离机制至关重要。某电商平台案例显示,通过组合SSH隔离(终止原Active NN进程)和STONITH(Shoot The Other Node In The Head)硬件级隔离,可将故障恢复时间控制在30秒内。关键配置包括:
<property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value>
</property>
<property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hdfs/.ssh/id_rsa</value>
</property>JournalNode性能瓶颈
在写入密集型场景下,JournalNode可能成为系统瓶颈。某金融机构的测试数据显示,当每秒编辑日志操作超过5000次时,3节点JournalNode集群的写入延迟从平均2ms骤增至50ms。解决方案包括:
- 1. 升级至JournalNode 3.0+版本,支持批处理写入
- 2. 调整
dfs.journalnode.threads参数至CPU核心数的2倍 - 3. 采用RDMA网络降低节点间通信延迟
- 4. 定期使用
hdfs dfsadmin -getJournalState命令检查集群一致性
ZKFC误切换问题
由于GC暂停或系统负载过高导致NameNode响应延迟,可能触发ZKFC误判。某电信运营商通过以下改进将误切换率降低90%:
- • 设置
ha.health-monitor.connect-retry-interval.ms为渐进式增长间隔(初始1秒,最大10秒) - • 增加
ha.health-monitor.rpc-timeout.ms至60秒 - • 在ZKFC中实现动态健康评分机制,综合考量JVM状态和系统负载
元数据同步异常
当Active NN与JournalNode集群间出现持续网络中断时,可能导致编辑日志断裂。此时需要人工介入处理:
- 1. 使用
hdfs dfsadmin -fetchImage从最新状态的NN获取元数据镜像 - 2. 通过
hdfs namenode -bootstrapStandby重建备用节点 - 3. 验证JournalNode序列号连续性(
journalnode -getJournalStatus)
某云服务商开发了自动化修复工具,可将此过程从小时级缩短至分钟级。
版本升级与兼容性管理
HDFS HA集群的版本升级需要特殊处理流程。实践证明,滚动升级策略配合以下步骤可最大限度减少服务中断:
- 1. 首先升级JournalNode集群并验证QJM协议版本兼容性
- 2. 将Standby NN升级至新版本并完成元数据同步
- 3. 通过
hdfs haadmin -failover主动切换主备节点 - 4. 升级原Active NN节点
关键检查点包括:
- • 确认
dfs.journalnode.rpc-address在新旧版本间保持一致 - • 验证ZKFC的ACL权限在升级后未被重置
- • 检查
dfs.ha.automatic-failover.enabled配置是否保持为true
对于与上层组件(如Hive、Spark)的兼容性问题,典型案例是Hive metastore仍指向旧NN地址。解决方案包括:
- • 批量更新metastore中SDS表的LOCATION字段
- • 配置HDFS客户端使用逻辑服务ID(如
hdfs://mycluster)而非物理地址 - • 在core-site.xml中设置
fs.defaultFS为HA集群名称服务
未来展望:HDFS HA的发展方向
云原生架构下的HDFS HA演进
随着Kubernetes成为容器编排的事实标准,HDFS与云原生技术的融合正成为重要趋势。最新实践表明,通过将NameNode、JournalNode等组件容器化部署为Kubernetes StatefulSet,可以实现更灵活的弹性扩缩容。云原生AI工作负载的兴起(如白皮书《Cloud Native AI Whitepaper》所述)对存储系统提出了新要求,HDFS HA需要适应微服务架构下的动态资源调度特性。未来可能出现的"Serverless HDFS"模式,将允许按需启动NameNode实例,结合Kubernetes的Volcano调度器优化批处理作业的资源分配。
智能化的故障预测与自愈机制
传统ZKFC基于心跳超时的故障检测存在滞后性,新兴的AIOps技术为HA系统带来变革可能。通过收集NameNode的JVM指标、操作系统性能数据以及历史故障模式,机器学习模型可以实现:
- • 基于时间序列预测的故障预判(在节点完全宕机前触发优雅切换)
- • 自适应阈值调整(根据负载动态设置心跳超时阈值)
- • 根因分析辅助决策(区分网络分区与真实节点故障)
华为云等厂商已在实验性项目中验证,这类技术可将故障切换时间缩短30%以上,同时降低误切换概率。
跨地域元数据同步的突破
当前JournalNode的Quorum写入机制在跨地域部署时面临延迟挑战。学术界提出的"分层日志同步"方案值得关注:
- 1. 区域内部采用强一致性同步
- 2. 跨区域通过异步复制+冲突解决算法保证最终一致性
- 3. 引入向量时钟技术追踪元数据修改顺序
阿里云在2023年的测试中实现了北京-上海双活部署,元数据同步延迟控制在500ms内。未来可能结合RDMA网络优化JournalNode通信协议,进一步降低同步开销。
存储计算分离架构的适配优化
现代大数据平台普遍采用存储计算分离架构,这对HDFS HA提出新要求:
- • 轻量化NameNode:剥离数据块管理功能,专注命名空间服务
- • 持久化内存应用:使用Intel Optane PMem加速EditLog写入
- • 对象存储集成:通过HDFS-Ozone Connector实现元数据与数据的分离高可用
Cloudera CDP7已支持将NameNode元数据存储在外部数据库,这种设计可能成为未来标准,使HA部署不再依赖JournalNode集群。
安全增强与多租户隔离
随着企业级应用深化,HDFS HA需要在安全领域持续改进:
- 1. 零信任架构整合:每次主备切换时动态轮换Kerberos凭证
- 2. TEE可信执行环境:在SGX enclave中运行关键切换逻辑
- 3. 细粒度审计追踪:记录所有HA操作到区块链日志
某金融机构POC项目显示,这些措施可使系统通过金融级安全认证,同时保持亚秒级故障恢复能力。
边缘计算场景的轻量级方案
针对边缘设备资源受限的特点,新兴的"微型HA"方案正在发展:
- • 基于Raft共识算法替代ZKFC(减少ZooKeeper依赖)
- • 差分元数据同步(仅传输修改部分)
- • 智能压缩算法处理EditLog
华为边缘AI解决方案已实现500MB内存占用下的双节点HA部署,为IoT场景提供新可能。
性能监控体系的智能化重构
传统基于SNMP的监控体系难以满足现代需求,下一代监控方案可能包含:
- • 分布式追踪集成(通过OpenTelemetry捕获全链路HA事件)
- • 因果推理引擎(分析切换延迟与底层硬件状态的关联)
- • 预测性容量规划(基于工作负载预测提前扩容JournalNode集群)
某电信运营商在实验环境中部署的AI监控系统,成功将计划外停机减少了45%。




)





)




)

)

