第一步: Depth Anything V2介绍
本文介绍了 Depth Anything V2。在不追求复杂技术的前提下,我们旨在揭示一些关键发现,为构建强大的单目深度估计模型铺平道路。与 V1 [89] 相比,本版本通过三项关键实践产生了更精细且更鲁棒的深度预测:1)用合成图像替代所有标注的真实图像;2)扩大教师模型的容量;3)通过大规模伪标签真实图像的桥梁来训练学生模型。与基于稳定扩散(Stable Diffusion)构建的最新模型 [31] 相比,我们的模型在效率上显著更高(速度提升超过 10 倍),且更为准确。我们提供了不同规模的模型(参数量从 2500 万到 13 亿不等),以支持广泛的应用场景。得益于其强大的泛化能力,我们对其进行了度量深度标签的微调,以获得我们的度量深度模型。除了我们的模型外,考虑到当前测试集的多样性有限且常常存在噪声,我们构建了一个多功能评估基准,具有精确的标注和多样的场景,以促进未来的研究。

第二步:Depth Anything V2模型框架
训练 Depth Anything V2 的模型流程包括三个主要步骤:
- 在高质量合成图像上训练基于 DINOv2-G 编码器的教师模型。
- 在大规模未标记的真实图像上生成准确的伪深度。
- 在伪标记的真实图像上训练最终的学生模型,以实现稳健的泛化。
以下是 Depth Anything V2 训练过程的更简单说明:

第三步:模型代码展示
import cv2
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.transforms import Composefrom .dinov2 import DINOv2
from .util.blocks import FeatureFusionBlock, _make_scratch
from .util.transform import Resize, NormalizeImage, PrepareForNetdef _make_fusion_block(features, use_bn, size=None):return FeatureFusionBlock(features,nn.ReLU(False),deconv=False,bn=use_bn,expand=False,align_corners=True,size=size,)class ConvBlock(nn.Module):def __init__(self, in_feature, out_feature):super().__init__()self.conv_block = nn.Sequential(nn.Conv2d(in_feature, out_feature, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(out_feature),nn.ReLU(True))def forward(self, x):return self.conv_block(x)class DPTHead(nn.Module):def __init__(self, in_channels, features=256, use_bn=False, out_channels=[256, 512, 1024, 1024], use_clstoken=False):super(DPTHead, self).__init__()self.use_clstoken = use_clstokenself.projects = nn.ModuleList([nn.Conv2d(in_channels=in_channels,out_channels=out_channel,kernel_size=1,stride=1,padding=0,) for out_channel in out_channels])self.resize_layers = nn.ModuleList([nn.ConvTranspose2d(in_channels=out_channels[0],out_channels=out_channels[0],kernel_size=4,stride=4,padding=0),nn.ConvTranspose2d(in_channels=out_channels[1],out_channels=out_channels[1],kernel_size=2,stride=2,padding=0),nn.Identity(),nn.Conv2d(in_channels=out_channels[3],out_channels=out_channels[3],kernel_size=3,stride=2,padding=1)])if use_clstoken:self.readout_projects = nn.ModuleList()for _ in range(len(self.projects)):self.readout_projects.append(nn.Sequential(nn.Linear(2 * in_channels, in_channels),nn.GELU()))self.scratch = _make_scratch(out_channels,features,groups=1,expand=False,)self.scratch.stem_transpose = Noneself.scratch.refinenet1 = _make_fusion_block(features, use_bn)self.scratch.refinenet2 = _make_fusion_block(features, use_bn)self.scratch.refinenet3 = _make_fusion_block(features, use_bn)self.scratch.refinenet4 = _make_fusion_block(features, use_bn)head_features_1 = featureshead_features_2 = 32self.scratch.output_conv1 = nn.Conv2d(head_features_1, head_features_1 // 2, kernel_size=3, stride=1, padding=1)self.scratch.output_conv2 = nn.Sequential(nn.Conv2d(head_features_1 // 2, head_features_2, kernel_size=3, stride=1, padding=1),nn.ReLU(True),nn.Conv2d(head_features_2, 1, kernel_size=1, stride=1, padding=0),nn.ReLU(True),nn.Identity(),)def forward(self, out_features, patch_h, patch_w):out = []for i, x in enumerate(out_features):if self.use_clstoken:x, cls_token = x[0], x[1]readout = cls_token.unsqueeze(1).expand_as(x)x = self.readout_projects[i](torch.cat((x, readout), -1))else:x = x[0]x = x.permute(0, 2, 1).reshape((x.shape[0], x.shape[-1], patch_h, patch_w))x = self.projects[i](x)x = self.resize_layers[i](x)out.append(x)layer_1, layer_2, layer_3, layer_4 = outlayer_1_rn = self.scratch.layer1_rn(layer_1)layer_2_rn = self.scratch.layer2_rn(layer_2)layer_3_rn = self.scratch.layer3_rn(layer_3)layer_4_rn = self.scratch.layer4_rn(layer_4)path_4 = self.scratch.refinenet4(layer_4_rn, size=layer_3_rn.shape[2:]) path_3 = self.scratch.refinenet3(path_4, layer_3_rn, size=layer_2_rn.shape[2:])path_2 = self.scratch.refinenet2(path_3, layer_2_rn, size=layer_1_rn.shape[2:])path_1 = self.scratch.refinenet1(path_2, layer_1_rn)out = self.scratch.output_conv1(path_1)out = F.interpolate(out, (int(patch_h * 14), int(patch_w * 14)), mode="bilinear", align_corners=True)out = self.scratch.output_conv2(out)return outclass DepthAnythingV2(nn.Module):def __init__(self, encoder='vitl', features=256, out_channels=[256, 512, 1024, 1024], use_bn=False, use_clstoken=False):super(DepthAnythingV2, self).__init__()self.intermediate_layer_idx = {'vits': [2, 5, 8, 11],'vitb': [2, 5, 8, 11], 'vitl': [4, 11, 17, 23], 'vitg': [9, 19, 29, 39]}self.encoder = encoderself.pretrained = DINOv2(model_name=encoder)self.depth_head = DPTHead(self.pretrained.embed_dim, features, use_bn, out_channels=out_channels, use_clstoken=use_clstoken)def forward(self, x):patch_h, patch_w = x.shape[-2] // 14, x.shape[-1] // 14features = self.pretrained.get_intermediate_layers(x, self.intermediate_layer_idx[self.encoder], return_class_token=True)depth = self.depth_head(features, patch_h, patch_w)depth = F.relu(depth)return depth.squeeze(1)@torch.no_grad()def infer_image(self, raw_image, input_size=518):image, (h, w) = self.image2tensor(raw_image, input_size)depth = self.forward(image)depth = F.interpolate(depth[:, None], (h, w), mode="bilinear", align_corners=True)[0, 0]return depth.cpu().numpy()def image2tensor(self, raw_image, input_size=518): transform = Compose([Resize(width=input_size,height=input_size,resize_target=False,keep_aspect_ratio=True,ensure_multiple_of=14,resize_method='lower_bound',image_interpolation_method=cv2.INTER_CUBIC,),NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),PrepareForNet(),])h, w = raw_image.shape[:2]image = cv2.cvtColor(raw_image, cv2.COLOR_BGR2RGB) / 255.0image = transform({'image': image})['image']image = torch.from_numpy(image).unsqueeze(0)DEVICE = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'image = image.to(DEVICE)return image, (h, w)
第四步:运行交互代码

第五步:整个工程的内容
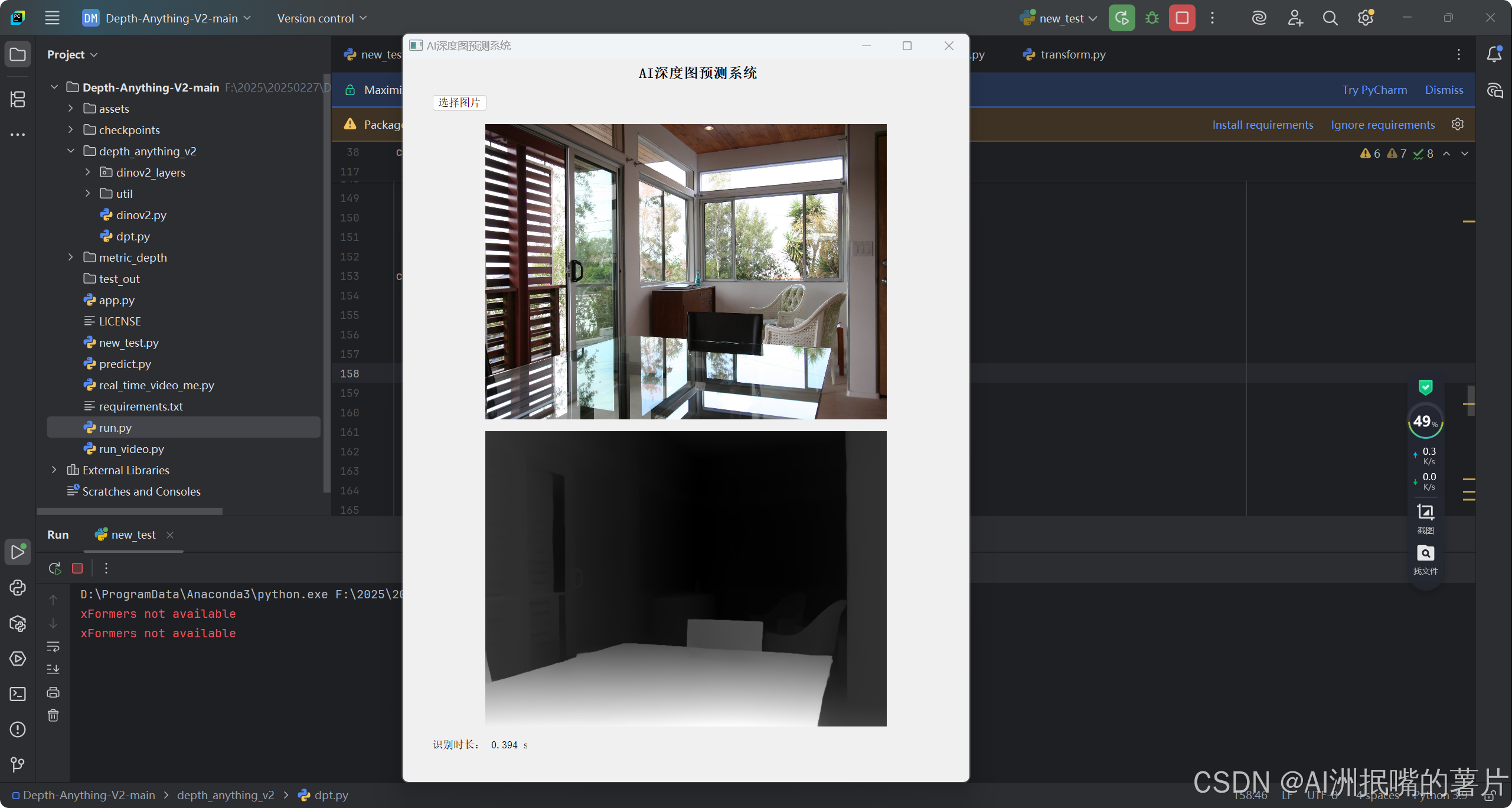
项目完整文件下载请见演示与介绍视频的简介处给出:➷➷➷
深度学习Depth Anything V2神经网络实现单目深度估计系统源码_哔哩哔哩_bilibili




 深度优先遍历(dfs) 暴力搜索 C++解题思路 每日一题)











)


